详解 JuiceFS 在多云架构下的数据同步与一致性
随着大模型流行,GPU 算力资源正变得日益稀缺,传统的“算力跟着存储跑”的策略需要转变为“存储跟着算力跑”。为了确保数据一致性和管理的便捷性,企业通常在特定地区的公有云上选择对象存储作为所有模型数据的集中存储点。当进行计算任务调度时,往往需要人工介入,手动进行数据拷贝和迁移方法不仅成本高昂,还存在管理和维护的复杂性,包括权限控制等问题都极为棘手。
JuiceFS 企业版的 “镜像文件系统” 功能允许用户从一个地区自动复制元数据到多个地区,形成一对多的复制模式。在多云架构下,该功能在确保数据一致性的同时,大幅降低人工运维的工作量。
最新的 JuiceFS 企业版 5.1 中, 镜像文件系统除了支持读取,还新增了可直接写入的功能。本文将探讨镜像文件系统的读写实现原理。
01 为什么需要镜像文件系统
让我们设想这样一个场景,某用户的文件系统部署在北京,但北京地区的 GPU 资源供给不足,而该用户在上海还有可用的 GPU 资源。这时用户想在上海运行模型训练任务,有两个简单的方案:
- 直接在上海挂载北京的文件系统。理论上来说,只要北京与上海之间的网络连接顺畅,上海的客户端确实就能访问数据以进行训练。然而实际情况是,文件系统的访问通常涉及到频繁的元数据操作,而由于两地的网络延迟较大,性能结果往往都无法达到预期。
- 在上海建立新的文件系统,在训练前拷贝所需数据集到上海。这样做的优点是可以保证上海训练任务的性能。但缺点也是很明显的,一方面构建新文件系统需要较高的硬件成本,另一方面每次训练前同步数据也提高了运维的复杂性。
综上所述,这两个简单的方案都无法令人满意。为此 JuiceFS 企业版提供了镜像文件系统功能。它允许用户为已有文件系统创建一个或多个完整的镜像,这些镜像会自动从源端同步元数据,这样在镜像区域的客户端可以就近访问文件系统,来得到高性能的体验。由于可以只镜像元数据,并且同步过程是自动的,因此相较于之前提到的方案二而言,镜像文件系统在成本与运维复杂性上都有明显的优势。
02 镜像文件系统原理
JuiceFS 企业版的架构与社区版相似,都包括客户端、对象存储以及元数据引擎。区别在于社区版的元数据引擎通常采用第三方数据库如 Redis、TiKV、MySQL 等,而企业版则配备了自研的高性能元数据服务,其中的元数据引擎由一个或多个 Raft 组组成,其架构图如下:

得益于元数据与数据分离的架构设计,用户在创建镜像文件系统时可以独立选择是否镜像元数据和是否镜像数据。两者皆配置镜像的架构如下:

此时,镜像的元数据服务其实跟源端的元数据服务同属一个 Raft 组,只是它们的角色是 learner。在源端发生元数据更新时,服务会自动推送变更日志到镜像端,并在镜像服务中进行回放。这样,镜像文件系统的存在并不会影响源端文件系统的性能表现,只是镜像的元数据版本会略落后一点点。
数据的镜像也是采用异步复制的方式,由指定配置的节点进行自动同步。不同的是,对镜像区域的客户端而言,它仅访问本区域的元数据,但是可以同时访问两个区域的对象存储。实际读取数据时,客户端优先从本区域读取;如果查找不到所需的对象,再尝试从源端区域读取。
一般而言,数据本身的体量较大,再拷贝一份的成本也比较高,因此另一种更推荐的方式是仅镜像元数据,并且在镜像区域构建一套分布式缓存组来提升读取数据的速度,示意如下:

JuiceFS 镜像文件系统推荐使用方法:两区域共用同一个对象存储,镜像区域搭建分布式缓存组来提升性能
这种使用方式尤其适合模型训练等可以提前准备数据集的场景。用户在执行训练任务前,先通过 juicefs warmup 命令将所需数据对象拉取到镜像区域的缓存组中,接下来的训练就能在镜像区域内完成,且性能与在源端(假设也配置了类似的分布式缓存组)基本一致。
03 实验性新功能:可写镜像文件系统
在之前的版本中,镜像客户端默认为只读模式,因为镜像元数据本身只支持读取,所有的修改操作必须在源端执行。然而,随着用户需求的增加,我们注意到一些新的使用情况,例如在数据训练过程中产生的临时数据。用户希望避免维护两个不同的文件系统,并期望镜像端也能支持少量写操作。
为了满足这些需求,我们在 5.1 版本中引入了 “可写镜像文件系统” 功能。在设计这项功能时,我们主要考虑三个方面:首先是系统的稳定性,这是必须保证的;其次是两端数据的一致性;最后是写入的性能。
最初,我们探索的一种直接方案是允许元数据镜像也能处理写操作。然而,在开发中我们发现,当需要将两端的元数据更新进行合并时,会面临非常复杂的细节处理和一致性问题。因此我们还是维持 “仅源端元数据可写” 的设计。为了处理镜像客户端的写请求,有两个可选的方案:
方案一:客户端将写请求发送至镜像的元数据服务,然后由其转发到源端。源端接收到请求后开始执行操作,并在完成后将元数据同步回镜像端,并最终返回。这个方法的优点是客户端操作简单,只需发送请求并等待响应。然而,这样会使元数据服务的实现变得复杂,因为需要管理请求的转发和元数据的同步。此外,由于链路较长,任何环节的错误都可能导致请求处理出错。
方案二:客户端不仅连接镜像的元数据服务,还直接连接源端的元数据服务。客户端内部进行读写分离,读请求仍然发送至镜像端,但将写请求发送至源端。这种方法虽然使客户端的处理逻辑复杂化,但简化了元数据服务的实现,让它们仅需做很小的适配改动即可。对整个系统而言,这样的做法稳定性也更高。
考虑到服务的简洁性和可靠性,我们最终选择了方案二,具体如下图所示。相较于原来的架构而言,这个方案主要多了一条镜像客户端发送写请求到源端元数据服务的流程。

以下将以创建一个新文件(create 请求)为例对此流程进行详细的介绍。假设源端和镜像端的元数据服务分别是 A 和 B,镜像客户端为 C,请求的完成大致分为 5 步:

- 客户端发送写请求:C 首先将创建文件的 create 请求发送至 A。
- 源端服务响应:A 在处理请求后,发送 create OK 告知 C 文件已成功创建,并在响应中附带 A 的元数据版本号(假设为 v1)。
- 变更日志推送:A 在发送回复给客户端的同时,也会立即生成一条变更日志,并将其推送给 B。
- 客户端发送等待请求:C 接收到源端的成功回复后,会检查自己的镜像元数据缓存,看其版本是否也达到了 v1。如果没有,客户端会发送一条 wait 消息给 B,并附上版本号 v1。
- 镜像端服务响应:B 收到等待消息后,检查自己的元数据版本。如果已经达到 v1,则立即回复 wait OK 给 C;否则的话就将请求放入内部队列,等自己的版本号更新到 v1 以后再发送回复。
C 在第 4 步确认镜像版本已经达到 v1,或者第 5 步收到 wait OK 后返回给上层应用。无论哪种情况,都表示 B 已经包含了本次 create 的修改,因此后续 C 在读取时,就能访问到最新的元数据。另外,由于步骤 2 和 3 几乎是同时发生的,所以大部分情况下 wait 消息都能被立即处理并返回。
镜像客户端的读操作也有类似的检查版本的机制。具体而言,C 在发送读请求前,会先比较其缓存中源端服务和镜像端服务的元数据版本号;如果源端的版本号更新,则会先发送 wait 消息给 B,等到其版本也更新上来后再处理原来的读请求。遗憾的是,C 缓存的源端版本号并不一定是最新的(比如其长时间未发送过写请求的情况),也就是说该机制只是尽可能地让 C 能读到较新的数据,但并不保证其一定是最新的(可能会有小于 1 秒的滞后,与原有的只读镜像相同)。
最后,我们通过一个稍复杂些的读写混合的例子,来简要说明使用 JuiceFS 镜像文件系统给用户带来的直接收益。
需求是客户端 C 希望在 /d1/d2/d3/d4 目录下创建一个新文件 newf。按照文件系统的设计,C 需要逐级查找路径上的每一个目录和文件,并在确认文件不存在后再发送创建请求。现假设 C 到 A 和 B 的网络延迟分别是 30ms 和 1ms,C 尚未建立元数据缓存,并且忽略 A 和 B 的请求处理时间。
使用镜像文件系统的情况:C 的读请求都由 B 处理,只有最后的创建文件请求需要发往 A。总耗时大概需要 1 * 2 * 6(mirror lookup) + 30 * 2(source create) + 1 * 2(mirror wait) = 74ms。
没有使用镜像文件系统的情况:如果直接在镜像区域挂载源文件系统,C 的每个请求都需要跟 A 交互,那么总耗时就需要 30 * 2 * 6(source lookup) + 30 * 2(source create) = 420ms,是前者的 5 倍还多。
04 小结
在 AI 研究中,由于 GPU 资源的成本极高,多云架构已成为众多企业的标配。通过使用 JuiceFS 镜像文件系统,用户可创建一个或多个完整的文件系统镜像,这些镜像会自动从源端同步元数据,使得镜像区域的客户端能够就近访问文件,从而提供高性能并减少运维工作量。
在最新的 JuiceFS 5.1 版本中,我们对镜像文件系统进行了重要的优化,新增了允许写入的功能,使得企业能够在任何数据中心通过统一的命名空间访问数据。同时在保证数据一致性的前提下,享受就近缓存的加速效果。希望通过这篇文章分享的实现思路与尝试,为用户提供一些见解与启发。
相关文章:
详解 JuiceFS 在多云架构下的数据同步与一致性
随着大模型流行,GPU 算力资源正变得日益稀缺,传统的“算力跟着存储跑”的策略需要转变为“存储跟着算力跑”。为了确保数据一致性和管理的便捷性,企业通常在特定地区的公有云上选择对象存储作为所有模型数据的集中存储点。当进行计算任务调度…...

赛氪贡献突出获评优秀合作伙伴,第十九届环境友好科技竞赛落幕
2024年10月19日,第十九届全国环境友好科技竞赛终审答辩会在同济大学顺利举行,标志着这一环境领域顶级学科竞赛的又一盛事圆满落幕。本次竞赛由清华大学、同济大学、西安建筑科技大学及中国环境科学学会共同主办,吸引了全国各高校相关专业学生…...
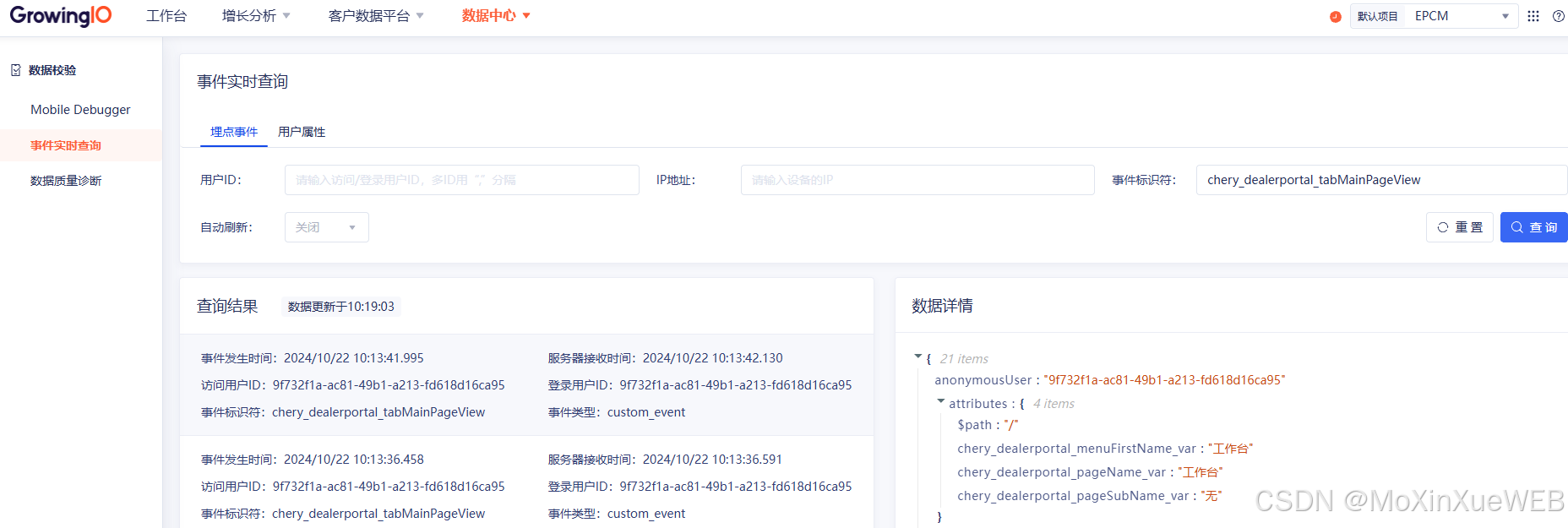
GrowingIO埋点(前端)
GrowingIO埋点(前端) 一、CDN集成SDK 1、初始化 当用户加载页面的时候,会异步加载 WebJS SDK,不会影响到用户的加载速度,所以一般建议把这段代码加入到 <head></head> 中的最下面,这样能…...

MySQL-15.DQL-排序查询
一.DQL-排序查询 -- 排序查询 -- 1.根据入职时间,对员工进行升序排序 select * from tb_emp order by entrydate asc ;-- 2.根据入职时间,对员工进行降序排序 select * from tb_emp order by entrydate desc ;-- 3.根据 入职时间 对公司员工进行 升序排序…...

SpringBoot中大量数据导出方案:使用EasyExcel并行导出多个excel文件并压缩zip后下载
文章目录 前言一、控制器层代码二、服务层代码三、代码亮点分析 前言 SpringBoot的同步excel导出方式中,服务会阻塞直到Excel文件生成完毕,如果导出数据很多时,效率低体验差。有效的方案是将导出数据拆分后利用CompletableFuture,…...

黑马软件测试第一篇_数据库
说明: 数据库是专门用来存储数据的软件 注意: 对于测试工作而言, 如果项目页面没有实现, 但是我们又想要校验数据,则可以直接通过查询数据库实现 关系: 具体存在的商品录入后 -> 产生对应的数据(存到数据库中) -> 最后会被加载到项目页面中 数据库的分类 分类: 1> 关…...

第十六届蓝桥杯嵌入式组准备
最近我看很多人都在准备蓝桥杯的比赛了,这里我给大家整理一下历届真题或模拟题的讲解与源码 蓝桥杯嵌入式第十二届省赛真题二 蓝桥杯嵌入式第十三届省赛真题一 蓝桥杯嵌入式第十三届省赛真题二 蓝桥杯嵌入式第十四届省赛真题 蓝桥杯嵌入式第十四届模拟考试一 蓝…...
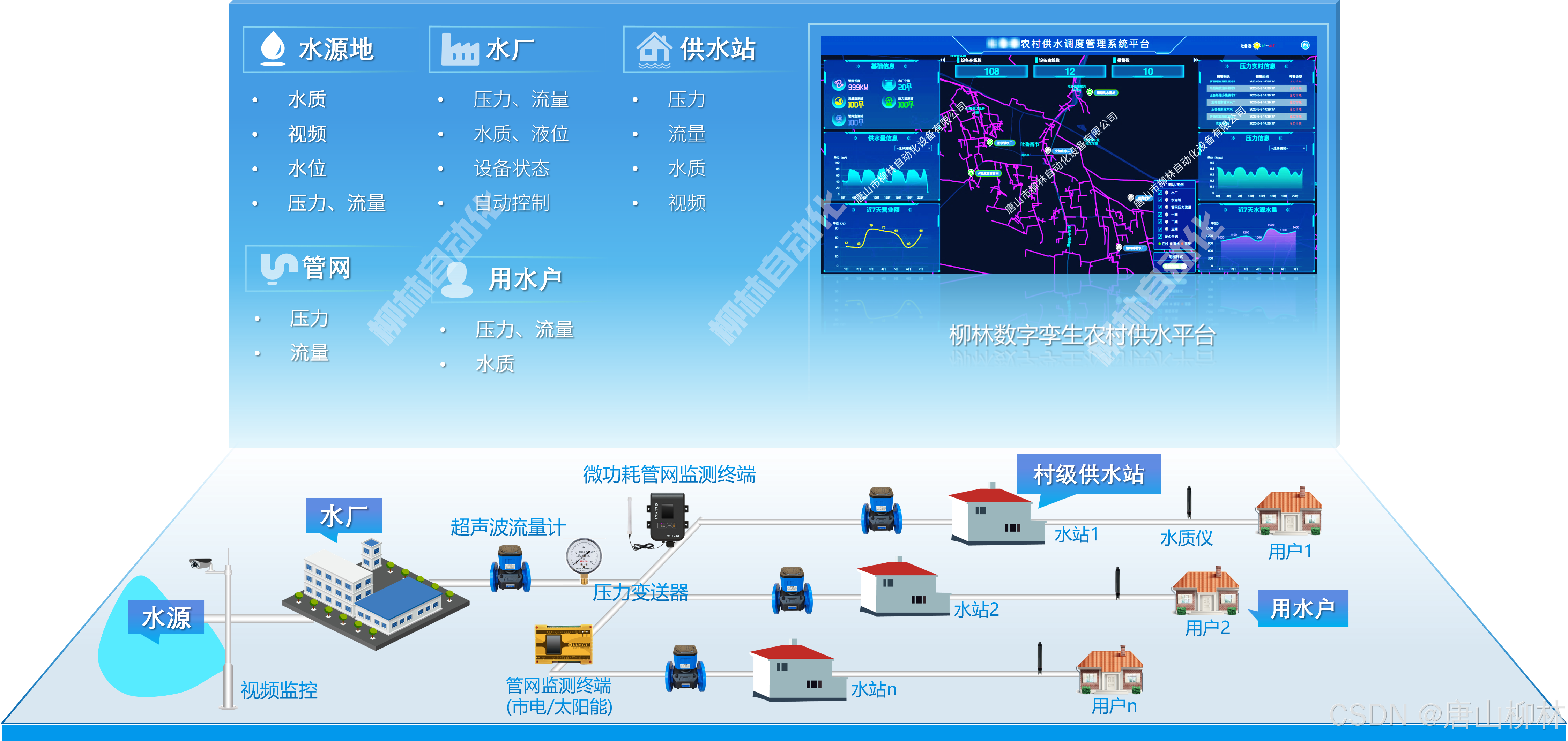
城乡供水信息化系统如何建设?
城乡供水信息化建设是一个综合性的过程,旨在通过现代信息技术提升农村供水系统的管理效率和服务质量。这一过程包含以下关键内容: 一、信息化基础设施建设 感知层建设:在农村饮水工程的关键部位,如水源地、水厂、供水管网等&#…...

【Petri网导论学习笔记】Petri网导论入门学习(七) —— 1.5 并发与冲突
导航 1.5 并发与冲突1.5.1 并发定义 1.14定义 1.15 1.5.2 冲突定义 1.17 1.5.3 一般Petri网系统中的并发与冲突定义 1.18一般网系统中无冲撞概念阻塞(有容量函数K的P/T系统,类似于冲撞)一般Petri网中并发与冲突共存情况 1.5 并发与冲突 Petr…...

MongoDB常用语句
1.只统计记录总数: let result await CorrectionRecordModel.countDocuments(db);2.数组遍历,循环体中可以有调用异步函数: for(let item of result2){if(item && Tool.checkNotEmptString(item.auth_id) && (item.status …...

自动创作PPT 利用提示词和大模型自动创建ppt
背景 ppt创作可以分为3个步骤:1.大纲撰写;2.内容填充;3.ppt实现。我前几天用十分钟的时间做了一个ppt,主讲大模型测评。这里给大家分享一下我的创作过程。 关于步骤1和步骤2,最近发现一个非常好的提示词,…...

二分类评价指标AUROC和AUPR
文章目录 一、AUROC(Area Under the Receiver Operating Characteristic Curve)二、AUPR(Area Under the Precision-Recall Curve)三、区别3.1 案例3.2 如何选择? 在分类任务中, AUROC(受试者工…...

雅迪控股营收、净利润和毛利下滑:销量大幅减少,屡屡抽查不合格
《港湾商业观察》廖紫雯 日前,雅迪集团控股有限公司(以下简称:雅迪控股,01585.HK)发布业绩报告,披露2024年上半年营收净利双下滑等情况,在业绩承压的情况下,雅迪控股遭多家券商下调…...
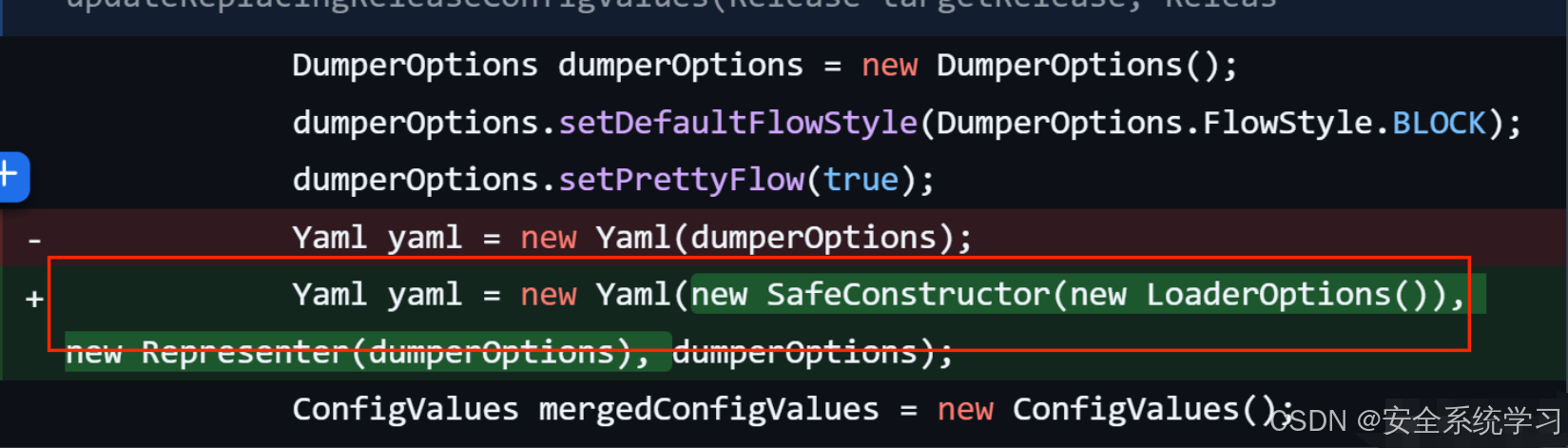
【网络安全】记一次漏洞挖掘
Spring Cloud Data Flow 热点漏洞详细分析 环境搭建 2.10.0 - 2.11.2版本都可以,这里下的2.11.2 源码下载https://github.com/spring-cloud/spring-cloud-dataflow/tree/v2.11.2 在src/docker-compose里面是有docker文件的,使用docker即可 最近是爆出…...
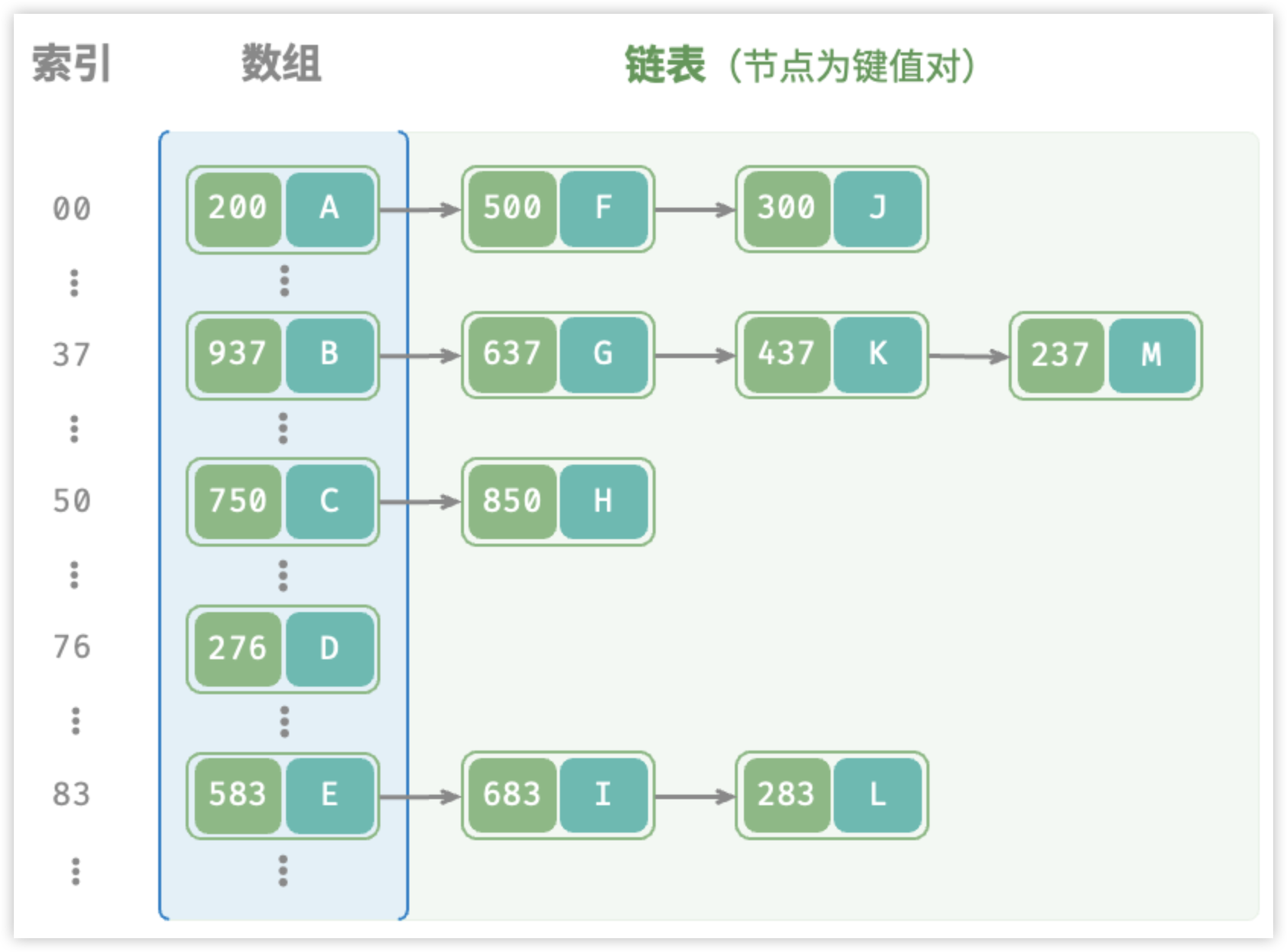
Redis遇到Hash冲突怎么办?
这是小伙伴之前遇到的一个面试题,感觉也是一个经典八股,和大伙分享下。 一 什么是 Hash 冲突 Hash 冲突,也称为 Hash 碰撞,是指不同的关键字通过 Hash 函数计算得到了相同的 Hash 地址。 Hash 冲突在 Hash 表中是不可避免的&am…...

React综合指南(四)
61、描述React事件处理。 为了解决跨浏览器兼容性问题,React中的事件处理程序将传递SyntheticEvent实例,该实例是React跨浏览器本机事件的跨浏览器包装器。这些综合事件具有与您惯用的本机事件相同的界面,除了它们在所有浏览器中的工作方式相…...

Spring集成Redisson及存取几种基本类型数据
目录 一.什么是Redisson 二.为什么要使用Redisson 三.Spring集成Redisson 1.添加依赖 2.添加配置信息 3.添加redisson配置类 四.Redisson存取各种类型数据 1.字符串(String类型) 存储 获取 2.object对象类型 1.实体类信息 2.存储 3.获取 3.List集合类型 第一种…...

Maplibre-gl\Mapbox-gl改造支持对矢量瓦片加密
Maplibre-gl是Mapbox-gl剔除自带地图服务之后的一个分支,代码很相似。Maplibre-gl\Mapbox-gl使用的pbf格式的矢量瓦片,数据量小,渲染效果好。但也存在着信息泄露的风险。但如果想使用这个开发框架的前端渲染效果,还必须要使用这个格式。最近研究了一下如何对矢量瓦片进行加…...
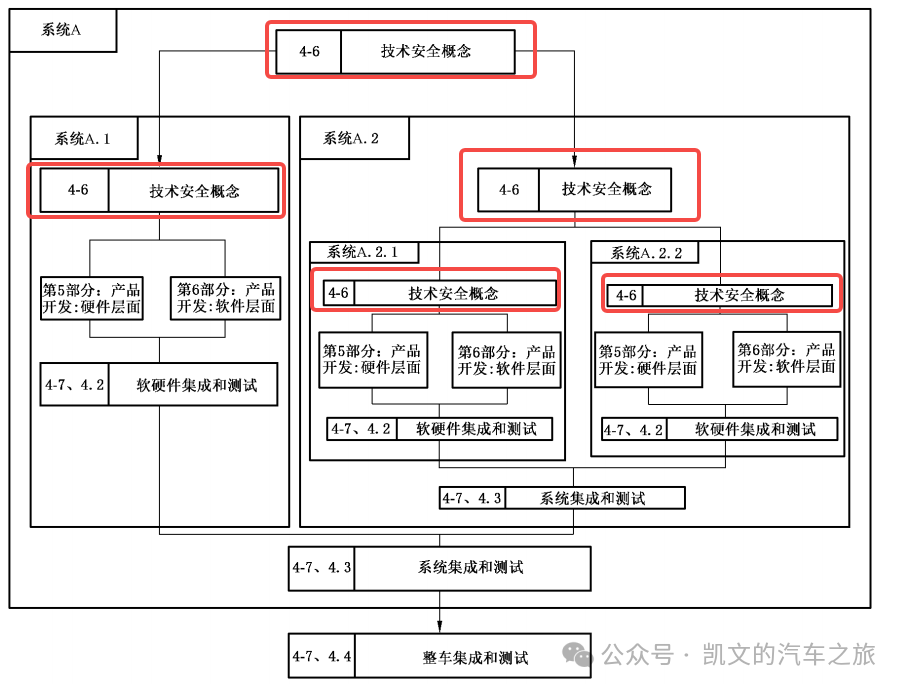
【功能安全】技术安全概念TSC
目录 01 TSC定义 02 TSC注意事项 03 TSC案例 📖 推荐阅读 01 TSC定义 所处位置 TSC:Technical safety concept技术安全概念 TSR:Technical safety requirement技术安全需求 在系统开发阶段属于安全活动4-6 系统层产品开发示例 TSC目的...

Spark数据源的读取与写入、自定义函数
1. 数据源的读取与写入 1.1 数据读取 读文件 read.jsonread.csv csv文件由两个部分组成:头部数据(也就是字段数据)、行数据。 read.orc 读数据库 read.jdbc(jdbc连接地址,table‘表名’,properties{‘user’用户名,‘password’密码,‘driv…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

终极指南:3步掌握yfinance金融数据获取与智能修复实战
终极指南:3步掌握yfinance金融数据获取与智能修复实战 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够从Yahoo! Finan…...

揭秘Midjourney“树胶重铬酸盐”风格指令:3步精准触发古典印相质感,92%用户从未用对的隐藏参数组合
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的光学原理与数字映射本质 树胶重铬酸盐(Gum Bichromate)工艺是19世纪末发展起来的经典光敏印相技术,其核心光学原理基于重铬酸盐在紫外光照射下发生…...

【最新v2.7.1 版本安装包】OpenClaw 小白入门必看,零基础无需命令零代码保姆级教学
OpenClaw v2.7.1 一键安装部署教程|可视化傻瓜式搭建 ✨适配系统:Windows10/11 64 位 ✨当前版本:v2.7.1 版本(虾壳云版) ✨安装包大小:58.7MB 【点击下载最新安装包】https://xiake.yun/api/download/…...

量子退火与经典优化结合的金融投资组合优化实践
1. 量子退火与经典优化结合的金融投资组合优化实践在金融投资领域,如何构建最优投资组合一直是核心挑战。传统方法如现代投资组合理论(MPT)和均值-方差优化(MVO)虽然奠定了理论基础,但在处理大规模资产配置时往往面临计算效率瓶颈。近年来,量…...

ANSYS APDL函数方程加载:从GUI操作到命令流集成的完整指南
1. 项目概述:为什么我们需要函数方程加载?在ANSYS的仿真世界里,我们经常遇到一个头疼的问题:载荷不是一成不变的。比如,一个大型储罐的侧壁,水压会随着深度线性增加;一个高速旋转的叶片…...

Go语言LLM应用开发框架:统一接口与工具调用实战
1. 项目概述:一个为Go语言量身打造的LLM应用开发框架如果你正在用Go语言构建一个需要集成大语言模型(LLM)的应用,比如一个智能客服机器人、一个代码生成工具,或者一个文档分析系统,那么你很可能已经体会过那…...

Logseq Full House Templates 终极指南:如何用智能模板提升知识管理效率
Logseq Full House Templates 终极指南:如何用智能模板提升知识管理效率 【免费下载链接】logseq13-full-house-plugin Logseq Templates you will really love ❤️ 🏛️ 项目地址: https://gitcode.com/gh_mirrors/lo/logseq13-full-house-plugin …...

英文专业论文,可以用维普AIGC检测查AI率吗?
维普查重系统目前是国内比较权威的查重系统,目前国内很多高校是和维普系统合作的。 维普系统也是很多大学生都知晓的查重系统,并且上线了维普AIGC检测功能,可以查论文的AI率。 但是英文专业的毕业论文又和其他专业的不一样,那么…...