python爬虫快速入门之---Scrapy 从入门到包吃包住
python爬虫快速入门之—Scrapy 从入门到包吃包住
文章目录
- python爬虫快速入门之---Scrapy 从入门到包吃包住
- 一、scrapy简介
- 1.1、scrapy是什么?
- 1.2、Scrapy 的特点
- 1.3、Scrapy 的主要组件
- 1.4、Scrapy 工作流程
- 1.5、scrapy的安装
- 二、scrapy项目快速入门
- 2.1、scrapy项目快速创建以及运行
- 2.1.1、创建爬虫项目
- 2.1.2、创建爬虫文件
- 2.1.3、运行爬虫代码
- 2.1.4、修改遵守robots协议
- 2.2、scrapy项目
- 2.2.1、文件结构
- 2.2.2、parse方法中的response属性和方法
- 2.2.3、scrapy的工作原理
- 2.3、yield关键字
- 三、scrapy shell
- 3.1、scrapy shell简介
- 3.2、进入scrapy shell
- 3.3、scrapy shell的基本使用
- 四、scrapy项目实战--抓取商品数据并保存
- 4.1、创建项目
- 4.2、定义item数据结构
- 4.3、编写爬虫文件
- 4.4、编写pipeline管道
- 4.5、单管道运行查看
- 4.6、多管道的编写
- 4.6.1、定义广告类
- 4.6.2、在setting中开启管道
- 4.6.3、启动测试
- 4.7、下载多页数据
- 五、scrapy项目实战--网页嵌套处理
- 六、CrawlSpider
- 6.1、简介
- 6.2、链接提取器
- 七、CrawlSpider案例实战
- 7.1、项目初始化
- 7.2、改造项目
- 7.3、运行并查看结果
- 八、联动mysql数据库持久化到本地
- 8.1、安装pymysql
- 8.2、创建mysql数据库
- 8.3、编写配置
- 8.4、编写数据库持久化管道类
- 8.5、开启管道
- 8.6、测试并观察数据库中保存的结果
- 九、日志与日志文件
- 十、scrapy的post请求
- 十一、scrapy的代理
- 11.1、 **在 `settings.py` 中配置代理**
- 11.2、 **自定义代理中间件**
- 11.3、 **为特定请求设置代理**
- 11.4、 **使用第三方代理服务**
一、scrapy简介
1.1、scrapy是什么?

官方文档:https://scrapy.org/
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 是一个开源的 Python 爬虫框架,用于从网站上提取数据(即进行网络爬虫),并能将这些数据进行处理和存储。
它的设计目标是简单高效地抓取大量网页,并提供强大的工具来进行数据的提取和分析。
1.2、Scrapy 的特点
- 快速开发:Scrapy 提供了许多内置功能,帮助开发者快速构建高效的爬虫程序。
- 可扩展性强:它允许用户自定义中间件、管道等,满足各种爬虫需求。
- 异步处理:Scrapy 使用 Twisted 异步网络库,可以同时处理大量请求,从而加快爬虫的效率。
- 数据处理方便:支持将数据保存为多种格式,例如 JSON、CSV、XML 等。
1.3、Scrapy 的主要组件
- Spider(爬虫):这是用户定义的类,用于指定如何从某个或多个网站抓取数据以及如何解析和处理这些数据。
- Selectors(选择器):Scrapy 提供了强大的选择器工具(如 XPath、CSS 选择器),用于从 HTML 页面中提取数据。
- Item(数据容器):类似于一个数据结构,用来定义要从网页中抓取和存储的数据。
- Pipeline(数据管道):用于对抓取到的数据进行后续处理,如清洗、验证、存储等。
- Middleware(中间件):在请求和响应的处理中,可以通过中间件对其进行拦截和处理,比如修改 headers、处理 cookies 等。
1.4、Scrapy 工作流程
- 发送请求:Spider 定义了要抓取的网站地址。Scrapy 通过异步方式发送请求。
- 接收响应:收到响应后,通过 Spider 定义的回调方法处理响应数据。
- 数据提取:利用 Scrapy 提供的选择器工具提取目标数据。
- 保存数据:提取到的数据会通过管道处理,进行清洗、存储或输出
1.5、scrapy的安装
懒得记笔记,直接上连接:https://blog.csdn.net/qq_45476428/article/details/108739943
- 如果报错twisted:
http://www.1fd.uci.edu/~gohlke/pythonlibs/#twisted - 也可以使用anaconda安装环境:
https://docs.anaconda.com/anaconda/install/windows
二、scrapy项目快速入门
2.1、scrapy项目快速创建以及运行
2.1.1、创建爬虫项目
切换到一个你想存放项目的文件夹,并进入命令行,使用命令来创建一个scrapy项目。
命令如下:
scrapy startproject scrapy_study_01
其中scrapy_study_01是项目的名字,项目的名字不允许使用数字开头,也不能包含中文。
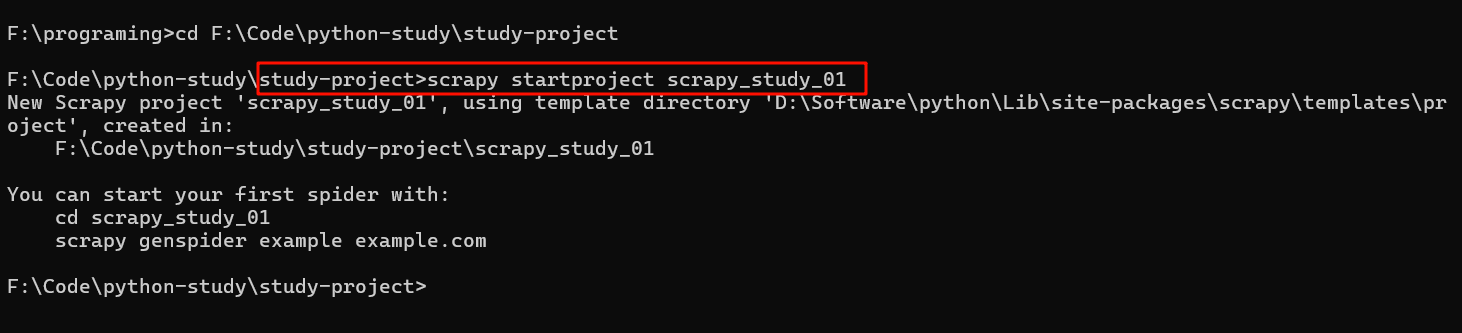
从而可以在目录下看到这个项目:

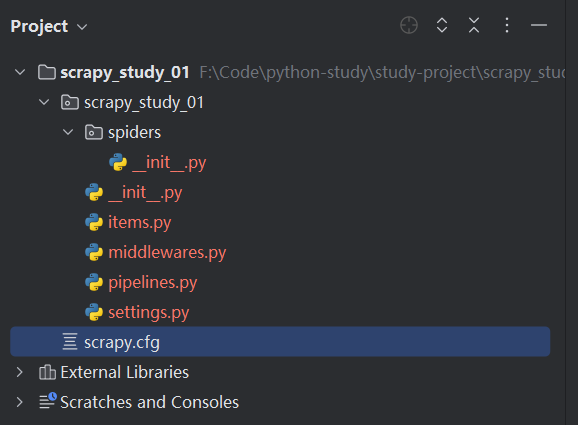
然后使用我们的ide来打开这个项目:
2.1.2、创建爬虫文件
要在spiders文件夹中去创建爬虫文件
命令:cd 项目的名字\项目的名字\spiders
cd scrapy_study_01\scrapy_study_01\spiders
创建爬虫文件:scrapy genspider 爬虫文件的名字 要爬取网页
scrapy genspider baidu http://www.baidu.com
一般情况下不需要添加http协议

可以看到新创建的文件:
import scrapyclass BaiduSpider(scrapy.Spider):# 爬虫名称name = "baidu"# 允许的域名allowed_domains = ["www.baidu.com"]# 起始url 在allowed_domains的前面添加了http://start_urls = ["http://www.baidu.com"]# 是执行了start_urls之后 执行的方法 方法中的response就是返回的那个对象# 相当于response = urllib.request.urlopen()# 和 response = requests.get()def parse(self, response):print("我是一个百度的爬虫程序")2.1.3、运行爬虫代码
语法:scrapy crawl 爬虫的名字
scrapy crawl baidu

当我运行爬虫的代码的时候,并没有执行我的
print("我是一个百度的爬虫程序")语句,这可以网站就做了一些反扒的手段。怎么处理:
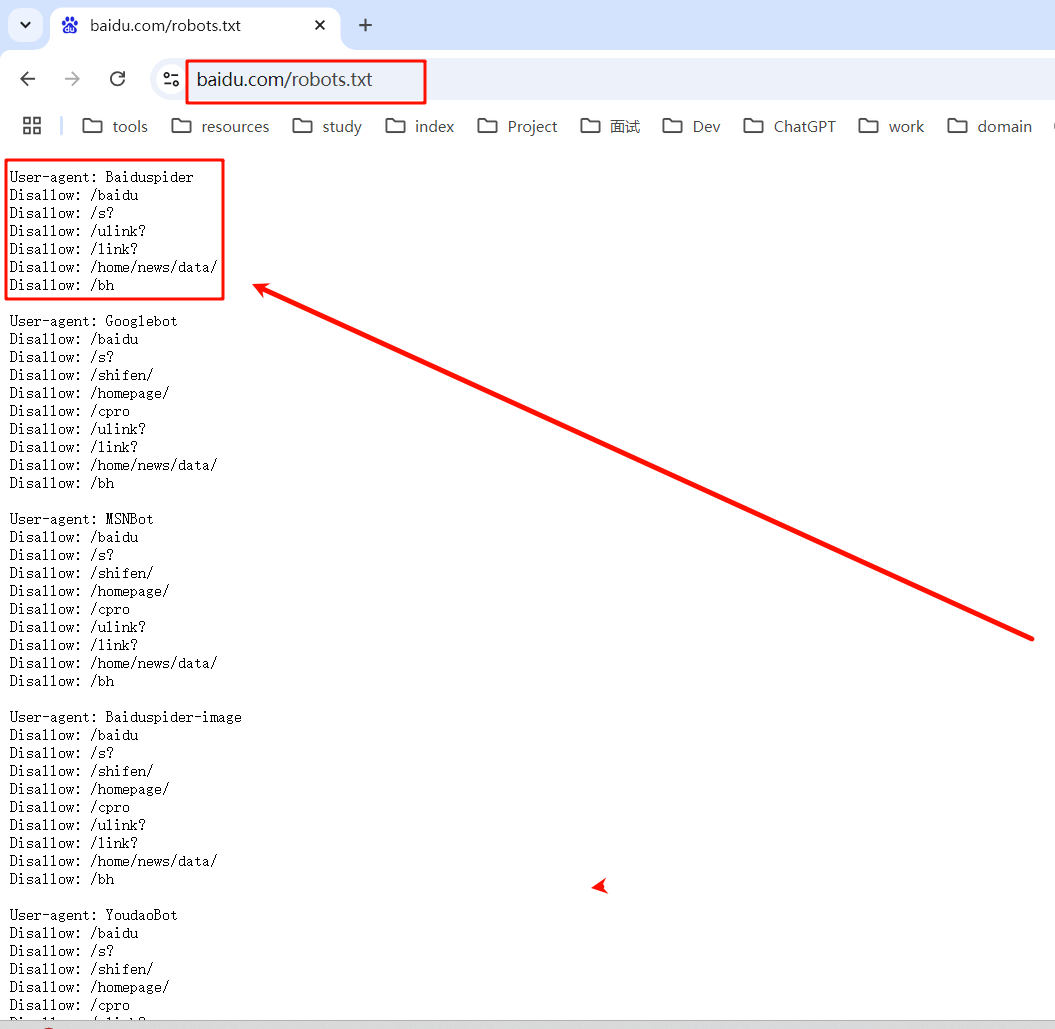
百度的robots.txt协议:
根据下图可以看到百度是不允许爬虫的
2.1.4、修改遵守robots协议
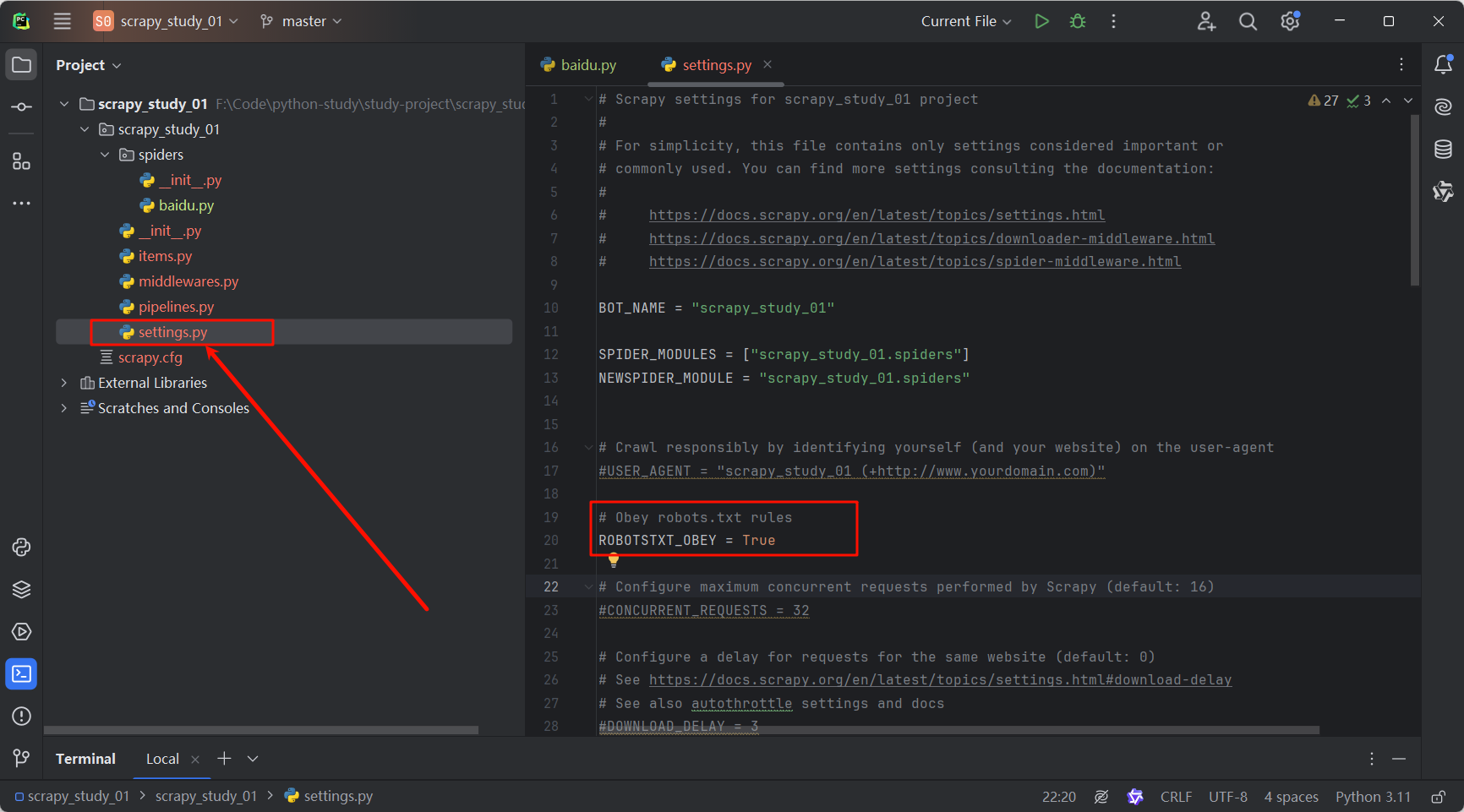
打开项目下的settings.py文件,把这句ROBOTSTXT_OBEY = True代码注释即可,意为不遵守robots协议。
然后再次运行代码:
scrapy crawl baidu
发现我们的语句执行了:

2.2、scrapy项目
2.2.1、文件结构

2.2.2、parse方法中的response属性和方法
| 属性和方法 | 意义 |
|---|---|
| response.text | 获取的是响应的字符串 |
| response.body | 获取的是二进制数据 |
| response.xpath | 可以直接是xpath方法来解析response中的内容 |
| response.extract() | 提取seletor对象的data属性值 |
| response.extract_first() | 取的seletor列表的第-个数据 |
可以使用下面这个58同城的案例来测试:
-
创建项目
scrapy startproject scrapy_study_02 -
创建爬虫文件
cd scrapy_study_02\scrapy_study_02\spidersscrapy genspider tc "https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=uuid_c84b556016c34f2392cf3772a0ff84d3%2Cclassify_B&search_uuid=c84b556016c34f2392cf3772a0ff84d3"上述网址来源于:58同城
-
修改遵守robots协议

修改tc.py文件来查看response参数里面的内容:
import scrapyclass TcSpider(scrapy.Spider):name = "tc"allowed_domains = ["bj.58.com"]start_urls = ["https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=uuid_c84b556016c34f2392cf3772a0ff84d3%2Cclassify_B&search_uuid=c84b556016c34f2392cf3772a0ff84d3"]def parse(self, response):html= response.textprint("*******************************")print(html)运行python文件:
scrapy crawl tc
查看控制台的打印结果,发现就是我们需要的网页:

所以现在总结一下response的属性和方法:
| 属性和方法 | 意义 |
|---|---|
| response.text | 获取的是响应的字符串 |
| response.body | 获取的是二进制数据 |
| response.xpath | 可以直接是xpath方法来解析response中的内容 |
| response.extract() | 提取seletor对象的data属性值 |
| response.extract_first() | 取的seletor列表的第-个数据 |
2.2.3、scrapy的工作原理

引擎(Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
爬虫(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
项目管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
爬虫中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
简言之可以总结为下面几点:
- 引擎向spiders要url
- 引擎将要爬取的ur给调度器
- 调度器会将ur生成请求象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给到spiders
- spiders通过xpath解析该数据,得到数据或者url
- spiders将数据或者url给到引擎
- 引擎判断该数据还是url,是数据,交给管道(item pipeline)处理,是url交给调度器处理
2.3、yield关键字
- 带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
- yield是一个类似return的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
- 简要理解:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
三、scrapy shell
3.1、scrapy shell简介
Scrapy shell是一个交互式shell(终端),您可以在其中快速调试您的抓取代码,而无需运行spider。它旨在用于测试数据提取代码,但您实际上可以将其用于测试任何类型的代码,因为它也是一个常规的Python shell。
shell用于测试XPath或CSS表达式,看看它们是如何工作的,以及它们从您试图抓取的网页中提取了什么数据。它允许您在编写spider时交互式地测试表达式,而无需运行spider来测试每一个更改。
一旦你熟悉了Scrapy shell,你就会发现它是开发和调试spider的宝贵工具。
scrapy shell官方文档
3.2、进入scrapy shell
进入到scrapy shell的终端直接在window的终端中输入scrapy shell 域名
即:
scrapy shell www.baidu.com
如果想看到一些高亮或者自动补全那么可以安装ipython,使用命令安装:
pip install ipython
3.3、scrapy shell的基本使用
可用的方法
shelp(): 打印可用的对象和方法fetch(url[, redirect=True]): 爬取新的 URL 并更新所有相关对象fetch(request): 通过给定request 爬取,并更新所有相关对象view(response): 使用本地浏览器打开给定的响应。这会在计算机中创建一个临时文件,这个文件并不会自动删除
可用的Scrapy对象
Scrapy shell自动从下载的页面创建一些对象,如 Response 对象和 Selector 对象。这些对象分别是
crawler: 当前Crawler 对象spider: 爬取使用的 Spider,如果没有则为Spider对象request: 最后一个获取页面的Request对象,可以使用 replace() 修改请求或者用 fetch() 提取新请求response: 最后一个获取页面的Response对象settings: 当前的Scrapy设置
例如使用response:
-
response.body
-
response.text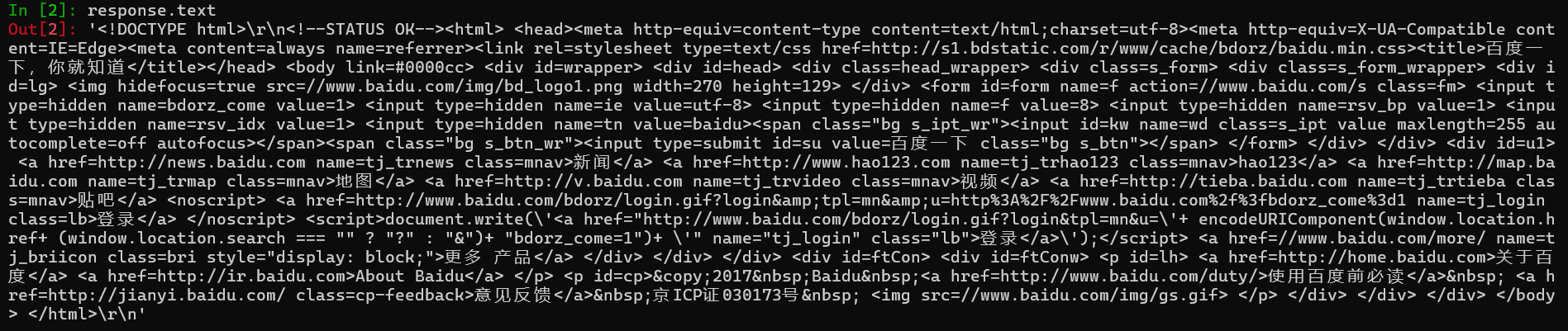
-
response.url
-
response.status
-
response.xpath('//input[@id="su"]/@value')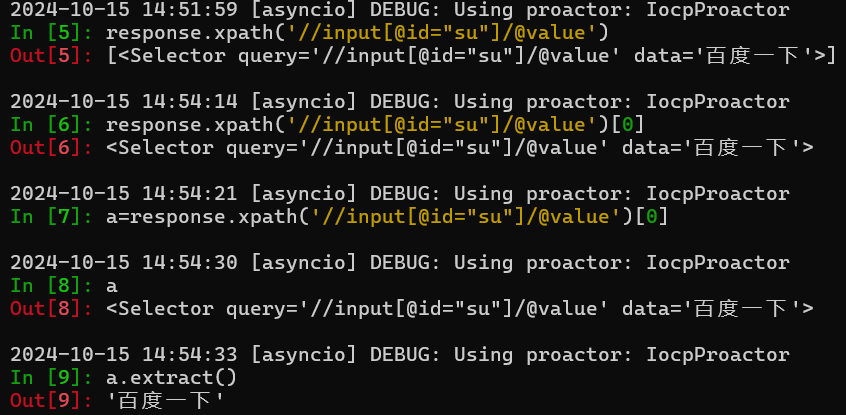
四、scrapy项目实战–抓取商品数据并保存
案例背景: 获取一个购物网页的一些数据,例如标题、图片、价格等。
4.1、创建项目
根据本篇博客的2.1部分内容来进行创建,其中创建爬虫文件关键的语句为:
scrapy genspider dang https://category.dangdang.com/cp01.01.01.00.00.00.html
4.2、定义item数据结构
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyStudy04DangdangItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 价格price = scrapy.Field()# 标题title = scrapy.Field()# 图片img_url = scrapy.Field()
4.3、编写爬虫文件
import scrapy
from scrapy_study_04_dangdang.items import ScrapyStudy04DangdangItemclass DangSpider(scrapy.Spider):name = "dang"allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.01.01.00.00.00.html"]def parse(self, response):# pipelines 存储数据# item 定义数据li_list = response.xpath("//ul[@id='component_59']/li")for li in li_list:title = li.xpath(".//a[1]/@title").extract_first()price = li.xpath(".//p[3]/span[1]/text()").extract_first()img = li.xpath(".//img/@data-original").extract_first()if img:img = imgelse:img = li.xpath(".//img/@src").extract_first() # 防止出现没有data-original数据的情况book = ScrapyStudy04DangdangItem(img_url=img, title=title, price=price)# 获取一个book就将book交给pipelinesyield book
其中通过yield关键字将我们需要的book数据对象传输到pipelines中,方便我们进行数据处理。
而关键语句book = ScrapyStudy04DangdangItem(img_url=img, title=title, price=price)可以看出我们的语句是来自items.py文件。
4.4、编写pipeline管道
在使用这个文件之前,需要先在setting.py中开启这个功能:

即:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"scrapy_study_04_dangdang.pipelines.ScrapyStudy04DangdangPipeline": 300,
}
- 其中管道可以有很多个;
- 管道是有优先级的,优先级的范围是1-1000 ;
- 取值越小的优先级越高。
现在我们就可以将我们的数据进行处理(保存成json文件):
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 如果需要使用pipeline,需要现在setting中开启
class ScrapyStudy04DangdangPipeline:# item: yield 后面的book对象def process_item(self, item, spider):with open("book.json", "a", encoding="utf-8") as f:f.write(str(item))return item实际操作的时候要注意以下几个问题:
(1)write里面必须传入字符串,所以需要先转成字符串
(2)写入文件的w模式,每次写入都会覆盖之前的数据,所以把w改成a(追加)
缺点:每次写入都会打开文件,然后关闭文件,效率不高
优化版pipelines:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 如果需要使用pipeline,需要现在setting中开启
class ScrapyStudy04DangdangPipeline:# 爬虫文件执行之前def open_spider(self, spider):self.fp = open("book.json", "w", encoding="utf-8")# item: yield 后面的book对象def process_item(self, item, spider):# 优化版self.fp.write(str(item))# 爬虫文件执行之后def close_spider(self, spider):self.fp.close()
经过上述这种写法的优化之后,就改变了频繁的打开和关闭文件的操作,其中两个方法分别对应的是爬虫文件执行之前和之后执行。
4.5、单管道运行查看
根据上述代码的方式来编写项目,起始就是一个单管道的一种模式。
运行结果:
4.6、多管道的编写
在上述代码的基础上,再添加一些代码即可实现多管道的编写
4.6.1、定义广告类
在pipelines.py文件上新建一个ScrapyDangdangDownloadPipeline类,用来下载图片资源:
class ScrapyDangdangDownloadPipeline:# 这个方法源自上面这个类的process_item方法def process_item(self, item, spider):url = item.get("img_url")filename = './books/' + item.get("title") + ".jpg"urllib.request.urlretrieve(url, filename)return item
4.6.2、在setting中开启管道
打开settings.py文件,找到ITEM_PIPELINES这个参数,并在里面添加ScrapyDangdangDownloadPipeline参数如下:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {# 管道可以有很多个,管道是有优先级的,优先级的范围是1-1000 值越小的优先级越高"scrapy_study_04_dangdang.pipelines.ScrapyStudy04DangdangPipeline": 300,# ScrapyDangdangDownloadPipeline"scrapy_study_04_dangdang.pipelines.ScrapyDangdangDownloadPipeline": 301,
}
4.6.3、启动测试
输入命令启动多管道项目:
scrapy crawl dang
就会发现新产生的json文件和图片资源文件:
需要注意的是,books文件夹需要手动添加。
4.7、下载多页数据
多页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法
但是首先需要观察每页变化的逻辑:
https://category.dangdang.com/pg1-cp01.01.07.00.00.00.html
https://category.dangdang.com/pg2-cp01.01.07.00.00.00.html
https://category.dangdang.com/pg6-cp01.01.07.00.00.00.html
https://category.dangdang.com/pg100-cp01.01.07.00.00.00.html
改造原来的dang.py文件里面的parse函数
import scrapy
from scrapy_study_04_dangdang.items import ScrapyStudy04DangdangItemclass DangSpider(scrapy.Spider):name = "dang"# 这里只写域名,在旧版本上面会自动添加原始请求,但是在请求多个页面,不同接口的时候这里只能写域名allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.01.01.00.00.00.html"]base_url = "https://category.dangdang.com/pg"page = 1def parse(self, response):# pipelines 存储数据# item 定义数据li_list = response.xpath("//ul[@id='component_59']/li")sfor li in li_list:title = li.xpath(".//a[1]/@title").extract_first()# detail = li.xpath(".//p[1]/a/text()").extract_first()price = li.xpath(".//p[3]/span[1]/text()").extract_first()img = li.xpath(".//img/@data-original").extract_first()if img:img = imgelse:img = li.xpath(".//img/@src").extract_first() # 防止出现没有data-original数据的情况book = ScrapyStudy04DangdangItem(img_url="https:" + img, title=title, price=price)# 获取一个book就将book交给pipelinesyield bookif self.page <= 100:url = self.base_url + str(self.page) + "-cp01.01.07.00.00.00.html"self.page += 1# 调用parse函数get请求# scrapy.Request就是scrapy的# url 就是请求地址# callback 回调函数(即需要调用的函数,后面不用加())yield scrapy.Request(url=url, callback=self.parse)
具体细节在上述代码的注释上面存在,请仔细阅读。
最后启动测试即可:
scrapy crawl dang


五、scrapy项目实战–网页嵌套处理
根据本篇博客的2.1部分内容来进行创建,其中创建爬虫文件关键的语句为:
scrapy genspider mv https://btwuji.com/html/gndy/index.html
起始其他逻辑都与本博客第四模块差不多,主要就是网页嵌套的请求发起,当我们点击另一个链接的时候又需要对其发起请求,大致逻辑如下:
import scrapy
from scrapy_study_05_movie.items import ScrapyStudy05MovieItemclass MvSpider(scrapy.Spider):name = "mv"allowed_domains = ["btwuji.com"]start_urls = ["https://btwuji.com/html/gndy/index.html"]def parse(self, response):list = "//div[@class='co_content8']//td[1]/a[2]"for i in response.xpath(list):# 获取第二页urlurl = "https://btwuji.com/" + i.xpath("./@href").extract_first()# 获取电影名称name = i.xpath("./text()").extract_first()# 对第二页url进行请求yield scrapy.Request(url=url, callback=self.parse_second, meta={"name": name})def parse_second(self, response):img_src = response.xpath("//div[@id='Zoom']//img/@src").extract_first() # 需要注意的是span不能识别到# print(img_src)name = response.meta["name"]movie = ScrapyStudy05MovieItem(name=name, src=img_src)yield movie # 将数据返回给管道
其中主要的重点就是:
对第二页url进行请求:
yield scrapy.Request(url=url, callback=self.parse_second, meta={"name": name})
六、CrawlSpider
6.1、简介
CrawlSpider 是 Scrapy 框架中的一个常用类,专门用于编写爬取网站的规则导向型爬虫。
它继承自 Scrapy 的 Spider 类,并提供了更灵活的机制来处理复杂的网站导航结构。
相对于基础的 Spider,CrawlSpider 允许你定义一系列规则(rules),通过这些规则,爬虫可以自动跟踪链接并处理页面。
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用crawlspider是非常合适的
6.2、链接提取器
在链接提取器里面可以写规则来提取我们想要的链接列表。
使用之前需要先导入
from scrapy.linkextractors import LinkExtractor
语法:
| 操作 | 含义 |
|---|---|
| allow =() | 正则表达式提取符合正则的链接 |
| deny =() | 正则表达式不提取符合正则的链接(不常用) |
| allow_domains =() | 允许的域名(不常用) |
| deny_domains =() | 不允许的域名(不常用) |
| restrict_xpaths =() | xpath,提取符合xpath规则的链接 |
| restrict_css =() | 提取符合选择器规则的链接(不推荐) |
示例:
from scrapy.linkextractors import LinkExtractorlink = LinkExtractor(allow=r'/book/1188_\d+\.html')
link.extract_links(response)
r'/book/1188_\d+\.html',其中,r是忽略转义的字符。
输出所有符合正则表达式的链接:

七、CrawlSpider案例实战
需求:某读书网站数据入库
7.1、项目初始化
-
新建项目
scrapy startproject scrapy_study_06_dushu -
创建爬虫类
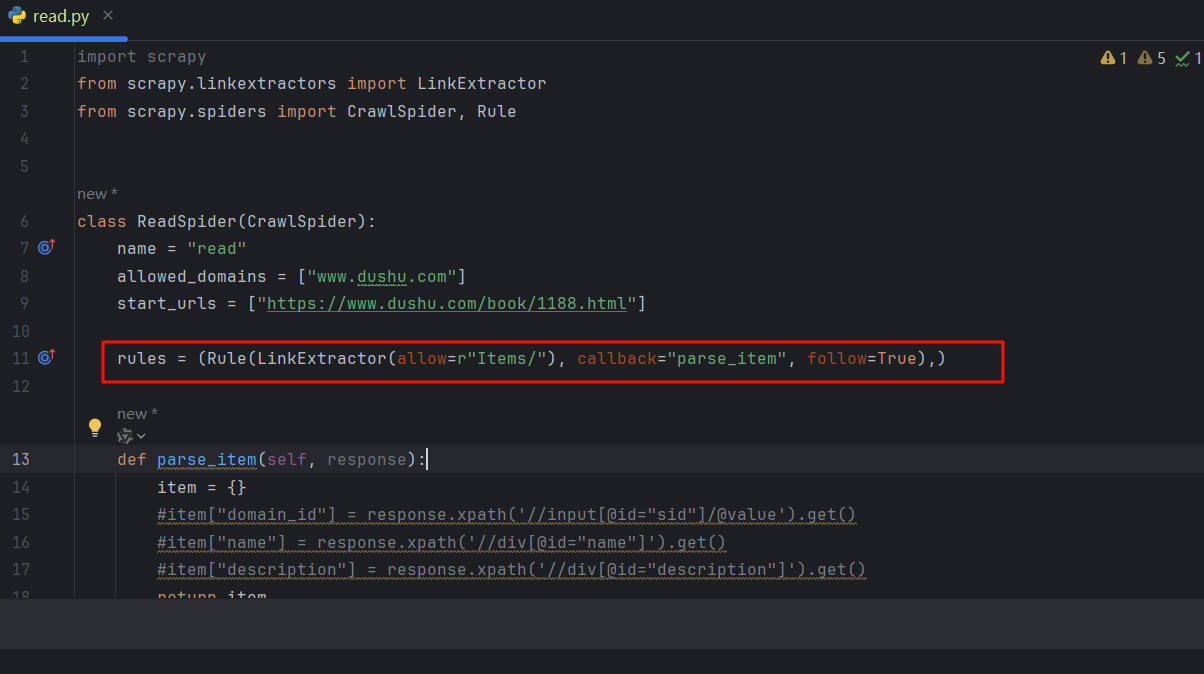
cd .\scrapy_study_06_dushu\scrapy_study_06_dushu\spiders\ scrapy genspider -t crawl read https://www.dushu.com/book/1188.html- 其中
-t参数的意义就是会给我们多新增加一些内容,利于我们使用CrawlSpider。 - 还有follow参数:follow=true 是否跟进就是按照提取连接规则进行提取(如果是True将会一直爬取数据直至最后一页。)
- 其中
7.2、改造项目
-
爬虫文件:
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_study_06_dushu.items import ScrapyStudy06DushuItemclass ReadSpider(CrawlSpider):name = "read"allowed_domains = ["www.dushu.com"]# 原网页是1188但是不符合我们下面的正则规则,所以原网页会丢失,现在改成1188_1start_urls = ["https://www.dushu.com/book/1188_1.html"]rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"),callback="parse_item",follow=False),)def parse_item(self, response):img_list = response.xpath("//div[@class='bookslist']//img")for img in img_list:name = img.xpath("./@alt").extract_first()src = img.xpath("./@data-original").extract_first()book = ScrapyStudy06DushuItem(name=name, src=src)yield book -
items文件
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyStudy06DushuItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field()src = scrapy.Field() -
pipelines文件
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface from itemadapter import ItemAdapterclass ScrapyStudy06DushuPipeline:def open_spider(self, spider):self.fp = open("dushu.json", "w", encoding="utf-8")def process_item(self, item, spider):self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close() -
在setting.py中打开设置

7.3、运行并查看结果
八、联动mysql数据库持久化到本地
案例就是第七章的内容继续改造。
8.1、安装pymysql
使用命令在python的安装目录下
pip install pmysql
8.2、创建mysql数据库
sql语句:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for spider01
-- ----------------------------
DROP TABLE IF EXISTS `spider01`;
CREATE TABLE `spider01` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,`src` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 521 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;SET FOREIGN_KEY_CHECKS = 1;

不懂MySQL的安装和使用的朋友先去简单入门一下mysql,我这里就直接放上数据库的字段和sql语句。
推荐快速入门的教程:mysql的安装
8.3、编写配置
在settings.py文件中的任意位置编写配置的参数信息:
# 数据库连接参数
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'toor'
DB_NAME = 'spider1'
DB_CHARSET = 'utf8'
注意:必须要是与自己数据库参数对应才行。
8.4、编写数据库持久化管道类
# 加载settings数据
from scrapy.utils.project import get_project_settings
import pymysqlclass MysqlPipeline:def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.db = settings['DB_NAME']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.charset = settings['DB_CHARSET']self.conn = pymysql.connect(host=self.host,port=self.port,db=self.db,user=self.user,password=self.password,charset=self.charset)self.cursor = self.conn.cursor()def process_item(self, item, spider):# 编写插入数据的sql语句sql = 'insert into spider01(name,src) values("{}","{}")'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交数据self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
8.5、开启管道
将数据库持久化的管道类在setting.py配置文件中进行配置
ITEM_PIPELINES = {"scrapy_study_06_dushu.pipelines.ScrapyStudy06DushuPipeline": 300,"scrapy_study_06_dushu.pipelines.MysqlPipeline": 301,
}
8.6、测试并观察数据库中保存的结果

九、日志与日志文件
科普一下日志级别相关信息:
-
CRITICAL:严重错误
-
ERROR:般错误
-
WARNING:警告
-
INFO:一般信息
-
DEBUG:调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志
那么这些日志将会打印
对于scrapy的日志管理在setting.py文件中可以进行设置
- 默认的级别为DEBUG,会显示上面所有的信息
- 在配置文件中settings·py
- LOG_FILE:将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是
.log - LOG_LEVEL:设置日志显示的等级,就是显示哪些,不显示哪些
具体配置如下:
# 指定日志的级别
LOG_LEVEL = 'INFO'
LOG_FILE = 'log.txt'
十、scrapy的post请求
具体是写start_requests方法:def start_requests(self)
start_requests的返回值:
scrapy.FormRequest(url=url,headers=headers, callback=self.parse_item, formdata=data)
其中:
- url:要发送的post地址
- headers:可以定制头信息
- callback:回调函数
- formdata:post所携带的数据,这是一个字典
具体以百度翻译示例:
在创建项目之后,对start_requeats文件进行重新:
import scrapy
import jsonclass FanyiSpider(scrapy.Spider):name = "fanyi"allowed_domains = ["fanyi.baidu.com"]start_urls = ["https://fanyi.baidu.com/sug"]def start_requests(self):url = 'https://fanyi.baidu.com/sug'data = {'kw': 'hello'}yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)def parse_second(self, response):# 解决编码问题print(json.loads(response.text))
运行发现毫无问题。
十一、scrapy的代理
在Scrapy中使用代理可以帮助你绕过一些反爬虫机制或避免IP被封禁。可以通过以下几种方式实现Scrapy的代理设置:
11.1、 在 settings.py 中配置代理
在Scrapy的 settings.py 中可以通过设置 HTTP_PROXY 或 DOWNLOADER_MIDDLEWARES 来全局配置代理。例如:
# settings.py
HTTP_PROXY = 'http://your_proxy_ip:proxy_port'DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,'your_project.middlewares.CustomProxyMiddleware': 543,
}
HttpProxyMiddleware 是Scrapy自带的中间件,你可以通过设置 HTTP_PROXY 来为所有请求指定一个代理。
11.2、 自定义代理中间件
如果需要根据不同请求设置不同的代理,可以自定义一个代理中间件:
# middlewares.py
import randomclass CustomProxyMiddleware(object):def __init__(self):self.proxies = ['http://proxy1_ip:proxy1_port','http://proxy2_ip:proxy2_port','http://proxy3_ip:proxy3_port',]def process_request(self, request, spider):# 随机选择一个代理proxy = random.choice(self.proxies)request.meta['proxy'] = proxyspider.logger.info(f"Using proxy: {proxy}")
然后在 settings.py 中启用这个中间件:
# settings.py
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,'your_project.middlewares.CustomProxyMiddleware': 543,
}
11.3、 为特定请求设置代理
如果你不想为所有请求都设置代理,可以在 spider 中为某些请求动态设置代理:
def start_requests(self):urls = ['http://example.com', 'http://another-site.com']for url in urls:request = scrapy.Request(url=url, callback=self.parse)request.meta['proxy'] = 'http://your_proxy_ip:proxy_port'yield request
11.4、 使用第三方代理服务
如果你需要大量代理,可能需要使用一些代理池或者代理服务。可以通过API获取代理,并在 middlewares.py 中根据实际需求动态设置代理。
class DynamicProxyMiddleware(object):def fetch_proxy(self):# 调用API获取代理response = requests.get('https://proxy-provider.com/api/get_proxy')return response.textdef process_request(self, request, spider):proxy = self.fetch_proxy()request.meta['proxy'] = proxyspider.logger.info(f"Using proxy: {proxy}")
通过这种方式,你可以动态地获取代理,并应用于请求。
这些方法可以灵活地帮助你在Scrapy中设置和管理代理,从而提高爬虫的成功率。
相关文章:
python爬虫快速入门之---Scrapy 从入门到包吃包住
python爬虫快速入门之—Scrapy 从入门到包吃包住 文章目录 python爬虫快速入门之---Scrapy 从入门到包吃包住一、scrapy简介1.1、scrapy是什么?1.2、Scrapy 的特点1.3、Scrapy 的主要组件1.4、Scrapy 工作流程1.5、scrapy的安装 二、scrapy项目快速入门2.1、scrapy项目快速创建…...

【Photoshop——肤色变白——曲线】
1. 三通道曲线原理 在使用RGB曲线调整肤色时,你可以通过调整红、绿、蓝三个通道的曲线来实现黄皮肤到白皮肤的转变。 黄皮肤通常含有较多的红色和黄色。通过减少这些颜色的量,可以使肤色看起来更白。 具体步骤如下: 打开图像并创建曲线调…...

[python]从零开始的API调用教程
一、API是什么? API即应用程序编程接口,是一组定义了不同软件系统或组件之间如何交互的规则和协议。API为开发者提供了一种简化的方式,通过预定义的函数或方法,来使用某个软件、库、操作系统或硬件的功能,而不需要深入…...

FFmpeg 怎样根据图片和文本生成视频
使用FFmpeg根据图片和文本生成视频,你可以使用image2过滤器来处理图片,并使用subtitles过滤器来添加文本。以下是一个基本的命令行示例,它将图片转换为视频,并将文本作为字幕叠加: ffmpeg -loop 1 -i image.jpg -vf &…...

paddlepaddle显存未正常释放
NVIDIA GPU 显存未正常释放 问题描述 paddlepaddle 训练过程出现问题中断等导致GPU显存没有释放。 情况1: 使用nvidia-smi -l查看显存占用情况,输出结果中没有显示PID,但是有显存占用。 解决方法 使用killall python 直接kill掉所有python进程。假如运行此命…...

websocket的使用
1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency> 2.配置websocket服务 Configuration public class WebSocketConfig {/*** 配置WebSocket服…...

docker如何建立本地私有仓库,并将docker镜像推到私有仓库
在 Docker 中,您可以通过 Docker Registry 创建本地私有仓库,并将 Docker 镜像推送到这个私有仓库。以下是具体步骤: 步骤 1:启动一个本地 Docker 私有仓库 拉取 registry 镜像: Docker 官方提供了一个 registry 镜像…...

vllm启动大语言模型时指定chat_template
问题介绍 在Linux下启动vllm: python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --model /model/Baichuan2-7B-Chat --trust-remote-code --gpu-memory-utilization 0.80使用下面的命令测试出错: curl -X POST \http://127.0.0.1…...
)
网络相关(HTTP/TCP/UDP/IP)
网络相关 常见的状态码 100 临时响应 100 继续,请求者应当继续提出请求101 切换协议200 成功响应 200: 服务器成功处理请求201 以创建,请求成功并且服务器创建了新的资源202 已接受:服务器已接受请求,但尚未处理203 非授权信息:服务器已成功处理请求,但返回的信息可能来…...

TF卡长期不用会丢失数据吗?TF卡数据恢复容易吗?
在现代科技快速发展的时代,TF卡(TransFlash卡)作为便携式存储设备,广泛应用于手机、相机、无人机等多种电子设备中,成为我们日常存储照片、视频、文档等重要数据的得力助手。然而,关于TF卡长期不使用是否会…...

Flink状态一致性保证
前言 一个Flink作业由一系列算子构成,每个算子可以有多个并行实例,这些实例被称为 subTask,每个subTask运行在不同的进程或物理机上,以实现作业的并行处理。在这个复杂的分布式场景中,任何一个节点故障都有可能导致 F…...

前端一键复制解决方案分享
需求背景 用户需要对流水号进行复制使用,前端的展示是通过样式控制,超出省略号表示,鼠标悬浮展示完整流水号。此处的鼠标悬浮展示采用的是:title,这样就无法对文本进行选中。 下面是给出一键复制的不同的解决方案,希望…...

麒麟操作系统swap使用率过高的排查思路
现象:用户业务环境服务器在运行时,监控平台告警swap使用99%,在系统内查询物理内存使用39%左右,swap使用达99%。 问题排查: 1)使用命令查询使用了swap空间的进程并排序:for i in cd /proc;ls |gr…...

爬虫python=豆瓣Top250电影
主流程:获取数据,解析数据,保存数据 from bs4 import BeautifulSoup #网页解析获取数据 import re #正则表达式 import urllib.request,urllib.error #获取网页数据 import sqlite3 #轻量级数据库 import xlwt #进行excel操作 #影视详情…...

【Eclipse系列】解决Eclipse中xxx.properties文件中文乱码问题
问题描述:由于eclipse对Properties资源文件的编码的默认设置是ISO-8859-1,所以在打开.properties文件时,会发现中文乱码了,如图: 解决方法: 1、一次生效法 右击该properties文件–>properties–>Re…...

mysql主从复制及故障修复
一、主MySQL数据库的配置 分别在三台主机(chen2/10.110、chen3/10.120、chen4/10.130)中安装mysql数据,其中chen2/10.110作为主MySQL服务器,其余两台作为从MySQL服务器。 1、在主机上部署mysql数据库 详细的请看上一篇:mysql数据…...

基于springboot的网上服装购物商城系统
基于springboot的网上服装购物商城系统 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:idea 源码获取: &#x…...

aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理
aws(学习笔记第六课) AWS的虚拟私有,共有子网以及ACL,定义公网碉堡主机子网以及varnish反向代理 学习内容: AWS的虚拟私有,共有子网以及ACL定义公网碉堡主机子网,私有子网和共有子网以及varnish反向代理 1. AWS的虚拟…...

接口测试(三)jmeter——连接mysql数据库
一、jmeter安装jdbc 1. 下载插件包,mysql数据库为例,驱动 com.mysql.jdbc.Driver 需要下载 mysql-connector-java-5.1.7-bin.jar 插件包,将插件包放到 jmeter 安装目录下的 lib 目录 2. 给jmeter安装jdbc驱动 二、jmeter操作数据库 1.…...

双十一购物节有哪些好物值得入手?2024双十一好物清单合集分享
一年一度的双十一购物狂欢节即将来临,各大平台纷纷开启预热活动,伴随着品牌的疯狂折扣和满减优惠,众多商品即将迎来超值的价格。现在正是大家“剁手”换新装备的大好时机。作为一名深耕智能产品多年的资深达人,今天这期我将从不同…...
原理与实现解析)
量子卷积神经网络(QCNN)原理与实现解析
1. 量子卷积神经网络(QCNN)概述量子卷积神经网络(QCNN)是近年来量子计算与深度学习交叉领域最具突破性的研究方向之一。作为经典CNN的量子版本,QCNN通过在量子线路中实现卷积、池化等操作,充分利用量子态的叠加性和纠缠特性,在希尔伯特空间中…...

FPGA超声波测距项目优化:从50MHz到17kHz时钟分频,聊聊资源与精度的权衡
FPGA超声波测距的时钟优化艺术:从50MHz到17kHz的工程哲学 在资源受限的嵌入式系统中,每一个逻辑单元和存储位都显得弥足珍贵。当我们在Cyclone IV这类中低端FPGA上实现超声波测距功能时,时钟管理策略往往成为决定项目成败的关键因素之一。本文…...

出口欧美设备机箱:必须符合HASCO模架与DME顶针标准
在出口欧美市场的设备机箱领域,符合HASCO模架与DME顶针标准是至关重要的。这不仅关乎产品的质量和性能,还影响着企业在国际市场的竞争力。本文将深入探讨这一标准的重要性,并结合深圳市机汇五金制品有限公司(以下简称“机汇五金”…...

独立开发者如何利用Taotoken以更低成本体验全球主流大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken以更低成本体验全球主流大模型 对于预算有限的独立开发者或个人研究者而言,探索不同的大模…...

3种创新方案解决抖音视频保存难题
3种创新方案解决抖音视频保存难题 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾遇到过这样的困扰:在抖…...
)
几十人团队跨部门共享大文件难?企业网盘选型必须知道的 3 个标准(含 5 款网盘实测)
企业 IT 和财务在做工具选型时,常常把网盘的“投资回报率(ROI)”简单等同于“多少钱买多少 GB 的存储空间”。但对于一个几十人的活跃团队来说,每天跨部门大文件传输引发的网络拥堵、向外部客户分享资料时的漫长等待与沟通摩擦&am…...

NVDC充电架构深度解析:智能电源管理如何提升笔记本性能与电池寿命
1. 项目概述:NVDC充电器,一个被低估的“能量管家”如果你是一位经常需要带着笔记本电脑移动办公的资深用户,或者是一位对设备续航和充电效率有极致追求的硬件爱好者,那么“NVDC”这个词,很可能已经或即将进入你的视野。…...

PostgreSQL 13.8 子查询优化实战:手把手教你读懂 `pull_up_sublinks` 源码
PostgreSQL 13.8 子查询优化实战:手把手教你读懂 pull_up_sublinks 源码 数据库查询优化器是数据库系统的核心组件之一,它负责将用户提交的SQL语句转换为高效的执行计划。在PostgreSQL中,子查询优化是查询优化的重要环节,而pull_u…...

32位寄存器全解析:逆向分析与系统底层开发的基石
1. 从零开始:为什么32位寄存器是逆向分析的基石如果你刚开始接触逆向工程或者系统底层开发,面对一堆以E开头的寄存器缩写,是不是感觉有点头大?EAX、EBP、ESP……这些看起来神秘的代号,其实是理解程序如何“思考”和“行…...

标签系统的底层同步拓扑:大批量客户标签异步更新的一致性方案
标签(Tag)是私域精细化运营的灵魂。在进行大规模广告投放、或者老客清洗时,企业系统经常需要同时为上万个外部客户批量追加或清空标签。 1. 标签同步的复杂性在哪里? 原生设计中,企业微信的标签是以“企业标签组&#…...