大语言模型(LLM)入门级选手初学教程
链接:https://llmbook-zh.github.io/
前言:
- GPT发展:GPT-1 2018 -->GPT-2&GPT-3(扩大预训练数据和模型参数规模)–> GPT-3.5(代码训练、人类对齐、工具使用等)–> 2022.11 ChatGPT(对话形式)–> 2023.3 GPT-4 --> GPT-4V(多模态能力)
- 两个要点
- Transformer 架构能够拓展到百亿、千亿甚至万亿参数规模,并将预训练任务统一为预测下一个词这一通用学习范式 ;
- 数据质量与数据规模的重视
大语言模型发展的时间线:

背景与基础知识
一、引言
1.1 何为大语言模型(Large Language Model, LLM)
- 通过规模扩展(如增加模型参数规模或数据规模)通常会带来下游任务的模型性能提升,大规模的预训练语言模型(175B 参数的GPT-3 和540B 参数的PaLM)在解决复杂任务时表现出了与小型预训练语言模型(例如330M 参数的BERT 和1.5B 参数的GPT-2)不同的行为,GPT-3 可以通过“上下文学习”(In-Context Learning, ICL)的方式来利用少样本数据解决下游任务,这种大模型具有但小模型不具有的能力通常被称为“涌现能力”(Emergent Abilities)。
- 语言模型发展的四个阶段:

1.2 大语言模型的能力特点
- 较为丰富的世界知识:超大规模的文本数据训练,充分学习到丰富的世界知识,无需微调
- 较强的通用任务解决能力:基于大规模无标注文本的下一个词元预测任务本质上可以看作一个多任务学习过程
- 较好的复杂任务推理能力:回答知识关系复杂的推理问题,解决涉及复杂数学推理过程的数学题目
- 较强的人类指令遵循能力:提示学习
- 较好的人类对齐能力:安全性,目前广泛采用的对齐方式是基于人类反馈的强化学习技术,通过强化学习使得模型进行正确行为的加强以及错误行为的规避,进而建立较好的人类对齐能力
- 可拓展的工具使用能力:会受到所采用的归纳假设以及训练数据的限制,无法有效回答涉及到预训练数据时间范围之外的问题,并且对于数学中的数值计算问题也表现不佳;可以通过微调、上下文学习等方式掌握外部工具的使用,如搜索引擎与计算器
- 长程对话的语义一致性、对于新任务的快速适配、对于人类行为的准确模拟等
1.3 大语言模型关键技术概览
- 规模扩展:超大规模语言模型能够展现出一些小型语言模型不具备的能力特点,如上下文学习能力、思维链能力等
- 数据工程:GPT-2给出通过在海量文本上进行下一个词预测的优化,使得模型能够学习到丰富的语义知识信息,进而通过文本补全的方式解决各种下游任务。
- 全面的采集,拓宽高质量的数据来源
- 精细的清洗,尽量提升用于大模型训练的数据质量
- 高效预训练,大规模分布式训练算法优化大语言模型的神经网络参数,并行策略及效率优化方法【(3D 并行(数据并行、流水线并行、张量并行)、ZeRO(内存冗
余消除技术)等】,分布式优化框架:DeepSpeed&Megatron-LM。由于大语言模型的训练需要耗费大量的算力资源,通常需要开展基于小模型的沙盒测试实验,进而确定面向大模型的最终训练策略,提升训练稳定性和优化效率,如混合精度训练 - 能力激发,设计合适的指令微调以及提示学习进行激发或诱导
- 指令微调:使用自然语言表达的任务描述以及期望的任务输出对于大语言模型进行指令微调,提升模型在未见任务上的泛化能力(无法向大模型注入新的知识,训练大模型学会利用自身所掌握的知识与信息进行任务的求解)
- 提示学习:设计合适的提示策略去诱导大语言模型生成正确的问题答案,上下文学习、思维链提示,可以通过逐步求解提升模型在复杂任务上的表现
- 人类对齐:经过海量无标注文本预训练的大语言模型可能会生成有偏见、泄露隐私甚至对人类有害的内容。3H 对齐标准,即Helpfulness(有用性)、Honesty(诚实性)和Harmlessness(无害性)。与人类主观感知相关,很难直接建立形式化的特定优化目标。提出基于人类反馈的强化学习算法(Reinforcement Learning from Human Feedback, RLHF),将人类偏好引入到大模型的对齐过程中。
- 训练奖励模型 :区分模型输出质量好坏
- 强化学习算法来指导语言模型输出行为的调整,让大语言模型能够生成符合人类预期的输出,不过由于强化学习算法优化复杂,出现使用监督微调的对齐方式,从而简化RLHF 优化过程的算法(DPO)。
- 工具使用:受限于预训练数据所提供的信息,无法有效推断出超过数据时间范围以及覆盖内容的语义信息;工具调用能力主要是通过指令微调以及提示学习两种途径实现,而未经历过特殊训练或者缺乏有效提示的大语言模型则很难有效利用候选工具
二、基础介绍
2.1 大语言模型的构建过程
- 大规模预训练
- 指令微调与人类对齐
- “指令微调”(也叫做有监督微调,Supervised Fine-Tuning, SFT),使用任务输入与输出的配对数据进行模型训练,可以使得语言模型较好地掌握通过问答形式进行任务求解的能力。一般需要数十万到百万规模的指令微调数据。对于算力资源的需求相对较小。
- 基于人类反馈的强化学习对齐方法RLHF(Reinforcement Learning from Human Feedback),在指令微调后使用强化学习加强模型的对齐能力,需要训练一个符合人类价值观的奖励模型(Reward Model)。需要标注人员针对大语言模型所生成的多条输出进行偏好排序,并使用偏好数据训练奖励模型,用于判断模型的输出质量。
2.2 扩展法则
可预测的扩展(Predictable Scaling)::使用小模型的性能去预估大模型的性能,或者使用大模型的早期训练性能去估计训练完成后的性能
- KM 扩展法则:模型规模(𝑁)、数据规模(𝐷)和计算算力(𝐶)之间的幂律关系

N、D、C分别对应于非嵌入参数数量、训练数据数量和实际的算力开销。 - Chinchilla 扩展法则
2.3 涌现能力
定义:当模型扩展到一定规模时,模型的特定任务性能突然出现显著跃升的趋势,远超过随机水平。 - 代表性的涌现能力:
- 上下文学习:在提示中为语言模型提供自然语言指令和多个任务示例,无需显式的训练或梯度更新,仅输入文本的单词序列就能为测试样本生成预期的输出。
- 指令遵循:通过指令微调,大语言模型可以在没有使用显式示例的情况下按照任务指令完成新任务,有效提升了模型的泛化能力。
- 逐步推理:用思维链(Chain-of-Thought, CoT)提示策略来加强推理性能。可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解。
- 涌现能力与扩展法则的关系
两种不同的模型性能提升趋势(持续改进v.s. 性能跃升)- 扩展法则使用语言建模损失来衡量语言模型的整体性能,整体上展现出了较为平滑的性能提升趋势,具有较好的可预测性
- 涌现能力通常使用任务性能来衡量模型性能,整体上展现出随规模扩展的骤然跃升趋势,不具有可预测性
2.4 GPT 系列模型的技术演变

- 早期探索:
- GPT-1(Generative Pre-Training):预测下一个Token任务,无监督预训练和有监督微调相结合的范式。与BERT同期,与BERT-Base参数相当,性能没有优势,未引发关注;
- GPT-2:沿用GPT-1架构,参数规模扩大至1.5B,使用大规模网页数据集WebText 进行预训练,GPT-2 旨在探索通过扩大模型参数规模来提升模型性能,并且尝试去除针对特定任务所需要的微调环节。使用无监督预训练的语言模型来解决各种下游任务,进而不需要使用标注数据进行显式的模型微调。𝑃(output|input, task)——根据输入和任务信息来预测输出。输入、输出、任务信息均通过自然语言描述,后续求解则是任务方案(或答案)的文本生成问题。“如果无监督语言建模经过训练后具有足够的能力复原全部世界文本,那么本质上它就能够解决各种任务”。
- 规模扩展
- GPT-2可看成是无监督多任务学习器,效果逊色于有监督微调
- GPT-3对模型参数规模进行大幅扩展至175B,在下游任务中初步展现出了一定的通用性(通过上下文学习技术适配下游任务),为后续打造更为强大的模型确立了关键的技术发展路线。
- GPT-3提出上下文学习,上下文学习可以指导大语言模型学会“理解”自然语言文本形式描述的新任务,从而消除了针对新任务进行微调的需要。模型预训练是在给定上下文条件下预测后续文本序列,模型使用则是根据任务描述以及示例数据来推理正确的任务解决方案。
- 能力增强
- 代码数据训练:GPT-3对编程问题和数学问题求解不好,推出Codex,在大量GitHub 代码数据集合上微调的GPT 模型。GPT-3.5模型是在基于代码训练的GPT 模型(即code-davinci-002)基础上开发 ,对于可用于预训练的数据范围的扩展,可能并不局限于自然语言形式表达的文本数据。
- 人类对齐:InstructGPT旨在改进GPT-3 模型与人类对齐的能力,建立了基于人类反馈的强化学习算法,即RLHF 算法。这对安全部署非常重要。
- 性能跃升
- ChatGPT:沿用了InstructGPT训练技术, 对于对话能力进行了针对性优化。并支持了插件机制
- GPT-4:由单一文本模态扩展到了图文双模态,为期六个月的迭代对齐(在基于人类反馈的强化学习中额外增加了安全奖励信号),GPT-4 对恶意或挑衅性查询的响应更加安全。
- GPT-4V、GPT-4 Turbo,讨论了与视觉输入相关的风险评估手段和缓解策略。GPT-4 Turbo 扩展了知识来源(拓展到2023 年4 月),支持更长上下文窗口(达到128K),优化了模型性能(价格更便宜),引入了若干新的功能(如函数调用、可重复输出
等)。
三、大语言模型资源
3.1 公开可用的模型检查点或API
- 公开可用的通用大语言模型检查点
- LLaMA 和LLaMA-2:LLaMA 2023.2,包括7B、13B、30B 和65B ,开源。13B超越了175B的GPT-3。65B模型在2,048 张80G 显存的A100 GPU 上训练了近21 天。由于开源且性能优秀,以其为基座模型进行微调或继续预训练,衍生出了众多变体模型。7月,LLaMA-2诞生,7B、13B、34B(未开源)和70B,可用于商用。扩充了预训练的词元量(1T到2T),上下文长度翻了一倍(达到4,096 个词元),引入了分组查询注意力机制。LLaMA-2 作为基座模型 + 预训练-有监督微调-基于人类反馈的强化学习 = LLaMA-2 Chat(面向对话),更好的模型性能,也更加安全。
- ChatGLM【智谱AI+清华】:现在已经迭代到了ChatGLM-3,参数量均为6B,
四、数据准备
4.1 数据来源
- 网页:大规模网页文本数据进行预训练,有助于大语言模型获取多样化的语言知识,并增强其自然语言理解和生成的能力
- 书籍:内容更正式与详实,篇幅较长,模型可以积累丰富的语言知识,还能加强其长程语义关系的建模
- 多语文本:在多语言语料库上训练过的大语言模型能够更好地建立多语言间的语义关联,为跨语言理解与对话任务提供支持
- 科学文本:构建科学文本语料的常用方法是收集arXiv 论文、科学教材、数学网页等科学资源,特殊符号需要预处理
- 代码:Stack Exchange 等编程问答社区的数据& GitHub 等开源项目仓库
4.2 数据预处理(消除低质量、冗余、无关甚可能有害的数据)

-
质量过滤:
- 基于启发式规则的方法:语种、简单统计指标(语料中标点符号分布、符号与单词比率、句子长度)、困惑度(Perplexity)等文本生成的评估指标来检测和删除表达不自然的句子、关键词(重复文本模式)
- 基于分类器的方法:训练用于判别数据质量的文本分类器,进行预训练语料的清洗;为了减少数据的误筛(训练样本中低资源),可以使用多个分类器进行联合过滤或召回;轻量级模型(FastText)、可微调的预训练语言模型、闭源大模型API。
- 基于启发式的方法,规则简洁,能够迅速过滤10M 乃至100M 级别的庞大文档集。基于分类器有更高的精确度,但需要消耗更多的计算资源。为了平衡效率与准确性,可以针对具体数据集合进行清洗策略的灵活组合。初筛&精筛。
-
敏感内容过滤(有毒内容或隐私信息)
- 过滤有毒内容:基于分类器,训练数据如Jigsaw 评论数据集合,包括“有毒”、“严重有毒”、“有威胁”、“侮辱性”、“暴力”以及“身份仇恨”等六个类别,需要在精确度和召回率之间平衡
- 过滤隐私内容:直接且有效的方法是使用启发式方法,如关键字识别,来检测和删除这些私人信息,邮箱地址、IP 地址以及电话号码

-
数据去重:大语言模型具有较强的数据拟合与记忆能力,很容易习得训练数据中的重复模式,可能导致对于这些模式的过度学习。这些数据也可能导致训练过程的不稳定(训练损失震荡),可能导致训练过程崩溃。
- 计算粒度:句子级别、文档级别和数据集级别。a. 删除包含重复单词和短语的低质量句子。b. 依靠单词或𝑛 元词组的重叠这类表层特征,来衡量文档的重叠比率,进而检测和删除包含相似内容的重复文档。c.去除那些具有高度相似甚至完全一致内容的文档
- 用于去重的匹配方法:精确匹配(完全相同)与近似匹配算法(基于相似性度量),
-
数据对预训练效果的影响 - 含有噪音、有毒和重复数据的低质量语料库进行预训练,会严重损害模型性能
- 如果模型在包含事实性错误的、过时的数据上进行训练,那么它在处理相关主题时可能会产生不准确或虚假的信息,这种现象被称为"幻象"。
- 重复数据影响巨大:将语料中0.1% 的数据重复100 次后,基于这些包含重复数据语料训练的800M 参数模型,其性能仅能达到在无重复语料上训练的400M 参数模型的相同表现。“双下降现象”:模型训练损失先经历下降然后出现升高再下降的现象
- 有偏、有毒、隐私内容:
- 数据集污染:训练集与测试集重叠
4.3 词元化
-
BPE:BPE 算法从一组基本符号(例如字母和边界字符)开始,迭代地寻找语料库中的两个相邻词元,并将它们替换为新的词元,这一过程被称为合并。合并的选择标准是计算两个连续词元的共现频率,也就是每次迭代中,最频繁出现的一对词元会被选择与合并。合并过程将一直持续达到预定义的词表大小。


字节级别的BPE(Byte-level BPE, B-BPE)是BPE 算法的一种拓展,实现更细粒度的分割,且解决了未登录词问题(GPT-2 、BART 和LLaMA)。GPT-2 的词表大小为50,257 ,包括256 个字节的基本词元、一个特殊的文末词元以及通过50,000 次合并学习到的词元。通过使用一些处理标点符号的附加规则,GPT2 的分词器可以对文本进行分词,不再需要使用“<UNK>” 符号 -
WordPiece 分词: BERT,与BPE类似,通过迭代合并连续的词元,但是合并的选择标准略有不同。会首先训练一个语言模型,并用这个语言模型对所有可能的词元对进行评分。然后,在每次合并时,它都会选择使得训练数据的似然性增加最多的词元对。

-
Unigram:从语料库的一组足够大的字符串或词元初始集合开始,迭代地删除其中的词元,直到达到预期的词表大小。T5 和mBART,pretrained一元语言模型,EM算法优化该模型,使用动态规划算法高效地找到语言模型对词汇的最优分词方式。
-
SentencePiece支持BPE 分词和Unigram 分词,分词器特性:无损重构(准确无误地还原为原始输入文本),高压缩率(经过分词处理后的词元数量应尽可能少,从而实现更为高效的文本编码和存储)

4.4 数据调度 - 混合比例&训练顺序

- 数据混合:

- 数据混合策略(配比):增加数据源的多样性;优化数据混合(手动/可学习方式);优化特定能力
- 数据课程:指按照特定的顺序安排预训练数据进行模型的训练:代码能力,数学能力.长文本能力.
相关文章:
大语言模型(LLM)入门级选手初学教程
链接:https://llmbook-zh.github.io/ 前言: GPT发展:GPT-1 2018 -->GPT-2&GPT-3(扩大预训练数据和模型参数规模)–> GPT-3.5(代码训练、人类对齐、工具使用等)–> 2022.11 ChatG…...
).oO 困)
HTML 实例/测验之HTML 基础一口气讲完!(o-ωq)).oO 困
HTML 基础 非常简单的HTML文档 <!DOCTYPE html> <html><head><title>页面标题(w3cschool.cn)</title></head><body><h1>我的第一个标题</h1><p>我的第一个段落。</p></body> </html> 输出&a…...

c语言基础程序——经典100道实例。
c语言基础程序——经典100道实例 001, 组无重复数字的数002,企业发放的奖金根据利润提成003,完全平方数004,判断当天是这一年的第几天005,三个数由小到大输出006,输出字母C图案007,特殊图案008&…...
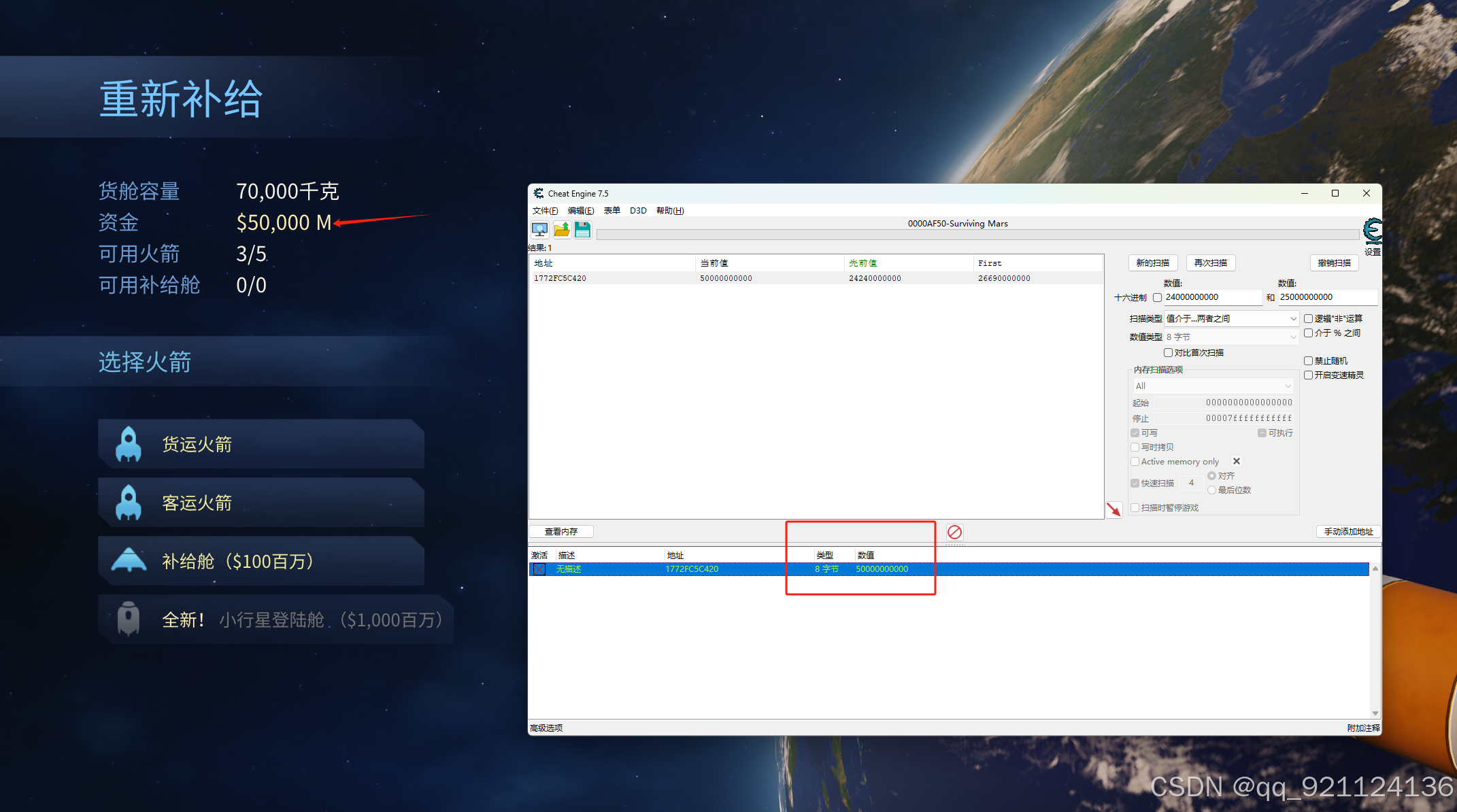
火星求生CE修改金钱,无限资金
由于火星求生前期没有资金非常难玩,想通过修改资金渡过前期,网上找了一圈修改器,只有修改无限声望和无限科研,就是没有无限资金,于是自己用CE修改 教程 首先查看自己资金是多少M,如下图我是22430M资金&…...
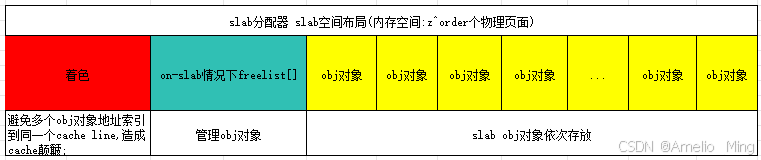
linux 内存管理-slab分配器
伙伴系统用于分配以page为单位的内存,在实际中很多内存需求是以Byte为单位的,如果需要分配以Byte为单位的小内存块时,该如何分配呢? slab分配器就是用来解决小内存块分配问题,也是内存分配中非常重要的角色之一。 slab分配器最终还是由伙伴系统分配出实际的物理内存,只不过s…...
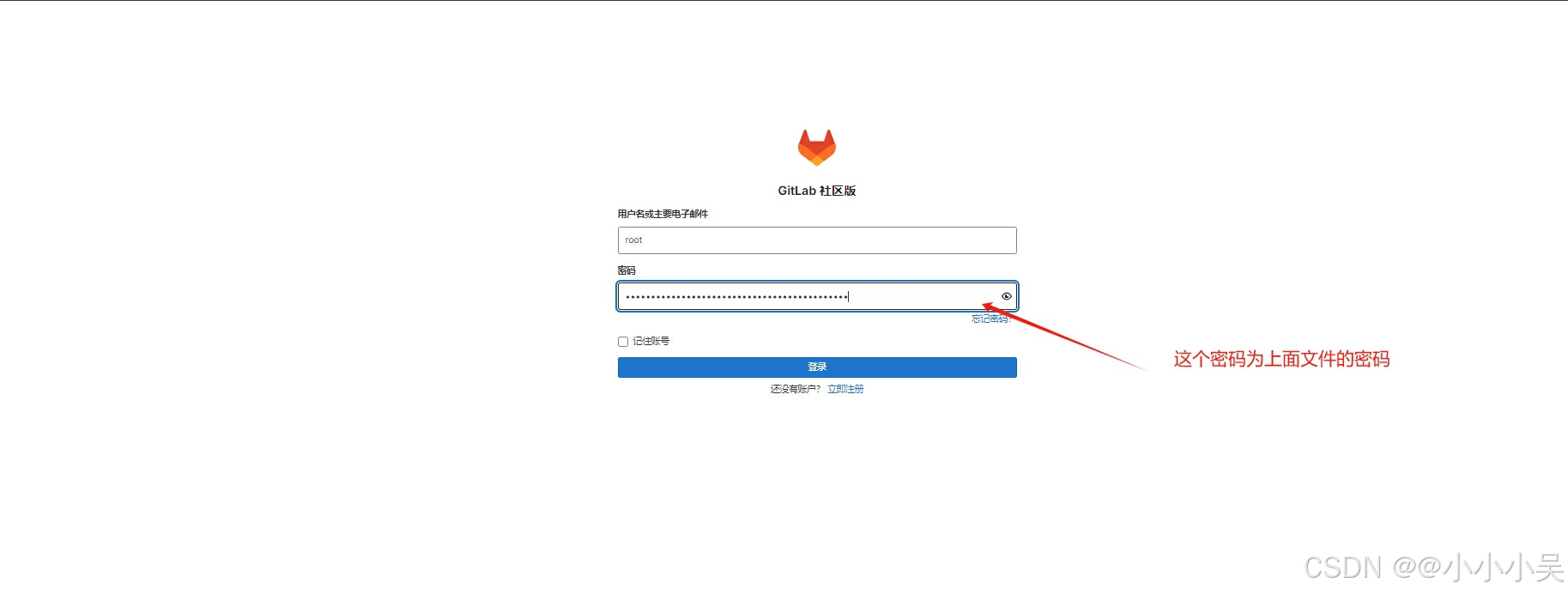
docker-compose部署gitlab(亲测有效)
一.通过DockerHub拉取Gitlab镜像 docker pull gitlab/gitlab-ce:latest 二.创建目录 mkdir -p /root/tool/gitlab/{data,logs,config} && cd /root/tool/gitlab/ 三.编辑DockerCompose.yaml文件 vim /root/tool/gitlab/docker-compose.yml version: "3&quo…...

Leetcode 赎金信
利用hash map做 java solution class Solution {public boolean canConstruct(String ransomNote, String magazine) {//首先利用HashMap统计magazine中字符频率HashMap<Character, Integer> magazinefreq new HashMap<>();for(char c : magazine.toCharArray())…...

S7--环境搭建基本操作
1.修改蓝牙名称和地址 工程路径:$ADK_ROOT\adk\src\filesystems\CDA2\factory_default_config\ 在subsys7_config5.htf中 DeviceName = "DEVICE_NAME“ # replace with your device name BD_ADDRESS=[00 FF 00 5B 02 00] # replace with your BD address 2.earbud工程修改…...

webAPI中的排他思想、自定义属性操作、节点操作(配大量案例练习)
一、排他操作 1.排他思想 如果有同一组元素,我们想要某一个元素实现某种样式,需要用到循环的排他思想算法: 1.所有的元素全部清除样式 2.给当前的元素设置样式 注意顺序能不能颠倒,首先清除全部样式,再设置自己当前的…...

101、QT摄像头录制视频问题
视频和音频录制类QMediaRecorder QMediaRecorder 通过摄像头和音频输入设备进行录像。 注意: 使用Qt多媒体模块的摄像头相关类无法在Windows平台上进行视频录制,只能进行静态图片抓取但是在Linux平台上可以实现静态图片抓取和视频录制。 Qt多媒体模块的功能实现是依…...
FairGuard游戏加固全面适配纯血鸿蒙NEXT
2024年10月8日,华为正式宣布其原生鸿蒙操作系统 HarmonyOS NEXT 进入公测阶段,标志着其自有生态构建的重要里程碑。 作为游戏安全领域领先的第三方服务商,FairGuard游戏加固在早期就加入了鸿蒙生态的开发,基于多项独家技术与十余年…...

鲸信私有化即时通信如何平衡安全性与易用性之间的关系?
即时通信已经成为我们生活中不可或缺的一部分。从日常沟通到工作协作,每一个信息的传递都承载着信任与效率。然而,随着网络安全威胁日益严峻,如何在享受即时通信便捷的同时,确保信息的私密性与安全性,成为了摆在我们面…...

vivado 接口带宽验证
存储器接口 使用赛灵思存储器 IP 时需要更多的 I/O 管脚分配步骤。自定义 IP 之后,您可采用 Vivado IDE 中的细化 (elaborated) 或综 合 (synthesized) 设计分配顶层 IP 端口到物理封装引脚。同每一个存储器 IP 关联的所有端口都被纳入一个 I/O 端口接口…...

Qt中使用线程之QThread
使用Qt中自带的线程类QThread时 1、需要定义一个子类继承自QThread 2、重写run()方法,在run方法中编写业务逻辑 3、子类支持信号槽 4、子类的构造函数的执行是在主线程进行的,而run方法的执行是在子线程中进行的 常用方法 静态方法 获取线程id 可…...

多IP连接
一.关闭防火墙 systemctl stop firewalld setenforce 0 二.挂在mnt mount /dev/sr0 /mnt 三.下载nginx dnf install nginx -y 四.启动nginx协议 systemctl start nginx 五.修改协议 vim /etc/nginx/nginx.conf 在root前加#并且下一行添加 root /www:(浏…...

Linux重点yum源配置
1.配置在线源 2.配置本地源 3.安装软件包 4.测试yum源配置 5.卸载软件包...
289.生命游戏
目录 题目解法代码说明: 每一个各自去搜寻他周围的信息,肯定存在冗余,如何优化这个过程?如何遍历每一个元素的邻域?方向数组如何表示方向? auto dir : directions这是什么用法board[i][j]一共有几种状态&am…...

如何保证Redis和数据库的数据一致性
文章目录 0. 前言1. 补充知识:CP和AP2. 什么情况下会出现Redis与数据库数据不一致3. 更新缓存还是删除缓存4. 先操作缓存还是先操作数据库4.1 先操作缓存4.1.1 数据不一致的问题是如何产生的4.1.2 解决方法(延迟双删)4.1.3 最终一致性和强一致…...

Android Framework AMS(06)startActivity分析-3(补充:onPause和onStop相关流程解读)
该系列文章总纲链接:专题总纲目录 Android Framework 总纲 本章关键点总结 & 说明: 说明:本章节主要解读AMS通过startActivity启动Activity的整个流程的补充,更新了startActivity流程分析部分。 一般来说,有Activ…...

【LangChain系列2】【Model I/O详解】
目录 前言一、LangChain1-1、介绍1-2、LangChain抽象出来的核心模块1-3、特点1-4、langchain解决的一些行业痛点1-5、安装 二、Model I/O模块2-0、Model I/O模块概要2-1、Format(Prompts Template)2-1-1、Few-shot prompt templates2-1-2、Chat模型的少样…...

Linux应用配置分层实战指南
Linux应用配置分层实战指南本文面向具备一定 Linux 基础的技术人员,围绕应用配置分层展开,重点讨论默认配置、环境覆盖和敏感参数隔离。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在…...

【亲测免费】 TSK UF系列Prober操作手册下载
TSK UF系列Prober操作手册下载 【下载地址】TSKUF系列Prober操作手册下载 本仓库提供TSK UF系列Prober的操作手册下载,具体为UF190/UF200系列的manual。TSK UF系列Prober是半导体厂针测的重要设备,该手册详细介绍了设备的各项功能、操作步骤以及维护保养…...

Bootstrap Magic自定义组件开发:扩展你的主题生成能力
Bootstrap Magic自定义组件开发:扩展你的主题生成能力 【免费下载链接】bootstrap-magic Bootstrap themes generator made with AngularJS 项目地址: https://gitcode.com/gh_mirrors/bo/bootstrap-magic Bootstrap Magic是一款基于AngularJS构建的Bootstra…...
基于Circuit Playground Express与NeoPixel的智能光控花环制作全攻略
1. 项目概述:打造一个会“呼吸”的智能光之花环你是否想过,让一串普通的装饰灯带拥有感知环境、自动调节的“生命”?这听起来像是科幻电影里的场景,但实际上,利用今天唾手可得的开源硬件和图形化编程工具,任…...
)
NotebookLM文档召回率骤降73%?(内部实验报告首次公开:BM25+SBERT混合排序实战框架)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM相似文档推荐 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的实验性工具,其核心能力之一是“相似文档推荐”——即在用户提问时,自动从已导入的文…...

B站视频转文字终极指南:5分钟掌握高效知识管理神器
B站视频转文字终极指南:5分钟掌握高效知识管理神器 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容࿰…...

深度解析DriverStore Explorer:Windows驱动存储管理的终极解决方案
深度解析DriverStore Explorer:Windows驱动存储管理的终极解决方案 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Windows系统驱动管理是每个高级用户和系统管理员都会面临…...

因果推理第四层盲区:为什么关联≠因果
因果推理第四层盲区:为什么关联≠因果 副标题: 从Pearl因果阶梯到知识库因果链,AI如何跨越观测vs建模的鸿沟痛点:为什么你的AI只能"描述"不能"规划"? 你有没有遇到过这样的情况: AI能告诉你"…...

Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生![特殊字符]
Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生!🚀 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是…...

3步深度解决方案:彻底修复Krita AI Diffusion插件IP-Adapter缺失问题
3步深度解决方案:彻底修复Krita AI Diffusion插件IP-Adapter缺失问题 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: h…...