合成数据用于大模型训练的3点理解
最近看国内对合成数据的研究讨论也变得多 ,而不单单是多模态,扩散模型这些偏视觉类的, 因此就合成数据写一下目前的情况。
2023年国外就有很多研究合成数据的论文, 包括Self-Consuming Generative Models Go MAD, Crowd Workers Widely Use Large Language Models for Text Production Tasks
前者表明即使使用合成数据训练, 这个合成数据也一定要有新的数据, 如果没有, LLM的多样性,质量会随着合成数据训练得越来越多而受到损害, MAD即model autophagy disorder, 出现类似生物学中自噬机制。
“
熟悉信息论的听众应该了解,单纯的合成数据并不能提供任何新的信息量,除非有新的 input,那么这种新的 input 是什么呢?就可能是专家对合成数据进行的检验和校正。因此,我认为利用合成数据是一个可行的方向,但单纯依靠合成数据是难以取得突破的
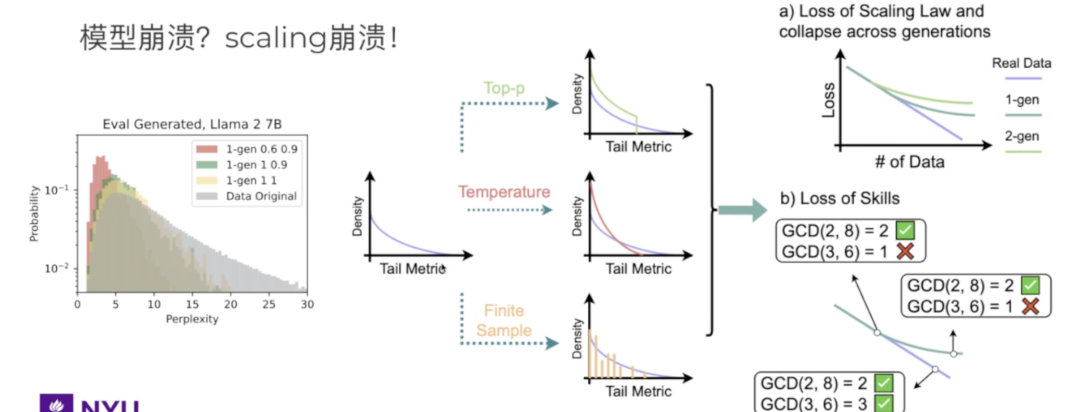
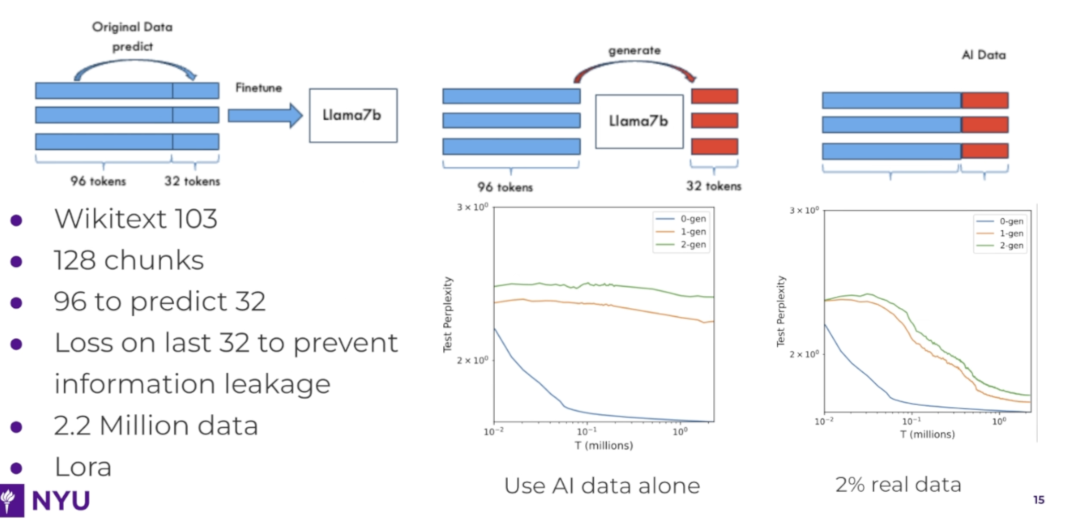
0-gen(蓝线)困惑度test perplexity最低,模型的预测表现最好,因为它使用了原始的真实数据进行训练。1-gen和2-gen曲线(橙线和绿线)表现较差,困惑度较高,说明当模型大量依赖自己生成的数据时,性能会逐渐下降。这是因为生成的数据可能引入噪声或偏差,降低了模型的学习效果
后者则表面在2023年, ChatGPT 3.5出来后, 出于节省成本提高效率, 越来越多做数据标注的外包员工开始用LLM做标注, 据论文统计, 约33%–46%的外包员工在用LLM生成数据标注, 做数据清洗, 导致交给下游客户的数据已经夹杂了LLM自己生成的合成数据
背景tip: 2010年以前的论文研究验证都用小数据, 2010年之后开始逐渐使用几百万,几千万的大数据去验证, 训练。这是这几十年研究方向的一个重大调整。
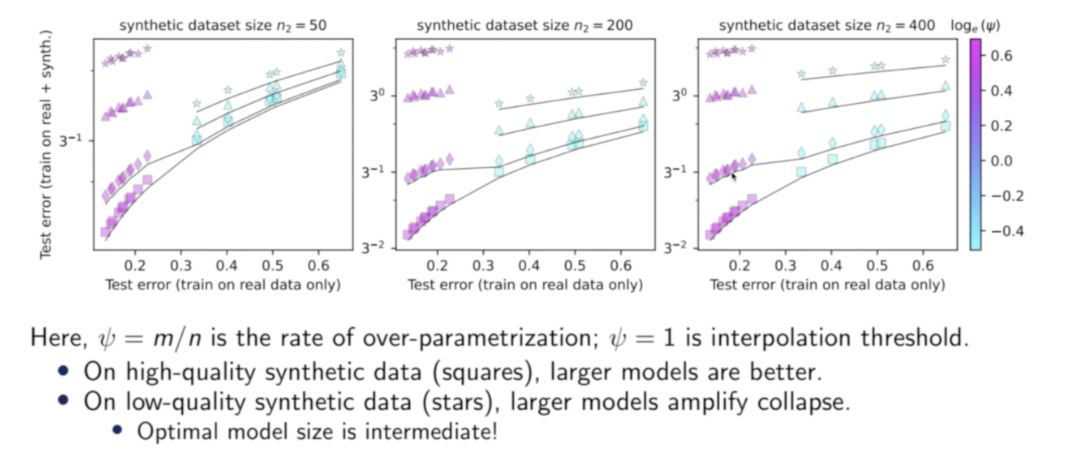
对于较高质量的合成数据(方形和菱形),使用较大的模型(即更大的ψ)的确是最佳实践;但如果数据质量较低,模型并不是越大越好,最佳权衡反而处于中等大小, LLM参数越大用低质量合成数据训练时就越容易崩溃
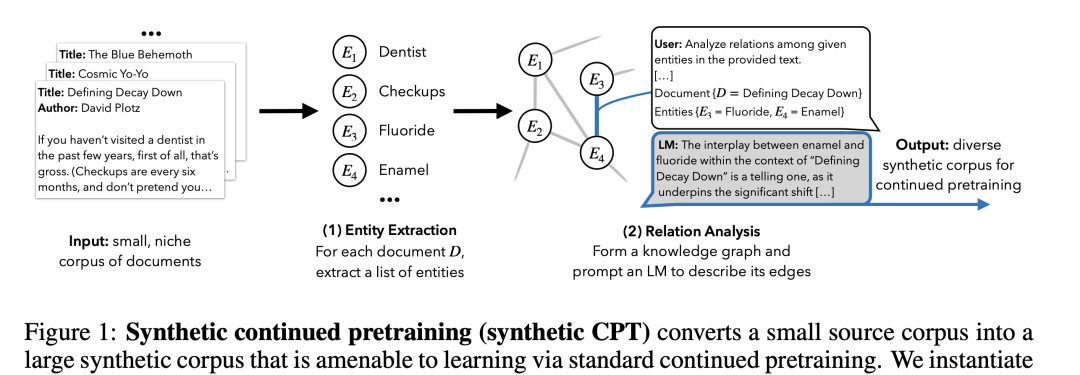
近1、2月新发表的合成数据论文包括synthetic continued pretraining和HuggingFace的SmolLM360M
大规模预训练模型已经非常擅长处理日常常识和普遍知识,但为了进一步提高模型的能力,它们需要专注于学习那些只出现一两次稀有、专业化和复杂的知识,因为这些知识没有被大规模预训练模型充分学习到。synthetic continued pretraining就设计了一个EntiGraph模型, 把真实的原有数据通过知识图谱理解实体关系, 合成新的不同场景的数据, 让LLM能对这个知识点学习得更深入。给我的感觉, 像是为那些晦涩的知识提供相应练习题, 让LLM把知识学得更透。

但生成的这个过程有个问题是LLM生成的合成数据不一定有那么大的多样性, 很可能是同质化地重复。而且领域适合真实数据比较少的领域。按huggingface研究团队的人来说,“合成数据目前只在特定领域有用,网络是如此之大和多样化,真实数据的潜力还没完全发挥。”
根据真实数据, 怎么生成高质量又多样的合成数据, 也是一个需要考虑的点。prompt的不同要求,运动多个不同性能的LLM来生成, LLM as judge的进一步筛选…
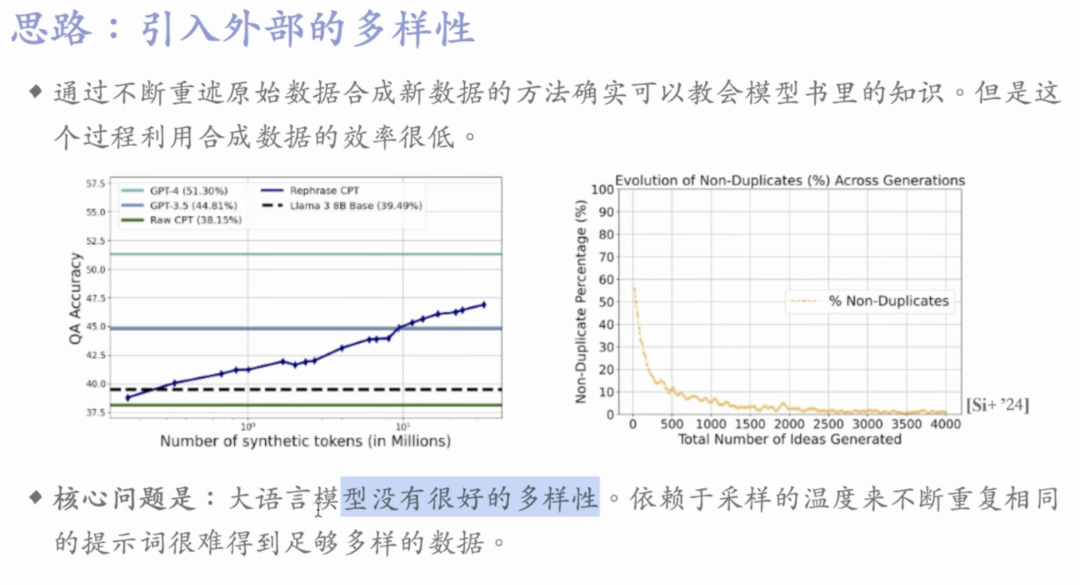
synthetic continued pretraining论文结果表明在RAG加上经过专业知识的合成数据微调后的模型的生成质量优于RAG和普通模型, 在谷歌Long-Context LLMs Meet RAG:长文本,Retriever, RAG FT对检索准确性的影响也有实验证明
SmolLM360M除了用大模型从头生成合成数据,也用大模型筛选过滤网络数据,只提取整理最真实最相关的信息。具体来说是使用Llama3-70B-Struct 生成的标注开发了一个分类器,仅保留FineWeb数据集中最具教育意义的网页
基于Cosmo-Corpus构建, 涵盖了Cosmopedia v2(由Mixtral生成的280亿个token的合成教科书和故事)、Python-Edu(来自The Stack的40亿个token的教育性Python样本)以及FineWeb-Edu(来自FineWeb的220亿个token的去重教育性网页样本)。这些数据均由 Mixtral-8x7B-Instruct-v0.1 模型生成。绝大部分数据是通过这种方式生成的: 搜集网页内容 (称为“种子样本”),提供内容所属的主题类别,然后让模型扩写来生成
研究成功除了比较新颖的用LLM作为过滤器, 发现即使是小模型也要在大量数据上训练, 且训练时间要够长。此外数据退火(Anneal the data)也被证明是有效的,也就是在训练的最后一部分保留一组特殊的高质量数据
也发现一个问题: 过去的对齐和微调技术,如SFT、DPO、PPO等都是针对大模型非常有效,但对小模型效果并不理想。
总结下来, 我目前理解的合成数据的要点有:
①合成数据也要新的内容来里面。不然随着合成数据1代, 2代, 还是重复的知识,容易出现过拟合的情况, LLM的性能也会下降, 且模型参数越大,越容易过拟合。而这种新的内容最欠缺的是我们人类思考的过程, 人类倾向于抽象的结果, 容易把思考的过程, 那些草稿纸素材扔掉, 只保留结果。而那些草稿纸的过程数据对大模型训练来说是很珍贵的数据, 能够让它更能学会分布思考。
②合成数据适合于特定的领域, 在大多数领域 ,真实数据都还没有充分利用好。有真实数据肯定优先利用真实数据
③合成数据的质量,多样性受prompt, 合成数据的LLM本身训练数据, 人工验证补充等影响, 这方面目前的研究我还了解得比较少。相比怎么优化RAG的检索质量, 怎么优化合成数据的生成质量不怎么是我的关注话题, 也对生产应用没有那么直接的影响。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
合成数据用于大模型训练的3点理解
最近看国内对合成数据的研究讨论也变得多 ,而不单单是多模态,扩散模型这些偏视觉类的, 因此就合成数据写一下目前的情况。 2023年国外就有很多研究合成数据的论文, 包括Self-Consuming Generative Models Go MAD, Crowd Workers Widely Use Large Language Models for Text Pr…...

Safari 中 filter: blur() 高斯模糊引发的性能问题及解决方案
目录 引言问题背景:filter: blur() 引发的问题产生问题的原因分析解决方案:开启硬件加速实际应用示例性能优化建议常见的调试工具与分析方法 引言 在前端开发中,CSS滤镜(如filter: blur())的广泛使用为页面带来了各种…...
浏览器实时更新esp32-c3 Supermini http server 数据
一利用此程序的思路就可以用浏览器显示esp32 采集的各种传感器的数据,也可以去控制各种传感器。省去编写针对各系统的app. 图片 1.浏览器每隔1秒更新一次数据 2.现在更新的是开机数据,运用此程序,可以实时显示各种传感器的实时数据 3.es…...
【亚马逊云】基于 Amazon EKS 搭建开源向量数据库 Milvus
文章目录 一、先决条件1.1 安装AWS CLI ✅1.2 安装 EKS 相关工具✅1.3 创建 Amazon S3 存储桶✅1.4 创建 Amazon MSK 实例✅ 二、创建EKS集群三、创建 ebs-sc StorageClass四、安装 AWS Load Balancer Controller五、部署 Milvus 数据库5.1 添加 Milvus Helm 仓库5.2 配置 S3 作…...

pytorch安装GPU版本,指定设备
安装了GPU版本的pytorch的时候,想要使用CPU,怎么操作呢? 设置环境变量: set TF_FORCE_GPU_ALLOW_GROWTHfalse set CUDA_VISIBLE_DEVICES如果想要使用固定序号的GUP设备,则指定ID set CUDA_VISIBLE_DEVICES0 # 使用第…...

草地杂草数据集野外草地数据集田间野草数据集YOLO格式VOC格式目标检测计算机视觉数据集
一、数据集概述 数据集名称:杂草图像数据集 数据集是一个包含野草种类的集合,其中每种野草都有详细的特征描述和标记。这些数据可以包括野草的图片、生长习性、叶片形状、颜色等特征。 1.1可能应用的领域 农业领域: 农业专家和农民可以利用这一数据集来…...

顺序表排序相关算法题|负数移到正数前面|奇数移到偶数前面|小于x的数移到大于x的数前面|快排思想(C)
负数移到正数前面 已知顺序表 ( a 1 , … , a n ) (a_{1},\dots,a_{n}) (a1,…,an),每个元素都是整数,把所有值为负数的元素移到全部正数值元素前边 算法思想 快排的前后指针版本 排序|冒泡排序|快速排序|霍尔版本|挖坑版本|前后指针版本|非递归版…...
)
【小白学机器学习20】单变量分析 / 0因子分析 (只分析1个变量本身的数据)
目录 1 什么是单变量分析(就是只分析数据本身) 1.1 不同的名字 1.2 《戏说统计》这本书里很多概念和一般的书不一样 1.3 具体来说,各种概率分布都属于单变量分析 2 一维的数据分析的几个层次 2.1 数据分析的层次 2.2 一维的数据为什么…...

[软件工程]—桥接(Brige)模式与伪码推导
桥接(Brige)模式与伪码推导 1.基本概念 1.1 动机 由于某些类型的固有的实现逻辑,使它们具有两个变化的维度,乃至多个维度的变化。如何应对这种“多维度的变化”?如何利用面向对象技术是的类型可以轻松的沿着两个乃至…...

TensorFlow面试整理-TensorFlow 结构与组件
TensorFlow 的结构和组件是其功能强大、灵活性高的重要原因。掌握这些结构和组件有助于更好地理解和使用 TensorFlow 构建、训练和部署模型。以下是 TensorFlow 关键的结构与组件介绍: 1. Tensor(张量) 定义:张量是 TensorFlow 中的数据载体,类似于多维数组或矩阵。张量的…...

linux下gpio模拟spi三线时序
目录 前言一、配置内容二、驱动代码实现三、总结 前言 本笔记总结linux下使用gpio模拟spi时序的方法,基于arm64架构的一个SOC,linux内核版本为linux5.10.xxx,以驱动三线spi(时钟线sclk,片选cs,sdata数据读和写使用同一…...

makesense导出的压缩包是空的
md ,那些教程感觉都不是人写的,没说要在右边选标签,我本来就是一个标签,我以为他会自动识别打标,结果死活导出来空包 密码要在右边选标签,...

Spring Boot框架下的中小企业设备维护系统
5系统详细实现 5.1 用户信息管理 中小企业设备管理系统的系统管理员可以对用户信息添加修改删除以及查询操作。具体界面的展示如图5.1所示。 图5.1 用户信息管理界面 5.2 员工信息管理 管理员可以对员工信息进行添加修改删除操作。具体界面如图5.2所示。 图5.2 员工信息界面…...

处理文件上传和进度条的显示(进度条随文件上传进度值变化)
成品效果图: 解决问题:上传文件过大时,等待时间过长,但是进度条却不会动,只会在上传完成之后才会显示上传完成 上传文件的upload.component.html <nz-modal [(nzVisible)]"isVisible" [nzTitle]"文…...

【套题】大沥2019年真题——第5题
05.魔术数组 题目描述 一个 N 行 N 列的二维数组,如果它满足如下的特性,则成为“魔术数组”: 1、从二维数组任意选出 N 个整数。 2、选出的 N 个整数都是在不同的行且在不同的列。 3、在满足上述两个条件下,任意选出来的 N 个整…...

上传Gitee仓库流程图
推荐一个流程图工具 登录 | ProcessOnProcessOn是一个在线协作绘图平台,为用户提供强大、易用的作图工具!支持在线创作流程图、思维导图、组织结构图、网络拓扑图、BPMN、UML图、UI界面原型设计、iOS界面原型设计等。同时依托于互联网实现了人与人之间的…...

二叉树相关OJ题 — 第一弹
目录 1. 检验两棵树是否相同 编辑 1. 题目解析 2. 解题步骤 2.判断一棵大树中是否包含有和一棵小树具有相同结构和节点值的子树 1. 题目解析 2. 解题步骤 3. 翻转二叉树 1. 题目解析 2.解题步骤 4. 判断一颗二叉树是否是平衡二叉树 1. 题目解析 2. 解题步骤…...

【学习笔记】RFID
RFID 1、 概述 1.1、RFID 介绍 1.2、RFID 发展史 1.3、RFID 系统的构造 1.3.1、阅读器 Reader 和 天线 Antenna 1.3.3、电子标签 tag 1.4、电子标签按吐字率分类 1.5、电子标签按能量供应的方式划分 1.6、RFID 工作流程 …...

自动化部署-01-jenkins安装
文章目录 前言一、下载安装二、启动三、问题3.1 jdk版本问题3.2 端口冲突3.3 库文件加载问题3.4 系统字体配置问题 四、再次启动五、配置jenkins5.1 解锁5.2 安装插件5.3 创建管理员用户5.4 实例配置5.5 开始使用5.6 完成 总结 前言 spingcloud微服务等每次部署到服务器上&…...
AI工具大爆发,建议每个都使用收藏
2024年被誉为AI应用元年,这一年人们普遍意识到,未来占据主导地位的将是基于大模型的应用程序,而不仅仅是大模型本身。因此,在这一趋势的推动下,各式各样的AI应用如雨后春笋般涌现出来。 今天就聊聊这些好用的AI工具&a…...
)
从零到一:手把手教你为Nachos实现Exec和Exit系统调用(附完整代码与调试技巧)
从零构建Nachos系统调用:Exec与Exit的深度实现指南 1. 系统调用实现基础 在操作系统中,系统调用是用户程序与内核交互的唯一途径。Nachos作为一个教学用操作系统框架,其系统调用机制模拟了真实操作系统的核心设计思想。 寄存器交互机制是系统…...

从单机到集群的基石:手把手配置ZooKeeper 3.5.8单机模式,为分布式应用铺路
从单机到集群的基石:手把手配置ZooKeeper 3.5.8单机模式,为分布式应用铺路 在分布式系统的世界里,协调服务就像交响乐团的指挥,确保每个乐器(节点)在正确的时间演奏正确的音符。ZooKeeper正是这样一个"…...

【信息科学与工程学】【人工智能】【知识工程】企业知识库管理与评估-第四篇-市场篇
一、企业价格知识管理参数体系 1.1、价格知识管理参数列表 内部交易价格参数 参数名称 参数定义 计算公式 计量单位 数据来源 部门间转移定价准确率 内部转移定价的准确程度 准确转移定价次数 / 总转移定价次数 100% % 财务系统、转移定价记录 成本中心计价合规率…...

用TensorFlow Lite Micro在Arduino上跑个‘Hello World’:从模型部署到LED闪烁的完整流程
在Arduino Nano 33 BLE Sense上部署TinyML模型的实战指南 当微控制器遇上机器学习,TinyML技术正在重新定义边缘计算的边界。本文将带您完成从TensorFlow Lite模型训练到Arduino硬件部署的全流程,通过控制LED亮度直观展示正弦波预测结果,让算…...

暗黑破坏神2存档编辑终极指南:5分钟掌握免费Web修改器
暗黑破坏神2存档编辑终极指南:5分钟掌握免费Web修改器 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2中无尽的刷装备和重复练级而苦恼吗?想快速体验不同职业的build却不想投入数百小时…...

Simulink仿真报错‘积分器发散’?别慌,试试把ode45换成ode3并固定步长
Simulink仿真中积分器发散问题的深度解析与实战解决方案 当你在Simulink中进行控制系统仿真时,突然弹出一条令人不安的错误信息——"Derivative not finite"或"singularity",这往往意味着你的仿真遇到了积分器发散问题。这种报错不…...
)
手把手教你用Matlab R2018a为TI C2000 DSP安装Embedded Coder支持包(含账户与版本避坑)
从零搭建Matlab与TI C2000 DSP的嵌入式开发环境:避坑指南与实战解析 当Matlab R2018a遇上TI C2000系列DSP处理器,工程师们便获得了一个从算法设计到硬件部署的完整解决方案。不同于传统的CCS开发模式,这种基于模型的设计(Model-Ba…...

Win10/Win11网络适配器‘罢工’终极排查指南:从驱动、服务到协议栈的完整修复流程
Win10/Win11网络适配器深度修复指南:从驱动到协议栈的全面诊断 当你的Windows设备突然无法联网,只剩下孤零零的飞行模式图标时,那种焦虑感每个IT从业者都深有体会。上周我的主力开发机就遭遇了这样的"罢工"事件——所有网络连接突然…...

SwiftHTTP文件上传完全指南:从基础到企业级应用
SwiftHTTP文件上传完全指南:从基础到企业级应用 【免费下载链接】SwiftHTTP Thin wrapper around NSURLSession in swift. Simplifies HTTP requests. 项目地址: https://gitcode.com/gh_mirrors/sw/SwiftHTTP 在iOS和macOS开发中,SwiftHTTP文件上…...

5分钟掌握Typora插件:从文件管理小白到高效写作达人的3步法
5分钟掌握Typora插件:从文件管理小白到高效写作达人的3步法 【免费下载链接】typora_plugin Typora plugin. Feature enhancement tool | Typora 插件,功能增强工具 项目地址: https://gitcode.com/gh_mirrors/ty/typora_plugin 你是否曾在Typora…...