selenium案例——爬取哔哩哔哩排行榜
案例需求:
1.使用selenium自动化爬虫爬取哔哩哔哩排行榜中舞蹈类的数据(包括视频标题、up主、播放量和评论量)
2.利用bs4进行数据解析和提取
3.将爬取的数据保存在本地json文件中
4.保存在excel文件中
分析:
1.请求url地址:https://www.bilibili.com/v/popular/rank/dance

2.加载等待事件,否则获取数据不充分
wait = WebDriverWait(self.browsers, 280) wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'rank-item'))) time.sleep(5)
3.获取相应内容
last_height = self.browsers.execute_script("return document.body.scrollHeight")
while True:self.browsers.execute_script('window.scrollTo(0, document.body.scrollHeight);')time.sleep(5)data = self.browsers.page_source # 获取网页源码self.parse_data(data=data)new_height = self.browsers.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_height
4.使用bs4解析数据
soup = BeautifulSoup(data, 'lxml')
titles = soup.select('.info .title') # 标题
up_names = soup.select('.info .up-name') # up主
# :nth-of-type(2) 用于选择指定类型的第二个元素
play_counts = soup.select('.info .detail-state .data-box:nth-of-type(1)') # 播放量
comment_counts = soup.select('.info .detail-state .data-box:nth-of-type(2)') # 评论量
rank_data = {}
print(len(titles))
for title, name, play_count, comment_count in zip(titles, up_names, play_counts, comment_counts):t = title.get_text().strip()n = name.get_text().strip()p = play_count.get_text().strip()c = comment_count.get_text().strip()print('标题:', t)print('up主:', n)print('播放量:', p)print('评论量:', c)print('==========================')
5.保存在本地json文件中
with open('rank_data.json', 'a', encoding='utf-8') as f:f.write(json.dumps(rank_data, ensure_ascii=False) + '\n')
6.保存在excel文件中
wb =workbook.Workbook()#创建一个EXcel对象 就相当于是要生成一个excel 程序 ws = wb.active #激活当前表 ws.append(['标题','up主','播放量','评论量'])
#保存数据
def save_data(self,title,name,paly,comment):ws.append([title,name,paly,comment])# 保存为Excel数据wb.save('哔哩哔哩排行榜数据.xlsx')
案例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from openpyxl import workbook #第三方模块 需要安装
import time
import jsonwb =workbook.Workbook()#创建一个EXcel对象 就相当于是要生成一个excel 程序
ws = wb.active #激活当前表
ws.append(['标题','up主','播放量','评论量'])class Spider:def __init__(self):self.url = 'https://www.bilibili.com/v/popular/rank/dance'self.options = webdriver.ChromeOptions()self.options.add_experimental_option('excludeSwitches', ['enable-automation'])self.browsers = webdriver.Chrome(options=self.options)# 访问哔哩哔哩排行榜def get_bili(self):self.browsers.get(self.url)wait = WebDriverWait(self.browsers, 280)wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'rank-item')))time.sleep(5)# 获取响应内容def get_data(self):last_height = self.browsers.execute_script("return document.body.scrollHeight")while True:self.browsers.execute_script('window.scrollTo(0, document.body.scrollHeight);')time.sleep(5)data = self.browsers.page_source # 获取网页源码self.parse_data(data=data)new_height = self.browsers.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_height# 解析信息def parse_data(self, data):soup = BeautifulSoup(data, 'lxml')titles = soup.select('.info .title') # 标题up_names = soup.select('.info .up-name') # up主# :nth-of-type(2) 用于选择指定类型的第二个元素play_counts = soup.select('.info .detail-state .data-box:nth-of-type(1)') # 播放量comment_counts = soup.select('.info .detail-state .data-box:nth-of-type(2)') # 评论量rank_data = {}print(len(titles))for title, name, play_count, comment_count in zip(titles, up_names, play_counts, comment_counts):t = title.get_text().strip()n = name.get_text().strip()p = play_count.get_text().strip()c = comment_count.get_text().strip()print('标题:', t)print('up主:', n)print('播放量:', p)print('评论量:', c)print('==========================')self.save_data(t,n,p,c)rank_data['标题'] = trank_data['up主'] = nrank_data['播放量'] = prank_data['评论量'] = cwith open('rank_data.json', 'a', encoding='utf-8') as f:f.write(json.dumps(rank_data, ensure_ascii=False) + '\n')#保存数据def save_data(self,title,name,paly,comment):ws.append([title,name,paly,comment])# 保存为Excel数据wb.save('哔哩哔哩排行榜数据.xlsx')if __name__ == '__main__':s = Spider()s.get_bili()s.get_data()运行结果:



相关文章:
selenium案例——爬取哔哩哔哩排行榜
案例需求: 1.使用selenium自动化爬虫爬取哔哩哔哩排行榜中舞蹈类的数据(包括视频标题、up主、播放量和评论量) 2.利用bs4进行数据解析和提取 3.将爬取的数据保存在本地json文件中 4.保存在excel文件中 分析: 1.请求url地址&…...

HTML5教程(三)- 常用标签
1 文本标签-h 标题标签(head): 自带加粗效果,从h1到h6字体大小逐级递减一个标题独占一行 语法 <h1>一级标题</h1><h2>二级标题</h2><h3>三级标题</h3><h4>四级标题</h4><h5…...

【HCIE-Datacom考试战报】2024-08-21 深圳 SRv6
8月21日深圳考试战报(SRV6) 前言 大家好呀,我是来自誉天的学员---,我是今年4月份开始看集训、备考实验的,但是专业课比较多,又还有其他比赛,所以我刚开始的进度很慢,六月底才进入冲…...

【京准电钟】“安全卫士”:卫星时空安全隔离防护装置
【京准电钟】“安全卫士”:卫星时空安全隔离防护装置 【京准电钟】“安全卫士”:卫星时空安全隔离防护装置 当前,我国电力系统普遍采用北斗卫星或者GPS卫星授时来实现时间同步,但不加防护的授时装置存在卫星信号被干扰或欺骗的风险…...

优先级队列(2)_数据流中第k大元素
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 优先级队列(2)_数据流中第k大元素 收录于专栏【经典算法练习】 本专栏旨在分享学习算法的一点学习笔记,欢迎大家在评论区交流讨论💌 目…...

【CSS】纯CSS Loading动画组件
<template><div class"ai-loader-box"><!-- AI loader --><div class"ai-loader"><div class"text"><p>AI智能分析中....</p></div><div class"horizontal"><div class&quo…...

rootless模式下istio ambient鉴权策略
环境说明 rootless模式下测试istio Ambient功能 四层鉴权策略 这里四层指的是网络通信模型的第四层,主要的传输协议为TCP和UDP。 用于限制服务间的通信,比如下面的策略应用于带有 app: productpage 标签的 Pod, 并且仅允许来自服务帐户 clus…...

超详细的总结!最新大模型算法岗面试题(含答案)来了!
大模型应该是目前当之无愧的最有影响力的AI技术,它正在革新各个行业,包括自然语言处理、机器翻译、内容创作和客户服务等,正成为未来商业环境的重要组成部分。 截至目前大模型已超过200个,在大模型纵横的时代,不仅大模…...

vmware-17pro全网最细安装教程(图文讲解,不需注册账户)
文章目录 一、下载安装包: 二、安装教程: 三、检查是否安装成功 四、许可证密匙 vmware安装教程 一、下载安装包: 链接:https://pan.baidu.com/s/1yC610SU1-O9Jtk7nUrZuSA?pwdsKBy 提取码:sKBy 二、安装教程&…...
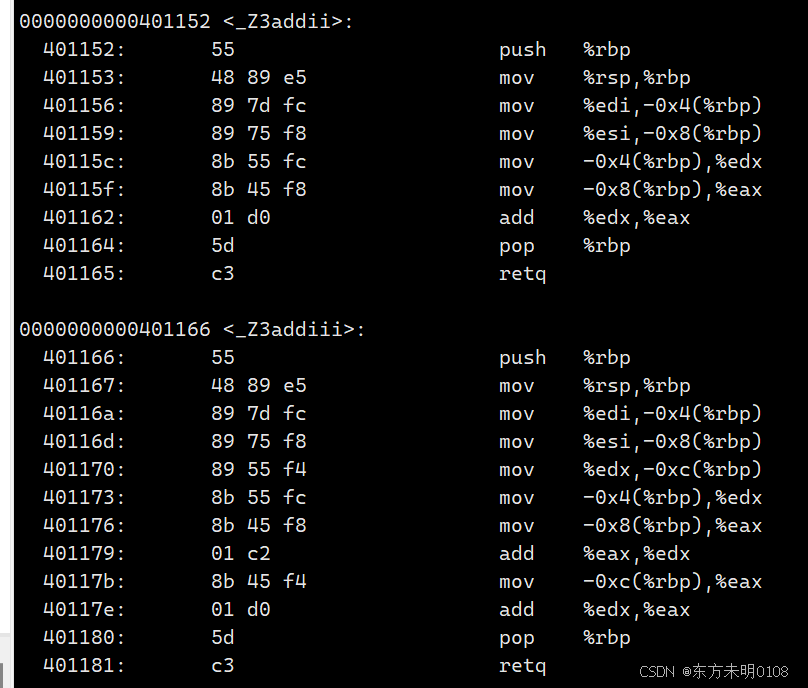
C/C++(二)C++入门基础
这一章会介绍C入门必须掌握的一些基础概念。 一、函数重载 1、什么是函数重载? 函数重载是C相比于C语言的一个重大改进。 即C允许在同一作用域内声明多个功能类似的同名函数,这些函数的参数类型 / 个数 / 类型顺序不同。(注:返回…...

人工智能发展:一场从“被教导”到“自我成长”的奇妙冒险
说到人工智能(AI),大家的第一反应往往是机器人、无人驾驶、或者那个让人害怕的AI会不会取代人类。其实,AI的进化过程简直像一部精彩的电影,有起伏、有高潮、有让人摸不着头脑的时刻。今天,我们就一起来“吃…...

企业级 RAG 全链路优化关键技术
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人: 邢少敏 | 阿里云智能集团高级技术专家 活动: 2024 云栖大会 - AI 搜索企业级 RAG 全链路优化关键技术 在2024云栖大会上,阿里云 AI 搜索研发负责人之一的…...
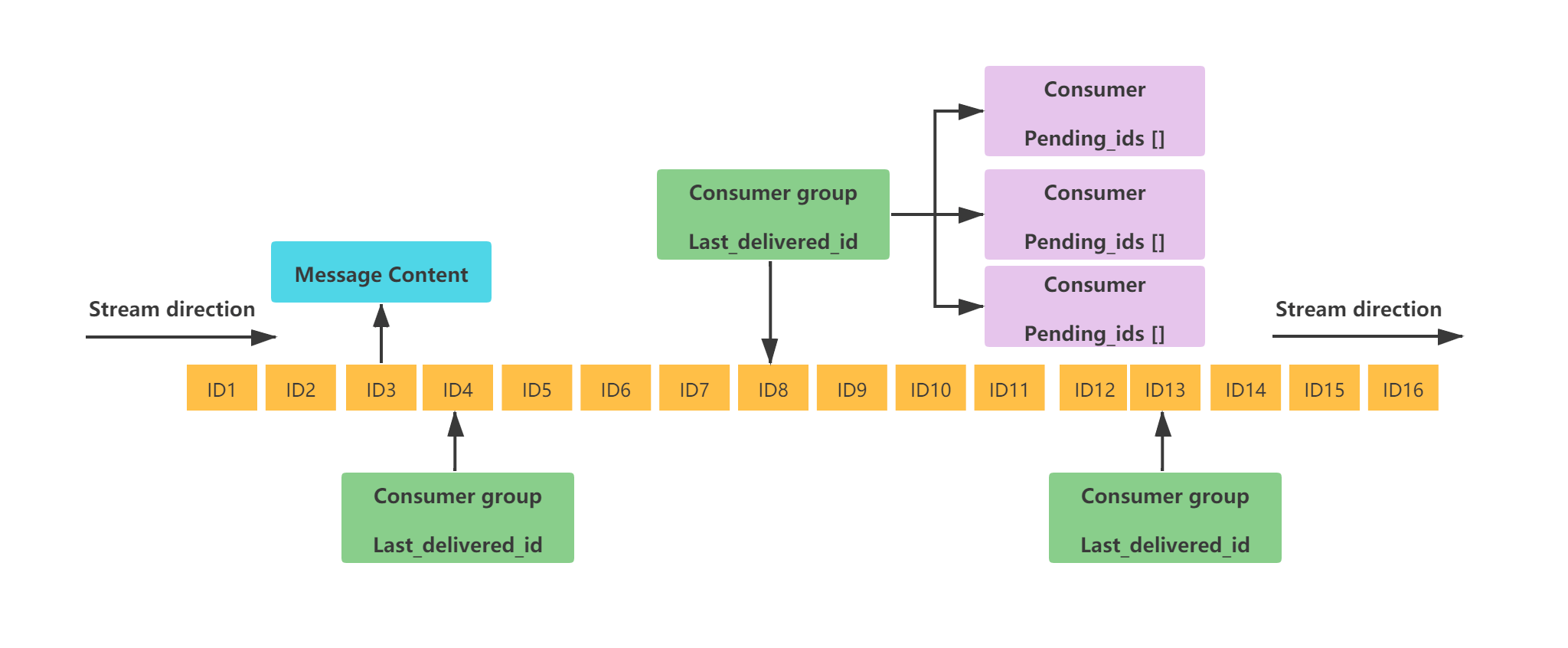
学习文档(5)
Redis应用 目录 Redis应用 Redis 除了做缓存,还能做什么? Redis 可以做消息队列么? Redis 可以做搜索引擎么? 如何基于 Redis 实现延时任务? Redis 除了做缓存,还能做什么? 分布式锁&…...

node.js下载安装以及环境配置超详细教程【Windows版本】
node安装以及环境变量配置 Step1:选择版本进行安装Step2:安装Node.jsStep3:环境配置Step4:检查node.js是否成功安装Step5:npm修改下载镜像 Step1:选择版本进行安装 Node.js 安装包及源码下载地址为 Node.…...

08_实现 reactive
目录 编写 reactive 的函数签名处理对象的其他行为拦截 in 操作符拦截 for...in 循环delete 操作符 处理边界新旧值发生变化时才触发依赖的情况处理从原型上继承属性的情况处理一个对象已经是代理对象的情况处理一个原始对象已经被代理过一次之后的情况 浅响应与深响应代理数组…...

finereport 中台 帆软 编码解码
帆软用的 post 方式编码不是用的 dict,而是二次 url 编码,需要二次解析 import time import urllib.parse import json# 原始字符串 encoded_string data "__parameters__%7B%22MANUFACTURER%22%3A%22%22%2C%22CATEGORY%22%3A%22%22%2C%22HHPN_L…...

Day15-数据库服务全面优化与PT工具应用
Day15-数据库服务全面优化与PT工具应用 1、数据库服务优化讲解1.2 数据库服务系统层面的优化1.3 数据库服务软件版本选择1.4 数据库服务结构参数优化1.4.1 数据库连接层优化1.4.2 数据库服务层优化1.4.3 数据库引擎层优化1.4.4 数据库复制相关优化1.4.5 数据库其他相关优化 1.5…...

开源限流组件分析(二):uber-go/ratelimit
文章目录 本系列漏桶限流算法uber的漏桶算法使用mutex版本数据结构获取令牌松弛量 atomic版本数据结构获取令牌测试漏桶的松弛量 总结 本系列 开源限流组件分析(一):juju/ratelimit开源限流组件分析(二):u…...

探索 SVG 创作新维度:svgwrite 库揭秘
文章目录 **探索 SVG 创作新维度:svgwrite 库揭秘**背景介绍库简介安装指南基础函数使用实战场景常见问题与解决方案总结 探索 SVG 创作新维度:svgwrite 库揭秘 背景介绍 在数字艺术和网页设计领域,SVG(Scalable Vector Graphic…...

为什么要做PFAS测试?PFAS检测项目详细介绍
PFAS测试之所以重要,主要归因于PFAS(全氟和多氟化合物)的广泛存在、持久性、生物累积性和潜在的毒性。这些特性使得PFAS在环境和人体中可能长期存在,并对生态系统和人类健康构成威胁。以下是对PFAS检测项目的详细介绍以及进行PFAS…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南
如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼…...

基于Arduino与TSL2561的光照度测量系统:从硬件连接到软件调试
1. 项目概述:从园艺需求到嵌入式光测量方案最近在折腾一个园艺相关的项目,需要量化评估不同覆盖材料(比如遮阳网、塑料薄膜)对光线透射率的影响。说白了,就是想精确知道,盖上一层材料后,底下还能…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...