Flink状态一致性保证
前言
一个Flink作业由一系列算子构成,每个算子可以有多个并行实例,这些实例被称为 subTask,每个subTask运行在不同的进程或物理机上,以实现作业的并行处理。在这个复杂的分布式场景中,任何一个节点故障都有可能导致 Flink 作业宕机,Flink 状态本地化虽然可以实现极致的访问速度,但是节点故障后的状态恢复问题也是Flink必须要解决的。
状态持久化
恢复状态最简单粗暴的方式,就是回溯全量数据,重新计算一遍。不过缺点也很明显,首先,有的数据源压根就不支持保存全量数据,例如Kafka可能就只保存近几天甚至几小时的数据;其次,回溯全量数据必然会消耗大量时间,导致作业产出结果出现较大延时,这本身就和Flink高吞吐低延时的目标相悖。
于是,Flink 推出了状态持久化方案,Flink 作业运行时会自动、定时地将状态数据持久化到远程分布式文件系统中,一旦 Flink 作业异常重启,就会从远程分布式文件系统中读取最新的快照恢复状态,避免了状态数据丢失的问题。
如下示例,数据源会不断产生一些数字,Flink 作业会对这些数字求和,并输出到目标数据库。第一步,数字1输入,subTask更新本地状态sum=1,然后将其持久化到远程文件系统,此时作业异常宕机,本地状态丢失;第二步,Flink 作业重启,从远程文件系统恢复状态sum=1;第三步,subTask继续处理数据,整个过程就像没发生故障一样。

状态一致性
状态持久化只实现了基本的异常容错,用户往往还有“状态一致性”的诉求。发生故障时,Flink不仅要能从远程文件系统中恢复状态数据,还要能协调所有subTask节点在故障恢复后实现数据的精准一次处理,也就是数据即不会多算,也不会少算,以保证作业的计算结果如同没有发生过故障一样。
流计算的状态一致性有三个等级:
- at-most-once 最多计算一次,允许数据丢失,最弱的一致性保证
- at-least-once 至少计算一次,允许数据重复计算,对于自身具备幂等性写入的业务指标可以保证一致性
- exactly-once 精准计算一次,最强的一致性保证,数据不会多算也不会少算
仅仅通过状态持久化,只能保证 at-most-once 一致性,本地状态更新后还没来得及保存到远程文件系统时发生故障,数据就会丢失,导致漏算。
如下图所示,数据2处理完,本地状态更新sum=3,状态还没来得及持久化就发生故障,重启后恢复状态sum=1,数据2的计算丢失了,数据漏算。

要想避免数据漏算,可以通过故障恢复时向前回溯一部分数据来解决,例如回溯前一小时的数据甚至全部数据,这样可以保证数据至少被计算一次,也就是满足 at-least-once 一致性,但是会有数据被重复计算,对于本身具备幂等性的业务指标这没什么问题,非幂等性的业务指标计算结果仍不准确。
最理想的一致性场景就是 exactly-once,数据精准计算一次,既不多算也不少算。在咱们这个例子中,要想实现 exactly-once 一致性,除了同步sum状态,还要同步作业处理数据的偏移量offset,故障恢复时,根据恢复的offset从指定的位置重新读取数据进行处理。
如图所示,第一步处理数字1求和,更新本地状态sum=1、offset=1并持久化到远程文件系统;第二步处理数字2求和,更新本地状态sum=3、offset=2,状态还没持久化时发生故障,本地状态丢失;第三步从远程文件系统恢复状态;第四步从offset=1处开始继续处理数据2,更新本地状态并输出结果,整个流程就像没发生过故障一样。

由此可见,要满足 exactly-once 一致性,有以下几个条件:
- 数据源支持根据偏移量回溯
- subTask持久化状态的同时,也要持久化偏移量offset
- subTask持久化状态和处理数据要互斥,不能持久化状态的同时还处理数据
一个完整的Flink作业由若干个subTask构成,运行在一个复杂的分布式环境中,Flink作业状态一致性的前提是每个subTask先保证自身状态一致性。对于Source算子subTask来说,如果数据源支持根据offset回溯数据,那么执行上述流程不会有问题。但是对于下游非Source算子subTask来说,情况会显得更加复杂。
Source算子subTask读取到数据后,是通过Socket传输给下游subTask的,Socket通道的数据首先不支持回溯,其次数据压根就没有offset,这就意味着下游subTask可能会漏算数据,又回到 at-most-once 一致性了。丢失的这些数据不能让上游subTask重发,因为上游subTask根本就不知道下游subTask的处理结果是成功还是失败,如果再额外引入一套ACK机制,增加复杂度不说,额外的性能消耗也是Flink无法承受的。
既然上游不支持重发,就只能下游subTask自己解决了。下游subTask在收到上游传过来的数据时,除了计算并更新本地状态外,还要将收到的这部分数据也写进状态里面,打快照时和状态一同持久化。故障恢复时,除了恢复状态外,再把这部分数据拿出来重新计算一下,最终的状态结果就是准确的了。下游subTask也无需保存接收到的所有数据,只要数据被计算过且打过快照,这部分数据就没用了,所以下游subTask要保存的数据,只有上游subTask开始执行快照到下游subTask开始执行快照时的这部分数据,怎么让下游subTask知道上游subTask在执行快照呢?很简单,上游subTask执行快照时给下游subTask广播一条特殊的消息即可,这个消息被称为“barrier”(屏障)。
再次总结一下,要满足 exactly-once 一致性,满足以下条件:
- 数据源支持根据offset回溯
- Source算子持久化offset,并向下游算子广播barrier
- subTask持久化状态和处理数据要互斥,不能持久化状态的同时还处理数据
- 非Source算子subTask要持久化两部分数据:本地状态数据、上游subTask执行快照到自己执行快照这段时间接收到的数据
- 所有subTask快照执行成功,才算一次完整的快照
故障恢复时,Source算子从远程文件系统恢复offset,根据offset回溯数据源,并发送给下游subTask;下游subTask先从远程文件系统恢复状态,再读取之前上游发送给自己的数据,重新计算一遍这部分数据恢复自身状态,再继续处理上游发给自己的数据。
Checkpoint机制
有了上述理论,再看Flink Checkpoint机制就很容易理解了。
Flink 以 Chandy-Lamport 算法理论为基础,实现了一套分布式轻量级异步快照算法,即 Flink Checkpoint。
每个需要Checkpoint的Flink应用启动时,JobManager都会为其创建一个 CheckpointCoordinator(检查点协调器)的组件,由它来负责生成全局快照,流程如下:
- CheckpointCoordinator周期性的向所有Source算子的subTask发送barrier,开始执行快照
- Source算子收到barrier,暂停处理数据,将本地状态持久化到远程文件系统,并向CheckpointCoordinator报告自己的快照结果,同时向下游subTask广播barrier
- 下游subTask收到barrier,同样暂停数据处理。对于有多个输入的subTask来说,需要收到所有上游发来的subTask才会开始执行快照,这里就存在barrier对齐的问题。subTask同样地将本地状态持久化到远程文件系统,并向CheckpointCoordinator报告自己的快照结果,同时将barrier转发给下游subTask,直到Sink算子
- 当CheckpointCoordinator收到所有算子的快照成功报告之后,认为该周期的快照制作成功。如果没有在指定时间内收到所有算子的报告,则认定为快照制作失败。
Checkpoint 优化了subTask执行快照的时机,避免了整个快照期间,所有subTask都要暂停处理数据的问题。CheckpointCoordinator负责通知Source算子执行快照,而下游算子执行快照的时机,依赖于上游算子发送过来的barrier,这套机制执行快照无需暂停整个作业的数据处理,有效降低了流处理作业的延时问题。
相关文章:
Flink状态一致性保证
前言 一个Flink作业由一系列算子构成,每个算子可以有多个并行实例,这些实例被称为 subTask,每个subTask运行在不同的进程或物理机上,以实现作业的并行处理。在这个复杂的分布式场景中,任何一个节点故障都有可能导致 F…...

前端一键复制解决方案分享
需求背景 用户需要对流水号进行复制使用,前端的展示是通过样式控制,超出省略号表示,鼠标悬浮展示完整流水号。此处的鼠标悬浮展示采用的是:title,这样就无法对文本进行选中。 下面是给出一键复制的不同的解决方案,希望…...

麒麟操作系统swap使用率过高的排查思路
现象:用户业务环境服务器在运行时,监控平台告警swap使用99%,在系统内查询物理内存使用39%左右,swap使用达99%。 问题排查: 1)使用命令查询使用了swap空间的进程并排序:for i in cd /proc;ls |gr…...

爬虫python=豆瓣Top250电影
主流程:获取数据,解析数据,保存数据 from bs4 import BeautifulSoup #网页解析获取数据 import re #正则表达式 import urllib.request,urllib.error #获取网页数据 import sqlite3 #轻量级数据库 import xlwt #进行excel操作 #影视详情…...

【Eclipse系列】解决Eclipse中xxx.properties文件中文乱码问题
问题描述:由于eclipse对Properties资源文件的编码的默认设置是ISO-8859-1,所以在打开.properties文件时,会发现中文乱码了,如图: 解决方法: 1、一次生效法 右击该properties文件–>properties–>Re…...

mysql主从复制及故障修复
一、主MySQL数据库的配置 分别在三台主机(chen2/10.110、chen3/10.120、chen4/10.130)中安装mysql数据,其中chen2/10.110作为主MySQL服务器,其余两台作为从MySQL服务器。 1、在主机上部署mysql数据库 详细的请看上一篇:mysql数据…...

基于springboot的网上服装购物商城系统
基于springboot的网上服装购物商城系统 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:idea 源码获取: &#x…...

aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理
aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理 学习内容: AWS的虚拟私有,共有子网以及ACL定义公网碉堡主机子网,私有子网和共有子网以及varnish反向代理 1. AWS的虚拟…...

接口测试(三)jmeter——连接mysql数据库
一、jmeter安装jdbc 1. 下载插件包,mysql数据库为例,驱动 com.mysql.jdbc.Driver 需要下载 mysql-connector-java-5.1.7-bin.jar 插件包,将插件包放到 jmeter 安装目录下的 lib 目录 2. 给jmeter安装jdbc驱动 二、jmeter操作数据库 1.…...

双十一购物节有哪些好物值得入手?2024双十一好物清单合集分享
一年一度的双十一购物狂欢节即将来临,各大平台纷纷开启预热活动,伴随着品牌的疯狂折扣和满减优惠,众多商品即将迎来超值的价格。现在正是大家“剁手”换新装备的大好时机。作为一名深耕智能产品多年的资深达人,今天这期我将从不同…...

jmeter中请求参数:Parameters、Body Data的区别
使用jmeter发送请求,常常要伴随传递参数。有两种请求参数: Parameters, Body Data, 它们的使用方式有很大不同。 先看下get和post请求的区别。 get请求:顾名思义是从服务器获取资源。 post请求:顾名思义是往服务器提交要处理的数据。 直观…...

Docker安装ActiveMQ镜像以及通过Java生产消费activemq示例
拉取镜像 docker pull docker.io/webcenter/activemq 启动容器 docker run -d --name myactivemq -p 61616:61616 -p 8162:8161 docker.io/webcenter/activemq:latest 这样就代表启动成功了 浏览器访问 http://localhost:8162/ admin admin 开启验证 修改配置文件/opt/ac…...

迅为RK3562开发板/核心板240PIN引脚全部引出,产品升级自如
可应用于人脸跟踪、身体跟踪、视频监控、自动语音识别(ASR)、图像分类驾驶员辅助系统(ADAS)、车牌识别、物体识别等。 iTOP-3562开发板/核心板采用瑞芯微RK3562处理器,内部集成了四核A53Mali G52架构,主频2GHZ,内置1TOPSNPU算力,R…...

C++实现顺序栈和链栈操作(实验3--作业)
顺序栈 一、主要功能 实现了顺序栈(SqStack)的数据结构,并利用该数据结构进行了栈的基本操作以及数制转换的功能。 二、数据结构定义 定义了一些常量: MAXSIZE表示栈的最大长度为 100。OVERFLOw表示存储失败的错误码为 -2。O…...
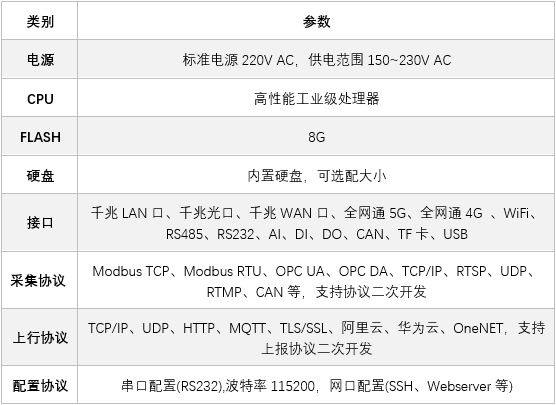
龙兴物联一体机:设备监测的智能先锋
龙兴物联物联网一体机的崛起 龙兴物联物联网一体机在设备监测领域占据着至关重要的地位。随着科技的不断进步和各行业对设备监测需求的日益增长,龙兴物联物联网一体机以其卓越的性能和广泛的适用性,迅速崛起并成为众多企业和机构的首选。 在当今数字化时…...
KinectDK相机SDK封装Dll出现k4abt_tracker_create()创建追踪器失败的问题
项目场景: KinectDK相机SDK封装Dll 问题描述 在 C 环境下,使用 GPU 模式(默认)调用 k4abt_tracker_create 函数正常工作。但是,在 Python 环境下,通过 ctypes 调用相同的 DLL,当使用 GPU 模式…...

Linux 命令—— ping、telnet、curl、wget(网络连接相关命令)
文章目录 网络连接相关命令pingtelnetcurlwget 网络连接相关命令 ping ping 命令是用于测试网络连接和诊断网络问题的工具。它通过向目标主机发送 ICMP(Internet Control Message Protocol)回显请求,并等待回复,以确定目标主机是…...

高速缓冲存储器Cache是如何工作的、主要功能、高速缓冲存储器Cache和主存有哪些区别
1、高速缓冲存储器Cache是如何工作的 高速缓冲存储器Cache的工作主要基于程序和数据访问的局部性原理,其工作方式可以概括为以下几点: 存储近期可能访问的数据和指令:Cache会存储CPU近期可能访问的数据和指令,当CPU需要访问这些…...

极简版Java敏感词检测SDK
敏感词工具 sensitive-word 基于 DFA 算法实现的高性能敏感词工具,开源在GitHub:https://github.com/houbb/sensitive-word。用于敏感词/违禁词/违法词/脏词等的识别和阻拦,是基于 DFA 算法实现的高性能 java 敏感词过滤工具框架。 使用场景…...

H3C路由器交换机操作系统介绍
路由器 路由器的作用 连接具有不同介质的链路连接网络或子网,隔离广播对数据报文执行寻路和转发交换和维护路由信息 H3C 路由器系列 CR系列核心路由器SR系列高端路由器MSR系列路由器ER系列路由器 交换机 交换机的作用 连接多个以太网物理段,隔离冲…...

避坑指南:RK3566给GC2053提供MCLK,分压电阻怎么选?实测波形告诉你答案
RK3566与GC2053时钟信号分压设计实战:从波形分析到电阻选型 当RK3566处理器需要为GC2053图像传感器提供MCLK时钟信号时,电平转换电路的设计往往成为项目成败的关键。许多工程师在首次设计分压电路时,会陷入"阻值越大功耗越小"的误区…...

从Ring Bus到Mesh:聊聊Intel CPU内部那些‘堵车’与‘修路’的往事
从Ring Bus到Mesh:Intel CPU内部通信架构的演进与工程智慧 1. 当CPU内部变成"早高峰的北京三环" 2006年,Intel工程师们围在白板前,盯着密密麻麻的电路图皱起了眉头。他们刚刚完成测试的八核处理器原型机显示:当所有核心…...

成都不良资产收包出包难?专业处置破局存量盘活困境
不仅如此,规范化的不良资产处置模式,还能助力区域化解债务风险,稳定地方金融环境,激活存量资产活力,对地方经济发展起到正向推动作用。不良资产收包出包,拼的从来不是蛮力与时间,而是专业、合规…...

用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现
用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现 数字电路设计中最精妙的概念之一,莫过于补码表示法。它不仅解决了计算机中正负数的统一表示问题,还让加减法运算可以用同一套电路完成。但你是否好奇过,这个看似简单…...

视听融合新范式!黎阳之光打破视觉边界,声影协同赋能全域智慧管控
长久以来,图形图像可视化技术早已成为智慧安防、低空管控、工业监测领域的主流应用,依托高清视频、三维实景、数字孪生图形图像能力,实现场景直观呈现、目标可视追踪、环境全景复刻,为各行各业搭建起可视化智慧管理体系。深耕图形…...

NoSleep:彻底告别电脑自动休眠的终极解决方案
NoSleep:彻底告别电脑自动休眠的终极解决方案 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否经历过这些令人沮丧的时刻?在线会议进行到关键演示…...

瑞萨电子2019年中国市场战略与MCU/SoC产品深度解析
1. 项目概述:一次对特定年份半导体巨头市场策略的深度复盘在半导体这个日新月异的行业里,每年各大厂商的产品发布和市场策略,都像是一张张精心绘制的航海图,指引着下游应用市场的技术风向。今天,我想和大家深入聊聊一个…...

B站账号管理终极指南:如何用BiliBiliToolPro实现全自动任务管理
B站账号管理终极指南:如何用BiliBiliToolPro实现全自动任务管理 【免费下载链接】BiliBiliToolPro B 站(bilibili)自动任务工具,支持docker、青龙、k8s等多种部署方式。全面拥抱AI。敏感肌也能用。 项目地址: https://gitcode.c…...

良品铺子卖菜:OEM模式的极限与宿命
一家卖零食的公司开始卖菜,听起来像是一个关于“内卷”的黑色幽默。2026年5月,良品铺子在武汉开出首家“良品铺子鲜生活”超市。这家门店不再陈列整齐的包装零食,而是摆上了新鲜蔬菜、现制熟食、现烤面包和冷藏冷冻品。公司将其定位为“社区厨…...

终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案
终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。 项目…...