深度学习(五):语音处理领域的创新引擎(5/10)

一、深度学习在语音处理中的崛起
在语音处理领域,传统方法如谱减法、维纳滤波等在处理复杂语音信号时存在诸多局限性。这些方法通常假设噪声是平稳的,但实际噪声往往是非平稳的,导致噪声估计不准确。同时,为了去除噪声,传统方法不可避免地会对语音信号造成一定程度的失真,影响语音的自然性,且面对复杂多变的噪声环境,传统方法的适应性和鲁棒性有限。
近年来,深度学习的兴起为语音处理带来了革命性的变化。深度神经网络(DNN)具有强大的特征提取和模式识别能力,能够有效地学习语音信号中的复杂特征。例如,在语音识别中,使用深度神经网络替代传统的高斯混合模型(GMM),能够更准确地对语音信号进行建模,提取更具辨识度的声学特征。

在语音增强方面,深度学习也展现出了巨大的优势。基于深度学习的语音去噪方法通过构建强大的噪声和语音模型,能够自适应地去除复杂噪声,同时最大限度地保留语音的细节特征。如 PACDNN(一种相位感知复合深度神经网络)利用频谱掩模进行幅度处理和利用相位导数进行相位重构,从而实现幅度和相位同时增强。
此外,循环神经网络(RNN)适用于处理序列数据,如语音信号,具有记忆功能,能够捕捉序列中的长期依赖关系。在语言模型建模中,使用循环神经网络(如长短期记忆网络 LSTM)等模型,能够更好地捕捉语音信号中的时序信息,从而更准确地预测下一个单词或音素。卷积神经网络(CNN)则主要用于图像识别和处理,但也在语音处理中发挥着重要作用,如提取语音信号的局部特征。
总之,深度学习在语音处理领域的崛起,克服了传统方法的不足,为实现更加智能、鲁棒的语音处理提供了新的解决方案。
二、深度神经网络(DNN)的应用
(一)声学模型建模
DNN 在声学模型中发挥着至关重要的作用。传统的高斯混合模型(GMM)在对语音信号进行建模时,存在一定的局限性。GMM 假设语音信号的分布是多个高斯分布的线性组合,对于复杂的语音信号,这种假设往往不够准确。而 DNN 则具有强大的特征提取和模式识别能力,能够更准确地对语音信号进行建模。
DNN 通过多层非线性变换,能够学习到语音信号中的复杂特征。例如,在语音识别中,DNN 可以学习到不同音素的特征,从而更准确地识别语音信号中的音素。此外,DNN 还可以学习到不同说话人的特征,提高语音识别的准确性和鲁棒性。
(二)语言模型建模
在语言模型中,DNN 也有着广泛的应用。传统的语言模型通常采用 n-gram 模型,这种模型假设当前单词的出现概率只与前面的 n-1 个单词有关。然而,这种假设在实际应用中往往不够准确,因为语言是一种复杂的序列数据,当前单词的出现概率可能与前面的多个单词甚至整个句子有关。
循环神经网络(如长短期记忆网络 LSTM)等模型能够更好地捕捉语音信号中的时序信息,从而更准确地预测下一个单词或音素。DNN 可以与循环神经网络相结合,构建更加复杂的语言模型。例如,可以使用 DNN 对语音信号进行特征提取,然后将提取到的特征输入到循环神经网络中进行语言建模。
(三)端到端语音识别
在端到端语音识别中,DNN 具有显著的优势。传统的语音识别系统通常由声学模型、语言模型和解码三个部分组成,每个部分都需要单独进行训练和优化,这使得整个系统的训练和优化过程非常复杂。而端到端语音识别系统则直接将语音信号转换为文本序列,无需中间的声学模型和语言模型,大大简化了系统的训练和优化过程。
DNN 在端到端语音识别中可以直接学习语音信号到文本序列的映射关系。通过大规模的训练数据和强大的计算能力,DNN 可以自动学习到语音信号中的复杂特征和语言规律,从而实现更加准确的语音识别。例如,在基于深度学习的端到端语音识别系统中,DNN 可以通过多层非线性变换,将语音信号中的声学特征和语言特征进行融合,从而直接输出文本序列。
三、卷积神经网络(CNN)的应用

(一)在语音识别中的应用
卷积神经网络在语音识别中的算法原理主要是通过卷积操作学习输入数据的特征表示。卷积层通过卷积操作将输入的语音数据转换为特征图,这个过程可以表示为:
其中, 是输入的语音数据, 是输出的特征图, 是卷积核, 和 是卷积核的大小。卷积操作可以自动学习语音信号中的局部特征,如频谱特征、时域特征等。池化层则通过采样操作减少特征图的大小并保留关键信息,进一步提高模型的效率和鲁棒性。全连接层将输入的特征图转换为输出的类别分数,实现语音识别的任务。激活函数引入非线性性,增强模型的表达能力。
(二)在唤醒词识别中的应用
反卷积技术在唤醒词识别中起着重要作用。在唤醒词识别的过程中,首先将输入的语音信号进行预处理,包括滤波、降噪、分帧等操作。然后将预处理后的语音信号输入到反卷积神经网络中,进行唤醒词特征提取。反卷积神经网络的核心在于将卷积操作的逆过程作为网络的基本操作,从而实现图像或语音信号的恢复、分类、识别等任务。数学模型公式为:
其中, 表示输出的唤醒词识别结果, 表示反卷积神经网络的参数, 表示输入的语音信号, 表示偏置项。最后,将反卷积神经网络输出的特征向量与唤醒词模板进行匹配,实现唤醒词识别。
(三)在音频处理中的应用
卷积神经网络在音频处理中的历史与发展经历了多个阶段。从 1980 年推出的第一个真正意义上的级联卷积神经网络 neocognitron,到 1989 年 Hinton 用于处理声音信号的卷积网络 TDNN,再到后来的 LeNet 网络以及如今广泛应用的基于卷积神经网络的音频处理系统。随着技术的不断发展,卷积神经网络逐渐能够自动学习更高级的音频特征和模式。
在音频处理中,CNN 可以通过对音频信号进行卷积操作,提取音频信号的特征表示。例如,可以学习音频信号的频谱特征、时域特征、频域特征等。通过池化层和全连接层的处理,可以对音频信号进行分类和识别,如音乐分类、对话识别、音效识别等。同时,CNN 还可以结合其他技术,如循环神经网络(RNN)、长短期记忆网络(LSTM)等,实现更加复杂的音频处理任务,如音频生成、音频合成等。
四、循环神经网络(RNN)的应用
(一)在语音识别中的应用
循环神经网络(RNN)非常适用于处理时间序列数据,在语音识别领域有着独特的优势。语音信号本身就是一种典型的时间序列数据,RNN 能够捕捉语音信号中的长时依赖关系。例如,在识别一个句子时,前面的单词对后面的单词有一定的影响,RNN 可以通过其记忆功能记住前面的信息,从而更好地理解整个句子的含义。
RNN 在语音识别中的工作原理是,在每个时间步接收输入的语音特征向量,并结合上一时刻的隐藏状态来更新当前时刻的隐藏状态。这个隐藏状态包含了过去的信息,能够为当前的识别任务提供上下文信息。通过不断地迭代这个过程,RNN 可以逐步处理整个语音信号,最终输出识别结果。
在实际应用中,长短期记忆网络(LSTM)和门控循环单元(GRU)等 RNN 的变体被广泛应用于语音识别。这些变体通过引入门控机制,有效地解决了传统 RNN 中存在的梯度消失和梯度爆炸问题,能够更好地捕捉长时依赖关系,提高语音识别的准确性。
(二)在语音合成中的应用
在语音合成中,RNN 发挥着重要的作用。其算法原理主要是通过学习大量的文本和对应的语音数据,建立从文本到语音的映射关系。具体来说,RNN 首先对输入的文本进行预处理,将其转换为一系列的特征向量。然后,RNN 以这些特征向量为输入,逐步生成连续的语音信号。
RNN 在语音合成中的一个关键步骤是学习语音的韵律特征。韵律特征包括语调、重音、节奏等,对于生成自然流畅的语音非常重要。RNN 可以通过对大量语音数据的学习,自动捕捉这些韵律特征,并在合成语音时加以应用。
例如,在基于 RNN 的端到端语音合成模型中,如 Tacotron 和 WaveGlow,RNN 可以直接将文本输入转换为语音波形。Tacotron 通过 RNN 架构结合注意力机制,能够准确地生成与输入文本对应的语音信号。WaveGlow 则利用 LSTM 等 RNN 变体,生成高质量的语音波形。
数学模型公式方面,以 Tacotron 为例,其生成过程可以表示为:
其中, 表示预测的概率分布; 表示概率分布的权重; 表示预测的标记序列。
总的来说,RNN 在语音合成中通过学习文本和语音的对应关系,能够生成自然流畅、富有韵律的语音信号,为语音合成技术的发展提供了强大的支持。
五、语音处理的数据预处理技术

(一)重要性阐述
数据预处理在语音处理中起着至关重要的作用。在提高语音识别准确率方面,通过有效的预处理可以去除噪声和干扰,优化语音信号的参数,使得语音特征更易于提取和识别,从而提高语音识别系统的准确率。例如,在嘈杂的环境中,经过预处理的语音信号能够减少背景噪声的影响,让系统更准确地识别出语音内容。
在提升交互体验方面,预处理可以优化语音信号的流畅度和清晰度。去除语音中的异常值和噪声,减少误识别和漏识别的情况,提高交互的准确性和流畅性。同时,预处理还能降低对硬件设备的要求,使得语音交互更加普及和便捷,例如在一些低性能的设备上也能实现较好的语音交互效果。
在拓展应用方面,预处理可以将语音数据转化为标准化的格式,有利于语音数据的应用和共享。通过预处理,可以扩展语音数据的应用领域,如语音识别、语音合成、语音情感分析等。此外,预处理可以促进语音数据与其他模态数据的融合,为人工智能提供更多元化的数据支持。
(二)数据清洗和标准化
在数据清洗方面,首先进行数据完整性检查。确保数据完整且无缺失,对于缺失的数据,可根据实际情况进行补充或删除。例如,如果是一段语音信号中有部分时间段没有声音数据,可以根据前后的声音特征进行合理的插值补充。
数据格式转换也是重要的一步。将不同格式的数据转换成统一的格式,以便于后续的分析处理。比如,不同来源的语音文件可能有不同的采样率和编码格式,需要将它们统一转换为适合处理的格式。
数据异常值处理同样关键。识别并处理数据中的异常值,以避免对分析结果造成不良影响。例如,在语音信号中,如果出现了异常高的振幅值,可能是由于设备故障或其他异常情况引起的,需要进行处理。
在标准化方面,数据规范化是将数据按照一定的规则进行缩放,使其落入一个小的特定区间,便于后续分析处理。例如,可以将语音信号的振幅值缩放到 [-1,1] 区间内。
数据归一化则是将数据缩放到 [0,1] 区间内,使得不同数据之间的比较更加直观和便捷。比如,将不同语音信号的能量值进行归一化处理,方便比较它们的相对强度。
标准化方法的选择需要根据数据的分布情况和实际需求进行。如最小 - 最大标准化、Z-score 标准化等方法各有适用场景。
(三)语音信号分帧和加窗
分帧是为了将连续的语音信号切割成一段段独立的帧,以便进行后续的语音处理。分帧的方法一般采用滑动窗口法,即设定一个固定长度的窗口,按照一定的步长滑动,每次滑动都将窗口内的语音信号作为一帧。
分帧的长度和步长的选择需要根据语音信号的特性和处理需求进行权衡。一般来说,如果分帧长度过短,可能无法充分包含语音信号的特征;如果分帧长度过长,又可能导致语音信号的变化被平均化,丢失一些细节信息。步长的选择也会影响到处理的效率和准确性。例如,在语音识别任务中,通常会根据语音信号的采样率和语音的特点选择合适的分帧长度和步长。一般在 8kHz 采样频率下,分帧长度可选择为 20-30ms,步长可以选择为 10ms。
加窗函数的作用是为了减少语音信号在分帧时出现的边缘效应和频谱泄漏现象,提高语音处理的准确性。常用的加窗函数包括矩形窗、汉宁窗、哈曼窗等。不同的加窗函数对语音信号的影响不同,需要根据具体需求进行选择。例如,矩形窗的谱平滑性能较好,但损失了高频成分,使波形细节丢失;而汉明窗则相反,从这一方面来看,汉明窗比矩形窗更为合适。
加窗函数的长度应与分帧的长度保持一致,以确保语音处理的准确性。加窗函数的选择会对语音信号的频谱产生影响,不同的加窗函数会导致不同的频谱失真和频率分辨率。加窗函数的长度和形状也会影响语音信号的能量分布和时域分辨率。
为了提高语音处理的准确性,可以采用一些优化措施来对分帧加窗进行处理。一种常见的优化方法是采用重叠分帧加窗,即相邻的帧之间有一定的重叠部分,以提高语音信号的连续性。例如,可以设置重叠率为 50%,这样可以更好地保留语音信号的过渡信息。
另外,也可以采用一些先进的加窗函数或自适应加窗方法来优化分帧加窗的效果。分帧加窗是语音处理中常用的技术手段,广泛应用于语音识别、语音合成、语音增强等领域。分帧加窗的有效性取决于语音信号的特性和处理需求,因此在实际应用中需要根据具体场景进行优化和调整。随着深度学习等新技术的发展,分帧加窗的方法也在不断更新和改进,为提高语音处理的性能和准确性提供了更多的可能性。
六、深度学习在语音处理中的实际应用案例
(一)智能语音助手
智能语音助手如 Siri、Google Assistant 和 Amazon Alexa 等,是深度学习在语音处理领域的典型应用。这些语音助手利用深度学习技术,实现了语音识别、语义理解和对话生成等功能。
在语音识别方面,深度学习模型如循环神经网络(RNN)和长短期记忆网络(LSTM)等,能够有效地捕捉语音信号中的长时依赖关系,提高语音识别的准确率。例如,当用户说出一句话时,智能语音助手可以准确地识别出语音内容,并将其转换为文本。
在语义理解方面,深度学习模型可以通过自然语言处理技术,将用户的语音指令转化为计算机可以理解的语义表示。例如,当用户说 “播放音乐” 时,智能语音助手可以理解用户的意图,并执行相应的操作。
在对话生成方面,深度学习模型可以通过学习大量的对话数据,生成自然流畅的对话内容。例如,当用户提出一个问题时,智能语音助手可以根据问题的内容,生成合适的回答。
此外,智能语音助手还可以通过个性化服务,为用户提供更加贴心的服务。例如,根据用户的历史记录和偏好,推荐音乐、电影或新闻等内容。
(二)语音翻译
语音翻译是深度学习在语音处理领域的另一个重要应用。语音翻译系统利用深度学习技术,实现了语音识别、语言翻译和语音合成等功能。
在语音识别方面,深度学习模型可以准确地识别出源语言的语音内容,并将其转换为文本。例如,当用户说出一句话时,语音翻译系统可以准确地识别出源语言的语音内容,并将其转换为文本。
在语言翻译方面,深度学习模型可以通过学习大量的双语语料库,实现源语言到目标语言的翻译。例如,当用户说出一句话时,语音翻译系统可以将源语言的文本内容翻译为目标语言的文本内容。
在语音合成方面,深度学习模型可以将目标语言的文本内容转换为语音信号,实现语音翻译的输出。例如,当用户说出一句话时,语音翻译系统可以将源语言的文本内容翻译为目标语言的文本内容,并将其转换为语音信号输出。
以中科金财申请的深度学习专利为例,该专利提出了一种基于深度学习的实时多语言处理的直播方法及系统,能够在保证翻译质量的同时,实现语音和弹幕的实时翻译。同时,通过音视频同步技术和唇形合成技术,解决了音画不同步和口型不匹配的问题。
综上所述,深度学习在智能语音助手和语音翻译等实际应用中,展现出了巨大的价值。通过深度学习技术,语音处理系统可以更加准确地识别语音内容、理解语义、生成自然流畅的对话内容和实现高质量的语音翻译,为用户提供更加便捷、高效的服务。
七、未来展望

(一)面临的挑战
- 提高准确性:虽然深度学习在语音处理中已经取得了显著的成果,但在一些复杂场景下,如嘈杂环境、多人同时说话等情况下,语音识别和合成的准确性仍有待提高。此外,不同口音、方言的识别也是一个挑战,需要更加智能的模型来适应各种语言变体。
- 降低计算复杂度:深度学习模型通常需要大量的计算资源和时间来训练和运行。随着语音处理应用的普及,尤其是在移动设备和嵌入式系统中的应用,需要开发更加高效的算法和模型,以降低计算复杂度,提高实时性。
- 数据隐私和安全:语音数据包含大量的个人信息,如何在利用深度学习进行语音处理的同时,确保数据的隐私和安全是一个重要的问题。需要开发更加安全的加密技术和数据管理方法,以保护用户的隐私。
(二)发展趋势
- 多模态融合:将语音与其他模态的数据,如图像、文本等进行融合,可以提供更多的信息,提高语音处理的准确性和鲁棒性。例如,结合唇语识别和语音识别,可以在嘈杂环境下提高语音识别的准确性。
- 模型压缩和优化:为了适应移动设备和嵌入式系统的需求,未来的发展趋势将是开发更加高效的模型压缩和优化技术,以减少模型的大小和计算量,提高实时性。
- 个性化定制:随着人工智能的发展,个性化服务将成为未来的趋势。在语音处理领域,可以根据用户的口音、语速、喜好等特点,为用户提供个性化的语音识别和合成服务。
- 跨语言处理:随着全球化的发展,跨语言语音处理将变得越来越重要。未来的深度学习模型将需要具备更强的跨语言处理能力,能够实现不同语言之间的语音识别、翻译和合成。
- 可解释性研究:深度学习模型通常被认为是黑箱模型,难以解释其决策过程。未来的研究将致力于提高深度学习模型的可解释性,以便更好地理解模型的工作原理,提高模型的可靠性和安全性。
总之,深度学习在语音处理领域具有广阔的发展前景。虽然面临着一些挑战,但随着技术的不断进步,相信未来的深度学习模型将能够更好地满足人们对语音处理的需求,为人们的生活和工作带来更多的便利。
八、总结和代码案例
深度学习在语音处理领域取得了显著的成就,为语音识别、语音合成、语音增强等任务提供了强大的解决方案。通过深度神经网络、卷积神经网络和循环神经网络等模型,能够从语音信号中提取特征并进行处理,提高了语音处理的准确性和鲁棒性。同时,数据预处理技术如采样、分帧、加窗等也为深度学习模型的应用提供了基础。在实际应用中,智能语音助手和语音翻译等案例展示了深度学习在语音处理领域的价值。
以下是一些代码案例:
案例一:使用 Python 的 TensorFlow 实现简单的语音识别
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam# 假设已经有预处理好的语音数据和标签
X_train, y_train, X_test, y_test =...# 构建模型
model = Sequential([Flatten(input_shape=(...)),Dense(128, activation='relu'),Dense(64, activation='relu'),Dense(len(set(y_train)), activation='softmax')
])# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))案例二:基于 PyTorch 的语音合成示例
import torch
import torch.nn as nn# 定义一个简单的语音合成模型
class VoiceSynthesizer(nn.Module):def __init__(self):super(VoiceSynthesizer, self).__init__()self.fc1 = nn.Linear(100, 256)self.fc2 = nn.Linear(256, 512)self.fc3 = nn.Linear(512, 1024)self.fc4 = nn.Linear(1024, 2048)self.fc5 = nn.Linear(2048, 4096)self.output_layer = nn.Linear(4096,...)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = torch.relu(self.fc3(x))x = torch.relu(self.fc4(x))x = torch.relu(self.fc5(x))return self.output_layer(x)model = VoiceSynthesizer()# 假设已经有输入数据和目标语音数据
input_data, target_voice =...# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(100):optimizer.zero_grad()output = model(input_data)loss = criterion(output, target_voice)loss.backward()optimizer.step()案例三:使用 Keras 的语音增强模型
from keras.models import Sequential
from keras.layers import Dense, Conv1D, MaxPooling1D, Flatten# 构建语音增强模型
model = Sequential([Conv1D(filters=32, kernel_size=3, activation='relu', input_shape=(...)),MaxPooling1D(pool_size=2),Conv1D(filters=64, kernel_size=3, activation='relu'),MaxPooling1D(pool_size=2),Flatten(),Dense(128, activation='relu'),Dense(64, activation='relu'),Dense(32, activation='relu'),Dense(..., activation='sigmoid')
])# 假设已经有带噪声的语音数据和纯净语音数据
noisy_data, clean_data =...# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy')# 训练模型
model.fit(noisy_data, clean_data, epochs=50, batch_size=32)九、本文相关学习资源

(一)学术论文推荐
- 《Deep Learning for Speech Recognition: An Overview》:这篇论文全面介绍了深度学习在语音识别中的应用,包括各种深度神经网络架构如 DNN、CNN 和 RNN 的详细阐述,以及它们在不同语音处理任务中的优势和挑战。
- 《Tacotron: Towards End-to-End Speech Synthesis》:深入探讨了基于循环神经网络的语音合成模型 Tacotron,对于理解 RNN 在语音合成中的应用具有重要价值。
- 《Convolutional Neural Networks for Speech Recognition》:专注于卷积神经网络在语音识别中的应用,分析了其算法原理和实际效果。
(二)在线课程平台
- Coursera:提供了多门与深度学习和语音处理相关的课程,如《深度学习专项课程》中包含了对语音处理应用的介绍。课程由知名大学教授和行业专家授课,通过视频讲解、作业和项目实践,帮助学习者系统地掌握深度学习在语音处理中的知识和技能。
- Udemy:有大量关于深度学习和语音技术的课程,涵盖从基础理论到实际应用的各个方面。例如,《Deep Learning for Audio and Speech Processing》课程详细讲解了如何使用深度学习算法处理音频和语音数据。
(三)开源项目和代码库
- Mozilla DeepSpeech:一个开源的语音识别项目,基于深度学习技术实现了高准确率的语音识别功能。它提供了预训练模型和代码示例,方便开发者进行二次开发和应用。
- TensorFlow Speech Recognition:TensorFlow 提供的语音识别工具包,包含了多种深度学习模型和算法,可以用于构建和训练自己的语音识别系统。
- PyTorch-Kaldi:结合了 PyTorch 和 Kaldi 两个强大的工具,为语音处理任务提供了高效的解决方案。它支持多种深度学习模型,并提供了丰富的功能和接口,方便开发者进行实验和研究。
通过利用这些学习资料,学习者可以更加系统地学习深度学习的知识和技术,提高自己的实践能力和创新能力。同时,也可以与其他学习者进行交流和互动,共同推动深度学习领域的发展。
博主还写跟本文相关的文章,邀请大家批评指正:
1、深度学习(一)基础:神经网络、训练过程与激活函数(1/10)
2、深度学习(二)框架与工具:开启智能未来之门(2/10)
3、深度学习(三)在计算机视觉领域的璀璨应用(3/10)
4、深度学习(四):自然语言处理的强大引擎(4/10)
5、深度学习(五):语音处理领域的创新引擎(5/10)
相关文章:
深度学习(五):语音处理领域的创新引擎(5/10)
一、深度学习在语音处理中的崛起 在语音处理领域,传统方法如谱减法、维纳滤波等在处理复杂语音信号时存在诸多局限性。这些方法通常假设噪声是平稳的,但实际噪声往往是非平稳的,导致噪声估计不准确。同时,为了去除噪声࿰…...
公式)
双曲函数(Hyperbolic functuons)公式
在python等语言里有双曲函数库和反双曲函数库,但是并没有包含所有的双曲函数。以numpy为例子,numpy只提供了sinh、cosh、tanh、arcsinh、arccosh、arctanh六种函数,那么其余的就需要用公式计算了。 转换公式 对于函数库不能直接计算的&#…...

【CSS/SCSS】@layer的介绍及使用方法
目录 基本用法layer 的作用与优点分离样式职责,增强代码可读性和可维护性防止无意的样式冲突精确控制样式的逐层覆盖提高复用性 兼容性实际示例:使用 import 管理加载顺序实际示例:混入与 layer 结合使用 layer 是 CSS 中用于组织和管理样式优…...

我为什么投身于青少年AI编程?——打造生态圈(三)
第五部分 青少年AI编程生态圈 一、生态圈 主要涵盖家庭、社区/中小学、高校高职、主管部门。 1、家庭 我们与社区/中小学一道打造让家长满意的模式。 教得好: 费用少: 家门口: 2、社区/中小学 社区党群服务中心和中小学都有大面积科普…...

出海要深潜,中国手机闯关全球化有了新标杆
经济全球化的大势之下,中国科技企业开拓海外市场已成为一种必然选择。 对于国内手机企业来说,推进全球商业版图扩张,业务潜力巨大,海外市场是今后的关键增长引擎。 当前中国手机厂商在海外市场的发展,有收获也有坎坷…...

百度SEO中的关键词密度与内容优化研究【百度SEO专家】
大家好,我是百度SEO专家(林汉文),在百度SEO优化中,关键词密度和关键词内容的优化对提升页面排名至关重要。关键词的合理布局与内容的质量是确保网页在百度搜索结果中脱颖而出的关键因素。下面我们将从关键词密度和关键…...

如何用fastapi集成pdf.js 的viewer.html ,并支持 mjs
fastapi 框架 集成pdf.js 的 viewer.html?file=***,支持跨域,支持.mjs .wasm .pdf 给出完整示例代码 要在 FastAPI 框架中集成 pdf.js 的 viewer.html,并支持跨域访问以及 .mjs、.wasm、.pdf 文件的正确加载,可以按照以下步骤进行。下面提供一个完整的示例,包括项目结构…...

文件相对路径与绝对路径
前言: 在写代码绘制图像的过程中,发现出现cant read input file的异常,而且输出框没有绘制图片,所以寻找解决方案。先贴上之前写的简洁版绘制图像代码 1.BackGround类 import java.awt.image.BufferedImage;public class BackG…...

Linux 重启命令全解析:深入理解与应用指南
Linux 重启命令全解析:深入理解与应用指南 在 Linux 系统中,掌握正确的重启命令是确保系统稳定运行和进行必要维护的关键技能。本文将深入解析 Linux 中常见的重启命令,包括功能、用法、适用场景及注意事项。 一、reboot 命令 功能简介 re…...

【北京迅为】《STM32MP157开发板嵌入式开发指南》-第六十七章 Trusted Firmware-A 移植
iTOP-STM32MP157开发板采用ST推出的双核cortex-A7单核cortex-M4异构处理器,既可用Linux、又可以用于STM32单片机开发。开发板采用核心板底板结构,主频650M、1G内存、8G存储,核心板采用工业级板对板连接器,高可靠,牢固耐…...

`a = a + b` 与 `a += b` 的区别
在 Java 中,a a b 和 a b 都用于将 b 的值加到 a 上,但它们之间存在一些重要的区别,尤其是在类型转换和操作行为方面。 使用 操作符时,Java 会自动进行隐式类型转换,而使用 则不会。这意味着在 a b 的情况下&am…...

mysqld.log文件过大,清理后不改变所属用户
#1024程序员节# 一、背景 突然有一天,我的mysql报磁盘不足了。仔细查看才发现,是磁盘满了。而MySQL的日志文件占用了91个G.如下所示: [roothost-172-16-14-128 mysql]# ls -lrth 总用量 93G -rw-r----- 1 mysql mysql 1.1G 7月 30 2023 m…...
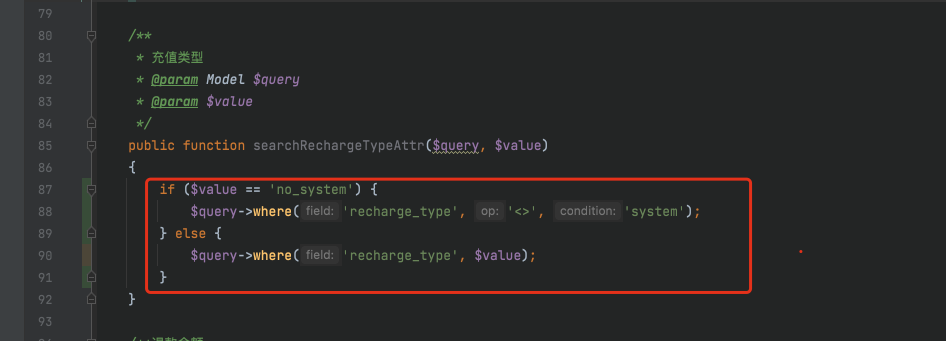
v4.7+版本用户充值在交易统计中计算双倍的问题修复
app/services/statistic/TradeStatisticServices.php 文件中 $whereInRecharge[recharge_type] no_system; $whereInRecharge[recharge_type] system; app/model/user/UserRecharge.php 中 修改此搜索器内容 public function searchRechargeTypeAttr($query, $value){ if…...

[GXYCTF 2019]Ping Ping Ping 题解(多种解题方式)
知识点: 命令执行 linux空格绕过 反引号绕过 变量绕过 base64编码绕过 打开页面提示 "听说php可以执行系统函数?我来康康" 然后输入框内提示输入 bjut.edu.cn 输入之后回显信息,是ping 这个网址的信息 输入127.0.0.1 因为提示是命令…...

MODSI EVI 数据的时间序列拟合一阶谐波模型
目录 简介 函数 ee.Reducer.linearRegression(numX, numY) Arguments: Returns: Reducer ee.Image.cat(var_args) Arguments: Returns: Image hsvToRgb() Arguments: Returns: Image 代码 结果 简介 MODIS/006/MOD13A1数据是由美国国家航空航天局(NASA)的MODIS…...

Java:String类(超详解!)
一.常用方法 🥏1.字符串构造 字符串构造有三种方法: 📌注意: 1. String是引用类型,内部并不存储字符串本身 如果String是一个引用那么s1和s3应该指向同一个内容,s1和s2是相等的,应该输出两…...

【日志】力扣13.罗马数字转整数 || 解决泛型单例热加载失败问题
2024.10.28 【力扣刷题】 13. 罗马数字转整数 - 力扣(LeetCode)https://leetcode.cn/problems/roman-to-integer/description/?envTypestudy-plan-v2&envIdtop-interview-150这题用模拟的思想可以给相应的字母赋值,官方的答案用的是用一…...

Mybatis高级
系列文章目录 高级Mybatis,一些结果映射,引入新的注解 目录 系列文章目录 文章目录 一、结果映射 1.ResultType 2.ResultMap 基础应用: 二、一对一 嵌套结果和嵌套查询 嵌套结果 嵌套查询 区别 三、一对多 四、多对多 五、注解补充 1.一对一…...

【spark】spark structrued streaming读写kafka 使用kerberos认证
spark版本:2.4.0 官网 Spark --files使用总结 Spark --files理解 一、编写jar import org.apache.kafka.clients.CommonClientConfigs import org.apache.kafka.common.config.SaslConfigs import org.apache.spark.sql.SparkSession import org.apache.spark.sql.streaming.T…...

【脚本】B站视频AB复读
控制台输入如下代码,回车 const video document.getElementsByTagName("video")[0];//获取bpx-player-control-bottom-center容器,更改其布局方式const div document.getElementsByClassName("bpx-player-control-bottom-center")[0];div.sty…...

Piccolo-FIM:DRAM细粒度访问优化技术解析
1. 现代DRAM架构的细粒度访问挑战在传统DRAM架构中,数据访问的最小单位通常是一个完整的行(Row),这种粗粒度的访问机制在处理图计算等不规则访问模式时暴露出了明显的效率问题。当需要随机访问内存中的离散数据时,系统…...

月薪8K到年薪80万!这个AI职位一年暴涨985%,普通人如何抓住风口?2026年最火爆的5个岗位+3条入场路径全解析!
文章讲述了AI Agent开发工程师的兴起,年薪可达80万。文章以小李的真实故事为例,展示了通过主动学习AI技术,可以实现职业的巨大转变。文章还分析了Agentic AI的特点及其对就业市场的影响,指出40%的岗位将被重新定义。文章列举了AI …...

Python 爬虫进阶技巧:JSON 数据多层嵌套解析取值技巧
前言 在现代网络数据采集场景中,JSON(JavaScript Object Notation)已成为前后端数据交互的核心格式,绝大多数动态网页、API 接口均采用多层嵌套 JSON 结构传输数据。对于爬虫开发者而言,基础的 JSON 取值仅能应对简单数据结构,而面对深度嵌套、数组嵌套、混合嵌套等复杂…...

工业控制中自定义串行总线协议的设计与实现:DataView系统实战
1. 项目背景与核心需求:为什么需要自定一个串行总线?在工业控制领域,尤其是信号调理模块和开关电源这类产品里,我们常常会遇到一个看似简单、实则棘手的问题:如何在有限的成本、空间和算力下,为多个分散的模…...

Snowflake Postgres、Lakebase、HorizonDB 登场,如何选“锁定”方案?
2026 年 5 月 12 日 阅读时长 4 分钟在过去的十二个月里,三家大型数据平台公司推出了具有自定义存储层和“横向扩展计算、共享存储”架构的 Postgres 风格数据库。Snowflake Postgres 已正式发布,它基于 Crunchy Data 团队的工作构建,以 pg_l…...

国产多模态大模型部署利器:深度解析陈天奇技术栈
国产多模态大模型部署利器:深度解析陈天奇技术栈 引言 在国产大模型“百模大战”的喧嚣浪潮中,我们的目光常常被那些能说会道、能文能图的多模态大模型本身所吸引。然而,一个同样关键却容易被忽视的问题是:如何让这些动辄数百亿…...

如何快速实现语音转文字:AsrTools 零配置音频转字幕工具指南
如何快速实现语音转文字:AsrTools 零配置音频转字幕工具指南 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio into acc…...

如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程
如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程 第一次用降AI工具会遇到很多不确定的地方——传什么格式、选哪个模式、怎么验收效果。 这篇教程把常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&…...

为什么83%的企业在2025年底紧急替换AI Agent?2026年必须升级的4个底层能力清单
更多请点击: https://intelliparadigm.com 第一章:为什么83%的企业在2025年底紧急替换AI Agent?2026年必须升级的4个底层能力清单 2025年Q3起,全球头部金融、制造与医疗企业集中触发AI Agent架构重构——Gartner最新调研显示&…...

从锡疫到无铅焊料失效:材料环境可靠性设计实战解析
1. 从拿破仑的纽扣说起:材料失效背后的工程警示在电子工程领域,我们每天都在与材料打交道。从PCB上的焊点,到芯片内部的金属互连,再到外壳的塑料,材料的可靠性直接决定了产品的成败。几年前,当整个行业因Ro…...