【力扣 + 牛客 | SQL题 | 每日5题】牛客SQL热题204,201,215
1. 力扣1126:查询活跃业务
1.1 题目:
事件表:Events
+---------------+---------+ | Column Name | Type | +---------------+---------+ | business_id | int | | event_type | varchar | | occurrences | int | +---------------+---------+ (business_id, event_type) 是这个表的主键(具有唯一值的列的组合)。 表中的每一行记录了某种类型的事件在某些业务中多次发生的信息。
平均活动 是指有特定 event_type 的具有该事件的所有公司的 occurrences 的均值。
活跃业务 是指具有 多个 event_type 的业务,它们的 occurrences 严格大于 该事件的平均活动次数。
写一个解决方案,找到所有 活跃业务。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Events table: +-------------+------------+-------------+ | business_id | event_type | occurrences | +-------------+------------+-------------+ | 1 | reviews | 7 | | 3 | reviews | 3 | | 1 | ads | 11 | | 2 | ads | 7 | | 3 | ads | 6 | | 1 | page views | 3 | | 2 | page views | 12 | +-------------+------------+-------------+ 输出: +-------------+ | business_id | +-------------+ | 1 | +-------------+ 解释: 每次活动的平均活动可计算如下: - 'reviews': (7+3)/2 = 5 - 'ads': (11+7+6)/3 = 8 - 'page views': (3+12)/2 = 7.5 id=1 的业务有 7 个 'reviews' 事件(多于 5 个)和 11 个 'ads' 事件(多于 8 个),所以它是一个活跃的业务。
1.2 思路:
使用ans字段判断每组记录的平均值是否要比公司的均值要大.
1.3 题解:
-- 先求出所有公司的各个event_type业务的平均值
with tep1 as (select event_type, avg(occurrences) avgsfrom Eventsgroup by event_type
), tep2 as (-- 然后判断每组记录的平均值是否比公司的均值要大-- 如果大的话ans字段的值为1,否则为0select business_id ,case when avg(occurrences) > (select avgs from tep1 t2 where t1.event_type = t2.event_type)and avg(occurrences) > 0then 1else 0end ansfrom Events t1group by business_id, event_type
)
-- where过滤掉ans不为1 的记录
-- having过滤不是活跃业务的记录
select business_id
from tep2
where ans = 1
group by business_id
having count(*) >= 22. 力扣1069:产品销售分析2
2.1 题目:
销售表:Sales
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ sale_id 是这个表的主键(具有唯一值的列)。 product_id 是 Product 表的外键(reference 列)。 该表的每一行显示产品product_id在某一年的销售情况。 请注意价格是每单位的。
产品表:Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ product_id 是这个表的主键(具有唯一值的列)。 该表的每一行表示每种产品的产品名称。
编写解决方案,统计每个产品的销售总量。
返回结果表 无顺序要求 。
结果格式如下例子所示。
示例 1:
输入:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
输出:
+--------------+----------------+
| product_id | total_quantity |
+--------------+----------------+
| 100 | 22 |
| 200 | 15 |
+--------------+----------------+2.2 思路:
看SQL即可。
2.3 题解:
with tep as (select t1.product_id, quantity from Sales t1join Product t2on t1.product_id = t2.product_id
)
select product_id, sum(quantity) total_quantity
from tep
group by product_id3. 牛客SQL热题204:获取所有非manager的员工emp_no
3.1 题目:
描述
有一个员工表employees简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
有一个部门领导表dept_manager简况如下:
| dept_no | emp_no | from_date | to_date |
| d001 | 10002 | 1996-08-03 | 9999-01-01 |
| d002 | 10003 | 1990-08-05 | 9999-01-01 |
请你找出所有非部门领导的员工emp_no,以上例子输出:
| emp_no |
| 10001 |
示例1
输入:drop table if exists `dept_manager` ;
drop table if exists `employees` ;
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO dept_manager VALUES('d001',10002,'1996-08-03','9999-01-01');
INSERT INTO dept_manager VALUES('d002',10003,'1990-08-05','9999-01-01');
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
复制输出:100013.2 思路:
看SQL
3.3 题解:
select emp_no
from employees
where emp_no not in (select emp_nofrom dept_manager
)4. 牛客SQL热题201:查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
4.1 题目:
描述
有一个薪水表,salaries简况如下:
| emp_no | salary | from_date | to_date |
| 10001 | 60117 | 1986-06-26 | 1987-06-26 |
| 10001 | 62102 | 1987-06-26 | 1988-06-25 |
| 10001 | 66074 | 1988-06-25 | 1989-06-25 |
| 10001 | 66596 | 1989-06-25 | 1990-06-25 |
| 10001 | 66961 | 1990-06-25 | 1991-06-25 |
| 10001 | 71046 | 1991-06-25 | 1992-06-24 |
| 10001 | 74333 | 1992-06-24 | 1993-06-24 |
| 10001 | 75286 | 1993-06-24 | 1994-06-24 |
| 10001 | 75994 | 1994-06-24 | 1995-06-24 |
| 10001 | 76884 | 1995-06-24 | 1996-06-23 |
| 10001 | 80013 | 1996-06-23 | 1997-06-23 |
| 10001 | 81025 | 1997-06-23 | 1998-06-23 |
| 10001 | 81097 | 1998-06-23 | 1999-06-23 |
| 10001 | 84917 | 1999-06-23 | 2000-06-22 |
| 10001 | 85112 | 2000-06-22 | 2001-06-22 |
| 10001 | 85097 | 2001-06-22 | 2002-06-22 |
| 10002 | 72527 | 1996-08-03 | 1997-08-03 |
请你查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t,以上例子输出如下:
| emp_no | t |
| 10001 | 16 |
示例1
输入:drop table if exists `salaries` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO salaries VALUES(10001,60117,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25');
INSERT INTO salaries VALUES(10001,66074,'1988-06-25','1989-06-25');
INSERT INTO salaries VALUES(10001,66596,'1989-06-25','1990-06-25');
INSERT INTO salaries VALUES(10001,66961,'1990-06-25','1991-06-25');
INSERT INTO salaries VALUES(10001,71046,'1991-06-25','1992-06-24');
INSERT INTO salaries VALUES(10001,74333,'1992-06-24','1993-06-24');
INSERT INTO salaries VALUES(10001,75286,'1993-06-24','1994-06-24');
INSERT INTO salaries VALUES(10001,75994,'1994-06-24','1995-06-24');
INSERT INTO salaries VALUES(10001,76884,'1995-06-24','1996-06-23');
INSERT INTO salaries VALUES(10001,80013,'1996-06-23','1997-06-23');
INSERT INTO salaries VALUES(10001,81025,'1997-06-23','1998-06-23');
INSERT INTO salaries VALUES(10001,81097,'1998-06-23','1999-06-23');
INSERT INTO salaries VALUES(10001,84917,'1999-06-23','2000-06-22');
INSERT INTO salaries VALUES(10001,85112,'2000-06-22','2001-06-22');
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
复制输出:10001|174.2 思路:
太基础了吧。
4.3 题解:
select emp_no, count(*) t
from salaries
group by emp_no
having count(*) > 155. 牛客SQL热题215:查找在职员工自入职以来的薪水涨幅情况
5.1 题目:
描述
有一个员工表employees简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 2001-06-22 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1999-08-03 |
有一个薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
| 10001 | 85097 | 2001-06-22 | 2002-06-22 |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 1999-08-03 | 2000-08-02 |
| 10002 | 72527 | 2000-08-02 | 2001-08-02 |
请你查找在职员工自入职以来的薪水涨幅情况,给出在职员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为
(注: to_date为薪资调整某个结束日期,或者为离职日期,to_date='9999-01-01'时,表示依然在职,无后续调整记录)
| emp_no | growth |
| 10001 | 3861 |
示例1
输入:drop table if exists `employees` ;
drop table if exists `salaries` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','2001-06-22');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1999-08-03');
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1999-08-03','2000-08-02');
INSERT INTO salaries VALUES(10002,72527,'2000-08-02','2001-08-02');
复制输出:10001|38615.2 思路:
5.3 题解:
相关文章:

【力扣 + 牛客 | SQL题 | 每日5题】牛客SQL热题204,201,215
1. 力扣1126:查询活跃业务 1.1 题目: 事件表:Events ------------------------ | Column Name | Type | ------------------------ | business_id | int | | event_type | varchar | | occurrences | int | --------…...

下载数据集用于图像分类并自动分为训练集和测试集方法
一、背景 最近需要用Vision Transformer(ViT)完成图像分类任务,因此查到了WZMIAOMIAO的GitHub,里面有各种图像处理的方法。而图像处理的前期工作就是获取大量的数据集,用于训练模型参数,以准确识别或分类我…...

Python xlrd库介绍
一、简介 xlrd是一个用于读取Excel文件(.xls和.xlsx格式)的Python库。它提供了一系列函数来访问Excel文件中的数据,如读取工作表、单元格的值等。 二、安装 可以使用以下命令安装xlrd库: pip install xlrd 三、使用方法 1. 导入库: 示例…...

Javascript立即执行函数
//立即执行函数 把函数的声明看作一个整体声明结束就立即调用 // (function(){console.log(hello) // })(); console.log((function (){ return 0; })()); // let afunction(){ console.log(hello) }; console.log(typeof a);//function,数组:objeck...

Linux相关概念和易错知识点(17)(文件、文件的系统调用接口、C语言标准流)
目录 1.文件 (1)文件组成和访问 (2)文件的管理 (3)C语言标准流 (4)struct file ①文件操作表 ②文件内核缓冲区 (5)Linux下一切皆文件 (…...

三防加固工业平板国产化的现状与展望
在当今全球科技竞争日益激烈的背景下,工业4.0和智能制造的浪潮推动了工业自动化设备的迅速发展,其中,三防加固工业平板电脑作为连接物理世界与数字世界的桥梁,其重要性不言而喻。所谓“三防”,即防水、防尘、防震&…...

3.1.3 看对于“肮脏”页面的处理
3.1.3 看对于“肮脏”页面的处理 文章目录 3.1.3 看对于“肮脏”页面的处理再看对于“肮脏”页面的处理MmPageOutVirtualMemory() 再看对于“肮脏”页面的处理 MmPageOutVirtualMemory() NTSTATUS NTAPI MmPageOutVirtualMemory(PMADDRESS_SPACE AddressSpace,PMEMORY_AREA Me…...

学 Python 还是学 Java?——来自程序员的世纪困惑!
文章目录 1. Python:我就是简单,so what?2. Java:严谨到让你头疼,但大佬都在用!3. 到底谁更香?——关于学哪门语言的百思不得姐结论——到底该选谁?推荐阅读文章 每个程序员都可能面…...

Spring Web MVC 入门
1. 什么是 Spring Web MVC Spring Web MVC 是基于 Servlet API 构建的原始 Web 框架,从从⼀开始就包含在Spring框架中。它的 正式名称“SpringWebMVC”来⾃其源模块的名称(Spring-webmvc),但它通常被称为"Spring MVC". 什么是Servlet呢? Ser…...
吃牛羊肉的季节来了,快来看看怎么陈列与销售!
一、肉品陈列基本原则 (一)新鲜卫生 1、保证商品在正确的温度、正确的方式下陈列 (1)正确的温度:冷藏柜-2℃-2℃;冷冻柜库-20℃-18℃ (2)正确的方式: 商品不遮挡冷气出风口&…...

租房业务全流程管理:Spring Boot系统应用
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了租房管理系统的开发全过程。通过分析租房管理系统管理的不足,创建了一个计算机管理租房管理系统的方案。文章介绍了租房管理系统的系统分析部分&…...
Linker链接脚本)
GCC之编译(7)Linker链接脚本
GCC之(7)Linker链接脚本 Author: Once Day Date: 2024年10月25日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 本文档翻译自GNU LD链接脚本官方手册 参考文章: GNU LD …...

【设计模式系列】适配器模式(九)
目录 一、什么是适配器模式 二、适配器模式的角色 三、适配器模式的典型应用 四、适配器模式在InputStreamReader中的应用 一、什么是适配器模式 适配器模式(Adapter Pattern)是一种结构型设计模式,它允许将不兼容的接口转换为一个客户端…...

C# 文档打印详解与示例
文章目录 一、概述二、PrintDocument 类的使用三、PrintDialog 类的使用四、PageSetupDialog 类的使用五、PrintPreviewDialog 类的使用六、完整示例七、总结 在软件开发过程中,文档打印是一个常见的功能需求。本文将详细介绍如何在C#中实现文档打印,并给…...

Spring Cloud --- Sentinel 熔断规则
熔断规则 慢调用比例 发送10个请求,每个请求理想响应时长为200毫秒。统计1秒钟,如果10个请求响应时间超过200毫秒的比例大于等于10%,则触发熔断,熔断5秒。 异常比例 1秒内,发送请求出现异常率为20%,则触…...

使用爬虫爬取Python中文开发者社区基础教程的数据
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
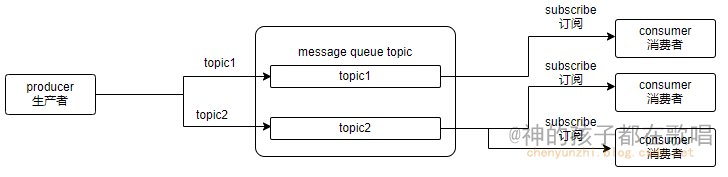
你了解kafka消息队列么?
消息队列概述 一. 消息队列组件二. 消息队列通信模式2.1 点对点模式2.2 发布/订阅模式 三. 消息队列的优缺点3.1 消息队列的优点3.2 消息队列的缺点 四. 总结 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者&…...

力扣102 二叉树的层序遍历 广度优先搜索
二叉树的层序遍历 题目描述 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15…...

堆(堆排序,TOP K, 优先级队列)
1 概念解释 堆的定义:堆是一颗完全二叉树,分为大堆和小堆 大堆:一棵树中,任何父亲节点都大于等于孩子的节点,大堆的根结点最大 小堆:一棵树中,任何父亲节点都小于等于孩子节点,小堆…...

(三)行为模式:11、模板模式(Template Pattern)(C++示例)
目录 1、模板模式含义 2、模板模式的UML图学习 3、模板模式的应用场景 4、模板模式的优缺点 5、C实现的实例 1、模板模式含义 模板模式(Template Method Pattern)是一种行为设计模式,它定义了一个操作中的算法骨架,将某些步骤…...

连接器选型三张“底牌”:电源、高速、射频的隐性代价与系统级权衡
当产品进入量产阶段,连接器往往是“压死骆驼的最后一根稻草”。它不像芯片那样有明确的数据手册边界,也不像PCB那样可归咎于Layout规则。连接器的失效模式高度依赖“配合状态”——插拔了几次?压接用了什么工具?相邻器件发热多少&…...

Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动
Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动 【免费下载链接】neoscroll.nvim Smooth scrolling neovim plugin written in lua 项目地址: https://gitcode.com/gh_mirrors/ne/neoscroll.nvim Neoscroll.nvim是一款用Lua编写的Neovim平滑滚动插件…...

CANN Ascend C LayerNorm梯度Beta API
LayerNormGradBeta 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitc…...

Java 判断选择循环
一、判断1.应用场景:只有满足条件,对应的代码才能执行2.三种形式:3.示例:4.注意事项:二、选择1.使用:把所有的选择一一列举出来,根据不同的条件任选其一2.格式:3.示例:4.…...

目标检测算法——史上最全遥感数据集汇总附下载链接【速速收藏】
🚀🚀🚀 近期,小海带在空闲之余收集整理了一批遥感检测数据集供大家参考。 整理不易,小伙伴们记得一键三连喔!!!🎈 🖥️ 专注开源数据集分享与深度学习科研思路…...

为LLM构建持久化知识大脑:基于知识图谱与向量搜索的Memento MCP实战
1. 项目概述:为LLM构建一个持久化、可理解的知识大脑如果你用过Claude Desktop、Cursor或者GitHub Copilot,可能会发现一个痛点:这些AI助手虽然聪明,但它们的“记忆”是短暂的、碎片化的。每次对话都像是一次全新的邂逅࿰…...

从零部署私有AI助手:igogpt项目实战与优化指南
1. 项目概述与核心价值最近在折腾AI应用部署的时候,发现了一个挺有意思的项目,叫igolaizola/igogpt。乍一看这个名字,可能会有点摸不着头脑,但如果你对开源AI模型部署和WebUI界面搭建感兴趣,那这个项目绝对值得你花时间…...

基于MCP协议的Burp Suite AI安全测试插件部署与应用实战
1. 项目概述:当Burp Suite遇见MCP,安全测试的“智能副驾”来了如果你是一名Web安全测试工程师或者渗透测试人员,Burp Suite这个名字对你来说,就像木匠手里的锤子一样熟悉。它几乎是手动安全测试的代名词,从拦截代理到漏…...

【信息科学与工程学】【制造工程】【通信工程】第一百零一篇 2nm 200Tbps+核心交换机全尺度参数 第二系列 物料与生产体系12
系统概述 系统名称: 200Tbps 集群核心交换机 核心功能: 提供超高密度、超低延迟、无阻塞的数据交换,用于数据中心集群核心或超算中心网络。 系统组成: 机箱、主控板卡、交换网板卡(4块,互为冗余)、线卡(业务板卡)、风扇模块、电源模块。 关键设计参数: 整机交换容量: …...
:CASE WHEN 与“行转列/列转行”花式玩法)
SQL与数据库开发(四):CASE WHEN 与“行转列/列转行”花式玩法
在企业级应用的开发中,后端程序员和报表工程师往往面临着一种天然的矛盾:“数据库的存储格式”与“前端的展示格式”是完全不匹配的。 关系型数据库最喜欢“瘦长”的表(不断往下插入新行),而业务方和老板最喜欢看的是…...