MMA: Multi-Modal Adapter for Vision-Language Models

两个观察
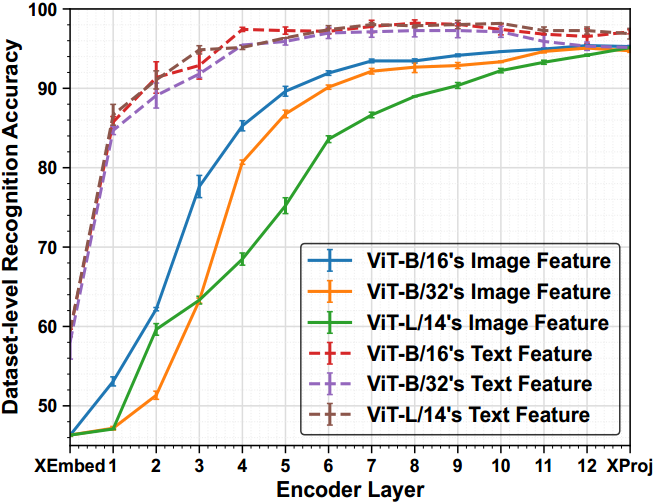
图1所示。各种基于transformer的CLIP模型中不同层的数据集级识别精度。这个实验是为了确定样本属于哪个数据集。我们用不同的种子运行了三次,并报告了每层识别精度的平均值和标准差。 X E m b e d XEmbed XEmbed是指变压器块之前的文本或图像嵌入层(即自关注层和前馈层[13]), X P r o j XProj XProj是指文本或图像投影层。注意,本实验仅使用来自所有数据集的训练样例进行评估。
如图1所示,我们有两个观测:
Observation-1。在预训练的文本和图像编码器中,较高的层包含可区分的数据集特定表示,而较低的层包含跨不同数据集的可通用表示。这些结果表明,为下游任务调整高层比低层更容易,冻结低层比高层可以保存更多的可泛化知识。
Observation-2。在大多数情况下,文本特征,因为它们是用语义类别名称编码的,在数据集中比视觉特征更容易区分。此外,低层的文本和图像特征之间的间隙比高层的更大。因此,我们认为在文本和图像特征之间对齐较低的层比在较高的层之间对齐更困难,特别是在有限的训练样本下进行调优。
Macro Design(宏观的设计)

新的适配器 A \mathcal{A} A(在下一节中详细介绍)被部分添加到图像和文本编码器的几个更高层中。形式上,对于图像编码器 V \mathcal{V} V,我们从第 k k k个transformer块中添加适配器 A v \mathcal{A}^v Av
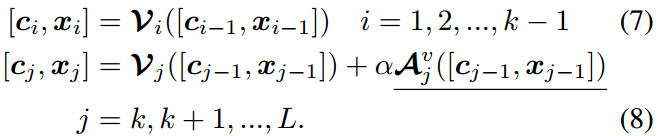
这里,下划线表示可训练的块。 α \alpha α是任务特定知识和一般预训练知识之间的平衡系数。显然, α = 0 \alpha=0 α=0在不集成任何额外知识的情况下退化为原始transformer块。同样,我们在文本编码器 τ \tau τ上增加适配器 A t \mathcal{A}^t At
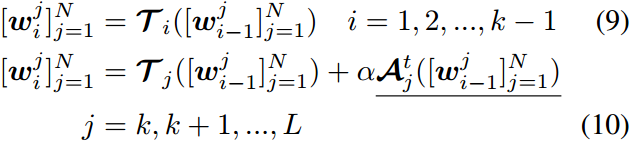
Micro Design(微观设计)
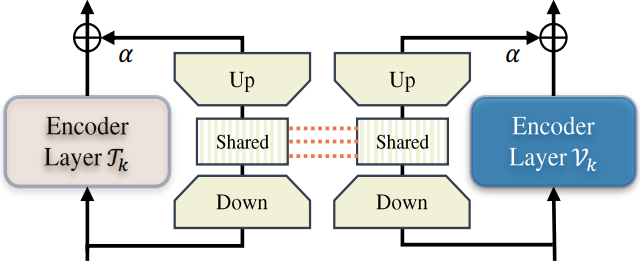
该单元首先使用单独的投影层将每个分支输入投影到具有相同尺寸的特征中。然后,使用一个共享投影层来聚合这些双峰信号,然后使用一个单独的层来匹配每个分支的输出维度。形式上,这个过程可以概括如下:
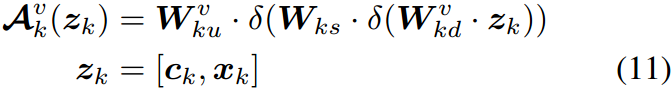
一个类似的过程被添加到文本编码器如下:
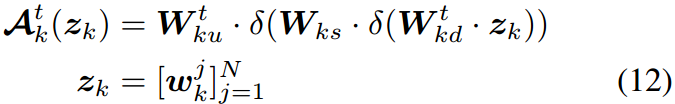
其中, W k w \bm W_{kw} Wkw和 W k d \bm W_{kd} Wkd是图所示的第 k k k个“上”和“下”投影层,其中模态分支用上标突出显示。 W k s \bm W_{ks} Wks是第 k k k个投影层,由Eq.(11)和Eq.(12)中的不同分支共享。重要的是,共享投影作为两个模态之间的桥梁,允许梯度相互传播,从而更好地对齐不同的模态信号。
实验
me:简单的改动,但效果真的很好啊。
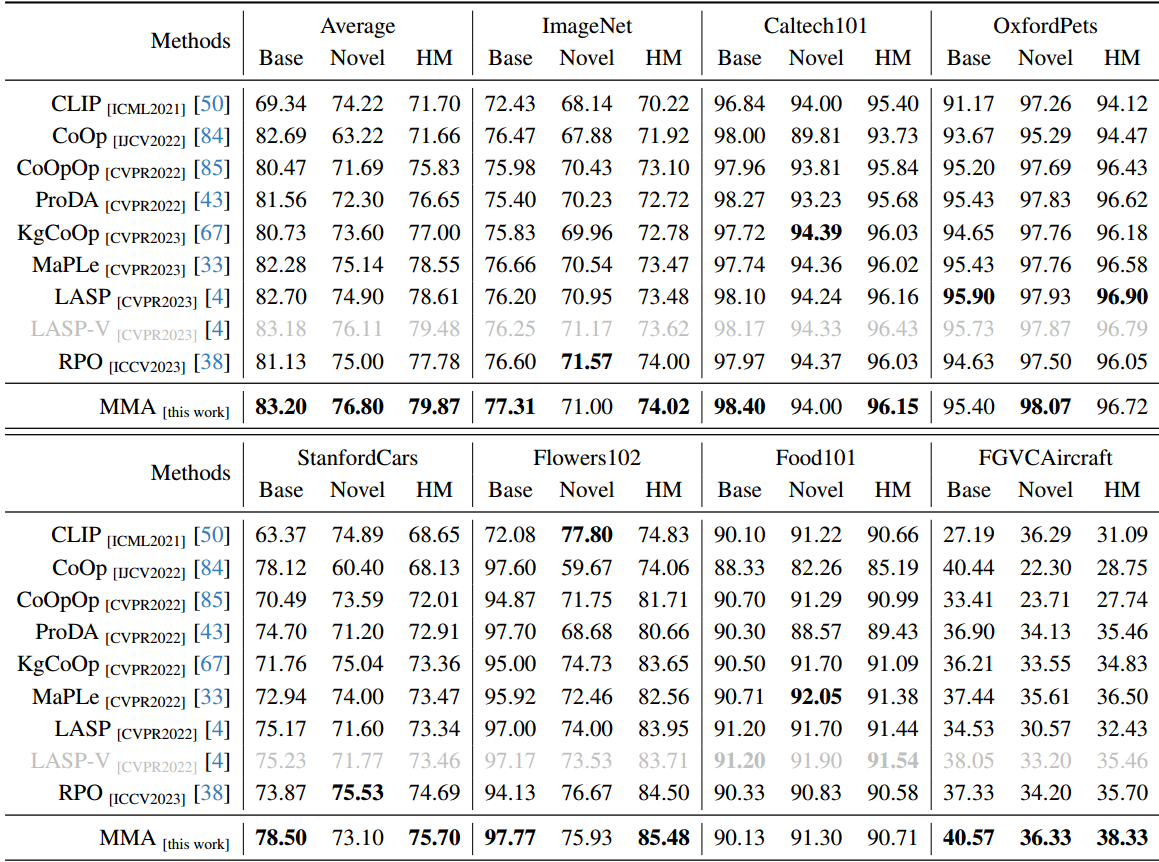
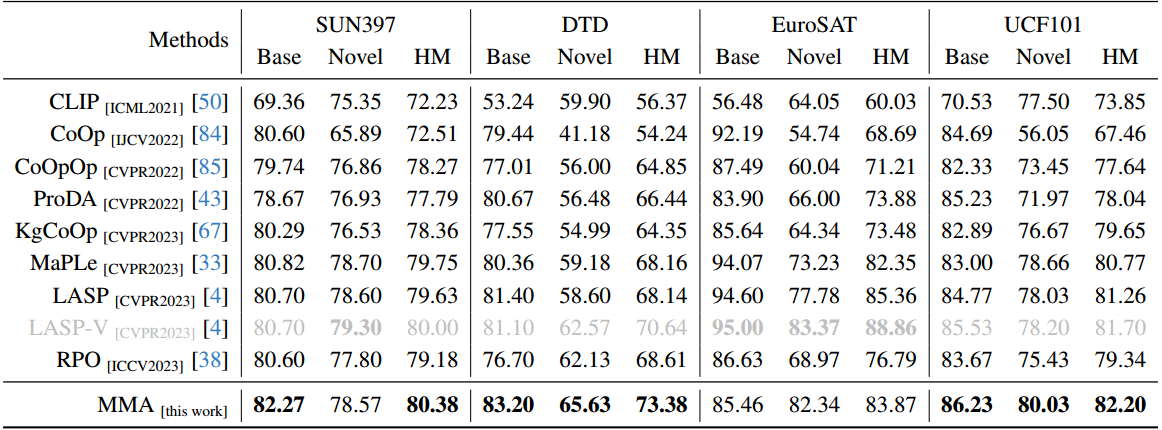
结论
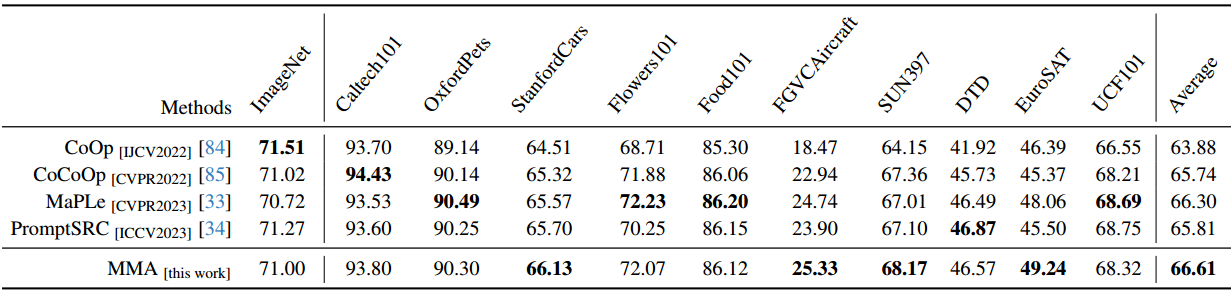
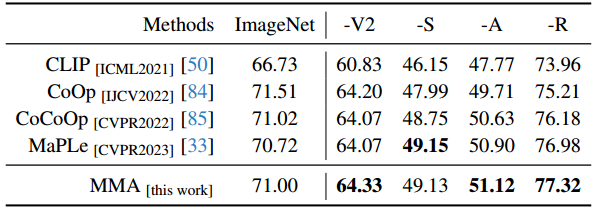
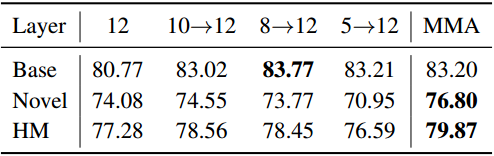
以CLIP为例[50]的大规模VLM对下游任务的适应提出了一个巨大的挑战,主要是因为可训练参数的数量庞大,而可用训练样本的规模有限。在本文中,我们提出了一种针对视觉和语言分支设计的多模态适配器(MMA),以增强其各自表示之间的一致性。我们系统地分析了视觉和语言分支跨数据集的特征的判别性和泛化性,因为这两个特征在迁移学习中起着重要的作用,特别是在少样本设置中。基于我们的分析,我们有选择地将MMA引入到特定的更高的transformer层,以实现区分和泛化之间的最佳平衡。我们通过三个代表性任务来评估我们方法的有效性:对新类别的泛化,对新目标数据集的适应,以及看不见的领域转移。与其他先进方法的比较表明,我们的综合性能在所有三种类型的评估中都取得了卓越的表现。
参考资料
论文下载(CVPR 2024)
https://openaccess.thecvf.com/content/CVPR2024/papers/Yang_MMA_Multi-Modal_Adapter_for_Vision-Language_Models_CVPR_2024_paper.pdf

代码地址
https://github.com/ZjjConan/Multi-Modal-Adapter
相关文章:
MMA: Multi-Modal Adapter for Vision-Language Models
两个观察 图1所示。各种基于transformer的CLIP模型中不同层的数据集级识别精度。这个实验是为了确定样本属于哪个数据集。我们用不同的种子运行了三次,并报告了每层识别精度的平均值和标准差。 X E m b e d XEmbed XEmbed是指变压器块之前的文本或图像嵌入层&#x…...
)
uniapp通过id获取div的宽度,高度,位置等(应该是 任意平台都通用 )
uniapp通过id获取div的宽度,高度,位置等(应该是 任意平台都通用 ) <template><view class"" id"domId"></view> </template>// 如果获取的dome高度等不对,还需要加上延迟…...

Python Transformer 模型的基本原理:BERT 和 GPT 以及它们在情感分析中的应用
Transformer 模型的基本原理:BERT 和 GPT 以及它们在情感分析中的应用 近年来,Transformer 模型在自然语言处理(NLP)领域取得了巨大成功,为任务如翻译、生成文本、问答和情感分析带来了显著的性能提升。本文将介绍 Tr…...

【云原生】Kubernets1.29部署StorageClass-NFS作为存储类,动态创建pvc(已存在NFS服务端)
文章目录 在写redis集群搭建的时候,有提到过使用nfs做storageclass,那时候kubernetes是1.20版本,https://dongweizhen.blog.csdn.net/article/details/130651727 现在使用的是kubernetes 1.29版本,根据之前的修改方式并未生效,反而提示:Error: invalid argument "Re…...

使用 Pandas 进行时间序列分析的 10个关键点
使用Pandas进行时间序列分析的10个关键点(由于篇幅限制,这里调整为10个,但实际操作中可能涉及更多细节)如下: 1. 创建时间序列数据 时间序列数据是指在多个时间点上形成的数值序列。在Pandas中,可以使用t…...

使用 Mermaid 语言描述 AGI 系统架构图
使用Mermaid语言描述AGI系统架构图 一、整体架构概述 以下是一个简化的AGI(Artificial General Intelligence,通用人工智能)系统架构的Mermaid描述。该系统主要包括数据收集与预处理、模型训练、推理与决策以及交互接口等模块,各…...

绘制线性可分支持向量机决策边界图 代码解析
### 绘制线性可分支持向量机决策边界图 def plot_classifer(model, X, y):# 超参数边界x_min -7x_max 12y_min -12y_max -1step 0.05# meshgridxx, yy np.meshgrid(np.arange(x_min, x_max, step),np.arange(y_min, y_max, step))# 模型预测z model.predict(np.c_[xx.ra…...

No.23 笔记 | WEB安全 - 任意文件漏洞 part 5
本文全面且深入地探讨了文件上传漏洞相关知识。从基础概念出发,清晰地阐述了文件上传漏洞的定义及其产生的本质原因,同时列出了该漏洞成立的必要条件。详细说明了文件上传漏洞可能对服务器控制权、网站安全以及业务运营带来的严重危害。 文中还深入解析了…...

EasyPlayer.js网页播放器,支持FLV、HLS、WebSocket、WebRTC、H.264/H.265、MP4、ts各种音视频流播放
EasyPlayer.js功能: 1、支持解码H.264视频(Baseline, Main, High Profile全支持,支持解码B帧视频) 2、支持解码H.265视频(flv id 12) 3、支持解码AAC音频(LC,HE,HEv2 Profile全支持) 4、支持解码MP3音频以及Speex音频格式 5、可…...

WPF数据绑定的五大模式
WPF(Windows Presentation Foundation)是微软推出的一种用于构建Windows用户界面的UI框架。它支持数据绑定,允许开发者将UI元素与数据源绑定,从而实现数据和界面的自动同步。WPF数据绑定有几种不同的模式, 以下是五种…...

从零到一:大学新生编程入门攻略与成长指南
文章目录 每日一句正能量前言编程语言选择:为大学新生量身定制Python:简单而强大的选择JavaScript:Web开发的基石Java:面向对象的经典C#:微软的全能选手 学习资源推荐:编程学习的宝藏在线课程教程和文档书籍…...

详细分析Pytorch中的transpose基本知识(附Demo)| 对比 permute
目录 前言1. 基本知识2. Demo 前言 原先的permute推荐阅读:详细分析Pytorch中的permute基本知识(附Demo) 1. 基本知识 transpose 是 PyTorch 中用于交换张量维度的函数,特别是用于二维张量(矩阵)的转置操…...

初识WebGL
思路: 构建<canvas>画布节点,获取其的实例。使用getWebGLContext() 拿到画布上下文。拿到上下文用clearColor() 设置背景颜色。最后清空canvas画布,是为了清除颜色缓冲区。 html结构: <!DOCTYPE html> <html lang"en&…...

【力扣】Go语言回溯算法详细实现与方法论提炼
文章目录 一、引言二、回溯算法的核心概念三、组合问题1. LeetCode 77. 组合2. LeetCode 216. 组合总和III3. LeetCode 17. 电话号码的字母组合4. LeetCode 39. 组合总和5. LeetCode 40. 组合总和 II小结 四、分割问题6. LeetCode 131. 分割回文串7. LeetCode 93. 复原IP地址小…...

「C/C++」C/C++ 之 第三方库使用规范
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...

六、元素应用CSS的习题
题目一: 使用CSS样式对页面元素加以修饰,制作“ 旅游攻略 ”网站。如下图所示 运行效果: 代码: <!DOCTYPE html> <html><head><meta charset"utf-8" /><title>旅游攻略</title><…...

正式入驻!上海斯歌BPM PaaS管理软件等产品入选华为云联营商品
近日,上海斯歌旗下BPM PaaS管理软件(NBS)等多款产品入选华为云云商店联营商品,上海斯歌正式成为华为云联营商品合作伙伴。用户登录华为云云商店即可采购上海斯歌的BPM PaaS产品及配套服务。通过联营模式,双方合作能够深…...

使用 Axios 上传大文件分片上传
背景 在上传大文件时,分片上传是一种常见且有效的策略。由于大文件在上传过程中可能会遇到内存溢出、网络不稳定等问题,分片上传可以显著提高上传的可靠性和效率。通过将大文件分割成多个小分片,不仅可以减少单次上传的数据量,降…...

Nginx+Lua脚本+Redis 实现自动封禁访问频率过高IP
1 、安装OpenResty 安装使用 OpenResty,这是一个集成了各种 Lua 模块的 Nginx 服务器,是一个以Nginx为核心同时包含很多第三方模块的Web应用服务器,使用Nginx的同时又能使用lua等模块实现复杂的控制。 (1)安装编译工具…...

PART 1 数据挖掘概论 — 数据挖掘方法论
目录 数据库知识发掘步骤 数据挖掘技术的产业标准 CRISP-DM SEMMA 数据库知识发掘步骤 数据库知识发掘(Knowledge Discovery in Database,KDD)是从数据库中的大量数据中发现不明显、之前未知、可能有用的知识。 知识发掘流程(Knowledge Discovery Process)包括属性选择…...
深度解析与高级部署方案)
Visual C++运行库合集(vcredist)深度解析与高级部署方案
Visual C运行库合集(vcredist)深度解析与高级部署方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库合集(vcredist)是解决Windows系统依赖问题的…...

茉莉花插件:重塑你的中文文献研究新范式
茉莉花插件:重塑你的中文文献研究新范式 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 作为一名学术研究者ÿ…...

AI编程套餐怎么选:别只看模型和额度,更要看你会不会被绑定
AI Coding 套餐已经不是单纯比模型强弱的时代。Copilot 改成按量计费,Claude 开始做身份验证,真正决定你成本和稳定性的,越来越不是“今天谁最强”,而是“明天规则变了,你还能不能无痛切走”。以前看模型,2…...

模拟芯片巨头Maxim 2010技术日深度解读:从工艺到应用的创新启示
1. 一场迟到的“技术盛宴”:深入解读Maxim 2010年编辑分析师日 在半导体行业,尤其是模拟芯片这个领域,巨头们的一举一动都牵动着整个产业链的神经。2010年9月底,模拟与混合信号半导体领域的“安静巨人”——Maxim Integrated&…...

ATF IronPython集成:如何在C应用中嵌入Python脚本引擎的完整指南
ATF IronPython集成:如何在C#应用中嵌入Python脚本引擎的完整指南 【免费下载链接】ATF Authoring Tools Framework (ATF) is a set of C#/.NET components for making tools on Windows. ATF has been in continuous development in Sony Computer Entertainments …...

把轻量接口做成真正可用的业务入口,聊透 ABAP HTTP Service Editor 的开发节奏
做 ABAP 集成时,经常会碰到这样一类需求,外部系统只想调用一个很轻的 URL,拿一段文本、一个健康检查结果、一个简单的回调响应,或者把某个小型业务动作推到 ABAP 后端里。这个时候,很多人脑子里冒出来的还是 RAP、Service Binding、Gateway,甚至直接跳到 SICF 手工找节点…...

SVG 滤镜:全面解析与高效应用
SVG 滤镜:全面解析与高效应用 引言 SVG(可缩放矢量图形)作为一种广泛使用的图形格式,因其具有高度的可缩放性和跨平台性而备受青睐。SVG 滤镜作为 SVG 的一项强大功能,能够实现丰富的图形效果,提升图形的表…...

Go语言CLI工具服务化:基于JSON-RPC的进程间通信与自动化集成
1. 项目概述与核心价值最近在折腾一些自动化流程和跨平台脚本时,遇到了一个挺有意思的需求:如何让一个用Go语言写的、功能强大的命令行工具,能够被其他语言(比如Python、Node.js)或者更上层的应用(比如Web界…...

App安全测试实战:OWASP ZAP 2.8 代理配置进阶与场景化应用
1. OWASP ZAP 2.8代理配置的核心价值 如果你做过移动应用安全测试,一定遇到过这样的困境:抓不到HTTPS流量、内网环境难以调试、自动化测试时代理频繁断开。这些问题看似简单,实际会浪费大量时间在环境搭建上。我在去年的一次金融App测试中&am…...

AI研发团队“隐性崩溃”前的9个信号:SITS2026追踪18个月的142起项目衰变案例全复盘
更多请点击: https://intelliparadigm.com 第一章:AI研发团队“隐性崩溃”的本质定义与SITS2026研究框架 什么是“隐性崩溃”? AI研发团队的“隐性崩溃”并非指系统宕机或项目终止,而是指团队在表观正常运转下,持续丧…...