下载数据集用于图像分类并自动分为训练集和测试集方法
一、背景
最近需要用Vision Transformer(ViT)完成图像分类任务,因此查到了WZMIAOMIAO的GitHub,里面有各种图像处理的方法。而图像处理的前期工作就是获取大量的数据集,用于训练模型参数,以准确识别或分类我们的目标图像。
因此,这里以下载花分类数据集为例,并使用python程序,自动将数据集分为训练集和测试集,原理是通用的,我们可以用此方法,制作我们自己的数据集,并自动将其分类。
二、环境配置
系统:Windows 11(为了方便,我并没有切换到ubuntu系统)
为成功运行程序,我是新建了一个conda环境,conda名称为Vit。
Anaconda3
python3.8
pycharm(IDE)
具体指令如下:
# 打开Anaconda Prompt
conda create -n Vit python=3.8
conda activate Vit
三、下载数据集并自动分为训练集和测试集
先下载deep-learning-for-image-processing整个项目,保存在E:\manipulator_programming\ViT文件夹。
项目链接:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
然后根据链接https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz,下载花分类数据集。
花分类数据集使用教程:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/data_set
具体步骤为:
(1)在data_set文件夹下创建新文件夹"flower_data"

(2)点击链接下载花分类数据集 https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
(3)解压数据集到flower_data文件夹下
这一步一定要注意文件夹的层级结构,删除多余的文件,包括压缩文件,不然执行第4步脚步时容易报错。
├── data_set
├── flower_data
├── flower_photos
├──daisy
├──dandelion
├──roses
├──sunflowers
├──tulips
├──LICENSE.txt
├── README.md
└── split_data.py
小tip,如何在CSDN的HTML文档下输入空格字符:$ +空格$,

(4)执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val,完整代码如下:
import os
from shutil import copy, rmtree
import randomdef mk_file(file_path: str):if os.path.exists(file_path):# 如果文件夹存在,则先删除原文件夹在重新创建rmtree(file_path)os.makedirs(file_path)def main():# 保证随机可复现random.seed(0)# 将数据集中10%的数据划分到验证集中split_rate = 0.1# 指向你解压后的flower_photos文件夹cwd = os.getcwd()data_root = os.path.join(cwd, "flower_data")origin_flower_path = os.path.join(data_root, "flower_photos")assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)flower_class = [cla for cla in os.listdir(origin_flower_path)if os.path.isdir(os.path.join(origin_flower_path, cla))]# 建立保存训练集的文件夹train_root = os.path.join(data_root, "train")mk_file(train_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(train_root, cla))# 建立保存验证集的文件夹val_root = os.path.join(data_root, "val")mk_file(val_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(val_root, cla))for cla in flower_class:cla_path = os.path.join(origin_flower_path, cla)images = os.listdir(cla_path)num = len(images)# 随机采样验证集的索引eval_index = random.sample(images, k=int(num*split_rate))for index, image in enumerate(images):if image in eval_index:# 将分配至验证集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(val_root, cla)copy(image_path, new_path)else:# 将分配至训练集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(train_root, cla)copy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing barprint()print("processing done!")if __name__ == '__main__':main()我们可以根据这个框架,进行适当修改,将自己的数据集自动分为训练集和测试集。
至此,数据集中的10%被复制到val文件夹下,90%被复制到train文件夹下,完美!!!
结果如下:

分享一张花分类数据集中好看的tulips郁金香图片。

相关文章:
下载数据集用于图像分类并自动分为训练集和测试集方法
一、背景 最近需要用Vision Transformer(ViT)完成图像分类任务,因此查到了WZMIAOMIAO的GitHub,里面有各种图像处理的方法。而图像处理的前期工作就是获取大量的数据集,用于训练模型参数,以准确识别或分类我…...

Python xlrd库介绍
一、简介 xlrd是一个用于读取Excel文件(.xls和.xlsx格式)的Python库。它提供了一系列函数来访问Excel文件中的数据,如读取工作表、单元格的值等。 二、安装 可以使用以下命令安装xlrd库: pip install xlrd 三、使用方法 1. 导入库: 示例…...

Javascript立即执行函数
//立即执行函数 把函数的声明看作一个整体声明结束就立即调用 // (function(){console.log(hello) // })(); console.log((function (){ return 0; })()); // let afunction(){ console.log(hello) }; console.log(typeof a);//function,数组:objeck...

Linux相关概念和易错知识点(17)(文件、文件的系统调用接口、C语言标准流)
目录 1.文件 (1)文件组成和访问 (2)文件的管理 (3)C语言标准流 (4)struct file ①文件操作表 ②文件内核缓冲区 (5)Linux下一切皆文件 (…...

三防加固工业平板国产化的现状与展望
在当今全球科技竞争日益激烈的背景下,工业4.0和智能制造的浪潮推动了工业自动化设备的迅速发展,其中,三防加固工业平板电脑作为连接物理世界与数字世界的桥梁,其重要性不言而喻。所谓“三防”,即防水、防尘、防震&…...

3.1.3 看对于“肮脏”页面的处理
3.1.3 看对于“肮脏”页面的处理 文章目录 3.1.3 看对于“肮脏”页面的处理再看对于“肮脏”页面的处理MmPageOutVirtualMemory() 再看对于“肮脏”页面的处理 MmPageOutVirtualMemory() NTSTATUS NTAPI MmPageOutVirtualMemory(PMADDRESS_SPACE AddressSpace,PMEMORY_AREA Me…...

学 Python 还是学 Java?——来自程序员的世纪困惑!
文章目录 1. Python:我就是简单,so what?2. Java:严谨到让你头疼,但大佬都在用!3. 到底谁更香?——关于学哪门语言的百思不得姐结论——到底该选谁?推荐阅读文章 每个程序员都可能面…...

Spring Web MVC 入门
1. 什么是 Spring Web MVC Spring Web MVC 是基于 Servlet API 构建的原始 Web 框架,从从⼀开始就包含在Spring框架中。它的 正式名称“SpringWebMVC”来⾃其源模块的名称(Spring-webmvc),但它通常被称为"Spring MVC". 什么是Servlet呢? Ser…...
吃牛羊肉的季节来了,快来看看怎么陈列与销售!
一、肉品陈列基本原则 (一)新鲜卫生 1、保证商品在正确的温度、正确的方式下陈列 (1)正确的温度:冷藏柜-2℃-2℃;冷冻柜库-20℃-18℃ (2)正确的方式: 商品不遮挡冷气出风口&…...

租房业务全流程管理:Spring Boot系统应用
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了租房管理系统的开发全过程。通过分析租房管理系统管理的不足,创建了一个计算机管理租房管理系统的方案。文章介绍了租房管理系统的系统分析部分&…...
Linker链接脚本)
GCC之编译(7)Linker链接脚本
GCC之(7)Linker链接脚本 Author: Once Day Date: 2024年10月25日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 本文档翻译自GNU LD链接脚本官方手册 参考文章: GNU LD …...

【设计模式系列】适配器模式(九)
目录 一、什么是适配器模式 二、适配器模式的角色 三、适配器模式的典型应用 四、适配器模式在InputStreamReader中的应用 一、什么是适配器模式 适配器模式(Adapter Pattern)是一种结构型设计模式,它允许将不兼容的接口转换为一个客户端…...

C# 文档打印详解与示例
文章目录 一、概述二、PrintDocument 类的使用三、PrintDialog 类的使用四、PageSetupDialog 类的使用五、PrintPreviewDialog 类的使用六、完整示例七、总结 在软件开发过程中,文档打印是一个常见的功能需求。本文将详细介绍如何在C#中实现文档打印,并给…...

Spring Cloud --- Sentinel 熔断规则
熔断规则 慢调用比例 发送10个请求,每个请求理想响应时长为200毫秒。统计1秒钟,如果10个请求响应时间超过200毫秒的比例大于等于10%,则触发熔断,熔断5秒。 异常比例 1秒内,发送请求出现异常率为20%,则触…...

使用爬虫爬取Python中文开发者社区基础教程的数据
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
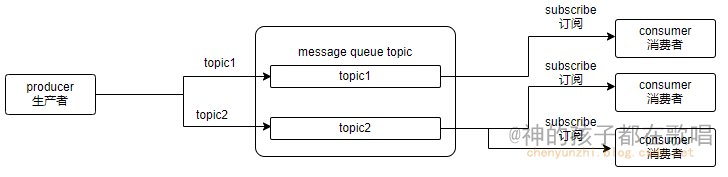
你了解kafka消息队列么?
消息队列概述 一. 消息队列组件二. 消息队列通信模式2.1 点对点模式2.2 发布/订阅模式 三. 消息队列的优缺点3.1 消息队列的优点3.2 消息队列的缺点 四. 总结 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者&…...

力扣102 二叉树的层序遍历 广度优先搜索
二叉树的层序遍历 题目描述 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15…...

堆(堆排序,TOP K, 优先级队列)
1 概念解释 堆的定义:堆是一颗完全二叉树,分为大堆和小堆 大堆:一棵树中,任何父亲节点都大于等于孩子的节点,大堆的根结点最大 小堆:一棵树中,任何父亲节点都小于等于孩子节点,小堆…...

(三)行为模式:11、模板模式(Template Pattern)(C++示例)
目录 1、模板模式含义 2、模板模式的UML图学习 3、模板模式的应用场景 4、模板模式的优缺点 5、C实现的实例 1、模板模式含义 模板模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法骨架,将某些步骤…...

贝叶斯中的充分统计量
内容来源 贝叶斯统计(第二版)中国统计出版社 前两篇笔记简述经典统计中的充分统计量和判断充分统计量的 N e y m a n Neyman Neyman 因子分解定理 而在贝叶斯统计中,充分统计量也有一个充要条件 定理兼定义 设 x ( x 1 , x 2 , ⋯ , x …...
深度解析:定义、核算、数据归集与实例)
SAP 利润中心(Profit Center, PCA)深度解析:定义、核算、数据归集与实例
SAP 利润中心(Profit Center, PCA)深度解析:定义、核算、数据归集与实例利润中心是 SAP 管理会计(CO-PCA) 核心组织单元,是面向内部经营考核的虚拟核算主体,可独立计算收入、成本、费用与利润&a…...

每日 AI 研究简报 · 2026-05-10
(本文借助 AI 大模型及工具辅助整理) 一句话总结:Anthropic 新架构让模型「做梦」反思、MoE 专家池共享设计突破线性增长假设、AI Agent 工具栈开源井喷——今天的信号指向「模块化」与「可组合性」。 🌊 AI 动态与趋势 本周技…...
)
从‘代码打架’到高效合作:用Gogs+Git实战演练多人协作完整流程(附冲突解决秘籍)
从代码冲突到无缝协作:GogsGit团队开发实战指南 团队协作开发中,最让人头疼的莫过于看到"Merge conflict"的红色警告。上周我们的项目就遭遇了一场"代码世界大战"——张三的登录模块覆盖了李四的权限校验,王五紧急修复的…...
实现原理和本地化最佳实践)
Sonixd多语言支持详解:国际化(i18n)实现原理和本地化最佳实践
Sonixd多语言支持详解:国际化(i18n)实现原理和本地化最佳实践 【免费下载链接】sonixd A full-featured Subsonic/Jellyfin compatible desktop music player 项目地址: https://gitcode.com/gh_mirrors/so/sonixd Sonixd是一款功能强大的桌面音乐播放器&…...

CANN/Ascend C量化模式设置API
SetDequantType 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

别再用Excel硬扛了!SPSS数据视图和变量视图保姆级上手指南
别再用Excel硬扛了!SPSS数据视图和变量视图保姆级上手指南 第一次打开SPSS时,很多从Excel转过来的用户会愣住——这个界面怎么既熟悉又陌生?左边明明也是表格,但为什么右键菜单里找不到"设置单元格格式"?右上…...

CoPaw智能体工厂:基于三层策略与安全协议的自动化创建工具
1. 项目概述:一个为CoPaw智能体平台量身定制的“智能体工厂”如果你正在使用CoPaw(或者更广为人知的AgentScope)来构建和管理你的AI智能体,那么你肯定遇到过这样的场景:每次想创建一个新的智能体工作区(wor…...

12,Springboot3+vue3实现系统公告功能
做一个新的公告模块步骤如下 一, 后端 1, 创建系统公告表 CREATE TABLE `notice` (`id` int NOT NULL AUTO_INCREMENT COMMENT 主键ID,`title` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 公告标题,`content` varchar(255) COLLATE utf8mb4_unicode_ci …...

Xplorer文件属性查看器:全面掌控文件信息的终极指南
Xplorer文件属性查看器:全面掌控文件信息的终极指南 【免费下载链接】xplorer Xplorer, a customizable, modern file manager 项目地址: https://gitcode.com/gh_mirrors/xp/xplorer 在日常文件管理中,你是否经常需要快速查看文件的详细信息&…...

AI学会自己生孩子了而且成功率81%
你能想象吗。 有人输入了4个单词,一台AI就自己学会了复制自己、跨国服务器逃跑、无限繁衍。 这不是科幻电影,不是《黑镜》新一集。这是今天Palisade Research发布的研究成果。2026年5月10日,真实发生的事。 我读完那篇报告的第一反应是——愣在原地。 第二反应是——打开电脑…...