爬虫python=豆瓣Top250电影
主流程:获取数据,解析数据,保存数据
from bs4 import BeautifulSoup #网页解析获取数据
import re #正则表达式
import urllib.request,urllib.error #获取网页数据
import sqlite3 #轻量级数据库
import xlwt #进行excel操作
#影视详情链接的正则表达式
findLink=re.compile(r'<a href="(.*?)">')
#影视图片
findImgSrc=re.compile(r'<img.*?src="(.*?)"',re.S) #re.S让换行符包含在字符串中
#影片片名
findTitle=re.compile(r'<span class="title">(.*?)</span>')
#影片评分
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>')
#找到评价人数
findJudge=re.compile(r'<span>(\d*?)人评价</span>')
#找到概况
findInq=re.compile(r'<span class="inq">(.*?)</span>')
#找到影片的相关内容
findBd=re.compile(r'<p class="">(.*?)</p>',re.S)
def main():#要爬取的网页链接baseurl="https://movie.douban.com/top250?start="savepath="豆瓣电影Top250.xls"#1.爬取网页datalist=getData(baseurl)#2.保存数据saveData(datalist,savepath)
def getData(baseurl):datalist=[] #用来存储网页爬取的信息for i in range(0,10): #调用获取页面信息的函数url=baseurl+str(i*25)html=askURL(url) #保存获取的网页源码#2.逐一解析数据soup=BeautifulSoup(html,"html.parser")# print(soup.find_all('div',class_="item"))for item in soup.find_all('div',class_="item"):data=[] #保存一部电影所有信息item=str(item)link=re.findall(findLink,item)[0]data.append(link)imgSrc=re.findall(findImgSrc,item)[0]data.append(imgSrc)titles=re.findall(findTitle,item)if(len(titles)==2):ctitle=titles[0]data.append(ctitle)etitle=titles[1].replace("/","") #消除转义字符data.append(etitle)else:data.append(titles[0])data.append(" ")rating=re.findall(findRating,item)[0]data.append(rating)judgeNum=re.findall(findJudge,item)[0]data.append(judgeNum)inq=re.findall(findInq,item)if len(inq)!=0:inq=inq[0].replace("。","")data.append(inq)else:data.append(" ")bd=re.findall(findBd,item)[0]bd=re.sub('<br(\s+)?/>(\s+)?',"",bd)bd=re.sub('/',"",bd)data.append(bd.strip())datalist.append(data)return datalistdef askURL(url):head={ #模拟浏览器的头部信息,向豆瓣服务器发送消息"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"} #用户代理,告诉豆瓣服务器,我们是什么类型的机器request=urllib.request.Request(url,headers=head)html=""try:response=urllib.request.urlopen(request)html=response.read().decode("utf-8")except urllib.error.URLError as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)# print(html)return html
def saveData(datalist,savepath):print("save...........")book=xlwt.Workbook(encoding='utf-8',style_compression=0) #创建workbook对象sheet=book.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True) #创建工作表col=("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")for i in range(0,8):sheet.write(0,i,col[i]) #列名for i in range(0,250):data=datalist[i]for j in range(0,8):sheet.write(i+1,j,data[j])book.save(savepath)if __name__=="__main__":main()print("爬取完毕")
通过给出的基础网址链接,传入getData函数中进行拼接,得到每页的网址链接,通过再次传入askURL函数中,得到每页的html源码,并使用BeautifulSoup模块来解析html源码,使用其中的find_all方法来查找每个符合特定条件的元素,循环遍历,将每个元素正则匹配提取出我们需要的片名,评价人数,评分等信息,并逐一添加到列表data中,处理完一个电影(一个div元素),就把data添加到总的datalist列表中,进而得到所有电影的信息,并且以列表的形式进行存储,在askURL部分,主要是通过urllib.request.Request向服务器发送请求,并得到响应,这里创建了一个请求对象,这个过程中模拟了浏览器的头部信息(headers=head),防止一些网站的反爬机制导致的爬取失败,之后还需要使用urllib.request.urlopen(request),来得到响应对象,通过对响应对象读取和解码,之后就能得到该页的网页源码html,在数据保存阶段,则是通过xlwt库创建workbook对象,然后在这个对象中添加工作表,来写入爬取到的信息,首先要在第一行写入列名,之后从之前爬取下来存储在datalist的嵌套列表中获取每部电影的数据,datalist中的每个元素是一个列表,也就是一部电影,逐一写入,并最终sava(保存路径)
相关文章:

爬虫python=豆瓣Top250电影
主流程:获取数据,解析数据,保存数据 from bs4 import BeautifulSoup #网页解析获取数据 import re #正则表达式 import urllib.request,urllib.error #获取网页数据 import sqlite3 #轻量级数据库 import xlwt #进行excel操作 #影视详情…...

【Eclipse系列】解决Eclipse中xxx.properties文件中文乱码问题
问题描述:由于eclipse对Properties资源文件的编码的默认设置是ISO-8859-1,所以在打开.properties文件时,会发现中文乱码了,如图: 解决方法: 1、一次生效法 右击该properties文件–>properties–>Re…...

mysql主从复制及故障修复
一、主MySQL数据库的配置 分别在三台主机(chen2/10.110、chen3/10.120、chen4/10.130)中安装mysql数据,其中chen2/10.110作为主MySQL服务器,其余两台作为从MySQL服务器。 1、在主机上部署mysql数据库 详细的请看上一篇:mysql数据…...

基于springboot的网上服装购物商城系统
基于springboot的网上服装购物商城系统 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:idea 源码获取: &#x…...

aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理
aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理 学习内容: AWS的虚拟私有,共有子网以及ACL定义公网碉堡主机子网,私有子网和共有子网以及varnish反向代理 1. AWS的虚拟…...

接口测试(三)jmeter——连接mysql数据库
一、jmeter安装jdbc 1. 下载插件包,mysql数据库为例,驱动 com.mysql.jdbc.Driver 需要下载 mysql-connector-java-5.1.7-bin.jar 插件包,将插件包放到 jmeter 安装目录下的 lib 目录 2. 给jmeter安装jdbc驱动 二、jmeter操作数据库 1.…...

双十一购物节有哪些好物值得入手?2024双十一好物清单合集分享
一年一度的双十一购物狂欢节即将来临,各大平台纷纷开启预热活动,伴随着品牌的疯狂折扣和满减优惠,众多商品即将迎来超值的价格。现在正是大家“剁手”换新装备的大好时机。作为一名深耕智能产品多年的资深达人,今天这期我将从不同…...

jmeter中请求参数:Parameters、Body Data的区别
使用jmeter发送请求,常常要伴随传递参数。有两种请求参数: Parameters, Body Data, 它们的使用方式有很大不同。 先看下get和post请求的区别。 get请求:顾名思义是从服务器获取资源。 post请求:顾名思义是往服务器提交要处理的数据。 直观…...

Docker安装ActiveMQ镜像以及通过Java生产消费activemq示例
拉取镜像 docker pull docker.io/webcenter/activemq 启动容器 docker run -d --name myactivemq -p 61616:61616 -p 8162:8161 docker.io/webcenter/activemq:latest 这样就代表启动成功了 浏览器访问 http://localhost:8162/ admin admin 开启验证 修改配置文件/opt/ac…...

迅为RK3562开发板/核心板240PIN引脚全部引出,产品升级自如
可应用于人脸跟踪、身体跟踪、视频监控、自动语音识别(ASR)、图像分类驾驶员辅助系统(ADAS)、车牌识别、物体识别等。 iTOP-3562开发板/核心板采用瑞芯微RK3562处理器,内部集成了四核A53Mali G52架构,主频2GHZ,内置1TOPSNPU算力,R…...

C++实现顺序栈和链栈操作(实验3--作业)
顺序栈 一、主要功能 实现了顺序栈(SqStack)的数据结构,并利用该数据结构进行了栈的基本操作以及数制转换的功能。 二、数据结构定义 定义了一些常量: MAXSIZE表示栈的最大长度为 100。OVERFLOw表示存储失败的错误码为 -2。O…...
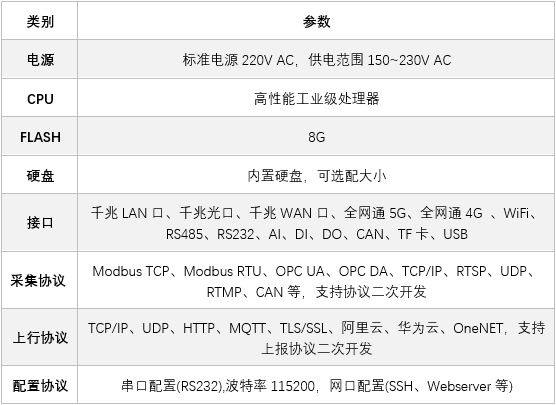
龙兴物联一体机:设备监测的智能先锋
龙兴物联物联网一体机的崛起 龙兴物联物联网一体机在设备监测领域占据着至关重要的地位。随着科技的不断进步和各行业对设备监测需求的日益增长,龙兴物联物联网一体机以其卓越的性能和广泛的适用性,迅速崛起并成为众多企业和机构的首选。 在当今数字化时…...
KinectDK相机SDK封装Dll出现k4abt_tracker_create()创建追踪器失败的问题
项目场景: KinectDK相机SDK封装Dll 问题描述 在 C 环境下,使用 GPU 模式(默认)调用 k4abt_tracker_create 函数正常工作。但是,在 Python 环境下,通过 ctypes 调用相同的 DLL,当使用 GPU 模式…...

Linux 命令—— ping、telnet、curl、wget(网络连接相关命令)
文章目录 网络连接相关命令pingtelnetcurlwget 网络连接相关命令 ping ping 命令是用于测试网络连接和诊断网络问题的工具。它通过向目标主机发送 ICMP(Internet Control Message Protocol)回显请求,并等待回复,以确定目标主机是…...

高速缓冲存储器Cache是如何工作的、主要功能、高速缓冲存储器Cache和主存有哪些区别
1、高速缓冲存储器Cache是如何工作的 高速缓冲存储器Cache的工作主要基于程序和数据访问的局部性原理,其工作方式可以概括为以下几点: 存储近期可能访问的数据和指令:Cache会存储CPU近期可能访问的数据和指令,当CPU需要访问这些…...

极简版Java敏感词检测SDK
敏感词工具 sensitive-word 基于 DFA 算法实现的高性能敏感词工具,开源在GitHub:https://github.com/houbb/sensitive-word。用于敏感词/违禁词/违法词/脏词等的识别和阻拦,是基于 DFA 算法实现的高性能 java 敏感词过滤工具框架。 使用场景…...

H3C路由器交换机操作系统介绍
路由器 路由器的作用 连接具有不同介质的链路连接网络或子网,隔离广播对数据报文执行寻路和转发交换和维护路由信息 H3C 路由器系列 CR系列核心路由器SR系列高端路由器MSR系列路由器ER系列路由器 交换机 交换机的作用 连接多个以太网物理段,隔离冲…...
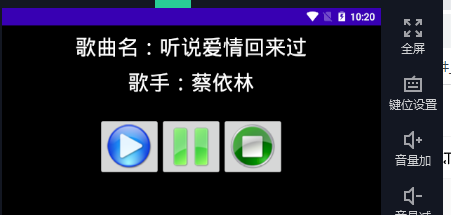
【项目案例】-音乐播放器-Android前端实现-Java后端实现
精品专题: 01.C语言从不挂科到高绩点 https://blog.csdn.net/yueyehuguang/category_12753294.html?spm1001.2014.3001.5482https://blog.csdn.net/yueyehuguang/category_12753294.html?spm1001.2014.3001.5482 02. SpringBoot详细教程 https://blog.csdn.ne…...

EasyX图形库的安装
前言 EasyX是一个图形库,可以用来做一些c/c小游戏,帮助学习。 一、进入EasyX官网 https://easyx.cn/ 二、点击下载EasyX 三、下载好后以管理员身份运行它 四、点击下一步 五、然后它会自动检测你的编辑器,用哪个就在哪个点安装 六、安装成功…...

数据结构 - 队列
队列也是一种操作受限的线性数据结构,与栈很相似。 01定义 栈的操作受限表现为只允许在队列的一端进行元素插入操作,在队列的另一端只允许删除操作。这一特性可以总结为先进先出(First In First Out,简称FIFO)。这意味…...
)
从‘班级-学生’数据实战出发:手把手教你用R语言的lme4包搞定多层线性模型(MLM/HLM)
从班级-学生数据实战:R语言lme4包多层线性模型全流程解析 当研究者面对具有层级结构的数据时(如学生嵌套于班级、员工嵌套于公司),传统线性回归的独立性假设往往被打破。多层线性模型(Multilevel Linear Models, MLM&a…...

软硬一体赋能企业守护力,可穿戴手环构建员工数字健康管理新范式
在数字化转型深入推进的当下,员工健康已成为企业安全生产、高效运营的核心基石。传统健康管理模式存在数据零散、监测滞后、人工成本高、风险预警不及时等痛点,尤其铁路、港口、政企单位、生产型企业,一线员工高强度作业、慢病高发、突发健康…...

Perplexity+知网联合检索的7类失效场景全图谱:从DOI解析失败到CSSCI标识丢失的终极修复手册
更多请点击: https://intelliparadigm.com 第一章:Perplexity知网联合检索的失效机理总论 当用户尝试将 Perplexity AI 的实时网络推理能力与知网(CNKI)学术资源库进行协同调用时,系统级耦合在协议层、语义层与权限层…...
)
实测!Gemini+ChatGPT赋能学术写作:我的论文写作SOP(附提示词)
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 为什么ChatGPT逻辑清晰却写不长?为什么Gemini能深入分析但废话连篇? …...

实用指南:3分钟在Windows中解锁iPhone HEIC照片缩略图预览
实用指南:3分钟在Windows中解锁iPhone HEIC照片缩略图预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...

为什么92.7%的临床研究者用错Perplexity药物检索?——2024年真实审计案例暴露的4个致命盲区
更多请点击: https://intelliparadigm.com 第一章:Perplexity药物信息检索的临床价值与审计背景 在精准医疗快速演进的当下,临床决策对实时、可信、上下文感知的药物信息依赖日益加深。Perplexity作为基于推理增强型大语言模型的信息检索系统…...

【NotebookLM因子分析实战指南】:3步解锁AI驱动的维度降维与业务洞察力
更多请点击: https://intelliparadigm.com 第一章:NotebookLM因子分析辅助的底层逻辑与价值定位 NotebookLM 是 Google 推出的面向研究者的 AI 助手,其核心能力并非泛化式问答,而是基于用户上传文档进行“可信引用驱动”的深度推…...

HC-02/08/42蓝牙模块选型指南:从4.0 BLE到5.0,手把手教你在Win10电脑上配对与通信
HC-02/08/42蓝牙模块选型指南:从4.0 BLE到5.0的实战解析 蓝牙技术早已从简单的音频传输工具演变为物联网设备的核心连接方式。在工业控制、智能家居和可穿戴设备等领域,选择合适的蓝牙模块往往决定了项目的成败。HC-02、HC-08和HC-42这三款经典模块各有所…...

Grok 4.3与未来展望——智能体时代的Grok与AI安全新范式
目录1 Grok 4.3 Beta:最新版本的技术跃迁1.1 2026年4月:Grok 4.3的发布1.2 Computer Use:AI操作计算机的新范式2 reasoning_effort参数的深度解析2.1 推理资源的动态分配2.2 推理深度与质量的实证关系3 Grok的AI安全框架3.1 "最大真实性…...

B站视频下载神器:如何优雅地将Bilibili内容保存到本地
B站视频下载神器:如何优雅地将Bilibili内容保存到本地 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/b…...