黑马软件测试第一篇_数据库
说明: 数据库是专门用来存储数据的软件
注意: 对于测试工作而言, 如果项目页面没有实现, 但是我们又想要校验数据,则可以直接通过查询数据库实现
关系: 具体存在的商品录入后 -> 产生对应的数据(存到数据库中) -> 最后会被加载到项目页面中
数据库的分类
分类:
1> 关系型数据库: 以数据表为核心
2> 非关系型数据库: 不存在数据表的概念
关系型数据库: RDMS(Relational Database Management System)关系型数据库系统
常见的关系型数据库:
Oracle: 在大型项目中使用,例如:银行、电信等项目
MySQL: Web 项目中使用最广泛的关系型数据库
Microsoft SQL Server: 在微软的项目中使用
SQLite: 轻量级数据库,主要应用在移动平台
关系型数据库的核心要素:
数据行(⼀一条记录)
数据列(字段)
数据表(数据行的集合)
数据库(数据表的集合,⼀一个数据库中能够有 n 多个数据表)
关系型数据库核心要素示例

SQL 语言
说明: SQL:Structured Query Language(结构化查询语言),通过 SQL 语言可以对数据库进行操作
注意:
- SQL 语言默认支持操作所有常见的关系型数据库
- 作为测试人员, 必须要掌握 SQL 的查询语句
(DQL:数据查询语言,用于对数据进行查询,例如:select) - 对于 MySQL 而言, 编写 SQL 语句时, 不区分字母的大小写
MySQL 数据库介绍
说明: MySQL 是⼀一个关系型数据库管理系统,目前属于 Oracle 旗下产品, 目前为止 MySQL 社区版是可以免费使用的
特点: 开源/免费/跨平台(Windows/macOS/Linux)/跨语言(Java/Python…)
数据库连接工具 Navicat
说明: 由于数据库软件处于服务器中, 想要操作数据库, 就必须使用工具远程连接数据库后, 进行操作
连接数据库操作步骤
说明: 将来在工作中, 想要远程连接数据库, 需要具备以下条件:
1> 数据库所在服务器的 IP 地址及数据库的端口号
2> 向相关人员获取数据库的账号和密码
3> 使用数据库连接工具, 远程连接数据库即可
注意: 远程连接需要注意网络连通性
数据类型和约束
数据类型
数据类型: 对于填⼊入的数据值本身进行控制, 保证数据准确性
整数: int,有符号范围(-2147483648 ~2147483647),无符号(unsigned)范围(0 ~4294967295)
小数: decimal,例如:decimal(5,2) 表示共存5位数,小数占2位,整数占3位
字符串: varchar,范围(0~65533),例如:varchar(3) 表示最多存3个字符,一个中文或一个字母都占⼀一个字符
日期时间: datetime,范围(1000-01-01 00:00:00 ~ 9999-12-3123:59:59),例如:‘2020-01-01 12:29:59’
约束
约束: 对于整张数据表进行限制, 确保对应字段的所有数据符合设计要求
主键(primary key): 能唯一标识表中的每一条记录的属性组
非空(not null): 此字段不允许填写空值
唯一(unique): 此字段的值不允许重复
默认值(default): 当不填写此值时会使用默认值,如果填写时以填写为准
外键(foreign key): 一个表中的一个字段引用另一个表的主键
数据库操作
创建数据库
– 创建数据库
– create database 数据库名 charset=utf8 collate=utf8_general_ci;
create database python charset=utf8 collate=utf8_general_ci;
– 查看数据库
– show create database 数据库名;
show create database python;
使用数据库
– 使⽤用数据库(切换数据库)
– use 数据库名;
use python;
– 查看当前数据库: database() 是 SQL 的内置函数, 括号不不能省略略!
select database();
修改数据库
– 修改数据库
– 创建
create database testpython charset = gb2312;
– 修改
– alter database 数据库名
– default character set 编码格式
– default collate 排序规则;
alter database testpython
default character set utf8mb4
default collate utf8mb4_general_ci;
删除数据库和查看所有数据库
– 删除数据库
– drop database 数据库名;
drop database python;
– 查看所有数据库
show databases;
重点: 数据库备份
应用场景
说明: 在测试工作中, 为了防止对数据库产生错误操作, 或产生垃圾数据, 都需要在操作前, 适当对数据库进行备份操作.
垃圾数据: 例如在自动化测试中, 对注册模块操作生成的所有数据, 属于典型的垃圾数据, 应该清理
备份方法
利用⼯工具
备份步骤
数据库 -> 转储 SQL 文件 -> 结构+数据
 自行选择存放位置
自行选择存放位置
 备份结束
备份结束
 还原操作
还原操作
数据库 -> 运行 SQL 文件
 选择备份文件
选择备份文件
 还原结束
还原结束

扩展: 使用命令备份
注意: 命令是不需要连接到数据库以后执行的!(非 mysql> 模式)
mysql> 为 SQL 语句编写模式, 非 Linux 命令行模式

数据表操作
创建表
– 创建表
– create table 表名(
– 字段名 类型 约束,
– 字段名 类型 约束
– …
– )
– 简单创建
create table stu(
name varchar(5)
);
– 完整创建
– unsigned : 无符号
– primary key : 主键
– auto_increment : 自动增长
create table students(
id int unsigned primary key auto_increment,
name varchar(20),
age int unsigned,
height decimal(5,2)
);
查看表
– 查看表信息
– show create table 表名;
show create table students;
– 执行结果
– CREATE TABLE students (
– id int(10) unsigned NOT NULL AUTO_INCREMENT,
– name varchar(20) DEFAULT NULL,
– age int(10) unsigned DEFAULT NULL,
– height decimal(5,2) DEFAULT NULL,
– PRIMARY KEY (id)
– ) ENGINE=InnoDB DEFAULT CHARSET=utf8
扩展: 判断表存在移除再创建
– 扩展: 判断表是否存在, 存在时先删除再创建
– drop table : 删除表
– if exists students : 如果 students 存在
drop table if exists students;
create table students(
id int unsigned primary key auto_increment,
name varchar(20),
age int unsigned,
height decimal(5,2)
);
扩展: 通过 Navicat 工具获取创表语句的方法

查看表结构和删除表
– 查看表结构(字段)
– desc 表名;
desc students;
– 删除表
– drop table 表名;
drop table students;
数据操作
增加数据
增加一行数据
– 增加数据
– 增加一行数据
– insert into 表名 values(…)
– 注意:
– 1. 数据值需要和表的字段一一对应(数据个数及数据类型)
– 2. 主键列是自动增长,插入时需要占位,通常使用 0 或者 default 或者null 来占位,插⼊入成功后以实际数据为准
insert into students values(0, ‘张三’, 28, 1.78);
– 增加部分值
– insert into 表名(字段1,…) values(值1,…)
– 注意: 值的顺序与给出的字段顺序对应
insert into students(name, height) values(‘李四’, 1.68);
增加多行数据
– 插入多行数据
– 方式1: 将单行插入语句, 多句执行, 每句分号隔开
insert into students values(0, ‘王五’, 28, 1.78);
insert into students(name, height) values(‘赵六’, 1.68);
– 方式2: 在插入单行数据的语法基础上, 将 value 后边的数据进行多组化处理
– insert into 表名 values(…),(…)…
– insert into 表名(列1,…) values(值1,…),(值1,…)…
insert into students values(0, ‘王五1’, 29, 1.78),(0, ‘王五2’,30, 1.78);
insert into students(name, height) values(‘赵六1’, 1.78),(‘赵六2’, 1.88);
修改数据
– 修改数据
– update 表名 set 列1=值1,列2=值2… where 条件
– 注意: where 不能省略, 否则会修改整列数据
update students set age=48 where id=9;
 删除数据
删除数据
– 删除数据
– delete from 表名 where 条件;
– 注意: where 不能省略, 否则会删除全部数据
delete from students where id=6;
扩展 1: 逻辑删除
逻辑删除: 对于重要的数据,不能轻易执行 delete 语句进行删除。因为⼀一旦删除,数据无法恢复,这时可以进行逻辑删除。
1、给表添加字段,代表数据是否删除,⼀一般起名 isdelete,0代表未删除,1代表删除,默认值为0
2、当要删除某条数据时,只需要设置这条数据的 isdelete 字段为1
3、以后在查询数据时,只查询出 isdelete 为0的数据
 – 扩展 1: 逻辑删除(假删/标记删除)
– 扩展 1: 逻辑删除(假删/标记删除)
– 1> 修改要删除的数据的特定字段为删除状态
update students set isdelete=1 where id=4;
– 2> 查询所有 isdelete 字段为 0 的所有数据
select * from students where isdelete=0;
扩展 2: 其他删除数据的方法
– 扩展 2: 其他数据删除方法
– delete from 表名 : 删除所有数据, 但是不重置主键字段的计数
– truncate table 表名 : 删除所有数据, 并重置主键字段的计数
– drop table 表名 : 删掉表(字段和数据均不再存在)
delete from students;
truncate table students;
drop table students;

SQL 语句
查询语句
基本查询
– 需求1: 准备商品数据, 查询所有数据, 查询部分字段, 起字段别名, 去重
– 查询所有数据: select * from 表名;
select * from goods;
– 查询部分字段: select 字段名1, 字段名2 from goods;
select goodsName, price from goods;
– 起字段别名: select 字段名 as ‘别名’ from goods;
select goodsName as ‘商品名称’, price as ‘价格’ from goods;
– 注意: 别名的引号可以省略
select goodsName as 商品名称, price as 价格 from goods;
– 注意: as 关键字也可以省略[掌握]
select goodsName 商品名称, price 价格 from goods;
– 起别名的作用: 1> 美化数据结果的显示效果 2> 可以起到隐藏真正字段名的作用
– 另: 除了可以给字段起别名以外, 还可以给数据表起别名(连接查询时使用)
– 去重: select distinct(字段名) from goods;
– 效果: 将目标字段内重复出现的数据只保留一份显示
– 小需求: 显示所有的公司名称
select distinct(company) from goods;
条件查询
比较运算符&逻辑运算符
– 需求2: 查询价格等于30并且出⾃自并夕夕的所有商品信息
select * from goods;
– 查询价格等于30 : 比较运算符(特殊: (大于等于)>=/(小于等于)<=/(不等于)!=/<>)
select * from goods where price=30;
– 并且出自并夕夕的所有商品信息 : 逻辑运算符(and(与)/or(或)/not(非))
– 注意: 作为查询条件使用的字符串必须带引号!
select * from goods where price=30 and company=‘并夕夕’;
– 补充需求: 查询价格等于30但不出自并夕夕的所有商品信息
select * from goods where not company=‘并夕夕’ and price=30;
– 注意: not 与 and 和 or (左右两边连接条件)不同之处在于, not 只对自己右侧的条件有作用(右边连接条件)
select * from goods where price=30 and not company=‘并夕夕’;
模糊查询
– 需求3: 查询全部⼀一次性⼝口罩的商品信息
– 模糊查询: like 和符号 %(任意多个字符)/(任意⼀一个字符)
– 注意: 作为查询条件使用的字符串必须带引号!
– 注意: 如果需要控制字符数量, 需要使用, 并且有几个字符就使用几个_
– %关键词% : 关键词在中间
select * from goods where remark like ‘%⼀一次性%’;
– %关键词 : 关键词在末尾
select * from goods where remark like ‘%⼀一次性’;
– 关键词% : 关键词在开头
select * from goods where remark like ‘⼀一次性%’;
范围查询
– 需求4: 查询所有价格在30-100的商品信息
– 范围查询: 1> 非连续范围: in 2> 连续范围: between … and …
select * from goods where price between 30 and 100;
– 注意: between … and … 的范围必须是从小到大
select * from goods where price between 100 and 30;
判断空
– 需求5: 查询没有描述信息的商品信息
– 注意: 在 MySQL 中, 只有显示为 NULL 的才为空! 其余空白可能是空格/制表符(tab)/换行符(回车键)等空白符号
– 判断空: 1> 为空: is null 2> 不为空(双重否定表肯定): is not null
select * from goods where remark is null;
– 补充需求: 查询有描述信息的所有商品
select * from goods where remark is not null;
其他复杂查询
排序
– 需求6: 查询所有商品信息, 按照价格从大到小排序, 价格相同时, 按照数量少到多排序
– select * from 表名 order by 列1 asc|desc,列2 asc|desc,…
– 说明: order by 排序, asc : 升序, desc : 降序
– 注意: 排序过程中, ⽀支持连续设置多条排序规则, 但离 order by 关键字越近, 排序数据的范围越大!
select * from goods order by price desc;
select * from goods order by price desc, count asc;
– 注意: 默认排序为升序, asc 可以省略
select * from goods order by price desc, count;
聚合函数
– 需求7: 查询以下信息: 商品信息总条数; 最高商品价格; 最低商品价格;
商品平均价格; 一次性口罩的总数量
– 聚合函数: 系统提供的一些可以直接用来获取统计数据的函数
– 商品信息总条数: count(字段): 查询总记录数
select count() from goods;
– 注意: 统计数据总数, 建议使用, 如果使用某⼀一特定字段, 可能会造成数据总数错误!
select count(remark) from goods;
– 最高商品价格: max(字段): 查询最大值
select max(price) from goods;
– 最低商品价格: min(字段): 查询最小值
select min(price) from goods;
– 商品平均价格: avg(字段): 求平均值
select avg(price) from goods;
– 一次性口罩的总数量: sum(): 求和
– 注意: 此处的 count 是数据表中字段名!
select sum(count) from goods where remark like ‘%⼀一次性%’;
– 扩展: 在需求允许的情况下, 可以一次性在一条 SQL语句中, 使用所有的聚合函数
select count(*), max(price), min(price), avg(price) from goods;
分组
– 需求8: 查询每家公司的商品信息数量
– 分组: select 字段1,字段2,聚合… from 表名 group by 字段1,字段2…
– 说明: group by : 分组
– 注意:
– 1> 一般情况, 使用哪个字段进行分组, 那么只有该字段可以在 * 的位置处使用, 其他字段没有实际意义(只要一组数据中的一条)
– 2> 分组操作多和聚合函数配合使用
select count() from goods group by company;
select * from goods;
select company, count() from goods group by company;
– 说明: 其他字段没有实际意义(只要一组数据中的一条)
select price, count(*) from goods group by company;
– 扩充: 分组后条件过滤
– 说明: group by 后增加过滤条件时, 需要使用 having 关键字
– 注意:
– 1. group by 和 having 一般情况下需要配合使用
– 2. group by 后边不推荐使用 where 进行条件过滤
– 3. having 关键字后侧可以使用的内容与 where 完全一致(比较运算符/逻辑运算符/模糊查询/判断空)
– 3. having 关键字后侧允许使用聚合函数
– where 和 having 的区别:
– where 是对 from 后面指定的表进行数据筛选,属于对原始数据的筛选
– having 是对 group by 的结果进行筛选
– having 后面的条件中可以用聚合函数,where 后面不可以
分页查询
– 需求9: 查询当前表当中第5-10行的所有数据
– 分页查询: select * from 表名 limit start,count
– 说明: limit 分页; start : 起始行号; count : 数据行数
– 注意: 计算机的计数从 0 开始, 因此 start 默认的第一条数据应该为 0,后续数据依次减1
– 过渡需求: 获取前 5 条数据
select * from goods limit 0, 5;
– 注意: 如果默认从第一条数据开始获取, 则 0 可以省略!
select * from goods limit 5;
– 需求:
select * from goods limit 4, 6;
– 扩展 1: 根据公式计算显示某页的数据
– 已知:每页显示m条数据,求:显示第n页的数据
– select * from 表名 limit (n-1)*m, m
– 示例: 每页显示 4 条数据, 求展示第 2 页的数据内容
select * from goods limit 0, 4; – 第1页(有数据)
select * from goods limit 4, 4; – 第2页(有数据)
select * from goods limit 8, 4; – 第3页(有数据)
select * from goods limit 12, 4; – 第4页(一共 12 条数据, 每页显示4 条, 没有第 4 页数据)
– 扩展 2: 分页的其他应用
– 需求: 要求查询商品价格最贵的数据信息
select * from goods order by price desc limit 1;
– 进阶需求: 要求查询商品价格最贵的前三条数据信息
select * from goods order by price desc limit 3;
连接查询
内连接
- 需求1: 查询所有存在商品分类的商品信息
select * from goods;
select * from category;
– 内连接: select * from 表1 inner join 表2 on 表1.列=表2.列
– 显示效果: 两张表中有对应关系的数据都会显示出来, 没有对应关系的数据均不再显示
select * from goods
inner join category on goods.typeId=category.typeId;
– 扩充: 给表起别名(1> 缩短表名利于编写 2> 用别名给表创建副本)
select * from goods go
inner join category ca on go.typeId=ca.typeId;
– 扩展: 内连接的另⼀一种写法(旧式写法)
– select * from 表1, 表2 where 表1.字段名=表2.字段名;
select * from goods, category where
goods.typeId=category.typeId;
左连接
– 需求2: 查询所有商品信息,包含商品分类
– 左连接: select * from 表1 left join 表2 on 表1.列=表2.列
– 注意: 如果要保证一张数据表的全部数据都存在, 则一定不能选择内连接,
可以选择左连接或右连接
– 说明:
– 以 left join 关键字为界, 关键字左侧表为主表(都显示), 而关键字右侧的表为从表(对应内容显示, 不对应为 null)
select * from goods go
left join category ca on go.typeId=ca.typeId;
– 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别的!)
select * from category ca
left join goods go on ca.typeId=go.typeId;
右连接
– 需求3: 查询所有商品分类及其对应的商品的信息
– 右连接: select * from 表1 right join 表2 on 表1.列=表2.列
– 说明:
– 以 right join 关键字为界, 关键字右侧表为主表(都显示), 而关键字左侧的表为从表(对应内容显示, 不对应为 null)
select * from goods go
right join category ca on go.typeId=ca.typeId;
– 扩充需求: 查询所有商品信息及其对应分类信息
select * from category ca
right join goods go on ca.typeId=go.typeId;
补充: 存在左右连接的必要性
说明: 能够体现左右连接必要性的场景为: 至少为三张表进行连接查询
注意: 实际工作中, 最多也就三张表连接查询

连接查询的小结

自关联
前提: 1> 数据表只有一张 2> 数据表中至少有两个字段之间有某种联系
方式: 通过给表起别名的形式, 将原本只有一张的数据表变为两张, 然后通过对应字段实现连接查询
查询河南省下所有市的信息
– 需求4: 查询河南省所有的市
– 说明: 无论是使用内连接还是左连接, 都只影响中间数据表的内容多少, 由于最终的过滤条件相同, 因此查询结果一致
– 使用内连接
select * from areas a1
inner join areas a2 on a1.aid=a2.pid
where a1.atitle=‘河南省’;
– 使用左连接
select * from areas a1
left join areas a2 on a1.aid=a2.pid
where a1.atitle=‘河南省’;
查询河南省下所有的市和区的信息
– 需求5: 查询河南省的所有的市和区
– 说明: 想要实现三级行政单位显示, 需要分别处理省和市及市和区(三表连查)
select * from areas a1
left join areas a2 on a1.aid=a2.pid
left join areas a3 on a2.aid=a3.pid
where a1.atitle=‘河南省’;
子查询
子查询: 在⼀一个 select 语句中,嵌入了另外⼀一个 select 语句,那么嵌入的select 语句称之为子查询语句
作用: 子查询是辅助主查询的,要么充当[条件],要么充当[数据源]
子查询语句充当条件
– 需求6: 查询价格高于平均价的商品信息
– ⼦子查询语句充当条件:
– 求取平均价
select avg(price) from goods;
– 说明: 充当子查询的语句需要使用括号括起来(运算优先级括号最⾼高!)否则报错
select * from goods where price > (select avg(price) from goods);
子查询语句充当数据源
– 需求7: 查询所有来自并夕夕的商品信息, 包含商品分类
– 子查询语句充当数据源:
– select * from goods go
– left join category ca on go.typeId=ca.typeId;
– select * from (select * from goods go left join category ca
on go.typeId=ca.typeId) new
– where new.company=‘并夕夕’;
– 问题: 连接查询的结果中, 表和表之间的字段名不能出现重复, 否则无法直接使用
– 解决: 将重复字段使用别名加以区分(表名.* : 当前表的所有字段)
select * from (select go.*, ca.id cid, ca.typeId ctid,
ca.cateName from goods go left join category ca on
go.typeId=ca.typeId) new where new.company=‘并夕夕’;
数据库高级扩展内容(了解)
ER 模型
E 表示 entry,实体: 描述具有相同特征事物的抽象[数据表]
属性: 每个实体的具有的各种特征称为属性[数据(表内的字段)]
R 表示 relationship,联系: 实体之间存在各种关系,关系的类型包括包括一对一、一对多、多对多[表和表之间的联系]

外键
说明: 通过外部数据表的字段, 来控制当前数据表的数据内容变更, 以避免单方面移除数据, 导致关联表数据产生垃圾数据的一种方法
注意: 如果大量增加外键设置, 会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率, 因此在实际项目中很少会被采用, 但是在面试中容易被问到.
索引
说明: 可以大幅度提高查询语句的执行效率
注意: 如果大量增加索引设置, 会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率, 不方便过多添加
验证索引效果案例实现步骤
说明: 提供的示例文件可以使用在数据库中使用运行 SQL 文件方式导入!
– 开启运行时间监测
set profiling=1;
– 查找第一万条数据 10000
select * from test_index where num=‘10000’;
– 查看执行的时间
show profiles;
– 为表 text_index 的 num 列创建索引
create index test_index on test_index(num);
– 执行查询语句
select * from test_index where num=‘10000’;
– 再次查看执行的时间
show profiles;
扩展: 实际项目中数据库中表的样式
实际项目的表名设计规律
 查看创表语句中的字段注释
查看创表语句中的字段注释

SQL 练习题获取网站
力扣: https://leetcode-cn.com
牛客网: https://www.nowcoder.com
相关文章:
黑马软件测试第一篇_数据库
说明: 数据库是专门用来存储数据的软件 注意: 对于测试工作而言, 如果项目页面没有实现, 但是我们又想要校验数据,则可以直接通过查询数据库实现 关系: 具体存在的商品录入后 -> 产生对应的数据(存到数据库中) -> 最后会被加载到项目页面中 数据库的分类 分类: 1> 关…...

第十六届蓝桥杯嵌入式组准备
最近我看很多人都在准备蓝桥杯的比赛了,这里我给大家整理一下历届真题或模拟题的讲解与源码 蓝桥杯嵌入式第十二届省赛真题二 蓝桥杯嵌入式第十三届省赛真题一 蓝桥杯嵌入式第十三届省赛真题二 蓝桥杯嵌入式第十四届省赛真题 蓝桥杯嵌入式第十四届模拟考试一 蓝…...
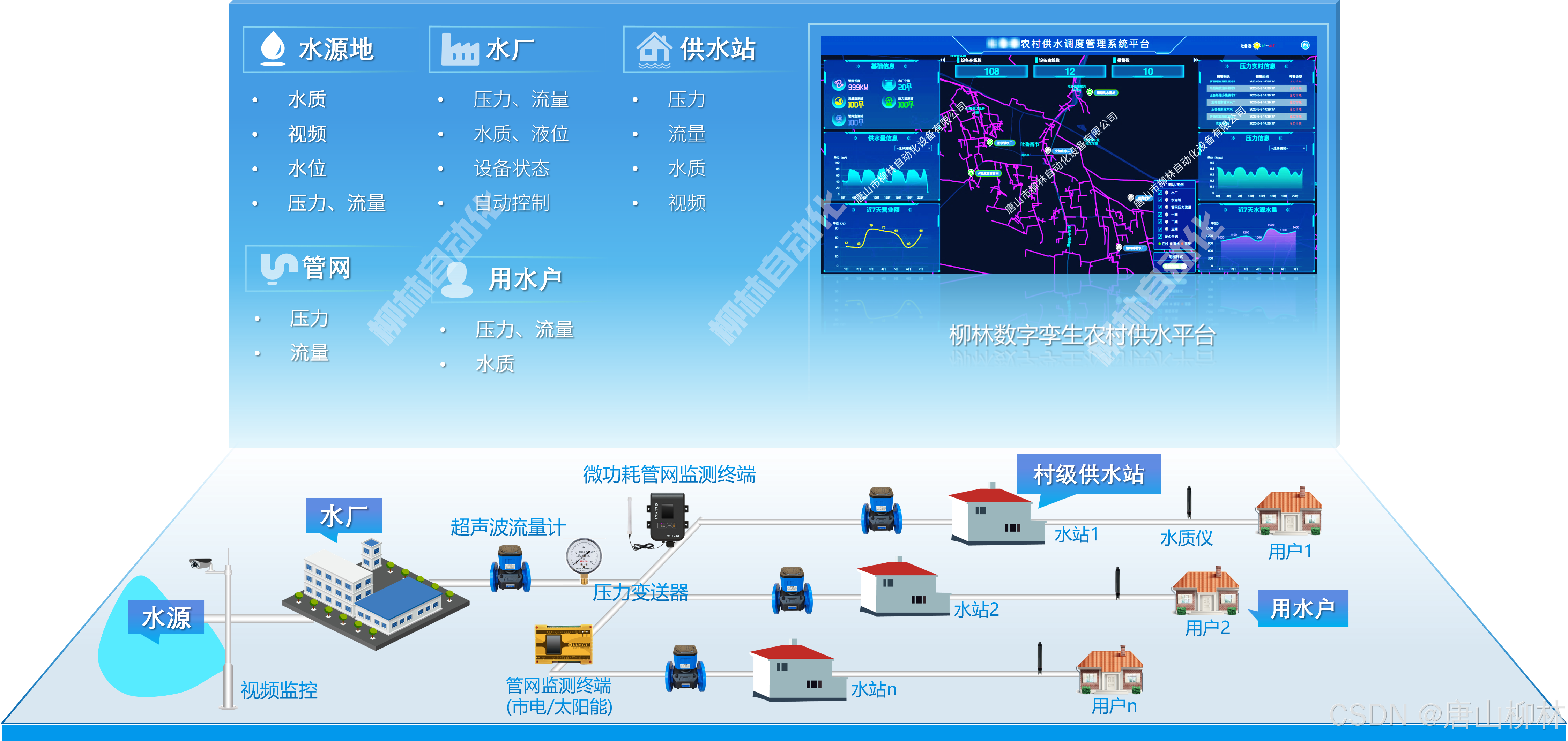
城乡供水信息化系统如何建设?
城乡供水信息化建设是一个综合性的过程,旨在通过现代信息技术提升农村供水系统的管理效率和服务质量。这一过程包含以下关键内容: 一、信息化基础设施建设 感知层建设:在农村饮水工程的关键部位,如水源地、水厂、供水管网等&#…...

【Petri网导论学习笔记】Petri网导论入门学习(七) —— 1.5 并发与冲突
导航 1.5 并发与冲突1.5.1 并发定义 1.14定义 1.15 1.5.2 冲突定义 1.17 1.5.3 一般Petri网系统中的并发与冲突定义 1.18一般网系统中无冲撞概念阻塞(有容量函数K的P/T系统,类似于冲撞)一般Petri网中并发与冲突共存情况 1.5 并发与冲突 Petr…...

MongoDB常用语句
1.只统计记录总数: let result await CorrectionRecordModel.countDocuments(db);2.数组遍历,循环体中可以有调用异步函数: for(let item of result2){if(item && Tool.checkNotEmptString(item.auth_id) && (item.status …...

自动创作PPT 利用提示词和大模型自动创建ppt
背景 ppt创作可以分为3个步骤:1.大纲撰写;2.内容填充;3.ppt实现。我前几天用十分钟的时间做了一个ppt,主讲大模型测评。这里给大家分享一下我的创作过程。 关于步骤1和步骤2,最近发现一个非常好的提示词,…...

二分类评价指标AUROC和AUPR
文章目录 一、AUROC(Area Under the Receiver Operating Characteristic Curve)二、AUPR(Area Under the Precision-Recall Curve)三、区别3.1 案例3.2 如何选择? 在分类任务中, AUROC(受试者工…...

雅迪控股营收、净利润和毛利下滑:销量大幅减少,屡屡抽查不合格
《港湾商业观察》廖紫雯 日前,雅迪集团控股有限公司(以下简称:雅迪控股,01585.HK)发布业绩报告,披露2024年上半年营收净利双下滑等情况,在业绩承压的情况下,雅迪控股遭多家券商下调…...
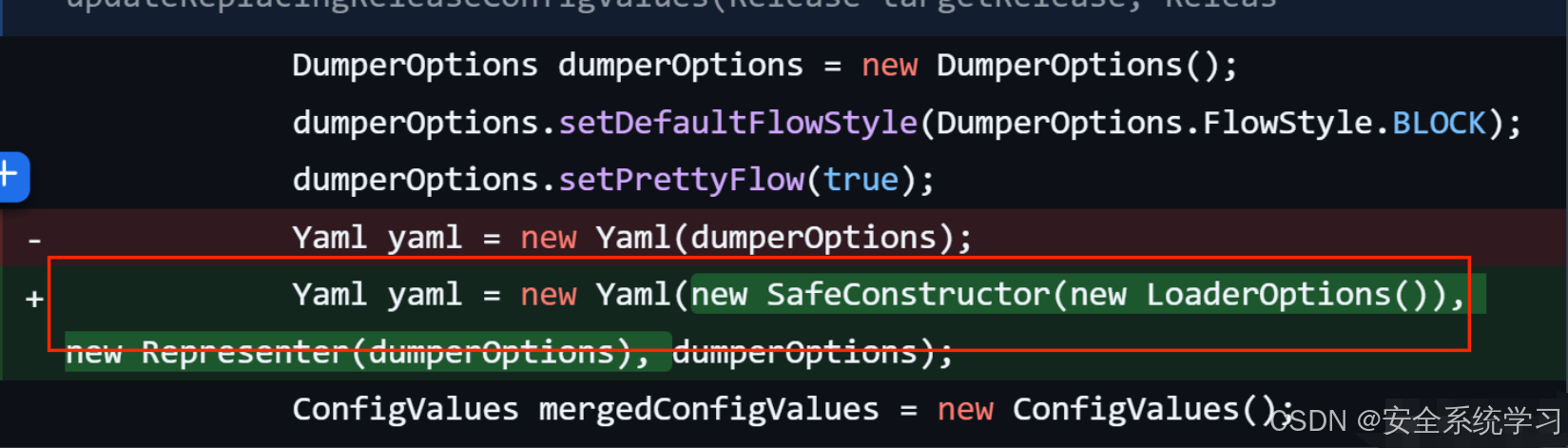
【网络安全】记一次漏洞挖掘
Spring Cloud Data Flow 热点漏洞详细分析 环境搭建 2.10.0 - 2.11.2版本都可以,这里下的2.11.2 源码下载https://github.com/spring-cloud/spring-cloud-dataflow/tree/v2.11.2 在src/docker-compose里面是有docker文件的,使用docker即可 最近是爆出…...
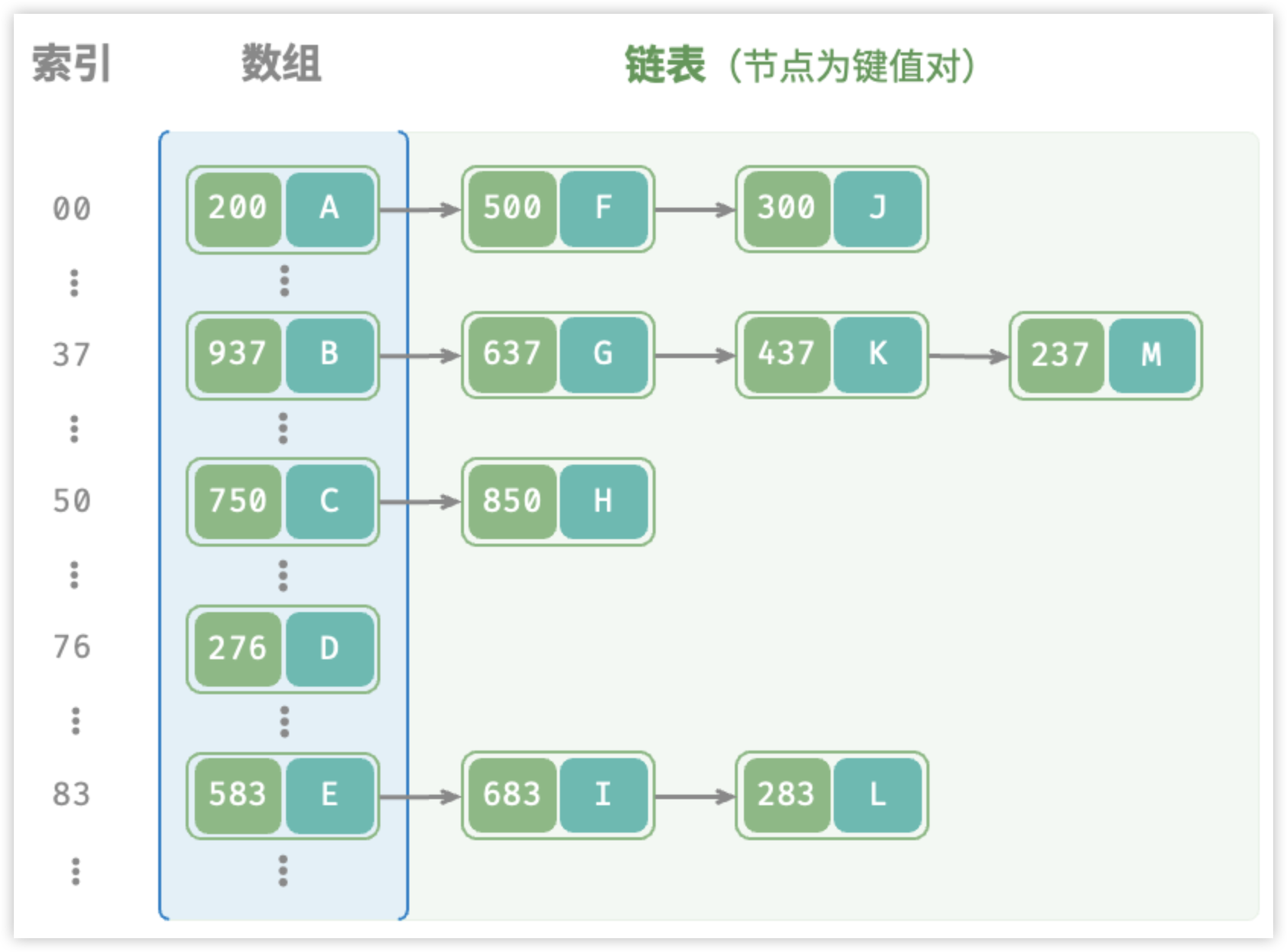
Redis遇到Hash冲突怎么办?
这是小伙伴之前遇到的一个面试题,感觉也是一个经典八股,和大伙分享下。 一 什么是 Hash 冲突 Hash 冲突,也称为 Hash 碰撞,是指不同的关键字通过 Hash 函数计算得到了相同的 Hash 地址。 Hash 冲突在 Hash 表中是不可避免的&am…...

React综合指南(四)
61、描述React事件处理。 为了解决跨浏览器兼容性问题,React中的事件处理程序将传递SyntheticEvent实例,该实例是React跨浏览器本机事件的跨浏览器包装器。这些综合事件具有与您惯用的本机事件相同的界面,除了它们在所有浏览器中的工作方式相…...

Spring集成Redisson及存取几种基本类型数据
目录 一.什么是Redisson 二.为什么要使用Redisson 三.Spring集成Redisson 1.添加依赖 2.添加配置信息 3.添加redisson配置类 四.Redisson存取各种类型数据 1.字符串(String类型) 存储 获取 2.object对象类型 1.实体类信息 2.存储 3.获取 3.List集合类型 第一种…...

Maplibre-gl\Mapbox-gl改造支持对矢量瓦片加密
Maplibre-gl是Mapbox-gl剔除自带地图服务之后的一个分支,代码很相似。Maplibre-gl\Mapbox-gl使用的pbf格式的矢量瓦片,数据量小,渲染效果好。但也存在着信息泄露的风险。但如果想使用这个开发框架的前端渲染效果,还必须要使用这个格式。最近研究了一下如何对矢量瓦片进行加…...
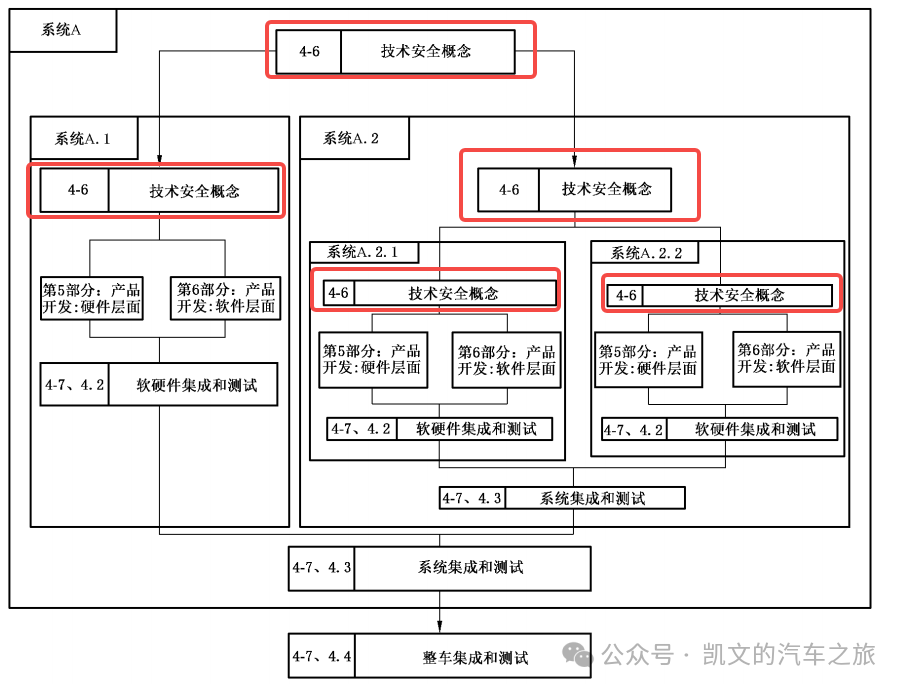
【功能安全】技术安全概念TSC
目录 01 TSC定义 02 TSC注意事项 03 TSC案例 📖 推荐阅读 01 TSC定义 所处位置 TSC:Technical safety concept技术安全概念 TSR:Technical safety requirement技术安全需求 在系统开发阶段属于安全活动4-6 系统层产品开发示例 TSC目的...

Spark数据源的读取与写入、自定义函数
1. 数据源的读取与写入 1.1 数据读取 读文件 read.jsonread.csv csv文件由两个部分组成:头部数据(也就是字段数据)、行数据。 read.orc 读数据库 read.jdbc(jdbc连接地址,table‘表名’,properties{‘user’用户名,‘password’密码,‘driv…...

LeetCode 每日一题 2024/10/14-2024/10/20
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 10/14 887. 鸡蛋掉落10/15 3200. 三角形的最大高度10/16 3194. 最小元素和最大元素的最小平均值10/17 3193. 统计逆序对的数目10/18 3191. 使二进制数组全部等于 1 的最少操…...

接口测试(六)jmeter——参数化(配置元件 --> 用户定义的变量)
一、jmeter——参数化(配置元件 --> 用户定义的变量) 注:示例仅供参考 1. 参数化格式:${变量名} 2. 配置元件:用户定义的变量 3. 添加【用户定义的变量】,【线程组】–>【添加】–>【配置元件】–…...

【学习笔记】网络流
背景 马上ICPC了,很惊奇的发现自己没整理网络流的板子。 最大流 dinic 这里选用的是二分图最大匹配的板子:飞行员配对方案问题 #include<bits/stdc.h> #define int long long using namespace std; const int N1e67,inf1e18; struct E {int to…...
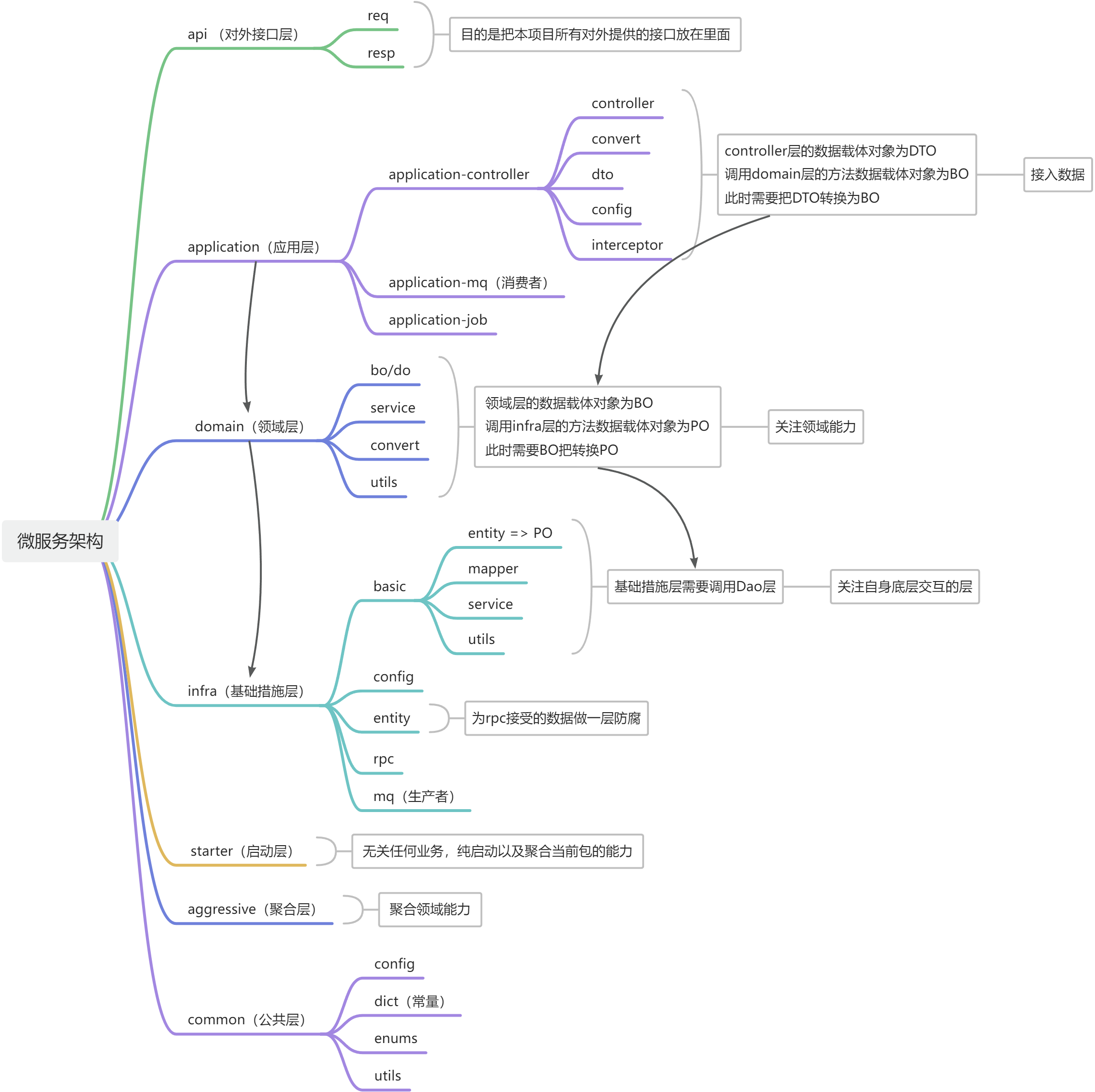
【鸡翅Club】项目启动
一、项目背景 这是一个 C端的社区项目,有博客、交流,面试学习,练题等模块。 项目的背景主要是我们想要通过面试题的分类,难度,打标,来评估员工的技术能力。同时在我们公司招聘季的时候,极大的…...

python+大数据+基于热门视频的数据分析研究【内含源码+文档+部署教程】
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

基于RAG的电影智能体构建:从向量检索到Agentic设计
1. 项目概述:一个能聊电影的智能体最近在GitHub上看到一个挺有意思的项目,叫tomasonjo/llm-movieagent。光看名字,你大概能猜到,这是一个和电影、和大型语言模型(LLM)相关的智能体。简单来说,它…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

三维重建下半场,拼的全是底层基建实力!
三维重建已从算法创新竞赛正式迈入基础设施比拼新阶段,主流技术路线逐步收敛,单纯算法红利见顶,行业竞争核心转向数据、算力、平台、生态等底层综合能力。当下竞争不再只比模型效果,而是聚焦四大核心基建维度:采集传感…...

n8n-claw:在自动化工作流中实现零代码网页抓取
1. 项目概述与核心价值最近在折腾自动化工作流,发现了一个挺有意思的项目,叫freddy-schuetz/n8n-claw。乍一看名字,你可能会有点懵,“n8n”我知道,是那个开源的自动化工具,但这个“claw”是啥?爪…...
——原理与CUDA实现)
训练篇第9节:FlashAttention深度解析(一)——原理与CUDA实现
从 O(N) 到 O(N),FlashAttention 用一记“IO感知”的巧劲,彻底解锁了Transformer处理超长序列的能力 前言 回溯整个训练篇,我们已经系统性地打怪升级:从显存优化的“三板斧”(梯度累积、激活重计算、碎片化管理),到分布式训练的并行策略(数据并行、模型并行、流水线并…...

AI科技热点日报 | 2026年5月16日
文章目录AI科技热点日报 | 2026年5月16日一、大模型与基础技术《人工智能终端智能化分级》系列国家标准发布"九章四号"量子计算原型机刷新世界纪录二、AI政策与监管人工智能科技伦理审查与服务先导计划启动工信部部署高质量行业数据集建设三、Agent与应用"AI教育…...