如何保证Redis和数据库的数据一致性
文章目录
- 0. 前言
- 1. 补充知识:CP和AP
- 2. 什么情况下会出现Redis与数据库数据不一致
- 3. 更新缓存还是删除缓存
- 4. 先操作缓存还是先操作数据库
- 4.1 先操作缓存
- 4.1.1 数据不一致的问题是如何产生的
- 4.1.2 解决方法(延迟双删)
- 4.1.3 最终一致性和强一致性
- 4.1.4 如何确定延迟双删的延迟时间
- 4.2 先操作数据库(推荐使用)
- 4.2.1 数据不一致的问题是如何产生的
- 4.2.2 解决方法(删除+延迟删除)
- 5. 删除缓存失败的情况
- 5.1 删除重试机制
- 5.2 canal
- 5.3 引入canal后的流程
- 6. 总结
阅读本文前可以先阅读我的另一篇博文: Windows环境下安装Redis并设置Redis开机自启
0. 前言
在面试的时候,如果面试官看到我们有处理高并发项目的经验,并且在项目中用到了 Redis,面试官通常都会问 Redis 缓存怎么跟数据库保持一致,我们一起来探讨一下这个问题
1. 补充知识:CP和AP
在分布式系统的一致性模型中,CP 和 AP 是 CAP 定理中的两个关键概念
CAP 定理,也称为布鲁尔定理(Brewer’s Theorem),是由计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年提出的
CAP 定理描述了分布式系统在设计时面临的三个基本属性,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),并指出分布式系统在任何给定时间只能同时满足其中的两个属性
以下是 CP 和 AP 的含义:
- CP(Consistency and Partition Tolerance):
- 一致性(Consistency):指所有节点看到的数据是一致的,即更新操作在所有节点上要么全部成功,要么全部失败
- 分区容错性(Partition Tolerance):指系统在出现网络分区(即网络中的一部分节点无法与其他节点通信)的情况下仍然能够继续运行
- CP系统在发生网络分区时,会选择一致性和分区容错性,可能会牺牲可用性。这意味着在分区发生时,系统可能会拒绝某些操作以保证数据的一致性
- AP(Availability and Partition Tolerance):
- 可用性(Availability):指系统在面对客户端的请求时,总是能够给出响应,即使是在部分节点失败或网络分区的情况下
- 分区容错性(Partition Tolerance):系统在出现网络分区的情况下仍然能够继续运行
- AP系统在发生网络分区时,会选择可用性和分区容错性,可能会牺牲一致性,这意味着系统在分区发生时,仍然可以响应客户端的请求,但可能会返回不一致的数据
总结来说,CP 和 AP 是 CAP 定理中描述的两种不同的设计选择,它们反映了分布式系统在不同场景下的权衡
选择 CP 还是 AP 取决于具体应用的需求,例如,金融系统通常需要强一致性,因此会选择CP,而社交媒体或某些类型的缓存系统可能会选择 AP 以提供更高的可用性
2. 什么情况下会出现Redis与数据库数据不一致
我们先来看一下使用 Redis 读取数据的场景

当客户端发起一个查询数据的请求时,会先检查 Redis 中检查有没有对应的数据,有的话直接返回,没有的话就会查询数据库,把从数据库中查询到的数据保存到 Redis 中后,再返回给客户端
在将数据库中查询到的数据保存到 Redis 时,一般会为数据设置一个过期时间,主要目的是为了避免一些冷数据一直占用 Redis 的空间
如果只进行读操作,是不会出现数据不一致的情况的,只有读操作和写操作同时进行,才会出现数据不一致的情况
我们再来看一下写数据的场景,写数据的场景就比较多了:
- 先更新缓存再更新数据库
- 先删除缓存再更新数据库
- 先更新数据库再更新缓存
- 先更新数据库再删除缓存
总结起来,就是以下两点区别:
- 更新缓存还是删除缓存
- 先操作缓存还是先操作数据库
3. 更新缓存还是删除缓存
我们是更新 Redis 中对应的数据,还是直接删除 Redis 中对应的数据呢
推荐使用删除 Redis 中对应的数据的方式,为什么呢
因为删除的逻辑非常简单,删除缓存之后 Redis 中就没有对应的数据了,等到下一个线程进行查询操作时,会从数据库中查询数据,接着将查询到的数据保存到 Redis 中
如果是更新 Redis 中的数据,可能会涉及到一系列复杂的业务逻辑计算,整个更新操作所需要付出的成本是比删除操作更高的
4. 先操作缓存还是先操作数据库
到底是先操作缓存好呢,还是先操作数据库好呢
当出现数据不一致的时候,这两种方案是怎么处理的呢,我们分别探讨一下
4.1 先操作缓存
4.1.1 数据不一致的问题是如何产生的
我们先来看一下比较简单的先操作缓存的场景

当读操作和写操作并发执行的时候,数据不一致的问题是如何产生的呢

首先,线程 1 发起了一个修改数据的请求,线程 1 删除缓存中的对应数据,接着去修改数据库,但是线程 1 在修改数据库时出现了网络延迟,在线程 1 修改数据库前,线程 2 发起了一个查询请求,由于线程 1 把缓存中对应的数据删掉了,线程 2 在 Redis 中找不到对应的数据,线程 2 会从数据库中查询数据,并将查询到的数据保存到 Redis 中
但线程 2 查询到的是一个旧数据,因为线程 1 还没有将的数据保存到数据库中,当线程 1 成功将新数据保存到数据库之后,就出现了数据不一致的情况(数据库中的是新数据,Redis 中的是旧数据)
线程 1 成功将新数据保存到数据库之后,如果有大量的查询请求,那么查到的数据都是 Redis 中的旧数据,只有等到旧数据过期了,才能查到数据库中的新数据
4.1.2 解决方法(延迟双删)
怎么解决呢,其实也比较简单
我们先重演一遍出现数据不一致的过程,当线程 1 成功将新数据保存到数据库之后,我能不能再删除一次缓存呢,当然是可以的,这也就是我们平时经常听到的延迟双删
将新数据保存到数据库之后再次删除缓存,如果后面又有查询请求,因为 Redis 中没有对应的数据,会从数据库中查询数据,并将查到的数据保存到 Redis 中,这样做就可以保证 Redis 和数据库的数据一致性
4.1.3 最终一致性和强一致性
但是在线程 1 成功将新数据保存到数据库之前,线程 2 查询到的数据依然是旧数据,会出现一次数据不一致的情况
有同学可能会说,能不能把这一次数据不一致也避免掉,当然可以,不过要引入强一致性的概念,如果要求 Redis 中的数据和数据库中的数据保持强一致性的话,就需要确保操作缓存操作和操作数据库操作满足原子性
但 Redis 和数据库一般是在不同的服务器上的,需要两步操作(即使是在同一台服务器上也需要两步操作),如果要保证同时进行两步操作的原子性,就需要借助锁了
但是加锁会影响我们整个系统的吞吐量,想一下,我们用 Redis 的目的是什么,是不是为了提高系统的性能,如果为了强一致性而去加锁,是不是就得不偿失了
所以说,一致性跟可用性,我们只能满足一个,在可用性的基础上,我们可以使用刚才提到的成功保存数据到数据库之后,再次删除缓存中对应的数据的策略,虽然会出现少量数据不一致的情况,但是 Redis 和数据库是保持数据的最终一致性的
我们保证 Redis 和数据库的数据一致性,一般是采用最终一致性,而不是强一致性,因为强一致性会影响系统的吞吐量
4.1.4 如何确定延迟双删的延迟时间
但我们得注意一点,上面提到的双删策略(操作数据库前删除一次缓存,操作数据库后又删除一次缓存),在第二次删除的时候,要延迟删除

为什么要这么做呢,我们重演一下发生数据不一致的过程,当线程 1 删除缓存之后,线程 2 发起查询请求,发现 Redis 中没有对应的数据,从数据库中查询数据,在线程 2 将查询到的数据之前,线程 1 成功将新数据保存到数据库并删除缓存,在线程 1 删除缓存之后,线程 2 才把查询到的数据放入到 Redis 中,造成了数据不一致的情况
所以,我们要延迟一定时间之后再进行删除,那怎么确定延迟时间呢,我们需要自行评估项目的读取数据业务的耗时(即线程 2 从数据库读取数据到写入缓存的整个过程的总耗时),防止线程 2 将旧数据存到 Redis 中
4.2 先操作数据库(推荐使用)
4.2.1 数据不一致的问题是如何产生的
我们先来看一下比较简单的先操作数据库的场景

客户端发起一个修改数据的请求,先将修改保存到数据库中,再删除缓存
当读操作和写操作并发执行的时候,数据不一致的问题是如何产生的呢

线程 1 操作数据库,将新数据保存到数据库中,在线程 1 删除缓存之前,线程 2 发起查询请求,那么线程 2 查询到的就是旧数据,等到线程 1 删除缓存之后,下一个线程才能查询到新数据
先操作数据库,再删除缓存,能保证数据的最终一致性,实现起来也比较简单,所以更推荐大家先操作数据库,再删除缓存
只不过先操作数据库,在线程 1 删除缓存之前,其它线程查询到的是脏数据,但是能保证数据的最终一致性
其实,先操作数据库也有可能会出现数据最终一致性被破坏的情况,我们来模拟一下这个过程,当线程 2 发起查询请求时,缓存中对应的数据刚好过期了,线程 2 从数据库中查找数据,在线程 2 将数据写入缓存之前,线程 1 完成了更新数据库并删除缓存的操作,接着线程 2 才将数据写入缓存,此时数据库中存的是新数据,缓存中存的是旧数据,数据最终一致性被破坏
另外,在数据库做了集群的情况下,先操作数据库也有可能导致数据的最终一致性被破坏的情况
在数据库集群中,一般是主节点负责写操作,从节点负责读操作,在高并发场景下,更新主库的数据并删除缓存之后,如果从库没来得及同步更改,后续的查询请求就会从数据库的从库中查找数据,并将数据保存到缓存中,但从库中的数据是旧数据,从而导致数据的最终一致性被破坏
4.2.2 解决方法(删除+延迟删除)
该怎么解决这个问题呢,跟前面提到的延迟双删思想类似,更新数据库并删除缓存之后,再延迟删除一次缓存,这样就能保证第二次删除缓存后查到的数据都是新数据
当然,这个延迟时间需要自行评估项目的读取数据业务的耗时,如果延迟时间过短,还是会出现数据不一致的情况
但频繁删除缓存有可能会导致缓存击穿的问题,也是比较严重的(至于什么是缓存击穿,可以参考我的另一篇博文:Redis缓存面试三兄弟:缓存穿透、缓存雪崩、缓存击穿)
先操作缓存中提到的延迟双删的过程:删除缓存→更新数据库→延迟删除缓存
此处的双删:更新数据库→删除缓存→延迟删除缓存
5. 删除缓存失败的情况
无论是先操作缓存还是先操作数据库,都有可能出现删除缓存失败的情况,当然,这种情况比较极端
如果删除缓存失败了,后续线程查询到的全都是旧数据,必须等待缓存中对应的数据过期了之后才能查到新数据
5.1 删除重试机制
针对这种删除失败的情况,我们可以借助消息队列,并采用删除重试机制,比如重试 3 次,如果重试 3 次后仍然失败,则记录日志到数据库并发送警告给相关人员,进行人工介入
高并发场景下,重试最好采用异步的方式
当缓存删除失败之后,发送一个异步消息到消息队列中,让系统监听消息队列,一旦发现 Redis 的某个 key 删除失败了,就执行删除重试操作,这样能在一定程度上避免删除失败所引起的数据不一致的情况

但是,当我们加入了删除重试的代码之后,有什么缺点呢
可以发现,加入删除重试的代码之后,业务代码的耦合度太高了,要实现解耦的话,可以采用另一个组件——canal
值得注意的是,引入 canal 之后,系统的复杂度也会提升,毕竟 canal 是一个新的中间件,需要监控 canal 的运行状态,保证 canal 运行正常
5.2 canal
canal 的官网:canal(阿里巴巴开源的一个组件)
Canal 是一个基于 MySQL 数据库增量日志解析的开源数据同步工具,主要用于解决数据库间的数据同步问题,特别是在大数据场景下,Canal 可以帮助用户将 MySQL 数据库中的数据实时同步到其他数据存储系统中,如 Elasticsearch、HBase、Kafka 等

Canal 的工作原理主要依赖于 MySQL 的主从复制机制,以下是 Canal 实现数据同步的基本步骤和原理(人工智能给出的回答,仅供参考):
- MySQL 主从复制原理:
- MySQL 支持主从复制功能,其中主库(Master)上的所有写操作都会记录到二进制日志(Binary Log,简称 binlog)中
- 从库(Slave)通过一个 I/O 线程连接到主库,请求主库的 binlog
- 主库将 binlog 发送给从库,从库的 I/O 线程将 binlog 写入到本地的中继日志(Relay Log)
- 从库的 SQL 线程读取中继日志,并执行日志中的写操作,从而实现数据的复制
- Canal 的工作流程:
- 模拟 Slave:Canal 模拟 MySQL 从库的行为,与主库建立连接,并请求主库的 binlog
- 解析 binlog:当主库有数据变更时,Canal 会接收到相应的 binlog 事件。Canal 使用自己的 binlog 解析引擎来解析这些事件,并将其转换为更容易理解的格式
- 事件投递:解析后的数据变更事件可以被投递到其他系统,如消息队列(例如 Kafka)或者直接写入到目标存储系统(例如 Elasticsearch)
- 关键组件:
- Canal Server:运行 Canal 服务,负责从 MySQL 中读取 binlog,解析并投递数据变更事件
- Canal Client:负责从 Canal Server 获取数据变更事件,并将其应用到目标系统
- 细节说明:
- 位置记录:Canal 需要记录每次同步的位置,以便在服务重启后能够从上次停止的位置继续同步
- 数据过滤:Canal 支持配置过滤规则,只同步特定数据库或表的数据
- 数据格式转换:Canal 可以将解析后的 binlog 事件转换为 JSON、XML 等格式
Canal 能够实现 MySQL 数据库与其他数据存储系统之间的实时数据同步,广泛应用于数据备份、数据迁移、数据集成和实时数据处理等场景
5.3 引入canal后的流程
简单地来说,当 MySQL 中出现了数据变动,canal 能够立马感知到,并通知 canal 的客户端
canal 的客户端有很多种,我们可以使用 SpringBoot 应用来充当 canal 的客户端,接收来自 canal 的通知,一旦数据库发生了数据修改,数据库的主节点会通知 canal,canal 再去通知 canal 的客户端
也就是说,更新数据库后的删除缓存操作和删除重试中的删除缓存操作都交由 canal 来完成

6. 总结
- 如果是在并发量不高的的场景下,采用
删除缓存→更新数据库→延迟删除缓存方案或更新数据库→删除缓存方案都是合理的 - 如果是在高并发的场景下,无论是哪种方案,即使对方案做了优化,都有可能出现数据不一致的情况,只不过是概率的大小问题
- 保证 Redis 和数据库的数据一致性,一般是保证数据的最终一致性,而不是数据的强一致性
- 对于读多写少的数据,我们可以放在缓存中,减轻数据库的压力;对于读多写多的数据,放入缓存中弊大于利,因为放入缓存中的数据应该是对一致性要求没有那么高的数据
- 如果数据要求强一致性,就需要借助锁来确保
更新数据库操作和删除缓存操作的原子性,但引入锁会降低系统的吞吐量,使用缓存本来就是为了提高系统的性能,引入锁反而是得不偿失 - 一致性和可用性往往不可兼得,需要根据实际选择符合业务场景的方案
相关文章:
如何保证Redis和数据库的数据一致性
文章目录 0. 前言1. 补充知识:CP和AP2. 什么情况下会出现Redis与数据库数据不一致3. 更新缓存还是删除缓存4. 先操作缓存还是先操作数据库4.1 先操作缓存4.1.1 数据不一致的问题是如何产生的4.1.2 解决方法(延迟双删)4.1.3 最终一致性和强一致…...

Android Framework AMS(06)startActivity分析-3(补充:onPause和onStop相关流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读AMS通过startActivity启动Activity的整个流程的补充,更新了startActivity流程分析部分。 一般来说,有Activ…...

【LangChain系列2】【Model I/O详解】
目录 前言一、LangChain1-1、介绍1-2、LangChain抽象出来的核心模块1-3、特点1-4、langchain解决的一些行业痛点1-5、安装 二、Model I/O模块2-0、Model I/O模块概要2-1、Format(Prompts Template)2-1-1、Few-shot prompt templates2-1-2、Chat模型的少样…...
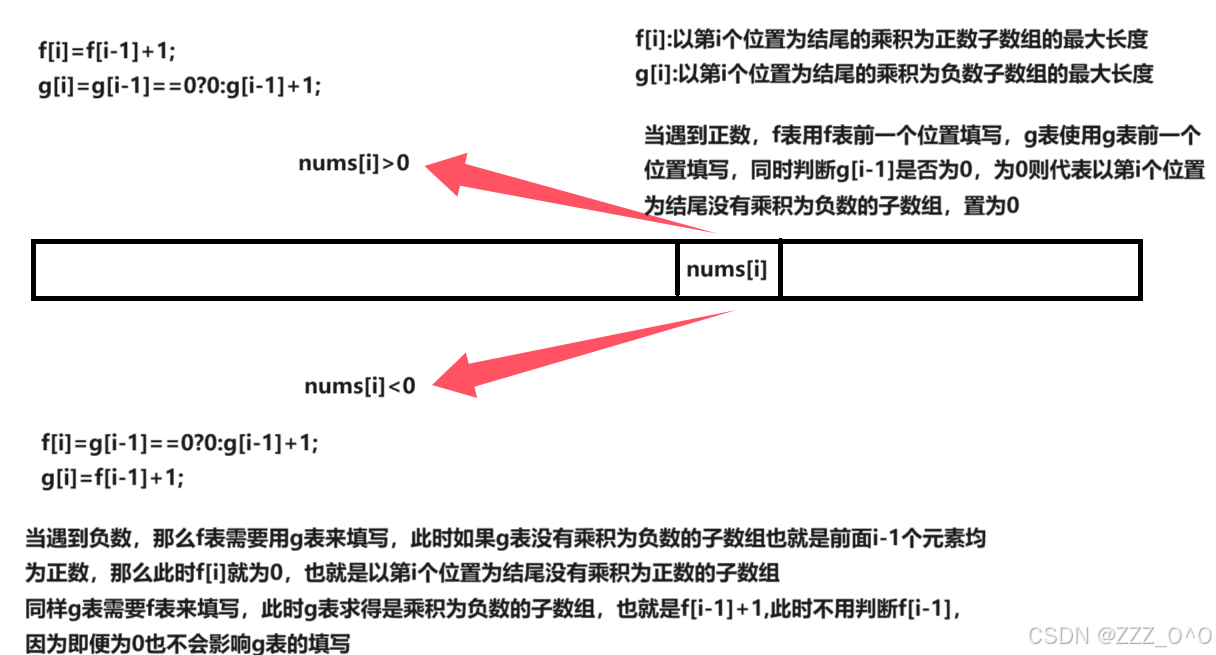
动态规划-子数组系列——1567.乘积为正数的最长子数组
1.题目解析 题目来源:1567.乘积为正数的最长子数组——力扣 测试用例 2.算法原理 1.状态表示 因为数组中存在正数与负数,如果求乘积为正数的最长子数组,那么存在两种情况使得乘积为正数,第一种就是正数乘以正数,第…...

Linux 运行执行文件并将日志输出保存到文本文件中
在 Linux 系统中运行可执行文件并将日志输出保存到文本文件中,可以使用以下几种方法: 方法一:使用重定向符号 > 或 >> 覆盖写入(>): ./your_executable > logfile.txt这会将可执行文件的输…...

注册安全分析报告:北外网校
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
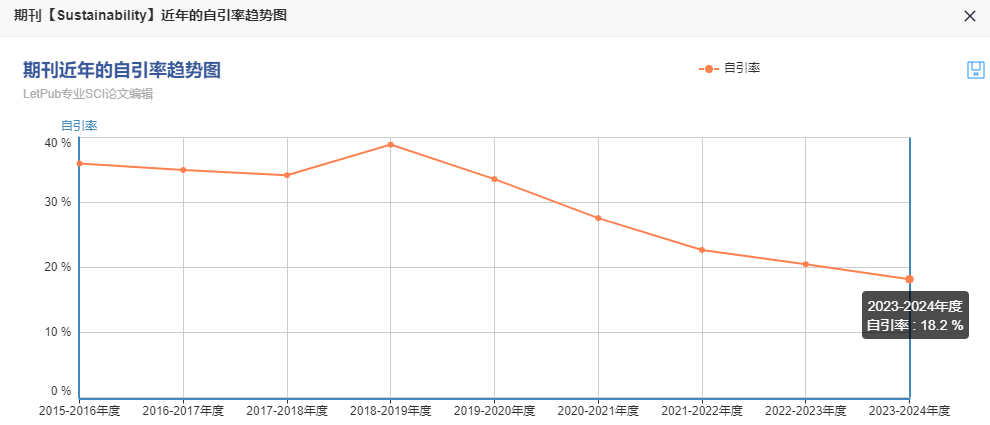
预警期刊命运逆袭到毕业好刊,仅45天!闭眼冲速度,发文量暴增!
选刊发表不迷路,就找科检易学术 期刊官网:Sustainability | An Open Access Journal from MDPI 1、期刊信息 期刊简介: Sustainability 是一本国际性的、同行评审的开放获取期刊,由MDPI出版社每半月在线出版。该期刊专注于人类…...

【LeetCode每日一题】——523.连续的子数组和
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 前缀和 二【题目难度】 中等 三【题目编号】 523.连续的子数组和 四【题目描述】 给你一个…...

leetcode54:螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2: 输入:matrix [[1,2,3,…...
全方面熟悉Maven项目管理工具(三)认识mvn的各类构建命令并创建、打包Web工程
1. POM(核心概念) 1.1 含义 POM: Project Object Model,项目对象模型。 DOM: Document Object Model,文档对象模型,和 POM 类似 它们都是模型化思想的具体体现 1.2 模型化思想 POM 表示将…...

MySQL中查询语句的执行流程
文章目录 前言流程图概述最后 前言 你好,我是醉墨居士,今天我们一起探讨一下执行一条查询的SQL语句在MySQL内部都发生了什么,让你对MySQL内部的架构具备一个宏观上的了解 流程图 概述 对于查询语句的SQL的执行流程,主要可以分为…...

【代码随想录Day47】单调栈Part02
42. 接雨水 题目链接/文章讲解:代码随想录 视频讲解:单调栈,经典来袭!LeetCode:42.接雨水_哔哩哔哩_bilibili 思路概述 问题理解:我们需要计算在给定柱子高度之间可以接住的雨水总量。雨水的量取决于柱子的高度和它们…...

Java全栈经典面试题剖析3】JavaSE面向对象2
目录 面试题2.12 Overload和Override的区别 面试题2.13 Overload方法是否可以改变返回值的类型? 面试题2.14 为什么方法不能根据返回类型来区分重载? 面试题2.15 构造器可不可以被重载或重写? 面试题2.16 在 Java 中定义⼀个不做事且没有…...

@JsonIgnoreProperties做接口对接时使用带来的好处
最近看到有个同事,在代码里面加了JsonIgnoreProperties这个注解,以前还真没有经常去用过,接口对接尤其是跟金蝶、用友等第三方,这个注解在接收数据是非常好用的;接下来带大家一起了解下具体的特性和使用方式 JsonIgno…...

SpringBoot整合mybatisPlus实现批量插入并获取ID
背景:需要实现批量插入并且得到插入后的ID。 使用for循环进行insert这里就不说了,在海量数据下其性能是最慢的。数据量小的情况下,没什么区别。 【1】saveBatch(一万条数据总耗时:2478ms) mybatisplus扩展包提供的:…...

实战RAG第一天——llama_index向量索引,查询引擎,搜索知识库问答,全部代码,保姆级教学
一、llama_index简介 llama_index(以前称为 GPT Index)是一个用于构建、查询、索引大型文档和数据集的开源框架。它的核心功能是帮助开发者将大语言模型(LLM)与自己的数据集无缝集成,从而进行知识库的构建、查询等任务。llama_index 使用 Python 编写,并结合了多种大语言…...

大数据治理
大数据治理是指对大数据的管理和控制,以确保数据的质量、可用性、安全性和合规性。随着大数据技术的不断发展,企业和组织面临着越来越多的数据管理挑战,如数据质量问题、数据安全问题、数据合规问题等。大数据治理成为了企业和组织应对这些挑战的重要手段。 一、大数据治理…...
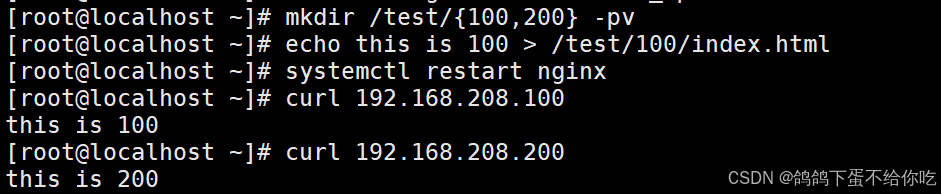
云计算作业
关闭防火墙 停用Linux 挂载 下载nginx程序 启动nginx程序 连接网卡配置文件并且修改 更改模式为静态手动,并且分别修改ip地址,网关地址,dns 激活 创建自定义文件 定义server模块 监听地址 设置目录 匹配 激活网址根目录 创建目录文…...

复制文件到U盘提示:对于目标文件系统,文件过大
查看U盘属性的文件系统是否为FAT32,需将其改为NTFS 方法一 Win R 输入cmd打开命令行,输入以下命令(注:f为U盘盘符) convert f: /fs:ntfs /x方法二 格式化U盘,右键点击U盘进行格式化,文件系…...

SpringBoot+Swagger2.7.0实现汉化(2.8.0不行)
场景 SpringBootSwagger2实现可视化API文档流程: SpringBootSwagger2实现可视化API文档流程_swagger 可视化端口-CSDN博客 上面SpringBoot中使用swagger的效果 上面使用的是swagger2.8.0,且在线API是英文的。现在要将其进行汉化。 汉化效果 实现 首先打开sprin…...

可穿戴声音装置DIY:用Adafruit Audio FX板制作互动节日毛衣
1. 项目概述:一件会“说话”的节日毛衣又到年底节日扎堆的时候了,除了琢磨穿什么衣服,你有没有想过让衣服本身成为节日气氛的一部分?我说的不是简单的亮片或印花,而是让衣服能发出声音——比如一按袖子就响起清脆的铃铛…...

AMBA系统监视器:从端口验证到SoC系统级验证的关键跃迁
1. 项目概述:从端口到系统的验证跃迁在SoC验证的战场上,我们常常陷入一种“只见树木,不见森林”的困境。作为一名验证工程师,你可能已经熟练地为每个AXI、AHB或APB接口挂上VIP(验证IP),看着端口…...

Taotoken的API Key分级管理与访问控制功能实测
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的API Key分级管理与访问控制功能实测 1. 功能定位与实际价值 在团队协作或项目集成的场景中,直接使用一个具…...
)
AI视频时间一致性失效的7种隐藏诱因(GPU显存碎片化、隐空间梯度漂移、跨模态时钟不同步…业内首次系统归因)
更多请点击: https://intelliparadigm.com 第一章:AI视频时间一致性失效的系统性归因框架 AI视频生成中,时间一致性失效并非孤立现象,而是多层级模型组件、训练范式与推理机制耦合失配的结果。其根源横跨数据建模、特征传播、时序…...

【免费下载】 Gmsh 4.11.1 资源包
Gmsh 4.11.1 资源包 【下载地址】Gmsh4.11.1资源包 Gmsh 4.11.1 资源包本仓库提供了一个包含 Gmsh 4.11.1 版本及相关资源的下载包 项目地址: https://gitcode.com/open-source-toolkit/804a2 本仓库提供了一个包含 Gmsh 4.11.1 版本及相关资源的下载包。Gmsh 是一款开源…...

对比直接使用厂商API体验Taotoken在路由与容灾上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken在路由与容灾上的差异 1. 引言:一次意料之外的服务波动 在日常开发与业务运营中&…...

当我们谈论“防治养”时,我们谈论的是一种生活方式的重构
一、重新审视“健康”的定义在现代生活的快节奏中,健康常常被简化为一个医学指标,或是年度体检报告上的一串数字。然而,当我们谈论肿瘤“防治养”时,我们谈论的远不止于此。这不是三个孤立的概念,而是一个完整的循环—…...

Arm LUTI指令解析:向量化查找表优化实战
1. Arm LUTI指令深度解析:多寄存器查找表操作实战指南在Armv9架构的SME2扩展中,LUTI(Lookup Table Indexed)系列指令为向量化查找表操作提供了硬件级支持。这类指令通过ZT0寄存器存储查找表数据,利用源向量寄存器中的索…...

Linux编译OpenSSL 3.0.1时,那个烦人的‘Can‘t locate IPC/Cmd.pm’错误,我是这样解决的
解决Linux编译OpenSSL 3.0.1时的Perl模块依赖问题 在Linux环境下从源码编译安装OpenSSL时,开发者常会遇到各种依赖问题,其中Cant locate IPC/Cmd.pm错误尤为常见。这个错误看似简单,却可能让不熟悉Perl模块管理机制的用户陷入困境。本文将深入…...
)
从一次Keycloak弱口令通报说起:微服务架构下的密码管理‘避坑’全指南(附Docker Compose配置)
微服务架构下的密码安全实践:从Keycloak弱口令到全局防护体系 1. 当安全工具成为攻击入口:一次真实事件复盘 去年某科技公司的运维团队收到了一份来自监管部门的网络安全通报——部署在公有云上的Keycloak服务遭到境外IP爆破攻击。攻击者仅用"admin…...