使用爬虫爬取Python中文开发者社区基础教程的数据

👨💻个人主页:@开发者-曼亿点
👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅!
👨💻 本文由 曼亿点 原创
👨💻 收录于专栏:机器学习
⭐🅰⭐
— 
文章目录
- ⭐🅰⭐
- ⭐前言⭐
- 🎶一、网页基础
- 1.HTML
- 2.HTML DOM
- 🎶二、beautifulsoup4库
- 1.beautifulsoup4基本用法
- 2.CSS选择器
- 结束语🥇
⭐前言⭐
Python中文开发者社区是一个Python开发者学习交流的社区门户网站,也是一个非营利性的公益网站,它致力于壮大Python中国开发者群体,帮助Python开发者解决开发中遇到的各种问题。本任务将带领大家编写Python程序,利用beautifulsoup4库,爬取Python中文开发者社区基础教程的数据。
🎶一、网页基础
1.HTML
超文本标记语言(hyper text marked language,HTML)是一种用于描述网页的语言。它通过不同类型的标签来描述不同的元素,各种标签通过不同的排列和嵌套形成网页的框架。有的标签还带有属性参数,其语法格式如下。
常用的标签如表所示。


【温馨提示】:打开浏览器的开发者工具窗口,选择“Elements”选项,即可查看HTML源代码

2.HTML DOM
文档对象模型(document object model,DOM)定义了访问HTML和可扩展标记语言(extensible markup language,XML)文档的标准。HTML DOM将HTML文档呈现为带有元素、属性和文本的树结构(也称为节点树),如图所示。

🎶二、beautifulsoup4库
1.beautifulsoup4基本用法
beautifulsoup4库也称为Beautiful Soup库或bs4库,用于解析HTML或XML文档。beautifulsoup4库不是Python内置的标准库,使用之前需要安装。
beautifulsoup4库中最重要的是BeautifulSoup类,它的实例化对象相当于一个页面。解析网页时,需要使用BeautifulSoup()创建一个BeautifulSoup对象,该对象是一个树形结构,包含了HTML页面中的标签元素,如、等。也就是说,HTML中的主要结构都变成了BeautifulSoup对象的一个个属性,然后可通过“对象名.属性名”形式获取该对象的第一个属性值(即节点)。
【温馨提示】: BeautifulSoup对象的属性名与HTML的标签名相同,HTML常用的标签见表。
每一个HTML标签在beautifulsoup4库中又是一个对象,称为Tag对象,它有4个常用属性,如表3所示。

其中,attrs返回的是标签的所有属性组成的字典类型的数据,可通过“atrrs[‘属性名’]”形式获取属性值。
【例1】爬取链家租房网站的内容(网址https://bj.lianjia.com/zufang/),通过beautifulsoup4库解析网页,输出第一个li节点的类型、内容及其属性等信息。
【问题分析】 在Google Chrome浏览器中访问https://bj.lianjia.com/zufang/,查看并分析HTML源代码,可以看到第一个li节点的源代码,如图所示。

【参考代码】
import requests #导入requests库
from bs4 import BeautifulSoup #从bs4库中导入BeautifulSoup模块
url = 'https://bj.lianjia.com/zufang/' #定义url字符串
headersvalue = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
}
#发送请求,并将返回结果赋值给r
r = requests.get(url, headers=headersvalue)
#创建BeautifulSoup对象,并设置使用lxml解析器
soup = BeautifulSoup(r.text, 'lxml')
print('soup类型:', type(soup)) #输出soup类型
print('“soup.li”类型:', type(soup.li)) #输出“soup.li”类型
print('第一个li节点:\n', soup.li) #输出第一个li节点
#输出第一个li节点的name属性
print('第一个li节点的name属性:', soup.li.name)
#输出第一个li节点的contents属性
print('第一个li节点的contents属性:', soup.li.contents)
#输出第一个li节点的string属性
print('第一个li节点的string属性:', soup.li.string)
#输出第一个li节点的attrs属性
print('第一个li节点的attrs属性:', soup.li.attrs)
#输出第一个li节点的attrs属性的“class”属性值
print('第一个li节点的attrs属性的“class”属性值:',soup.li.attrs['class'])
#输出第一个li节点下a节点的string属性
print('第一个li节点下a节点的string属性:', soup.li.a.string)【运行结果】 程序运行结果如图所示。

2.CSS选择器
beautifulsoup4库提供了使用CSS选择器来选择节点的方法,只需调用select()方法传入相应的CSS选择器即可,常用的选择器如表所示。

【例2】爬取链家租房网站的内容(网址https://bj.lianjia.com/zufang/),使用CSS选择器选择节点,输出第一个房源的小区和楼层信息。
【问题分析】 在Google Chrome浏览器中访问https://bj.lianjia.com/zufang/,打开浏览器的开发者工具窗口,选择“Elements”选项后单击左上角“”按钮,然后使用鼠标选择网页中的某处,即可直接定位到HTML中对应的节点,如图所示。可以看出,第一个房源的小区信息包含在class属性值为content__list–item–des的节点下的a节点中,楼层信息包含在span节点中。

【参考代码】
import requests #导入requests库
from bs4 import BeautifulSoup #从bs4库中导入BeautifulSoup模块
url = 'https://bj.lianjia.com/zufang/' #定义url字符串
headersvalue = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
}
#发送请求,并将响应赋值给r
r = requests.get(url, headers=headersvalue)
#创建BeautifulSoup对象,并设置使用lxml解析器
soup = BeautifulSoup(r.text, 'lxml')
#将class属性值为“content__list--item--des”的第一个节点赋值给node
node = soup.select('.content__list--item--des')[0]
print('第一个房源小区信息:')
for node_a in node.select('a'):#循环输出node节点下a节点的文本print(node_a.string, end=' ')
#输出node节点下span节点中的楼层信息
print('\n第一个房源楼层信息:',node.select('span')[0].contents[2].strip())【运行结果】 程序运行结果如图所示。

完成本任务,须首先发送HTTP请求,然后将爬取到的文章按标题保存到TXT文件中,并输出每篇文章下载完成的提示。具体实现步骤如下。
(1)定义请求的URL字符串(base_url)和请求头字典(headersvalue),其中,base_url赋值为https://www.pythontab.com/html/pythonjichu/,即Python中文开发者社区的Python基础教程首页;headersvalue包含User-Agent信息。
(2)定义get_onepage_url(url)函数获取每一网页10篇文章的URL,并保存在列表中。
(3)定义get_article(url)函数获取每一篇文章的内容,在其中调用towrite()函数保存文章内容,并输出下载完成提示。
(4)定义towrite(title,content)函数将文章内容保存到TXT文件中,以文章标题命名文件保存在文件夹时,由于文件名不能包含一些特殊字符,须对文章标题中包含的特殊字符进行处理。
(5)定义main()函数,在当前工作目录中创建“Python基础教程”文件夹,循环30次,组合网页的URL,并调用get_onepage_url()函数返回url列表,然后遍历列表,调用get_article()函数。
(6)调用main()函数运行程序。
结束语🥇
以上就是机器学习
持续更新机器学习教程,欢迎大家订阅系列专栏🔥机器学习
你们的支持就是曼亿点创作的动力💖💖💖

相关文章:
使用爬虫爬取Python中文开发者社区基础教程的数据
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
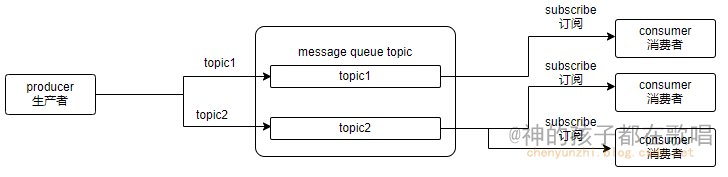
你了解kafka消息队列么?
消息队列概述 一. 消息队列组件二. 消息队列通信模式2.1 点对点模式2.2 发布/订阅模式 三. 消息队列的优缺点3.1 消息队列的优点3.2 消息队列的缺点 四. 总结 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者&…...

力扣102 二叉树的层序遍历 广度优先搜索
二叉树的层序遍历 题目描述 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15…...

堆(堆排序,TOP K, 优先级队列)
1 概念解释 堆的定义:堆是一颗完全二叉树,分为大堆和小堆 大堆:一棵树中,任何父亲节点都大于等于孩子的节点,大堆的根结点最大 小堆:一棵树中,任何父亲节点都小于等于孩子节点,小堆…...

(三)行为模式:11、模板模式(Template Pattern)(C++示例)
目录 1、模板模式含义 2、模板模式的UML图学习 3、模板模式的应用场景 4、模板模式的优缺点 5、C实现的实例 1、模板模式含义 模板模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法骨架,将某些步骤…...

贝叶斯中的充分统计量
内容来源 贝叶斯统计(第二版)中国统计出版社 前两篇笔记简述经典统计中的充分统计量和判断充分统计量的 N e y m a n Neyman Neyman 因子分解定理 而在贝叶斯统计中,充分统计量也有一个充要条件 定理兼定义 设 x ( x 1 , x 2 , ⋯ , x …...

012:ArcGIS Server 10.2安装与站点创建教程
摘要:本文详细介绍地理信息系统服务器软件ArcGIS Server 10.2的安装与站点创建流程。 一、软件介绍 ArcGIS Server 10.2是Esri公司开发的一款强大的地理信息系统(GIS)服务器软件。它支持发布和共享地图、地理数据处理服务及空间分析功能&…...

xlive.dll错误的详细解决办法步骤教程,xlive.dll基本状况介绍
在计算机的众多文件中,“xlive.dll”扮演着独特而重要的角色。所以当你的电脑丢失了xlive.dll文件时,会倒是电脑不能正常运行,那么出现这样的问题有什么办法可以将丢失的xlive.dll进行修复呢?今天这篇文章将和大家聊聊xlive.dll错…...
通俗易懂的餐厅例子来讲解JVM
餐厅版本 JVM(Java虚拟机)可以想象成一个虚拟的计算机,它能够运行Java程序。为了让你更容易理解,我们可以用一个餐厅的比喻来解释JVM: 菜单(Java源代码): 想象一下,Java…...

Python从入门到高手7.3节-列表的常用操作方法
目录 7.3.1 列表常用操作方法 7.3.2 列表的添加 7.3.3 列表的查找 7.3.4 列表的修改 7.3.5 列表的删除 7.3.6 与列表有关的其它操作方法 7.3.7 与10月说再见 7.3.1 列表常用操作方法 列表类型是一种抽象数据类型,抽象数据类型定义了数据类型的操作方法。在本…...

Prompt提示词设计:如何让你的AI对话更智能?
Prompt设计:如何让你的AI对话更智能? 在人工智能的世界里,Prompt(提示词)就像是一把钥匙,能够解锁AI的潜力,让它更好地理解和响应你的需求。今天,我们就来聊聊如何通过精心设计的Pr…...

2024-10月的“冷饭热炒“--解读GUI Agent 之computer use?phone use?——多模态大语言模型的进阶之路
GUI Agent 之computer use?phone use?——多模态大语言模型的进阶之路 1.最新技术事件浅析三、思考和方案设计工具代码部分1.提示词2.工具类API定义,这里主要看computer tool就够了 总结 本文会总结概括这一应用的利弊,然后给出分析和工具代…...

Me 攒的GPT修改论文提示词
没有会员的GPT They demonstrated that QGAN exhibits an exponential advantage over classical methods when using data consisting of samples of measurements made on high-dimensional spaces. 作为related work 时态对吗? 有需要修改的吗?你可…...

关于在vue2中接受后端返回的二进制流并进行本地下载
后端接口返回: 前端需要在两个地方写代码: 1.封装接口处,responseType: blob 2.接收相应处 download() {if (this.selectionList.length 0) {this.$message.error("请选择要导出的数据!");} else {examineruleExport…...
的解决办法)
[BUG]warn(f“Failed to load image Python extension: {e}“)的解决办法
在使用LlaMa-Factory工具包时,安装好环境后,输入llamafactory-cli env查看llama-factory的版本等信息时,bash提醒: /home/ubuntu/anaconda3/envs/Llama-Factory/lib/python3.10/site-packages/torchvision/io/image.py:13: UserW…...

配置MUX VLAN 的实验配置
概念和工作原理: MUX VLAN(Multiplex VLAN)是一种高级的VLAN技术,它通过在交换机上实现二层流量隔离和灵活的网络资源控制,提供了一种更为细致的网络管理方式。 概念与工作原理 基本概念: MUX VLAN通过定义主VLAN&am…...

高考相关 APP 案例分享
文章首发于https://qdgithub.com/article/2032 一、核心内容 (一)高考相关 APP 案例 圈友朱康分享高考相关的 APP。提到猿题库,其主要功能有练习册和猿辅导,都是收费的。猿题库出题给学生练习,将易错的总结起来出练习…...

AI的出现对计算机相关类型的博客或论坛的影响
最近越来越感觉到,AI的出现对计算机相关类型的博客是一种从寄生再到蚕食的过程。 在AI没出现之前,大家遇到问题,那一般都是去百度搜索,然后就能找到大神前辈的解答思路,这些解答思路基本都是写在博客或者论坛里的&…...

[LeetCode] 784. 字母大小写全排序
题目描述: 给定一个字符串 s ,通过将字符串 s 中的每个字母转变大小写,我们可以获得一个新的字符串。 返回 所有可能得到的字符串集合 。以 任意顺序 返回输出。 示例 1: 输入:s "a1b2" 输出࿱…...

大数据Azkaban(二):Azkaban简单介绍
文章目录 Azkaban简单介绍 一、Azkaban特点 二、Azkaban组成结构 三、Azkaban部署模式 1、solo-server ode(独立服务器模式) 2、two server mode(双服务器模式) 3、distributed multiple-executor mode(分布式多…...

基于Web Speech API与ChatGPT构建语音对话Web应用全解析
1. 项目概述与核心价值 最近在折腾一个挺有意思的玩意儿,一个能和ChatGPT进行语音对话的Web应用。这项目叫 chatgpt-voice ,是GitHub上一个开源的前端项目。说白了,它就是一个网页版的语音聊天机器人,你对着麦克风说话…...
)
GOCI数据爬虫失效了?别慌!手把手教你用Python搞定新版韩国官网批量下载(附完整代码)
GOCI数据爬虫失效了?别慌!手把手教你用Python搞定新版韩国官网批量下载 最近不少同行反馈,之前运行的GOCI数据爬虫脚本突然失效了。作为长期处理海洋遥感数据的老手,我第一时间测试了韩国官网的新版页面结构,发现他们确…...
中国医学科学院阜外医院放射科赵世华教授等团队:连续心肌纤维化评估预测肥厚型心肌病患者预后)
JACC Cardiovasc Imaging(IF=15.2)中国医学科学院阜外医院放射科赵世华教授等团队:连续心肌纤维化评估预测肥厚型心肌病患者预后
01文献学习今天分享的文献是由中国医学科学院阜外医院放射科赵世华教授等团队于2026年2月在《JACC: Cardiovascular Imaging》(中科院1区top,IF15.2)上发表的研究“Serial Myocardial Fibrosis Assessments Predict Outcomes in Patients Wit…...

CANN/asc-devkit Reset函数说明
Reset 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

RTLSeek:强化学习驱动的Verilog代码多样性生成技术
1. RTLSeek:当强化学习遇上硬件设计自动化在芯片设计领域,Verilog作为主流的硬件描述语言(HDL),其代码质量直接影响着芯片的性能、功耗和面积。传统RTL设计高度依赖工程师经验,一个资深工程师可能需要5-7年才能熟练掌握复杂芯片的…...

联发科2012年崛起:从功能机到智能机的转型与挑战
1. 从功能机到智能机的惊险一跃:联发科的2012年2012年,对于全球移动芯片行业来说,是几家欢喜几家愁的一年。诺基亚和黑莓的持续衰落,直接拖垮了像ST-Ericsson这样深度绑定的芯片供应商;即便是巨头如高通,也…...

从1991年Wescon展会看测试测量技术演进:DSP、GPIB与经典仪器解析
1. 从一份老杂志的周五测验说起:重温1991年Wescon展会的测试测量世界最近在整理资料时,翻到一篇2016年《EE Times》上的老文章,标题叫“周五测验:Wescon测试产品”。文章的核心是带读者回顾1991年EDN杂志为Wescon展会出版的一份厚…...

[CAN BUS] 从开源到商用:USB-CAN适配器选型避坑指南与稳定性深度剖析
1. 为什么USB-CAN适配器选型这么重要? 如果你正在开发汽车电子、工业控制或者机器人项目,大概率会用到CAN总线。作为嵌入式工程师,我最开始接触CAN总线时,天真地以为随便买个USB转CAN的工具就能搞定。结果在实际项目中踩了不少坑—…...

ARM Cortex-R7低功耗架构设计与动态RAM保留技术
1. ARM Cortex-R7低功耗架构设计精要 在嵌入式实时系统中,功耗优化始终是工程师面临的核心挑战。ARM Cortex-R7 MPCore处理器通过创新的动态RAM保留技术,为工业控制、汽车电子等实时应用场景提供了高性能与低功耗的完美平衡方案。这套机制的精妙之处在于…...

ARM9EJ-S核心调试技术与系统速度访问机制解析
1. ARM9EJ-S核心调试技术概述 在嵌入式系统开发领域,调试技术的重要性不亚于代码编写本身。ARM9EJ-S作为经典的嵌入式处理器核心,其调试子系统设计体现了ARM架构对开发效率的深度考量。这套调试系统不仅仅是简单的"暂停-查看"工具,…...