值得细读的8个视觉大模型生成式预训练方法
写在前面
大语言模型的进展催生出了ChatGPT这样的应用,让大家对“第四次工业革命”和“AGI”的来临有了一些期待,也作为部分原因共同造就了美股2023年的繁荣。LLM和视觉的结合也越来越多:比如把LLM作为一种通用的接口,把视觉特征序列作为文本序列的PrefixToken,一起作为LLM的输入,得到图片或者视频的caption;也有把LLM和图片生成模型、视频生成模型结合的工作,以更好控制生成的内容。当然2023年比较热门的一个领域便是多模态大模型,比如BLIP系列、LLaVA系列、LLaMA-Adapter系列和MiniGPT系列的工作。LLM的预训练范式也对视觉基础模型的预训练范式产生了一定的影响,比如MAE、BEIT、iBOT、MaskFEAT等工作和BERT的Masked Language Modeling范式就很类似,不过按照GPT系列的自回归方式预训练视觉大模型的工作感觉不是特别多。下面对最近视觉基础模型的生成式预训练的工作作一些简单的介绍。
LVM
《Sequential Modeling Enables Scalable Learning for Large Vision Models》是UC Berkely和Johns Hopkins University在2023提出的一个影响比较大的工作,视觉三大中文会议也在头版头条做了报道,知乎的讨论也比较热烈。
-
Sequential Modeling Enables Scalable Learning for Large Vision Models(https://arxiv.org/abs/2312.00785)
-
https://github.com/ytongbai/LVM
-
https://yutongbai.com/lvm.html
按照自回归的生成式训练模型的工作之前也有,比如Image Transformer和Generative Pretraining from Pixels等,不过无论是训练的数据量还是模型的参数量都比较小。LVM把训练数据统一表述成visual sentences的形式。对训练数据、模型参数量都做了Scaling,并验证了Scaling的有效性和模型的In-context推理能力。
本文的一大贡献便是数据的收集和整理,和训练LLM的文本数据一样规模的视觉数据在之前缺乏的,因此从开源的各种数据源出发,得到了 1.64billion 图片的数据集 UVDv1(Unified Vision Dataset v1)。文中对数据的来源以及将不同数据统一为visual sentences描述形式的方法做了详细的介绍Fig 1,可以refer原文更多的细节。

Fig 1 Visual sentences 能够将不同的视觉数据格式化为统一的图像序列结构
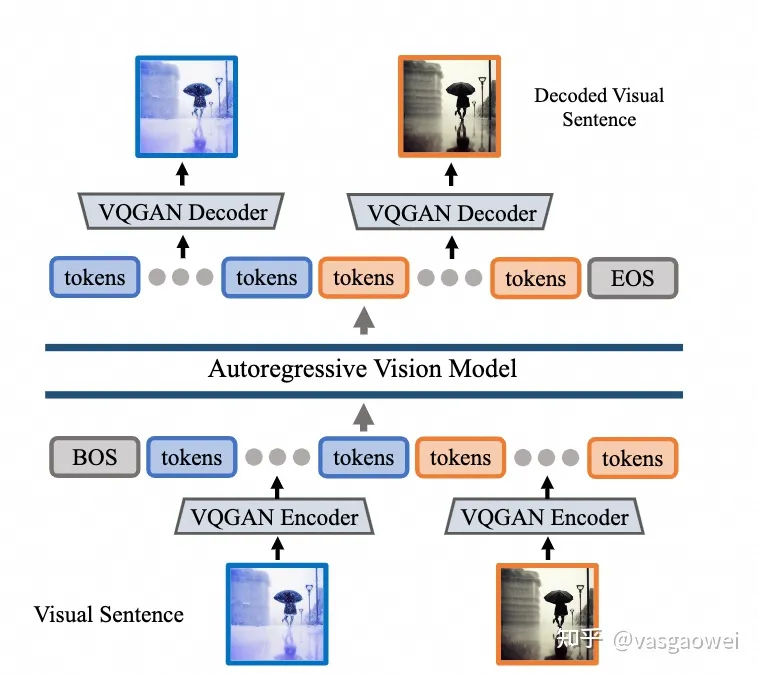
Fig 2
模型的结构如图Fig 2所示,主要包含三部分:Tokenizer、Autoregressive Vision Model和DeTokenizer。
其中Tokenizer和DeTokenizer取自于VQ-GAN,codebook大小为8192,输入图片分辨率为,下采样倍数为16,因此一张输入图片对应的Token数目为,这一个模块通过LAION 5B数据的1.5B的子集来训练。
这样对于一个visual sentence,会得到一个Token的序列(和目前的很多多模态大模型不一样,这儿没有特殊的token用以指示视觉任务的类型),作为Autoregressive Vision Model的输入,通过causal attention机制预测下一个Token。文中的自回归视觉模型的结果和LLaMA的结构一样,输入的token 序列的长度为4096个token(16张图片),同时在序列的开始和结束分别会放置[BOS](begin of sentence)和[EOS](end of sentence),代表序列的开始和结束。整个模型在UVD v1(包含420 billion tokens)数据上训练了一个epoch,模型的大小包括四种:300 million、600 million、1 billion和3 billion。
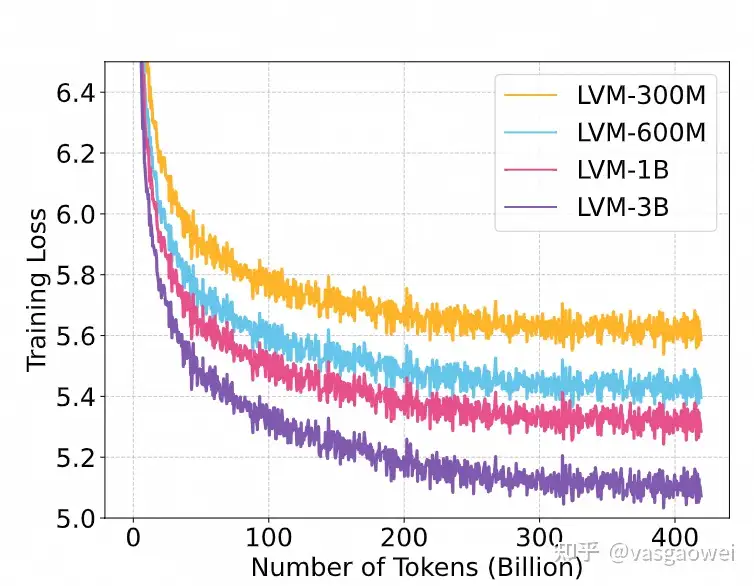
Fig 3
从Fig 3可以看出,训练过程中,模型的loss一直在下降,而且模型参数量越大,loss下降越快
更多的实验结果分析可以refer原文。
EMU
《Generative Pretraining in Multimodality》是BAAI、THU和PKU的工作,提出了多模态大模型EMU,EMU的输入是image-text interleaved的序列,可以生成文本,也可以桥接一些扩散模型的Decoder生成图片。
-
https://arxiv.org/abs/2307.05222
-
https://github.com/baaivision/Emu

Fig 4
EMU的结构如图Fig 4所示,包含四个部分,Visual Encoder(文中用的EVA-02-CLIP)、Causal Transformer、Multimodal Modeling(LLaMA)和Visual Decoder(Stable Diffusion)。
对于输入的 image-text-video interleaved的序列,EVA-CLIP会提取图片的特征,同时通过causal Transformer得到个visual embeddings ,即。对于包含个frame的视频,则会得到个视觉embedding。在每一张图片或者每一帧的特征序列的开始和结束分别有特殊的token,即[IMG]和[/IMG]。
text通过文本的tokenizer得到文本特征序列,和视觉信息对应特征序列连接,并在序列的开始和结束处分别添加表述开始和结束的特殊token,即[s]和[/s]。最后得到的多模态序列作为LLaMA的输入,得到文本输出,而LLaMA输出的视觉特征序列作为扩散模型的条件输入,得到生成的图像。
Emu用Image-text pair的数据、Video-text pair的数据、Interleaved Image and Text的数据以及Interleaved Video and Text的数据进行预训练。对于预测的文本token来说,损失函数为预测下一个token的cross entropy loss;对于视觉token来说,则是的回归损失。
对Emu预训练之后,会对图片生成的Stable Diffusion的Decoder进行微调。微调的时候,只有U-Net的参数会更新,其他的参数固定不变。训练数据集为LAION-COCO和LAION-Aesthetics。每一个训练样本的文本特征序列的结尾处都会添加一个[IMG] token,最后通过自回归的方式得到个视觉特征,这些特征序列作为Decoder的输入得到生成的图片。
文中还对Emu进行多模态指令微调以对其human instructions。数据集包括来自于ShareGPT和Alpaca的文本指令、来自于LLaVA的图像-文本指令以及来自于VideoChat和Video-ChatGPT的video指令。微调的时候,Emu的参数都会固定不变,只有LoRA模块的参数更新。微调的指令跟随数据集格式如下:
[USER]:[ASSISTANT]:。
[User]和[ASSISTANT]分别是单词“word”和“assistant”对应的embedding,不同的任务下也有所不同。

Fig 5
Fig 5是Emu的In-context Learning推理的一个例子,输入图片-描述,以及query文本,会得到对应的输出图片。
4M
《4M: Massively Multimodal Masked Modeling》是瑞士洛桑联邦理工和Apple发表在NeurIPS 2023的一个工作,提出了一种对视觉模型做生成式预训练的范式4M(Massively Multimodal Masked Modeling),将多模态的输入信息编码为特征序列,作为Transformer encoder-decoder的输入,同时采用Masked Modeling的方式,在大量的数据集上对模型进行了训练预训练,可以实现多模态输入、多模态输出,得到的transformer encoder也可以作为一些视觉任务的backbone网络提取图片特征。
-
4M: Massively Multimodal Masked Modeling(https://arxiv.org/abs/2312.06647)
-
4M: Massively Multimodal Masked Modeling(https://4m.epfl.ch/)
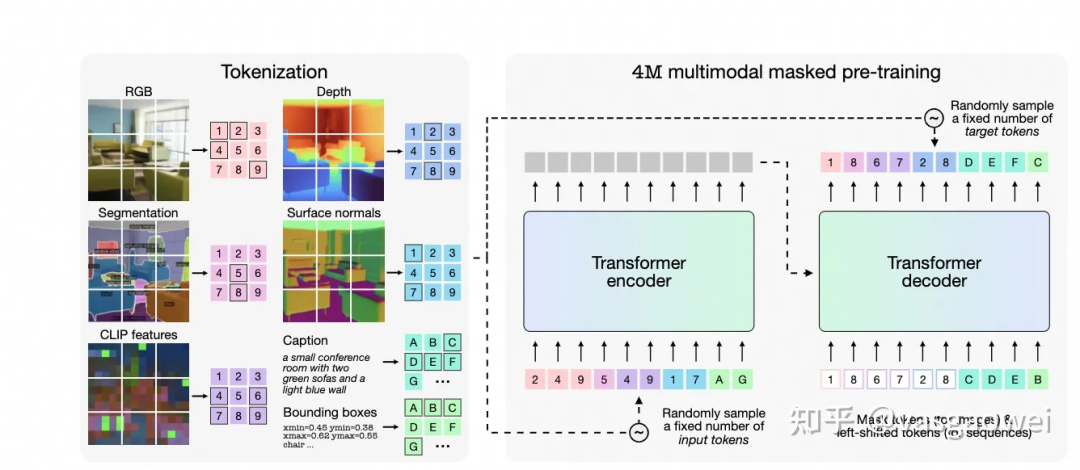
Fig 6
模型的结构如图Fig 6所示,不同模态的输入按照不同的方式编码为特征序列,同时从特征序列中随机选择一部分作为context,另外一部分作为需要预测的target,模型基于context序列预测target序列。
文中对bounding box的Tokenization方式和Pix2Seq一样,比如对于一个坐标为的框,会按照1000的分辨率对这些坐标做编码,即,这些编码之后的坐标和文本一样,通过WordPiece的text tokenizer得到对应的特征序列,训练的时候通过cross entropy的方式计算重建的loss。
分割的掩码通过ViT-B结构的encoder得到对应的特征序列,也通过ViT-B结构的decoder得到对应的重建结果,然后通过损失计算重建损失。
RGB、normals或者depth图则是用VQ_VAE的的encoder得到特征序列,同时用扩散模型的decoder得到重建结果,损失不是扩散模型里面常用的噪声回归损失,而是重建clean image的损失。
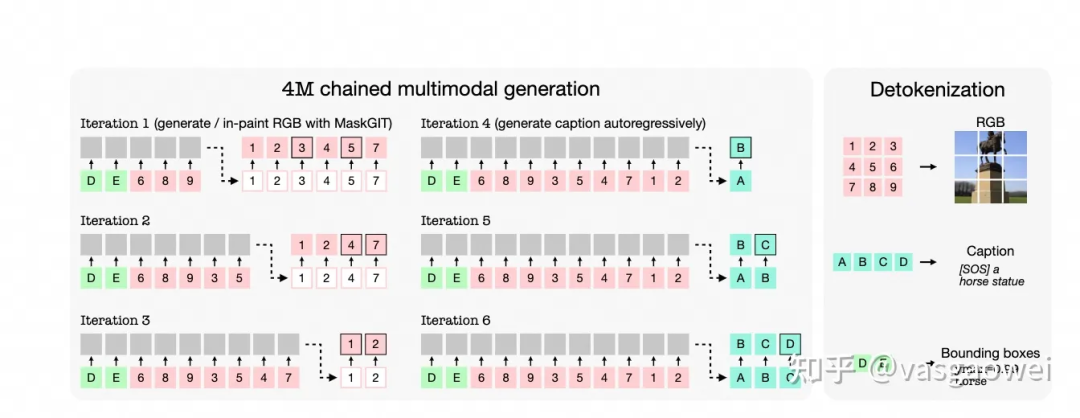
Fig 7
预训练之后的模型可以通过自回归的方式得到输出的特征序列,这些特征序列可以通过对应的decoder解码得到输出的图片、文本等,如图Fig7所示。训练之后encoder可以作为目标检测、语义分割等视觉任务的骨架网络。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

VL-GPT
《VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation》是西交、腾讯和港大提出的一个工作。
-
VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation(https://arxiv.org/abs/2312.09251)
-
https://github.com/AILab-CVC/VL-GPT
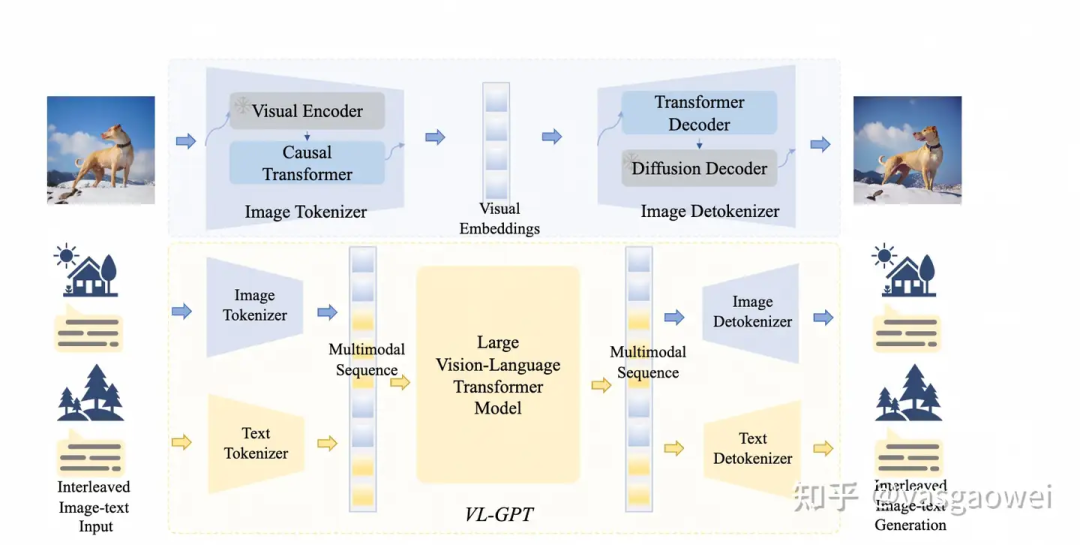
Fig 8
模型的结构如图Fig 8所示,包含两个部分,第一个部分是image tokenizer-detokenizer框架的训练,第二个部分是VL-GPT模型的预训练和指令微调。输入模型的文本、图片分别通过Image Tokenizer和Text Tokenizer得到图像和文本特征序列,连接之后得到imate-text interleaved的文本-图像特征序列,作为LLM的输入,通过自回归的方式得到输出的特征序列,输出的特征序列通过Image和Text Detokenizer得到生成的图片和文本。
Image tokenizer-detokenizer包含一个tokenizer 将图片编码为连续的视觉特征序列。detokenizer 则是将视觉特征转换为图片输出。
文中的用了ViT结构,得到输入图片的特征序列,而detokenizer 则是用到了隐空间扩散模型,包含一个transformer decoder用于基于估计扩散模型的条件特征,可以作为扩散模型的decoder的条件得到生成的图片。训练的时候如图Fig 9所示,用预训练的CLIP模型的图像encoder和文本encoder提取图像和文本特征作为监督信息,损失函数为。
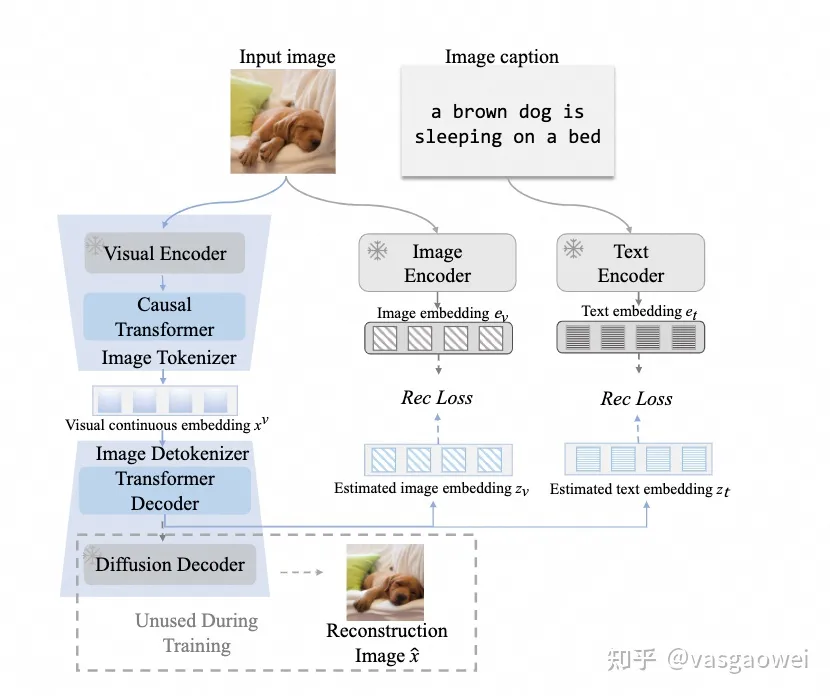
Fig 9
VL-GPT包含image tokenizer-detokenizer的tokenizer和detokenizer,其组件分别为LLM (文中用到了LLaMA)、图像encoder 、文本encoder 、图像detokenizer 和文本detokenizer 。输入image-text interleaved数据通过图像encoder和文本encoder得到多模态的特征序列,作为的输入,对下一个token进行预测。
预训练损失为,其中对于文本输出的token来说,损失为cross-entropy loss,对于视觉token来说,损失为。VL-GPT也用到了LLaVA、SVIT、InstructPixPix、Magicbrush和COCO Caption的数据进行指令微调。
更多的细节可以refer原文。
VILA
《VILA: On Pre-training for Visual Language Models》是NVIDIA和MIT提出的一个工作,文中对视觉语言模型预训练的有效机制进行了一些总结,并提出了一系列视觉语言的大模型VILA(Visual Language)。
- https://arxiv.org/abs/2312.07533
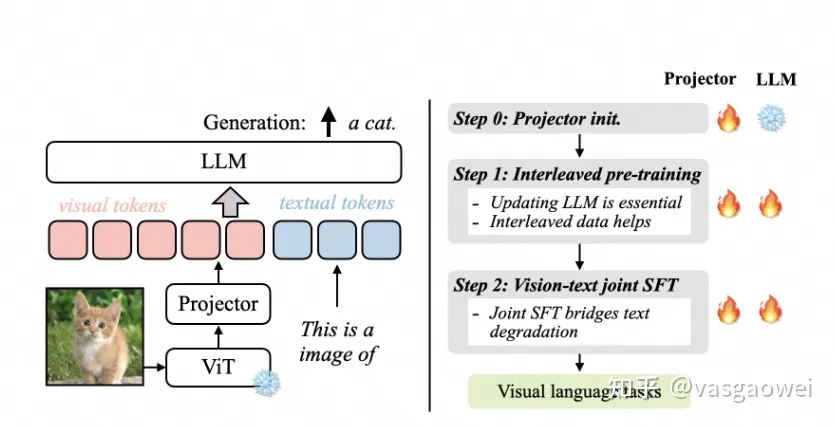
Fig 10
模型的结构如图Fig 10左图所示,和LLaVA系列差不多,模型的训练包含三个阶段,如图Fig 10所示。
-
LLM和ViT都是单独训练的,连接LLM和ViT的projector是随机初始化的,因此会首先对projector做训练。
-
这一个阶段对LLM和projector进行训练。
-
第二个阶段则是对预训练的模型进行视觉指令微调。
通过一系列的实验,文中得到了下面的三个结论:
-
LLM冻结与更新:在预训练过程中,冻结大型语言模型(LLM)可以实现不错的零样本(zero-shot)性能,但缺乏上下文学习能力(in-context learning capability)。为了获得更好的上下文学习能力,需要对LLM进行更新。实验表明,更新LLM有助于在更深层次上对齐视觉和文本的潜在嵌入,这对于继承LLM的上下文学习能力至关重要。
-
交错预训练数据:交错的视觉语言数据(如MMC4数据集)对于预训练是有益的,而仅使用图像-文本对(如COYO数据集)则不是最佳选择。交错数据结构有助于模型在保持文本能力的同时,学习与图像相关的信息。
-
文本数据重混合:在指令微调(instruction fine-tuning)阶段,将文本指令数据重新混合到图像-文本数据中,不仅能够修复LLM在文本任务的性能退化,还能提高视觉语言任务的准确性。这种数据混合策略有助于模型在保持文本能力的同时,提升对视觉语言任务的处理能力。
EMU2
《Generative Multimodal Models are In-Context Learners》是Emu的团队提出的另外一个工作,文中提出的多模态大语言模型Emu2对Emu进行了一些结构和训练策略上的改进。
-
Generative Multimodal Models are In-Context Learners(https://arxiv.org/abs/2312.13286)
-
https://github.com/baaivision/Emu
-
https://baaivision.github.io/emu2/
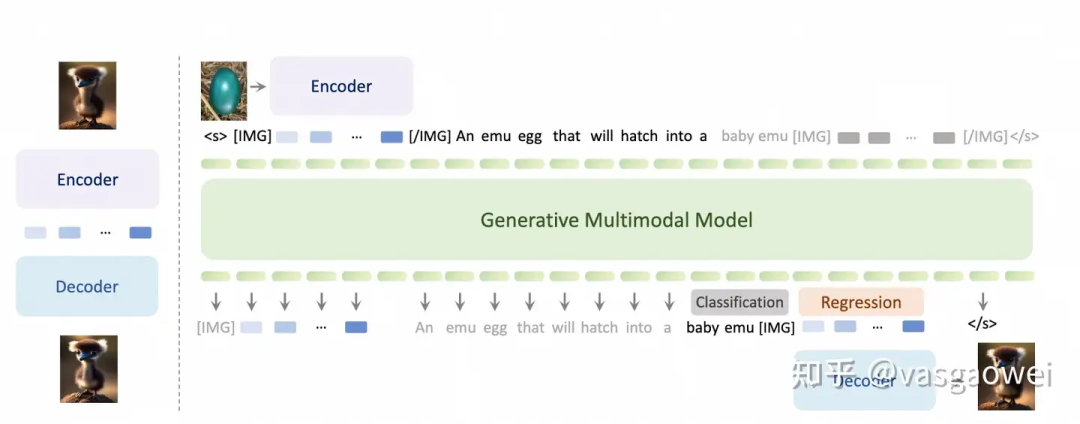
Fig 11
模型的结构如图Fig 11所示,包含三个部分:Visual Encoder、Multimodal LLM和Visual Decoder,文中分别用EVA-02-CLIP-E-plus、LLaMA-33B和SDXL对上述的三个模块进行参数初始化。和Emu相比,少了Casual Transformer,输入的图片通过mean pooling以及Visual Encoder提取图像特征之后,通过线性映射连接Visual Encoder和Multimodal LLM。
在预训练阶段,用到的训练数据包括image-text pair形式的数据(LAION-2B、CapsFusion-120M)、video-text pair形式的数据(WebVid-10M)、interleaved image-text形式的数据(Multimodal-C4 MMC4)、interleaved video-text形式的数据(YT-Storyboard-1B)、grounded image-text pair形式的数据(GRIT-20M、CapsFusoion-grounded-100M),同时为了保持模型的文本推理能力,还在只有文本数据的Pile上对模型进行了训练。图片都会通过visual encoder得到大小为的图像特征序列。
-
模型首先在image-text和video-text形式的数据上做了训练,损失函数只在text token上进行了计算。
-
接下来,固定住Visual Encoder的参数,对linear projection layer和Multimodal LLM的参数进行训练,包括文本的分类损失(这儿应该就是Cross Entropy)以及图像回归损失(针对图像特征的损失)。训练的时候,所有形式的数据都用来对模型进行了训练。
-
最后会对Visual Decoder进行训练,文中用SDXL-base对Visual Decoder的参数进行初始化,LLM输出的 大小为的图像特征序列会做为Decoder的条件,引导图片或者视频的生成。用到的训练数据包括LAION-COCO和LAION-Aesthetics,SDXL里面的Visual Encoder和VAE的参数都会固定不变,只有U-Net的参数会进行更新。
在指令微调阶段,用不同类型的数据,得到两个不同的指令微调模型,分别为Emu2-Chat和Emu2-Gen。Emu2-Chat可以基于多模态的输入得到对应的输出,Emu2-Gen则是接受文本、位置和图片的输入,生成符合输入条件的图片。
在训练Emu2-Chat的时候,用到了两种类型的数据,分别为academic-task-oriented 数据和multi-modal chat数据。academic-task-oriented数据包括image caption数据(比如COCO Caption和TextCaps)、visual question-answering数据(比如VQAv2、OKVQA、GQA、TextVQA)以及多模态分类数据(M3IT、RefCOCO、RecCOCO+和RefCOCOg),对应的system message为。multi-modal chat数据则是包括GPT辅助生成的数据(LLaVA和LLaVaR里面的数据)、来自于ShareGPT和Alpaca的语言指令数据和来自于VideoChat的视频指令数据,对应的system message为
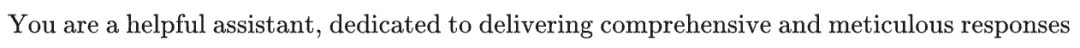
在训练Emu2-Gen的时候,用到的数据包括CapsFusion-grounded-100M、Kosmos-2提到的GRIT、InstructPix2Pix里面数据、CapsFusion、LAION-Asthetics、SA-1B和LAION-High-Resolution,文中还从其他付费渠道收集了数据(比如Unsplash、Midjourney-V5和DALL-E-3生成的图片等)。和其他多模态大模型不一样,物体的坐标不是以文本的形式或者ROI特征向量的方式送入LLM,而是直接在黑白图片上对应的坐标位置处绘制相应的框,得到的图片通过Visual Encoder提取特征。整个序列如下:A photo of
a man
image embedding of object localization image[IMG]image embedding of man[/IMG]sitting next toa dog
image embedding of object localization image[IMG]image embedding of dog[/IMG][IMG]image embedding of the whole image[/IMG]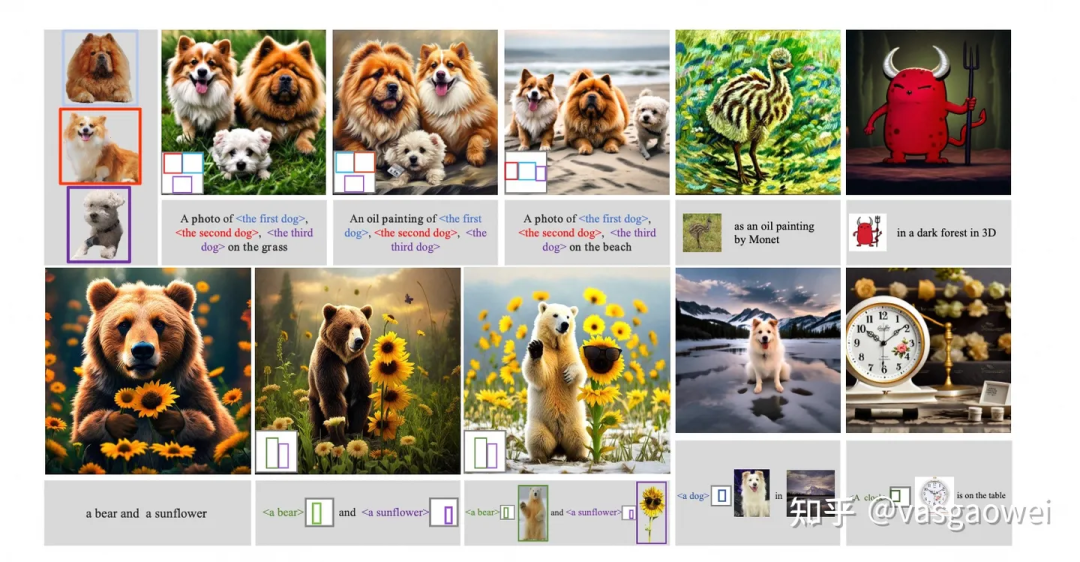
Fig 12
生成的一些示例图片如图Fig 12所示。
DeLVM
《Data-efficient Large Vision Models through Sequential Autoregression》是华为诺亚实验室的一个工作,是在LVM基础上提出的一个工作。
-
Data-efficient Large Vision Models through Sequential Autoregression(https://arxiv.org/abs/2402.04841)
-
https://github.com/ggjy/DeLVM
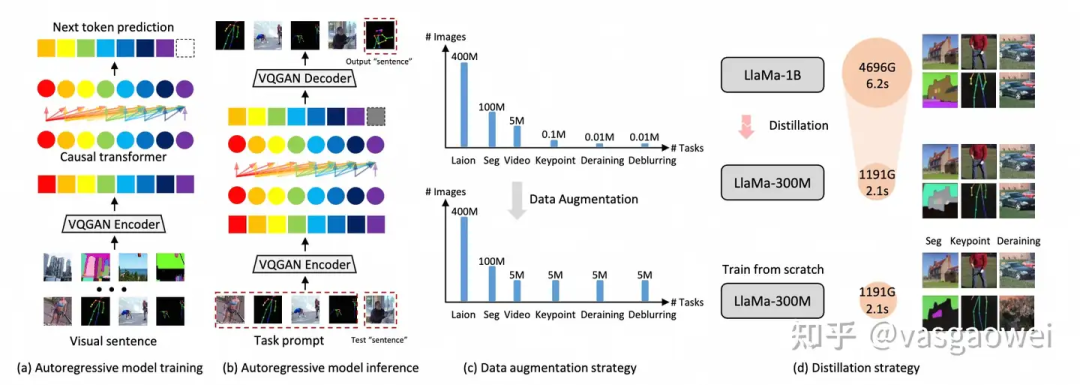
Fig 13
模型结构和LVM一直,如图Fig 13 a 所示,这篇文章主要在两个方面做了改进探索,比如数据增强和蒸馏。数据增强主要是对存在长尾分布的数据中数量较少的这一类型的数据做重复的采样,也提高这部分数据的数量。
AIM
《Scalable Pre-training of Large Autoregressive Image Models》是苹果提出的一个工作,也是通过自回归的方式训练视觉基础模型,也发现了和LVM类似的和数据、模型参数量有关的Scaling效果,不过实现方式和LVM还是存在不小的差异。
-
Scalable Pre-training of Large Autoregressive Image Models(https://arxiv.org/abs/2401.08541)
-
https://github.com/apple/ml-aim
Fig 14
模型预训练时候的结构如图Fig 14所示,输入图片划分为没有overlap且分辨率相同的patch ,并通过步长和kernel size大小相同的卷积层得到patch的特征,得到的图像特征序列通过Causal Transformer按照raster order预测下一个特征序列,得到特征向量通过一个MLP层得到对应的pixel。和LVM不一样,没有采用VQ-GAN里面的image tokenizer、detokenizer和codebook。
AIM在DFN数据集上进行了预训练,训练的损失函数为标准的预测下一个元素的自回归损失,即,在具体实现的时候则是损失,即输入的图片patch为,预测的图片patch为,损失和MAE一样,都是pixel级别的损失,即。文中也采用了和LVM类似的方式,用到了VQ-GAN类似的tokenizer,损失采用cross-entropy损失,但是效果不如pixel-wise的损失。
视觉基础模型按照自回归、causal attention的方式进行预训练,即,其中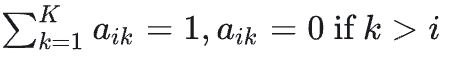
但是下游的任务一般是bidirectional attention,为了弥补这种差异性,文中把图像特征序列的前几个序列看作是prefix,这部分序列在transformer里面按照bidirectional attention提取特征,且不计算loss,prefix的序列长度为,这部分序列的attentiom只大于0,即。如图Fig 15所示。
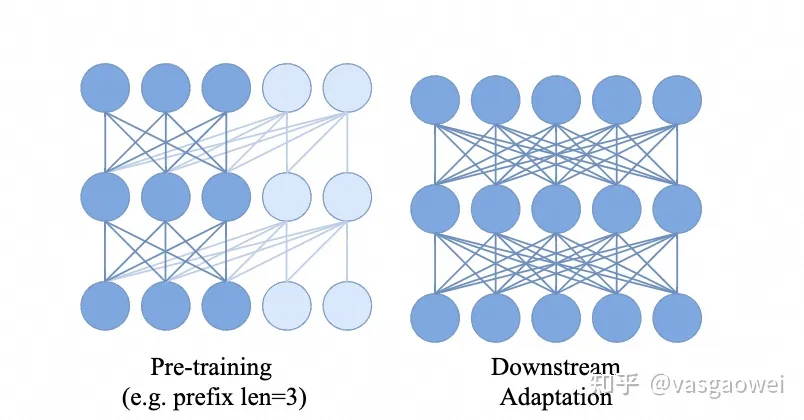
Fig 15
如图Fig 16,AIM观察到了和LVM一样的Scaling现象,即模型参数量越多,训练的时候损失下降越快,效果也更好。在图Fig 17中也可以看到,训练的数据量越大,在验证集上的损失下降就越低。
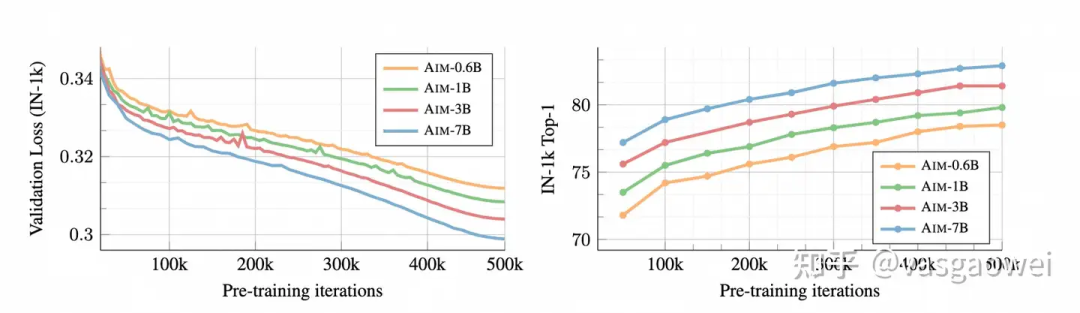
Fig 16
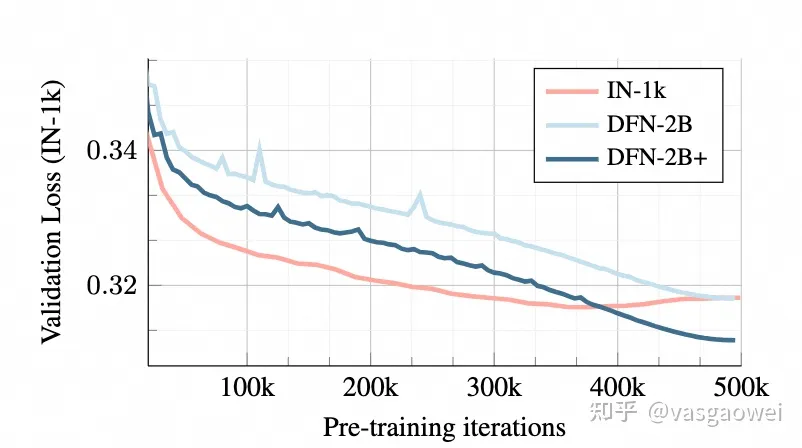
Fig 17
整体来说,是非常solid的一个工作,更多的细节可以refer原文。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
值得细读的8个视觉大模型生成式预训练方法
写在前面 大语言模型的进展催生出了ChatGPT这样的应用,让大家对“第四次工业革命”和“AGI”的来临有了一些期待,也作为部分原因共同造就了美股2023年的繁荣。LLM和视觉的结合也越来越多:比如把LLM作为一种通用的接口,把视觉特征…...

go 包相关知识
在Go语言中,包的引用和搜索路径是由环境变量GOPATH和GO111MODULE共同决定的。 GOPATH环境变量:这个变量定义了默认的工作目录,Go命令行工具将会在这个目录下查找包文件。这个目录通常包含三个子目录:src、bin和pkg。 src目录包含…...

机器学习:opencv--人脸检测以及微笑检测
目录 前言 一、人脸检测的原理 1.特征提取 2.分类器 二、代码实现 1.图片预处理 2.加载分类器 3.进行人脸识别 4.标注人脸及显示 三、微笑检测 前言 人脸检测是计算机视觉中的一个重要任务,旨在自动识别图像或视频中的人脸。它可以用于多种应用࿰…...
linux系统挂载硬盘
参考链接:https://www.cnblogs.com/wenhainan/p/12292823.html (1)lsblk命令查看磁盘挂载情况 (2)使用fdisk分区新磁盘 如果要分多个分区需指定每个分区的大小 (3)格式化新分区 mkfs命令格…...

MySQL实现主从同步
一、首先我们准备3台mysql 分别为: 主服务器:test-mysql-master,端口3306 从服务器:test-mysql-slave1,端口3307 从服务器:test-mysql-slave2,端口3308 注意:如果防火墙是开着的记得把关掉,并且重启docker…...

人工智能--数学基础
目录 编辑2.1 线性代数基础 2.2 微积分及优化理论 2.3 概率论与统计学 2.4 信息论简介 2.1 线性代数基础 线性代数是处理向量空间(包括有限维或无限维)以及这些空间上的线性映射的一门数学分支。在线性代数中,最核心的概念包括向量、矩…...

2024人工智能技术的普及 如何看待AI技术的应用前景
AI 技术的应用前景十分广阔,但也面临着一些挑战,以下是对其应用前景的一些看法: 积极方面: 多行业深度融合与效率提升5: 医疗领域:AI 在医疗影像分析、辅助诊断、疾病预测等方面具有巨大潜力。例如…...
日常记录:springboot 2.2.5 + es 6.8.12
前言 最近有用到搜索引擎的功能,这不得把之前的es过程实践一遍,但发现过程坎坷,因为版本太低了。 一、安装es 6.8.12 安装过程跟之前写那章日常记录:elasticsearch 在linux安装_elasticsearch linux安装-CSDN博客一样࿰…...

MySQL数据库备份与恢复详解
文章目录 一、为什么需要备份数据库?二、MySQL数据库的备份方式1. 逻辑备份2. 物理备份3. 二进制日志备份 三、恢复数据库1. 使用mysqldump备份文件恢复2. 使用物理备份恢复3. 使用二进制日志恢复 四、备份与恢复的最佳实践五、结语 在日常的数据库运维中࿰…...

10.22 MySQL
存储过程 存储函数 存储函数是有返回值的存储过程,存储函数的参数只能是in类型的。具体语法如下: characteristic 特性 练习: 从1到n的累加 create function fun1(n int) returns int deterministic begindeclare total i…...

「AIGC」n8n AI Agent开源的工作流自动化工具
n8n AI Agent 是一个利用大型语言模型(LLMs)来设计和构建智能体(agents)的工具,这些智能体能够执行一系列复杂的任务,如理解指令、模仿类人推理,以及从用户命令中理解隐含意图。n8n AI Agent 的核心在于构建一系列提示(prompts),使 LLM 能够模拟自主行为。 传送门→ …...

Android 中获取和读取短信验证码
方法一:通过 SMS Retriever API SMS Retriever API 是 Google 提供的一种安全的方式,可以从系统中获取不需要权限的短信验证码。这种方式不需要请求 READ_SMS 权限,非常适合处理短信验证码的情况。 1. 在 build.gradle 中添加依赖 dependen…...
SQL语句高级查询(适用于新手)
SQL查询语句的下载脚本链接!!! 【免费】SQL练习资源-具体练习操作可以查看我发布的文章资源-CSDN文库https://download.csdn.net/download/Z0412_J0103/89908378 本文旨在为那些编程基础相对薄弱的朋友们提供一份详尽的指南,特别聚…...

main.ts中引入App.vue报错,提示“Cannot find module ‘./App.vue’ or its corresponding type
原因 代码编辑器:vscode ,使用vue3,所以安装了 Volar 插件,可以使 vue 代码高亮显示,不同颜色区分代码块,以及语法错误提示等 提示:如果使用的是vue2,则使用 Vetur 插件࿱…...

Android15音频进阶之组音量调试(九十)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【原创干货持续更新中……】🚀 优质视频课程:AAOS车载系统+…...

【Java】常用方法合集
以 DemoVo 为实体 import lombok.Data; import com.alibaba.excel.annotation.ExcelProperty; import com.alibaba.excel.annotation.ExcelIgnoreUnannotated;Data ExcelIgnoreUnannotated public class ExportPromoteUnitResult {private String id;ExcelProperty(value &qu…...

深入了解Vue Router:基本用法、重定向、动态路由与路由守卫的性能优化
文章目录 1. 引言2. Vue Router的基本用法2.1 基本配置 3. 重定向和命名路由的使用3.1 重定向3.2 命名路由 4. 在Vue Router中如何处理动态路由4.1 动态路由的概念4.2 如何处理动态路由4.3 动态路由的懒加载 5. 路由守卫的实现与性能影响5.1 什么是路由守卫?5.2 路由…...

深入理解InnoDB底层原理:从数据结构到逻辑架构
💡 无论你是刚刚踏入编程世界的新人,还是希望进一步提升自己的资深开发者,在这里都能找到适合你的内容。我们共同探讨技术难题,一起进步,携手度过互联网行业的每一个挑战。 📣 如果你觉得我的文章对你有帮助,请不要吝啬你的点赞👍分享💕和评论哦! 让我们一起打造…...

Linux介绍及操作命令
Linux 是一种开源的操作系统,具有以下特点和优势: 一、稳定性和可靠性 内核稳定 Linux 内核经过多年的发展和优化,具有高度的稳定性。它能够长时间运行而不出现崩溃或故障,适用于服务器和关键任务应用。内核的稳定性得益于其严格的开发流程和质量控制,以及全球开发者社区…...

JS | 详解图片懒加载的6种实现方案
一、什么是懒加载? 懒加载是一种对网页性能优化的方式,比如,当访问一个网页的时候,优先显示可视区域的图片而不是一次加载全部的图片,当需要显示时,再发送请求加载图片。 懒加载 :延迟加载&…...

收藏!2026大厂AI招聘火爆:日薪5000抢博士,普通岗简历石沉大海?小白程序员必看生存指南
2026年大厂招聘季AI岗位需求暴涨215%,字节日薪5000抢清北博士,阿里AI岗占offer六成。AI核心岗位年薪可达百万,供需比仅0.15。非AI岗位受冲击,但AIGC产品经理、AI运营等潜力岗位升温。求职者需注重顶会论文、开源贡献等加分项&…...

【NotebookLM播客化实战指南】:3步将静态文档转化为高转化率AI播客,92%用户留存提升实测数据曝光
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文档播客化功能详解 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 增强理解与交互的实验性工具,其“文档播客化”(Document Podcasting)功能允许用…...

告别调试助手:在Linux终端用minicom高效收发AT指令
1. 为什么选择minicom替代图形化串口工具 作为一名在嵌入式领域摸爬滚打多年的开发者,我经历过各种串口调试工具的折磨。从早期的Windows超级终端到现在的各种图形化串口助手,最终发现Linux下的minicom才是真正的高效利器。你可能要问:为什么…...

3步搞定微信聊天记录导出:Mac用户必备的数据备份指南
3步搞定微信聊天记录导出:Mac用户必备的数据备份指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录因为手机丢失或系统升级而…...

Apache Arrow图像数据处理终极指南:如何构建高性能计算机视觉应用
Apache Arrow图像数据处理终极指南:如何构建高性能计算机视觉应用 【免费下载链接】arrow Apache Arrow is a multi-language toolbox for accelerated data interchange and in-memory processing 项目地址: https://gitcode.com/gh_mirrors/arrow13/arrow …...

先进制程EPE挑战:从系统误差到量测革命,如何驯服边缘位置误差
1. 从“理所当然”到“如履薄冰”:边缘位置误差如何成为先进制程的“隐形杀手”在半导体行业过去的黄金岁月里,工程师们有一个近乎奢侈的“共识”:芯片内部那些由光刻、刻蚀定义的特征边缘,可以被理所当然地看作是笔直且在不同工艺…...

Fillinger智能填充插件:如何用3分钟完成1小时的设计工作?
Fillinger智能填充插件:如何用3分钟完成1小时的设计工作? 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中繁琐的图案填充而头疼吗…...

PyCharm专业版SSH远程开发环境一站式部署指南
1. PyCharm专业版安装与激活 作为数据科学和算法开发的主力工具,PyCharm专业版提供了完整的远程开发支持。首先需要从JetBrains官网下载对应操作系统的安装包。这里有个小技巧:如果你使用的是Windows系统但需要连接Linux服务器开发,建议选择W…...

长期使用Taotoken Token Plan套餐在项目开发中的成本控制体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐在项目开发中的成本控制体会 在中长期AI项目的开发实践中,成本的可预测性与可控性是团…...

收藏!小白也能入行:AI训练师是什么?值不值?怎么学?
AI冲击重复性岗位,但AI训练师需求激增347%。本文解读AI训练师(非程序员)的工作内容(数据标注、Prompt设计等)、市场数据(薪资60k、缺口百万)、适合人群(内容创作者、白领、应届生&am…...