semi-Naive Bayesian(半朴素贝叶斯)
semi-Naive Bayesian(半朴素贝叶斯)
引言
朴素贝叶斯算法是基于特征是相互独立这个假设开展的(为了降低贝叶斯公式: P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) P(c|x) = \frac {P(c)P(x|c)}{P(x)} P(c∣x)=P(x)P(c)P(x∣c)中后验概率 P ( c ∣ x ) P(c|x) P(c∣x)的困难),但在现实中这个假设往往很难成立。对条件独立假设进行适当的放宽,便引申出了“半朴素贝叶斯”。半朴素的意思就是,在朴素和非朴素之间寻找平衡,并不完全遵从条件独立,也不完全符合现实情况。
原理
在朴素贝叶斯中,对一个样本进行预测就是要找最大概率对应的类别,即
a r g m a x c k p ( c k ) ∏ i = 1 d P ( x i ∣ c l ) argmax_{c_k}p(c_k)\prod_{i=1}^d P(x_i|c_l) argmaxckp(ck)i=1∏dP(xi∣cl)
半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息,从而既不需进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。“独依赖估计”(One-Dependent Estimator,简称ODE)是半朴素贝叶斯分类器最常用的一种策略。“独依赖”就是假设每个属性在类别之外最多仅依赖于一个其他属性,即:
p ( c ∣ x ) ∝ p ( c k ) ∏ i = 1 d p ( x i ∣ c k , p a i ) p(c|x) \propto p(c_k)\prod_{i=1}^d p(x_i|c_k,pa_i) p(c∣x)∝p(ck)i=1∏dp(xi∣ck,pai)
其中 p a i pa_i pai为属性 x i x_i xi所依赖的属性,称为 x i x_i xi的父属性。此时,对每个属性 x i x_i xi,若其父属性 p a i pa_i pai已知,则可采用类似
p ^ ( x i ∣ c ) = ∣ D c , x i ∣ + 1 ∣ D c ∣ + N i \hat p(x_i|c) = \frac{|D_{c,x_i}|+1}{|D_c|+N_i} p^(xi∣c)=∣Dc∣+Ni∣Dc,xi∣+1
的方法来估计概率值 p ( x i ∣ c , p a i ) p(x_i|c,pa_i) p(xi∣c,pai)。于是,问题就转化为如何确定每个属性的父属性,不同的做法产生不同的独依赖分类器。
根据不同确定父属性可以有不同的半朴素贝叶斯分类器:
- 选择贝叶斯分类器(SBC:Selective Bayesian Classifier)
- 超父独依赖估计分类器(SPODE:Super Parent ODE)
- 树增广朴素贝叶斯网络分类器(TAN:Tree Augmented NaiveBayes)
- 平均独依赖估测器(AODE:Averaged ODE)
- 加权平均独依赖估测器(WAODE:Weightily Averaged ODE)

-
SPODE
确定父属性最直接的做法是假设所有属性都依赖于同一个属性,称为“超父”(super-parent),然后通过交叉验证等模型选择方法来确定超父属性,由此形成了SPODE(Super-Parent ODE)方法。
-
AODE
将每个属性都作为超父来构建SPODE,然后将具有足够训练数据支撑的SPODE集成起来作为最终结果,由此形成了AODE算法(Averaged ODE),AODE是一种基于集成学习机制、更为强大的独依赖分类器。表达式:
∑ i = 1 d p ( c , x i ) ∏ j = 1 d p ( x j ∣ c , x i ) , ∣ D x i ∣ ≥ m ′ \sum_{i=1}^d p(c,x_i)\prod{j=1}^dp(x_j|c,x_i),|D_{x_i}|\geq m' i=1∑dp(c,xi)∏j=1dp(xj∣c,xi),∣Dxi∣≥m′∣ D x i ∣ |D_{x_i}| ∣Dxi∣ 是在第i个属性上取值为 x i x_i xi的样本的集合,m’是阈值常数。
p ( c , x i ) = ∣ D c , x i ∣ + 1 ∣ D ∣ + N c ∗ N i p(c,x_i) = \frac{|D_{c,x_i}|+1}{|D|+N_c*N_i} p(c,xi)=∣D∣+Nc∗Ni∣Dc,xi∣+1
p ( x j ∣ c , x i ) = ∣ D c , x i , x j ∣ + 1 ∣ D c , x i ∣ + N j p(x_j|c,x_i) = \frac {|D_{c,x_i,x_j}|+1}{|D_{c,x_i}|+N_j} p(xj∣c,xi)=∣Dc,xi∣+Nj∣Dc,xi,xj∣+1其中, N c N_c Nc表示分类类别数, N i N_i Ni表示第i个属性可能的取值数, N j N_j Nj表示第j个属性可能的取值数, ∣ D c , x I ∣ |D_{c,x_I}| ∣Dc,xI∣表示分类为c,第i个属性取值为 x i x_i xi的样本集合, ∣ D c , x i , x j ∣ |D_{c,x_i,x_j}| ∣Dc,xi,xj∣表示分类为c,第i个属性取值为 x i x_i xi,第j个属性取值为 x j x_j xj的样本集合。 -
TAN
TAN(Tree Augmented naive Bayes)是在最大带权生成树(maximum weighted spanning tree)算法的基础上,通过以下步骤将属性间依赖关系约简为如上图©所示的树形结构:
- 计算任意两个属性之间的条件互信息:
I ( x i , x j ∣ y ) = ∑ x i , x j ; c ∈ y P ( x i , x j ∣ c ) l o g P ( x i , x j ∣ c ) P ( x i ∣ c ) P ( x j ∣ c ) I(x_i,x_j|y) = \sum_{x_i,x_j;c\in y}P(x_i,x_j|c)log\frac{P(x_i,x_j|c)}{P(x_i|c)P(x_j|c)} I(xi,xj∣y)=xi,xj;c∈y∑P(xi,xj∣c)logP(xi∣c)P(xj∣c)P(xi,xj∣c) - 以属性为结点,构建完全图,任意两个结点之间边的权重设为 I ( x i , x j ∣ y ) I(x_i,x_j|y) I(xi,xj∣y)。
- 构建此完全图的最大带权生成树,挑选根变量,将边置为有向。
- 加入类别节点y,增加从y到每个属性的有向边。
- 计算任意两个属性之间的条件互信息:
代码
import numpy as np
import pandas as pd######一、朴素贝叶斯分类器
class NBayes(object):#设置属性def __init__(self):self.Y = 0 #训练集标签self.X = 0 #训练集数据self.PyArr = {} #先验概率总容器self.PxyArr = {} #条件概率总容器#连续变量处理,返回均值和标准差def Gaussian(self, xArr):miu = np.mean(xArr) #变量平均数sigma = np.std(xArr) #变量标准差return miu, sigma#离散变量直接计算概率def classify(self, x, xArr, countSetX):countX = len(xArr) #计算变量X的数量countXi = sum(xArr == x) #计算变量X某个属性的数量Pxy = (countXi+1)/(countX+countSetX) #加入拉普拉斯修正的概率return Pxy#计算P(y),加入了拉普拉斯修正def calPy(self,Y):Py = {}countY = len(Y)for i in set(Y.flatten()):countI = sum(Y[:,0] == i)Py[i] = (countI + 1) / (countY + len(set(Y.flatten())))self.PyArr = Pyreturn#计算P(x|y),加入了拉普拉斯修正def calPxy(self, X, Y):m, n = np.shape(X)Pxy = {}for yi in set(Y.flatten()):countYi = sum(Y[:,0] == yi)Pxy[yi] = {} #第一层是标签Y的分类for xIdx in range(n):Pxy[yi][xIdx] = {} #第二层是不同的变量XsetX = set(X[:,xIdx])tempX = X[np.nonzero(Y[:,0] == yi)[0],xIdx]for xi in setX:countSetX = len(setX)if countSetX <= 10:Pxy[yi][xIdx][xi] = self.classify(xi, tempX, countSetX) #第三层是变量Xi的分类概率,离散变量else:Pxy[yi][xIdx]['miu'], Pxy[yi][xIdx]['sigma'] = self.Gaussian(tempX)self.PxyArr = Pxyreturn#训练def train(self, X, Y):self.calPy(Y)print('P(y)训练完毕')self.calPxy(X, Y)print('P(x|y)训练完毕')self.X = Xself.Y = Yreturn#连续变量求概率密度def calContinous(self, x, miu, sigma):Pxy = np.exp(-(x-miu)**2/(2*sigma**2))/(np.power(2*np.pi,0.5)*sigma) #计算概率密度return Pxy#预测def predict(self, testX):preP = {}m, n = testX.shapefor yi, Py in self.PyArr.items():Ptest = Pyprint(yi,Ptest)for xIdx in range(n):xi = testX[0,xIdx]if len(set(self.X[:,xIdx])) <= 10:Ptest *= self.PxyArr[yi][xIdx][xi]else:pxy = self.calContinous(xi, self.PxyArr[yi][xIdx]['miu'], self.PxyArr[yi][xIdx]['sigma'])Ptest *= pxyprint(yi,Ptest)preP[yi] = Ptestreturn preP#防止数值下溢,预测时用logdef predictlog(self, testX):preP = {}m, n = testX.shapefor yi, Py in self.PyArr.items():Ptest = 0for xIdx in range(n):xi = testX[0,xIdx]if len(set(self.X[:,xIdx])) <= 10:Ptest += np.log(self.PxyArr[yi][xIdx][xi])else:pxy = self.calContinous(xi, self.PxyArr[yi][xIdx]['miu'], self.PxyArr[yi][xIdx]['sigma'])Ptest += np.log(pxy)print(yi,Ptest)preP[yi] = Py*Ptestreturn preP#数据集准备
from sklearn.preprocessing import OrdinalEncoder
dataSet = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'],['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'],['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'],['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'],['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'],['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'],['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'],['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'],['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'],['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'],['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'],['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'],['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'],['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'],['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'],['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'],['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']]
#特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感', '密度', '含糖率']
dataX = np.array(dataSet)[:,:6]
oriencode = OrdinalEncoder(categories='auto')
oriencode.fit(dataX)
X1=oriencode.transform(dataX) #编码后的数据
X2=np.array(dataSet)[:,6:8].astype(float)
X = np.hstack((X1,X2))
Y = np.array(dataSet)[:,8]
Y[Y=="好瓜"]=1
Y[Y=="坏瓜"]=0
Y=Y.astype(float)
Y = Y.reshape(-1,1)#训练
NB = NBayes()
NB.train(X, Y)
Pdict = NB.predict(X[0,:].reshape(1,-1))
logPdict = NB.predictlog(X[0,:].reshape(1,-1))######二、半朴素贝叶斯分类器(Averaged One-Dependent Estimator)
class HalfNBayes(object):#设置属性def __init__(self):self.Y = 0 #训练集标签self.X = 0 #训练集数据self.PyArr = {} #先验概率总容器self.PxyArr = {} #条件概率总容器#连续变量处理,返回均值和标准差def Gaussian(self, xArr):miu = np.mean(xArr) #变量平均数sigma = np.std(xArr) #变量标准差return miu, sigma#离散变量直接计算概率def classify(self, x, xArr, countSetX):countX = len(xArr) #计算变量X的数量countXi = sum(xArr == x) #计算变量X某个属性的数量Pxy = (countXi+1)/(countX+countSetX) #加入拉普拉斯修正的概率return Pxy#计算P(xi,y),加入了拉普拉斯修正def calPy(self, X, Y):m, n = np.shape(X)Py = {}countY = len(Y)for i in set(Y.flatten()):Py[i] = {} #第一层是标签Y的分类for j in range(n):setX = set(X[:,j])countSetX = len(setX)if countSetX <= 10:Py[i][j] = {} #第二层是不同的变量Xfor xi in setX:countI = sum((Y[:,0] == i) & (X[:,j] == xi))Py[i][j][xi] = (countI + 1) / (countY + countSetX*len(set(Y.flatten()))) #第二层是分类变量xi的不同值self.PyArr = Pyreturn#计算P(x|y,xi),加入了拉普拉斯修正def calPxy(self, X, Y):m, n = np.shape(X)Pxy = {}for yi in set(Y.flatten()):countYi = sum(Y[:,0] == yi)Pxy[yi] = {} #第一层是标签Y的分类for superX in range(n):setSuperX = set(X[:,superX])countSuperX = len(setSuperX)if countSuperX <= 10:Pxy[yi][superX] = {} #第二层是超父变量X,只有离散变量for superXi in setSuperX:Pxy[yi][superX][superXi] = {} #第三层是超父变量的属性值superXifor xIdx in range(n):if xIdx == superX:continuePxy[yi][superX][superXi][xIdx] = {} #第四层是不同的变量XsetX = set(X[:,xIdx])tempX = X[np.nonzero((Y[:,0] == yi)&(X[:,superX] == superXi))[0],xIdx]for xi in setX:countSetX = len(setX)if countSetX <= 10:Pxy[yi][superX][superXi][xIdx][xi] = self.classify(xi, tempX, countSetX) #第五层是变量Xi的分类概率,离散变量else:Pxy[yi][superX][superXi][xIdx]['miu'], Pxy[yi][superX][superXi][xIdx]['sigma'] = self.Gaussian(tempX)self.PxyArr = Pxyreturn#训练def train(self, X, Y):self.calPy(X, Y)print('P(y)训练完毕')self.calPxy(X, Y)print('P(x|y)训练完毕')self.X = Xself.Y = Yreturn#连续变量求概率密度def calContinous(self, x, miu, sigma):Pxy = np.exp(-(x-miu)**2/(2*sigma**2+1.0e-6))/(np.power(2*np.pi,0.5)*sigma+1.0e-6) #计算概率密度return Pxy#预测def predict(self, testX):preP = {}m, n = testX.shapefor yi, Py in self.PyArr.items():Ptest = Pyprint(yi,Ptest)for xIdx in range(n):xi = testX[0,xIdx]if len(set(self.X[:,xIdx])) <= 10:Ptest *= self.PxyArr[yi][xIdx][xi]else:pxy = self.calContinous(xi, self.PxyArr[yi][xIdx]['miu'], self.PxyArr[yi][xIdx]['sigma'])Ptest *= pxyprint(yi,Ptest)preP[yi] = Ptestreturn preP#防止数值下溢,预测时用logdef predictlog(self, testX):preP = {}m, n = testX.shapefor yi, superXdict in self.PyArr.items():print('yi是{}================'.format(yi))Ptest = 0for superX, superXidict in superXdict.items():superXi = testX[0,superX]Py = superXidict[superXi]print('超父属性是{},Py概率是{}'.format(superX, Py))print('----------------')Pxi = 0for xIdx in range(n):if xIdx == superX:continuexi = testX[0,xIdx]print('第{}个变量,值是{}'.format(xIdx, xi))if len(set(self.X[:,xIdx])) <= 10:Pxi += np.log(self.PxyArr[yi][superX][superXi][xIdx][xi])print('概率是:',np.log(self.PxyArr[yi][superX][superXi][xIdx][xi]))else:pxy = self.calContinous(xi, self.PxyArr[yi][superX][superXi][xIdx]['miu'], self.PxyArr[yi][superX][superXi][xIdx]['sigma'])print('概率是:',pxy)Pxi += np.log(pxy)Ptest += Py*PxipreP[yi] = Ptestreturn preP#训练
HNB = HalfNBayes()
HNB.train(X, Y)
logPdict = HNB.predictlog(X[15,:].reshape(1,-1))
参考
机器学习基础
知乎
知乎
代码
相关文章:
semi-Naive Bayesian(半朴素贝叶斯)
semi-Naive Bayesian(半朴素贝叶斯) 引言 朴素贝叶斯算法是基于特征是相互独立这个假设开展的(为了降低贝叶斯公式: P ( c ∣ x ) P ( c ) P ( x ∣ c ) P ( x ) P(c|x) \frac {P(c)P(x|c)}{P(x)} P(c∣x)P(x)P(c)P(x∣c)中后验概率 P …...

大语言模型(LLM)入门级选手初学教程
链接:https://llmbook-zh.github.io/ 前言: GPT发展:GPT-1 2018 -->GPT-2&GPT-3(扩大预训练数据和模型参数规模)–> GPT-3.5(代码训练、人类对齐、工具使用等)–> 2022.11 ChatG…...
).oO 困)
HTML 实例/测验之HTML 基础一口气讲完!(o-ωq)).oO 困
HTML 基础 非常简单的HTML文档 <!DOCTYPE html> <html><head><title>页面标题(w3cschool.cn)</title></head><body><h1>我的第一个标题</h1><p>我的第一个段落。</p></body> </html> 输出&a…...

c语言基础程序——经典100道实例。
c语言基础程序——经典100道实例 001, 组无重复数字的数002,企业发放的奖金根据利润提成003,完全平方数004,判断当天是这一年的第几天005,三个数由小到大输出006,输出字母C图案007,特殊图案008&…...
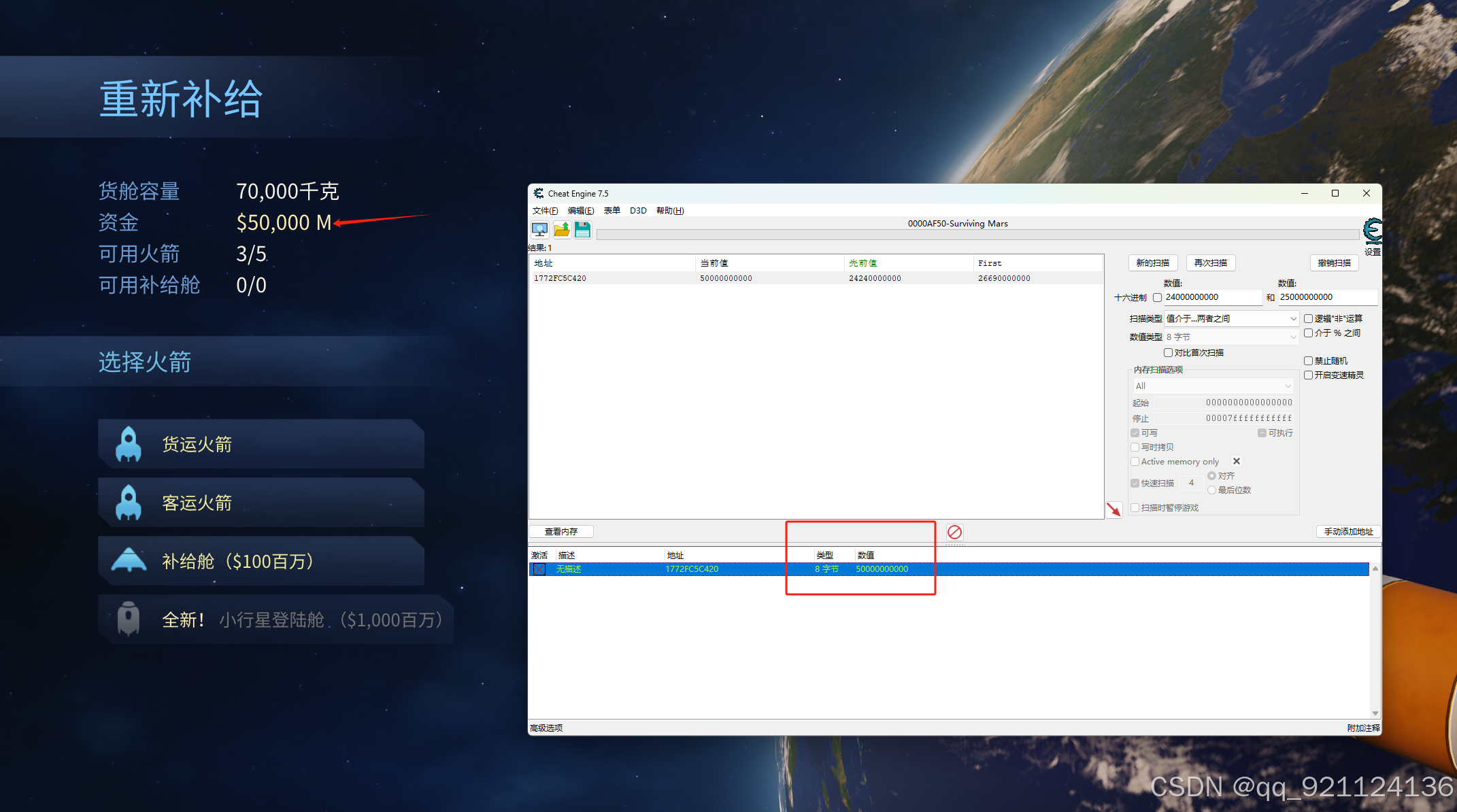
火星求生CE修改金钱,无限资金
由于火星求生前期没有资金非常难玩,想通过修改资金渡过前期,网上找了一圈修改器,只有修改无限声望和无限科研,就是没有无限资金,于是自己用CE修改 教程 首先查看自己资金是多少M,如下图我是22430M资金&…...
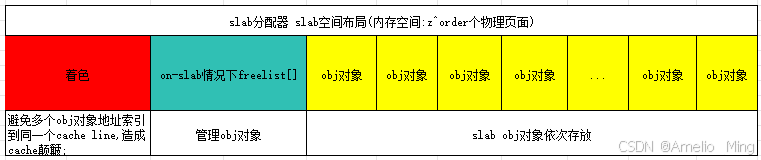
linux 内存管理-slab分配器
伙伴系统用于分配以page为单位的内存,在实际中很多内存需求是以Byte为单位的,如果需要分配以Byte为单位的小内存块时,该如何分配呢? slab分配器就是用来解决小内存块分配问题,也是内存分配中非常重要的角色之一。 slab分配器最终还是由伙伴系统分配出实际的物理内存,只不过s…...
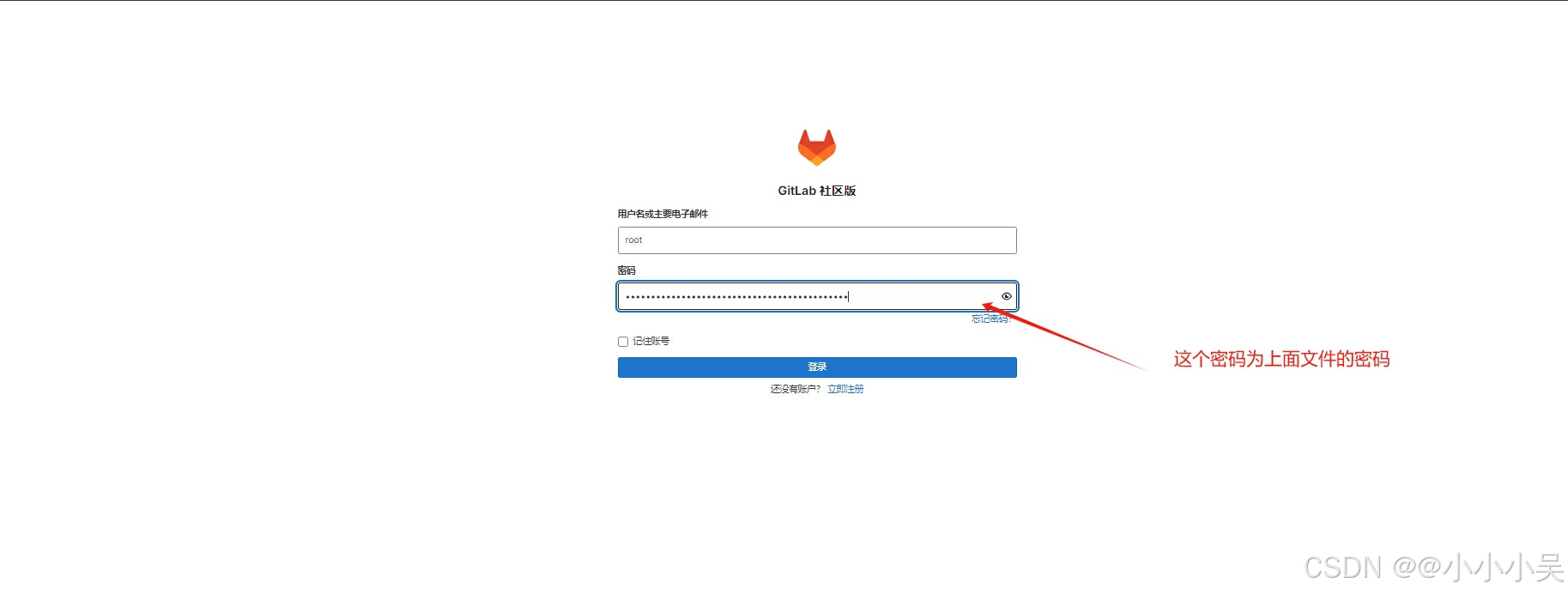
docker-compose部署gitlab(亲测有效)
一.通过DockerHub拉取Gitlab镜像 docker pull gitlab/gitlab-ce:latest 二.创建目录 mkdir -p /root/tool/gitlab/{data,logs,config} && cd /root/tool/gitlab/ 三.编辑DockerCompose.yaml文件 vim /root/tool/gitlab/docker-compose.yml version: "3&quo…...

Leetcode 赎金信
利用hash map做 java solution class Solution {public boolean canConstruct(String ransomNote, String magazine) {//首先利用HashMap统计magazine中字符频率HashMap<Character, Integer> magazinefreq new HashMap<>();for(char c : magazine.toCharArray())…...

S7--环境搭建基本操作
1.修改蓝牙名称和地址 工程路径:$ADK_ROOT\adk\src\filesystems\CDA2\factory_default_config\ 在subsys7_config5.htf中 DeviceName = "DEVICE_NAME“ # replace with your device name BD_ADDRESS=[00 FF 00 5B 02 00] # replace with your BD address 2.earbud工程修改…...

webAPI中的排他思想、自定义属性操作、节点操作(配大量案例练习)
一、排他操作 1.排他思想 如果有同一组元素,我们想要某一个元素实现某种样式,需要用到循环的排他思想算法: 1.所有的元素全部清除样式 2.给当前的元素设置样式 注意顺序能不能颠倒,首先清除全部样式,再设置自己当前的…...

101、QT摄像头录制视频问题
视频和音频录制类QMediaRecorder QMediaRecorder 通过摄像头和音频输入设备进行录像。 注意: 使用Qt多媒体模块的摄像头相关类无法在Windows平台上进行视频录制,只能进行静态图片抓取但是在Linux平台上可以实现静态图片抓取和视频录制。 Qt多媒体模块的功能实现是依…...
FairGuard游戏加固全面适配纯血鸿蒙NEXT
2024年10月8日,华为正式宣布其原生鸿蒙操作系统 HarmonyOS NEXT 进入公测阶段,标志着其自有生态构建的重要里程碑。 作为游戏安全领域领先的第三方服务商,FairGuard游戏加固在早期就加入了鸿蒙生态的开发,基于多项独家技术与十余年…...

鲸信私有化即时通信如何平衡安全性与易用性之间的关系?
即时通信已经成为我们生活中不可或缺的一部分。从日常沟通到工作协作,每一个信息的传递都承载着信任与效率。然而,随着网络安全威胁日益严峻,如何在享受即时通信便捷的同时,确保信息的私密性与安全性,成为了摆在我们面…...

vivado 接口带宽验证
存储器接口 使用赛灵思存储器 IP 时需要更多的 I/O 管脚分配步骤。自定义 IP 之后,您可采用 Vivado IDE 中的细化 (elaborated) 或综 合 (synthesized) 设计分配顶层 IP 端口到物理封装引脚。同每一个存储器 IP 关联的所有端口都被纳入一个 I/O 端口接口…...

Qt中使用线程之QThread
使用Qt中自带的线程类QThread时 1、需要定义一个子类继承自QThread 2、重写run()方法,在run方法中编写业务逻辑 3、子类支持信号槽 4、子类的构造函数的执行是在主线程进行的,而run方法的执行是在子线程中进行的 常用方法 静态方法 获取线程id 可…...

多IP连接
一.关闭防火墙 systemctl stop firewalld setenforce 0 二.挂在mnt mount /dev/sr0 /mnt 三.下载nginx dnf install nginx -y 四.启动nginx协议 systemctl start nginx 五.修改协议 vim /etc/nginx/nginx.conf 在root前加#并且下一行添加 root /www:(浏…...

Linux重点yum源配置
1.配置在线源 2.配置本地源 3.安装软件包 4.测试yum源配置 5.卸载软件包...
289.生命游戏
目录 题目解法代码说明: 每一个各自去搜寻他周围的信息,肯定存在冗余,如何优化这个过程?如何遍历每一个元素的邻域?方向数组如何表示方向? auto dir : directions这是什么用法board[i][j]一共有几种状态&am…...

如何保证Redis和数据库的数据一致性
文章目录 0. 前言1. 补充知识:CP和AP2. 什么情况下会出现Redis与数据库数据不一致3. 更新缓存还是删除缓存4. 先操作缓存还是先操作数据库4.1 先操作缓存4.1.1 数据不一致的问题是如何产生的4.1.2 解决方法(延迟双删)4.1.3 最终一致性和强一致…...

Android Framework AMS(06)startActivity分析-3(补充:onPause和onStop相关流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读AMS通过startActivity启动Activity的整个流程的补充,更新了startActivity流程分析部分。 一般来说,有Activ…...

B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本
B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text Bili2Text是一款开源的B站视频转文字工…...

3步完成Android Studio中文界面配置:终极汉化指南
3步完成Android Studio中文界面配置:终极汉化指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android Stud…...

实战剖析:利用Fluxion构建WiFi钓鱼热点与密码捕获
1. 环境准备与工具安装 在开始使用Fluxion进行WiFi安全测试之前,我们需要确保具备合适的硬件和软件环境。首先,你需要一台支持监听模式的无线网卡,这是进行任何无线安全测试的基础硬件。我推荐使用RTL8812AU芯片的网卡,实测下来兼…...

Android Studio中文界面完整指南:5分钟快速汉化教程
Android Studio中文界面完整指南:5分钟快速汉化教程 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android St…...

Bilibili-Evolved:打造无网络依赖的哔哩哔哩增强体验技术解析
Bilibili-Evolved:打造无网络依赖的哔哩哔哩增强体验技术解析 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 在当今网络环境复杂多变的时代,用户对Web应用的稳定性要…...

别再只盯着RRT了!关节空间六次多项式规划,可能是更简单的机械臂避障方案
关节空间六次多项式规划:机械臂避障的优雅解法 在工业机器人领域,路径规划一直是核心挑战之一。当机械臂需要在充满障碍物的环境中工作时,传统基于笛卡尔空间的规划方法常常面临逆运动学奇异、轨迹不平滑等问题。而基于关节空间的六次多项式规…...

给项目选YOLO模型别再纠结了:从参数量、训练曲线到mAP,手把手教你根据数据集做决策
YOLO模型选型实战指南:从参数解析到场景适配的决策方法论 在目标检测领域,YOLO系列模型凭借其出色的实时性能,已成为工业界和学术界的首选架构之一。然而,面对从YOLOv5到YOLOv9的多个版本迭代,以及每个版本中不同规模的…...

我终于把AI应用拆明白了:Agent、RAG、MCP
本文深入剖析AI应用开发的核心要素,指出仅靠强大的大模型(LLM)不足以构建实用的AI应用。文章详细阐述了Prompt、Skill、RAG、Tool、MCP、Agent等关键模块如何协同工作,使AI能够获取正确资料、调用外部工具、遵循固定流程并稳定交付…...

Stream Deck与Arduino打造物联网信息看板:软硬云结合实战
1. 项目概述:打造你的专属物理信息看板如果你和我一样,是个桌面极客或者直播爱好者,那你对Elgato的Stream Deck一定不陌生。这个小玩意儿最初是为直播设计的,可以一键切换场景、播放音效,堪称效率神器。但它的潜力远不…...

机器人碰撞检测2:FCL库进阶实战与性能优化
1. 从基础到进阶:FCL库在机器人运动规划中的角色 第一次接触FCL库时,你可能已经体验过它强大的基础碰撞检测功能。但当机器人需要在一个充满动态障碍物的工厂环境中自主导航,或者机械臂要在密集货架上精准抓取物品时,简单的两两碰…...