初始Python篇(4)—— 元组、字典
找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏: Python
目录
元组
相关概念
元组的创建与删除
元组的遍历
元组生成式
字典
相关概念
字典的创建与删除
字典的遍历与访问
字典的相关操作方法
字典生成式
元组
相关概念
元组是Python中内置的不可变序列,与上次我们学习的列表不同,因此元组中不存在增加、删除、修改元素的相关操作。
在Python中使用 () 定义元组,元素与元素之间使用英文的逗号分隔。
同样元组也是属于序列的,因此操作序列的一系列方法也是可以给元组使用的。
元组的创建与删除
语法:
# 使用()的方式创建元组
元组名 = (element1, element2, ..., elementN)# 使用内置函数tuple()创建元组
元组名 = tuple(序列)代码演示:
# 创建元组
# 使用()创建元组
t1 = (1,'Hello',[1,2,3])
print(t1) # 输出为 (1, 'Hello', [1, 2, 3])# 使用内置函数tuple创建元组
t2 = tuple('Hello') # 字符串是序列
print(t2) # 输出为 ('H', 'e', 'l', 'l', 'o')t3 = tuple([10,'Hello']) # 列表是序列
print(t3) # 输出为 (10, 'Hello')从上面的输出结果,我们可以得出一个结论:使用内置函数去创建元组时,序列中的基础元素会被拆解开来,而使用 () 去创建元组,最终的结果就是 () 内部的一个一个的元素。
注意:当创建的元组中只有一个元素时,"逗号"是不能省略的。
代码演示:
t = (3)
print(type(t)) # 输出为 <class 'int'> ——> 整型t = (3,)
print(type(t)) # 输出为 <class 'tuple'> ——> 元组类型元组的删除和列表是一样的,也是使用 关键字 del。
语法:
del 元组名元组的遍历
与列表一样,有三种常见的遍历方式:
1、使用for循环:
t = ('Hello', 'Python',123)
for item in t:print(item, end=' ') # 输出为 Hello Python 1232、使用for循环+range索引:
t = ('Hello', 'Python',123)
for i in range(0,len(t)):print(t[i],end=' ') # 输出为 Hello Python 1233、使用 enumerate 函数:
语法结构:
for index, item in enumerate(t):print(index, item)# index 是序号,不是索引。序号可以手动设置起始位置,索引是不变的
# item 是列表的元素代码演示:
t = ('Hello', 'Python',123)
for index,item in enumerate(t, 1):print(index,item)
元组生成式
元组生成式与列表生成式有些不同,列表生成式是直接生成了一个列表对象,而元组生成式是生成了一个生成器对象,需要我们手动地去转换为元组或者列表才行。
代码演示:
# 元组生成式
t = (i for i in range(1,4))
print(t)# 转换为列表
l = list(t)
print(l)# 转换为元组
t = tuple(t)
print(t)
当然,除了转换为列表或者元组之外,还可以直接使用for循环和"__next__方法"去遍历生成器对象。
代码演示:
for循环:
t = (i for i in range(1,4))
for item in t:print(item,end=' ') # 输出为 1 2 3 __next__方法:这个next前后都是有两个下划线的。
t = (i for i in range(1,4))print(t.__next__()) # 输出为 1
print(t.__next__()) # 输出为 2
print(t.__next__()) # 输出为 3# __next__方法是每次从生成器对象中取出一个值
# 因此我们都是把这个方法和for循环配合使用注意:只要这个生成器对象被遍历过一遍之后,这个生成器对象里面的内容就为空了,我们再去遍历就获取不到任何的元素了。
以上就是元组的全部内容了,下面我们来学习字典。
字典
相关概念
字典类型是根据一个信息查找另一个信息的方式构成了“键值对”,它表示索引用的键和对应的值构成的成对关系。如果学过数据结构的小伙伴,应该对这个概念很熟悉,哈希表就是通过哈希函数的映射方式实现了键值对的时间复杂度为O(1)的查找,而字典就是在数据结构中所学的哈希表。

字典和列表一样是可变的数据类型,具有增删改查的相关操作。在 Python 3.6 及以后的版本中,字典的键在插入顺序上是保持有序的。而在之前的版本中,字典中的键通常被认为是无序的。因为其底层的实现方式就是哈希函数的映射。 虽然现在字典中的键是在插入的顺序上保持有序的,但是我们仍然认为字典的键是无序的。
即字典本身的键是无序的,之所以在输出时,看起来处于有序的状态,是因为Python解释器的处理。
字典中的键要求是不可变的数据类型,且键是不能重复的,但是值是可以重复的。
字典也是序列,因此操作序列的方法也是可以用来操作字典的。
字典的创建与删除
语法结构:
# 使用{}直接创建字典
d = {key1:value1, key2:value2,......}# 使用内置函数创建字典
# 1、通过映射函数zip创建字典
# lst1、lst2一定要是可迭代的对象
zip(lst1, lst2) # lst1对应着键,lst2对应着值(两者的数量要一一对应)# 2、通过dict()创建字典
d = dict(key1=value1, key2=value2,......)

代码演示:
# 1、使用{}方式创建
d = {1:'Hello',2:'World',3:'Python'}
print(d) # 输出为 {1: 'Hello', 2: 'World', 3: 'Python'}# 当键冲突时,前面的值会被覆盖
d = {1:'Hello',2:'World',3:'Python',3:'Java'}
print(d) # 输出为 {1: 'Hello', 2: 'World', 3: 'Java'}# 2、使用dict()创建
d = dict(Hello=1,Python=2) # 这里的Hello会被当作字符串,作为键
print(d) # 输出为 {'Hello': 1, 'Python': 2}
# 不能直接将数字字面值作为键
# d = dict(1=Hello,2=Python) ——> error# 3、使用zip函数创建字典
z = zip([1,2,3],['Hello','Python','Java'])
print(z) # 这里也是生成的zip对象# zip对象需要转换为列表、元组、字典才行,同样只能这个对象只能使用一次
# print(list(z)) # 输出为[(1, 'Hello'), (2, 'Python'), (3, 'Java')]
# print(tuple(z)) # 输出为 ((1, 'Hello'), (2, 'Python'), (3, 'Java'))
print(dict(z)) # 输出为 {1: 'Hello', 2: 'Python', 3: 'Java'}注意:使用zip函数去创建zip对象时,lst1的元素必须是不可变类型。例如,lst1本身可以是不可变类型,但是其内不能嵌套列表,因为列表是可变的数据类型,不能作为键。
z = zip(([1,2],[3,4]),('Hello','World'))
print(dict(z)) # 这里会报错但是如果我们将 zip对象 转换为元组或者列表的话,是可以成功的,因为元组和列表没有规定。
1、转换为列表:
z = zip(([1,2],[3,4]),('Hello','World'))
print(list(z)) # 输出为 [([1, 2], 'Hello'), ([3, 4], 'World')]
2、转换为元组:
z = zip(([1,2],[3,4]),('Hello','World'))
print(tuple(z)) # 输出为 (([1, 2], 'Hello'), ([3, 4], 'World'))删除的字典的语法:
del 字典名字典的遍历与访问
字典的访问与元组和列表的访问有所不同,其有两种访问方式:
1、通过 d[key] 去访问对应的值:
2、通过 d.get(key) 去访问对应的值:
代码演示:
d = {1:'Hello',2:'World',3:'Python'}
print(d[1]) # 输出为 Hello
print(d.get(3)) # 输出为 Python注意:当 键 不存在时,d[key]的方式会报错,而d.get(key)会返回一个默认值:None,当然也可以指定返回默认值。
d = {1:'Hello',2:'World',3:'Python'}
print(d.get('Java',2)) # 输出为 2这个默认值,可以随便是什么类型的数据。可以字符串、整型、列表等。
字典的遍历语法:
# 1、遍历key与value的元组
for element in d.items():print(element)# 2、分别遍历key和value
for key,value in d.items():print(key,value)代码演示:
1、遍历key与value的元组:
d = {1:'Hello',2:'World',3:'Python'}
for element in d.items():print(element,end=' ') # 输出为 (1, 'Hello') (2, 'World') (3, 'Python')2、分别遍历key与value:
for key,value in d.items():print(key,'-->',value)
# 输出为
# 1 --> Hello
# 2 --> World
# 3 --> Python字典的相关操作方法
字典有一系列相关的操作方法:
| 字典的方法 | 描述说明 |
| d.keys() | 获取所有的key数据 |
| d.values() | 获取所有的value数据 |
| d.pop(key, default) | key存在获取相应的value,同时删除key-value对,否则获取默认值 |
| d.popitem() | 随机从字典中取出一个key-value对,结果为元组类型,同时将该key-value从字典中删除 |
| d.clear() | 清空字典中所有的key-value对 |
下面我们就来演示:
d = {1:'Hello',2:'World',3:'Python'}
print(d) # {1: 'Hello', 2: 'World', 3: 'Python'}# 增加元素,直接可以赋值
d[4] = 'Java'
print(d) # {1: 'Hello', 2: 'World', 3: 'Python', 4: 'Java'}# 获取所有的key
keys = d.keys()
print(keys) # dict_keys([1, 2, 3, 4])
print(list(keys)) # [1, 2, 3, 4]
print(tuple(keys)) # (1, 2, 3, 4)# 获取所有的value
values = d.values()
print(values) # dict_values(['Hello', 'World', 'Python', 'Java'])
print(list(values)) # ['Hello', 'World', 'Python', 'Java']
print(tuple(values)) # ('Hello', 'World', 'Python', 'Java')# 将字典的元素转为 key-value的形式,以元组的形式进行展现
z = d.items()
print(z) # dict_items([(1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java')])
print(list(z)) # [(1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java')]
print(tuple(z)) # ((1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java'))
print(dict(z)) # {1: 'Hello', 2: 'World', 3: 'Python', 4: 'Java'}# 找到对应key的value,并从字典中删除
print(d.pop(1)) # Hello
print(d) # {2: 'World', 3: 'Python', 4: 'Java'}
print(d.pop(5,"没找到")) # 如果不设置默认值,那么找不到就会报错# 随机找到一对key-value,并从字典中删除
print(d.popitem()) # (4, 'Java')-->这是随机删除的
print(d) # {2: 'World', 3: 'Python'}# 清空字典
d.clear()
print(d) # {}注意:
1、在字典中添加元素是直接使用 d[key] = value 的方式。
2、使用 d.keys() 和 d.values() 得到的结果是与我们之前学习的列表生成式、元组生成式不一样。虽然两者都是迭代器,但是前者是可以循环遍历的,也就是可以转换多次,而后者只能使用一次。
字典生成式
语法格式:
# 第一种方式:
d = {key:value for item in range}# 第二种方式:
d = {key:value for key,value in zip(lst1,lst2)}代码演示:
# 第一种方式:
# 0-2作为键、1-100之间的数作为值
d = {item:random.randint(1,100) for item in range(3)}
print(d) # {0: 22, 1: 65, 2: 52} -> 随机的值# 第二种方式:
lst1 = [1,2,3]
lst2 = ['张三','李四','王五']
d = {key:value for key,value in zip(lst1,lst2)}
print(d) # {1: '张三', 2: '李四', 3: '王五'}以上就是字典的全部内容了。
我们现在学习的三种数据类型:列表、元组、字典都是属于序列的一种。
好啦!本期 初始Python篇(4)—— 元组、字典 的学习之旅到此结束啦!我们下一期再一起学习吧!
相关文章:
初始Python篇(4)—— 元组、字典
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: Python 目录 元组 相关概念 元组的创建与删除 元组的遍历 元组生成式 字典 相关概念 字典的创建与删除 字典的遍历与访问 字典…...

C#中正则表达式
在C#中,正则表达式由 System.Text.RegularExpressions 命名空间提供,可以使用 Regex 类来处理正则表达式。以下是一些常见的用法及示例。 C# 中使用正则表达式的步骤: 引入命名空间: using System.Text.RegularExpressions; 创…...

【python写一个带有界面的计算器】
python写一个带有界面的计算器 为了创建一个带有图形用户界面(GUI)的计算器,我们可以使用Python的tkinter库。tkinter是Python的标准GUI库,它允许我们创建窗口、按钮、文本框等GUI元素。 下面是一个简单的带有GUI的计算器示例&a…...

K230获取单摄像头的 3 个通道图像并显示在 HDMI 显示器上
本示例打开摄像头,获取 3 个通道的图像并显示在 HDMI 显示器上。通道 0 采集 1080P 图像,通道 1 和通道 2 采集 VGA 分辨率的图像并叠加在通道 0 的图像上。 # Camera 示例 import time import os import sysfrom media.sensor import * from media.dis…...
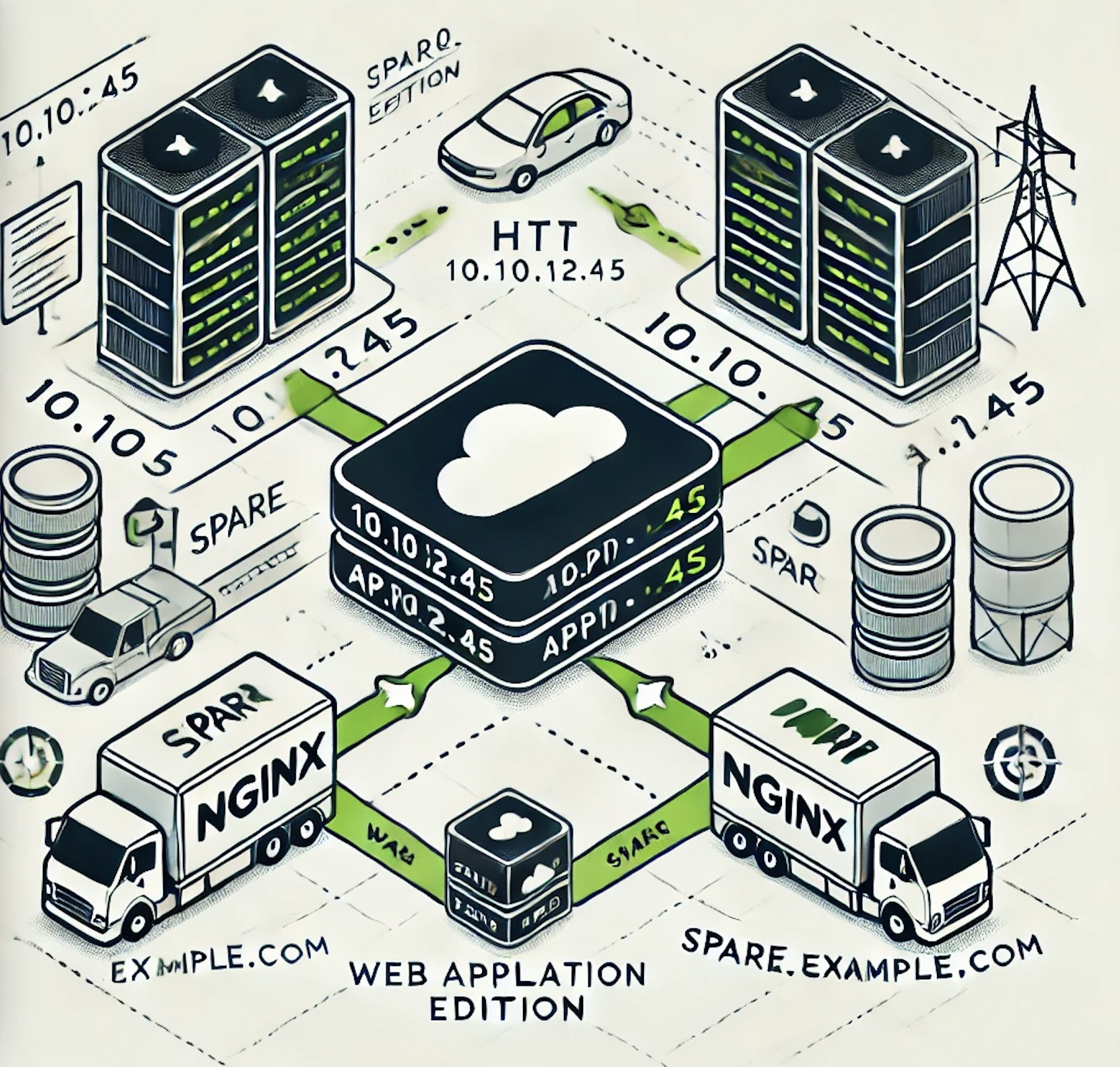
nginx中的HTTP 负载均衡
HTTP 负载均衡:如何实现多台服务器的高效分发 为了让流量均匀分配到两台或多台 HTTP 服务器上,我们可以通过 NGINX 的 upstream 代码块实现负载均衡。 方法 在 NGINX 的 HTTP 模块内使用 upstream 代码块对 HTTP 服务器实施负载均衡: upstr…...

package.json 里的 dependencies和devDependencies区别
dependencies(依赖的意思): 通过 --save 安装,是需要发布到生产环境的。 比如项目中使用react,那么没有这个包的依赖就会报错,因此把依赖写入dependencies npm install <package-name>// 缩写 np…...
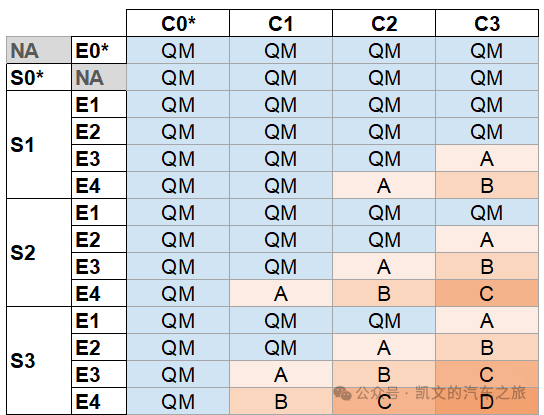
【功能安全】HARA分析中的SEC如何确认
目录 01 SEC介绍 02 SEC怎么定义 📖 推荐阅读 01 SEC介绍 SEC定义 S代表safety,E指的是Exposure,C指的是Controllability ASIL等级就是基于SEC三个参数确定下来的。 计算公式:10=D,9=C,8=B,7=A,<7=QM 举例:S3-C2-E4,即3+2+4=9,ASIL C 02 SEC怎么定义 Safe…...

阿里云Docker镜像源安装Docker的步骤
阿里云 Docker 镜像源安装 Docker 的步骤: 1. 更新包管理器: sudo apt update 2. 安装 Docker 的依赖包: sudo apt install apt-transport-https ca-certificates curl gnupg lsb-release 3. 添加阿里云 Docker 镜像源 GP…...

得一微全资子公司硅格半导体携手广东工业大学,荣获省科学技术奖一等奖
10月17日,全省科技大会在广州召开,会上颁发了2023年度广东省科学技术奖。得一微电子旗下全资子公司深圳市硅格半导体有限公司(以下简称“硅格半导体”)与广东工业大学(以下简称:广工大)携手多家…...

@SneakyThrows不合理使用,是真的坑
public static void main(String[] args) {int a 1;int b 2;String result getResult(a, b);System.out.println(result);}SneakyThrowspublic static String getResult(Integer a,Integer b){if (a.equals(b)){return "成功!";}else{throw new Interru…...
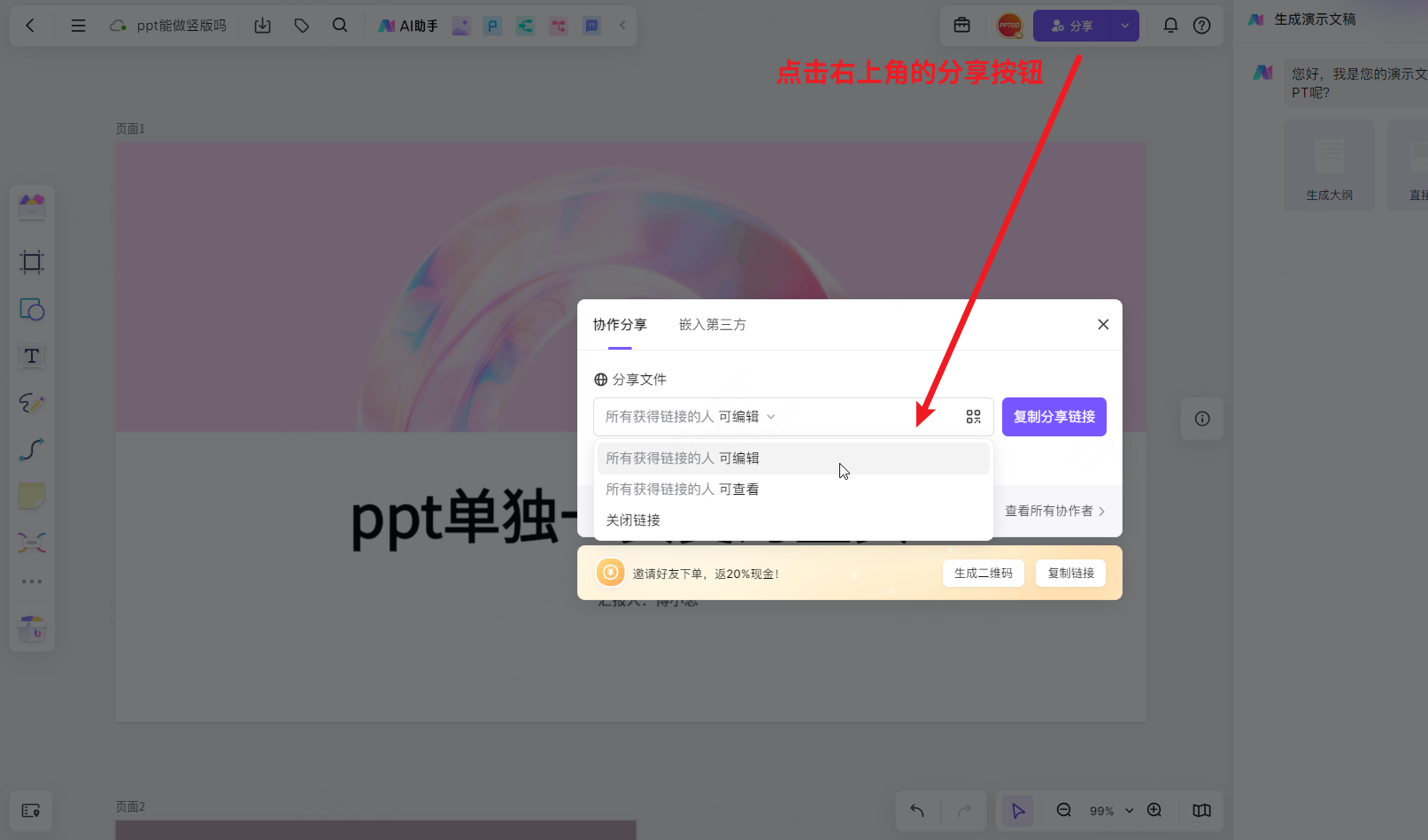
怎么把ppt页面切换为竖页?首推使用这个在线ppt工具!
熟悉ppt的朋友都知道,最常见的ppt演示文稿为横版样式,且一旦确定了ppt的版式,后续所有页面会保持相同的大小,但有时横版不能满足我们需求,想单独把其中一页或多页变为竖页,Office Powerpoint就无能为力了。…...

【JavaEE】——自定义协议方案、UDP协议
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 一:自定义协议 1:自定义协议 (1)交互哪些信息 &…...

python爬虫快速入门之---Scrapy 从入门到包吃包住
python爬虫快速入门之—Scrapy 从入门到包吃包住 文章目录 python爬虫快速入门之---Scrapy 从入门到包吃包住一、scrapy简介1.1、scrapy是什么?1.2、Scrapy 的特点1.3、Scrapy 的主要组件1.4、Scrapy 工作流程1.5、scrapy的安装 二、scrapy项目快速入门2.1、scrapy项目快速创建…...

【Photoshop——肤色变白——曲线】
1. 三通道曲线原理 在使用RGB曲线调整肤色时,你可以通过调整红、绿、蓝三个通道的曲线来实现黄皮肤到白皮肤的转变。 黄皮肤通常含有较多的红色和黄色。通过减少这些颜色的量,可以使肤色看起来更白。 具体步骤如下: 打开图像并创建曲线调…...

[python]从零开始的API调用教程
一、API是什么? API即应用程序编程接口,是一组定义了不同软件系统或组件之间如何交互的规则和协议。API为开发者提供了一种简化的方式,通过预定义的函数或方法,来使用某个软件、库、操作系统或硬件的功能,而不需要深入…...

FFmpeg 怎样根据图片和文本生成视频
使用FFmpeg根据图片和文本生成视频,你可以使用image2过滤器来处理图片,并使用subtitles过滤器来添加文本。以下是一个基本的命令行示例,它将图片转换为视频,并将文本作为字幕叠加: ffmpeg -loop 1 -i image.jpg -vf &…...

paddlepaddle显存未正常释放
NVIDIA GPU 显存未正常释放 问题描述 paddlepaddle 训练过程出现问题中断等导致GPU显存没有释放。 情况1: 使用nvidia-smi -l查看显存占用情况,输出结果中没有显示PID,但是有显存占用。 解决方法 使用killall python 直接kill掉所有python进程。假如运行此命…...

websocket的使用
1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency> 2.配置websocket服务 Configuration public class WebSocketConfig {/*** 配置WebSocket服…...

docker如何建立本地私有仓库,并将docker镜像推到私有仓库
在 Docker 中,您可以通过 Docker Registry 创建本地私有仓库,并将 Docker 镜像推送到这个私有仓库。以下是具体步骤: 步骤 1:启动一个本地 Docker 私有仓库 拉取 registry 镜像: Docker 官方提供了一个 registry 镜像…...

vllm启动大语言模型时指定chat_template
问题介绍 在Linux下启动vllm: python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --model /model/Baichuan2-7B-Chat --trust-remote-code --gpu-memory-utilization 0.80使用下面的命令测试出错: curl -X POST \http://127.0.0.1…...

GIS技巧100例23-ArcGIS像元统计实战:从月度栅格到年度气候指标
1. 像元统计基础与气候数据特点 刚接触GIS处理气候数据时,我经常被各种栅格格式和统计方法搞得晕头转向。直到有次用ArcGIS的像元统计工具批量处理了5年的月降水数据,才发现这个功能简直是隐藏的效率神器。像元统计(Cell Statisticsÿ…...

STM32F4/F7上跑AI手写识别:从CUBEMX配置到串口通信的完整避坑指南
STM32F4/F7实战AI手写识别:从模型部署到数据处理的工程化解决方案 在嵌入式设备上部署神经网络进行手写识别,正逐渐从实验室走向工业现场。STM32F4/F7系列凭借其平衡的性能与功耗,成为边缘AI应用的理想选择。本文将深入探讨从模型准备到实际部…...

从Ring Bus到Mesh:聊聊Intel CPU内部那些‘堵车’与‘修路’的往事
从Ring Bus到Mesh:Intel CPU内部通信架构的演进与工程智慧 1. 当CPU内部变成"早高峰的北京三环" 2006年,Intel工程师们围在白板前,盯着密密麻麻的电路图皱起了眉头。他们刚刚完成测试的八核处理器原型机显示:当所有核心…...

高级磁盘空间管理:WinDirStat深度配置与自动化清理指南
高级磁盘空间管理:WinDirStat深度配置与自动化清理指南 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 在当今数据爆炸的时代…...

3个高效方法解决抖音素材管理难题:从零散文件到有序素材库
3个高效方法解决抖音素材管理难题:从零散文件到有序素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

RK3399嵌入式Linux开发:Sysfs内核虚拟文件系统深度探索与实践指南
1. 项目概述:为什么从Sysfs开始内核探索拿到一块RK3399这样的高性能开发板,无论是做产品原型还是学习嵌入式Linux,第一步往往都是“点亮”和“跑起来”。但当系统启动,命令行提示符闪烁时,很多开发者,尤其是…...

别只盯着TPS!用JMeter汇总报告做一次完整的性能瓶颈分析实战
别只盯着TPS!用JMeter汇总报告做一次完整的性能瓶颈分析实战 在性能测试领域,JMeter的汇总报告(Summary Report)是最常用的监听器之一,但很多测试工程师往往只关注其中的TPS(每秒事务数)指标&am…...
)
STC15单片机定时器T0配置详解:从1T/12T模式选择到1秒精准定时(附完整代码)
STC15单片机定时器T0配置实战:1秒精准定制的全流程解析 从理论到实践的定时器T0深度探索 在嵌入式系统开发中,定时器功能如同系统的心跳,为各类任务提供精准的时间基准。STC15系列单片机凭借其高性能和丰富的外设资源,成为许多开…...

Linux入门指南:从内核到终端,掌握核心命令与文件操作
1. 从内核到终端:理解Linux的运作逻辑很多刚接触Linux的朋友,包括我当年,都会觉得它是一堆神秘命令的集合。输入几个字母,敲下回车,系统就乖乖听话了。但要想真正用好Linux,而不是死记硬背命令,…...

SAP PP实战指南:从零到一掌握BOM创建、群组BOM配置与CS01核心操作
1. BOM基础概念与核心价值 物料清单(Bill of Materials,简称BOM)是制造业的DNA图谱,它用结构化数据描述产品从原材料到成品的完整演化路径。我第一次接触SAP PP模块时,项目经理指着屏幕上的BOM结构说:"…...