从0-1搭建金融智能助理保姆级教程:拆箱即用的微信公众号后端+AI Agents智能体框架
大模型LLM 应用+AI Agents框架,为我们提供了非常便利的自动化执行任务的能力。微信公众号(订阅号) 是非常适合落地各种AI Agents的场景,我们可以利用微信公众号提供的文本、图像、语音的输入,在自己服务器上部署一套API框架,把自己感兴趣的一些对话、图文、语音等能力的API封装为Agents。这里给大家介绍一个拆箱即用的微信公众号服务端框架 Flask+tencent代码库来实现,并且会利用一个简单的金融智能助理(Finance Agent)的例子来实现一个根据用户输入来查询实时股价,并且返回给微信公众号用户的功能,支持更加复杂定制的AI Agents业务逻辑。

一键部署图文回复的Demo
跳转
AI Agents API调用实现查询股价功能的Demo
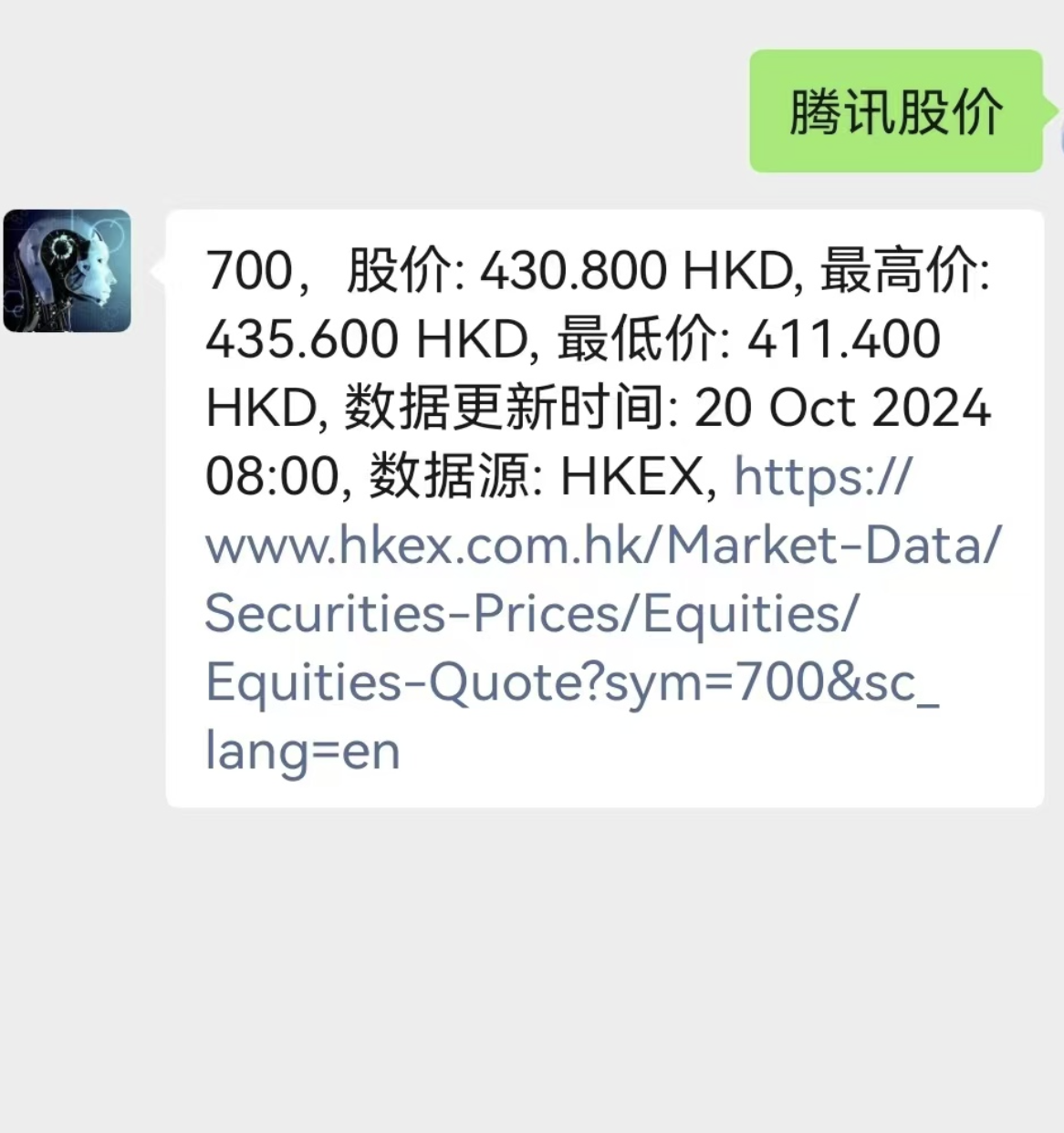
跳转
2. 环境准备
开发一个微信公众号(订阅号)的自动回复和AI Agents需要下列准备,包括:
- 2.1 服务器:可以提供80端口和公共IP的服务器,这样微信公众号后台就可以发送请求到 http://{ip_address}:80/wx 端口,然后你的服务端返回内容给公众号,给用户提供服务。
- 2.2 python库 flask (提供web服务)
- 2.3 python库 tencent (提供了三方的API包括封装好的微信服务端验证,文本请求,图像请求等等)。
安装环境可以执行下列命令
代码语言:txt
复制
pip install flask tencent
3. 拆箱即用部署
3.0 服务器上部署Flask+tencent服务端
微信开发平台上例子,第一次部署可能要花比较长时间,中间缺少debug信息需要尝试很多次。
https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Getting_Started_Guide.html
这里提供了封装好亲自测试一分钟可以成功跑通的基础类和Flask Server的执行脚本,复杂应用也可以在这个基础类上进行修改。从github上下载例子拆箱即用 main.py文件地址
地址:https://github.com/AI-Hub-Admin/tencent/blob/main/examples/wechat/main.py
代码语言:txt
复制
wget https://github.com/AI-Hub-Admin/tencent/blob/main/examples/wechat/main.py
python main.py
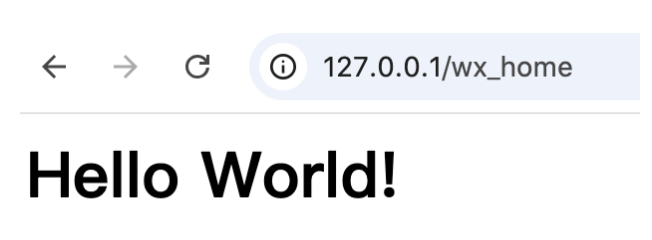
部署好服务之后,可以通过浏览器访问 http://127.0.0.1:80/wx_home 查看是否部署成功。如果可以看到Hello World的一个html页面就代表服务部署成功了。给微信提供验证的服务入口在 (http://127.0.0.1:80/wx)。
下一步就要在微信官方平台,验证你的服务器可以给公众号提供服务了。
需要保存好
\1. 你对外提供的URL: http://{your_ip_address}/wx (80端口从URL里省去)
\2. 一个验证用的token,例子代码中 token=“dummy”,需要填写在下一端的对应位置,你可以修改wechat_constants.py 文件中对应变量
3.1 注册微信公众号
详细的注册和开发流程参考微信公众号开发文档(https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Getting_Started_Guide.html),但是因为自己第一次部署很容易配置失败,这里给大家分享一些拆箱即用的可以直接上手跑的例子。
a.登录微信平台注册账号
官方网址 (https://mp.weixin.qq.com/) 个人开发者可以先选择订阅号,服务号和企业号都需要公司营业执照等材料。
b. 配置服务器设置
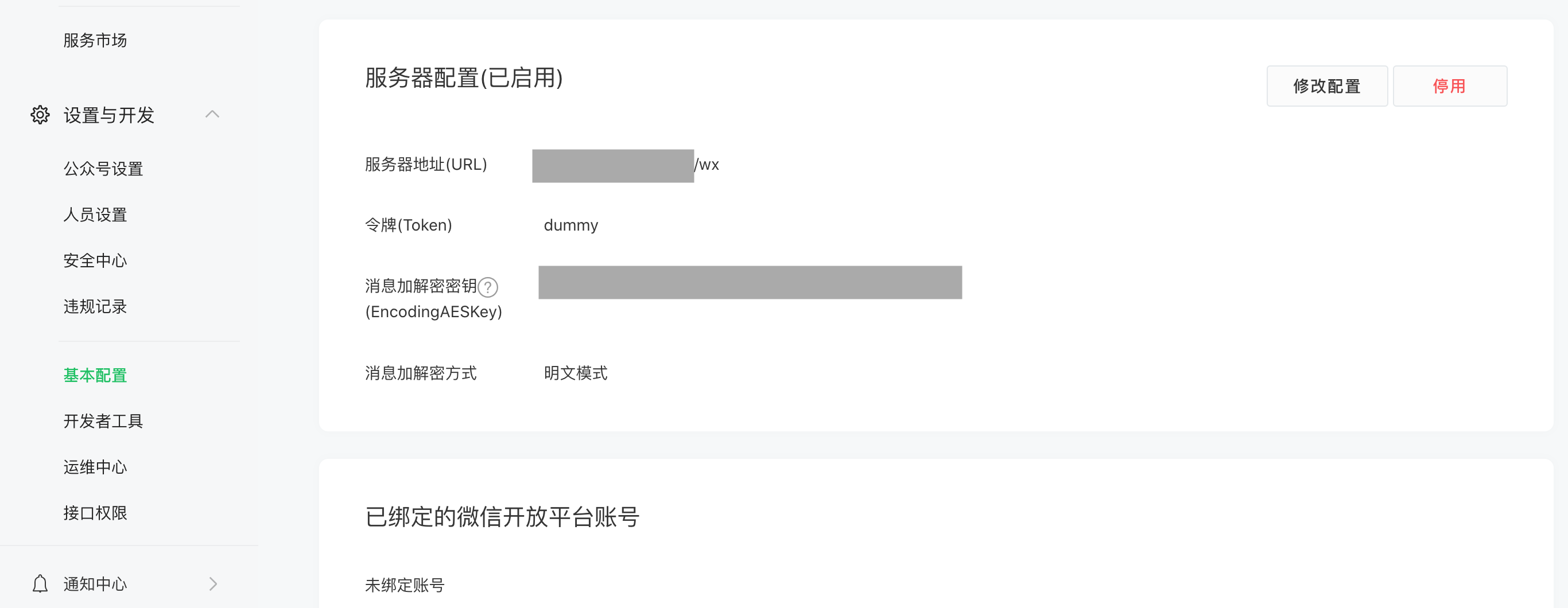
在导航栏选择 “设置与开发-基本配置”,在"服务器" 配置项选择修改配置。这里的对话框可以选择填写你的服务端信息。
URL:填写你对外暴露服务的地址 **http://{your_ip_address}/wx,**token:这里先填写 dummy (对应我们的 python例子,可以后续再修改)
最后保存。当你点击保存按钮的时候,微信服务端会给你的地址发一个 GET请求来验证你拥有服务器,这里如果验证失败了,可以看看python 后台的日志如下图中 (hashcode和signature是否一致).这里验证逻辑被封装到 tencent库的 WechatServerVeriAPI.static_api函数内,感兴趣可以查看 tencent.contrib.wechat.wechat_api 这个模块。保存后点击"启用"就可以从公众号上发消息验证了。
c. 关注公众号并发送文本图片消息
如果部署成功了,你发送文本消息,公众号回复 “hello”,如果你发送图片,公众号会把相同图片的mediaid 返回给你,达到回复用户相同图片效果。参考例子main.py文件中对基础文本回复 和 对图像回复,封装在了 WechatTextReplyBaseAPI.static_api 和 WechatImageReplyBaseAPI.static_api 这两个函数里。初次上手微信后台开发的开发者可以不用纠结于request的XML请求的格式细节,只用关注最核心的业务逻辑,获取用户输入,得到输出并返回给用户就好了。
3.2 常见错误
a. 系统发生错误,请稍后重试
因为填写配置错误导致 hash_code和signature计算不同,注意点:
\1. URL:不能带端口,一定是固定 服务器, 不能是 http://{your_ip_address}:80/wx 或者是 https://{your_ip_address}:443/wx,这样填写是不行的。
\2. token: 只能英文数字,不能有下划线,或者别的符号,这个很容易被忽略。必须为英文或数字,长度为3-32字符。 具体错误原因微信后台没有提供,我们可以从我们 python服务端日志来看出端倪。查看下列flask打印的日志,看看 hashcode 和 signature是否一致不一致就是哪里填错了。

4. 实现自己的金融助理(查询股价)
4.1 直接基于API来实现自动回复
可以参考代码库(https://github.com/AI-Hub-Admin/tencent)中 examples/tests/ 目录下的 main_finance_agent.py 例子。 微信公众号开发很多对 服务端request的输入输出格式都很复杂,为了简单上手,可以直接继承 WechatTextReplyBaseAPI 基础类,然后主要关心获取用户输入和返回给用户的核心业务逻辑就可以了。
这里金融智能助理为例,我们希望做一个可以查询股票价格的 AI Agents,我们只用自己实现核心业务逻辑就好。完整代码参考例子:
地址:https://github.com/AI-Hub-Admin/tencent/blob/main/examples/wechat/main_finance_agent.py
开发 WechatTextReplyFinanceAPI 类
这个 WechatTextReplyFinanceAPI 类继承 WechatTextReplyBaseAPI 基类,我们只用关系和修改入口静态方法 static_api(args, kwargs) 和 process(self, msg) 函数实现业务逻辑就好了。
这个类代码如下,实现了查询股票代码和组装自动回复的功能,我们使用了 FinanceAgent 库(包含了港股A股美国等api请求股价的函数,也支持Agents式的 tools自动化调用):
代码语言:txt
复制
class WechatTextReplyFinanceAPI(WechatTextReplyBaseAPI):@staticmethoddef static_api(args, kwargs):return WechatTextReplyFinanceAPI(None).api(args, kwargs)def process(self, msg):"""input: msg is a class of Wechat sent Msg, TextMsg, ImageMsg defined in receive.py file, you can also access other input information toUser = msg.FromUserNamefromUser = msg.ToUserNameoutput: str, the outer api method will process and wrap the Message Object"""input_text = msg.Content# parse user intent and query stock code from input text, This example, we will use 700 for tencent as example## implement_your_code_herestock_info_list = fa.api(symbol_list=['700'], market="HK")response_list = []for stock_info in stock_info_list:response= "%s,股价: %s, 最高价: %s, 最低价: %s, 数据更新时间: %s, 数据源: %s" % (stock_info["symbol"], stock_info["avg_price"], stock_info["high"], stock_info["low"], stock_info["update_time"], stock_info["source"])response_list.append(response)output_text = ";".join(response_list) return output_text
需要重写的函数:
- static_api是为了其他module 使用时候,不用实例化直接通过类Classname.static_api 来调用函数,注意这里要修改对应的类名字 (WechatTextReplyFinanceAPI)
- process() 是包含具体的处理用户请求的逻辑:输入是一个 Msg对象(从微信请求的xml请求体转化来的),我们通过 msg.Content 获取用户输入的文本。返回的是你希望回传给用户的 字符串(str),比如腾讯(股票代码: 700)的股价总结。
在Flask对应的 /wx方法的Flask 函数主入口,把原先的 WechatTextReplyBaseAPI.static_api(args=[recMsg], kwargs={}) 替换为你实现的金融服务的函数就好了。WechatTextReplyFinanceAPI.static_api(args=[recMsg], kwargs={})。点击运行,再给你的公众号发送消息。如果成功你就可以看到查询的腾讯的最新股价了。
4.2 AI Agents智能体构建方法(把API封装为Tool供大模型调用)
AI智能体借助大模型LLM能力,执行流程简单描述就是:LLM 输入用户的prompt和可以执行的函数 tools (tools的概念就是把函数统一schema化让模型可以理解),返回 可以执行的函数和填充好的parameters参数。我们再根据LLM返回决策结果来直接执行这段函数代码。
4.2.1 构造智能体调用tools或者function_calls
首先,AI智能体借助大模型和prompt来给函数填充参数,输入给LLM的信息包括:
\1. 函数的schema(包括函数名,函数参数列表,每个参数取值类型,哪些是required参数等等),
\2. 用户自然语言输入的prompt。
大模型还是十分智能的,会把prompt中的相关文本抽取,结合自己知识来对参数改写 (比如 hongkong 改为HK再填充到函数里)对应的数据填充到函数的schema中。OpenAI的API 返回信息包含了function 和 对应参数 params。以openai的函数填充为例。
输入 prompt
代码语言:txt
复制
## You can fill the function with json format, the schema for the function is {'type': 'function', 'function': {'name': 'tencent_api_base', 'description': '', 'parameters': {'type': 'object', 'properties': {'arg1': {'type': 'string'}, 'arg2': {'type': 'string'}, 'arg3': {'type': 'string'}, 'arg4': {'type': 'string'}, 'arg5': {'type': 'string'}}, 'required': ['arg1', 'arg2', 'arg3']}}}, the user inputs include arg1=10, arg2=20, arg3=30, please output the executable function values in json format, with key as 'function'
输出prompt
代码语言:txt
复制
{"function": {"name": "tencent_api_base","parameters": {"arg1": "10","arg2": "20","arg3": "30","arg4": "","arg5": ""}}
}
4.2.2 把股价查询API构建为Agent 基于tencent库中提供的函数
API调用毕竟相当于人工写死的逻辑,只能接受固定输入好的参数格式。
借助大模型我们将API直接调用转化为基于大模型的AI Agent范式。
完整的金融智能助理 AI Agents执行例子可以参考这个Tutorial 的例子。
地址:https://github.com/AI-Hub-Admin/tencent/blob/main/examples/agents/run_finance_agent_api_tools.py
a. Tool的定义函数function和参数类型
定义AI Agents执行流程,首先需要告诉大模型任务有哪些 Tools(函数or工具) 可以选择,以及用户的输入是什么。以我们构造金融助理Agent为例子,需要大模型解析的一个函数function finance_stock_price_api,明确入参类型: symbol_list 是 list类型,market 市场是string 类型。
代码语言:txt
复制
def finance_stock_price_api(symbol_list: list, market: str):"""symbol_list is list of jsonmarket is str"""import FinanceAgent as fastock_info_json = fa.api(symbol_list=symbol_list, market=market)return stock_info_json
b. 函数function转换为LLM理解的Schema格式
利用tencent.utils.agent_utils 中的 function_to_schema 将函数转化为统一的OpenAI训练的 schema,这里不同大模型数据格式不同,具体schema需要和大模型训练时保持一致才能达到最佳效果。
代码语言:txt
复制
from tencent.utils.agent_utils import function_to_schematools = [finance_stock_price_api]
tool_schemas = [function_to_schema(tool) for tool in tools]
schema是一个json格式如下
代码语言:txt
复制
{"type": "function","function": {"name": "finance_stock_price_api","description": "symbol_list is list of json\n market is str","parameters": {"type": "object","properties": {"symbol_list": {"type": "array"},"market": {"type": "string"}},"required": ["symbol_list","market"]}}
}
c. 输入给LLM进行Tools的决策
将可以执行的函数 Schema 和用户输入prompt 传给大模型让大模型产出需要执行函数,本质上是大模型预测了一下函数执行的最大概率并且输出最大概率的文本(相当于给函数填充了参数的槽位,得到了一个可以执行的 "字符串“)
代码语言:txt
复制
client = OpenAI() response = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": instruction}],tools=tool_schemas,)
假设用户输入prompt是:希望查询腾讯(700) 和 快手(1024) 的港股股价
合并得到给LLM的输入为:
代码语言:txt
复制
You can fill the function with json format, the schema for the function is {'type': 'function', 'function': {'name': 'finance_stock_price_api', 'description': 'symbol_list is list of json\n market is str', 'parameters': {'type': 'object', 'properties': {'symbol_list': {'type': 'array'}, 'market': {'type': 'string'}}, 'required': ['symbol_list', 'market']}}}, the inputs includes I am interested in Tencent(code:700) and Kuaishou (code:1024) stock price,please output the executable function values in json format, with key as 'function'

如果本地执行没有OpenAI的Key,可以尝试web端看看大模型产出结果如下,有的时候产出的Json也是有可能是错误的(大模型产出不准确有错误和幻觉),这个时候就需要业务后处理了。
代码语言:txt
复制
{"function": {"name": "finance_stock_price_api","description": "symbol_list is list of json\n market is str","parameters": {"symbol_list": ["700","1024"],"market": "Hong Kong"}}
}
如何没有大模型调用环境可以把这个字符串输入然后让Agent 程序继续跑下去。
代码语言:txt
复制
[{"function":{"name":"finance_stock_price_api","parameters":{"symbol_list":["700","1024"],"market":"HK"}}}]
最后就是执行 execute_tool_call_from_json 来具体执行返回的函数和参数值,然后保存结果到 messages 里面,我们就根据用户自然语言处理的输入,决策调用股价查询API 并且获得了结果。
代码语言:txt
复制
def execute_tool_call_from_json(tool_call, tools_map):"""tool_call: json format of {'functions': {'name': 'tencent_api_base','parameters': {'arg1': '10','arg2': '20','arg3': '30','arg4': '','arg5': ''}}}"""name = tool_call["function"]["name"]parameters = tool_call["function"]["parameters"]# args = json.loads(tool_call.function.arguments)print(f"Assistant: {name}({parameters})")# call corresponding function with provided argumentsreturn tools_map[name](**parameters)
d. 小结
这样我们就把API调用重构为了一个 AI Agents调用的范式,可以看出几点区别:
\1. API调用的确定性强,缺点就是参数处理和解析定制化,都需要根据query的NLP技术理解来处理。
2.AI Agents 调用支持用户输入灵活性更强,但是输出准确性不够高。
从AI Agents 根据用户输入和备选Tools的Schema,决策可以执行函数的字符串返回流程中,执行哪个参数和执行哪个函数都是LLM根据概率模型来预测的一段可以执行代码。不用NLP解析槽位再填写到API里。但是缺点就是LLM产出的字符串可能有各种bug,需要后处理,比如json格式不对,参数填写错误等。
在这个Tutorial 我们把API封装为 tools 让LLM调用过程中,tencent包提供了API函数方便封装,以及 function_to_schema 和 execute_tool_call 的一些utils的函数方便调用。具体业务下Agents执行还要结合各自业务,来智能地来对用户提供相应服务。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥《中国大模型落地应用案例集》 收录了52个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

💥《2024大模型行业应用十大典范案例集》 汇集了文化、医药、IT、钢铁、航空、企业服务等行业在大模型应用领域的典范案例。

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

相关文章:
从0-1搭建金融智能助理保姆级教程:拆箱即用的微信公众号后端+AI Agents智能体框架
大模型LLM 应用AI Agents框架,为我们提供了非常便利的自动化执行任务的能力。微信公众号(订阅号) 是非常适合落地各种AI Agents的场景,我们可以利用微信公众号提供的文本、图像、语音的输入,在自己服务器上部署一套API框架,把自己…...

Yolov10训练的餐盘菜品目标检测软件(包含源码及数据集)
本文摘要 摘要:本文主要使用YOLOV10深度学习框架自训练了一个“餐盘菜品目标检测模型”,基于此模型使用PYQT5实现了一款界面软件用于功能演示。让您可以更好的了解和学习,该软件支持图片、视频以及摄像头进行目标检测,本系统所涉…...

Active Directory(活动目录)密码审核工具
什么是Active Directory密码审核 Active Directory密码审核涉及监控用户密码的状态及其身份验证尝试,以便 IT 管理员收到有关弱 Active Directory密码或任何异常身份验证行为的通知。 Active Directory密码审核可帮助管理员评估用户密码的强度并采取必要措施来加强…...

Transformer为什么使用LayerNorm而不是BatchNorm?
01 引言 层归一化(Layer normalization ) 是Transformer模型中的一项重要技术,它通过对每一层的输入进行归一化,帮助稳定和加速训练。无论输入的规模或分布如何,它都能确保模型处理信息的一致性。在自注意力机制、多头注意力机制和位置编码…...

理解和重构目录结构:Java 中的父子关系管理
理解和重构目录结构:Java 中的父子关系管理 一、前言1. 问题背景2. 目录项结构3. 实现重构逻辑4. 示例代码5. 结果与输出 二、总结 好的,我们将目录结构调整为使用中文数字表示的标题。以下是重新组织后的内容: 一、前言 在软件开发中&…...
)
ES6面试题:(第一天)
目录 1.var,let,const的区别 2.说说你对数组的解构和对象的解构的理解? 3.ES6的新语法 4.Map对象和Set对象的区别 5.Set实现数组去重 1.var,let,const的区别 使用 var 声明的变量,其作用域为全局作用域或者为所在的函数内局部作用域,且存在变量提升…...

【ChatGPT】什么是ChatGPT:基础介绍与使用场景
什么是ChatGPT:基础介绍与使用场景 在当今科技快速发展的时代,人工智能工具正逐步融入我们生活的方方面面。你是否曾在编写报告时陷入思路停滞?或者在客户服务中焦急等待响应?这些问题,随着 ChatGPT 的出现࿰…...

工业自动化为什么依赖光耦隔离器 --- 腾恩科技
光耦合器隔离器在工业自动化中必不可少,可确保信号传输,同时保护敏感电子设备和人员免受高压影响。选择合适的光耦合器隔离器取决于对操作环境和隔离要求的了解。本文将重点介绍在为工业应用选择光耦合器隔离器时需要考虑的关键因素。 光耦合器隔离器在工…...

Linux环境下Jmeter执行压测脚本
Linux环境下Jmeter执行压测脚本 前提官网下载Jmeter执行脚本 前提 注意:Jmeter的运行依赖Java环境 官网下载Jmeter 1、下载链接:https://dlcdn.apache.org//jmeter/binaries/apache-jmeter-5.6.3.zip 2、解压 unzip apache-jmeter-5.6.3.zip 执行脚本…...

PROFINET开发或EtherNet/IP开发嵌入式板有用于工业称重秤
这是一个真实案例,不过客户选择不透露其品牌名称。稳联技术的嵌入式解决方案助力工业称重设备制造商连接至任意工业网络。多网络连接使得称重设备能够轻松接入不同的控制系统,进而加快产品的上市时间。 我们找到了稳联技术的解决方案。他们成熟的技术与专…...

OracleT5-2 Solaris11安装
1、Solaris11安装 在光驱中插入Solaris11的光盘后,在ok提示中boot cdrom {0} ok boot cdrom NOTICE: Entering OpenBoot. NOTICE: Fetching Guest MD from HV. NOTICE: Starting additional cpus. NOTICE: Initializing LDC services. NOTICE: Probing PCI devices. N…...

详解 JuiceFS 在多云架构下的数据同步与一致性
随着大模型流行,GPU 算力资源正变得日益稀缺,传统的“算力跟着存储跑”的策略需要转变为“存储跟着算力跑”。为了确保数据一致性和管理的便捷性,企业通常在特定地区的公有云上选择对象存储作为所有模型数据的集中存储点。当进行计算任务调度…...

赛氪贡献突出获评优秀合作伙伴,第十九届环境友好科技竞赛落幕
2024年10月19日,第十九届全国环境友好科技竞赛终审答辩会在同济大学顺利举行,标志着这一环境领域顶级学科竞赛的又一盛事圆满落幕。本次竞赛由清华大学、同济大学、西安建筑科技大学及中国环境科学学会共同主办,吸引了全国各高校相关专业学生…...
GrowingIO埋点(前端)
GrowingIO埋点(前端) 一、CDN集成SDK 1、初始化 当用户加载页面的时候,会异步加载 WebJS SDK,不会影响到用户的加载速度,所以一般建议把这段代码加入到 <head></head> 中的最下面,这样能…...

MySQL-15.DQL-排序查询
一.DQL-排序查询 -- 排序查询 -- 1.根据入职时间,对员工进行升序排序 select * from tb_emp order by entrydate asc ;-- 2.根据入职时间,对员工进行降序排序 select * from tb_emp order by entrydate desc ;-- 3.根据 入职时间 对公司员工进行 升序排序…...

SpringBoot中大量数据导出方案:使用EasyExcel并行导出多个excel文件并压缩zip后下载
文章目录 前言一、控制器层代码二、服务层代码三、代码亮点分析 前言 SpringBoot的同步excel导出方式中,服务会阻塞直到Excel文件生成完毕,如果导出数据很多时,效率低体验差。有效的方案是将导出数据拆分后利用CompletableFuture,…...

黑马软件测试第一篇_数据库
说明: 数据库是专门用来存储数据的软件 注意: 对于测试工作而言, 如果项目页面没有实现, 但是我们又想要校验数据,则可以直接通过查询数据库实现 关系: 具体存在的商品录入后 -> 产生对应的数据(存到数据库中) -> 最后会被加载到项目页面中 数据库的分类 分类: 1> 关…...

第十六届蓝桥杯嵌入式组准备
最近我看很多人都在准备蓝桥杯的比赛了,这里我给大家整理一下历届真题或模拟题的讲解与源码 蓝桥杯嵌入式第十二届省赛真题二 蓝桥杯嵌入式第十三届省赛真题一 蓝桥杯嵌入式第十三届省赛真题二 蓝桥杯嵌入式第十四届省赛真题 蓝桥杯嵌入式第十四届模拟考试一 蓝…...
城乡供水信息化系统如何建设?
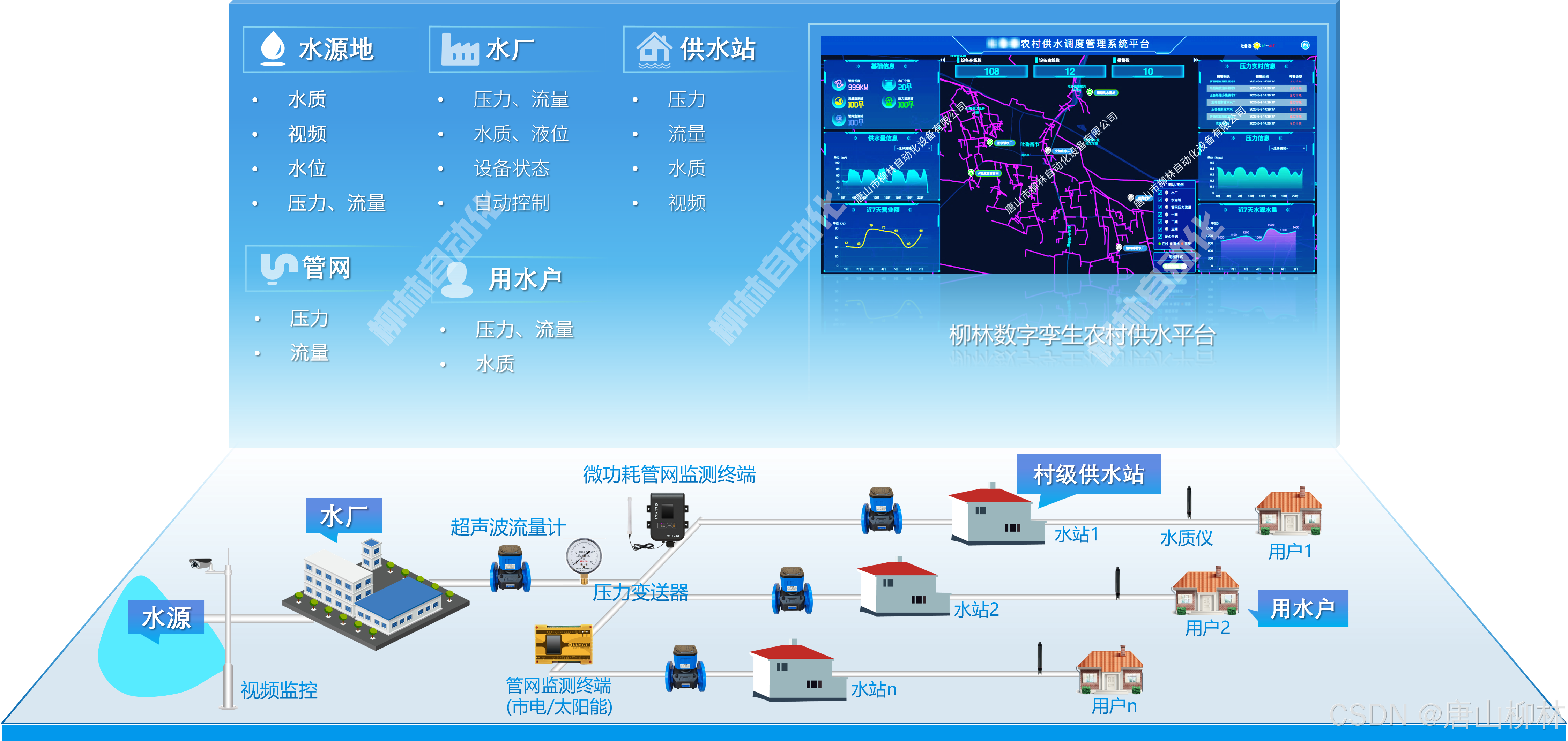
城乡供水信息化建设是一个综合性的过程,旨在通过现代信息技术提升农村供水系统的管理效率和服务质量。这一过程包含以下关键内容: 一、信息化基础设施建设 感知层建设:在农村饮水工程的关键部位,如水源地、水厂、供水管网等&#…...

【Petri网导论学习笔记】Petri网导论入门学习(七) —— 1.5 并发与冲突
导航 1.5 并发与冲突1.5.1 并发定义 1.14定义 1.15 1.5.2 冲突定义 1.17 1.5.3 一般Petri网系统中的并发与冲突定义 1.18一般网系统中无冲撞概念阻塞(有容量函数K的P/T系统,类似于冲撞)一般Petri网中并发与冲突共存情况 1.5 并发与冲突 Petr…...

解锁你的音乐宝藏:ncmdump让网易云音乐文件自由播放
解锁你的音乐宝藏:ncmdump让网易云音乐文件自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 当你精心收藏的网易云音乐只能在特定客户端播放时,那种被束缚的感觉是否让你感到无奈?想象一下…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间
终极FGO自动化助手:告别枯燥刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA Fate/Grand Automata(简称FGA)是一款专为Fate/Grand Or…...

时空镜像立体成像楼宇全态透明智慧管控技术解析方案
时空镜像立体成像楼宇全态透明智慧管控技术解析方案一、方案概述当前传统楼宇管控普遍存在二维监控信息碎片化、空间感知能力薄弱、人员定位依赖外设、跨镜头轨迹断裂、身份核验存在漏洞、设备运维滞后、区域管控存在盲区等行业共性痛点,多数系统仅实现视频录像与基…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

Grad-CAM实战:用热力图透视神经网络的决策焦点
1. Grad-CAM技术初探:为什么我们需要热力图? 当你训练了一个图像分类模型,准确率高达95%,但你真的了解它是如何做出判断的吗?我曾在项目中遇到过这样的尴尬:模型把一只坐在草地上的哈士奇误判为"狼&qu…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...