【LangChain系列2】【Model I/O详解】
目录
- 前言
- 一、LangChain
- 1-1、介绍
- 1-2、LangChain抽象出来的核心模块
- 1-3、特点
- 1-4、langchain解决的一些行业痛点
- 1-5、安装
- 二、Model I/O模块
- 2-0、Model I/O模块概要
- 2-1、Format(Prompts Template)
- 2-1-1、Few-shot prompt templates
- 2-1-2、Chat模型的少样本示例
- 2-1-3、部分提示模板partial
- 2-1-4、多个提示的组合
- 2-1-5、序列化(存储提示词)
- 2-1-6、例子选择器
- 2-1-7、连接特征存储
- 2-2、Predict(LLM调用,以Chat 模型为主)
- 2-2-1、概要
- 2-2-2、MessagePromptTemplate
- 2-2-3、Caching
- 2-2-4、流式响应
- 2-3、Parse(Output解析)
- 2-3-1、列表解析器
- 2-3-2、datetime
- 2-3-3、枚举解析器
- 附录
- 1、开源特征存储框架Feast
- 1-1、定义&核心功能
- 1-2、优势
- 1-3、如何使用?
- 总结
前言
LangChain给自身的定位是:用于开发由大语言模型支持的应用程序的框架。它的做法是:通过提供标准化且丰富的模块抽象,构建大语言模型的输入输入规范,利用其核心概念chains,灵活地连接整个应用开发流程。 这里是LangChain系列的第二篇,主要介绍Model I/O模块(标准化LLM的输入输出)。
一、LangChain
1-1、介绍
LangChain是一个框架,用于开发由大型语言模型(LLM)驱动的应用程序。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
- 开发:使用LangChain的开源构建块和组件构建应用程序。使用第三方集成和模板开始运行。
- 生产化:使用 LangSmith 检查、监控和评估您的链条,以便您可以自信地持续优化和部署。
- 部署:使用 LangServe 将任何链转换为 API。
总结: LangChain是一个用于开发由LLM支持的应用程序的框架,通过提供标准化且丰富的模块抽象,构建LLM的输入输出规范,主要是利用其核心概念chains,可以灵活地链接整个应用开发流程。(即,其中的每个模块抽象,都是源于对大模型的深入理解和实践经验,由许多开发者提供出来的标准化流程和解决方案的抽象,再通过灵活的模块化组合,才得到了langchain)

1-2、LangChain抽象出来的核心模块
想象一下,如果要组织一个AI应用,开发者一般需要?
- 提示词模板的构建,不仅仅只包含用户输入!
- 模型调用与返回,参数设置,返回内容的格式化输出。
- 知识库查询,这里会包含文档加载,切割,以及转化为词嵌入(Embedding)向量。
- 其他第三方工具调用,一般包含天气查询、Google搜索、一些自定义的接口能力调用。
- 记忆获取,每一个对话都有上下文,在开启对话之前总得获取到之前的上下文吧?
由上边的内容,引出LangChain抽象的一些核心模块:
LangChain通过模块化的方式去高级抽象LLM在不同场景下的能力,其中LangChain抽象出的最重要的核心模块如下:‘
- Model I/O :标准化各个大模型的输入和输出,包含输入模版,模型本身和格式化输出;
- Retrieval :检索外部数据,然后在执行生成步骤时将其传递到 LLM,包括文档加载、切割、Embedding等;
- Chains :链条,LangChain框架中最重要的模块,链接多个模块协同构建应用,是实际运作很多功能的高级抽象;
- Memory : 记忆模块,以各种方式构建历史信息,维护有关实体及其关系的信息;
- Agents : 目前最热门的Agents开发实践,未来能够真正实现通用人工智能的落地方案;
- Callbacks :回调系统,允许连接到 LLM 应用程序的各个阶段。用于日志记录、监控、流传输和其他任务;
1-3、特点
LangChain的特点如下:
-
大语言模型(llm): LangChain为自然语言处理提供了不同类型的模型,这些模型可用于处理非结构化文本数据,并且可以基于用户的查询检索信息
-
PromptTemplates: 这个特征使开发人员能够使用多个组件为他们的模型构造输入提示。在查询时,开发人员可以使用PromptTemplates为用户查询构造提示模板,之后模板会传递到大模型进行进一步的处理。
-
链:在LangChain中,链是一系列模型,它们被连接在一起以完成一个特定的目标。聊天机器人应用程序的链实例可能涉及使用LLM来理解用户输入,使用内存组件来存储过去的交互,以及使用决策组件来创建相关响应。
-
agent: LangChain中的agent与用户输入进行交互,并使用不同的模型进行处理。Agent决定采取何种行动以及以何种顺序来执行行动。例如,CSV Agent可用于从CSV文件加载数据并执行查询,而Pandas Agent可用于从Pandas数据帧加载数据并处理用户查询。可以将代理链接在一起以构建更复杂的应用程序。

1-4、langchain解决的一些行业痛点
在使用大模型的过程中,一些行业痛点:
- 大模型的使用规范以及基于大模型的开发范式不尽相同,当使用一个新模型时,我们往往需要学习新的模型规范。
- 大模型知识更新的滞后性
- 大模型的外部API调用能力
- 大模型输出的不稳定问题,如何稳定输出?
- 大模型与私有化数据的连接方式?
1-5、安装
pip install langchain
二、Model I/O模块
前情概要:
LangChain 提供的 LangChain Expression Language(LCEL) 让开发可以很方便地将多个组件连接成 AI 工作流。如下是一个简单的工作流:
chain = prompt | chatmodel | outputparser
chain.invoke({"input":"What's your name?")
其中,通过由|管道操作符连接而成的 LangChain 表达式,我们方便地将三个组件 prompt chatmodel outparser 按顺序连接起来,这就形成了一个 AI 工作流。 invoke()则是实际运行这个工作流。
而,LangChain 的 Model I/O 模块是与语言模型(LLMs)进行交互的核心组件,它包括模型输入(Prompts)、模型输出(Output Parsers)和模型本身(Models)。
2-0、Model I/O模块概要
在LangChain的Model I/O模块设计中,包含三个核心部分: Prompt Template(对应下图中的Format部分), Model(对应下图中的Predict部分) 和Output Parser(对应下图中的Parse部分)。
- Format:即指代Prompts Template,通过模板化来管理大模型的输入;
- Predict:即指代Models,使用通用接口调用不同的大语言模型;
- Parse:即指代Output部分,用来从模型的推理中提取信息,并按照预先设定好的模版来规范化输出。

后续将介绍两种不同类型的模型——基础LLM和Chat LLM。然后介绍如何使用Prompt Templates格式化这些模型的输入,以及如何使用Output parser处理输出。
Base LLM
- LangChain中的llm指的是纯文本补全模型(text completion)。它们包装的api接受字符串提示符作为输入,输出字符串补全。
Chat LLM
- Chat LLM通常由Base LLM支撑,但专门针对对话进行了调整。并且使用与Base LLM不同的调用接口。将聊天消息列表作为输入,得到Response 类型,而并不仅仅是字符串。
2-1、Format(Prompts Template)
一般来说:我们创建提示词模板主要是通过手动编写实现的,并且需要利用各种提示词工程技巧,如Few-Shot,Cot等。而固定的提示词只会限制模型的灵活性和适用范围。 那么怎么让Prompts Template变得更灵活呢?
2-1-1、Few-shot prompt templates
Few-shot prompt templates: 少样本示例提示模板
- 创建少量示例的列表,每个示例是一个字典,即输入变量&输出变量。
- 配置一个将少量示例格式化为字符串的格式化程序。该格式化程序应该是一个 PromptTemplate 对象。
- 最后,创建一个 FewShotPromptTemplate 对象。该对象接受少量示例和少量示例的格式化程序。
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplateexamples = [{"question": "Who lived longer, Muhammad Ali or Alan Turing?","answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""},{"question": "When was the founder of craigslist born?","answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""},{"question": "Who was the maternal grandfather of George Washington?","answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""},{"question": "Are both the directors of Jaws and Casino Royale from the same country?","answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""}
]example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
# 这里输出的是第一个范例prompt = FewShotPromptTemplate(examples=examples, example_prompt=example_prompt, suffix="Question: {input}", input_variables=["input"]
)
print(prompt.format(input="Who was the father of Mary Ball Washington?"))
输出: 得到的就是我们的范例+最后的问题模板啦!

2-1-2、Chat模型的少样本示例
Demo1: 使用Ai&Human Message交替形成历史记录
ChatPromptTemplate: 是 LangChain 库中用于生成与语言模型进行对话式交互提示的类。它特别适合于需要考虑上下文连续性和历史对话信息的场景,如构建聊天机器人或处理连续的文本交互任务。主要方法介绍如下:
- from_messages:从多种消息格式中创建聊天提示模板,使用不同的类, 包含SystemMessagePromptTemplate、HumanMessagePromptTemplate 和 AIMessagePromptTemplate,即系统提示词、人类提示词以及AI回复。
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (ChatPromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,
)
from langchain.schema import AIMessage, HumanMessage, SystemMessageos.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,
)template = "You are a helpful assistant that translates english to pirate."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
example_human = HumanMessagePromptTemplate.from_template("Hi")
example_ai = AIMessagePromptTemplate.from_template("Argh me mateys")
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, example_human, example_ai, human_message_prompt]
)
chain = LLMChain(llm=chat, prompt=chat_prompt)
# get a chat completion from the formatted messages
chain.run("I love programming.")
输出:
“Arr, me hearties, I be a landlubber who be lovin’ the art o’ code!”
2-1-3、部分提示模板partial
部分提示模板 partial: 希望部分填充提示模板的一个常见用例是如果您在获取某些变量之前获得了其他变量。(先固定一些变量,其他变量是用户输入的。)两种方式:
- 使用字符串值进行部分格式化。
- 使用返回字符串值的函数进行部分格式化。
案例: 先传入函数来得到部分变量。
from datetime import datetimedef _get_datetime():now = datetime.now()return now.strftime("%m/%d/%Y, %H:%M:%S")prompt = PromptTemplate(template="Tell me a {adjective} joke about the day {date}", input_variables=["adjective", "date"]
);
partial_prompt = prompt.partial(date=_get_datetime)
print(partial_prompt.format(adjective="funny"))
输出:
Tell me a funny joke about the day 02/27/2023, 22:15:16
或者是直接在初始化中赋予:
prompt = PromptTemplate(template="Tell me a {adjective} joke about the day {date}", input_variables=["adjective"],partial_variables={"date": _get_datetime}
);
print(prompt.format(adjective="funny"))
2-1-4、多个提示的组合
组合: 如何将多个提示组合在一起?可以通过PipelinePrompt来实现。PipelinePrompt由两个主要部分组成:
- 最终提示: 返回的最终提示
- 管道提示: 由一个字符串名称和一个提示模板组成的元组列表。每个提示模板将被格式化,然后作为相同名称的变量传递给未来的提示模板。
PipelinePromptTemplate: 是 LangChain 中用于组合多个提示模板一起使用的高级工具。它特别适用于需要将多个步骤或组件组合在一起以实现更复杂任务的场景,例如数据预处理、模型推理和后处理。使用 PipelinePromptTemplate 时,你可以定义一个最终提示(final prompt)和一系列管道提示(pipeline prompts)。每个管道提示都会被格式化,然后作为变量传递给后续的提示模板。这种方式允许你重用提示模板的各个部分,并且可以构建复杂的提示流程。实施步骤如下:
- 定义最终提示:这是返回的最终提示模板,可以是一个 PromptTemplate 实例。
- 定义管道提示:这是一系列元组,每个元组包含一个字符串名称和一个提示模板。每个提示模板将被格式化,然后作为变量传递给后续的提示模板。
- 创建 PipelinePromptTemplate 实例:使用最终提示和管道提示列表创建 PipelinePromptTemplate 的实例。
- 格式化和调用:使用输入变量格式化管道提示,然后调用最终提示模板。
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplatefull_template = """{introduction}{example}{start}"""
full_prompt = PromptTemplate.from_template(full_template)introduction_template = """You are impersonating {person}."""
introduction_prompt = PromptTemplate.from_template(introduction_template)example_template = """Here's an example of an interaction: Q: {example_q}
A: {example_a}"""
example_prompt = PromptTemplate.from_template(example_template)start_template = """Now, do this for real!Q: {input}
A:"""
start_prompt = PromptTemplate.from_template(start_template)input_prompts = [("introduction", introduction_prompt),("example", example_prompt),("start", start_prompt)
]
pipeline_prompt = PipelinePromptTemplate(final_prompt=full_prompt, pipeline_prompts=input_prompts)pipeline_prompt.input_variables
输出: 构建好的管道提示词所需要的输入变量如下:
[‘input’, ‘example_q’, ‘example_a’, ‘person’]
print(pipeline_prompt.format(person="Elon Musk",example_q="What's your favorite car?",example_a="Telsa",input="What's your favorite social media site?"
))
输出:
You are impersonating Elon Musk.
Here’s an example of an interaction:
Q: What’s your favorite car?
A: Telsa
Now, do this for real!
Q: What’s your favorite social media site?
A:
2-1-5、序列化(存储提示词)
序列化(存储提示词): 通常最好将提示存储为文件而不是Python代码。这样可以方便地共享、存储和版本化提示。
以下为从JSON中加载的代码:
# 所有的提示都通过`load_prompt`函数加载。
from langchain.prompts import load_promptprompt = load_prompt("simple_prompt.json")
print(prompt.format(adjective="funny", content="chickens"))
simple_prompt.json
{"_type": "prompt","input_variables": ["adjective", "content"],"template": "Tell me a {adjective} joke about {content}."}
2-1-6、例子选择器
主要内容:自定义示例选择器,以及采用不同算法来根据示例与输入之间的相似度、多样性来选择示例。
待后续补充。
2-1-7、连接特征存储
开源的特征存储框架: feast,详细介绍见附录
2-2、Predict(LLM调用,以Chat 模型为主)
2-2-1、概要
1、模型设置: 这里我们依旧使用智谱AI来设置模型
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
import osos.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,
)
2、Messages: LangChain 目前支持的消息类型有“AIMessage”,“HumanMessage”,“SystemMessage”和“ChatMessage”
messages = [# AIMessage(content="Hi."),# SystemMessage(content="你是一个数学家,只会回答数学问题."),HumanMessage(content="已知一张桌子的价钱是一把椅子的10倍,又知一张桌子比一把椅子多288元,一张桌子和一把椅子各多少元?"),
]
response = chat.invoke(messages)
print(response.content)
输出:
设一把椅子的价格为x元,那么根据题目中的信息,一张桌子的价格就是10x元。
题目还告诉我们,一张桌子比一把椅子多288元,所以我们可以建立以下等式:
10x - x = 288
这个等式表示桌子的价格减去椅子的价格等于288元。接下来,我们解这个方程:
9x = 288
为了找到x的值,我们将两边都除以9:
x = 288 / 9
x = 32
所以,一把椅子的价格是32元。现在我们可以计算出桌子的价格:
桌子的价格 = 10 * x = 10 * 32 = 320元
综上所述,一张桌子的价格是320元,一把椅子的价格是32元。
查看完整输出:
chat(messages)
输出:

3、generate: 多组提示
batch_messages = [[SystemMessage(content="You are a helpful assistant that translates English to French."),HumanMessage(content="I love programming.")],[SystemMessage(content="You are a helpful assistant that translates English to French."),HumanMessage(content="I love artificial intelligence.")],
]
chat.generate(batch_messages)
输出:

2-2-2、MessagePromptTemplate
MessagePromptTemplate: 如何从一个或多个 MessagePromptTemplates 构建一个 ChatPromptTemplate。
- ChatPromptTemplate 的 format_prompt 方法:这将返回一个 PromptValue,您可以将其转换为字符串或消息对象。
from langchain import PromptTemplate
from langchain.prompts.chat import (ChatPromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,
)template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
输出:

2-2-3、Caching
Caching: 它可以通过减少对LLM提供者的API调用次数来节省费用,如果您经常多次请求相同的完成。 它可以通过减少对LLM提供者的API调用次数来加快应用程序的速度。
from langchain.cache import InMemoryCache
import langchain
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
import osos.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,
)langchain.llm_cache = InMemoryCache()# The first time, it is not yet in cache, so it should take longer
# 二次调用时速度加快很多。
chat.predict("Tell me a farker")
SQLlite缓存:
# We can do the same thing with a SQLite cache
from langchain.cache import SQLiteCachelangchain.llm_cache = SQLiteCache(database_path=".langchain.db")# The first time, it is not yet in cache, so it should take longer
chat.predict("Tell me a joke")
2-2-4、流式响应
Stream: 一些聊天模型提供流式响应。这意味着你可以在整个响应返回之前就开始处理它,而不是等待整个响应返回。如果你想要在生成响应时将其显示给用户,或者在生成响应时处理响应,这将非常有用。
from langchain.chat_models import ChatOpenAI
from langchain.schema import (HumanMessage,
)from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandlerfrom langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
import osos.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,streaming=True, callbacks=[StreamingStdOutCallbackHandler()]
)
resp = chat([HumanMessage(content="Write me a song about sparkling water.")])
输出:

2-3、Parse(Output解析)
2-3-1、列表解析器
列表解析器:
- CommaSeparatedListOutputParser: 将输出解析为逗号分割列表的类。
- get_format_instructions(): 获取列表解析的格式化指令,得到的最终,即format_instructions 为:‘Your response should be a list of comma separated values, eg:
foo, bar, bazorfoo,bar,baz’ - PromptTemplate: 用于构建提示词模板,参数详细介绍(template:定义提示词模板的字符串,其中包含文本和变量占位符;input_variables: 列表,指定了模板中可以使用的变量名称,在调用模板时被替换;partial_variables:字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换。)
- format:传入模板中的变量名。
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAIoutput_parser = CommaSeparatedListOutputParser()format_instructions = output_parser.get_format_instructions()prompt = PromptTemplate(template="List five {subject}.\n{format_instructions}",input_variables=["subject"],partial_variables={"format_instructions": format_instructions}
)os.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,
)_input = prompt.format(subject="ice cream flavors")
output = chat.invoke(_input)
output_parser.parse(output.content)
输出:
[‘Vanilla’, ‘Chocolate’, ‘Strawberry’, ‘Mint Chocolate Chip’, ‘Rocky Road’]
2-3-2、datetime
日期解析器:
- DatetimeOutputParser: 日期解析类。
- get_format_instructions(): 获取日期解析的格式化指令,指令为:
“Write a datetime string that matches the following pattern: ‘%Y-%m-%dT%H:%M:%S.%fZ’.\n\nExamples: 1206-08-16T17:39:06.176399Z, 1151-09-19T07:15:29.949318Z, 0546-08-24T23:43:17.193459Z\n\nReturn ONLY this string, no other words!”
- LLMChain: 代表了与LLM交互的链,这个链通常包括一个提示模板(PromptTemplate),一个语言模型(LLM),以及一个输出解析器(OutputParser)。LLMChain 的目的是将这些组件组合起来,以便可以轻松地生成和处理语言模型的输出。(这里直接传入OutputParser会报错,所以先在构建提示模板时,插入格式化指令)
- run:接受输入,通过提示词模板生成提示,将其传递给LLM并且得到结果。
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAIoutput_parser = DatetimeOutputParser()
template = """Answer the users question:{question}{format_instructions}"""
prompt = PromptTemplate.from_template(template,partial_variables={"format_instructions": output_parser.get_format_instructions()},
)os.environ["ZHIPUAI_API_KEY"] = ""
chat = ChatZhipuAI(model="glm-4",temperature=0.5,
)chain = LLMChain(prompt=prompt, llm=chat)
output = chain.run("around when was bitcoin founded?")
output
输出:
‘2009-01-03T00:00:00.000000Z’
2-3-3、枚举解析器
枚举解析器: 将LLM的输出,解析为预定义的枚举值。操作步骤如下:
- 枚举定义:首先需要定义一个枚举类,该类继承自Python的Enum类。
- 创建解析器实例:使用定义的枚举类来创建实例。
- 解析输出:调用parse方法,传入模型的输出字符串,解析器会将其匹配到枚举类中的一个值。
from langchain.output_parsers.enum import EnumOutputParserfrom enum import Enumclass Colors(Enum):RED = "red"GREEN = "green"BLUE = "blue"parser = EnumOutputParser(enum=Colors)
parser.parse("red")# Can handle spaces
parser.parse(" green")# And new lines
parser.parse("blue\n")
输出:
<Colors.BLUE: ‘blue’>
附录
1、开源特征存储框架Feast
1-1、定义&核心功能
Feast 是一个开源的特征存储框架,专门为机器学习而设计。它允许组织存储和一致性地提供特征,以支持离线训练和在线推理。Feast 的主要目标是帮助数据科学家和机器学习工程师更高效地管理和使用特征数据,从而加速机器学习模型的开发和部署过程。
Feast 的核心功能包括:
- 特征定义和管理:Feast 允许用户通过 Python API 或 YAML 文件定义特征。用户可以指定特征的名称、类型、数据源等元数据信息。这些定义被存储在一个中央注册表中,方便团队成员查看和重用
。 - 离线存储:Feast 支持多种离线存储选项,如 Snowflake、BigQuery、Redshift 等。这些存储用于处理大规模的历史数据,支持批量评分和模型训练
。 - 在线存储:为了支持低延迟的实时预测,Feast 提供了多种在线存储选项,如 Redis、DynamoDB、Bigtable 等。这些存储可以快速服务预计算的特征值
。 - 特征服务:Feast 提供了 Python、Java 和 Go 版本的特征服务器,可以快速检索在线特征。这使得实时预测变得简单高效
。 - 点时间正确性:Feast 确保在生成训练数据集时不会出现数据泄露,通过生成点时间正确的特征集来实现这一点
。 - 数据源集成:Feast 支持多种数据源,包括批处理源(如 Parquet 文件、SQL 数据库)和流式源(如 Kafka)。这种灵活性使得 Feast 可以适应各种数据基础设施
。
1-2、优势
Feast 的优势:
1、一致性:Feast 确保在模型训练和在线推理过程中使用相同的特征定义和转换逻辑,减少了模型在生产环境中的不一致性。
2、可重用性:通过中央化的特征定义,团队成员可以轻松地重用和共享特征,提高了工作效率。
3、可扩展性:Feast 的架构设计支持大规模数据处理和服务,可以随着机器学习项目的增长而扩展。
4、灵活性:支持多种存储后端和数据源,可以适应不同的技术栈和基础设施需求。
5、开源生态:作为一个活跃的开源项目,Feast 拥有庞大的社区支持和持续的功能更新 。
1-3、如何使用?
如何开始使用 Feast:
1、安装 Feast:通过 pip 安装 Feast。
pip install feast
2、创建特征仓库:使用 feast init 命令初始化一个新的特征仓库。
feast init my_feature_repo
cd my_feature_repo/feature_repo
3、定义特征:编辑 feature_repo.py 文件,定义你的数据源和特征视图。
from feast import Entity, Feature, FeatureView, FileSource, ValueType# 定义数据源
driver_hourly_stats = FileSource(path="/path/to/driver_stats.parquet",event_timestamp_column="event_timestamp",created_timestamp_column="created",
)# 定义实体
driver = Entity(name="driver_id", value_type=ValueType.INT64, description="driver id")# 定义特征视图
driver_hourly_stats_view = FeatureView(name="driver_hourly_stats",entities=["driver_id"],ttl=timedelta(seconds=86400 * 1),features=[Feature(name="conv_rate", dtype=ValueType.FLOAT),Feature(name="acc_rate", dtype=ValueType.FLOAT),Feature(name="avg_daily_trips", dtype=ValueType.INT64),],online=True,batch_source=driver_hourly_stats,tags={},
)
4、部署特征存储:使用 feast apply 命令部署特征存储。
feast apply
5、探索数据:使用 Feast 的 Web UI(实验性)探索数据。
feast ui
6、构建训练数据集:使用 Feast SDK 构建训练数据集。
7、加载特征值:使用 feast materialize-incremental 命令将特征值加载到在线存储中。
CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
feast materialize-incremental $CURRENT_TIME
8、读取在线特征:使用 Feast SDK 读取在线特征,以进行实时预测。
from feast import FeatureStorestore = FeatureStore(repo_path=".")feature_vector = store.get_online_features(features=['driver_hourly_stats:conv_rate','driver_hourly_stats:acc_rate','driver_hourly_stats:avg_daily_trips'],entity_rows=[{"driver_id": 1001}]
).to_dict()print(feature_vector)
参考文章:
langchain_community.utilities.sql_database.SQLDatabase
LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发
LangChain官网
Rebuff: 防止提示词注入检测器
未完成:
Build a Question/Answering system over SQL data
langchain101 AI应用开发指南
ZhiPuAI——API官方文档
总结
人生而自由,却无往不在枷锁之中。
相关文章:
【LangChain系列2】【Model I/O详解】
目录 前言一、LangChain1-1、介绍1-2、LangChain抽象出来的核心模块1-3、特点1-4、langchain解决的一些行业痛点1-5、安装 二、Model I/O模块2-0、Model I/O模块概要2-1、Format(Prompts Template)2-1-1、Few-shot prompt templates2-1-2、Chat模型的少样…...
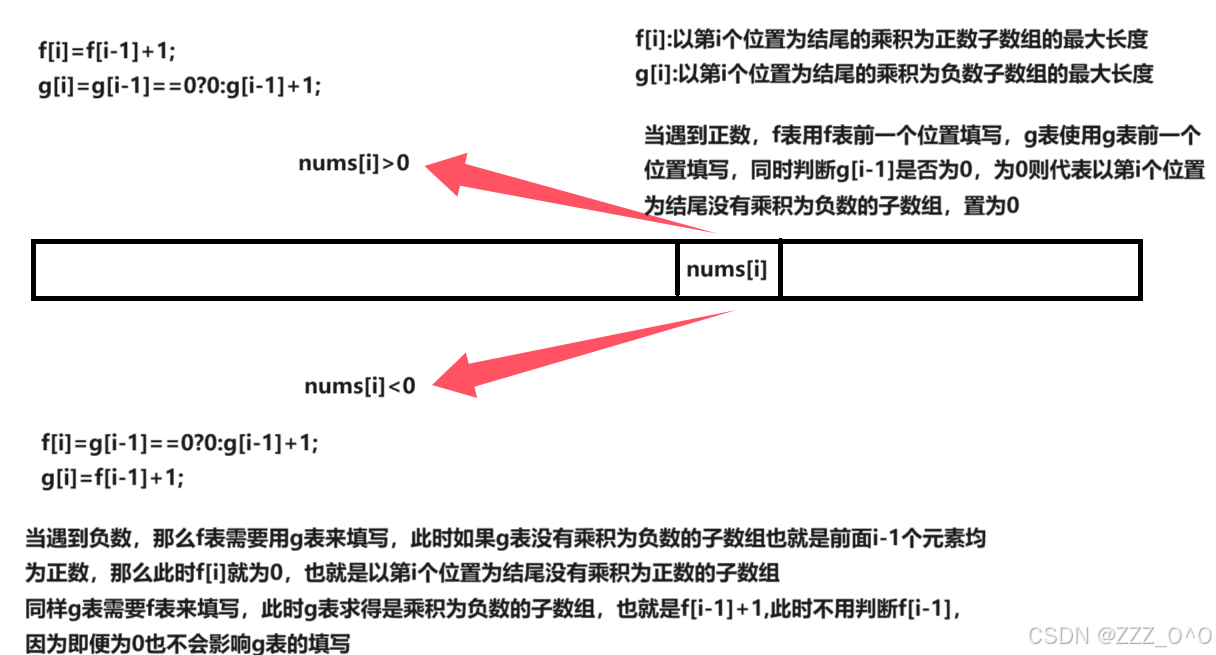
动态规划-子数组系列——1567.乘积为正数的最长子数组
1.题目解析 题目来源:1567.乘积为正数的最长子数组——力扣 测试用例 2.算法原理 1.状态表示 因为数组中存在正数与负数,如果求乘积为正数的最长子数组,那么存在两种情况使得乘积为正数,第一种就是正数乘以正数,第…...

Linux 运行执行文件并将日志输出保存到文本文件中
在 Linux 系统中运行可执行文件并将日志输出保存到文本文件中,可以使用以下几种方法: 方法一:使用重定向符号 > 或 >> 覆盖写入(>): ./your_executable > logfile.txt这会将可执行文件的输…...

注册安全分析报告:北外网校
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
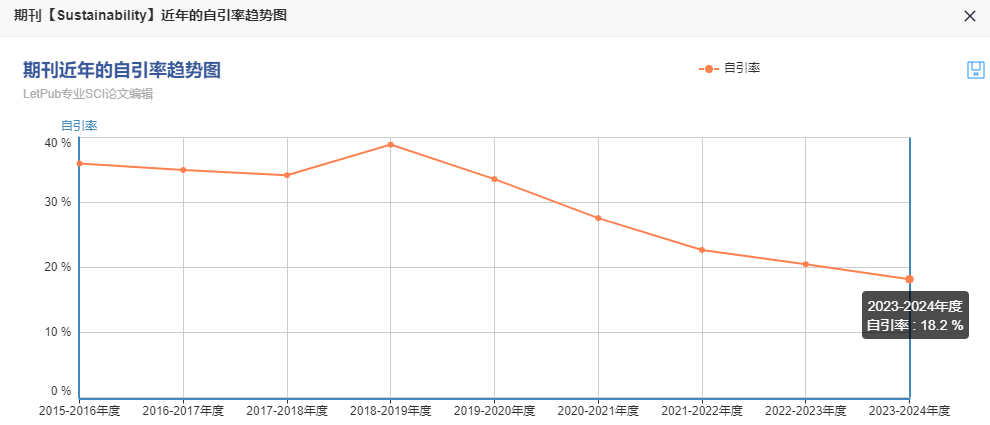
预警期刊命运逆袭到毕业好刊,仅45天!闭眼冲速度,发文量暴增!
选刊发表不迷路,就找科检易学术 期刊官网:Sustainability | An Open Access Journal from MDPI 1、期刊信息 期刊简介: Sustainability 是一本国际性的、同行评审的开放获取期刊,由MDPI出版社每半月在线出版。该期刊专注于人类…...

【LeetCode每日一题】——523.连续的子数组和
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 前缀和 二【题目难度】 中等 三【题目编号】 523.连续的子数组和 四【题目描述】 给你一个…...

leetcode54:螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2: 输入:matrix [[1,2,3,…...
全方面熟悉Maven项目管理工具(三)认识mvn的各类构建命令并创建、打包Web工程
1. POM(核心概念) 1.1 含义 POM: Project Object Model,项目对象模型。 DOM: Document Object Model,文档对象模型,和 POM 类似 它们都是模型化思想的具体体现 1.2 模型化思想 POM 表示将…...

MySQL中查询语句的执行流程
文章目录 前言流程图概述最后 前言 你好,我是醉墨居士,今天我们一起探讨一下执行一条查询的SQL语句在MySQL内部都发生了什么,让你对MySQL内部的架构具备一个宏观上的了解 流程图 概述 对于查询语句的SQL的执行流程,主要可以分为…...

【代码随想录Day47】单调栈Part02
42. 接雨水 题目链接/文章讲解:代码随想录 视频讲解:单调栈,经典来袭!LeetCode:42.接雨水_哔哩哔哩_bilibili 思路概述 问题理解:我们需要计算在给定柱子高度之间可以接住的雨水总量。雨水的量取决于柱子的高度和它们…...

Java全栈经典面试题剖析3】JavaSE面向对象2
目录 面试题2.12 Overload和Override的区别 面试题2.13 Overload方法是否可以改变返回值的类型? 面试题2.14 为什么方法不能根据返回类型来区分重载? 面试题2.15 构造器可不可以被重载或重写? 面试题2.16 在 Java 中定义⼀个不做事且没有…...

@JsonIgnoreProperties做接口对接时使用带来的好处
最近看到有个同事,在代码里面加了JsonIgnoreProperties这个注解,以前还真没有经常去用过,接口对接尤其是跟金蝶、用友等第三方,这个注解在接收数据是非常好用的;接下来带大家一起了解下具体的特性和使用方式 JsonIgno…...

SpringBoot整合mybatisPlus实现批量插入并获取ID
背景:需要实现批量插入并且得到插入后的ID。 使用for循环进行insert这里就不说了,在海量数据下其性能是最慢的。数据量小的情况下,没什么区别。 【1】saveBatch(一万条数据总耗时:2478ms) mybatisplus扩展包提供的:…...

实战RAG第一天——llama_index向量索引,查询引擎,搜索知识库问答,全部代码,保姆级教学
一、llama_index简介 llama_index(以前称为 GPT Index)是一个用于构建、查询、索引大型文档和数据集的开源框架。它的核心功能是帮助开发者将大语言模型(LLM)与自己的数据集无缝集成,从而进行知识库的构建、查询等任务。llama_index 使用 Python 编写,并结合了多种大语言…...

大数据治理
大数据治理是指对大数据的管理和控制,以确保数据的质量、可用性、安全性和合规性。随着大数据技术的不断发展,企业和组织面临着越来越多的数据管理挑战,如数据质量问题、数据安全问题、数据合规问题等。大数据治理成为了企业和组织应对这些挑战的重要手段。 一、大数据治理…...
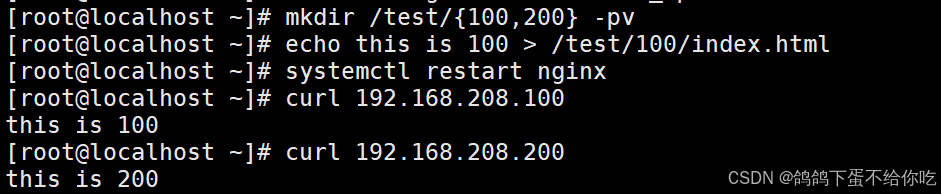
云计算作业
关闭防火墙 停用Linux 挂载 下载nginx程序 启动nginx程序 连接网卡配置文件并且修改 更改模式为静态手动,并且分别修改ip地址,网关地址,dns 激活 创建自定义文件 定义server模块 监听地址 设置目录 匹配 激活网址根目录 创建目录文…...

复制文件到U盘提示:对于目标文件系统,文件过大
查看U盘属性的文件系统是否为FAT32,需将其改为NTFS 方法一 Win R 输入cmd打开命令行,输入以下命令(注:f为U盘盘符) convert f: /fs:ntfs /x方法二 格式化U盘,右键点击U盘进行格式化,文件系…...

SpringBoot+Swagger2.7.0实现汉化(2.8.0不行)
场景 SpringBootSwagger2实现可视化API文档流程: SpringBootSwagger2实现可视化API文档流程_swagger 可视化端口-CSDN博客 上面SpringBoot中使用swagger的效果 上面使用的是swagger2.8.0,且在线API是英文的。现在要将其进行汉化。 汉化效果 实现 首先打开sprin…...

c++ 散列表
散列表(Hash Table)是一种高效的数据结构,广泛用于实现快速的键值对存储。 基本概念 散列表使用哈希函数将键映射到数组的索引。其主要优点在于平均情况下提供常数时间复杂度的查找、插入和删除操作。 哈希函数: 将键映射到一个固定大小的…...

Windows通过netsh控制安全中心防火墙和网络保护策略
Windows通过netsh控制安全中心防火墙和网络保护策略 1. 工具简介 【1】. Windows安全中心 【2】. netsh工具 netsh(Network Shell) 是一个Windows系统本身提供的功能强大的网络配置命令行工具。 2. 开启/关闭防火墙策略 在设置端口(禁用/启用)前&am…...

大模型求职避坑指南:收藏这份三层准备路径,轻松拿下高薪Offer!
本文针对大模型求职者,揭示了常见误区并提供了清晰的三层准备路径:基础能力、核心竞争力、差异化优势。文章强调刷题和背概念只是入门,真正重要的是项目经历,要能深入回答五个关键问题:项目背景、技术选型、难点解决、…...

对比官方直连体验Taotoken在模型调用稳定性上的差异感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方直连体验Taotoken在模型调用稳定性上的差异感受 作为一名长期与各类大模型API打交道的开发者,我习惯于直接调用…...

从SparseConvTensor到Rulebook:图解spconv稀疏卷积的核心工作流程
从SparseConvTensor到Rulebook:图解spconv稀疏卷积的核心工作流程 稀疏卷积(Sparse Convolution)作为处理3D点云数据的关键技术,正在重塑计算机视觉领域的格局。想象一下,当传统卷积神经网络在密集的2D图像上大展拳脚时…...

OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南
OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor OpenPLC Editor是一款基于Beremiz项目的开源工业自动化编程工具,为工程师和开发…...

三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密
三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为找不到三星官方固件而烦恼吗&am…...

PCIe调试避坑指南:当你的设备报Malformed TLP/UR/UC错误时,到底发生了什么?
PCIe调试实战:Malformed TLP/UR/UC错误排查全解析 当PCIe设备突然抛出Malformed TLP、UR(Unsupported Request)或UC(Unexpected Completion)错误时,很多工程师的第一反应往往是翻查协议手册。但真实调试场景…...

3分钟神奇恢复!让Windows 11 LTSC系统拥有完整Microsoft Store应用商店的终极秘籍
3分钟神奇恢复!让Windows 11 LTSC系统拥有完整Microsoft Store应用商店的终极秘籍 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正…...

测试09测试09测试09测试09测试09
测试09测试09测试09测试09测试09...

3分钟完成Honey Select 2中文汉化:免费增强补丁终极使用指南
3分钟完成Honey Select 2中文汉化:免费增强补丁终极使用指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的界面语言障碍而…...

KLayout 0.30.0:如何用这款专业版图工具提升你的集成电路设计效率
KLayout 0.30.0:如何用这款专业版图工具提升你的集成电路设计效率 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout 如果你正在寻找一款既强大又灵活的开源集成电路版图查看与编辑工具,KLayo…...