银行客户贷款行为数据挖掘与分析
#1024程序员节 | 征文#
在新时代下,消费者的需求结构、内容与方式发生巨大改变,企业要想获取更多竞争优势,需要借助大数据技术持续创新。本文分析了传统商业银行面临的挑战,并基于knn、逻辑回归、人工神经网络三种算法,对银行客户的贷款需求进行分析。最后,使用KMeans聚类算法进行客群分析,绘制出雷达图、t-SNE散点图、柱状图,多方面展现客户贷款行为。

前言
1、研究背景
银行主要业务包括:资产业务、负债业务、中间业务。其中资产业务主要是指贷款业务,并且它也是银行目前主要的收入来源。同时,随着互联网金融的兴起,一些客户向线上交易方式转移,国有银行的垄断地位开始动摇,其原因主要是这些互联网金融机构利用大数据、云计算、区块链、人工智能、物联网等技术,将其应用在很多应用场景中,包括智能投研、智能投顾、智能客服、智能营销、智能风控、银行云等,这些技术的作用不只是扩大客户的融资需求,还可以用于风险控制、项目评估等方面,达到利益与风险相均衡的状态。为扭转这一局面,传统银行业开始转型升级,与互联网领域融合,优化盈利模式。
2、影响客户贷款需求的因素
⑴客户基本信息
分析贷款客户的年龄、婚姻状况、教育水平、职业等特征,针对这些客户的特征进行分类,对每一类客户群体做出不同的营销方案。
如图1-1、1-2所示,从年龄上分析,进入银行办理业务的客户年龄大多集中在25-65岁之间,而具有贷款需求的客户的年龄分布与之相一致,同时,贷款客户占银行客户总人数的16.03%,说明贷款业务有很大的市场潜力,可以通过一些措施来激发客户的贷款需求。
import matplotlib.pyplot as plt
#设置字体
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.hist(o_data.loc[o_data['loan']=='yes','age'].values,color='red',label='y',range=(10,80),alpha=0.1)
plt.hist(o_data.loc[o_data['loan']=='no','age'].values,color='green',label='n',range=(10,80),alpha=0.1)
plt.xlabel('年龄')
plt.ylabel('人数')
plt.title('银行客户的年龄分布')
plt.legend(['y','n'])
plt.show()
图1-1 银行客户的年龄分布图
u,c=np.unique(np.array(data['loan']).astype(np.str),return_counts=True,axis=0)
#种类对应的个数
num=list(c)
#设置字体
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.pie(num,labels=['no', 'yes'],autopct='%1.2f%%') #绘制饼图,百分比保留小数点后两位
plt.title('贷款百分比饼图')
plt.show()
图1-2 贷款百分比饼图
如图1-3所示,从职业上分析,银行客户的职业大多集中在蓝领、银行人员、服务业从事人员、技术人员,而职业为蓝领的客户贷款可能性最大。

图1-3 银行客户的职业分布图
如图1-4所示,从受教育水平上分析,大部分银行客户的受教育水平处在中等、高等教育水平,有一小部分客户的受教育水平未知。
import seaborn as sns
from matplotlib import pyplot as plt
#教育水平
fig, ax = plt.subplots(figsize=(8,6))
ax = sns.countplot(x=data.education,hue=data.loan,palette="Set1")
图1-4 客户受教育水平的分布图
如图1-5所示,从婚姻状况上分析,各种情况的人数占比都差不多,其中,已婚和离婚的客户人数较多。
dataY=data.loc[data['loan']=='yes',:]
a=round(dataY.loc[dataY['marital']=='single','marital'].count()/data.loc[data['marital']=='single','marital'].count(),2)
b=round(dataY.loc[dataY['marital']=='married','marital'].count()/data.loc[data['marital']=='married','marital'].count(),2)
c=round(dataY.loc[dataY['marital']=='divorced','marital'].count()/data.loc[data['marital']=='divorced','marital'].count(),2)
print(a,b,c)
l=[0.13,0.17,0.18]plt.bar(['single', 'married', 'divorced'],l)
plt.xlabel('婚姻状况')
plt.ylabel('贷款人数/总人数')
plt.title('银行贷款客户的婚姻状况分布')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.show()
⑵业务情况
与业务情况相关的因素,主要包括与客户的交流方式、交流次数、客户的账户平均余额,通过对这一方面的分析,可以制定出贷款方案,以更大程度的满足客户需求,同时,通过对客户交易情况的了解,将信息推送限制在一定范围内,给客户带来银行交易的愉悦感,增强与客户之间的信任。
如图1-6、1-7、1-8所示,从账户平均余额上分析,客户的贷款金额较小,大多集中在0-3000元之间,高端客户资源稀少。从与客户办理业务时的交流方式上分析,大部分客户使用手机进行信息咨询。从交流次数上分析,与客户的交流次数大多集中在1-5次之间。
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.hist(data['balance'],color='blue',label='y',range=(0,15000),alpha=0.1)
plt.xlabel('账户平均余额')
plt.ylabel('人数')
plt.title('银行客户的账户平均余额分布')
plt.show()

#把异常值用均值代替
mean=round(data.iloc[:,14].describe()[1],0)
data.loc[data[:]['previous']>250,'previous']=mean
data.loc[data[:]['previous']==0,'previous']=mean
data[:]['previous']=data[:]['previous'].astype('int64')#交流次数
dataY=data.loc[data['loan']=='yes',:]
fig, ax = plt.subplots(figsize=(10,6))
ax =sns.countplot(x='previous',data=dataY.loc[dataY['previous']<30,:],palette="Set1")
图1-8 交流次数分布图
数据预处理
1、筛选有效特征
如图1-9、1-10所示,由于原始数据的列数过多,考虑到在构建模型阶段可能会浪费很多的时间,因此,我们用逻辑回归分析方法对数据进行筛选,删除不必要的列,最后筛选出job、material、education、balance、housing、contact、previous、loan这几列,经过评估,模型的平均正确率为0.8438。

data.corr()
data=data.loc[:,['job','marital','education','balance','housing','contact','previous','loan','age','default']]图1-9 原始数据

图1-10 筛选后数据
2、连续型数据的处理
如图1-10所示,使用info()方法来查看每一列的数据类型,其中,balance、previous这两列属于连续型数据。这类数据的处理方法是通过绘制箱线图,查看是否存在异常值,如果存在,需要利用describe()查看该列的均值,用均值替换掉异常值。
#连续型数据的处理
import matplotlib.pyplot as plt
#设置字体
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.boxplot(data.iloc[:,3]) #绘制饼图,百分比保留小数点后两位
plt.title('账户余额箱线图')
plt.show()
#把异常值用均值代替
mean=round(data.iloc[:,3].describe()[1],0)
data.loc[data[:]['balance']>100000,'balance']=mean
data.loc[data[:]['balance']==0,'balance']=mean3、离散型数据的处理
构造如下函数来处理离散型数据,首先要查看所在列中的值的种类数,并创建一个连续的数组,然后将该列的所有数据用数据进行替换,并将数据类型转成int64。
def replaceData(df):count=data[df].describe()[1]l=[]for i in range(0,count):l.append(str(i))data[df].replace(np.unique(data[df]),l,inplace=True)data[df]=data[df].astype('int64')#数据离散化
l=[]
for i in range(0,10):l.append(str(i))
print(l)
data['job'].replace(['blue-collar', 'entrepreneur', 'housemaid', 'management','retired', 'self-employed', 'services', 'student', 'technician','unemployed'],l,inplace=True)#把离散数据转成连续型
def replaceData(df):count=data[df].describe()[1]l=[]for i in range(0,count):l.append(str(i))data[df].replace(np.unique(data[df]),l,inplace=True)replaceData('marital')
replaceData('education')
replaceData('default')
replaceData('housing')
replaceData('loan')
replaceData('contact')
replaceData('poutcome')4、处理后的数据

数据预测方法
对银行客户的贷款需求做分析,需要用到分类算法,我们将使用knn、逻辑回归分析和人工神经网络三种算法来构建模型,并对模型进行评估,计算每种算法的准确率。
1、knn
(1)实现原理
Knn是一种基于已有样本进行推理的算法,通过对已有训练样本集和新进的未知样本做比较,找到与未知样本最相似的k个样本。最后通过对这k个样本的类标号投票得出该测试样本的类别。
(2)步骤
1.对离散数据做one-hot编码,将编码后的数据与连续型数据进行拼接,并对该数据统一做归一化处理,保证所有列对预测结果的影响程度都相同。
2.编写函数,根据测试集准确率与训练集准确率的比值,选定n-neighbors参数的值。
3.预测并得出测试集准确率与训练集准确率。通过计算得出,测试集准确率为0.8368,训练集准确率为0.8482。
from sklearn.model_selection import train_test_split#导入模块
from sklearn.neighbors import KNeighborsClassifier
def ping(n):X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y,test_size=0.4,random_state=2)knn = KNeighborsClassifier(n_neighbors=n)# 训练knn.fit(X_train,y_train)accuracy_train=knn.score(X_train, y_train)#评估-精确率accuracy_test=knn.score(X_test, y_test)#评估-精确率print(str(round(accuracy_test/accuracy_train,2)))(3)评估
如图2-1、2-2所示,通过构建混淆矩阵的方式对模型进行评估,其中,对无贷款需求的客户判定的准确率为85%,对有贷款需求的客户判定的准确率为24%,总体准确率为84%,证明预测结果有效。
#混淆矩阵
from sklearn import metrics
metrics.accuracy_score(y_test_pre, y_test)
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(metrics.confusion_matrix(y_test_pre, y_test),interpolation='nearest', cmap=plt.cm.binary)
plt.grid(False)
plt.colorbar()
plt.xlabel("predicted label")
plt.ylabel("true label")
#评估报告
from sklearn.metrics import classification_report
print(classification_report(y_test,y_test_pre))
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(10, 6))
plt.scatter(range(0,50),data.iloc[39951:,8], color='g',label='实际值',linewidth=3,alpha=0.1)
plt.scatter(range(0,50),y_train[23950:], color='r',label='预测值',linewidth=2,alpha=0.1)
plt.legend()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('knn预测结果')
plt.show() 
(4)预测
import seaborn as sns
from matplotlib import pyplot as plt
fig, ax = plt.subplots(figsize=(8,6))
ax = sns.barplot(x=ndata.job,y=ndata.education,hue=ndata.knn,palette="Set1")
贷款客户主要集中在蓝领、管理者、技术人员中,且客户的教育水平普遍都很高 。
from matplotlib import pyplot as plt
plt.hist(ndata.loc[ndata['knn']==1,'balance'].values,range=(0,15000))
plt.xlabel('账户余额')
plt.ylabel('人数')
plt.title('银行贷款客户的账户余额分布')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.show()
2、逻辑回归
(1)实现原理
逻辑回归是根据输入值域对记录进行分类的统计方法。它是将输入值域与输出字段每一类别的概率联系起来。一旦生成模型,便可用于预测。对于每一记录,计算其从属于每种可能输出类的概率,概率最大的类即为预测结果。
(2)步骤
1.划分测试集与训练集。
#划分自变量数据集与因变量数据集
x = data.iloc[:,[1,2,3,4,5,6,7,9,10,11,12,13,14,15,16,17]]
y = data.iloc[:,8]2.使用RandomizedLogisticRegression筛选特征
#使用RandomizedLogisticRegression筛选有效特征
from sklearn.linear_model import RandomizedLogisticRegression as RLR
rlr = RLR() #建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) #训练模型
rlr.get_support() #获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束。')
print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support(indices=True)]))
x = data[data.columns[rlr.get_support(indices=True)]].as_matrix()#筛选好特征x = data.loc[:,['job','marital','education','balance','housing','contact','previous']]3.进行预测并计算准确率。通过计算得出,测试集准确率为0.8403,训练集准确率为0.8461。
#使用筛选后的特征数据用LogisticRegression来训练模型
from sklearn.linear_model import LogisticRegression as LR
lr = LR() #建立逻辑回归模型
#训练集
x=p_data.iloc[0:24000,1:8]
y=p_data.iloc[0:24000,8]
#测试集
x1=p_data.iloc[24000:,1:8]
y1=p_data.iloc[24000:,8]
lr.fit(x, y) #训练数据
r=lr.score(x, y); # 模型准确率(针对训练数据)
#训练集的预测准确率
trainR=lr.predict(x)
trainZ=trainR-y
trainRs=len(trainZ[trainZ==0])/len(trainZ)
print('训练集的预测准确率为:',trainRs)
#测试集的预测准确率
R=lr.predict(x1)
Z=R-y1
Rs=len(Z[Z==0])/len(Z)
print('测试集的预测准确率为:',Rs)(3)评估
如图2-3、2-4所示,通过构建混淆矩阵的方式对模型进行评估,其中,对无贷款需求的客户判定的准确率为84%,召回率100%;对有贷款需求的客户判定的准确率为0%,总体准确率为84%。
from sklearn import metrics
metrics.accuracy_score(R, y1)
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(metrics.confusion_matrix(R, y1),interpolation='nearest', cmap=plt.cm.binary)
plt.grid(False)
plt.colorbar()
plt.xlabel("predicted label")
plt.ylabel("true label")

3、人工神经网络
(1)实现原理
在人工神经网络算法中,对损失函数用梯度下降法进行迭代优化求极小值的过程使用的是BP算法。BP算法由信号的正向传播和误差的反向传播构成。首先,将信号从输入层传递至输出层。若实际输出与期望输出不一致,则进入误差反向传播阶段,将误差反向传递,获得各层的误差信号,对误差做调整。通过反复执行信号的正向传播和误差的反向传播操作,直至输出误差达到期望值,或进行到预定的学习次数为止。
(2)步骤
1.对离散数据做one-hot编码,将编码后的数据与连续型数据进行拼接,并对该数据统一做归一化处理,保证所有列对预测结果的影响程度都相同。
2.划分训练集和测试集。
#分离训练集与测试集,median_house_value列的数据是研究的目标
from sklearn.model_selection import train_test_split
Train_X,Test_X,Train_y,Test_y=train_test_split(x,y,test_size=0.4,random_state=2)3.采用GridSearchCV来进行参数调整实验,对solver、hidden_layer_sizes两个参数的值进行调整,找出最佳参数组合。
4.预测并计算准确率。通过计算得出,测试集准确率为0.9997,训练集准确率为0.9998。
#采用GridSearchCV来进行参数调整实验,找出最佳参数组合
from sklearn.model_selection import GridSearchCV
from sklearn.neural_network import MLPRegressor
param_grid = {'solver':['lbfgs','sgd','adam'],'hidden_layer_sizes': [(5,5),(10,10)]}
#对param_grid中的各参数进行组合,传递进MPL回归器。
#cv=3,3折交叉验证,将数据集随机分为3份,每次将一份作为测试集,其他为训练集
#n_jobs=-1,使用CPU核心数,-1表示所有可用的核
best_mlp =GridSearchCV(MLPRegressor(max_iter=200),param_grid,cv=3)
best_mlp.fit(Train_X,Train_y)
print('当前最佳参数组合:',best_mlp.best_params_)
best_score=best_mlp.score(Test_X,Test_y)*100
print('sklearn人工神经网络上述参数得分: %.1f' %best_score + '%')
#用以上模型对Test_X进行预测
mlp_pred = best_mlp.predict(Test_X)(3)评估
accuracy_train=best_mlp.score(Train_X,Train_y)#评估-精确率
accuracy_test=best_mlp.score(Test_X,Test_y)#评估-精确率
print('训练集精确率:'+str(accuracy_train)+' 测试集:'+str(accuracy_test))![]()
三种算法之间的比较
(1)逻辑回归:该算法的数据处理过程较为简单,并且在构建模型的时候不能输入参数进行设置,因此需要手动划分训练集和测试集。
(2)人工神经网络:该算法内部带有很多方法,可以对数据进行one-hot编码、归一化等处理,排除特殊数值对结果的影响,还能进行参数调整,找到最佳参数组合,因此,在这三种算法中,人工神经网络算法的拟合度最高。
(3)Knn:在预测前需要对数据进行处理,排除特殊数值对结果的影响,同时,该算法在构建模型的过程中可以指定参数,尤其是n-neighbors,这个需要我们自行编写方法来找到n-neighbors的最佳值。
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(10, 6))
plt.plot(range(0,50),data.iloc[39951:,8], 'go--',label='实际值',linewidth=1)
plt.plot(range(0,50),f_data1.iloc[:,1], 'y--',label='逻辑分析',linewidth=2)
plt.plot(range(0,50),f_data1.iloc[:,2], 'r:',label='knn',linewidth=2)
plt.plot(range(0,50),f_data1.iloc[:,3], 'b',label='sklearn',linewidth=2,alpha=0.5)
plt.legend()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('三种算法预测结果')
plt.show()
KMeans聚类客群分析
1、将每个特征值归一化到一个固定范围
from sklearn import preprocessing
x=data.iloc[:,[1,3,4,5,6,7]]
x= preprocessing.MinMaxScaler(feature_range=(0,1)).fit_transform(x)#将每个特征值归一化到一个固定范围 2、开始聚类
from sklearn.cluster import KMeans
import numpy as np
#model = KMeans(init=np.array([[4,5],[5,5]]),n_clusters = k, n_jobs = 4, max_iter = iteration) #分为k类,并发数4
model = KMeans(n_clusters = 4,max_iter = 200) #分为k类,并发数4
model.fit(x) #开始聚类3、预测并绘图
(1)雷达图
coreData=np.array(model.cluster_centers_)
ydata0 = np.concatenate((coreData[0], [coreData[0][0]]))
ydata1 = np.concatenate((coreData[1], [coreData[1][0]]))
ydata2 = np.concatenate((coreData[2], [coreData[2][0]]))
ydata3 = np.concatenate((coreData[3], [coreData[3][0]]))xdata = np.linspace(0,2*np.pi,6,endpoint=False)
xdata = np.concatenate((xdata,[xdata[0]]))
from matplotlib import pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111,polar=True) #111表示“1×1网格,第一子图”
ax.plot(xdata, ydata0, 'ro--', linewidth=1.2, label='A组客户')
ax.plot(xdata, ydata1, 'b^--', linewidth=1.2, label='B组客户')
ax.plot(xdata, ydata2, 'y*--', linewidth=1.2, label='C组客户')
ax.plot(xdata, ydata2, 'g+-', linewidth=1.2, label='D组客户')
# ax.plot(xdata, ydata3, 'go--', linewidth=1.2, label='D组客户')
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号“-”显示异常
ax.set_thetagrids(xdata * 180 / np.pi, ['job ', 'education', 'balance', 'housing', 'contact','previous']) # 有六个值,将一个圆分为六块
ax.set_rlim(-4, 13) # 轴值范围,圆点是-4,最外层是13
plt.legend(loc=4)
plt.show()
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = ['job ', 'education', 'balance', 'housing', 'contact','previous'] + [u'kind'] #重命名表头
(2)t-SNE散点图
from sklearn.manifold import TSNE
t=TSNE()
t.fit_transform(x)
t=pd.DataFrame(t.embedding_)d=t[r[u'kind']==0]
plt.scatter(d[0],d[1],color='r')
d=t[r[u'kind']==1]
plt.scatter(d[0],d[1],color='b')
d=t[r[u'kind']==2]
plt.scatter(d[0],d[1],color='y')
# d=t[r[u'聚类类别']==3]
# plt.scatter(d[0],d[1],color='g')
plt.show()
(3)柱状图
import seaborn as sns
sns.countplot(x='job',color='salmon',data=r,hue='kind')
from matplotlib import pyplot as plt
l=[1415.26, 1599.9, 1661.7, 1056.26]
plt.bar(['客群1','客群2','客群3','客群4'],l)
plt.xlabel('客群种类')
plt.ylabel('账户余额')
plt.title('银行贷款客户的账户余额分布')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.show()
sns.barplot(x='contact',y='education',color='salmon',data=r,hue='kind')
结论
如图2-5所示,在这三种算法中,人工神经网络算法的拟合度最高。通过模型评估发现,每个算法对于无贷款需求的判定准确率较高,而对于有贷款需求的判定准确率较低。

相关文章:
银行客户贷款行为数据挖掘与分析
#1024程序员节 | 征文# 在新时代下,消费者的需求结构、内容与方式发生巨大改变,企业要想获取更多竞争优势,需要借助大数据技术持续创新。本文分析了传统商业银行面临的挑战,并基于knn、逻辑回归、人工神经网络三种算法࿰…...
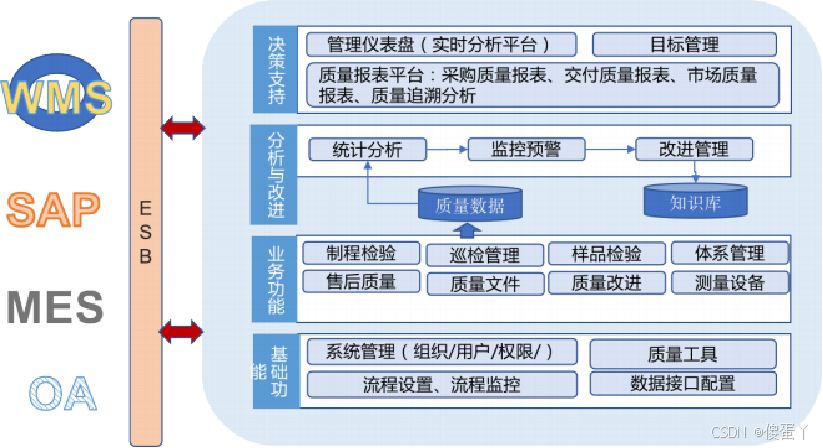
制程质量管理方案设计
质量管理系统框架——QMS 涵盖产生产制造体系的全生命周期的质量管理过程 与SAP、WMS、MES、OA等业务系统进行集成,整合各业务系统中的质量信息 利用整合的全价值链质量信息,寻找质量改进点和质量创新点 系统功能模块管理 系统管理:用户管理…...

uniapp移动端优惠券! 附源码!!!!
本文为常见的移动端uniapp优惠券,共有6种优惠券样式(参考了常见的优惠券),文本内容仅为示例,您可在此基础上调整为你想要的文本 预览效果 通过模拟数据,实现点击使用优惠券让其变为灰色的效果(模…...

【分布式技术】中间件-zookeeper安装配置
文章目录 安装部署1. 安装ZooKeeper2. 配置ZooKeeper3. 启动ZooKeeper服务器4. 使用ZooKeeper命令行客户端5. 使用ZooKeeper的四个基本操作6. ZooKeeper集群模式7. 安全和权限8. 监控和日志 相关文献 安装部署 在Linux环境中操作ZooKeeper通常涉及以下几个方面: 1…...

高等数学 7.6高阶线性微分方程
文章目录 一、线性微分方程的解的结构*二、常数变易法 方程 d 2 y d x 2 P ( x ) d y d x Q ( x ) f ( x ) (1) \cfrac{\mathrm{d}^2 y}{\mathrm{d}x^2} P(x) \cfrac{\mathrm{d}y}{\mathrm{d}x} Q(x) f(x) \tag{1} dx2d2yP(x)dxdyQ(x)f(x)(1) 叫做二阶线性微分方程。…...

LSP的建立
MPLS需要为报文事先分配好标签,建立一条LSP,才能进行报文转发。LSP分为静态LSP和动态LSP两种。 静态LSP的建立 静态LSP是用户通过手工为各个转发等价类分配标签而建立的。由于静态LSP各节点上不能相互感知到整个LSP的情况,因此静态LSP是一个…...

huggingface的数据集下载(linux下clone)
1. 安装lfs sudo apt-get install git-lfs 或者 apt-get install git-lfs 2. git lfs install git lfs install 3. git clone dataset包 第2,3步骤的截图如下:...

Java使用dom4j生成kml(xml)文件遇到No such namespace prefix: xxx is in scope on:问题解决
介绍addAttribute和addNamepsace: addAttribute 方法 addAttribute 方法用于给XML元素添加属性。属性(Attributes)是元素的修饰符,提供了关于元素的额外信息,并且位于元素的开始标签中。属性通常用于指定元素的行为或样式&#…...

深入探讨Java中的LongAdder:使用技巧与避坑指南
文章目录 一、什么是LongAdder?二、LongAdder的简单使用示例代码: 三、LongAdder的工作原理四、LongAdder的常见使用场景五、使用LongAdder时的注意事项(避坑指南)1. 不要滥用LongAdder2. sum()方法与精度问题3. 避免过度使用rese…...

【本科毕业设计】基于单片机的智能家居防火防盗报警系统
基于单片机的智能家居防火防盗报警系统 相关资料链接下载摘要Abstract第1章 绪论1.1课题的背景1.2 研究的目的和意义 第2章 系统总体方案设计2.1 设计要求2.2 方案选择和论证2.2.1 单片机的选择2.2.2 显示方案的选择 第3章 系统硬件设计3.1 整体方案设计3.1.1 系统概述3.1.2 系…...

C语言 动态数据结构的C语言实现单向链表-2
建立一个单向链表 在单向链表中查找节点---查找尾节点 在单向链表中查找节点 --- 查找第 n 个节点 向单向链表中插入一个节点 向单向链表的尾部插入一个节点 向单向链表中某节点后插入一个节点 向单向链表中插入一个节点 删除单向链表中的某一节点 链表 vs 数组 动态数据结构...

Github 2024-10-23C开源项目日报 Top10
根据Github Trendings的统计,今日(2024-10-23统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目10PLpgSQL项目1Redis - 内存数据库和数据结构服务器 创建周期:5411 天开发语言:C协议类型:BSD 3-Clause “New” or “Revised” Licen…...
: relocation报错解决)
ubuntu20.04 opencv4.0 /usr/local/lib/libgflags.a(gflags.cc.o): relocation报错解决
在一个只有ubuntu20.04的docker环境中配置opencv4.0.0, 什么库都没有,都要重新安装, 其他的问题在网上都找到了解决方案,唯独这个问题比较棘手: [ 86%] Linking CXX executable …/…/bin/opencv_annotation /usr/bin/ld: /usr/lo…...
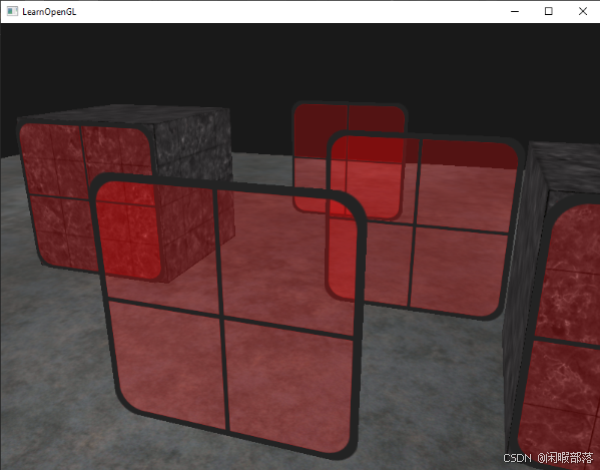
android openGL ES详解——混合
一、混合概念 混合是一种常用的技巧,通常可以用来实现半透明。但其实它也是十分灵活的,你可以通过不同的设置得到不同的混合结果,产生一些有趣或者奇怪的图象。混合是什么呢?混合就是把两种颜色混在一起。具体一点,就…...

计网--物理层
目录 物理层的任务 1、常见概念 2、信道极限容量 3、传输介质 (1)导引型传输介质 (2)非导引型传输介质 4、信道复用技术 (1)频分 / 时分 复用 (2)波分复用WDM (…...

算法的学习笔记—数组中的逆序对(牛客JZ51)
😀前言 在算法和数据结构领域,"逆序对"是一个经典问题。它在数组中两个数字之间定义,若前面的数字大于后面的数字,则这两个数字组成一个逆序对。我们要做的就是,给定一个数组,找出数组中所有的逆…...

Golang | Leetcode Golang题解之第498题对角线遍历
题目: 题解: func findDiagonalOrder(mat [][]int) []int {m, n : len(mat), len(mat[0])ans : make([]int, 0, m*n)for i : 0; i < mn-1; i {if i%2 1 {x : max(i-n1, 0)y : min(i, n-1)for x < m && y > 0 {ans append(ans, mat[x…...

什么是全局污染?怎么避免全局污染?
全局污染(Global Pollution)是指在编程过程中,过度使用全局变量或对象导致命名冲突、代码可维护性下降及潜在错误增加的问题。在 JavaScript 等动态语言中,尤其需要关注全局污染的风险。 全局污染的影响 1. 命名冲突 3. 意外修改…...

C# 串口通信教程
串口通信(Serial Communication)是一种用于设备之间数据传输的常见方法,通常用于与外部硬件设备(如传感器、机器人、微控制器)进行通信。在 C# 中,System.IO.Ports 命名空间提供了与串口设备交互的功能&…...

PHP编程基础
PHP(Hypertext Preprocessor,超文本预处理器)是一种广泛使用的开源服务器端脚本语言,主要用于网页开发,同时也可以进行命令行脚本编写。以下是PHP编程的基础知识: 1. PHP文件结构 PHP文件通常以 .php 为扩…...

10分钟轻松搞定Android Studio中文界面:社区维护版完整配置指南
10分钟轻松搞定Android Studio中文界面:社区维护版完整配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为…...

MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析
MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

Nix与Helm结合:实现声明式Kubernetes部署的确定性构建
1. 项目概述:当 Helm 遇见 Nix,一种声明式的新思路如果你和我一样,长期在 Kubernetes 生态里折腾,肯定对 Helm 又爱又恨。爱的是它用模板和 Values 文件,把一堆零散的 Kubernetes 资源打包成一个可配置、可版本化的“应…...

深入USB总线:图解移远EC20在Linux下如何从硬件接口到虚拟出5个ttyUSB
深入USB总线:图解移远EC20在Linux下如何从硬件接口到虚拟出5个ttyUSB 当我们拆解一台嵌入式设备时,常会遇到4G模块这类看似独立却又深度集成的组件。以移远EC20为例,它表面上通过MiniPCIE接口与主机通信,实则内部隐藏着一套复杂的…...

SM3国密算法实战:从原理到Java代码实现与数据完整性校验
1. SM3国密算法:你的数据安全守门人 第一次听说SM3算法时,我正在处理一个政府项目的投标文件加密需求。客户明确要求必须使用国密标准算法,当时我对这类算法还停留在"听说过但没用过"的阶段。经过两周的实战摸索,我发现…...

为什么你的Windows任务栏需要一次彻底的美学革命?
为什么你的Windows任务栏需要一次彻底的美学革命? 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否曾经盯着Windows桌面…...

如何用OBS插件打造专业音乐直播?Tuna插件完整指南
如何用OBS插件打造专业音乐直播?Tuna插件完整指南 【免费下载链接】tuna Song information plugin for obs-studio 项目地址: https://gitcode.com/gh_mirrors/tuna1/tuna 想让你的OBS直播画面瞬间升级为专业音乐电台风格吗?Tuna插件正是你需要的…...

Illustrator智能对象替换引擎:企业级设计自动化的技术杠杆
Illustrator智能对象替换引擎:企业级设计自动化的技术杠杆 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 技术价值宣言 在数字设计工业化时代,品牌资产管理…...

HiveWE:现代魔兽争霸III地图编辑器终极指南
HiveWE:现代魔兽争霸III地图编辑器终极指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器的缓慢加载和复杂操作而烦恼吗?HiveWE作为一款专注于速度…...

大模型令牌管理工具tokscale:统一计数与成本估算的插件化实践
1. 项目概述:一个面向现代开发者的轻量级令牌管理工具 最近在折腾一些需要处理大量文本数据的项目,比如自动化文档摘要、代码生成或者API调用,一个绕不开的问题就是“令牌”(Token)的管理。无论是使用OpenAI的GPT系列模…...