Redis 性能优化选择:Pika 的配置与使用详解
引言
在我们日常开发中 redis是我们开发业务场景中不可缺少的部分。Redis 凭借其内存存储和快速响应的特点,广泛应用于缓存、消息队列等各种业务场景。然而,随着数据量的不断增长,单节点的 Redis 因为内存限制和并发能力的局限,逐渐难以支撑高并发的请求。为了解决这些问题,我们通常会采用 搭建Redis 集群方案来解决高并发下的限制问题。然而,Redis 集群的部署往往需要更高的资源投入,巨大的内存需求和运维成本带来了不小的压力。除此之外,集群模式下的数据分片和一致性问题,也让系统设计的复杂度大大增加。
在这种高并发、大流量的业务场景下,我们是否能够在追求 Redis 高性能的同时,找到更经济高效的大数据解决方案呢?除了 Redis 集群方案外,今天我将介绍一种可以替代 Redis 集群的方案,也是我在以往开发中广泛使用的一种数据结构——Pika。Pika 在兼容 Redis API 的基础上,将数据存储在磁盘上,突破了内存限制,尤其适合大数据存储和高并发访问的需求。
什么是 Pika?
Pika 是一种兼容 Redis 协议的高效存储引擎,设计初衷就是为了解决 Redis 在大数据场景下因内存限制而带来的瓶颈问题。与 Redis 将数据存储在内存中的方式不同,Pika 将数据存储在磁盘上,从而有效扩展存储容量,适应大规模数据的需求。当 Redis 的内存使用量超过 16 GiB 时,会面临多种限制,如内存容量受限、单线程阻塞、启动恢复时间长、内存硬件成本高、缓冲区容易填满、一主多从故障时的切换成本高等。Pika 的出现并非为了替代 Redis,而是为了补充 Redis,以便在大数据场景下依然保持高性能。Pika 力求完全遵守 Redis 协议,继承 Redis 便捷的运维设计,同时通过持久化存储来突破 Redis 在数据量巨大时内存容量不足的瓶颈。此外,Pika 支持通过 slaveof 命令进行主从模式配置,支持全量和增量数据同步,方便在大数据和高可用场景下的灵活扩展。
Pika 的兼容性
Pika 兼容 Redis 中的 string、hash、list、zset 和 set 五大核心数据类型,能够支持大部分与之相关的操作接口(兼容详情可查阅官方文档),实现了几乎所有 Redis 的基本操作需求。这意味着,现有的 Redis 客户端和命令都可以无缝迁移到 Pika 上使用,无需额外学习新的命令或语法。
Pika 的主从备份能力
与 Redis 一样,Pika 支持通过 slaveof 命令进行主从复制,提供可靠的备份和高可用性支持。同时,Pika 实现了全同步和部分同步机制,能够在数据同步中做到既灵活又高效,确保数据一致性和稳定性。这样,Pika 既保留了 Redis 数据复制的优势,又在容量上扩展了存储空间,可以在不更改代码的前提下快速接入生产环境。
为什么选择 Pika?
Pika 提供了与 Redis 一致的使用体验,且不需要额外的学习和开发成本。相较于 Redis,Pika 的优势体现在以下几方面:
- 更大的存储容量:Pika 通过磁盘存储解决了 Redis 的内存瓶颈问题,适合大规模数据场景。
- 无缝替换:Pika 兼容 Redis 绝大多数核心命令,因此在功能实现和操作上与 Redis 几乎无异,用户不必更改现有代码或熟悉新的命令,即可将 Pika 集成到现有系统中。
- 高可用性和备份支持:Pika 支持主从复制、全同步和部分同步,确保数据可靠性和高并发访问。
Pika 的适用场景
Pika 的设计非常适合以下几种高容量、高并发的数据场景:
- 大数据量缓存:对于数据规模庞大的应用,比如实时数据处理、日志收集和分析场景,Pika 的磁盘存储使它能轻松应对 TB 级数据,不再受限于内存容量。适用于金融、广告、物联网等需要存储大量实时数据的行业。
- 高并发访问场景:在流量密集型业务中,如电商、游戏和社交网络,Pika 能够支持高并发访问需求,与 Redis 一样实现快速的数据读写,但在资源消耗上更经济。
- 长时间数据存储:在日志存储、历史数据存储等业务中,数据需要长时间保留,但访问频率相对较低。Pika 的磁盘持久化存储方式为此类场景提供了低成本的替代方案,不会因数据量增加而导致内存压力上升。
- 分布式集群环境:对于需要高可用性的数据集群应用,Pika 的主从复制和同步功能使其可以在分布式环境中稳定运行,支持多节点备份和容灾切换,确保数据的高可靠性和一致性。
Pika使用用户

Pika 已被各大公司广泛采用,用于内部部署,证明了其可扩展性和可靠性。一些值得注意的使用实例包括:
- 360公司:内部部署,规模10000+实例,单机数据量1.8TB。
- 微博:内部部署,有10000+个实例。
- 喜马拉雅(Xcache) :6000+实例,海量数据超过120TB。
- 个推 公司:内部部署,300+实例,累计数据量超过30TB。
此外,迅雷、小米、知乎、好未来、快手、搜狐、美团、脉脉等公司也在使用 Pika。有关完整用户列表,可以参考 Pika 项目提供的官方列表。
这些在不同公司和行业的部署凸显了 Pika 在处理大规模、大容量数据存储需求方面的适应性和有效性。
接下来,我将展示如何安装 Pika,并进行简单的使用示例,以便快速上手并体验 Pika 的性能。
安装之前我们先看下官方给的安装示例:安装示例
我按照官方的安装示例 安装的是v4.0.1最新版本及之前版本。但是我一直未make或build成功。不知道是不是我自己环境的问题。
本文章采用下载安装包的形式来安装
-
首先我们去版本库下载对应版本的安装包(我选择是v3.3.0)

-
将安装包上传到
/usr/local/pika目录中,便于管理:sudo mkdir -p /usr/local/pika -
然后解压该安装包
sudo tar -xvf pika-linux-x86_64-v3.3.0.tar.bz2
-
解压完成后会生成一个
output文件夹,接下来我们执行命令启动./output/bin/pika -c ./output/conf/pika.confb -
我第一次启动报错了 报错如下:

-
这个错误提示主要有两个原因:1. Rsync 失败:
pika_rsync_service.cc:48报错提示无法启动rsync服务,可能是rsync没有安装或者路径配置有问题。
2. 端口绑定失败:提示bind port 10221 failed,表示 Pika 无法绑定端口10221,可能是端口被占用,或者当前用户权限不足。 -
Pika 使用
rsync进行数据同步,请确保系统已安装rsync:sudo yum install -y rsync安装完成后,重新尝试启动 Pika。
-
使用以下命令检查是否有其他进程占用了
10221端口:sudo lsof -i :10221如果有其他进程占用端口,可以尝试停止占用端口的进程,或者更改 Pika 的端口配置。
-
解决上面问题后 我尝试重新启动,可以看到已经成功启动:

启动成功后我们另开一个窗口来测试操作简单命令:

我们来大概看下安装的Pika配置文件 在output/conf下的pika.conf:
# Pika port
port : 9221 # Pika 监听的端口# Thread Number
thread-num : 1 # 用于处理客户端请求的工作线程数# Thread Pool Size
thread-pool-size : 12 # 线程池大小,用于处理并发任务# Sync Thread Number
sync-thread-num : 6 # 用于主从同步的线程数# Pika log path
log-path : ./log/ # 日志文件的存储路径# Pika db path
db-path : ./db/ # 数据库文件的存储路径# Pika write-buffer-size
write-buffer-size : 268435456 # 写缓冲区大小,单位为字节(256MB)# Pika timeout
timeout : 60 # 客户端连接空闲超时时间,单位为秒# Requirepass
requirepass : # 设置管理员密码,用于验证高权限操作# Masterauth
masterauth : # 从节点连接主节点时的认证密码# Userpass
userpass : # 普通用户连接的密码# User Blacklist
userblacklist : # 黑名单用户列表,拒绝指定用户访问# Pika instance mode [classic | sharding]
instance-mode : classic # Pika 的实例模式:classic 为多数据库模式,sharding 为分片模式# Set the number of databases. Limited in [1, 8]
databases : 1 # 数据库数量,仅在 classic 模式下有效# default slot number each table in sharding mode
default-slot-num : 1024 # 每张表的分片数量,仅在 sharding 模式下有效# replication num defines followers in a single raft group, limited in [0, 4]
replication-num : 0 # Raft 组中的从节点数量# consensus level defines confirms before commit to client
consensus-level : 0 # 主节点提交前需要的确认数量,用于 Raft 一致性协议# Dump Prefix
dump-prefix : # 导出文件的前缀,用于数据持久化文件命名# daemonize [yes | no]
#daemonize : yes # 是否以守护进程方式运行(后台运行)# Dump Path
dump-path : ./dump/ # 数据导出路径# Expire-dump-days
dump-expire : 0 # 数据导出的过期天数(0 表示不过期)# pidfile Path
pidfile : ./pika.pid # Pika 进程 ID 文件路径# Max Connection
maxclients : 20000 # 最大客户端连接数# the per file size of sst to compact, default is 20M
target-file-size-base : 20971520 # 每个 SST 文件的目标大小(20MB)# Expire-logs-days
expire-logs-days : 7 # 日志文件的过期天数# Expire-logs-nums
expire-logs-nums : 10 # 日志文件的最大数量# Root-connection-num
root-connection-num : 2 # root 用户的最大连接数# Slowlog-write-errorlog
slowlog-write-errorlog : no # 慢查询日志是否写入错误日志文件# Slowlog-log-slower-than
slowlog-log-slower-than : 10000 # 慢查询记录的时间阈值,单位为微秒# Slowlog-max-len
slowlog-max-len : 128 # 慢查询日志的最大条数# Pika db sync path
db-sync-path : ./dbsync/ # 数据同步文件的存储路径# db sync speed(MB) max is set to 1024MB, min is set to 0
db-sync-speed : -1 # 主从同步的最大速度,单位为 MB/s,-1 表示无限制# The slave priority
slave-priority : 100 # 从节点的优先级# network interface
#network-interface : eth1 # 网络接口(可以指定特定的网卡)# replication
#slaveof : master-ip:master-port # 设置为从节点并指定主节点地址和端口# CronTask, e.g., 02-04/60 for compaction between 2-4am every day
#compact-cron : 3/02-04/60 # 压缩任务计划:在每周三的 2-4 点进行压缩# Compact-interval, e.g., 6/60 checks compaction every 6 hours
#compact-interval : # 压缩间隔,单位为小时。比 compact-cron 优先# sync window size for binlog between master and slave, default is 9000
sync-window-size : 9000 # 主从同步的 binlog 窗口大小# max connection read buffer size, default is 256MB
max-conn-rbuf-size : 268435456 # 最大读取缓冲区大小###################
## Critical Settings
###################
# write_binlog [yes | no]
write-binlog : yes # 是否开启 binlog 日志记录# binlog file size: default is 100M, limited in [1K, 2G]
binlog-file-size : 104857600 # binlog 文件大小限制(100MB)# Use cache to store up to 'max-cache-statistic-keys' keys
max-cache-statistic-keys : 0 # 缓存的统计键的最大数量,0 表示关闭此功能# Trigger small compaction after deleting/overwriting keys
small-compaction-threshold : 5000 # 触发小压缩的操作次数阈值# Flush triggered if all live memtables exceed this limit
max-write-buffer-size : 10737418240 # 所有 memtables 的总内存大小上限(10GB)# Limit some command response size
max-client-response-size : 1073741824 # 限制响应大小的最大值(1GB)# Compression type supported [snappy, zlib, lz4, zstd]
compression : snappy # 数据压缩类型# max-background-flushes: default is 1, limited in [1, 4]
max-background-flushes : 1 # 后台刷新任务的最大数量# max-background-compactions: default is 2, limited in [1, 8]
max-background-compactions : 2 # 后台压缩任务的最大数量# Maximum cached open file descriptors
max-cache-files : 5000 # 缓存的最大打开文件描述符数量# max_bytes_for_level_multiplier: default is 10, can change to 5
max-bytes-for-level-multiplier : 10 # RocksDB 层次的最大字节数乘数# BlockBasedTable block_size, default 4k
# block-size: 4096 # 块表的块大小(4KB)# block LRU cache, default 8M, 0 to disable
# block-cache: 8388608 # LRU 块缓存大小(8MB)# whether the block cache is shared among RocksDB instances
# share-block-cache: no # 是否在多个 RocksDB 实例之间共享块缓存# whether index and filter blocks are in block cache
# cache-index-and-filter-blocks: no # 是否将索引和过滤块放入块缓存# bloomfilter of the last level will not be built if set to yes
# optimize-filters-for-hits: no # 是否优化最后一层的布隆过滤器# Enables dynamic levels target size for compaction
# level-compaction-dynamic-level-bytes: no # 是否启用动态级别的压缩目标大小根据配置文件的配置项可以根据自己的需求更改
在每次启动时手动执行启动命令既麻烦又不便于管理。为此,我们可以通过 Systemd 配置一个服务,使 Pika 开机自启并便于系统控制,提升管理效率。
配置启动服务
-
创建 Pika 系统用户
为了提高安全性,创建一个专用的系统用户和用户组来运行 Pika(在/usr/local/pika下执行):
sudo groupadd --system pika sudo useradd -M -s /sbin/nologin -g pika -d /usr/local/pika pika -
设置文件拥有者
chown -R pika:pika output -
配置 Pika 作为 Systemd 服务
在
/usr/lib/systemd/system目录下创建pika.service文件:cat > /usr/lib/systemd/system/pika.service <<EOF[Unit] Description=pika server Requires=network.target After=network.target[Service] User=pika Group=pika Type=forking WorkingDirectory=/usr/local/pika/output ExecStart=/usr/local/pika/output/bin/pika -c /usr/local/pika/output/conf/pika.conf Restart=always[Install] WantedBy=multi-user.target EOF确保
WorkingDirectory路径是有效的目录,并且已经在系统中正确创建。根据您之前的路径配置,将WorkingDirectory修改为实际存在的路径,例如:WorkingDirectory=/usr/local/pika/pika-v4.0.1
ExecStart=/usr/local/pika/pika-v4.0.1-alpha/output/pika -c /usr/local/pika/pika-v4.0.1-alpha/conf/pika.conf -
增加文件描述符限制
为确保高并发场景下的稳定性,增加文件描述符的限制:
-
创建
pika.service.d目录:sudo mkdir -p /etc/systemd/system/pika.service.d -
在该目录下创建
limit.conf文件:sudo cat > /etc/systemd/system/pika.service.d/limit.conf <<EOF [Service] LimitNOFILE=65536 EOF
-
启动和管理 Pika 服务
完成配置后,可以使用以下命令来管理 Pika:
# 重新加载 systemd 配置文件 sudo systemctl daemon-reload # 启动 Pika 服务 sudo systemctl start pika# 设置 Pika 开机启动 sudo systemctl enable pika # 检查服务状态 sudo systemctl status pika
通过以上步骤,Pika 已成功安装并配置为 systemd 服务,支持自动启动、停止和重启管理,方便在生产环境中使用。这样不仅简化了管理,还提高了服务的稳定性。
注意事项
在安装和配置 Pika 后,以下几点是需要特别注意的,以便更好地理解 Pika 的使用场景和性能表现:
-
线程模型
Pika 是多线程设计,不同于 Redis 的单线程模型,这使得 Pika 能在大多数多核 CPU 环境下有效地处理更多的并发请求。这种设计更适合于大量数据的场景,尤其是在持久化存储需求强烈的场合。 -
适用场景
- 大数据、高容量场景:Pika 在大数据和持久化存储的场景下更具优势。例如,当 Redis 内存超出 16GB 后可能出现瓶颈,Pika 则通过将数据存储在磁盘上而不依赖于内存,有效解决了存储容量的限制问题。
- 写密集型操作:在写密集型操作时,Pika 的多线程设计使其在高并发写入场景中表现更优。
-
性能限制
虽然 Pika 在某些场景下优于 Redis,但它并非在所有情况下都优于 Redis,也不能完全取代 Redis。在高性能内存操作和极低延迟需求的场景下,例如高速缓存、实时性极高的操作,Redis 的内存操作速度更具优势。 -
主从同步和故障恢复
Pika 支持通过slaveof命令配置主从关系,但其同步机制依赖于磁盘 I/O,可能会导致与 Redis 相比稍微较慢的同步速度。对于高频数据变更或对数据实时性要求较高的场景,可能仍需要 Redis 提供更快的响应。 -
存储开销
因为 Pika 依赖磁盘存储,所以需要保证存储空间充足并定期清理过期数据。过大的数据集可能会导致磁盘 I/O 增加,从而对系统的整体性能产生影响。 -
选择依据
Pika 并不是 Redis 的完全替代品。在决定使用 Pika 或 Redis 时,最好结合业务场景:如果数据量较小且关注内存操作的速度,Redis 更合适;而在持久化需求高、数据量大或关注磁盘存储扩展性的场景下,Pika 更适用。
最后
Pika 作为一种兼容 Redis 协议的高效存储引擎,在大数据和持久化存储需求的业务场景中,为 Redis 用户提供了一个强有力的补充方案。Pika 通过将数据存储在磁盘上,有效突破了 Redis 在内存容量上的限制,同时保持了 Redis 的高效操作体验和简便的管理特性。得益于多线程设计,Pika 能在写密集和大容量场景中表现优异,尤其适合那些对数据持久化、扩展性要求较高的场合。
然而,Pika 并非 Redis 的完全替代品。在需要极低延迟、以缓存为核心的场景中,Redis 仍然具备不可替代的优势。因此,选择 Pika 或 Redis 需要结合具体的业务需求,权衡各自的优缺点。总体而言,Pika 在特定的应用场景下能够发挥重要作用,是 Redis 在大数据场景中的有益补充。希望通过本次配置和使用指南,大家能够更好地理解 Pika 的特性和适用性,为项目需求提供更高效的解决方案。
相关文章:
Redis 性能优化选择:Pika 的配置与使用详解
引言 在我们日常开发中 redis是我们开发业务场景中不可缺少的部分。Redis 凭借其内存存储和快速响应的特点,广泛应用于缓存、消息队列等各种业务场景。然而,随着数据量的不断增长,单节点的 Redis 因为内存限制和并发能力的局限,逐…...

【某农业大学计算机网络实验报告】实验三 IP数据报发送和转发流程
实验目的: (1)掌握基本的网络配置方法。 (2)观察 IP 数据报的发送和转发流程,掌握 IP 转发分组的原理。 实验器材: 一台Windows操作系统的PC机。 实验准备: 1.配置…...

Android13 添加运行时权限
在一些场景下,需要给app 添加运行时权限,这样就不需要在使用的时候再去点击授权。 直接上代码: --- a/services/core/java/com/android/server/pm/permission/DefaultPermissionGrantPolicy.javab/services/core/java/com/android/server/pm…...

官方操刀占用仅6G,Win 11 LTSC详细安装、优化教程来了
前段时间微软发布 Win 11 年度重磅更新 24H2,顺便也带来了备受期待的 Win 11 2024 官方精简 LTSC(老坛酸菜)版。 Win 11 重磅更新发布,老坛酸菜版成了配角! 简单来说,Win 11 LTSC 是微软针对企业用户推出…...
【论文精读】RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning
RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning 前言AbstractMotivationSolutionRELIEFIncorporating Feature Prompts as MDPAction SpaceState TransitionReward Function Policy Network ArchitectureDiscrete ActorContinuous ActorCritic Overall…...

2023-06 GESP C++三级试卷
2023-06 GESP C三级试卷 (满分:100 分 考试时间:90 分钟) PDF试卷及答案回复:GESPC2023063 一、单选题(每题 2 分,共 30 分) 1 高级语言编写的程序需要经过以下( )操…...

Maven--简略
简介 Apache旗下的一款开源项目,用来进行项目构建,帮助开发者管理项目中的jar及jar包之间的依赖,还拥有项目编译、测试、打包的功能。 管理方式 统一建立一个jar仓库,把jar上传至统一的仓库,使用时,配置…...
)
leetcode 刷题day44动态规划Part13( 647. 回文子串、516.最长回文子序列)
647. 回文子串 动规五部曲: 1、确定dp数组(dp table)以及下标的含义 按照之前做题的惯性,定义dp数组的时候很自然就会想题目求什么,就如何定义dp数组。但是对于本题来说,这样定义很难得到递推关系&#x…...

华为OD机试真题---关联子串
华为OD机试中的“关联子串”题目是一个考察字符串处理和算法理解的经典问题。以下是对该题目的详细解析: 一、题目描述 给定两个字符串str1 和 str2,如果字符串 str1 中的字符, 经过排列组合后的字符串中只要有一个是 str2 的子串ÿ…...

【OpenAI】第二节(Token)什么是Token?如何计算ChatGPT的Token?
深入解析:GPT如何计算Token数?让你轻松掌握自然语言处理的核心概念!🚀 在当今的人工智能领域,GPT(Generative Pre-trained Transformer)无疑是最受关注的技术之一。无论是在文本生成、对话系统…...

GraphRAG + Ollama + Groq 构建知识库 续篇 利用neo4j显示知识库
GraphRAG Ollama Groq 构建知识库 在上一篇文章中,我们详细介绍了如何创建一个知识库。尽管知识库已经建立,但其内容的可视化展示尚未实现。我们无法直接看到知识库中的数据,也就无法判断这些数据是否符合我们的预期。为了解决这个问题&…...

工业以太网之战:EtherCAT是如何杀出重围的?
前言 EtherCAT 是一种开放的实时工业以太网协议,由德国倍福公司开发并在 2003 年 4 月的汉诺威工业博览会上首次亮相,目前由 EtherCAT 技术协会(ETG)进行维护和推广。经过 21 年的不断发展,EtherCAT 显示出极强的生命…...
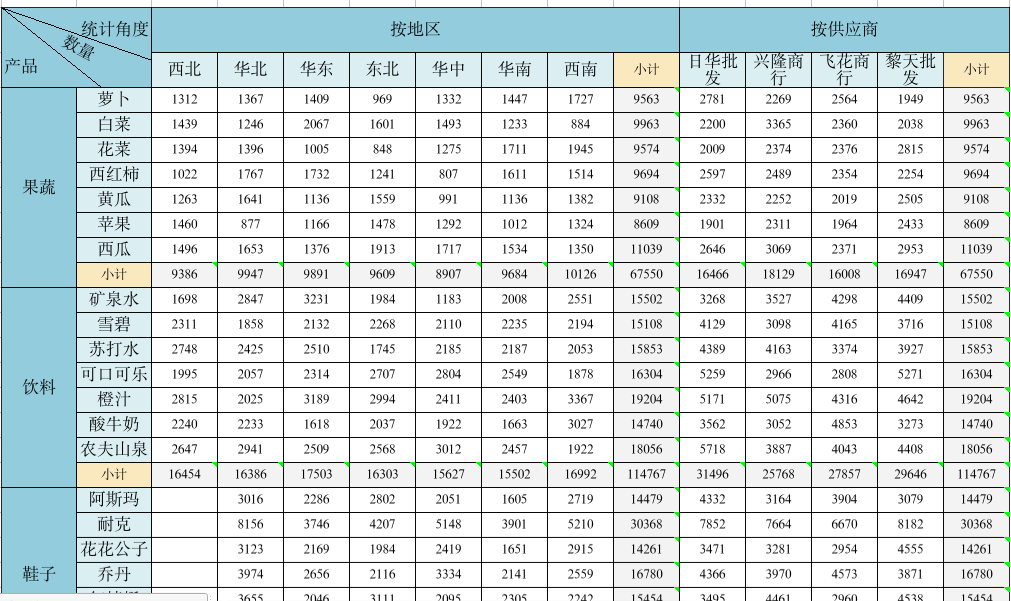
轻量级可视化数据分析报表,分组汇总表!
什么是可视化分组汇总表? 可视化分组汇总表,是一种结合了数据分组、聚合计算与视觉呈现功能的数据分析展示功能。它能够按照指定的维度(如时间、地区、产品类型等)对数据进行分组,还能自动计算各组的统计指标…...

初始Python篇(4)—— 元组、字典
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: Python 目录 元组 相关概念 元组的创建与删除 元组的遍历 元组生成式 字典 相关概念 字典的创建与删除 字典的遍历与访问 字典…...

C#中正则表达式
在C#中,正则表达式由 System.Text.RegularExpressions 命名空间提供,可以使用 Regex 类来处理正则表达式。以下是一些常见的用法及示例。 C# 中使用正则表达式的步骤: 引入命名空间: using System.Text.RegularExpressions; 创…...

【python写一个带有界面的计算器】
python写一个带有界面的计算器 为了创建一个带有图形用户界面(GUI)的计算器,我们可以使用Python的tkinter库。tkinter是Python的标准GUI库,它允许我们创建窗口、按钮、文本框等GUI元素。 下面是一个简单的带有GUI的计算器示例&a…...

K230获取单摄像头的 3 个通道图像并显示在 HDMI 显示器上
本示例打开摄像头,获取 3 个通道的图像并显示在 HDMI 显示器上。通道 0 采集 1080P 图像,通道 1 和通道 2 采集 VGA 分辨率的图像并叠加在通道 0 的图像上。 # Camera 示例 import time import os import sysfrom media.sensor import * from media.dis…...
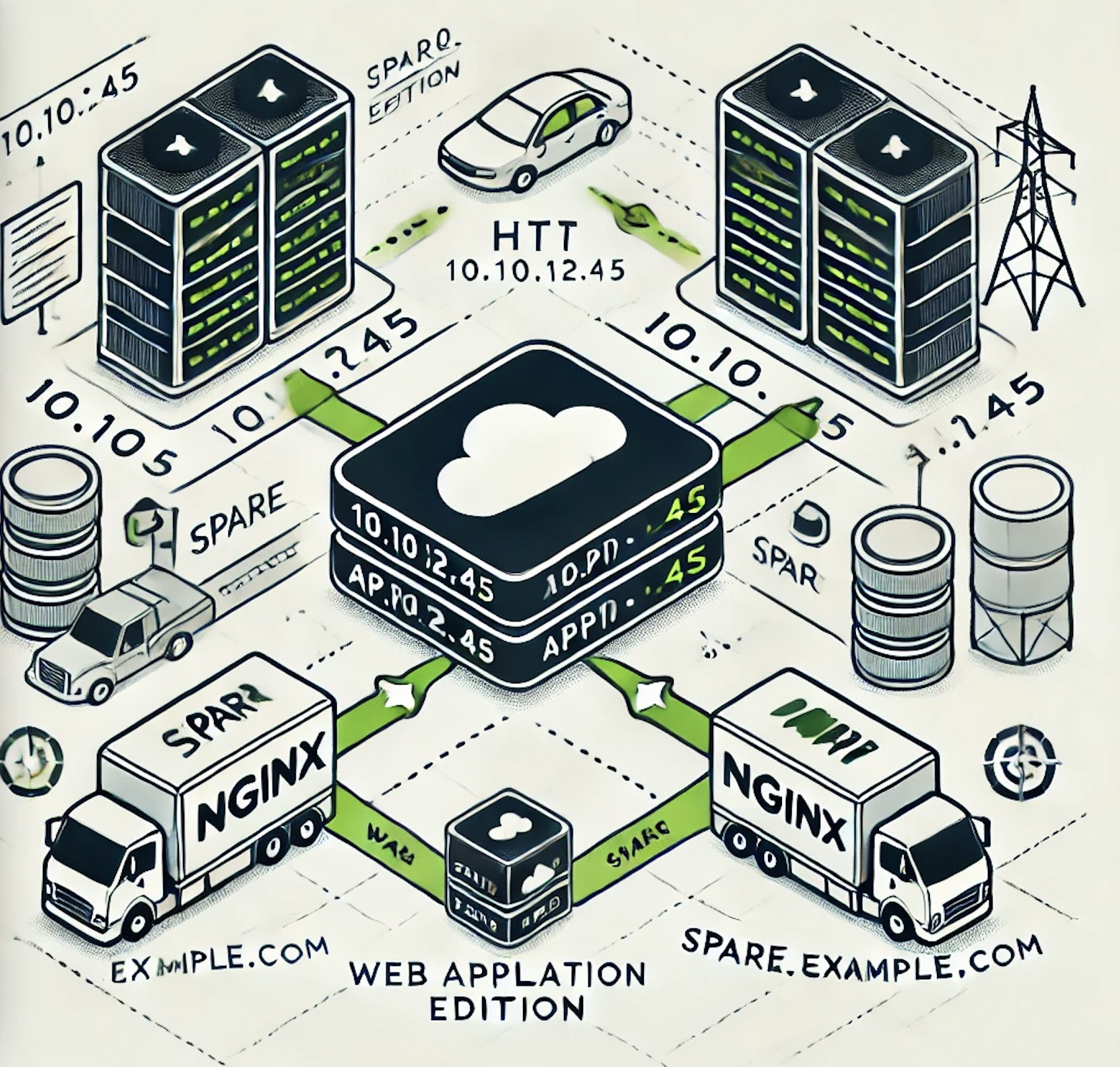
nginx中的HTTP 负载均衡
HTTP 负载均衡:如何实现多台服务器的高效分发 为了让流量均匀分配到两台或多台 HTTP 服务器上,我们可以通过 NGINX 的 upstream 代码块实现负载均衡。 方法 在 NGINX 的 HTTP 模块内使用 upstream 代码块对 HTTP 服务器实施负载均衡: upstr…...

package.json 里的 dependencies和devDependencies区别
dependencies(依赖的意思): 通过 --save 安装,是需要发布到生产环境的。 比如项目中使用react,那么没有这个包的依赖就会报错,因此把依赖写入dependencies npm install <package-name>// 缩写 np…...
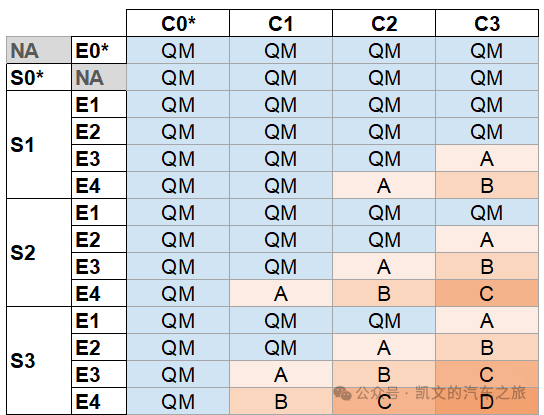
【功能安全】HARA分析中的SEC如何确认
目录 01 SEC介绍 02 SEC怎么定义 📖 推荐阅读 01 SEC介绍 SEC定义 S代表safety,E指的是Exposure,C指的是Controllability ASIL等级就是基于SEC三个参数确定下来的。 计算公式:10=D,9=C,8=B,7=A,<7=QM 举例:S3-C2-E4,即3+2+4=9,ASIL C 02 SEC怎么定义 Safe…...

RK3588 LGA核心板:高性能嵌入式开发的模块化解决方案
1. 项目概述:当旗舰SoC遇见极致封装最近在嵌入式圈子里,一个“小而强”的组合引起了我的注意:瑞芯微的旗舰级SoC RK3588,被塞进了一个极其紧凑的LGA封装里,做成了名为SOM-3588-LGA的核心板,并且已经现货发售…...

NVDC充电架构深度解析:智能电源管理如何提升笔记本性能与电池寿命
1. 项目概述:NVDC充电器,一个被低估的“能量管家”如果你是一位经常需要带着笔记本电脑移动办公的资深用户,或者是一位对设备续航和充电效率有极致追求的硬件爱好者,那么“NVDC”这个词,很可能已经或即将进入你的视野。…...

解决Claude Code频繁封号与Token不足问题转向Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足问题转向Taotoken 对于依赖Claude Code作为日常编程助手的开发者而言,服务中断是影…...

NCMconverter终极指南:3步轻松解密NCM音频,实现全平台播放自由 [特殊字符]
NCMconverter终极指南:3步轻松解密NCM音频,实现全平台播放自由 🎵 【免费下载链接】NCMconverter NCMconverter将ncm文件转换为mp3或者flac文件 项目地址: https://gitcode.com/gh_mirrors/nc/NCMconverter 你是否遇到过从音乐平台下载…...

ESP32-C3深度睡眠唤醒踩坑记:GPIO0~5始终低电平?手把手教你用Arduino框架正确配置RTC GPIO
ESP32-C3深度睡眠唤醒实战指南:破解GPIO0~5低电平陷阱 凌晨三点的调试灯依然亮着,这是我本周第三次被ESP32-C3的深度睡眠唤醒问题折磨到深夜。作为一款主打低功耗的物联网芯片,ESP32-C3的深度睡眠模式本该是电池供电设备的福音,但…...

基于金橙子MarkEzd.dll的激光打标二次开发实战:从函数解析到自动化标刻系统构建
1. 金橙子MarkEzd.dll开发入门指南 第一次接触激光打标二次开发的朋友可能会被各种专业术语吓到,但其实只要掌握几个核心概念就能快速上手。MarkEzd.dll是北京金橙子科技为EZCAD2激光打标软件提供的开发接口,相当于给开发者开了一个"后门"&…...

探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界
探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界 【免费下载链接】nvme-cli NVMe management command line interface. 项目地址: https://gitcode.com/gh_mirrors/nv/nvme-cli NVMe-CLI作为现代NVMe固态存储设备的核心管理工具,在v2.…...

Windows安卓应用安装器:5步实现电脑直接运行APK应用
Windows安卓应用安装器:5步实现电脑直接运行APK应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过,如果能在Windows电脑上直接运…...
)
解密冰蝎和蚁剑:在CTF流量分析中如何识别和还原WebShell攻击(含AES/Base64解密实操)
解密冰蝎与蚁剑:CTF流量分析中的WebShell识别与解密实战 在CTF竞赛和安全分析领域,WebShell流量分析一直是让许多选手头疼的高阶挑战。特别是当面对冰蝎(Behinder)、蚁剑(AntSword)这类采用强加密通信的Web…...

HS2-HF_Patch汉化补丁:3分钟打造完美中文游戏体验
HS2-HF_Patch汉化补丁:3分钟打造完美中文游戏体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗…...