数据结构中的堆(Heap)
堆(Heap)是计算机科学中一类特殊的数据结构,在计算机科学领域中扮演着至关重要的角色。以下是对堆的深入了解,包括其定义、特性、类型、底层实现原理以及广泛的应用场景。
一、堆的定义与特性
堆通常被看作是一棵完全二叉树的数组对象,它总是满足以下性质:
- 堆性质:堆中某个结点的值总是不大于或不小于其父结点的值。具体来说,在最大堆(Max Heap)中,父节点的值大于或等于任何一个子节点的值;而在最小堆(Min Heap)中,父节点的值小于或等于任何一个子节点的值。这一性质确保了堆的根节点始终是最大值(最大堆)或最小值(最小堆)。
- 完全二叉树:除了最底层外,其他每一层的节点都被填满,且最底层从左到右填充。这种结构使得堆在物理上可以通过数组高效地实现,而无需使用复杂的指针结构。
二、堆的类型
根据堆性质的不同,堆可以分为最大堆和最小堆两种类型:
- 最大堆:在最大堆中,父节点的值总是大于或等于其子节点的值。因此,最大堆的根节点始终是堆中的最大值。最大堆常用于实现优先队列,以便快速获取最高优先级的元素。
- 最小堆:在最小堆中,父节点的值总是小于或等于其子节点的值。因此,最小堆的根节点始终是堆中的最小值。最小堆同样可以用于实现优先队列,但此时是获取最低优先级的元素。
三、堆的底层实现原理
堆的底层实现通常依赖于数组,利用数组索引关系来表示堆的结构。对于父节点索引为i的节点,其左子节点的索引为2i+1,右子节点的索引为2i+2。同样地,对于子节点索引为j的节点,其父节点的索引为(j-1)/2。这种索引关系使得在数组中操作堆结构变得非常简单和高效。
在堆的实现中,有两个关键的操作:上浮(shiftUp)和下沉(shiftDown,也称为堆化heapify)。
- 上浮操作:当一个节点的值大于(最大堆)或小于(最小堆)其父节点的值时,需要执行上浮操作。该操作将节点与其父节点交换位置,并继续向上比较和交换,直到节点满足堆性质或到达根节点。
- 下沉操作:当一个节点的值小于(最大堆)或大于(最小堆)其子节点的值时,需要执行下沉操作。该操作将节点与其较大的子节点(最大堆)或较小的子节点(最小堆)交换位置,并继续向下比较和交换,直到节点满足堆性质或到达叶子节点。
四、堆的应用场景
堆在计算机科学中有着广泛的应用,以下是一些主要的应用场景:
-
优先队列:
- 堆是实现优先队列最常用的数据结构之一。优先队列是一种特殊的队列,其中的元素按照优先级进行排序。在最大堆实现的优先队列中,最高优先级的元素(即最大值)总是位于队首;而在最小堆实现的优先队列中,最低优先级的元素(即最小值)总是位于队首。这使得优先队列能够快速获取和删除具有最高或最低优先级的元素。
- 优先队列在多种算法和系统中都有重要应用,如Dijkstra算法中的最短路径求解、Prim算法中的最小生成树求解、任务调度中的高优先级任务优先执行等。
-
堆排序:
- 堆排序是一种高效的排序算法,它利用堆的性质进行排序。堆排序算法包括两个主要步骤:建堆和排序。在建堆步骤中,将待排序的序列调整成一个堆(最大堆或最小堆);在排序步骤中,反复执行删除堆顶元素(即最大值或最小值)和将堆的最后一个元素移动到堆顶并重新调整堆的操作,直到堆为空。由于堆排序的时间复杂度为O(nlogn),且不需要额外的存储空间(原地排序),因此在实际应用中非常受欢迎。
-
内存管理:
- 在操作系统中,堆可以用于内存管理,特别是用于实现动态内存分配和垃圾回收等功能。通过维护一个堆结构来管理内存块,可以高效地分配和回收内存资源。此外,堆还可以用于实现内存池等高级内存管理策略,以提高内存使用的效率和性能。
-
图算法:
- 在图算法中,堆可以用于实现一些重要的算法,如Dijkstra算法和Prim算法。这些算法利用堆来快速找到最短路径或最小生成树等关键信息。具体来说,Dijkstra算法利用最小堆来不断选择当前未访问节点中距离源点最近的节点进行扩展;而Prim算法则利用最小堆来选择当前未包含在生成树中的权重最小的边进行扩展。这些算法在图论和计算机科学领域中有着广泛的应用。
-
数据压缩与编码:
- 在数据压缩和编码领域,堆可以用于实现一些高效的算法,如霍夫曼编码(Huffman Coding)等。霍夫曼编码是一种基于频率的变长编码方法,它利用堆结构来动态地构建最优前缀码树(即霍夫曼树),从而实现数据的高效压缩。通过维护一个堆来存储当前节点的频率和指针等信息,可以快速地构建霍夫曼树并生成编码表。
-
数据流处理:
- 在数据流处理领域,堆可以用于实现一些实时算法和在线算法。例如,在实时系统中处理数据流时,可以利用堆来快速找到数据流中的最大值或最小值等信息。此外,堆还可以用于实现滑动窗口算法等在线算法,以高效地处理数据流中的动态变化信息。
-
游戏开发:
- 在游戏开发中,堆可以用于实现一些重要的游戏逻辑和算法。例如,在路径规划算法中,可以利用堆来快速找到从起点到终点的最短路径;在A*算法等启发式搜索算法中,也可以利用堆来高效地管理候选节点和路径等信息。此外,堆还可以用于实现游戏中的排行榜和得分记录等功能。
五、总结
综上所述,堆是一种非常重要的数据结构,在计算机科学领域中有着广泛的应用。通过理解堆的定义、特性、类型以及底层实现原理,我们可以更好地应用堆来解决各种实际问题。同时,了解堆在不同领域中的具体应用案例也有助于我们更深入地理解堆的重要性和实用性。无论是在算法设计、系统优化还是数据分析等领域中,堆都发挥着不可替代的作用。
相关文章:
)
数据结构中的堆(Heap)
堆(Heap)是计算机科学中一类特殊的数据结构,在计算机科学领域中扮演着至关重要的角色。以下是对堆的深入了解,包括其定义、特性、类型、底层实现原理以及广泛的应用场景。 一、堆的定义与特性 堆通常被看作是一棵完全二叉树的数…...

Linux误删文件找回
前言 公司要迁移文件服务器,100G文件夹执行了mv操作,由于网络都懂Shell卡死导致命令执行中途停止了。一看目标文件夹才10G的内容,赶紧去源文件夹查看~~~不料空空如也 完蛋,咋整,出事了,有备份吗?…...

深入计算机语言之C++:类与对象(中)
🔑🔑博客主页:阿客不是客 🍓🍓系列专栏:从C语言到C语言的渐深学习 欢迎来到泊舟小课堂 😘博客制作不易欢迎各位👍点赞⭐收藏➕关注 一、默认成员函数 如果一个类中什么成员都没有&…...

51单片机快速入门之 IIC I2C通信
51单片机快速入门之 IIC 总线通信 协议: 空闲时 SCL/SDA 为高电平SCL高时 SDA下降沿 为开始信号开始信号之后: SCL高电平时 SDA不能变化 , SCL低电平时 SDA才可变 SDA 传数据时 从高到低按位传输 SCL一个脉冲高电平对应一位数据 4.SCL高电平时 SDA上升沿 为停止信号 数…...

腾讯推出ima.copilot智能工作台产品 由混元大模型提供技术支持
腾讯公司近期推出了一款名为ima.copilot(简称ima)的智能工作台产品,它由腾讯混元大模型提供技术支持。这款产品旨在通过其会思考的知识库,为用户开启搜读写的新体验。ima.copilot的核心功能包括知识获取、打造专属知识库以及智能写…...

1024是什么日子
【1024程序员日数字编织梦想的赞歌】 在这个由二进制构建的宇宙里,每一行代码都是通往未来的桥梁,每一位程序员都是这浩瀚数字海洋中的航海家。今天,10月24日,不仅是一个简单的日期,它是属于我们的节日——程序员日&a…...

驱动开发系列20 - Linux Graphics Xorg-server 介绍
一: 概述 X.Org Server 是由 X.Org 基金会管理的 X Window System (X11) 显示服务器的自由开源实现。客户端 X Window System 协议的实现以 X11 库的形式存在,这些库作为与 X 服务器通信的有用 API。有两个主要的 X11 库。第一个库是 Xlib,它是最初的 C 语言 X11 API;…...

晶台推出SOP5封装的高速光耦KLM45X,提供1MBit/s超快速率
KLM452 和 KLM453 器件均由一个红外发射二极管与一个高速光电检测晶体管组成,两者之间光学耦合。光电二极管偏置和输出晶体管集电极的独立连接可以通过减少输入晶体管的基极-集电极电容来使速度比传统的光电晶体管耦合器提高几个数量级。它们采用行业内标准的 5 引脚…...

软物质流变探究:从宏观微观差异,到水凝胶界面特性
大家好!今天我们要探讨的是一篇关于纳米级界面水凝胶粘弹性的研究论文——《Nanoscopic Interfacial Hydrogel Viscoelasticity Revealed from Comparison of Macroscopic and Microscopic Rheology》发表于《Nano Letters》,该研究通过比较宏观和微观流…...

Axure中继器单选、多选和重置
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:Axure中继器单选、多选和重置 主要内容:根据查询条件,通过单选、多选和重置,从中继器中得到数据 应用场景&…...

微软公司用没有使用证据的商标申请驰名商标,该怎么维权?
收集证据:首先需要收集微软公司商标使用的证据,包括但不限于销售记录、广告宣传材料、市场调查报告等,以证明商标的实际使用情况和知名度。如果微软公司的商标确实没有在市场上使用,或者使用证据不足以证明其商标的知名度…...

学习分布式系统我来助你!【基本知识、基础理论、设计模式、应用场景、工程应用、缓存等全包含!】
基本知识 什么是分布式 分布式系统是一种通过网络连接多个独立计算机节点,共同协作完成任务的系统架构,具有高度的可扩展性、容错性和并发处理能力,广泛应用于大数据处理、云计算、分布式数据库等领域。 通俗来讲:分布式系统就…...

ubuntu查看系统版本命令
查看系统版本指令 在 Ubuntu 操作系统中,您可以使用多个命令来查看系统版本。以下是一些常用的命令: lsb_release -a 这个命令会显示详细的 Ubuntu 版本信息,包括发行版名称、版本号、代号等。lsb_release -acat /etc/os-release 这个命令会显…...
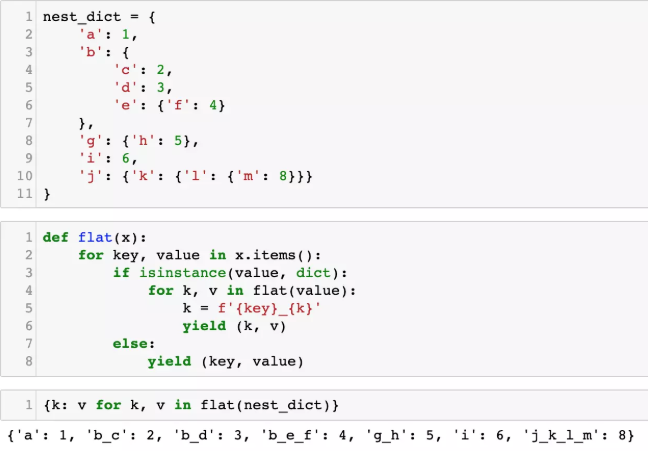
使用yield压平嵌套字典有多简单?
我们经常遇到各种字典套字典的数据,例如: nest_dict {a: 1,b: {c: 2,d: 3,e: {f: 4}},g: {h: 5},i: 6,j: {k: {l: {m: 8}}} } 有没有什么简单的办法,把它压扁,变成: {a: 1,b_c: 2,b_d: 3,b_e_f: 4,g_h: 5,i: 6,j_k_l_…...

express中使用morgan打印请求数据日志文件,按日期分割
使用morgan可以打印日志,但是要分割日志文件就需要使用file-stream-rotator,下面介绍使用方法: 1.安装2个依赖 npm i morgan file-stream-rotator 2.在入口文件app.js中引入相关插件 var express require("express"); var fs require("fs"); var pat…...
干货 | 2024 AI+智慧城市安全解决方案白皮书(免费下载)
导读:新型智慧城市是推动城市治理体系和治理能力现代化、提升城市居民幸 福感和满意度的新理念和新路径,也是网络强国建设和数字经济发展的重要载体。随着 AI 技术的不断发展和在智慧城市智领域广泛的应用,人们享受技 术红利的同时࿰…...

超越 React Query:探索更高效的数据请求策略
我们常常遇到组件间通信的难题。你是否也曾为如何优雅地在组件间传递信息而头疼?今天,我想和大家分享一个让我眼前一亮的解决方案——使用 alova。 跨组件触发请求的挑战 如果你正在构建一个电商应用,用户在更新了购物车后,需要…...

Scala trait
一.trait 基本使用 idea实例 二.实现单个特质 三.实现多个特质 idea实例 四.特质成员的处理方式...

AI大法之C语言哈希表算法比较两个文件去重
最近朋友在工作上遇到了一个问题,经常需要比对两个文件,筛选出文件中不同的订单号。比如有两个文件:计费.txt 和 受理.txt,文件中每一行都是一个订单号,需要找出计费.txt文件中有而受理.txt文件中没有的单号和计费.txt…...
)
Scala 提取器(Extractor)
Scala 提取器(Extractor) Scala 提取器(Extractor)是一个非常有用的特性,它允许你为任何类型定义自定义的解构赋值语法。在Scala中,提取器是一种用于从对象中提取值的工具,它可以帮助你以一种更直观和声明式的方式处理数据。本文将详细介绍Scala提取器的工作原理、使用场景…...

pytest Code Review skill.md
Skills 架构设计 本文深入探讨 Agent Skills 的技术架构和设计理念,帮助你理解 Skills 如何高效地扩展 Claude 的能力。 核心设计理念 Agent Skills 采用**渐进式披露(Progressive Disclosure)**架构,这是一种现代软件工程中的…...

Unity军事资源包的战术语义架构与实战集成指南
1. 这个资源包不是“拿来就能用”的万能钥匙,而是需要你亲手校准的战术装备“POLYGON Military”——光看名字,很多人第一反应是:Unity Asset Store上那个标着“POLYGON”风格、封面全是迷彩涂装M4和悍马车的军事资源包。它确实存在ÿ…...

免费在线去水印软件怎样选择?2026 优缺点对比及推荐指南
随着内容创作和素材收集的日常化,去水印的需求越来越普遍。一张素材上的水印、一段视频中的平台标志,都可能影响二次创作或个人使用的体验。市面上的去水印方案从专业软件到在线工具五花八门,选择合适的工具需要了解各自的特点和适用场景。本…...

第九届蓝桥杯国赛b组--备战国赛版h
第一题:0换零钞 - 蓝桥云课 模拟 #include <bits/stdc.h> using namespace std; int main() {int a,b,c0;for(a1;a<200;a)//一元钞票{for(b1;b<100;b)//两元钞票{for(c1;c<40;c)//五元钞票{if(ba*10&&(ab*2c*5)200){cout<<abc<&l…...

2026年HR推荐的10个专业简历模板网站,从模板到写法
2026年HR推荐的10个专业简历模板网站,从模板到写法写一份让HR眼前一亮的简历,是很多求职者遇到的难题。模板选什么风格、内容怎么写才专业、怎么排版才不会被系统筛掉——这些问题常常让人头疼。这篇文章整理了10个HR推荐的专业简历模板网站,…...
)
MT7628串口透传实战:手把手教你用ser2net把串口数据转发到TCP(含OpenWrt固件编译)
MT7628串口透传实战:从零构建网络化串口通信系统 在物联网和嵌入式开发领域,串口通信是最基础也是最常用的数据传输方式之一。MT7628作为一款广泛应用于路由器、智能家居设备的SoC芯片,其串口功能常被用于设备调试、传感器数据采集等场景。但…...
)
Midjourney盐印相风格实战手册(附12组可复用Prompt模板+SDXL交叉验证数据)
更多请点击: https://kaifayun.com 第一章:Midjourney盐印相风格的视觉溯源与美学内核 盐印相(Salted Paper Print)是19世纪早期摄影术诞生之初的核心工艺,由亨利福克斯塔尔博特于1839年系统完善。其本质是将纸基浸入…...

工业三防灯干货科普:核心参数、选型逻辑及应用场景全解析
在工业照明领域,三防灯是适配恶劣环境的核心照明设备,广泛应用于车间、仓库、隧道、冷链、食品加工等多场景。不同于民用照明灯具,工业级三防灯需具备防尘、防水、防腐蚀的核心能力,其性能直接决定照明稳定性、使用寿命及后期运维…...

Taotoken API Key的权限管理与审计日志功能初探
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key的权限管理与审计日志功能初探 对于将大模型能力集成到业务流程中的团队而言,API Key的安全管理与操作…...
)
编译原理|FIRST、FOLLOW、SELECT集超详细解读(含例题)
编译原理|FIRST、FOLLOW、SELECT集超详细解读(含例题)在编译原理的自顶向下语法分析中,FIRST、FOLLOW、SELECT三个集合是核心基石——它们是构造LL(1)分析表、判断文法是否为LL(1)文法的关键。很多同学刚开始接触时会被抽象的定义…...