linux 内存管理-slab分配器
伙伴系统用于分配以page为单位的内存,在实际中很多内存需求是以Byte为单位的,如果需要分配以Byte为单位的小内存块时,该如何分配呢?
slab分配器就是用来解决小内存块分配问题,也是内存分配中非常重要的角色之一。
slab分配器最终还是由伙伴系统分配出实际的物理内存,只不过slab分配器在这些连续的物理页面上实现了自己的算法,以此来对小内存块进行管理。
slab分配器把对象分组放进高速缓存,每个高速缓存都是同种类型对象的一种"储备"。包含高速缓存的主内存被划分为多个slab,每个slab由一个或多个连续的物理页面组成。这些页框中即包含已分配的对象,也包含空闲的对象。
本文将整个slab分配器所有相关的代码都进行了相关的注释,以及其中涉及的理论内容都进行了详细的描述。由于linux内核中slab分配器的重要性,不可能几句话就将其实现过程描述清楚,尤其是那些对slab分配器内部细节感兴趣的童靴,可能需要花点时间和耐心来阅读。笔者已经进行过整理,大家按照下面的代码直接阅读理解就行。
1、创建slab描述符
struct kmem_cache数据结构是slab分配器中的核心数据结构,称其为slab描述符。struct kmem_cache定义如下:
include/linux/slab_def.h
/** Definitions unique to the original Linux SLAB allocator.*//*每个slab描述符都由一个struct kmem_cache数据结构来抽象描述*/
struct kmem_cache {/*一个Per-CPU的struct array_cache,每个CPU一个,表示本地CPU的对象缓存池*/struct array_cache __percpu *cpu_cache;/* 1) Cache tunables. Protected by slab_mutex *//*表示当前CPU的本地对象缓存池array_cache为空时,从共享的缓冲池或则slabs_partial/slabs_free列表中获取对象的数目*/unsigned int batchcount;/*当本地对象缓存池的空闲对象数目大于limit时,会主动释放batchcount个对象,便于内核回收和销毁slab*/unsigned int limit;/*用于多核系统*/unsigned int shared;/*对象的长度,这个长度要加上align对齐字节*/unsigned int size;struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend *//*对象的分配掩码*/unsigned int flags; /* constant flags *//*一个slab中最多可以有多少个对象*/unsigned int num; /* # of objs per slab *//* 3) cache_grow/shrink *//* order of pgs per slab (2^n) *//*一个slab中占用2^gfporder个页面*/unsigned int gfporder;/* force GFP flags, e.g. GFP_DMA */gfp_t allocflags;/*一个slab中有几个不同的cache line*/size_t colour; /* cache colouring range *//*一个cache colour的长度,和L1缓存行相同*/unsigned int colour_off; /* colour offset *//*off-slab时使用,将freelist放在slab物理页面外部*/struct kmem_cache *freelist_cache;/*每个对象要占用1字节来存放freelist*/unsigned int freelist_size;/* constructor func */void (*ctor)(void *obj);/* 4) cache creation/removal *//*slab描述符的名称*/const char *name;struct list_head list;/*引用次数,释放slab描述符时会判断,只有引用次数为0时才真正释放*/int refcount;/*对象的实际大小*/int object_size;/*对齐的长度*/int align;/* 5) statistics */
#ifdef CONFIG_DEBUG_SLABunsigned long num_active;unsigned long num_allocations;unsigned long high_mark;unsigned long grown;unsigned long reaped;unsigned long errors;unsigned long max_freeable;unsigned long node_allocs;unsigned long node_frees;unsigned long node_overflow;atomic_t allochit;atomic_t allocmiss;atomic_t freehit;atomic_t freemiss;/** If debugging is enabled, then the allocator can add additional* fields and/or padding to every object. size contains the total* object size including these internal fields, the following two* variables contain the offset to the user object and its size.*/int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEMstruct memcg_cache_params memcg_params;
#endif/*slab节点,在NUMA系统中每个节点有一个struct kmem_cache_node数据结构,在ARM Vexpress平台中,只有一个节点*/struct kmem_cache_node *node[MAX_NUMNODES];
};slab描述符给每个CPU都提供一个对象缓存池(array_cache)
/** struct array_cache** Purpose:* - LIFO ordering, to hand out cache-warm objects from _alloc* - reduce the number of linked list operations* - reduce spinlock operations** The limit is stored in the per-cpu structure to reduce the data cache footprint.**/struct array_cache {/*对象缓存池中可用的对象数目*/unsigned int avail;/*limit,batchcount和struct kmem_cache中语义一致*/unsigned int limit;unsigned int batchcount;/*从缓存池移除一个对象时,将touched置1;而收缩缓存时,将touched置0*/unsigned int touched;/*保存对象的实体*/void *entry[]; /** Must have this definition in here for the proper* alignment of array_cache. Also simplifies accessing* the entries.** Entries should not be directly dereferenced as* entries belonging to slabs marked pfmemalloc will* have the lower bits set SLAB_OBJ_PFMEMALLOC*/
};struct kmem_cache_node为slab节点,从伙伴系统分配的物理页面由其进行管理。
/*The slab lists for all objects*/
struct kmem_cache_node {spinlock_t list_lock;#ifdef CONFIG_SLAB/*注意,三个链表上挂载的是页表*//*slab部分链表,即其链表成员中的物理内存部分用于分配slab对象*/struct list_head slabs_partial; /* partial list first, better asm code *//*slab满链表,即其链表成员中的物理内存全部用于分配slab对象*/struct list_head slabs_full;/*slab空闲链表,即其链表成员中的物理内存全部空闲,未用于分配slab对象*/struct list_head slabs_free;/*三个链表中所有空闲对象数目*/unsigned long free_objects;/*slab中可以容许的空闲对象数目最大阈值*/unsigned int free_limit;unsigned int colour_next; /* Per-node cache coloring *//*多核cpu中,共享缓存区slab对象*/struct array_cache *shared; /* shared per node */struct alien_cache **alien; /* on other nodes */unsigned long next_reap; /* updated without locking */int free_touched; /* updated without locking */
#endif#ifdef CONFIG_SLUBunsigned long nr_partial;struct list_head partial;
#ifdef CONFIG_SLUB_DEBUGatomic_long_t nr_slabs;atomic_long_t total_objects;struct list_head full;
#endif
#endif};下面是部分全局变量,后面代码中会用到,先贴出来:
mm/slab_common.c
LIST_HEAD(slab_caches);
DEFINE_MUTEX(slab_mutex);
struct kmem_cache *kmem_cache;include/linux/slab.h 下面是分配器中配置参数,其中slab,slob,slub分配器的参数存在差异:#define L1_CACHE_BYTES (1 << L1_CACHE_SHIFT) /*1<<6= 64*//** Memory returned by kmalloc() may be used for DMA, so we must make* sure that all such allocations are cache aligned. Otherwise,* unrelated code may cause parts of the buffer to be read into the* cache before the transfer is done, causing old data to be seen by* the CPU.*/
#define ARCH_DMA_MINALIGN L1_CACHE_BYTES/** Some archs want to perform DMA into kmalloc caches and need a guaranteed* alignment larger than the alignment of a 64-bit integer.* Setting ARCH_KMALLOC_MINALIGN in arch headers allows that.*/
#if defined(ARCH_DMA_MINALIGN) && ARCH_DMA_MINALIGN > 8
/*有效*/
#define ARCH_KMALLOC_MINALIGN ARCH_DMA_MINALIGN /*64*/
#define KMALLOC_MIN_SIZE ARCH_DMA_MINALIGN
#define KMALLOC_SHIFT_LOW ilog2(ARCH_DMA_MINALIGN) /*6*/
#else
#define ARCH_KMALLOC_MINALIGN __alignof__(unsigned long long)
#endif#ifdef CONFIG_SLAB
/** The largest kmalloc size supported by the SLAB allocators is* 32 megabyte (2^25) or the maximum allocatable page order if that is* less than 32 MB.** WARNING: Its not easy to increase this value since the allocators have* to do various tricks to work around compiler limitations in order to* ensure proper constant folding.*/
/*22*/
#define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? (MAX_ORDER + PAGE_SHIFT - 1) : 25)
#define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH /*22*/
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 5
#endif
#endif#ifdef CONFIG_SLUB
/** SLUB directly allocates requests fitting in to an order-1 page* (PAGE_SIZE*2). Larger requests are passed to the page allocator.*/
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1) /*13*/
#define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT) /*11+12=23*/
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 3
#endif
#endif#ifdef CONFIG_SLOB
/** SLOB passes all requests larger than one page to the page allocator.* No kmalloc array is necessary since objects of different sizes can* be allocated from the same page.*/
#define KMALLOC_SHIFT_HIGH PAGE_SHIFT /*12*/
#define KMALLOC_SHIFT_MAX 30
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 3
#endif
#endif/* Maximum allocatable size */
#define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX)
/* Maximum size for which we actually use a slab cache */
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
/* Maximum order allocatable via the slab allocagtor */
#define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT)/*kmalloc分配的最小值,slab分配器的值为32,slob,slub分配器值为8*/
#define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW)/*分配器中对象最小值,slab分配器的值为16,slob,slub分配器值为8*/
#define SLAB_OBJ_MIN_SIZE (KMALLOC_MIN_SIZE < 16 ? (KMALLOC_MIN_SIZE) : 16)kmem_cache_create的实现:
/** kmem_cache_create - Create a cache.* @name: A string which is used in /proc/slabinfo to identify this cache.* @size: The size of objects to be created in this cache.* @align: The required alignment for the objects.* @flags: SLAB flags* @ctor: A constructor for the objects.** Returns a ptr to the cache on success, NULL on failure.* Cannot be called within a interrupt, but can be interrupted.* The @ctor is run when new pages are allocated by the cache.** The flags are** %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)* to catch references to uninitialised memory.** %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check* for buffer overruns.** %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware* cacheline. This can be beneficial if you're counting cycles as closely* as davem.*/
struct kmem_cache * kmem_cache_create(const char *name, size_t size, size_t align,unsigned long flags, void (*ctor)(void *))
{struct kmem_cache *s;const char *cache_name;int err;get_online_cpus();get_online_mems();memcg_get_cache_ids();/*获取slab锁*/mutex_lock(&slab_mutex);err = kmem_cache_sanity_check(name, size);if (err) {s = NULL; /* suppress uninit var warning */goto out_unlock;}/** Some allocators will constraint the set of valid flags to a subset* of all flags. We expect them to define CACHE_CREATE_MASK in this* case, and we'll just provide them with a sanitized version of the* passed flags.*/flags &= CACHE_CREATE_MASK;/*查找是否有现成的slab描述符可以复用,若没有则新建一个slab描述符*/s = __kmem_cache_alias(name, size, align, flags, ctor);if (s)goto out_unlock;cache_name = kstrdup_const(name, GFP_KERNEL);if (!cache_name) {err = -ENOMEM;goto out_unlock;}printk("[f]%s,%s,%x,%x,%x \r\n",__func__,name,size,align,flags);/*创建新的slab描述符*/s = do_kmem_cache_create(cache_name, size, size,calculate_alignment(flags, align, size),flags, ctor, NULL, NULL);if (IS_ERR(s)) {err = PTR_ERR(s);kfree_const(cache_name);}out_unlock:mutex_unlock(&slab_mutex);memcg_put_cache_ids();put_online_mems();put_online_cpus();if (err) {if (flags & SLAB_PANIC)panic("kmem_cache_create: Failed to create slab '%s'. Error %d\n",name, err);else {printk(KERN_WARNING "kmem_cache_create(%s) failed with error %d",name, err);dump_stack();}return NULL;}printk("[e]%s,%s,%x,%x,%x,%x \r\n",__func__,name,s->object_size,s->size,s->align,s->flags);return s;
}首先通过__kmem_cache_alias查找是否有现成的slab描述符可以复用,若没有则通过do_kmem_cache_create创建一个新的slab描述符。
下面是内核中kmem_cache_create打印信息:
[ 0.000000] [f]kmem_cache_create,idr_layer_cache,42c,0,40000
[ 0.000000] -----[f],calculate_slab_order,430,8,80040000,1,a,ff
[ 0.000000] calculate_slab_order,0,370,3
[ 0.000000] calculate_slab_order,1,2b0,7
[ 0.000000] -----[e],calculate_slab_order,1,2b0
[ 0.000000] [e]kmem_cache_create,idr_layer_cache,42c,430,8,40000
[ 0.000000] [f]kmem_cache_create,ftrace_event_field,20,4,40000
[ 0.000000] -----[f],calculate_slab_order,20,8,40000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,7c
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] [e]kmem_cache_create,ftrace_event_field,20,20,8,40000
[ 0.000000] [f]kmem_cache_create,ftrace_event_file,30,4,40000
[ 0.000000] -----[f],calculate_slab_order,30,8,40000,1,a,ff
[ 0.000000] calculate_slab_order,0,18,53
[ 0.000000] -----[e],calculate_slab_order,0,18
[ 0.000000] [e]kmem_cache_create,ftrace_event_file,30,30,8,40000
[ 0.000000] [f]kmem_cache_create,radix_tree_node,130,0,60000
[ 0.000000] -----[f],calculate_slab_order,130,8,80060000,1,a,ff
[ 0.000000] calculate_slab_order,0,90,d
[ 0.000000] -----[e],calculate_slab_order,0,90
[ 0.000000] [e]kmem_cache_create,radix_tree_node,130,130,8,60000
上面的打印信息可知,slab分配器最终的对齐大小值(align)是8,因为在ARM32中架构要求的SLAB最小对齐长度为8字节。
#define ARCH_SLAB_MINALIGN __alignof__(unsigned long long)。
如果系统存在能够合并slab描述符,会尝试进行合并操作。具体如下:
struct kmem_cache * __kmem_cache_alias(const char *name, size_t size, size_t align,unsigned long flags, void (*ctor)(void *))
{struct kmem_cache *cachep;cachep = find_mergeable(size, align, flags, name, ctor);if (cachep) {cachep->refcount++; /*slab描述符引用次数*//** Adjust the object sizes so that we clear* the complete object on kzalloc.*/cachep->object_size = max_t(int, cachep->object_size, size);}return cachep;
}struct kmem_cache *find_mergeable(size_t size, size_t align,unsigned long flags, const char *name, void (*ctor)(void *))
{struct kmem_cache *s;/*不支持merge的情况下直接退出*/if (slab_nomerge || (flags & SLAB_NEVER_MERGE))return NULL;if (ctor) /*必须传入ctor析构函数*/return NULL;/*size关于sizeof(void *)对齐*/size = ALIGN(size, sizeof(void *));/*修正align值*/align = calculate_alignment(flags, align, size);size = ALIGN(size, align);flags = kmem_cache_flags(size, flags, name, NULL);/*遍历slab_caches链表上的slab描述符*/list_for_each_entry_reverse(s, &slab_caches, list) {if (slab_unmergeable(s)) /*跳过不能merge的slab描述符*/continue;if (size > s->size) /*size不匹配*/continue;if ((flags & SLAB_MERGE_SAME) != (s->flags & SLAB_MERGE_SAME))continue;/** Check if alignment is compatible.* Courtesy of Adrian Drzewiecki*/if ((s->size & ~(align - 1)) != s->size) /*s->size关于align对齐*/continue;if (s->size - size >= sizeof(void *)) /*size之差不超过4字节*/continue;if (IS_ENABLED(CONFIG_SLAB) && align && (align > s->align || s->align % align))continue;return s;}return NULL;
}#define ARCH_SLAB_MINALIGN __alignof__(unsigned long long)
/** Figure out what the alignment of the objects will be given a set of* flags, a user specified alignment and the size of the objects.*/
unsigned long calculate_alignment(unsigned long flags,unsigned long align, unsigned long size)
{/** If the user wants hardware cache aligned objects then follow that* suggestion if the object is sufficiently large.** The hardware cache alignment cannot override the specified* alignment though. If that is greater then use it.*/if (flags & SLAB_HWCACHE_ALIGN) {unsigned long ralign = cache_line_size();while (size <= ralign / 2)ralign /= 2;align = max(align, ralign); /*修正align值*/}if (align < ARCH_SLAB_MINALIGN) /*架构要求的SLAB最小对齐长度为8字节*/align = ARCH_SLAB_MINALIGN;return ALIGN(align, sizeof(void *));
}static struct kmem_cache * do_kmem_cache_create(const char *name, size_t object_size, size_t size,size_t align, unsigned long flags, void (*ctor)(void *),struct mem_cgroup *memcg, struct kmem_cache *root_cache)
{struct kmem_cache *s;int err;err = -ENOMEM;/*从kmem_cache中分配struct kmem_cache数据结构*/s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL);if (!s)goto out;s->name = name;/*对象实际大小*/s->object_size = object_size;/*对象的长度,这个长度要加上align对齐字节,后面对齐后会重新设置size的值*/s->size = size;s->align = align;s->ctor = ctor;err = init_memcg_params(s, memcg, root_cache);if (err)goto out_free_cache;/*初始化slab描述符内部其他成员*/err = __kmem_cache_create(s, flags);if (err)goto out_free_cache;/*slab描述符引用次数设置为1*/s->refcount = 1;/*将新分配的struct kmem_cache挂载到slab_cachesi链表上*/list_add(&s->list, &slab_caches);
out:if (err)return ERR_PTR(err);return s;out_free_cache:destroy_memcg_params(s);kmem_cache_free(kmem_cache, s);goto out;
}#define BYTES_PER_WORD sizeof(void *)
#define REDZONE_ALIGN max(BYTES_PER_WORD, __alignof__(unsigned long long))
#define FREELIST_BYTE_INDEX (((PAGE_SIZE >> BITS_PER_BYTE) <= SLAB_OBJ_MIN_SIZE) ? 1 : 0)
#define SLAB_OBJ_MAX_NUM ((1 << sizeof(freelist_idx_t) * BITS_PER_BYTE) - 1) /*0xff,255*//*** __kmem_cache_create - Create a cache.* @cachep: cache management descriptor* @flags: SLAB flags** Returns a ptr to the cache on success, NULL on failure.* Cannot be called within a int, but can be interrupted.* The @ctor is run when new pages are allocated by the cache.** The flags are** %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)* to catch references to uninitialised memory.** %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check* for buffer overruns.** %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware* cacheline. This can be beneficial if you're counting cycles as closely* as davem.*/
int __kmem_cache_create (struct kmem_cache *cachep, unsigned long flags)
{size_t left_over, freelist_size;/*word对齐,物理地址是word对齐的话,那么进行ddr防存时更加高效*/size_t ralign = BYTES_PER_WORD;gfp_t gfp;int err;size_t size = cachep->size;#if DEBUG
#if FORCED_DEBUG/** Enable redzoning and last user accounting, except for caches with* large objects, if the increased size would increase the object size* above the next power of two: caches with object sizes just above a* power of two have a significant amount of internal fragmentation.*/if (size < 4096 || fls(size - 1) == fls(size-1 + REDZONE_ALIGN +2 * sizeof(unsigned long long)))flags |= SLAB_RED_ZONE | SLAB_STORE_USER;if (!(flags & SLAB_DESTROY_BY_RCU))flags |= SLAB_POISON;
#endifif (flags & SLAB_DESTROY_BY_RCU)BUG_ON(flags & SLAB_POISON);
#endif/** Check that size is in terms of words. This is needed to avoid* unaligned accesses for some archs when redzoning is used, and makes* sure any on-slab bufctl's are also correctly aligned.*//*size自身也需要关于BYTES_PER_WORD对齐*/if (size & (BYTES_PER_WORD - 1)) { /*size没有对齐到BYTES_PER_WORD*/size += (BYTES_PER_WORD - 1);size &= ~(BYTES_PER_WORD - 1); /*size关于BYTES_PER_WORD向上取整*/}/*如果flags设置了SLAB_RED_ZONE标志,size自身需要关于REDZONE_ALIGN对齐*/if (flags & SLAB_RED_ZONE) {ralign = REDZONE_ALIGN;/* If redzoning, ensure that the second redzone is suitably* aligned, by adjusting the object size accordingly. */size += REDZONE_ALIGN - 1;size &= ~(REDZONE_ALIGN - 1); /*size关于REDZONE_ALIGN向上对齐*/}/* 3) caller mandated alignment */if (ralign < cachep->align) {ralign = cachep->align; /*以设置的align为准*/}/* disable debug if necessary */if (ralign > __alignof__(unsigned long long))flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);/** 4) Store it.*//*最终align值*/cachep->align = ralign;/*slab分配器状态*/if (slab_is_available())gfp = GFP_KERNEL;elsegfp = GFP_NOWAIT;#if DEBUG/** Both debugging options require word-alignment which is calculated* into align above.*/if (flags & SLAB_RED_ZONE) {/* add space for red zone words */cachep->obj_offset += sizeof(unsigned long long);size += 2 * sizeof(unsigned long long);}if (flags & SLAB_STORE_USER) {/* user store requires one word storage behind the end of* the real object. But if the second red zone needs to be* aligned to 64 bits, we must allow that much space.*/if (flags & SLAB_RED_ZONE)size += REDZONE_ALIGN;elsesize += BYTES_PER_WORD;}
#if FORCED_DEBUG && defined(CONFIG_DEBUG_PAGEALLOC)if (size >= kmalloc_size(INDEX_NODE + 1)&& cachep->object_size > cache_line_size()&& ALIGN(size, cachep->align) < PAGE_SIZE) {cachep->obj_offset += PAGE_SIZE - ALIGN(size, cachep->align);size = PAGE_SIZE;}
#endif
#endif/** Determine if the slab management is 'on' or 'off' slab.* (bootstrapping cannot cope with offslab caches so don't do* it too early on. Always use on-slab management when* SLAB_NOLEAKTRACE to avoid recursive calls into kmemleak)*/if ((size >= (PAGE_SIZE >> 5)/*128*/) && !slab_early_init && !(flags & SLAB_NOLEAKTRACE))/** Size is large, assume best to place the slab management obj* off-slab (should allow better packing of objs).*/flags |= CFLGS_OFF_SLAB; /*off-slab*//*size做对齐处理*/size = ALIGN(size, cachep->align);/** We should restrict the number of objects in a slab to implement* byte sized index. Refer comment on SLAB_OBJ_MIN_SIZE definition.*//*如果size小于SLAB_OBJ_MIN_SIZE,size取SLAB_OBJ_MIN_SIZE,且关于align对齐*/if (FREELIST_BYTE_INDEX && size < SLAB_OBJ_MIN_SIZE) size = ALIGN(SLAB_OBJ_MIN_SIZE, cachep->align); /*最小size值为SLAB_OBJ_MIN_SIZE,该值关于align对齐*//*最终obj对象的size大小和align对齐大小和传入的参数可能相去甚远,因为检查过程中会修改size和align值*//*计算一个slab需要多少个物理页面,同时页计算slabg中可以容纳多少个对象;此时还未进行物理页面的真正分配;通过增加打印信息,基本上小内存块size分配一个物理页面,大的内存块size也是分配少量物理页面满足需求即可。*/left_over = calculate_slab_order(cachep, size, cachep->align, flags);if (!cachep->num)return -E2BIG;/*freelist_size整体对齐所需空间*/freelist_size = calculate_freelist_size(cachep->num, cachep->align);/** If the slab has been placed off-slab, and we have enough space then* move it on-slab. This is at the expense of any extra colouring.*/if (flags & CFLGS_OFF_SLAB && left_over >= freelist_size) {flags &= ~CFLGS_OFF_SLAB; /*如果剩余空间足够大,就取消CFLGS_OFF_SLAB,放在slab内部*/left_over -= freelist_size;}if (flags & CFLGS_OFF_SLAB) {/* really off slab. No need for manual alignment */freelist_size = calculate_freelist_size(cachep->num, 0);#ifdef CONFIG_PAGE_POISONING/* If we're going to use the generic kernel_map_pages()* poisoning, then it's going to smash the contents of* the redzone and userword anyhow, so switch them off.*/if (size % PAGE_SIZE == 0 && flags & SLAB_POISON)flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
#endif}/*colour_off大小为cache line的大小*/cachep->colour_off = cache_line_size(); /*cache line大小*//* Offset must be a multiple of the alignment. */if (cachep->colour_off < cachep->align)cachep->colour_off = cachep->align;/*剩余空间中能够用于cachep->colour_off的个数,即着色使用的空间*/cachep->colour = left_over / cachep->colour_off;cachep->freelist_size = freelist_size;cachep->flags = flags;/*这里设置compound标志*/cachep->allocflags = __GFP_COMP;if (CONFIG_ZONE_DMA_FLAG && (flags & SLAB_CACHE_DMA))cachep->allocflags |= GFP_DMA;/*重新设置size值*/cachep->size = size;cachep->reciprocal_buffer_size = reciprocal_value(size);if (flags & CFLGS_OFF_SLAB) {/*如果管理数据off slab,则分配空间*/cachep->freelist_cache = kmalloc_slab(freelist_size, 0u);/** This is a possibility for one of the kmalloc_{dma,}_caches.* But since we go off slab only for object size greater than* PAGE_SIZE/8, and kmalloc_{dma,}_caches get created* in ascending order,this should not happen at all.* But leave a BUG_ON for some lucky dude.*/BUG_ON(ZERO_OR_NULL_PTR(cachep->freelist_cache));}/*设置cpu cache*/err = setup_cpu_cache(cachep, gfp);if (err) {__kmem_cache_shutdown(cachep);return err;}return 0;
}/*** calculate_slab_order - calculate size (page order) of slabs* @cachep: pointer to the cache that is being created* @size: size of objects to be created in this cache.* @align: required alignment for the objects.* @flags: slab allocation flags** Also calculates the number of objects per slab.** This could be made much more intelligent. For now, try to avoid using* high order pages for slabs. When the gfp() functions are more friendly* towards high-order requests, this should be changed.*/
static size_t calculate_slab_order(struct kmem_cache *cachep,size_t size, size_t align, unsigned long flags)
{unsigned long offslab_limit;size_t left_over = 0;int gfporder;printk("-----[f],%s,%x,%x,%x,%x,%x,%x \r\n",__func__,size,align,flags,slab_max_order,KMALLOC_MAX_ORDER,SLAB_OBJ_MAX_NUM);for (gfporder = 0; gfporder <= KMALLOC_MAX_ORDER; gfporder++) {unsigned int num;size_t remainder;/*预估占用内存页面的空间,slab对象个数,剩余空间*/cache_estimate(gfporder, size, align, flags, &remainder, &num);printk("%s,%x,%x,%x \r\n",__func__,gfporder,remainder,num);if (!num) /*最少也要能分配出一个obj对象*/continue;/* Can't handle number of objects more than SLAB_OBJ_MAX_NUM */if (num > SLAB_OBJ_MAX_NUM) /*对num最大值的限制(255)*/break;if (flags & CFLGS_OFF_SLAB) { /*管理slab的数据存放在slab自己内存空间之外*/size_t freelist_size_per_obj = sizeof(freelist_idx_t);/** Max number of objs-per-slab for caches which* use off-slab slabs. Needed to avoid a possible* looping condition in cache_grow().*/if (IS_ENABLED(CONFIG_DEBUG_SLAB_LEAK))freelist_size_per_obj += sizeof(char);offslab_limit = size;offslab_limit /= freelist_size_per_obj;if (num > offslab_limit) /*避免freelist占用过多空间*/break;}/* Found something acceptable - save it away */cachep->num = num;cachep->gfporder = gfporder;left_over = remainder;/** A VFS-reclaimable slab tends to have most allocations* as GFP_NOFS and we really don't want to have to be allocating* higher-order pages when we are unable to shrink dcache.*/if (flags & SLAB_RECLAIM_ACCOUNT)break;/** Large number of objects is good, but very large slabs are* currently bad for the gfp()s.*/if (gfporder >= slab_max_order) /*slab_max_order为1*/break;/** Acceptable internal fragmentation?*/if (left_over * 8 <= (PAGE_SIZE << gfporder)) /*剩余空间的占比<=总物理页面大小/8*/break;}printk("-----[e],%s,%x,%x\r\n",__func__,gfporder,left_over);return left_over;
}calculate_slab_order会计算一个slab需要多少个物理页面,同时计算slab中可以容纳多少个对象。
一个slab由2^gfporder个连续物理页面组成,包含num个slab对象,着色区和freelist区。
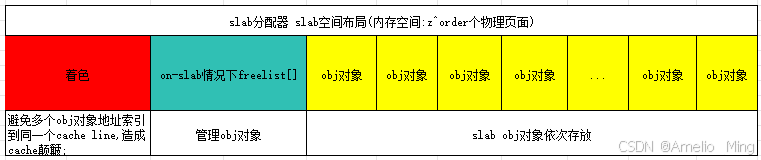
下面是内核启动阶段的打印信息:
[ 0.000000] -----[f],calculate_slab_order,80,40,2000,1,a,ff
[ 0.000000] calculate_slab_order,0,40,1f
[ 0.000000] -----[e],calculate_slab_order,0,40
[ 0.000000] -----[f],calculate_slab_order,40,40,2000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,3f
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,80,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,20
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,c0,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,40,15
[ 0.000000] -----[e],calculate_slab_order,0,40
[ 0.000000] -----[f],calculate_slab_order,100,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,10
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,200,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,8
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,400,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,4
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,800,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,2
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,1000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,0,1
[ 0.000000] -----[e],calculate_slab_order,0,0
[ 0.000000] -----[f],calculate_slab_order,2000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,0,1
[ 0.000000] -----[e],calculate_slab_order,1,0
[ 0.000000] -----[f],calculate_slab_order,4000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,0,1
[ 0.000000] -----[e],calculate_slab_order,2,0
[ 0.000000] -----[f],calculate_slab_order,8000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,0,1
[ 0.000000] -----[e],calculate_slab_order,3,0
[ 0.000000] -----[f],calculate_slab_order,10000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,0,1
[ 0.000000] -----[e],calculate_slab_order,4,0
[ 0.000000] -----[f],calculate_slab_order,20000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,0,1
[ 0.000000] -----[e],calculate_slab_order,5,0
[ 0.000000] -----[f],calculate_slab_order,40000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,20000,0
[ 0.000000] calculate_slab_order,6,0,1
[ 0.000000] -----[e],calculate_slab_order,6,0
[ 0.000000] -----[f],calculate_slab_order,80000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,20000,0
[ 0.000000] calculate_slab_order,6,40000,0
[ 0.000000] calculate_slab_order,7,0,1
[ 0.000000] -----[e],calculate_slab_order,7,0
[ 0.000000] -----[f],calculate_slab_order,100000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,20000,0
[ 0.000000] calculate_slab_order,6,40000,0
[ 0.000000] calculate_slab_order,7,80000,0
[ 0.000000] calculate_slab_order,8,0,1
[ 0.000000] -----[e],calculate_slab_order,8,0
[ 0.000000] -----[f],calculate_slab_order,200000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,20000,0
[ 0.000000] calculate_slab_order,6,40000,0
[ 0.000000] calculate_slab_order,7,80000,0
[ 0.000000] calculate_slab_order,8,100000,0
[ 0.000000] calculate_slab_order,9,0,1
[ 0.000000] -----[e],calculate_slab_order,9,0
[ 0.000000] -----[f],calculate_slab_order,400000,40,80002000,1,a,ff
[ 0.000000] calculate_slab_order,0,1000,0
[ 0.000000] calculate_slab_order,1,2000,0
[ 0.000000] calculate_slab_order,2,4000,0
[ 0.000000] calculate_slab_order,3,8000,0
[ 0.000000] calculate_slab_order,4,10000,0
[ 0.000000] calculate_slab_order,5,20000,0
[ 0.000000] calculate_slab_order,6,40000,0
[ 0.000000] calculate_slab_order,7,80000,0
[ 0.000000] calculate_slab_order,8,100000,0
[ 0.000000] calculate_slab_order,9,200000,0
[ 0.000000] calculate_slab_order,a,0,1
[ 0.000000] -----[e],calculate_slab_order,a,0
通过上面的打印信息可知,如果slab 对象的size很小,一般分配的一个物理页面即可(order=0),如果slab对象的size很大,一般分配的对象num为1,当然所需的物理页面也足够容纳对象size。
/** Calculate the number of objects and left-over bytes for a given buffer size.*/
static void cache_estimate(unsigned long gfporder, size_t buffer_size,size_t align, int flags, size_t *left_over,unsigned int *num)
{int nr_objs;size_t mgmt_size;/*2^gfporder个页面总共大小*/size_t slab_size = PAGE_SIZE << gfporder;/** The slab management structure can be either off the slab or* on it. For the latter case, the memory allocated for a* slab is used for:** - One unsigned int for each object* - Padding to respect alignment of @align* - @buffer_size bytes for each object** If the slab management structure is off the slab, then the* alignment will already be calculated into the size. Because* the slabs are all pages aligned, the objects will be at the* correct alignment when allocated.*/if (flags & CFLGS_OFF_SLAB) {mgmt_size = 0;/*无其他额外数据,所用页面都用来存放slab对象*/nr_objs = slab_size / buffer_size;} else {/*计算slab对象个数*/nr_objs = calculate_nr_objs(slab_size, buffer_size,sizeof(freelist_idx_t), align);/*计算freelist_size大小,mgmt_size就是每个obj对象需要占用一个 freelist_idx_t的空间*/mgmt_size = calculate_freelist_size(nr_objs, align);}/*slab对象的个数*/*num = nr_objs;/*剩余空间大小*/*left_over = slab_size - nr_objs*buffer_size - mgmt_size;
}static int calculate_nr_objs(size_t slab_size, size_t buffer_size,size_t idx_size, size_t align)
{int nr_objs;size_t remained_size;size_t freelist_size;int extra_space = 0;if (IS_ENABLED(CONFIG_DEBUG_SLAB_LEAK))extra_space = sizeof(char);/** Ignore padding for the initial guess. The padding* is at most @align-1 bytes, and @buffer_size is at* least @align. In the worst case, this result will* be one greater than the number of objects that fit* into the memory allocation when taking the padding* into account.*//*多占用idx_size,extra_space的空间*/nr_objs = slab_size / (buffer_size + idx_size + extra_space);/** This calculated number will be either the right* amount, or one greater than what we want.*/remained_size = slab_size - nr_objs * buffer_size;/*freelist_size整体对齐*/freelist_size = calculate_freelist_size(nr_objs, align);if (remained_size < freelist_size)nr_objs--;return nr_objs;
}static size_t calculate_freelist_size(int nr_objs, size_t align)
{size_t freelist_size;freelist_size = nr_objs * sizeof(freelist_idx_t);if (IS_ENABLED(CONFIG_DEBUG_SLAB_LEAK))freelist_size += nr_objs * sizeof(char);/*freelist_size整体对齐*/if (align)freelist_size = ALIGN(freelist_size, align);return freelist_size;
}调用setup_cpu_cache来继续配置slab描述符。假设slab_state为FULL,即slab机制已经初始化完成,内部调用enable_cpucache继续进行处理。
setup_cpu_cache->enable_cpucache
/* Called with slab_mutex held always */
static int enable_cpucache(struct kmem_cache *cachep, gfp_t gfp)
{int err;int limit = 0;int shared = 0;int batchcount = 0;if (!is_root_cache(cachep)) {struct kmem_cache *root = memcg_root_cache(cachep);limit = root->limit;shared = root->shared;batchcount = root->batchcount;}if (limit && shared && batchcount)goto skip_setup;/** The head array serves three purposes:* - create a LIFO ordering, i.e. return objects that are cache-warm* - reduce the number of spinlock operations.* - reduce the number of linked list operations on the slab and* bufctl chains: array operations are cheaper.* The numbers are guessed, we should auto-tune as described by* Bonwick.*//*根据slab对象大小设置limit值*/if (cachep->size > 131072) /*>128K*/limit = 1;else if (cachep->size > PAGE_SIZE) /*>4k*/limit = 8;else if (cachep->size > 1024) /*>1k*/limit = 24;else if (cachep->size > 256) /*>256*/limit = 54;else /*<256*/limit = 120;/** CPU bound tasks (e.g. network routing) can exhibit cpu bound* allocation behaviour: Most allocs on one cpu, most free operations* on another cpu. For these cases, an efficient object passing between* cpus is necessary. This is provided by a shared array. The array* replaces Bonwick's magazine layer.* On uniprocessor, it's functionally equivalent (but less efficient)* to a larger limit. Thus disabled by default.*/shared = 0;if (cachep->size <= PAGE_SIZE && num_possible_cpus() > 1)shared = 8; /*slab obj对象size不超个PAGE_SIZE且为多核情况*/#if DEBUG/** With debugging enabled, large batchcount lead to excessively long* periods with disabled local interrupts. Limit the batchcount*/if (limit > 32)limit = 32;
#endif/*batchcount为limit的一半*/batchcount = (limit + 1) / 2;
skip_setup:err = do_tune_cpucache(cachep, limit, batchcount, shared, gfp);if (err)printk(KERN_ERR "enable_cpucache failed for %s, error %d.\n",cachep->name, -err);return err;
}继续调用do_tune_cpucahce来配置slab描述符。
do_tune_cpucache->__do_tune_cpucache
/* Always called with the slab_mutex held */
static int __do_tune_cpucache(struct kmem_cache *cachep, int limit,int batchcount, int shared, gfp_t gfp)
{struct array_cache __percpu *cpu_cache, *prev;int cpu;/*分配一个per-cpu变量,本地cpu缓存区;分配空间大小,size = sizeof(void *)*limit+sizeof(struct array_cache);注意,struct array_cache中的entry[]的大小和limit直接相关;*/cpu_cache = alloc_kmem_cache_cpus(cachep, limit, batchcount);if (!cpu_cache)return -ENOMEM;prev = cachep->cpu_cache; /*保存cpu_cache旧值*/cachep->cpu_cache = cpu_cache;kick_all_cpus_sync();check_irq_on();cachep->batchcount = batchcount;cachep->limit = limit;/*多核且slab obj对象size不超过page size情况下shared值为8*/cachep->shared = shared;if (!prev) /*每个slab描述符对应一个slab节点(kmem_cache_node数据结构)*/goto alloc_node;/*prev存在情况,即slab描述符中已经存在array_cache,理论上应该,需要destroy slab描述符*/for_each_online_cpu(cpu) {LIST_HEAD(list);int node;struct kmem_cache_node *n;/*获取遍历cpu对应的array_cache*/struct array_cache *ac = per_cpu_ptr(prev, cpu);node = cpu_to_mem(cpu);n = get_node(cachep, node);spin_lock_irq(&n->list_lock);free_block(cachep, ac->entry, ac->avail, node, &list);spin_unlock_irq(&n->list_lock);slabs_destroy(cachep, &list);}free_percpu(prev);alloc_node:/*分配并初始化kmem_cache_node*/return alloc_kmem_cache_node(cachep, gfp);
}include/linux/nodemask.h
typedef struct { DECLARE_BITMAP(bits, MAX_NUMNODES); } nodemask_t;/** Array of node states.*/
nodemask_t node_states[NR_NODE_STATES] __read_mostly = {[N_POSSIBLE] = NODE_MASK_ALL,[N_ONLINE] = { { [0] = 1UL } },
#ifndef CONFIG_NUMA[N_NORMAL_MEMORY] = { { [0] = 1UL } },
#ifdef CONFIG_HIGHMEM[N_HIGH_MEMORY] = { { [0] = 1UL } },
#endif
#ifdef CONFIG_MOVABLE_NODE[N_MEMORY] = { { [0] = 1UL } },
#endif[N_CPU] = { { [0] = 1UL } },
#endif /* NUMA */
};/*遍历online状态位图*/
#define for_each_online_node(node) for_each_node_state(node, N_ONLINE)#define for_each_node_state(__node, __state) for_each_node_mask((__node), node_states[__state])
通过上面的定义可知,node_states[N_ONLINE] 的bit 0初始化为1,那么在遍历node_states[N_ONLINE]位图时,bit 0是有效的。/** This initializes kmem_cache_node or resizes various caches for all nodes.*/
static int alloc_kmem_cache_node(struct kmem_cache *cachep, gfp_t gfp)
{int node;struct kmem_cache_node *n;struct array_cache *new_shared;struct alien_cache **new_alien = NULL;printk("----[f]%s,%x \r\n",__func__,use_alien_caches);/*根据 node_states 位图配置,online状态中node=0是成立的*/for_each_online_node(node) { /*非NUMA结构下应该有一个node存在*/if (use_alien_caches) {new_alien = alloc_alien_cache(node, cachep->limit, gfp);if (!new_alien)goto fail;}new_shared = NULL;/*多核且slab obj对象size不超过page size情况下shared值为8*/if (cachep->shared) {/*分配并初始化array_cache 用于多核之间共享使用,这个batchcount值:0xbaadf00d*/new_shared = alloc_arraycache(node,cachep->shared*cachep->batchcount,0xbaadf00d, gfp);if (!new_shared) {free_alien_cache(new_alien);goto fail;}}n = get_node(cachep, node);if (n) {struct array_cache *shared = n->shared;LIST_HEAD(list);spin_lock_irq(&n->list_lock);if (shared)free_block(cachep, shared->entry,shared->avail, node, &list);n->shared = new_shared;if (!n->alien) {n->alien = new_alien;new_alien = NULL;}n->free_limit = (1 + nr_cpus_node(node)) * cachep->batchcount + cachep->num;spin_unlock_irq(&n->list_lock);slabs_destroy(cachep, &list);kfree(shared);free_alien_cache(new_alien);continue;}/*分配kmem_cache_node*/n = kmalloc_node(sizeof(struct kmem_cache_node), gfp, node);if (!n) {free_alien_cache(new_alien);kfree(new_shared);goto fail;}/*初始化kmem_cache_node*/kmem_cache_node_init(n);/*周期后台回收 4HZ*/n->next_reap = jiffies + REAPTIMEOUT_NODE + ((unsigned long)cachep) % REAPTIMEOUT_NODE;/*分配slab节点上的共享缓存区,共享缓存区中的obj对象什么是否分配?*/n->shared = new_shared;n->alien = new_alien;n->free_limit = (1 + nr_cpus_node(node)) * cachep->batchcount + cachep->num;cachep->node[node] = n; /*注意存放位置*/}return 0;fail:if (!cachep->list.next) {/* Cache is not active yet. Roll back what we did */node--;while (node >= 0) {n = get_node(cachep, node);if (n) {kfree(n->shared);free_alien_cache(n->alien);kfree(n);cachep->node[node] = NULL;}node--;}}return -ENOMEM;
}static void kmem_cache_node_init(struct kmem_cache_node *parent)
{INIT_LIST_HEAD(&parent->slabs_full);INIT_LIST_HEAD(&parent->slabs_partial);INIT_LIST_HEAD(&parent->slabs_free);parent->shared = NULL;parent->alien = NULL;parent->colour_next = 0;spin_lock_init(&parent->list_lock);parent->free_objects = 0;parent->free_touched = 0;
}static struct array_cache __percpu *alloc_kmem_cache_cpus(struct kmem_cache *cachep, int entries, int batchcount)
{int cpu;size_t size;struct array_cache __percpu *cpu_cache;size = sizeof(void *) * entries + sizeof(struct array_cache);/*分配一个per-cpu变量*/cpu_cache = __alloc_percpu(size, sizeof(void *));if (!cpu_cache)return NULL;for_each_possible_cpu(cpu) {init_arraycache(per_cpu_ptr(cpu_cache, cpu),entries, batchcount);}return cpu_cache;
}static void init_arraycache(struct array_cache *ac, int limit, int batch)
{/** The array_cache structures contain pointers to free object.* However, when such objects are allocated or transferred to another* cache the pointers are not cleared and they could be counted as* valid references during a kmemleak scan. Therefore, kmemleak must* not scan such objects.*/kmemleak_no_scan(ac);if (ac) {ac->avail = 0; /*新创建的slab描述符中的arrar_cache中的avail值为0*/ac->limit = limit;ac->batchcount = batch;ac->touched = 0;}
}2、分配slab对象
kmem_cache_alloc是分配slab缓存对象的核心函数,在slab分配过程中是全程关闭本地中断。
/*** kmem_cache_alloc - Allocate an object* @cachep: The cache to allocate from.* @flags: See kmalloc().** Allocate an object from this cache. The flags are only relevant* if the cache has no available objects.*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{void *ret = slab_alloc(cachep, flags, _RET_IP_);trace_kmem_cache_alloc(_RET_IP_, ret,cachep->object_size, cachep->size, flags);return ret;
}static __always_inline void * slab_alloc(struct kmem_cache *cachep, gfp_t flags, unsigned long caller)
{unsigned long save_flags;void *objp;flags &= gfp_allowed_mask;lockdep_trace_alloc(flags);if (slab_should_failslab(cachep, flags))return NULL;cachep = memcg_kmem_get_cache(cachep, flags);cache_alloc_debugcheck_before(cachep, flags);local_irq_save(save_flags); /*关闭本地cpu中断*//*分配slab对象*/objp = __do_cache_alloc(cachep, flags);local_irq_restore(save_flags); /*开启本地cpu中断*/objp = cache_alloc_debugcheck_after(cachep, flags, objp, caller);kmemleak_alloc_recursive(objp, cachep->object_size, 1, cachep->flags,flags);prefetchw(objp);if (likely(objp)) {kmemcheck_slab_alloc(cachep, flags, objp, cachep->object_size);if (unlikely(flags & __GFP_ZERO))memset(objp, 0, cachep->object_size);}memcg_kmem_put_cache(cachep);return objp;
}static __always_inline void * __do_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{return ____cache_alloc(cachep, flags);
}static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{void *objp;struct array_cache *ac;bool force_refill = false;check_irq_off();/*获取本地cpu的per-cpu变量array_cache;疑问,slab描述符是在cpu1上创建的,且在cpu1上已经完成slab对象的分配;现在在cpu2上执行alloc分配操作结果如何?此时cpu2本地缓存中肯定是没有slab对象的,如果是多核情况则查看共享缓存区中是否有slab对象,共享缓存区有则从共享缓存区分配batchcount个对象到cpu2本地缓存区中,如果共享缓存区无则查看slab节点(kmem_cache_node)的slab部分/空闲链表中是否存在有效物理页面,如果存在则从物理页面从分配slab对象,如果无则只能借助伙伴系统来分配物理页面再从物理页面中分配batchcount个对象到cpu2本地缓存区中用于分配使用。*/ac = cpu_cache_get(cachep);if (likely(ac->avail)) { /*缓存池中存在可分配对象,但是新创建的slab描述符中的avail应该是0*/ac->touched = 1;objp = ac_get_obj(cachep, ac, flags, false);/** Allow for the possibility all avail objects are not allowed* by the current flags*/if (objp) {STATS_INC_ALLOCHIT(cachep);goto out;}/*获取失败,需要填充本地缓冲区,设置force_refill为true*/force_refill = true;}STATS_INC_ALLOCMISS(cachep);/*缓存池中无可用对象用于分配*/objp = cache_alloc_refill(cachep, flags, force_refill);/** the 'ac' may be updated by cache_alloc_refill(),* and kmemleak_erase() requires its correct value.*/ac = cpu_cache_get(cachep);out:/** To avoid a false negative, if an object that is in one of the* per-CPU caches is leaked, we need to make sure kmemleak doesn't* treat the array pointers as a reference to the object.*/if (objp)kmemleak_erase(&ac->entry[ac->avail]);return objp;
}static inline void *ac_get_obj(struct kmem_cache *cachep,struct array_cache *ac, gfp_t flags, bool force_refill)
{void *objp;if (unlikely(sk_memalloc_socks()))objp = __ac_get_obj(cachep, ac, flags, force_refill);elseobjp = ac->entry[--ac->avail]; /*直接从entry[]中获取*/return objp;
}static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags,bool force_refill)
{int batchcount;struct kmem_cache_node *n;struct array_cache *ac;int node;check_irq_off();node = numa_mem_id();if (unlikely(force_refill))goto force_grow;
retry:ac = cpu_cache_get(cachep);batchcount = ac->batchcount;if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {/** If there was little recent activity on this cache, then* perform only a partial refill. Otherwise we could generate* refill bouncing.*/batchcount = BATCHREFILL_LIMIT;}/*获取kmem_cache_node节点*/n = get_node(cachep, node);BUG_ON(ac->avail > 0 || !n);spin_lock(&n->list_lock);/* See if we can refill from the shared array *//*支持shared则从shared中拷贝batchcount个 slab对象到ac中;kmem_cache_node中shared在什么地方进行设置? 在kmem_cache_free中设置,free的slab对象回收到cpu本地缓存区,如果本地缓存区数量超过limit值则移动batchcount个obj对象到共享缓存区中。*/if (n->shared && transfer_objects(ac, n->shared, batchcount)) {n->shared->touched = 1;goto alloc_done;}/*共享缓存区无obj对象则从slab节点的slab部分/空闲链表中通过物理页面来分配*/ while (batchcount > 0) {struct list_head *entry;struct page *page;/* Get slab alloc is to come from. */entry = n->slabs_partial.next;if (entry == &n->slabs_partial) {n->free_touched = 1; /*node的slab部分链表为空*/entry = n->slabs_free.next;if (entry == &n->slabs_free) /*node的slab空闲链表也为空,则必须从伙伴系统中进行物理页面的分配*/goto must_grow;}/*从slab链表中获取物理页面进行obj对象的分配*/page = list_entry(entry, struct page, lru);check_spinlock_acquired(cachep);/** The slab was either on partial or free list so* there must be at least one object available for* allocation.*/BUG_ON(page->active >= cachep->num); /*上述两个链表中不应该出现page中无空间分配slab obj对象的情况*//*每次从kmem_cache_node中最大分配batchcount个slab obj对象到本地cpu slab缓存区entry[]中*/while (page->active < cachep->num && batchcount--) {STATS_INC_ALLOCED(cachep);STATS_INC_ACTIVE(cachep);STATS_SET_HIGH(cachep);/*将slab obj对象放到本地cpu缓存区entry[]中*/ac_put_obj(cachep, ac, slab_get_obj(cachep, page,node)/*从slab物理页面中分配obj对象*/);}/* move slabp to correct slabp list: */list_del(&page->lru);if (page->active == cachep->num) /*物理页面空间已经全部用于slab obj对象分配,则将其挂接到slabs_full链表上*/list_add(&page->lru, &n->slabs_full);elselist_add(&page->lru, &n->slabs_partial); /*物理页面空间部分用于slab obj对象分配,则将其挂接到slabs_partial链表上*/}must_grow:n->free_objects -= ac->avail;
alloc_done:spin_unlock(&n->list_lock);if (unlikely(!ac->avail)) { /*当前cpu中的本地缓存区array_cache中无可用slab对象*/int x;
force_grow:/*伙伴系统分配物理页面用于slab分配器*/x = cache_grow(cachep, flags | GFP_THISNODE, node, NULL);/* cache_grow can reenable interrupts, then ac could change. *//*获取本地cpu的array_cache*/ac = cpu_cache_get(cachep);node = numa_mem_id();/* no objects in sight? abort */if (!x && (ac->avail == 0 || force_refill))return NULL;/*前面cache_grow已经分配了物理页面但是并未添加到本地缓存中,所以本地缓存中还是无可用的obj对象用于分配,需要跳转到retry,分配batchcount个obj对象到cpu本地缓存区中。*/if (!ac->avail) /* objects refilled by interrupt? */goto retry;}ac->touched = 1;/*从本地缓存区中获取obj对象*/return ac_get_obj(cachep, ac, flags, force_refill);
}static inline freelist_idx_t get_free_obj(struct page *page, unsigned int idx)
{return ((freelist_idx_t *)page->freelist)[idx];
}static inline void *index_to_obj(struct kmem_cache *cache, struct page *page,unsigned int idx)
{return page->s_mem + cache->size * idx;
}/*obj对象在整个slab对象中的index索引号*/
static inline unsigned int obj_to_index(const struct kmem_cache *cache,const struct page *page, void *obj)
{u32 offset = (obj - page->s_mem); /*偏移量*/return reciprocal_divide(offset, cache->reciprocal_buffer_size);
}/*从slab物理页面中分配obj对象*/
static void *slab_get_obj(struct kmem_cache *cachep, struct page *page,int nodeid)
{void *objp;/*从分配的物理页面中分配一个obj对象*/objp = index_to_obj(cachep, page, get_free_obj(page, page->active)); /*page->s_mem + cache->size * idx*/page->active++; /*active标识物理已经分配的obj对象个数或者活跃obj对象个数*/
#if DEBUGWARN_ON(page_to_nid(virt_to_page(objp)) != nodeid);
#endifreturn objp;
}/*将obj对象释放会slab物理页面*/
static void slab_put_obj(struct kmem_cache *cachep, struct page *page,void *objp, int nodeid)
{/*obj对象在整个slab中的index索引号*/unsigned int objnr = obj_to_index(cachep, page, objp);
#if DEBUGunsigned int i;/* Verify that the slab belongs to the intended node */WARN_ON(page_to_nid(virt_to_page(objp)) != nodeid);/* Verify double free bug */for (i = page->active; i < cachep->num; i++) {if (get_free_obj(page, i) == objnr) {printk(KERN_ERR "slab: double free detected in cache ""'%s', objp %p\n", cachep->name, objp);BUG();}}
#endifpage->active--;set_free_obj(page, page->active, objnr);
}/*将slab obj对象放到本地cpu缓存区中*/
static inline void ac_put_obj(struct kmem_cache *cachep, struct array_cache *ac,void *objp)
{if (unlikely(sk_memalloc_socks()))objp = __ac_put_obj(cachep, ac, objp);/*将slab obj对象放到本地cpu缓存区中*/ac->entry[ac->avail++] = objp;
}/*从本地cpu缓存区中获取slab obj对象*/
static inline void *ac_get_obj(struct kmem_cache *cachep,struct array_cache *ac, gfp_t flags, bool force_refill)
{void *objp;if (unlikely(sk_memalloc_socks()))objp = __ac_get_obj(cachep, ac, flags, force_refill);elseobjp = ac->entry[--ac->avail]; /*直接从entry[]中获取*/return objp;
}/** Transfer objects in one arraycache to another.* Locking must be handled by the caller.** Return the number of entries transferred.*/
static int transfer_objects(struct array_cache *to,struct array_cache *from, unsigned int max)
{/* Figure out how many entries to transfer */int nr = min3(from->avail, max, to->limit - to->avail);if (!nr)return 0;/*从from中拷贝对象到to中*/memcpy(to->entry + to->avail, from->entry + from->avail -nr,sizeof(void *) *nr);from->avail -= nr;to->avail += nr;return nr;
}/** Grow (by 1) the number of slabs within a cache. This is called by* kmem_cache_alloc() when there are no active objs left in a cache.*/
static int cache_grow(struct kmem_cache *cachep,gfp_t flags, int nodeid, struct page *page)
{void *freelist;size_t offset;gfp_t local_flags;struct kmem_cache_node *n;/** Be lazy and only check for valid flags here, keeping it out of the* critical path in kmem_cache_alloc().*/if (unlikely(flags & GFP_SLAB_BUG_MASK)) {pr_emerg("gfp: %u\n", flags & GFP_SLAB_BUG_MASK);BUG();}local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);/* Take the node list lock to change the colour_next on this node */check_irq_off();n = get_node(cachep, nodeid);spin_lock(&n->list_lock);/* Get colour for the slab, and cal the next value. *//*slab分配器中着色的处理*/offset = n->colour_next;n->colour_next++;if (n->colour_next >= cachep->colour)n->colour_next = 0;spin_unlock(&n->list_lock);/*着色本质是将空闲空间前移,错开cache line颠簸*/offset *= cachep->colour_off; /*colour_off大小为cache line的大小*/if (local_flags & __GFP_WAIT)local_irq_enable();/** The test for missing atomic flag is performed here, rather than* the more obvious place, simply to reduce the critical path length* in kmem_cache_alloc(). If a caller is seriously mis-behaving they* will eventually be caught here (where it matters).*/kmem_flagcheck(cachep, flags);/** Get mem for the objs. Attempt to allocate a physical page from* 'nodeid'.*/if (!page) /*从伙伴系统中分配物理页面*/page = kmem_getpages(cachep, local_flags, nodeid);if (!page)goto failed;/* Get slab management. *//*整个slab物理页面的布局管理*/freelist = alloc_slabmgmt(cachep, page, offset, local_flags & ~GFP_CONSTRAINT_MASK, nodeid);if (!freelist)goto opps1;slab_map_pages(cachep, page, freelist);/*设备每个obj对象*/cache_init_objs(cachep, page);if (local_flags & __GFP_WAIT)local_irq_disable();check_irq_off();spin_lock(&n->list_lock);/* Make slab active. *//*将page添加到slabs_free链表中*/list_add_tail(&page->lru, &(n->slabs_free));STATS_INC_GROWN(cachep);/*node中空闲free_objects数量增加*/n->free_objects += cachep->num;spin_unlock(&n->list_lock);return 1;
opps1:kmem_freepages(cachep, page);
failed:if (local_flags & __GFP_WAIT)local_irq_disable();return 0;
}kmem_getpages从伙伴系统中分配slab描述符所需的物理页面数量。
/** Interface to system's page allocator. No need to hold the* kmem_cache_node ->list_lock.** If we requested dmaable memory, we will get it. Even if we* did not request dmaable memory, we might get it, but that* would be relatively rare and ignorable.*/
static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags,int nodeid)
{struct page *page;int nr_pages;/*注意,slab描述符中 cachep->allocflags默认设置为__GFP_COMP;该标志使得在prep_compound_page 中slab物理页面中后面每个物理页面都能通过p->first_page 找头物理页面*/flags |= cachep->allocflags;if (cachep->flags & SLAB_RECLAIM_ACCOUNT)flags |= __GFP_RECLAIMABLE;if (memcg_charge_slab(cachep, flags, cachep->gfporder))return NULL;/*调用__alloc_pages 分配物理页面,分配完物理页面最后检查时的prep_compound_page中会处理__GFP_COMP标志*/page = alloc_pages_exact_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);if (!page) {memcg_uncharge_slab(cachep, cachep->gfporder);slab_out_of_memory(cachep, flags, nodeid);return NULL;}/* Record if ALLOC_NO_WATERMARKS was set when allocating the slab */if (unlikely(page->pfmemalloc))pfmemalloc_active = true;nr_pages = (1 << cachep->gfporder);if (cachep->flags & SLAB_RECLAIM_ACCOUNT)add_zone_page_state(page_zone(page),NR_SLAB_RECLAIMABLE, nr_pages);elseadd_zone_page_state(page_zone(page),NR_SLAB_UNRECLAIMABLE, nr_pages);__SetPageSlab(page);if (page->pfmemalloc)SetPageSlabPfmemalloc(page);if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);if (cachep->ctor)kmemcheck_mark_uninitialized_pages(page, nr_pages);elsekmemcheck_mark_unallocated_pages(page, nr_pages);}return page;
}/** Get the memory for a slab management obj.** For a slab cache when the slab descriptor is off-slab, the* slab descriptor can't come from the same cache which is being created,* Because if it is the case, that means we defer the creation of* the kmalloc_{dma,}_cache of size sizeof(slab descriptor) to this point.* And we eventually call down to __kmem_cache_create(), which* in turn looks up in the kmalloc_{dma,}_caches for the disired-size one.* This is a "chicken-and-egg" problem.** So the off-slab slab descriptor shall come from the kmalloc_{dma,}_caches,* which are all initialized during kmem_cache_init().*/
static void *alloc_slabmgmt(struct kmem_cache *cachep,struct page *page, int colour_off,gfp_t local_flags, int nodeid)
{void *freelist;/*page物理页面对应的虚拟地址*/void *addr = page_address(page);if (OFF_SLAB(cachep)) {/* Slab management obj is off-slab. */freelist = kmem_cache_alloc_node(cachep->freelist_cache,local_flags, nodeid);if (!freelist)return NULL;} else {freelist = addr + colour_off; /*着色偏移后面存放freelist管理数据*/colour_off += cachep->freelist_size;}/*active设置为0*/page->active = 0;/*在addr基础上做偏移(着色)后才使用该地址,并不是每个slab对象需要偏移,而是每次进行slab整体空间分配时才需要*/page->s_mem = addr + colour_off;return freelist;
}include/linux/mm.h
#define page_address(page) lowmem_page_address(page)static __always_inline void *lowmem_page_address(const struct page *page)
{return __va(PFN_PHYS(page_to_pfn(page)));
}#define page_to_pfn __page_to_pfn
#define pfn_to_page __pfn_to_page#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)/*页框号对应的物理地址*/
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)/** Map pages beginning at addr to the given cache and slab. This is required* for the slab allocator to be able to lookup the cache and slab of a* virtual address for kfree, ksize, and slab debugging.*/
static void slab_map_pages(struct kmem_cache *cache, struct page *page,void *freelist)
{/*page内部也存在数据结构 指向slab描述符*/page->slab_cache = cache;page->freelist = freelist;
}/*page为第一个物理页面*/
static void cache_init_objs(struct kmem_cache *cachep,struct page *page)
{int i;for (i = 0; i < cachep->num; i++) {void *objp = index_to_obj(cachep, page, i); /*page->s_mem + cache->size*idx*/
#if DEBUG/* need to poison the objs? */if (cachep->flags & SLAB_POISON)poison_obj(cachep, objp, POISON_FREE);if (cachep->flags & SLAB_STORE_USER)*dbg_userword(cachep, objp) = NULL;if (cachep->flags & SLAB_RED_ZONE) {*dbg_redzone1(cachep, objp) = RED_INACTIVE;*dbg_redzone2(cachep, objp) = RED_INACTIVE;}/** Constructors are not allowed to allocate memory from the same* cache which they are a constructor for. Otherwise, deadlock.* They must also be threaded.*/if (cachep->ctor && !(cachep->flags & SLAB_POISON))cachep->ctor(objp + obj_offset(cachep));if (cachep->flags & SLAB_RED_ZONE) {if (*dbg_redzone2(cachep, objp) != RED_INACTIVE)slab_error(cachep, "constructor overwrote the"" end of an object");if (*dbg_redzone1(cachep, objp) != RED_INACTIVE)slab_error(cachep, "constructor overwrote the"" start of an object");}if ((cachep->size % PAGE_SIZE) == 0 &&OFF_SLAB(cachep) && cachep->flags & SLAB_POISON)kernel_map_pages(virt_to_page(objp),cachep->size / PAGE_SIZE, 0);
#elseif (cachep->ctor)cachep->ctor(objp);
#endifset_obj_status(page, i, OBJECT_FREE);set_free_obj(page, i, i);}
}static inline void set_free_obj(struct page *page,unsigned int idx, freelist_idx_t val)
{((freelist_idx_t *)(page->freelist))[idx] = val;
}
3、释放slab对象
释放slab缓存对象使用kmem_cache_free接口。
/*** kmem_cache_free - Deallocate an object* @cachep: The cache the allocation was from.* @objp: The previously allocated object.** Free an object which was previously allocated from this* cache.*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{unsigned long flags;/*获取obj对应的kmem_cache slab描述符*/cachep = cache_from_obj(cachep, objp);if (!cachep)return;local_irq_save(flags); /*关闭本地cpu中断*/debug_check_no_locks_freed(objp, cachep->object_size);if (!(cachep->flags & SLAB_DEBUG_OBJECTS))debug_check_no_obj_freed(objp, cachep->object_size);/*释放obj对象*/__cache_free(cachep, objp, _RET_IP_);local_irq_restore(flags); /*开启本地cpu中断*/trace_kmem_cache_free(_RET_IP_, objp);
}/** Release an obj back to its cache. If the obj has a constructed state, it must* be in this state _before_ it is released. Called with disabled ints.*/
static inline void __cache_free(struct kmem_cache *cachep, void *objp,unsigned long caller)
{/*获取本地cpu obj对象缓存区*/struct array_cache *ac = cpu_cache_get(cachep);check_irq_off();kmemleak_free_recursive(objp, cachep->flags);objp = cache_free_debugcheck(cachep, objp, caller);kmemcheck_slab_free(cachep, objp, cachep->object_size);/** Skip calling cache_free_alien() when the platform is not numa.* This will avoid cache misses that happen while accessing slabp (which* is per page memory reference) to get nodeid. Instead use a global* variable to skip the call, which is mostly likely to be present in* the cache.*/if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))return;if (ac->avail < ac->limit) { /*小于限制值,直接回收到本地缓存区*/STATS_INC_FREEHIT(cachep);} else {STATS_INC_FREEMISS(cachep); /*超高限制值,需要将batchcount个obj对象放回共享缓存区*/cache_flusharray(cachep, ac);}/*将slab obj对象放到本地cpu缓存区entry[]中*/ac_put_obj(cachep, ac, objp);
}static void cache_flusharray(struct kmem_cache *cachep, struct array_cache *ac)
{int batchcount;struct kmem_cache_node *n;int node = numa_mem_id();LIST_HEAD(list);batchcount = ac->batchcount;
#if DEBUGBUG_ON(!batchcount || batchcount > ac->avail);
#endifcheck_irq_off();/*slab节点*/n = get_node(cachep, node);spin_lock(&n->list_lock);if (n->shared) {struct array_cache *shared_array = n->shared;int max = shared_array->limit - shared_array->avail;if (max) { /*avail < limit则继续往共享缓存区中存放obj对象*/if (batchcount > max)batchcount = max;/*将数据从本地cpuu缓存区拷贝到slab节点 sharedan共享缓存区中*/memcpy(&(shared_array->entry[shared_array->avail]),ac->entry, sizeof(void *) * batchcount);shared_array->avail += batchcount;goto free_done;}}/*avail等于limit,共享缓存区无法存放更多的obj对象,只能释放batchount个本地缓存区obj对象回物理页面中*/free_block(cachep, ac->entry, batchcount, node, &list);
free_done:
#if STATS{int i = 0;struct list_head *p;p = n->slabs_free.next;while (p != &(n->slabs_free)) {struct page *page;page = list_entry(p, struct page, lru);BUG_ON(page->active);i++;p = p->next;}STATS_SET_FREEABLE(cachep, i);}
#endifspin_unlock(&n->list_lock);/*如果存在整个slab的物理页面中无活跃的obj对象则释放整个物理页面,被释放的物理页面page挂接在list上,最后伙伴系统释放物理页面*/slabs_destroy(cachep, &list);ac->avail -= batchcount;/*填充被移动到shared共享缓存区的对象留下的空位*/memmove(ac->entry, &(ac->entry[batchcount]), sizeof(void *)*ac->avail);
}/** Caller needs to acquire correct kmem_cache_node's list_lock* @list: List of detached free slabs should be freed by caller*/
static void free_block(struct kmem_cache *cachep, void **objpp,int nr_objects, int node, struct list_head *list)
{int i;struct kmem_cache_node *n = get_node(cachep, node);for (i = 0; i < nr_objects; i++) {void *objp;struct page *page;clear_obj_pfmemalloc(&objpp[i]);objp = objpp[i];/*obj对象对应的首物理页面*/page = virt_to_head_page(objp);list_del(&page->lru); /*从链表上删除页表*/check_spinlock_acquired_node(cachep, node);slab_put_obj(cachep, page, objp, node);STATS_DEC_ACTIVE(cachep);n->free_objects++;/* fixup slab chains */if (page->active == 0) { /*物理页面中无活跃的obj对象,即整个物理页面可以进行回收*/if (n->free_objects > n->free_limit) {n->free_objects -= cachep->num;list_add_tail(&page->lru, list); /*添加到list上*/} else {list_add(&page->lru, &n->slabs_free);}} else {/* Unconditionally move a slab to the end of the* partial list on free - maximum time for the* other objects to be freed, too.*/list_add_tail(&page->lru, &n->slabs_partial);}}
}static void slabs_destroy(struct kmem_cache *cachep, struct list_head *list)
{struct page *page, *n;list_for_each_entry_safe(page, n, list, lru) {list_del(&page->lru); /*物理页面从list上删除*/slab_destroy(cachep, page); /*伙伴系统回收物理页面*/}
}/*** slab_destroy - destroy and release all objects in a slab* @cachep: cache pointer being destroyed* @page: page pointer being destroyed** Destroy all the objs in a slab page, and release the mem back to the system.* Before calling the slab page must have been unlinked from the cache. The* kmem_cache_node ->list_lock is not held/needed.*/
static void slab_destroy(struct kmem_cache *cachep, struct page *page)
{void *freelist;freelist = page->freelist;slab_destroy_debugcheck(cachep, page);if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {struct rcu_head *head;/** RCU free overloads the RCU head over the LRU.* slab_page has been overloeaded over the LRU,* however it is not used from now on so that* we can use it safely.*/head = (void *)&page->rcu_head;call_rcu(head, kmem_rcu_free);} else { /*通过伙伴系统释放物理页面*/kmem_freepages(cachep, page);}/** From now on, we don't use freelist* although actual page can be freed in rcu context*/if (OFF_SLAB(cachep)) /*释放freelist的空间*/kmem_cache_free(cachep->freelist_cache, freelist);
}
注意,最开始存放到本次cpu对象缓存区的对象是按照虚拟地址递增的顺序存放batchcount个对象。经过中间无数次的分配和回收操作后,本地cpu对象缓存区entry[]中的
对象的虚拟地址就是乱序的,因此本地cpu对象缓存区回收对象时是直接存放到entry[avail++]中的,此时的虚拟地址毫无顺序可言。
相关文章:
linux 内存管理-slab分配器
伙伴系统用于分配以page为单位的内存,在实际中很多内存需求是以Byte为单位的,如果需要分配以Byte为单位的小内存块时,该如何分配呢? slab分配器就是用来解决小内存块分配问题,也是内存分配中非常重要的角色之一。 slab分配器最终还是由伙伴系统分配出实际的物理内存,只不过s…...
docker-compose部署gitlab(亲测有效)
一.通过DockerHub拉取Gitlab镜像 docker pull gitlab/gitlab-ce:latest 二.创建目录 mkdir -p /root/tool/gitlab/{data,logs,config} && cd /root/tool/gitlab/ 三.编辑DockerCompose.yaml文件 vim /root/tool/gitlab/docker-compose.yml version: "3&quo…...

Leetcode 赎金信
利用hash map做 java solution class Solution {public boolean canConstruct(String ransomNote, String magazine) {//首先利用HashMap统计magazine中字符频率HashMap<Character, Integer> magazinefreq new HashMap<>();for(char c : magazine.toCharArray())…...

S7--环境搭建基本操作
1.修改蓝牙名称和地址 工程路径:$ADK_ROOT\adk\src\filesystems\CDA2\factory_default_config\ 在subsys7_config5.htf中 DeviceName = "DEVICE_NAME“ # replace with your device name BD_ADDRESS=[00 FF 00 5B 02 00] # replace with your BD address 2.earbud工程修改…...

webAPI中的排他思想、自定义属性操作、节点操作(配大量案例练习)
一、排他操作 1.排他思想 如果有同一组元素,我们想要某一个元素实现某种样式,需要用到循环的排他思想算法: 1.所有的元素全部清除样式 2.给当前的元素设置样式 注意顺序能不能颠倒,首先清除全部样式,再设置自己当前的…...

101、QT摄像头录制视频问题
视频和音频录制类QMediaRecorder QMediaRecorder 通过摄像头和音频输入设备进行录像。 注意: 使用Qt多媒体模块的摄像头相关类无法在Windows平台上进行视频录制,只能进行静态图片抓取但是在Linux平台上可以实现静态图片抓取和视频录制。 Qt多媒体模块的功能实现是依…...
FairGuard游戏加固全面适配纯血鸿蒙NEXT
2024年10月8日,华为正式宣布其原生鸿蒙操作系统 HarmonyOS NEXT 进入公测阶段,标志着其自有生态构建的重要里程碑。 作为游戏安全领域领先的第三方服务商,FairGuard游戏加固在早期就加入了鸿蒙生态的开发,基于多项独家技术与十余年…...

鲸信私有化即时通信如何平衡安全性与易用性之间的关系?
即时通信已经成为我们生活中不可或缺的一部分。从日常沟通到工作协作,每一个信息的传递都承载着信任与效率。然而,随着网络安全威胁日益严峻,如何在享受即时通信便捷的同时,确保信息的私密性与安全性,成为了摆在我们面…...

vivado 接口带宽验证
存储器接口 使用赛灵思存储器 IP 时需要更多的 I/O 管脚分配步骤。自定义 IP 之后,您可采用 Vivado IDE 中的细化 (elaborated) 或综 合 (synthesized) 设计分配顶层 IP 端口到物理封装引脚。同每一个存储器 IP 关联的所有端口都被纳入一个 I/O 端口接口…...

Qt中使用线程之QThread
使用Qt中自带的线程类QThread时 1、需要定义一个子类继承自QThread 2、重写run()方法,在run方法中编写业务逻辑 3、子类支持信号槽 4、子类的构造函数的执行是在主线程进行的,而run方法的执行是在子线程中进行的 常用方法 静态方法 获取线程id 可…...

多IP连接
一.关闭防火墙 systemctl stop firewalld setenforce 0 二.挂在mnt mount /dev/sr0 /mnt 三.下载nginx dnf install nginx -y 四.启动nginx协议 systemctl start nginx 五.修改协议 vim /etc/nginx/nginx.conf 在root前加#并且下一行添加 root /www:(浏…...

Linux重点yum源配置
1.配置在线源 2.配置本地源 3.安装软件包 4.测试yum源配置 5.卸载软件包...
289.生命游戏
目录 题目解法代码说明: 每一个各自去搜寻他周围的信息,肯定存在冗余,如何优化这个过程?如何遍历每一个元素的邻域?方向数组如何表示方向? auto dir : directions这是什么用法board[i][j]一共有几种状态&am…...

如何保证Redis和数据库的数据一致性
文章目录 0. 前言1. 补充知识:CP和AP2. 什么情况下会出现Redis与数据库数据不一致3. 更新缓存还是删除缓存4. 先操作缓存还是先操作数据库4.1 先操作缓存4.1.1 数据不一致的问题是如何产生的4.1.2 解决方法(延迟双删)4.1.3 最终一致性和强一致…...

Android Framework AMS(06)startActivity分析-3(补充:onPause和onStop相关流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读AMS通过startActivity启动Activity的整个流程的补充,更新了startActivity流程分析部分。 一般来说,有Activ…...

【LangChain系列2】【Model I/O详解】
目录 前言一、LangChain1-1、介绍1-2、LangChain抽象出来的核心模块1-3、特点1-4、langchain解决的一些行业痛点1-5、安装 二、Model I/O模块2-0、Model I/O模块概要2-1、Format(Prompts Template)2-1-1、Few-shot prompt templates2-1-2、Chat模型的少样…...
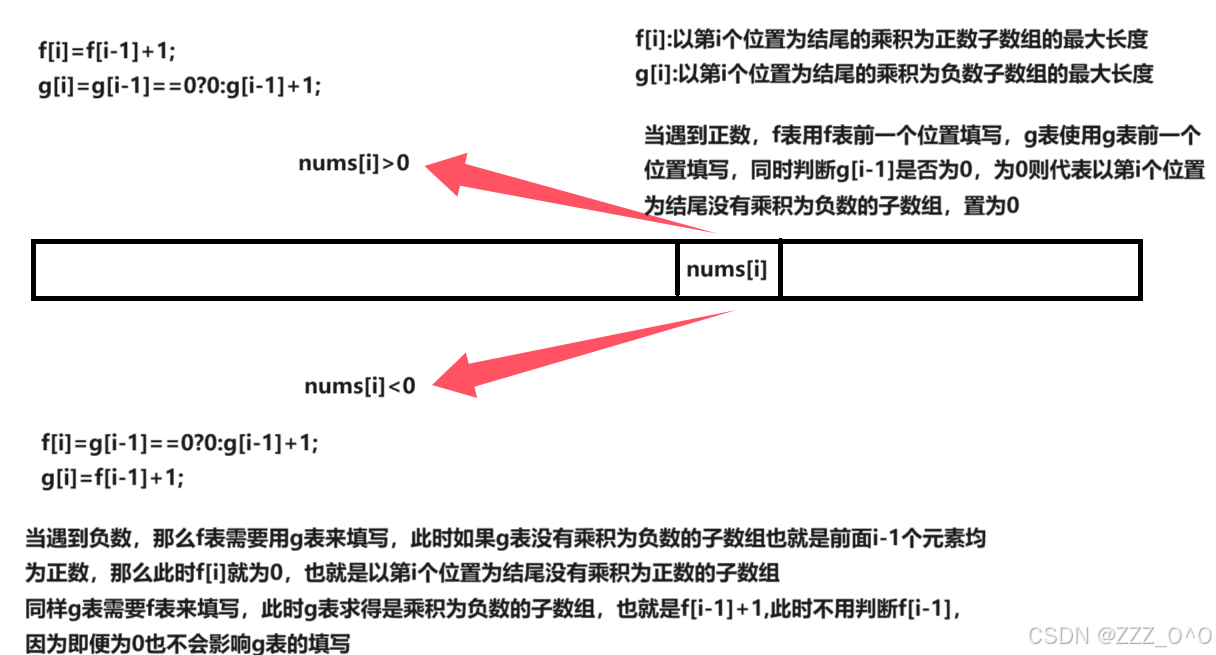
动态规划-子数组系列——1567.乘积为正数的最长子数组
1.题目解析 题目来源:1567.乘积为正数的最长子数组——力扣 测试用例 2.算法原理 1.状态表示 因为数组中存在正数与负数,如果求乘积为正数的最长子数组,那么存在两种情况使得乘积为正数,第一种就是正数乘以正数,第…...

Linux 运行执行文件并将日志输出保存到文本文件中
在 Linux 系统中运行可执行文件并将日志输出保存到文本文件中,可以使用以下几种方法: 方法一:使用重定向符号 > 或 >> 覆盖写入(>): ./your_executable > logfile.txt这会将可执行文件的输…...

注册安全分析报告:北外网校
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
预警期刊命运逆袭到毕业好刊,仅45天!闭眼冲速度,发文量暴增!
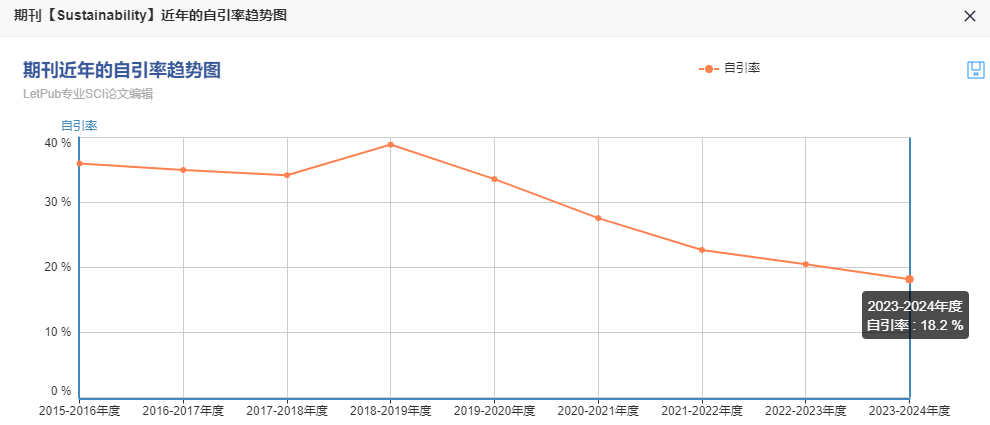
选刊发表不迷路,就找科检易学术 期刊官网:Sustainability | An Open Access Journal from MDPI 1、期刊信息 期刊简介: Sustainability 是一本国际性的、同行评审的开放获取期刊,由MDPI出版社每半月在线出版。该期刊专注于人类…...

Unity HDRP 2023.2水系统实战:从清澈泳池到湍急溪流,5分钟调出电影感水体
Unity HDRP 2023.2水系统实战:从清澈泳池到湍急溪流,5分钟调出电影感水体 在游戏和影视级实时渲染中,水体的表现力往往决定了场景的沉浸感上限。Unity 2023.2的HDRP Water Surface系统通过物理参数的艺术化组合,让开发者无需编写着…...

瑞萨RA2L2 MCU深度解析:USB-C Rev 2.4与超低功耗设计实战
1. 项目概述:瑞萨RA2L2 MCU的定位与核心价值作为一名在嵌入式领域摸爬滚打了十多年的老工程师,每当看到像瑞萨RA2L2这样的新品发布,我的第一反应不是看那些华丽的参数,而是会立刻思考:这玩意儿到底能解决我手头项目里的…...

如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南
如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

【亲测免费】 ImageNet标签文件及读取脚本:加速您的计算机视觉研究
ImageNet标签文件及读取脚本:加速您的计算机视觉研究 【下载地址】ImageNet标签文件及读取脚本 ImageNet 标签文件及读取脚本 项目地址: https://gitcode.com/open-source-toolkit/56c9e 项目介绍 在计算机视觉领域,ImageNet数据集是图像分类任务…...

高效AI专著生成:20万字专著一键搞定,AI写专著工具实测推荐!
学术专著写作挑战与AI工具助力 对于初次尝试编写学术专著的研究者来说,写作过程就像是在“摸索着走过一条未知的小路”,处处都有挑战等待着他们。在选题上常常感到迷惘,难以在“有意义”与“可操作性”之间找到合适的平衡:有的研…...

全新英雄联盟国服换肤实战指南:3种方法实现安全个性化游戏体验
全新英雄联盟国服换肤实战指南:3种方法实现安全个性化游戏体验 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 厌倦了英雄联盟国服中千篇一…...

Armv9 SME2架构下BFloat16计算优化与机器学习加速
1. SME2指令集与BFloat16计算优化解析在Armv9架构的SME2扩展中,BFloat16(简称BF16)支持成为机器学习加速的关键特性。这种16位浮点格式通过截断IEEE 754单精度浮点的尾数位(从23位减至7位),同时保留完整的8…...

完全掌握JetBrains IDE试用期重置:从原理到实战的终极解决方案
完全掌握JetBrains IDE试用期重置:从原理到实战的终极解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains系列开发工具的试用期限制而困扰吗?IDE Eval Resetter为您提…...

CLI工具集claw:模块化设计与插件化架构深度解析
1. 项目概述:一个面向开发者的现代化CLI工具集最近在GitHub上看到一个名为opsyhq/claw的项目,第一眼就被它简洁的名字吸引了。claw,中文意思是“爪子”,听起来就很有力量感和抓取感。点进去一看,果然,这是一…...

CMOS概率计算芯片设计与工程实践
1. CMOS概率计算芯片的核心设计理念概率计算作为一种新兴的计算范式,正在突破传统冯诺依曼架构的局限。我们团队开发的这款440节点CMOS芯片,其核心创新点在于将物理启发的随机性与标准CMOS工艺完美结合。不同于传统计算机的确定性计算方式,每…...