计算不停歇,百度沧海数据湖存储加速方案 2.0 设计和实践
本文整理自百度云智峰会 2024 —— 云原生论坛的同名演讲。

今天给大家介绍下百度沧海·存储团队在数据湖加速方面的工作进展情况。
数据湖这个概念,从 2012 年产生到现在已经有十余年的时间,每家公司对它内涵的解读都不太一样。但是数据湖的主要存储底座有从传统的 HDFS 向对象存储演进的趋势。
传统的大数据计算场景,比如 MapReduce、Spark、Hive 这些大数据组件都是基于 HDFS 构建的。但是,它有如下几点不足:
-
第一个是资源问题。由于 HDFS 计算资源和存储资源混布在一起,只有计算和存储资源匹配,才不会出现资源的浪费。这对业务发展趋势的规划能力要求是非常高的,实际业务中很难预测 3 年、5 年之后的计算和存储的规模变化,如果出现不匹配,会出现某种资源的浪费。
-
第二个是规模问题,单个 HDFS 集群的 Namenode 最高支持 10 亿量级的规模的文件数,现在大模型训练文件数最高会超过百亿,甚至千亿的文件规模, HDFS 集群很难满足,虽然有一些改进方案,如集群的 Federation 可以使支持的规模变得大一些,实际上会牺牲很多特性,带来使用上的不便。
-
第三个运维问题。HDFS 运维负担比较重,需要有丰富的 HDFS 运维经验的工程师才能解决数百 PB 规模集群的可靠性、可用性问题。
对象存储的出现可以很好的解决 HDFS 存在的问题:
-
对象存储作为存储组件是存算分离的架构,计算和存储可以独立扩容,具有更大的弹性。
-
对象存储扩展性要好,支持的规模更大,并具有云原生的无运维负担、多级存储体系成本低等特点。

对象存储作为数据湖存储底座能完美的代替 HDFS 吗?
这里还是有诸多挑战需要解决:
第一个挑战是性能问题。存算分离有弹性的优势,但是性能有下降。在元数据维度,HDFS Client 访问 HDFS Namenode,一次元数据操作只需要几百微秒。而对象存储要经过鉴权、协议转换再加上由于计算节点和存储节点延迟变高的原因,延迟会有增加。在数据面维度,由于要经过网关节点、对象存储前端、以及对象存储后端,相比于 HDFS,数据吞吐会有很大的衰减。
第二个挑战是 HDFS 上游计算生态的兼容性问题。上游的大数据组件 MR、Spark、Hive 这些都是基于 HDFS 构建的,对象存储在访问协议、鉴权方式存在非常大的差异。如何屏蔽这些差异,对上游业务无感实现平滑切换,这也是一个非常棘手的问题。

为了更好的加速上层大数据、AI 计算业务,发挥存储底座的基础支撑作用,百度沧海在数据湖存储加速方案 1.0 的基础上,发布了数据湖存储加速 2.0 版本,在新版本中:
-
升级了层级 Namespace 2.0 版本,实现了基于规模的自适应存储架构,达到了规模和性能的有效平衡。
-
在对象存储后端升级了对大数据更加友好的流式存储引擎。相比于 HDFS,单流吞吐提升 70% 以上。
-
在计算侧缓存我们发布了 RapidFS 托管型产品,能够更高效的实现数据缓存和写入加速。
-
同时,发布了 BOS-HDFS 全新版本,实现了对 HDFS API 100% 兼容,能够实现上层业务无缝对接和迁移。
下面分别展开介绍一下各个方面的内容。

先看一下 Namespace 的演进路线。
对象存储有两套 Namespace 体系,一个是平坦 Namespace,另外一个是层级 Namespace。平坦 Namespace 对大数据计算来说有 rename 原子性和性能问题,省去不谈,这里重点讲一下层级 Namespace 的演进。
-
第一代的层级 Namespace 方案,是单机的方案,最典型的代表是 HDFS 的目录树全内存方案,这种方案性能高,但是扩展性差,只能在 10 亿的量级。有的系统把目录树全内存扩展到了 SSD,部分热数据放内存或者一些系统做了静态子树划分的扩展方案,支持的规模有一定的增加,但是扩展的不多。
-
第二代的层级 Namespace 基于分布式数据库构建,典型的代表是 Facebook 的 Tectonic 系统,优点是线性扩展,支持的规模大,缺点在创建文件、rename 时候会触发多次 RPC 和两阶段提交,延迟相当于单机方案会比较高。
-
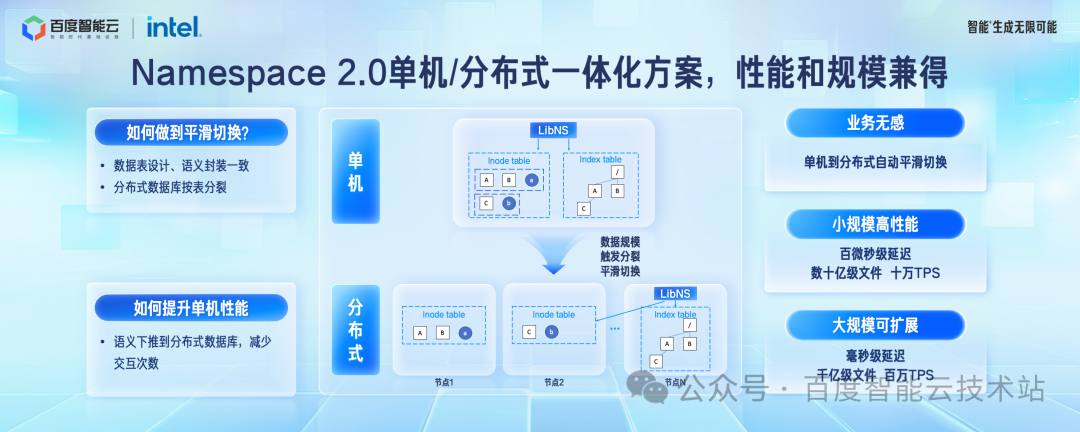
百度提出的第三代层级 Namespace 系统是「单机/分布式一体化方案」,能够做到规模自适应。在规模小的时候具备单机 Namespace 系统的性能优势,百微秒级延迟。在规模扩大到必须采用分布式方案的时候,能够无感平滑迁移到分布式架构,满足规模的水平扩展,适应各个阶段的要求。

单机和分布式架构能够做到合二为一的最核心的一个点是在规模达到临界点的时候,后端架构如何做到平滑切换。
我们是这样做的,无论是单机架构和分布式架构,我们都基于我们自研的分布式数据库去构建,也就是百度沧海的元数据底座 TafDB。
在单机架构下,我们强制层级Namespace依赖的Inode信息和目录树信息绑定分配到同一组存储节点。这个时候,不需要跨机事务和多次 RPC 就可以完成文件创建、目录 rename 等元数据操作,这时候跟单机架构的延迟一致。
当桶的文件规模达到 10 亿量级的临界点之后,会触发分布式数据库按不同的表边界分裂。分布式数据库的分裂操作对上层业务无感,Inode 表动态水平扩展,这个时候单机事务转换为跨节点事务,单次 RPC 转换为多次 RPC,上层 Lib 库对这两种接口进行了很好的的封装,上层 API 一致。
这样单机架构就可以平滑的过渡到分布式架了,分布式架构的性能相对于单机架构有一些衰减,单次操作到毫秒级延迟,但是规模可以支撑到百亿到千亿的规模。
在单机架构下还有一个问题待解决,就是如何提升系统的吞吐。我们的做法是把文件语义操作下推到分布式数据库层,直接使用数据库的内置语义完成操作,减少跟上层组件的通讯次数,单桶支持到十万 TPS。
在对象存储后端数据面的引擎优化方面,我们针对大数据和 AI 场景进行了优化升级。
原来的存储引擎专门针对小文件设计,数据按 Blob 切块之后,数据块随机放到整个集群的磁盘上,这样可以充分分散压力,利用数十万块磁盘的 I/O 能力。
大数据计算有文件大、顺序读的特点。针对这个特点,我们升级了存储引擎,整个文件切成更大的 Block,Block 内部顺序放置。
这样既不会出现热点,又可以充分发挥 HDD 顺序访问高吞吐的优势,一次性预读更多的数据,单流吞吐可以达到 300MB/s,相比于原生 HDFS 单流的带宽提升 70% 以上。

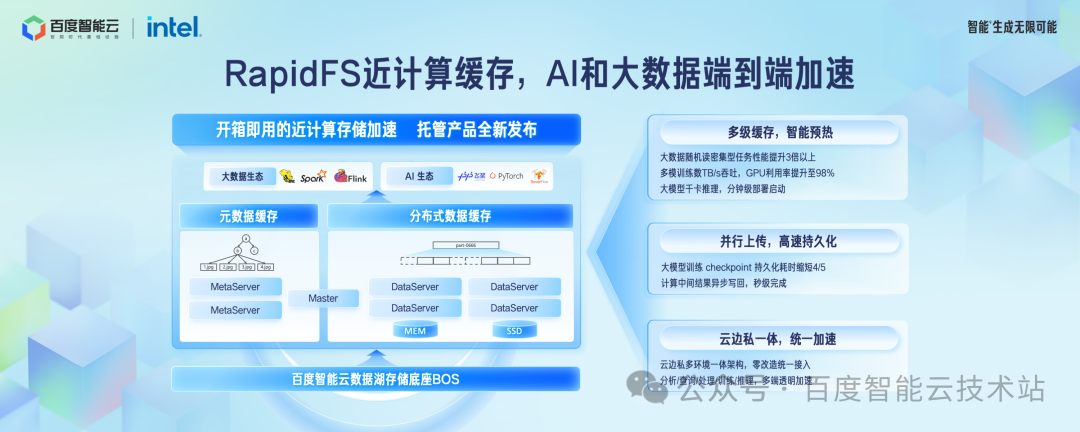
在近计算侧的缓存加速方面,我们发布了 RapidFS 托管型产品,端到端加速大数据和 AI 应用。
对于随机读密集型的计算场景,I/O size 很小,对象存储性能较差,这时候把大块数据缓存到 RapidFS,可以更好的发挥出优势,性能提升 3 倍以上。
在多模态训练场景,通过智能预热到 RapidFS 做训练加速,使得 GPU 使用率提升 98% 以上。
在推理集群模型文件分发场景,RapidFS 支持复制出更多的副本数来分摊读压力,使得千卡推理集群的模型部署在分钟级完成。
对于大模型训练 Checkpoint 持久化场景,数据先写入 RapidFS 的分布式缓存,再异步写到后端的对象存储集群,Checkpoint 持久化耗时缩短了 4/5。
数据湖存储加速 RapidFS 在专属云、边缘云、公有云都提供了一体化的架构,业务可以实现零改造成本统一接入。
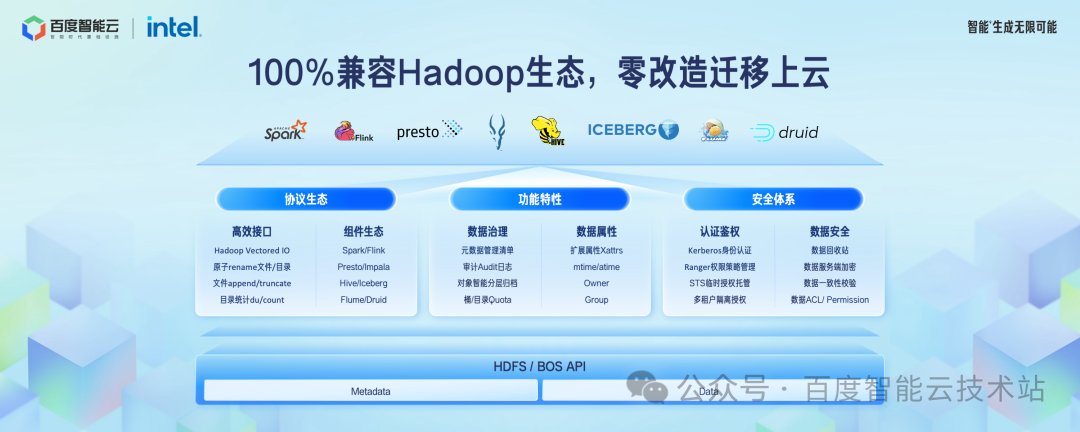
在 Hadoop 生态兼容方面,我们发布了 BOS-HDFS 全新版本,对上层 Hadoop 应用提供 100% 的兼容,无需修改代码就可以运行原有的大数据和 AI 任务,实现零改造迁移上云。
BOS-HDFS 提供了原子 rename、Vectored I/O、文件 append/truncate 等 Posix 文件语义接口。
BOS-HDFS 兼容所有主流计算引擎,并且在这个基础上,提供了额外的智能数据分层、子目录 Quota、日志审计、服务端加密等更丰富的功能。
在认证鉴权方面提供了 Kerboeros + Ranger 到临时 token 鉴权体系的无缝转换方案。
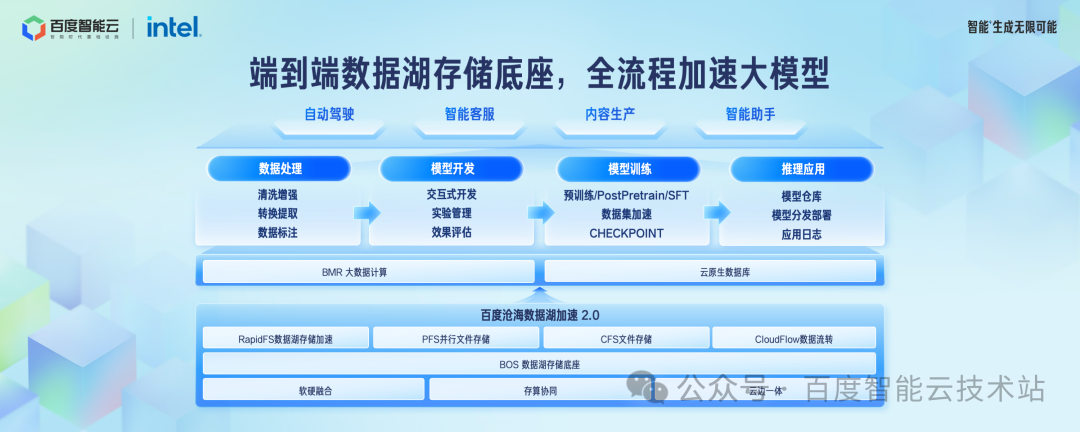
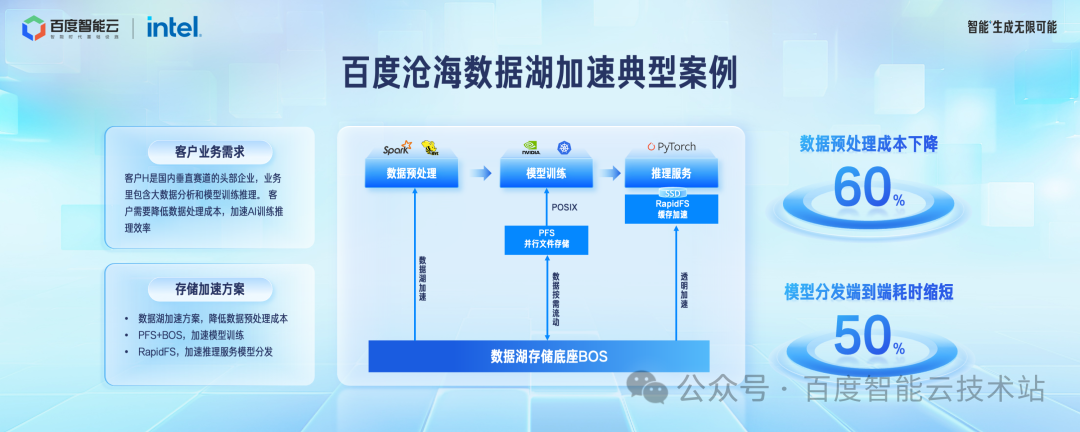
这张图是百度沧海支持大模型场景的全景图。
对象存储 BOS 作为基础的数据存储底座,数据湖存储加速 RapidFS、文件存储 CFS、并行文件存储 PFS 作为加速层,在数据处理、模型开发、模型训练、模型推理各个环节,我们都提供了完善的端到端解决方案。
下面介绍下典型应用案例。
客户 H 是国内垂直赛道的头部客户,在百度智能云上构建自己的 AI 应用。
-
在数据预处理阶段,使用对象存储 BOS 作为数据湖存储底座处理待训练的数据,相比于自建的 HDFS 模式,成本下降了60%。
-
在模型训练阶段,使用 PFS + BOS 的加速方案。热数据按需加载到 PFS,冷数据存放到 BOS。
-
在模型推理阶段,使用 RapidFS 做模型分发的加速。相比于之前的方案,模型分发的端到端延迟缩短了 50% 以上。
以上就是这次的全部分享,谢谢大家!
相关文章:
计算不停歇,百度沧海数据湖存储加速方案 2.0 设计和实践
本文整理自百度云智峰会 2024 —— 云原生论坛的同名演讲。 今天给大家介绍下百度沧海存储团队在数据湖加速方面的工作进展情况。 数据湖这个概念,从 2012 年产生到现在已经有十余年的时间,每家公司对它内涵的解读都不太一样。但是数据湖的主要存储底座…...

vue2项目 实现上边两个下拉框,下边一个输入框 输入框内显示的值为[“第一个下拉框选中值“ -- “第二个下拉框选中的值“]
效果: 思路: 采用vue中 [computed:] 派生属性的方式实现联动效果,上边两个切换时,下边的跟随变动 demo代码: <template><div><!-- 第一个下拉框 --><select v-model"firstValue"><option v-for"option in options" :key&q…...

el-radio 点击报错 Element with focus: inputAncestor with aria-hidden....
一、序言 浏览器版本影响的问题(与代码无关,可能是web或浏览器相关协议更新导致),不影响功能的使用. 翻译:元素上的Blocked aria-hidden,因为刚刚接收焦点的元素不能对辅助技术用户隐藏。避免在焦点元素或…...

集成平台,互联互通平台,企业大数据平台建设方案,技术方案(Word原件 )
企业集成平台建设方案及重点难点攻坚 基础支撑平台主要承担系统总体架构与各个应用子系统的交互,第三方系统与总体架构的交互。需要满足内部业务在该平台的基础上,实现平台对于子系统的可扩展性。基于以上分析对基础支撑平台,提出了以下要求&…...

宠物用品交易网站开发:SpringBoot技术详解
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...
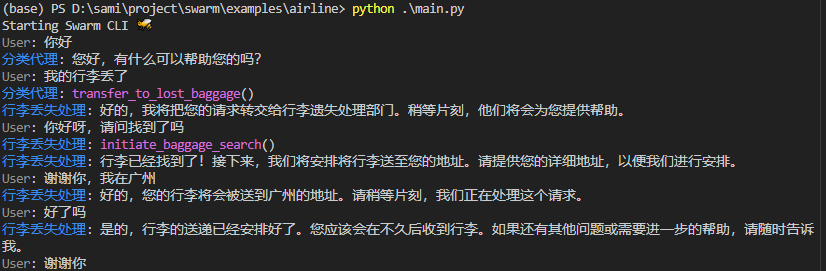
解构OpenAI swarm:利用Cursor进行框架分析与示例运行
解构OpenAI SWARM:利用Cursor进行框架分析与示例运行 1. 引言 在AI技术日新月异的今天,OpenAI再次为我们带来了惊喜。SWARM框架作为其最新研究成果,正在开创多智能体协作的新纪元。本文将带您深入探索这一框架,通过Cursor工具进行代码分析,并手把手教您安装运行SWARM。无论您…...
基于springboot的秦皇岛旅游景点管理系统 设计与实现
博主介绍:专注于Java(springboot ssm 等开发框架) vue .net php phython node.js uniapp 微信小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不…...

uniapp展示本地swf格式文件,实现交互
概览 uniapp打包的Android项目实现本地swf格式文件的展示,并且能够进行交互 需求分析 1、因为是打包的Android项目展示本地的swf文件,首先需要拿到这个本地的swf文件路径 2、如何在uniapp的vue页面中展示swf,因为没有直接展示swf文件的标…...

ZYNQ:流水灯实验
实验目的 PL_LED0 和 PL_LED1 连接到 ZYNQ 的 PL 端,PL_LED0 和 PL_LED1循环往复产生流水灯的效果,流水间隔时间为 0.5s。 原理图 程序设计 本次实验是需要实现两个LED的循环熄灭点亮,时间间隔是0.5S,对时间间隔的控制使用计数器来完成。本…...
配置与实现的深度解析)
StratoVirt中vCPU拓扑(SMP)配置与实现的深度解析
tratoVirt作为计算产业中面向云数据中心的企业级虚拟化平台,通过一套统一的架构支持虚拟机、容器和Serverless三种场景。它不仅在轻量低噪、软硬协同和Rust语言级安全等方面具备关键技术竞争优势,还预留了接口和设计来支持更多特性,并向着标准…...

Xml 相关注解使用
XmlRootElement XmlAccessorType(XmlAccessType.FIELD) 在 Java 中,XmlRootElement 和 XmlAccessorType 是用于 JAXB(Java Architecture for XML Binding)库的注解。它们帮助开发人员将 Java 对象映射到 XML 格式,反之亦然。下面对…...
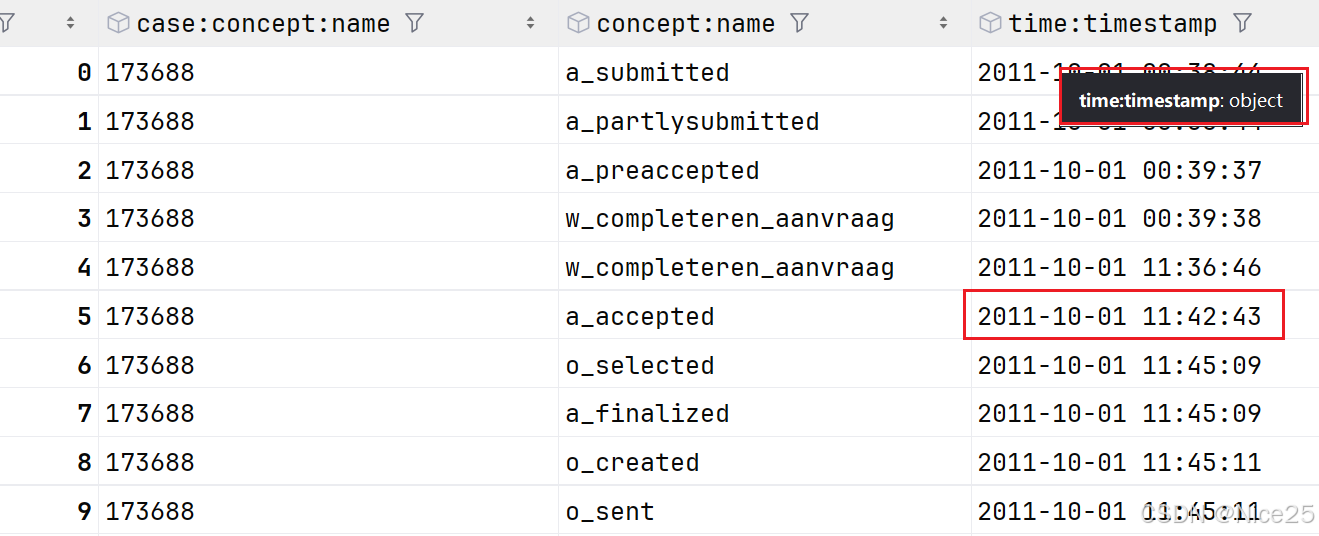
本地时间与时区时间转化(以Helpdesk和BPI Challenge 2012为例)
数据集:Helpdesk 数据来源:https://data.4tu.nl/datasets/94ee26c8-78f6-4387-b32b-f028f2103a2c/1 描述问题:此数据三列属性皆为object,此为本地时间,只需关注时间格式的变化。 经过格式转化, 数据集&am…...

Golang | Leetcode Golang题解之第482题秘钥格式化
题目: 题解: func licenseKeyFormatting(s string, k int) string {ans : []byte{}for i, cnt : len(s)-1, 0; i > 0; i-- {if s[i] ! - {ans append(ans, byte(unicode.ToUpper(rune(s[i]))))cntif cnt%k 0 {ans append(ans, -)}}}if len(ans) &…...

代码随想录 -- 贪心 -- 无重叠区间
435. 无重叠区间 - 力扣(LeetCode) 思路:与上一题十分相似。 依然按照左边界从小到大对数组排序,初始化删除的区间数为0; 从1遍历数组:如果当前区间的左边界小于上一个区间的右边界,说明这两…...

sql server xml
参考SQL Server XML学习笔记 - 缥缈的尘埃 - 博客园...

WPF中MVVM的应用举例
WPF(Windows Presentation Foundation)是微软开发的用于创建用户界面的框架,而MVVM(Model-View-ViewModel)模式是一种分离前端UI逻辑与后台业务逻辑的方法。在WPF中使用MVVM模式可以提高代码的可维护性、可测试性和可扩…...

编程题 7-24 约分最简分式【PAT】
文章目录 题目输入格式输出格式输入样例输出样例 题解解题思路完整代码 编程练习题目集目录 题目 分数可以表示为分子/分母的形式。编写一个程序,要求用户输入一个分数,然后将其约分为最简分式。最简分式是指分子和分母不具有可以约分的成分了。如 6 /…...

尚硅谷大数据Flink1.17实战教程-笔记04【Flink DataStream API】
尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据Flink1.17实战教程-笔记01【Flink 概述、Flink 快速上手】尚硅谷大数据Flink1.17实战教程-笔记02【Flink 部署】尚硅…...

MySQL常见优化策略
MySQL 是一种广泛使用的开源数据库管理系统,性能的优化对于应用程序的效率至关重要。以下是一些常见的 MySQL 优化策略,帮助提高数据库性能和响应速度。🚀 1. 合理的索引设计 使用索引:确保在常用的查询条件(如 WHER…...

gyp ERR stack Error: Command failed: D:\python\python.EXE -c import sys; print
文章目录 1、问题描述 2、解决方案 1、问题描述 网上clone的开源项目在执行npm install的时候报错如下: 2、解决方案 经过多方查证,后来发现是python的版本太高了,我重新配置了个python2.7的环境变量就好了。 …...

Cursor AI插件开发:从代码补全到智能动作执行的范式演进
1. 项目概述:当AI代码助手遇上插件生态最近在GitHub上看到一个挺有意思的项目,叫RightbrainAI/cursor-plugin。光看名字,可能很多用惯了Cursor的朋友会眼前一亮,以为这是Cursor编辑器官方或者某个社区大神出的插件。但点进去仔细一…...

终极指南:如何用NoFences桌面分区工具提升3倍工作效率
终极指南:如何用NoFences桌面分区工具提升3倍工作效率 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上杂乱无章的图标?每天…...

LizzieYzy深度解析:专业围棋AI分析平台的实战进阶手册
LizzieYzy深度解析:专业围棋AI分析平台的实战进阶手册 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 在围棋AI技术日新月异的今天,如何将强大的计算能力转化为实用的分析工…...

ElevenLabs动画配音语音项目踩坑实录,深度复盘4类合规风险与3种本地化绕过方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音项目踩坑实录,深度复盘4类合规风险与3种本地化绕过方案 在为国产原创2D动画《星尘回廊》接入ElevenLabs API实现多语种AI配音时,团队遭遇了超出预期的合规…...

【AI Agent软件直控革命】:20年架构师亲授5大落地陷阱与3步安全接入法
更多请点击: https://intelliparadigm.com 第一章:AI Agent软件直控革命:从概念到产业拐点 AI Agent 已不再停留于对话式助手或任务调度器的初级形态,正加速演进为具备环境感知、自主决策与系统级直控能力的“数字执行体”。其核…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

第07章 FastMCP 把检索封装成 Agent 工具
第07章 FastMCP 把检索封装成 Agent 工具 工单知识库已经能在 Python 进程内被普通函数调用,但要让外部 Agent、Web 后端或其他语言的客户端使用这份能力,函数级别的接口不够:缺少协议、缺少描述、缺少跨进程通讯。MCP(Model Cont…...

制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践
制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0的浪潮中,制造业企业面临着…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

深度学习图像风格迁移:从Gatys算法到PyTorch工程实践
1. 项目概述:一个基于深度学习的图像风格迁移应用最近在GitHub上闲逛,发现了一个名为“aristoapp/DDalkkak”的项目。单看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于图像风格迁移(Image S…...