数据结构单向链表的插入和删除(一)
链表
- 一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)
- 二、单链表:
- 三、单项链表的代码实现:
- 四、开发可用的链表:
- 四、单链表的效率分析:
一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)
概念:
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
数据域:存数数据元素信息的域。
指针域:存储直接后继位置的域。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型:
根据链表的构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向循环链表
二、单链表:
概念:
链表的每个结点中只包含一个指针域,叫做单链表(即构成链表的每个结点只有一个指向直接后继结点的指针)
单链表中每个结点的结构:

1、头指针和头结点:
单链表有带头结点结构和不带头结点结构两种:
链表中第一个结点的存储位置叫做头指针”,如果链表有头结点,那么头指针就是指向头结点的指针。
头指针所指的不存放数据元素的第一个结点称作头结点(头结点指向首元结点)。头结点的数据域一般不放数据(当然有些情况下也可存放链表的长度、用做监视哨等)
存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
如下图所示:

不带头结点的单链表如下:

带头结点的单链表如下图:

2、不带头结点的单链表的插入操作:

上图中,是不带头结点的单链表的插入操作。如果我们在非第一个结点前进行插入操作,只需要a(i-1)的指针域指向s,然后将s的指针域指向a(i)就行了;如果我们在第一个结点前进行插入操作,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。
因此,算法对这两种情况就要分别设计实现方法。
3、带头结点的单链表的插入操作:(操作统一,推荐)

上图中,如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值(改变头结点的指针域),而头指针head的值不变。
因此,算法实现方法比较简单,其操作与对其它结点的操作统一。
三、单项链表的代码实现:
1、结点类:
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
步骤如下:
(1)头结点的构造(设置指针域即可)
(2)非头结点的构造
(3)获得当前结点的指针域
(4)获得当前结点数据域的值
(5)设置当前结点的指针域
(6)设置当前结点数据域的值
注:类似于get和set方法,成员变量是数据域和指针域。
代码实现:
(1)List.java:(链表本身也是线性表,只不过物理存储上不连续)
//线性表接口
public interface List {//获得线性表长度public int size();//判断线性表是否为空public boolean isEmpty();//插入元素public void insert(int index, Object obj) throws Exception;//删除元素public void delete(int index) throws Exception;//获取指定位置的元素public Object get(int index) throws Exception;
}
(2)Node.java:结点类
//结点类
public class Node {Object element; //数据域Node next; //指针域//头结点的构造方法public Node(Node nextval) {this.next = nextval;}//非头结点的构造方法public Node(Object obj, Node nextval) {this.element = obj;this.next = nextval;}//获得当前结点的指针域public Node getNext() {return this.next;}//获得当前结点数据域的值public Object getElement() {return this.element;}//设置当前结点的指针域public void setNext(Node nextval) {this.next = nextval;}//设置当前结点数据域的值public void setElement(Object obj) {this.element = obj;}public String toString() {return this.element.toString();}
}
2、单链表类:
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便
代码实现:
LinkList.java:单向链表类(核心代码)
//单向链表类
public class LinkList implements List {Node head; //头指针Node current;//当前结点对象int size;//结点个数//初始化一个空链表public LinkList(){//初始化头结点,让头指针指向头结点。并且让当前结点对象等于头结点。this.head = current = new Node(null);this.size =0;//单向链表,初始长度为零。}//定位函数,实现当前操作对象的前一个结点,也就是让当前结点对象定位到要操作结点的前一个结点。//比如我们要在a2这个节点之前进行插入操作,那就先要把当前节点对象定位到a1这个节点,然后修改a1节点的指针域public void index(int index) throws Exception{if(index <-1 || index > size -1){throw new Exception("参数错误!");}//说明在头结点之后操作。if(index==-1) //因为第一个数据元素结点的下标是0,那么头结点的下标自然就是-1了。return;current = head.next;int j=0;//循环变量while(current != null&&j<index){current = current.next;j++;}}@Overridepublic void delete(int index) throws Exception {// TODO Auto-generated method stub//判断链表是否为空if(isEmpty()){throw new Exception("链表为空,无法删除!");}if(index <0 ||index >size){throw new Exception("参数错误!");}index(index-1);//定位到要操作结点的前一个结点对象。current.setNext(current.next.next);size--;}@Overridepublic Object get(int index) throws Exception {// TODO Auto-generated method stubif(index <-1 || index >size-1){throw new Exception("参数非法!");}index(index);return current.getElement();}@Overridepublic void insert(int index, Object obj) throws Exception {// TODO Auto-generated method stubif(index <0 ||index >size){throw new Exception("参数错误!");}index(index-1);//定位到要操作结点的前一个结点对象。current.setNext(new Node(obj,current.next));size++;}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn size==0;}@Overridepublic int size() {// TODO Auto-generated method stubreturn this.size;}}3、测试类:(单链表的应用)
使用单链表建立一个线性表,依次输入十个0-99之间的随机数,删除第5个元素,打印输出该线性表。
(4)Test.java:
public class Test {public static void main(String[] args) throws Exception {// TODO Auto-generated method stubLinkList list = new LinkList();for (int i = 0; i < 10; i++) {int temp = ((int) (Math.random() * 100)) % 100;list.insert(i, temp);System.out.print(temp + " ");}list.delete(4);System.out.println("\n------删除第五个元素之后-------");for (int i = 0; i < list.size; i++) {System.out.print(list.get(i) + " ");}}}运行效果:

四、开发可用的链表:
对于链表实现,Node类是整个操作的关键,但是首先来研究一下之前程序的问题:Node是一个单独的类,那么这样的类是可以被用户直接使用的,但是这个类由用户直接去使用,没有任何的意义,即:Node这个类有用,但是不能让用户去用,只能让LinkList类去调用,内部类Node中完成。
于是,我们需要把Node类定义为内部类,并且在Node类中去完成addNode和delNote等操作。使用内部类的最大好处是可以和外部类进行私有操作的互相访问。
注:内部类访问的特点是:内部类可以直接访问外部类的成员,包括私有;外部类要访问内部类的成员,必须先创建对象。
*1、增加数据:
public Boolean add(数据 对象)
代码实现:
*(1)LinkList.java:(核心代码)
public class LinkList {private Node root; //定义一个根节点//方法:增加节点public boolean add(String data) {if (data == null) { // 如果添加的是一个空数据,那增加失败return false;}// 将数据封装为节点,目的:节点有next可以处理关系Node newNode = new Node(data);// 链表的关键就在于根节点if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)root = newNode;} else {root.addNode(newNode);}return true;}//定义一个节点内部类(假设要保存的数据类型是字符串)//比较好的做法是,将Node定义为内部类,在这里面去完成增删、等功能,然后由LinkList去调用增、删的功能class Node {private String data;private Node next; //next表示:下一个节点对象(单链表中)public Node(String data) {this.data = data;}public void addNode(Node newNode) {//下面这段用到了递归,需要反复理解if (this.next == null) { // 递归的出口:如果当前节点之后没有节点,说明我可以在这个节点后面添加新节点this.next = newNode; //添加新节点} else {this.next.addNode(newNode); //向下继续判断,直到当前节点之后没有节点为止}}}
}
代码解释:
14行:如果我们第一次调用add方法,那根结点肯定是空的,此时add的是根节点。
当继续调用add方法时,此时是往根节点后面添加数据,需要用到递归(42行),这个递归需要在内部类中去完成。递归这段代码需要去反复理解
(2)LinkListDemo.java:
public class LinkListDemo {public static void main(String[] args) {LinkList list = new LinkList();boolean flag = list.add("haha");System.out.println(flag);}}

2、增加多个数据:
public boolean addAll(数据 对象 [] )
上面的操作是每次增加了一个对象,那么如果现在要求增加多个对象呢,例如:增加对象数组。可以采用循环数组的方式,每次都调用add()方法。
在上面的(1)LinkList.java中加入如下代码:
//方法:增加一组数据public boolean addAll(String data[]) { // 一组数据for (int x = 0 ; x < data.length ; x ++) {if (!this.add(data[x])) { // 只要有一次添加不成功,那就是添加失败return false ;}}return true ;}
3、统计数据个数:
public int size()
在一个链表之中,会保存多个数据(每一个数据都被封装为Node类对象),那么要想取得这些保存元素的个数,可以增加一个size()方法完成。
具体做法如下:
在上面的(1)LinkList.java中增加一个统计的属性count:
private int size ; // 统计个数
当用户每一次调用add()方法增加新数据的时候应该做出统计:(下方第18行代码)
//添加节点public boolean add(String data) {if (data == null) { // 如果添加的是一个空数据,那增加失败return false;}// 将数据封装为节点,目的:节点有next可以处理关系Node newNode = new Node(data);// 链表的关键就在于根节点if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)root = newNode;} else {root.addNode(newNode);}this.size++;return true;}
而size()方法就是简单的将count这个变量的内容返回:
//获取数据的长度public int size() {return this.size;}
4、判断是否是空链表:
public boolean isEmpty()
所谓的空链表指的是链表之中不保存任何的数据,实际上这个null可以通过两种方式判断:一种判断链表的根节点是否为null,另外一个是判断保存元素的个数是否为0。
在LinkList.java中添加如下代码:
//判断是否为空链表public boolean isEmpty() {return this.size == 0;}
5、查找数据是否存在:
public boolean contains(数据 对象)
现在如果要想查询某个数据是否存在,那么基本的操作原理:逐个盘查,盘查的具体实现还是应该交给Node类去处理,但是在盘查之前必须有一个前提:有数据存在。
在LinkList.java中添加查询的操作:
//查询数据是否存在public boolean contains(String data) { // 查找数据// 根节点没有数据,查找的也没有数据if (this.root == null || data == null) {return false; // 不需要进行查找了}return this.root.containsNode(data); // 交给Node类处理}
紧接着,在Node类之中,完成具体的查询,查询的流程:
判断当前节点的内容是否满足于查询内容,如果满足返回true;
如果当前节点的内容不满足,则向后继续查,如果已经没有后续节点了,则返回false。
代码实现:
//判断节点是否存在public boolean containsNode(String data) { // 查找数据if (data.equals(this.data)) { // 与当前节点数据吻合return true;} else { // 与当前节点数据不吻合if (this.next != null) { // 还有下一个节点return this.next.containsNode(data);} else { // 没有后续节点return false; // 查找不到}}}
6、删除数据:
public boolean remove(数据 对象)
在LinkList.java中加入如下代码:
//方法:删除数据public boolean remove(String data) { //要删除的节点,假设每个节点的data都不一样if (!this.contains(data)) { //要删除的数据不存在return false;}if (root != null) {if (root.data.equals(data)) { //说明根节点就是需要删除的节点root = root.next; //让根节点的下一个节点成为根节点,自然就把根节点顶掉了嘛(不像数组那样,要将后面的数据在内存中整体挪一位)} else { //否则root.removeNode(data);}}size--;return true;}
注意第2代码中,我们是假设删除的这个String字符串是唯一的,不然就没法删除了。
删除时,我们需要从根节点开始判断,如果根节点是需要删除的节点,那就直接删除,此时下一个节点变成了根节点。
然后,在Node类中做节点的删除:
//删除节点public void removeNode(String data) {if (this.next != null) {if (this.next.data.equals(data)) {this.next = this.next.next;} else {this.next.removeNode(data);}}}
7、输出所有节点:
在LinkList.java中加入如下代码:
//输出所有节点public void print() {if (root != null) {System.out.print(root.data);root.printNode();System.out.println();}}
然后,在Node类中做节点的输出:
//输出所有节点public void printNode() {if (this.next != null) {System.out.print("-->" + this.next.data);this.next.printNode();}}
8、清空链表:
public void clear()
所有的链表被root拽着,这个时候如果root为null,那么后面的数据都会断开,就表示都成了垃圾:
//清空链表public void clear() {this.root = null;this.size = 0;}
总结:
上面的方法中,LinkList的完整代码如下:
/*** Created by smyhvae on 2015/8/27.*/public class LinkList {private int size;private Node root; //定义一个根节点private int foot = 0; // 操作返回数组的脚标private String[] retData; // 返回数组private boolean changeFlag = true;// changeFlag == true:数据被更改了,则需要重新遍历// changeFlag == false:数据没有更改,不需要重新遍历//添加数据public boolean add(String data) {if (data == null) { // 如果添加的是一个空数据,那增加失败return false;}// 将数据封装为节点,目的:节点有next可以处理关系Node newNode = new Node(data);// 链表的关键就在于根节点if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)root = newNode;} else {root.addNode(newNode);}this.size++;return true;}//方法:增加一组数据public boolean addAll(String data[]) { // 一组数据for (int x = 0; x < data.length; x++) {if (!this.add(data[x])) { // 只要有一次添加不成功,那就是添加失败return false;}}return true;}//方法:删除数据public boolean remove(String data) { //要删除的节点,假设每个节点的data都不一样if (!this.contains(data)) { //要删除的数据不存在return false;}if (root != null) {if (root.data.equals(data)) { //说明根节点就是需要删除的节点root = root.next; //让根节点的下一个节点成为根节点,自然就把根节点顶掉了嘛(不像数组那样,要将后面的数据在内存中整体挪一位)} else { //否则root.removeNode(data);}}size--;return true;}//输出所有节点public void print() {if (root != null) {System.out.print(root.data);root.printNode();System.out.println();}}//方法:获取全部数据public String[] toArray() {if (this.size == 0) {return null; // 没有数据}this.foot = 0; // 清零this.retData = new String[this.size]; // 开辟数组大小this.root.toArrayNode();return this.retData;}//获取数据的长度public int size() {return this.size;}//判断是否为空链表public boolean isEmpty() {return this.size == 0;}//清空链表public void clear() {this.root = null;this.size = 0;}//查询数据是否存在public boolean contains(String data) { // 查找数据// 根节点没有数据,查找的也没有数据if (this.root == null || data == null) {return false; // 不需要进行查找了}return this.root.containsNode(data); // 交给Node类处理}//方法:根据索引取得数据public String get(int index) {if (index > this.size) { // 超过个数return null; // 返回null}this.foot = 0; // 操作foot来定义脚标return this.root.getNode(index);}//定义一个节点内部类(假设要保存的数据类型是字符串)//比较好的做法是,将Node定义为内部类,在这里面去完成增删、等功能,然后由LinkList去调用增、删的功能class Node {private String data;private Node next; //next表示:下一个节点对象(单链表中)public Node(String data) {this.data = data;}//添加节点public void addNode(Node newNode) {//下面这段用到了递归,需要反复理解if (this.next == null) { // 递归的出口:如果当前节点之后没有节点,说明我可以在这个节点后面添加新节点this.next = newNode; //添加新节点} else {this.next.addNode(newNode); //向下继续判断,直到当前节点之后没有节点为止}}//判断节点是否存在public boolean containsNode(String data) { // 查找数据if (data.equals(this.data)) { // 与当前节点数据吻合return true;} else { // 与当前节点数据不吻合if (this.next != null) { // 还有下一个节点return this.next.containsNode(data);} else { // 没有后续节点return false; // 查找不到}}}//删除节点public void removeNode(String data) {if (this.next != null) {if (this.next.data.equals(data)) {this.next = this.next.next;} else {this.next.removeNode(data);}}}//输出所有节点public void printNode() {if (this.next != null) {System.out.print("-->" + this.next.data);this.next.printNode();}}//获取全部数据public void toArrayNode() {LinkList.this.retData[LinkList.this.foot++] = this.data;if (this.next != null) {this.next.toArrayNode();}}//根据索引位置获取数据public String getNode(int index) {if (LinkList.this.foot++ == index) { // 当前索引为查找数值return this.data;} else {return this.next.getNode(index);}}}
}
四、单链表的效率分析:
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:

删除单链表的一个数据元素时比较数据元素的平均次数为:

因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表读取数据元素操作的时间复杂度也为O(n)。
顺序表和单链表的比较:
顺序表:
优点:主要优点是支持随机读取,以及内存空间利用效率高;
缺点:主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
单链表:
优点:主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素;
缺点:主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。
相关文章:
数据结构单向链表的插入和删除(一)
链表 一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)二、单链表:三、单项链表的代码实现:四、开发可用的链表:四、单链表的效率分析: 一、链表结构&#x…...
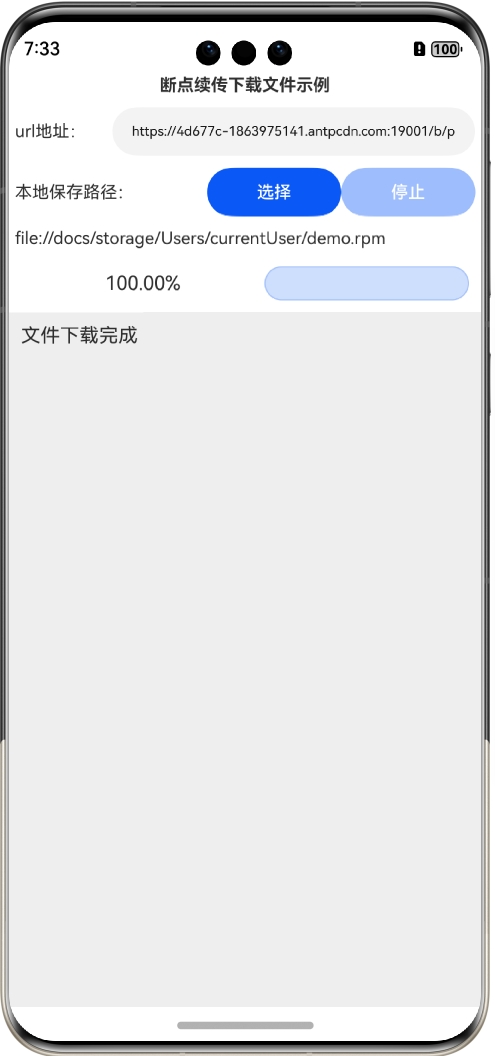
鸿蒙网络编程系列30-断点续传下载文件示例
1. 断点续传简介 在文件的下载中,特别是大文件的下载中,可能会出现各种原因导致的下载暂停情况,如果不做特殊处理,下次还需要从头开始下载,既浪费了时间,又浪费了流量。不过,HTTP协议通过Range…...
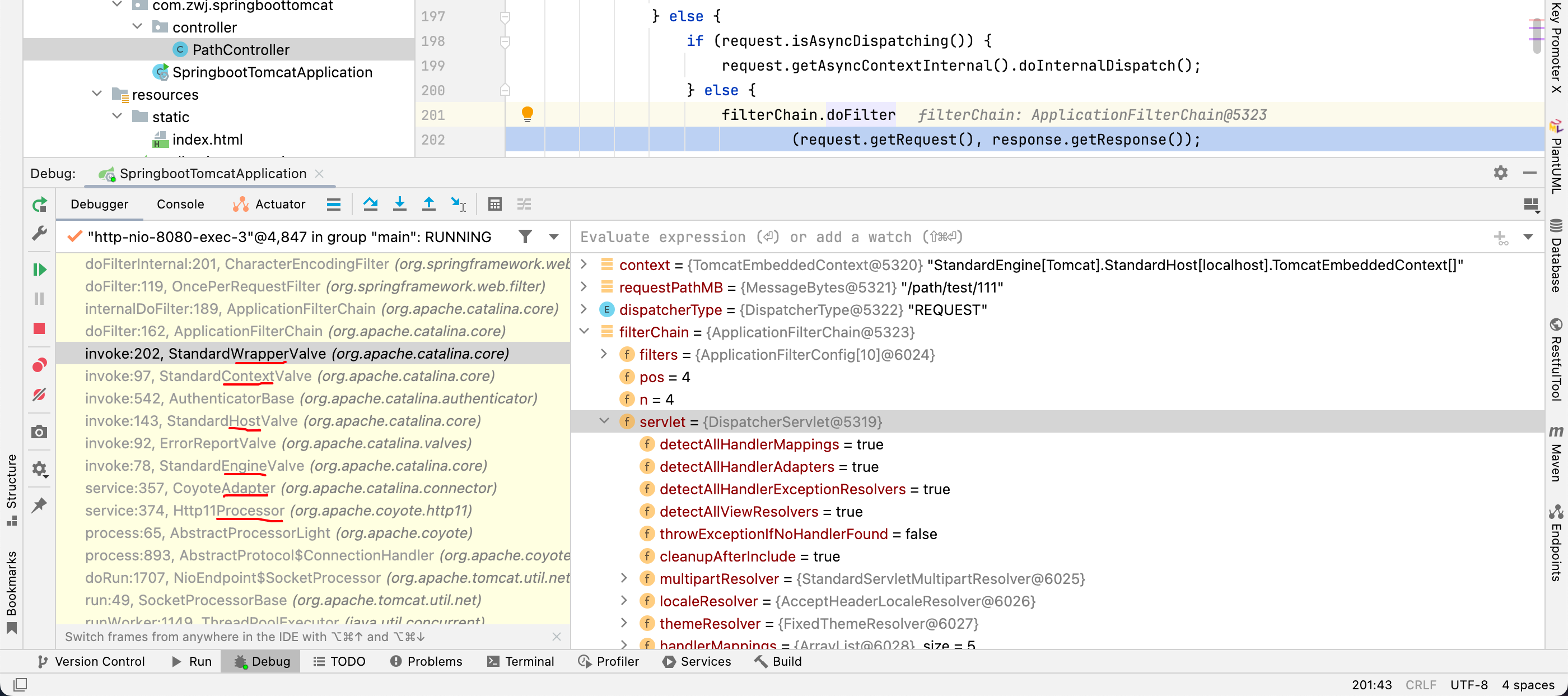
深入拆解TomcatJetty(二)
深入拆解Tomcat&Jetty(二) 专栏地址:https://time.geekbang.org/column/intro/100027701 1、Tomcat支持的IO模型和应用层协议 IO模型: NIO:非阻塞 I/O,采用 Java NIO 类库实现。NIO2:异…...

单元化架构,分布式系统的新王!
0 关键收获 单元化架构通过减少故障的爆炸半径来增加系统弹性单元化架构是那些任何停机时间都被认为是不可接受的,或者可以显著影响最终用户的系统的一个好选择单元化架构通过强制使用固定大小的单元作为部署单元,并倾向于扩展而不是扩展的方法…...

【力扣打卡系列】滑动窗口与双指针(乘积小于K的子数组)
坚持按题型打卡&刷&梳理力扣算法题系列,语言为go,Day6 乘积小于K的子数组 题目描述解题思路 双指针移动,遍历右端点right,滑动左端点left子数组的个数:固定右端点r,子数组的个数其实就是从l到r的元…...

浅谈微前端【qiankun】的应用
一、为什么要使用微前端 微前端的核心理念是将一个大型的单体前端应用拆分成多个独立的小型应用,以便各个应用能够独立开发、部署和更新。这带来了以下几个好处: 独立开发与部署:各个团队可以独立开发自己的子应用,快速上线新功能…...

【JavaEE】——四次挥手,TCP状态转换,滑动窗口,流量控制
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 一:断开连接的本质 二:四次挥手 1:FIN 2:过程梳理 …...

D42【python 接口自动化学习】- python基础之函数
day42 高阶函数 学习日期:20241019 学习目标:函数﹣- 55 高阶函数:函数对象与函数调用的用法区别 学习笔记: 函数对象和函数调用 # 函数对象和函数调用 def foo():print(foo display)# 函数对象 a foo print(a) # &…...
GitLab 老旧版本如何升级?
极狐GitLab 正式对外推出 GitLab 专业升级服务 https://dl.gitlab.cn/cm33bsfv! 专业的技术人员为您的 GitLab 老旧版本实例进行专业升级!服务详情可以在官网查看详细解读! 那些因为老旧版本而被攻击的例子 话不多说,直接上图&a…...

现今 CSS3 最强二维布局系统 Grid 网格布局
深入学习 CSS3 目前最强大的布局系统 Grid 网格布局 Grid 网格布局的基本认识 Grid 网格布局: Grid 布局是一个基于网格的二位布局系统,是目前 CSS 最强的布局系统,它可以同时对列和行进行处理(它将网页划分成一个个网格,可以任…...

【图解版】力扣第146题:LRU缓存
力扣第146题:LRU缓存 一、LRU算法1. 基本概念2. LRU 和 LFU 的区别:3. 为什么 LRU 不需要记录使用频率? 二、Golang代码实现三、代码图解1. LRUCache、DLinkedNode两个结构体2. 初始化结构体对象3. addToHead函数4. removeNode函数5. moveToH…...

数据库知识点整理
DDL DDL-数据库操作 show databases ------------ 查看所有数据库 select database(); ----------查看当前数据库 create database 数据库名;---- 创建数据库 use 数据库名; --------------使用数据库 drop database 数据库名;--…...

【JVM】内存模型
文章目录 内存模型的基本概念案例 程序计数器栈Java虚拟机栈局部变量表栈帧中局部变量表的实际状态栈帧中存放的数据有哪些 操作数栈帧数据 本地方法栈 堆堆空间是如何进行管理的? 方法区静态变量存储 直接内存直接内存的作用 内存模型的基本概念 在前面的学习中,我们知道了字…...

代码随想录:二叉树的四种遍历
144. 二叉树的前序遍历 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullpt…...

【Linux】从多线程同步到生产者消费者模型:多线程编程实践
目录 1.线程的同步 1.1.为什么需要线程的同步? 2.2.条件变量的接口函数 2.生产消费模型 2.1 什么是生产消费模型 2.2.生产者消费者模型优点 2.3.为何要使用生产者消费者模型 3.基于BlockingQueue的生产者消费者模型 3.1为什么要将if判断变成whileÿ…...
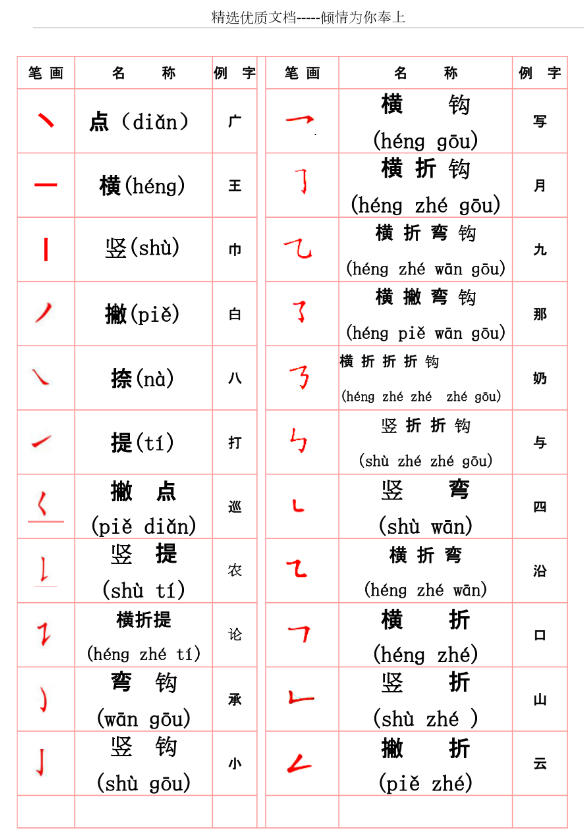
如何在word里面给文字加拼音?
如何在word里面给文字加拼音?在现代社会,阅读已经成为了我们日常生活中不可或缺的一部分。尤其是在学习汉语的过程中,拼音的帮助显得尤为重要。为了帮助大家更好地理解和掌握汉字的发音,许多教师和学生都希望能够在Word文档中为文…...

Detr论文精读
摘要: 作者提到,该方法将物体检测看做直接的集合预测,在传统的目标检测算法中,会先生成候选区域,然后对每个候选区域进行单独的预测(包括物体的分类和预测框的回归),集合预测就是直…...

找寻孤独伤感视频素材的热门资源网站推荐
在抖音上,伤感视频总是能够引起观众的共鸣,很多朋友都在寻找可以下载伤感视频素材的地方。作为一名资深的视频剪辑师,今天我来分享几个提供高清无水印伤感素材的网站,如果你也在苦苦寻找这些素材,不妨看看以下推荐&…...

大模型~合集13
我自己的原文哦~ https://blog.51cto.com/whaosoft/12302606 #TextRCNN、TextCNN、RNN 小小搬运工周末也要学习一下~~虽然和世界没关 但还是地铁上看书吧, 大老勿怪 今天来说一下 文本分类必备经典模型 模型 SOTA!模型资源站收录情况 模型来源论文 RAE ht…...

【Next.js 项目实战系列】04-修改 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】03-查看 Issue 修改 Issue 添加修改 Button 本节代码链接 安装 Radix UI 的 Ra…...

BAAI/bge-m3新手指南:无需代码基础,也能玩转高级语义分析模型
BAAI/bge-m3新手指南:无需代码基础,也能玩转高级语义分析模型 1. 什么是BAAI/bge-m3语义分析引擎 1.1 模型的基本功能 BAAI/bge-m3是一个强大的语义分析工具,它能理解文本背后的含义而不仅仅是表面的词语。想象一下,当你说&quo…...

别只盯着server.log了!Kafka Controller日志与GC日志里的“宝藏”与“陷阱”
别只盯着server.log了!Kafka Controller日志与GC日志里的“宝藏”与“陷阱” 当Kafka集群出现Leader选举异常、副本同步缓慢或频繁Full GC时,大多数工程师的第一反应是打开server.log翻找线索。但真正的高手会告诉你:controller.log和GC日志才…...

STM32启动模式详解与实战指南
1. STM32启动过程概述作为一名嵌入式开发工程师,理解STM32的启动过程是基本功。很多初学者在使用STM32时,往往只关注main函数中的代码,却忽略了芯片上电后到执行main函数之前发生了什么。实际上,从按下复位键到程序开始运行&#…...

OpenClaw密码管理方案:Qwen3-14b_int4_awq辅助生成与安全存储
OpenClaw密码管理方案:Qwen3-14b_int4_awq辅助生成与安全存储 1. 为什么需要AI辅助的密码管理 去年我的三个重要账户相继被盗,原因都是使用了简单密码和重复密码。传统密码管理器虽然解决了存储问题,但生成密码时往往缺乏场景适配性——那些…...

Topeka Android应用终极部署指南:从源码编译到多渠道分发的完整教程
Topeka Android应用终极部署指南:从源码编译到多渠道分发的完整教程 【免费下载链接】topeka A fun to play quiz that showcases material design on Android 项目地址: https://gitcode.com/gh_mirrors/to/topeka Topeka是一款基于Material Design设计理念…...

视觉障碍辅助:OpenClaw+Phi-3-vision-128k-instruct实时描述周围环境
视觉障碍辅助:OpenClawPhi-3-vision-128k-instruct实时描述周围环境 1. 项目背景与核心需求 去年在帮助一位视障朋友调试智能家居时,我意识到现有环境感知工具存在明显断层——要么是功能单一的"拍照识物"APP,要么是昂贵的企业级…...

Manim进阶技巧:如何用Python代码制作复杂的数学动画
Manim进阶技巧:如何用Python代码制作复杂的数学动画 数学可视化是理解抽象概念的有力工具,而Manim作为3Blue1Brown开发的数学动画引擎,已经成为科研、教育和科普领域的首选工具。当你已经掌握了基础图形的创建和简单动画效果后,如…...

汇川CodeSys PLC组态实战:从网络配置到硬件集成的核心步骤解析
1. 汇川PLC与CodeSys环境基础搭建 第一次接触汇川PLC和CodeSys组态时,我完全被各种专业术语搞懵了。后来在实际项目中摸爬滚打才发现,这套组合其实就像搭积木一样有趣。汇川PLC作为国产工控领域的佼佼者,搭配CodeSys这个国际通用的开发环境&a…...

obsidian claudian 插件配置使用minimax模型
首先,打开.claude/settings.json文件 sudo gedit .claude/settings.json参考官网配置 “ANTHROPIC_BASE_URL”: “https://api.minimaxi.com/anthropic”, “ANTHROPIC_AUTH_TOKEN”: “MINIMAX_API_KEY”, 等参数然后在claudian插件中在配置一遍,即可正…...

OpenClaw龙虾实用使用教程:一键安装工具分享,教“员工”上手,解锁你想要的效果
很多人安装完OpenClaw龙虾后,都会和我当初一样陷入一个误区:以为点击启动就能实现自己想要的功能,结果发现龙虾“无所适从”。其实OpenClaw龙虾就像一位新员工——它本身具备强大的潜力,但需要你耐心教导、提供足够的“资料”&…...