什么是信息熵,什么是交叉熵,什么是KL散度?
什么是信息熵?
信息熵(Entropy)是信息论中的一个基本概念,用来衡量一个随机变量不确定性的大小。它反映了对一个事件结果的预测难度,或者说是描述这个事件需要多少“信息量”。信息熵是由香农(Claude Shannon)提出的,信息熵的大小越高,代表事件结果的不确定性越大,反之则越小。
1. 信息熵的定义
给定一个离散的随机变量 X X X,它有 n n n 个可能的取值( x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn),每个取值的概率分别为 p ( x 1 ) , p ( x 2 ) , … , p ( x n ) p(x_1), p(x_2), \dots, p(x_n) p(x1),p(x2),…,p(xn)。则信息熵 H ( X ) H(X) H(X) 的定义为:
H ( X ) = − ∑ i = 1 n p ( x i ) log 2 p ( x i ) H(X) = -\sum_{i=1}^n p(x_i) \log_2 p(x_i) H(X)=−i=1∑np(xi)log2p(xi)
其中:
- p ( x i ) p(x_i) p(xi) 表示事件 x i x_i xi 发生的概率。
- log 2 p ( x i ) \log_2 p(x_i) log2p(xi) 表示事件发生所带来的“信息量”,它是概率的负对数,概率越低,信息量越大。
- 信息熵的单位是比特(bit),在公式中使用对数底数为2。
2. 信息熵的直观解释
信息熵描述的是不确定性:如果一个事件的结果很确定,信息熵就会很小;如果事件的结果不确定性很高,则信息熵会较大。以抛硬币和掷骰子为例:
- 公平的硬币:抛硬币有两种可能结果(正面、反面),概率均为 0.5。此时信息熵为:
H ( X ) = − ( 0.5 log 2 0.5 + 0.5 log 2 0.5 ) = 1 比特 H(X) = - (0.5 \log_2 0.5 + 0.5 \log_2 0.5) = 1 \text{ 比特} H(X)=−(0.5log20.5+0.5log20.5)=1 比特
也就是说对于这枚硬币,我们在没有额外信息的情况下是很难预测到底抛硬币后是正面朝上还是反面朝上。
- 不公平的硬币:如果硬币不公平,正面概率为 0.9,反面概率为 0.1。此时的信息熵较小,因为我们几乎可以预测结果(总是正面)。计算得:
H ( X ) = − ( 0.9 log 2 0.9 + 0.1 log 2 0.1 ) ≈ 0.47 比特 H(X) = - (0.9 \log_2 0.9 + 0.1 \log_2 0.1) \approx 0.47 \text{ 比特} H(X)=−(0.9log20.9+0.1log20.1)≈0.47 比特
因此,不公平的硬币的信息熵小于公平硬币,这表明预测其结果的不确定性较低。这枚硬币相较于公平硬币而言,更容易猜出结果(肯定会首先猜测证明朝上),就说明紊乱程度低,自然信息熵就低。
3. 信息熵的特性
信息熵的几个重要特性包括:
- 非负性:信息熵总是非负的,且 H ( X ) ≥ 0 H(X) \geq 0 H(X)≥0。当随机变量 X X X 的结果完全确定时,信息熵 H ( X ) = 0 H(X) = 0 H(X)=0。
- 最大化:对于一个有 n n n 个可能取值的离散均匀分布,信息熵最大。也就是说,当每个事件的概率相等时,不确定性达到最大。例如,对于一个6面骰子,每个面出现的概率都是 1 6 \frac{1}{6} 61,此时信息熵最大。
- 加法性:对于多个独立事件,其联合熵为各个事件的熵的和。即如果 X X X 和 Y Y Y 是两个独立随机变量,那么 H ( X , Y ) = H ( X ) + H ( Y ) H(X, Y) = H(X) + H(Y) H(X,Y)=H(X)+H(Y)。
4. 信息熵的计算示例
假设有一个数据集 D D D,包含5个样本,用于预测某人是否会外出。其中有3个样本为“是”(外出),2个样本为“否”(不外出)。计算熵:
- 样本中“是”事件的概率: p ( 是 ) = 3 5 p(是) = \frac{3}{5} p(是)=53
- 样本中“否”事件的概率: p ( 否 ) = 2 5 p(否) = \frac{2}{5} p(否)=52
熵 H ( D ) H(D) H(D) 的计算如下:
H ( D ) = − ( 3 5 log 2 3 5 + 2 5 log 2 2 5 ) H(D) = - \left( \frac{3}{5} \log_2 \frac{3}{5} + \frac{2}{5} \log_2 \frac{2}{5} \right) H(D)=−(53log253+52log252)
通过计算,得到:
H ( D ) ≈ 0.971 比特 H(D) \approx 0.971 \text{ 比特} H(D)≈0.971 比特
这表示在给定数据集 D D D 的情况下,每次对“是否外出”进行预测时,大约需要 0.971 比特的信息来消除不确定性。
KL散度(Kullback-Leibler Divergence),也可以被叫做相对熵,是一种用于衡量两个概率分布之间差异的非对称度量。在信息论和机器学习中,KL散度广泛用于评估一个分布相对于另一个分布的“信息丢失”程度。或者也可以认为,KL散度用于衡量真实分布与近似分布之间的差异,或计算两个分布之间的信息距离。
什么是KL散度?
1. KL散度的定义
给定两个概率分布 P P P 和 Q Q Q,其中 P P P 通常是数据的真实分布, Q Q Q 是用来近似 P P P 的分布(例如模型分布或者预测分布),KL散度 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 的数学表达式为:
D K L ( P ∥ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) D_{KL}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)logQ(x)P(x)
或对于连续分布,则为积分形式:
D K L ( P ∥ Q ) = ∫ P ( x ) log P ( x ) Q ( x ) d x D_{KL}(P \parallel Q) = \int P(x) \log \frac{P(x)}{Q(x)} \, dx DKL(P∥Q)=∫P(x)logQ(x)P(x)dx
其中:
- P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x) 分别是两个分布在点 x x x 的概率值。
- log P ( x ) Q ( x ) \log \frac{P(x)}{Q(x)} logQ(x)P(x) 表示 P P P 相对于 Q Q Q 的信息增益。(信息增益表示在某个条件下,数据的熵(不确定性)减少的量。)
2. KL散度的直观解释
KL散度可以理解为:在给定分布 Q Q Q 的情况下,使用分布 P P P 需要多大的“信息量”或“信息代价”来描述或编码数据。KL散度越大,表示分布 P P P 和分布 Q Q Q 越不相似。
例如:
- 当 P P P 和 Q Q Q 完全一致时,KL散度 D K L ( P ∥ Q ) = 0 D_{KL}(P \parallel Q) = 0 DKL(P∥Q)=0。
- 当 P P P 和 Q Q Q 有明显差异时,KL散度会是一个较大的正值。
- 由于 KL 散度不对称,所以 D K L ( P ∥ Q ) ≠ D K L ( Q ∥ P ) D_{KL}(P \parallel Q) \neq D_{KL}(Q \parallel P) DKL(P∥Q)=DKL(Q∥P)。
3. KL散度的特性
- 非负性: D K L ( P ∥ Q ) ≥ 0 D_{KL}(P \parallel Q) \geq 0 DKL(P∥Q)≥0。当且仅当 P = Q P = Q P=Q 时, D K L ( P ∥ Q ) = 0 D_{KL}(P \parallel Q) = 0 DKL(P∥Q)=0。这称为信息论中的 Gibbs 不等式。
- 非对称性:KL散度并不对称,即 D K L ( P ∥ Q ) ≠ D K L ( Q ∥ P ) D_{KL}(P \parallel Q) \neq D_{KL}(Q \parallel P) DKL(P∥Q)=DKL(Q∥P)。这也意味着它不能作为真正的“距离度量”,因为距离度量一般要求对称性。
- 信息增益:KL散度度量的是当用分布 Q Q Q 来替代分布 P P P 时,信息的额外损失。它描述了我们在使用 Q Q Q 来代替 P P P 时,丢失的“信息量”。
4. KL散度的计算实例
假设有两个离散分布 P P P 和 Q Q Q:
- P P P: P ( x = 1 ) = 0.4 P(x=1)=0.4 P(x=1)=0.4, P ( x = 2 ) = 0.6 P(x=2)=0.6 P(x=2)=0.6
- Q Q Q: Q ( x = 1 ) = 0.5 Q(x=1)=0.5 Q(x=1)=0.5, Q ( x = 2 ) = 0.5 Q(x=2)=0.5 Q(x=2)=0.5
KL散度计算如下:
D K L ( P ∥ Q ) = 0.4 log 0.4 0.5 + 0.6 log 0.6 0.5 D_{KL}(P \parallel Q) = 0.4 \log \frac{0.4}{0.5} + 0.6 \log \frac{0.6}{0.5} DKL(P∥Q)=0.4log0.50.4+0.6log0.50.6
通过计算可以得到:
D K L ( P ∥ Q ) = 0.4 × ( − 0.263 ) + 0.6 × 0.176 = − 0.1052 + 0.1056 ≈ 0.0004 D_{KL}(P \parallel Q) = 0.4 \times (-0.263) + 0.6 \times 0.176 = -0.1052 + 0.1056 \approx 0.0004 DKL(P∥Q)=0.4×(−0.263)+0.6×0.176=−0.1052+0.1056≈0.0004
说明分布 P P P 和 Q Q Q 的差异很小。
其实就好比两个数字比较差异,我们会将他们相减,如果减出来=0说明二者相等,而KL散度就是把数字的差异放在了分布的差异上,两个分布(两个数字)差异性越大,那么KL散度(数字的差值)越大,代表二者越不相似。
什么是交叉熵?
讲完KL散度和信息熵,我们再引入交叉熵(Cross Entropy),它是用来度量两个概率分布之间的相似性的。在机器学习和深度学习中,交叉熵损失函数是用于分类任务的常用损失函数,通过计算真实分布和预测分布之间的差异,帮助模型更好地拟合数据。
1. 交叉熵的定义
给定两个概率分布 P P P 和 Q Q Q:
- P P P 表示真实分布(例如,数据的标签分布)。
- Q Q Q 表示预测分布(例如,模型的输出概率分布)。
交叉熵 H ( P , Q ) H(P, Q) H(P,Q) 的定义是:
H ( P , Q ) = − ∑ x P ( x ) log Q ( x ) H(P, Q) = -\sum_{x} P(x) \log Q(x) H(P,Q)=−x∑P(x)logQ(x)
在这个公式中:
- x x x 表示数据样本的取值。
- P ( x ) P(x) P(x) 是样本在真实分布中的概率。
- Q ( x ) Q(x) Q(x) 是样本在预测分布中的概率。
交叉熵度量了真实分布 P P P 下观测到数据点时的“平均信息量”,而这种信息量是基于模型提供的预测分布 Q Q Q 来计算的。交叉熵越小,表示 Q Q Q 与 P P P 越接近;交叉熵越大,表示 Q Q Q 与 P P P 越不接近。
2. 交叉熵与熵和KL散度的关系
交叉熵可以拆解为熵和KL散度之和:
H ( P , Q ) = H ( P ) + D K L ( P ∥ Q ) H(P, Q) = H(P) + D_{KL}(P \parallel Q) H(P,Q)=H(P)+DKL(P∥Q)
其中:
- H ( P ) H(P) H(P) 是数据真实分布 P P P 的熵,表示在真实分布下系统的不确定性。
- D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 是KL散度,表示分布 Q Q Q 相对于分布 P P P 的“信息损失”或“信息差异”。
这说明交叉熵实际上是熵和KL散度的组合。当 Q Q Q 和 P P P 越接近时,KL散度 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 越小,交叉熵也就越接近 H ( P ) H(P) H(P) 的最小值。
3. 交叉熵在分类中的应用
在机器学习中,交叉熵损失函数用于二分类和多分类任务:
(1)二分类交叉熵
对于一个二分类问题,真实标签 y y y 可以是0或1,模型的预测概率为 y ^ \hat{y} y^,则二分类的交叉熵损失为:
H ( y , y ^ ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] H(y, \hat{y}) = -[y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})] H(y,y^)=−[ylog(y^)+(1−y)log(1−y^)]
- 当真实标签 y = 1 y = 1 y=1 时,损失为 − log ( y ^ ) -\log(\hat{y}) −log(y^),即预测值 y ^ \hat{y} y^ 越接近1,损失越小。
- 当真实标签 y = 0 y = 0 y=0 时,损失为 − log ( 1 − y ^ ) -\log(1 - \hat{y}) −log(1−y^),即预测值 y ^ \hat{y} y^ 越接近0,损失越小。
这种损失函数逼迫模型输出的概率接近真实标签,从而提升模型的分类效果。
(2)多分类交叉熵
对于一个有 k k k 类的多分类问题,使用 softmax 函数输出每个类别的概率预测 y ^ i \hat{y}_i y^i,真实标签用 one-hot 编码表示,交叉熵损失为:
H ( y , y ^ ) = − ∑ i = 1 k y i log ( y ^ i ) H(y, \hat{y}) = -\sum_{i=1}^k y_i \log(\hat{y}_i) H(y,y^)=−i=1∑kyilog(y^i)
其中 y i y_i yi 是真实类别的 one-hot 编码(即正确类别对应的概率为1,其余类别为0), y ^ i \hat{y}_i y^i 是模型对第 i i i 类的预测概率。
4. 交叉熵的直观理解
交叉熵可以理解为一个度量模型预测与真实标签之间相似度的指标。当模型预测接近真实分布 P P P 时,交叉熵的值较小;当模型预测偏离真实分布 P P P 时,交叉熵的值较大。因此,通过最小化交叉熵损失,模型能够更好地匹配真实标签的分布。
例如,在图像分类任务中:
- 如果图像真实类别为“猫”,且模型预测也为“猫”且概率接近1,则交叉熵损失较小,表明预测准确。
- 如果图像真实类别为“猫”,但模型预测为“狗”且概率较高,则交叉熵损失较大,表明预测不准确,模型需要优化。
5. 交叉熵的性质
- 非负性:交叉熵总是非负的。
- 最小化:交叉熵最小化目标就是让预测分布 Q Q Q 尽量接近真实分布 P P P。
- 非对称性:交叉熵对 P P P 和 Q Q Q 的顺序敏感, H ( P , Q ) ≠ H ( Q , P ) H(P, Q) \neq H(Q, P) H(P,Q)=H(Q,P)。
交叉熵和KL散度都可以用于衡量两个概率分布之间差异,那到底有什么区别?
1. 定义和公式上的差异
- 交叉熵 H ( P , Q ) H(P, Q) H(P,Q):
交叉熵衡量的是在真实分布 P P P 下,使用预测分布 Q Q Q 来编码数据所需要的信息量。其公式为:
H ( P , Q ) = − ∑ x P ( x ) log Q ( x ) H(P, Q) = -\sum_{x} P(x) \log Q(x) H(P,Q)=−x∑P(x)logQ(x)
- KL散度 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q):
KL散度表示的是真实分布 P P P 与预测分布 Q Q Q 之间的相对熵,或说 Q Q Q 相对 P P P 的信息损失。其公式为:
D K L ( P ∥ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) D_{KL}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)logQ(x)P(x)
2. 数学关系
交叉熵和KL散度通过以下关系联系起来:
H ( P , Q ) = H ( P ) + D K L ( P ∥ Q ) H(P, Q) = H(P) + D_{KL}(P \parallel Q) H(P,Q)=H(P)+DKL(P∥Q)
其中:
- 熵 H ( P ) H(P) H(P) 是真实分布 P P P 自身的熵,表示在没有近似分布时,描述数据本身所需的最少信息量。
- KL散度 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 表示的是用 Q Q Q 替代 P P P 带来的额外信息量。
因此,交叉熵可以看作是“熵 + KL散度”,即在使用分布 Q Q Q 进行编码时所需要的额外信息量,而 KL散度单独度量的是使用 Q Q Q 而非 P P P 带来的信息丢失。
3. 意图和用途的差异
- 交叉熵用于度量模型的预测效果。它不仅仅关注两个分布的差异,而是考虑整个预测分布 Q Q Q 对真实分布 P P P 的匹配程度。交叉熵在模型训练时常用作损失函数,通过最小化交叉熵,使得模型输出的预测分布尽可能接近真实分布。
- KL散度关注的是“差异性”本身,用于量化两个分布之间的“相对距离”或“信息损失”。它在变分推断、贝叶斯方法、信息理论等场景中广泛应用,以便衡量模型分布(如 Q Q Q)和目标分布(如 P P P)的相似性,帮助约束模型参数。
4. 总结
- 交叉熵:偏向实际模型的优化,通过衡量预测结果相对于真实标签的“信息量”来训练模型。
- KL散度:偏向分析两个分布之间的差异性,用来度量模型分布与目标分布的接近程度,通常作为“相对差异”的参考指标。
总结一下:交叉熵更关注信息量的实际消耗,而KL散度更关注两个分布之间的相对信息损失。
相关文章:

什么是信息熵,什么是交叉熵,什么是KL散度?
什么是信息熵? 信息熵(Entropy)是信息论中的一个基本概念,用来衡量一个随机变量不确定性的大小。它反映了对一个事件结果的预测难度,或者说是描述这个事件需要多少“信息量”。信息熵是由香农(Claude Shan…...
开发者的福音:PyTorch 2.5现已支持英特尔独立显卡训练
《PyTorch 2.5重磅更新:性能优化新特性》中的一个新特性就是:正式支持在英特尔独立显卡上训练模型! PyTorch 2.5 独立显卡类型 支持的操作系统 Intel 数据中心GPU Max系列 Linux Intel Arc™系列 Linux/Windows 本文将在IntelCore™…...

Deep InfoMax(DIM)(2019-02-ICLR)
论文:LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION ABSTRACT 研究目标 研究通过最大化输入和深度神经网络编码器输出之间的互信息来进行无监督表示学习目的是学习到对下游任务有用的特征表示 核心发现:结构很重…...

2024年10月中国数据库排行榜:TiDB续探花,GaussDB升四强
10月中国数据库流行度排行榜如期发布,再次印证了市场分层的加速形成。国家数据库测评结果已然揭晓,本批次通过的产品数量有限,凸显了行业标准的严格与技术门槛的提升。再看排行榜,得分差距明显增大,第三名与后续竞争者…...

css边框修饰
一、设置线条样式 通过 border-style 属性设置,可选择的一些属性如下: dotted:点线 dashed:虚线 solid:实线 double:双实线 效果如下: 二、设置边框线宽度 ① 通过 border-width 整体设置…...

利用Python进行数据可视化:实用指南与推荐库
利用Python进行数据可视化:实用指南与推荐库 数据可视化是将数据转化为图形和图表的过程,它能够帮助我们更直观地理解数据的趋势、模式和关系。在Python中,有许多强大的库可用于数据可视化,从简单的折线图到复杂的交互式图表,应有尽有。本文将详细介绍Python数据可视化的…...

MobileNetv2网络详解
背景: MobileNet v1中DW卷积在训练完之后部分卷积核会废掉,大部分参数为“0” MobileNet v2网络是由Google团队在2018年提出的,相比于MobileNet v1网络,准确率更高,模型更小 网络亮点: Inverted Residu…...

惊了!大模型连这样的验证码都能读懂_java_识别验证码
最近在看视觉大模型的能力,然后用了某网站的一个验证码试了试,竟然连这样的验证码都能认识,这个有点夸张,尤其是这个9和6颠倒的都能理解,现在的能力已经这么牛了么 具体就是用了通义最新的qwen vl模型spring ai alibab…...
【小白学机器学习26】 极大似然估计,K2检验,logit逻辑回归(对数回归)(未完成----)
目录 1 先从一个例题出来,预期值和现实值的差异怎么评价? 1.1 这样一个问题 1.2 我们的一般分析 1.3 用到的关键点1 1.4 但是差距多远,算是远呢? 2 极大似然估计 2.1 极大似然估计的目的 2.1.1 极大似然估计要解决什么问题…...

【日常记录-Java】SLF4J扫描实现框架的过程
1. 简介 SLF4J(Simple Logging Facade for Java)作为一种简单的门面或抽象,服务于其他各种日志框架,例如JUL、log4j、logback等,核心作用有两项: 提供日志接口;提供获取具体日志对象的方法; 2. 扫描过程 …...

uni-app 获取 android 手机 IMEI码
1、需求来源 最近项目上需要获取手机的IMEI码,并且在更换手机号登录后,需要提示重新更新IMEI码。 2、需求拆分 2.1 获取 IMEI 码 查阅 uni-app 官网发现在android 10 已经无法获取imei码,所以对于这个需求拆分成两种情况。 第一种情况&am…...
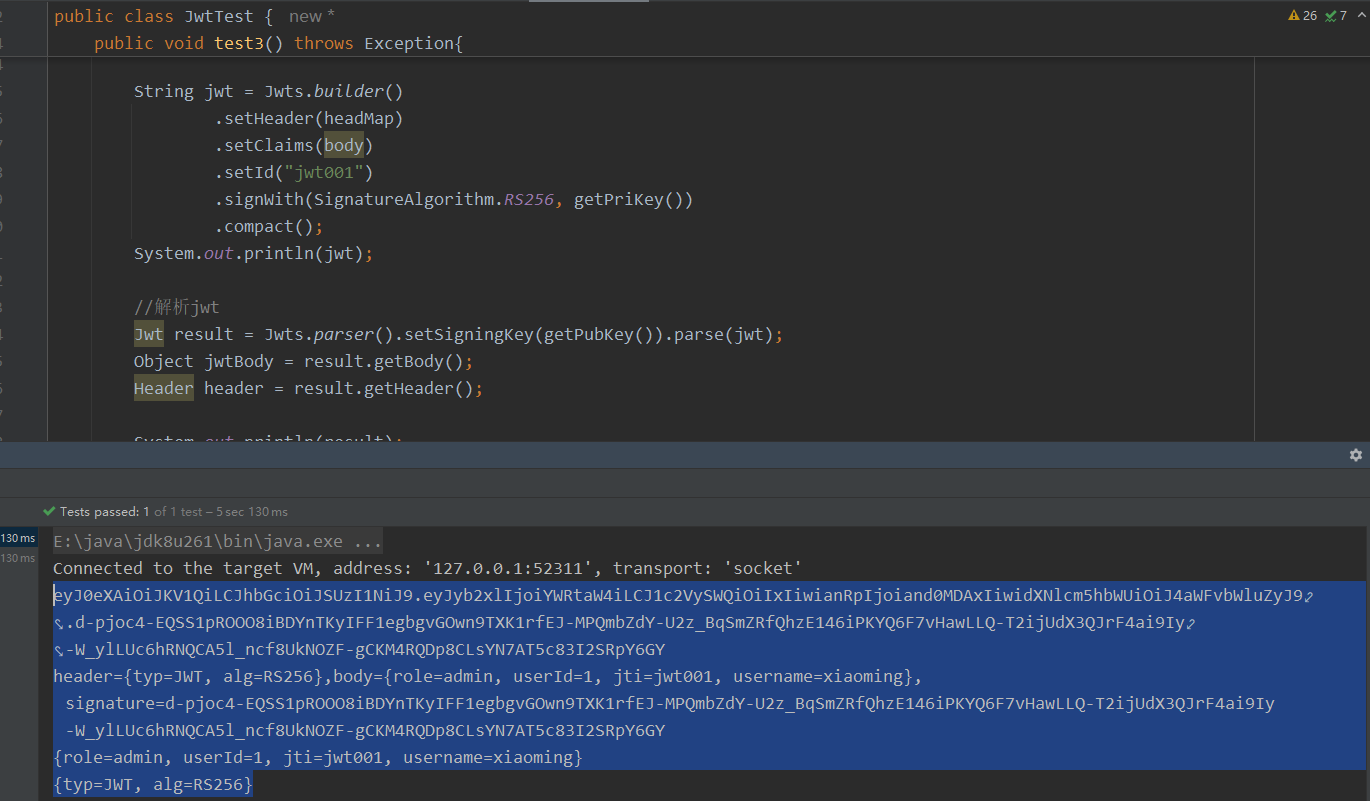
后台管理系统的通用权限解决方案(八)认证机制介绍、JWT介绍与jjwt框架的使用
文章目录 1 认证机制介绍1.1 HTTP Basic Auth1.2 Cookie-Session Auth1.3 OAuth1.4 Token Auth 2 JWT2.1 JWT介绍2.2 JWT的数据结构2.2.1 JWT头2.2.2 JWT有效载荷2.2.3 JWT签名 3 jjwt3.1 jjwt介绍3.2 jjwt案例 1 认证机制介绍 1.1 HTTP Basic Auth HTTP Basic Auth 是一种简…...

接口测试 —— Postman 变量了解一下!
Postman变量是在Postman工具中使用的一种特殊功能,用于存储和管理动态数据。它们可以用于在请求的不同部分、环境或集合之间共享和重复使用值。 Postman变量有以下几种类型: 1、环境变量(Environment Variables): 环境变量是在…...

鸿蒙系统:核心特性、发展历程与面临的机遇与挑战
好动与不满足是进步的第一必需品 文章目录 前言重要特点和组成部分核心特性主要组件发展历程 机遇挑战总结 前言 鸿蒙系统(HarmonyOS)是由华为技术有限公司开发的一款面向全场景的分布式操作系统。它旨在为用户提供更加流畅、安全且高效的数字生活体验&…...
从0到1,用Rust轻松制作电子书
我之前简单提到过用 Rust 做电子书,今天分享下如何用Rust做电子书。制作电子书其实用途广泛,不仅可以用于技术文档(对技术人来说非常方便),也可以制作用户手册、笔记、教程等,还可以应用于文学创作。 如果…...

半天入门!锂电池剩余寿命预测(Python)
往期精彩内容: 时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 全是干货 | 数据集、学习资料、建模资源分享! EMD变体分解效果最好算法——CEEMDAN(五)-CSDN博客 拒绝信息泄露!VMD滚动分…...

学生党头戴式耳机哪款音质更胜一筹?TOP4好音质头戴式耳机推荐
在挑选头戴式耳机时,市场上琳琅满目的品牌和型号常常让人目不暇接。究竟哪个学生党头戴式耳机哪款音质更胜一筹?这已成为许多人面临的难题。由于每个人对耳机的偏好各有侧重——一些人追求音质的纯净,一些人重视佩戴的舒适性,而另…...

数据结构 ——— 二叉树的概念及结构
目录 二叉树的概念 特殊的二叉树 一、满二叉树 二、完全二叉树 二叉树的概念 二叉树树示意图: 从以上二叉树示意图可以看出: 二叉树每个节点的度不大于 2 ,那么整个二叉树的度也不大于 2 ,但是也不是每个节点都必须有 2 个…...

【React】React 的核心设计思想
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React 的核心设计思想引言声明式编程声明式 vs 命令式示例 组件化组件的优势组件…...

C++ 二叉树进阶:相关习题解析
目录 1. 二叉树创建字符串。 2. 二叉树的分层遍历1 3. 二叉树的分层遍历2 4. 二叉树的最近公共祖先 5. 将二叉搜索树转换为排序的双向链表 6. 从前序与中序遍历序列构造二叉树 7. 从中序与后序遍历序列构造二叉树 8. 二叉树的前序遍历,非递归迭代实现 9.…...

机器学习在非洲公共卫生疾病预测中的实战应用与技术解析
1. 项目概述:当AI遇见非洲公共卫生在非洲大陆,公共卫生系统长期面临着资源不均、基础设施薄弱和疾病负担沉重的多重挑战。传统的疾病监测依赖于被动报告和人工数据分析,往往存在滞后性,当疫情警报拉响时,病毒可能已经悄…...

Dify-Flow:构建复杂AI工作流的流程编排引擎设计与实现
1. 项目概述:当Dify遇上Flow,一个面向开发者的AI应用编排新范式如果你最近在折腾AI应用开发,特别是想把大语言模型(LLM)的能力集成到自己的业务流程里,那你大概率听说过Dify。它作为一个开源的LLM应用开发平…...

Weaviate官方示例库全解析:从向量数据库入门到AI应用实战
1. 项目概述:一个向量数据库的“游乐场”如果你最近在折腾大语言模型应用,或者想给自己的数据加上一个智能的“记忆大脑”,那你大概率已经听说过向量数据库了。在众多选择中,Weaviate 以其开源、易用和强大的功能,成为…...

作业4:独立按键+数码管实操
文章目录 1.测试代码视频2.流水灯视频3.独立按键视频(点亮四个灯)4.独立按键视频(思考题点亮8个灯)5.数码管显示“111111”6.数码管显示“123456”7.数码管显示“11.12.13”8.数码管显示“HH8800.” 1.测试代码视频 测试2.流水灯视频 流水灯#include <reg51.h> // 包含…...

Windows平台Android开发环境自动化部署:ADB与Fastboot驱动智能安装工具技术解析
Windows平台Android开发环境自动化部署:ADB与Fastboot驱动智能安装工具技术解析 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitc…...

艾尔登法环性能突破:隐藏的帧率限制与视野优化技术解密
艾尔登法环性能突破:隐藏的帧率限制与视野优化技术解密 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/El…...

雨天高速公路元胞传输模型可变限速控制方法【附程序】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)雨天改进元胞传输模型参数标定与验证: 在…...

独立开发者工具箱:2026年全栈与AI应用高效开发技术栈指南
1. 项目概述与核心价值作为一名在独立开发领域摸爬滚打了十多年的老兵,我深知一个道理:工具选型,是决定项目成败的第一道分水岭。你花在纠结技术栈、寻找合适API、调试部署环境上的每一分钟,都是从产品核心价值中偷走的时间。今天…...

智能网盘加速方案:3步实现下载速度飞跃
智能网盘加速方案:3步实现下载速度飞跃 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的下载速度折磨到崩溃?当急需下载重要文件时…...

S32K144 Lin组件实战:告别官方LinStack,手把手教你用底层驱动搞定超声波雷达
S32K144 Lin组件实战:从高级封装到底层驱动的技术跃迁 在嵌入式开发领域,协议栈选择往往决定了项目的灵活性与开发效率。当我们使用NXP S32K144微控制器进行LIN总线通信时,官方提供的LinStack组件确实能快速搭建基础通信框架。但真正投入工业…...