Deep InfoMax(DIM)(2019-02-ICLR)
论文:LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION
ABSTRACT
- 研究目标
- 研究通过最大化输入和深度神经网络编码器输出之间的互信息来进行无监督表示学习
- 目的是学习到对下游任务有用的特征表示
- 核心发现:结构很重要(structure matters)
- 在目标函数中引入输入数据的局部性知识(locality)可以显著提升表示的质量
- 这说明考虑数据的内在结构对学习好的表示很重要
- 特征控制方法
- 通过对抗性地匹配先验分布(matching to a prior distribution adversarially)
- 这样可以控制学到的表示的特征
- 方法命名与性能
- 将这种方法命名为Deep InfoMax (DIM)
性能优于多个流行的无监督学习方法 - 在某些标准架构的分类任务上可以与全监督学习媲美
- 意义与影响
- 为无监督表示学习开辟了新途径
- 朝着针对特定目标的灵活表示学习目标迈出了重要一步
1. INTRODUCTION
- 深度学习核心目标
- 发现有用的特征表示
- 训练编码器最大化输入和输出之间的互信息(MI)
- 互信息在连续和高维设置中难以计算
- 最新进展使得计算深度神经网络输入/输出对之间的MI成为可能
- 结构重要性发现
- 仅最大化输入与编码器输出之间的全局MI往往不足
- 最大化表示与输入局部区域(如图像块)之间的平均MI能显著提升分类任务的表示质量
- 全局MI在重建任务中发挥更重要作用
- 表示的有效性考虑
- 不仅关乎信息含量
- 表示特征的独立性也很重要
- 结合MI最大化和类似AAE的先验匹配来约束表示
- Deep InfoMax (DIM)主要贡献
- 形式化DIM方法,同时估计和最大化输入数据与高层表示之间的互信息
- MI最大化过程可以优先考虑全局或局部信息
- 使用对抗学习来约束表示具有特定的先验统计特性
- 引入两个新的表示质量度量:基于MINE和基于NDM
- 创新意义
- 可以调整学到的表示以适应分类或重建任务
- 提供了新的表示质量评估方法
- 加强了与其他无监督方法的比较
2. RELATED WORK
- 表示学习的经典方法
- 独立成分分析(ICA)
- 自组织映射(Self-organizing maps)
- 这些方法通常缺乏深度神经网络的表示能力
- 近期方法
- 深度体积保持映射(Deep volume-preserving maps)
- 深度聚类(Deep clustering)
- 噪声作为目标(NAT)
- 自监督学习或协同学习
- 生成模型在表示学习中的应用
- 常用于构建表示
- 互信息(MI)对学习到的表示质量起重要作用
- 包括变分自编码器、对抗自编码器等
- 重建误差与互信息的关系
- 公式: I e ( X , Y ) = H e ( X ) − H e ( X ∣ Y ) ≥ H e ( X ) − R e , d ( X ∣ Y ) \mathcal{I}_{e}(X,Y)=\mathcal{H}_{e}(X)-\mathcal{H}_{e}(X|Y)\geq\mathcal{H}_{e}(X)-\mathcal{R}_{e,d}(X|Y) Ie(X,Y)=He(X)−He(X∣Y)≥He(X)−Re,d(X∣Y)
- X和Y分别表示编码器的输入和输出
- R e , d ( X ∣ Y ) \mathcal{R}_{e,d}(X|Y) Re,d(X∣Y) 表示给定编码Y时X的期望重建误差
- H e ( X ) \mathcal{H}_{e}(X) He(X) 和 H e ( X ∣ Y ) \mathcal{H}_{e}(X|Y) He(X∣Y) 分别表示边缘熵和条件熵
- 重要结论
- 基于重建的模型能保证中间表示包含一定量的信息
- 双向对抗模型也有类似的保证
- 通过对抗训练来匹配联合分布或最小化重建误差
2.1 Mutual-information estimation
- 基于互信息的方法历史
- infomax原则倡导最大化输入和输出之间的MI
- 是多个ICA算法的基础
- 非线性ICA算法难以适应深度网络
- MINE(互信息神经估计)特点
- 学习连续变量的MI估计
- 具有强一致性
- 可用于学习更好的隐式双向生成模型
- DIM遵循MINE但发现生成器是不必要的
- DIM的关键发现
- 不需要使用基于KL的MI精确公式
- 基于Jensen-Shannon散度(JSD)的简单替代方案更稳定
- 可以使用各种MI估计器
- 可以利用输入的局部结构来改善分类表示
- 利用已知结构的发展
- 在设计基于MI最大化的目标时使用输入结构并非新概念
- 数据增强和变换可用于避免退化解
- 通过最大化变换或空间临近相关图像间的MI可实现无监督聚类和分割
- DIM与CPC的比较
- CPC也是基于MI的方法,最大化全局和局部表示对之间的MI
- 主要区别:
- CPC顺序处理局部特征构建部分"摘要特征"
- CPC需要为每个时间偏移训练单独的估计器
- DIM使用单个摘要特征,可同时预测所有局部特征
- DIM在训练时使用遮挡,执行"自我"预测和无序自回归
- DIM的优势
- 使用单个估计器
- 单步预测所有局部特征
- 训练过程更简单高效
- 具有更灵活的结构
3. DEEP INFOMAX

DIM(Deep InfoMax)是一种无监督表示学习方法,旨在通过最大化输入数据与其编码表示之间的互信息来学习丰富、紧凑的特征表示。下面我们将从几个方面对DIM进行概述。
DIM编码器结构解析
首先,让我们根据图1来理解DIM的编码器结构:
- 输入图像通过一个卷积神经网络(convnet)进行处理。
- Convnet输出一个M×M的特征图(feature map),其中每个位置对应输入图像的一个局部块(patch)。
- 这些局部特征向量通过一个可学习的函数(如池化操作)进一步汇总为一个全局特征向量Y。
直观地说,Y捕获了输入数据X的高层、全局信息,而M×M特征图则保留了丰富的局部细节。
全局MI目标的DIM结构
接下来,我们基于图2来看DIM如何实现互信息最大化:
- DIM同时使用高层特征向量Y和低层M×M特征图。
- 通过一个判别器(discriminator)网络,DIM试图区分来自同一图像的特征对(即正样本)和来自不同图像的特征对(即负样本)。
- 正样本的特征对由同一图像的Y与其M×M特征图配对而成。
- 负样本的特征对则通过将一个图像的Y与另一图像的M×M特征图组合而成。
直观上,这鼓励编码器提取与全局特征一致的、独特的局部特征。通过最大化正负样本的区分能力,DIM实际上最大化了输入与编码特征的互信息。
模型的数学形式化
为了更严格地描述DIM,我们引入一些数学符号:
- 定义编码器 E ψ : X → Y E_\psi:\mathcal{X}\to\mathcal{Y} Eψ:X→Y,其中ψ为编码器参数。
- E Ψ = { E ψ } ψ ∈ Ψ \mathcal{E}_\Psi=\{E_\psi\}_{\psi\in\Psi} EΨ={Eψ}ψ∈Ψ 表示所有可能的编码器的集合。
- 假设我们有N个训练样本 X : = { x ( i ) ∈ X } i = 1 N \mathbf{X}:=\{x^{(i)}\in\mathcal{X}\}_{i=1}^N X:={x(i)∈X}i=1N,服从某个经验概率分布P。
DIM的目标是在编码器族 E Ψ \mathcal{E}_\Psi EΨ 中找到一个最优编码器 E ψ ∗ E_{\psi^*} Eψ∗,使其提取的特征最大限度地保留输入数据的信息。
DIM的两个主要优化目标
DIM的训练涉及两个关键目标:
- 互信息最大化
- DIM寻找最优参数ψ,以最大化输入X与其编码表示 E ψ ( X ) E_\psi(X) Eψ(X) 之间的互信息 I ( X ; E ψ ( X ) ) \mathcal{I}(X;E_\psi(X)) I(X;Eψ(X))。
- 互信息最大化可以针对完整输入X,也可以针对X的局部子集(如图像块)进行。
- 统计约束
- 为了引导编码器学习具有期望特性的表示,DIM引入了一个统计约束。
- 具体而言,编码表示的边际分布 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 应该与某个预定义的先验分布V尽可能接近。
- 通过惩罚 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 与V的差异,DIM鼓励编码器输出符合先验假设的特征。
DIM巧妙地将互信息最大化与分布匹配结合,联合优化这两个目标,最终得到高度信息量和统计上可控的特征表示。
关键创新点
总结起来,DIM的一些关键创新点包括:
- 设计了一种灵活的特征提取架构,可以捕获数据的不同抽象层次的信息。
- 通过最大化全局特征与局部特征图的互信息,实现了全局一致性和局部丰富性的统一。
- 引入先验分布匹配,实现了对学习到的特征分布的有效约束和控制。
- 该方法具有很强的普适性,不仅适用于图像数据,也可以扩展到时序数据等其他领域。
DIM代表了无监督表示学习领域的一项重要进展,为进一步提高深度学习模型的特征提取和泛化能力提供了新的思路。
3.1 MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION
DIM(Deep InfoMax)是一种无监督表示学习方法,通过最大化输入数据与其编码表示之间的互信息,来学习信息丰富的特征表示。下面我们将详细解析其中的关键技术和数学原理。
互信息估计
互信息(Mutual Information, MI)衡量了两个随机变量之间的依赖性。对于随机变量X和Y,它们的互信息定义为:
I ( X ; Y ) : = D K L ( J ∣ ∣ M ) \mathcal{I}(X;Y):=\mathcal{D}_{KL}(\mathbb{J}||\mathbb{M}) \quad I(X;Y):=DKL(J∣∣M)
其中, J \mathbb{J} J表示X和Y的联合分布, M \mathbb{M} M表示X和Y的边缘分布的乘积, D K L \mathcal{D}_{KL} DKL表示KL散度。
然而,直接计算互信息在实践中往往不可行,因此需要估计的方法。DIM采用了MINE(Mutual Information Neural Estimation)的思想,通过训练一个判别器网络T来估计互信息的下界。
Donsker-Varadhan估计器
基于Donsker-Varadhan (DV)表示,MINE给出了互信息的如下下界:
I ( X ; Y ) ≥ I ^ ω ( D V ) ( X ; Y ) : = E J [ T ω ( x , y ) ] − log E M [ e T ω ( x , y ) ] ( 2 ) \mathcal{I}(X;Y) \geq \widehat{\mathcal{I}}_\omega^{(DV)}(X;Y):=\mathbb{E}_\mathbb{J}[T_\omega(x,y)]-\log\mathbb{E}_\mathbb{M}[e^{T_\omega(x,y)}] \quad (2) I(X;Y)≥I ω(DV)(X;Y):=EJ[Tω(x,y)]−logEM[eTω(x,y)](2)
其中, T ω : X × Y → R T_\omega:\mathcal{X}\times\mathcal{Y}\to\mathbb{R} Tω:X×Y→R是一个参数为 ω \omega ω的判别器网络。它的目标是将正样本(来自联合分布 J \mathbb{J} J)和负样本(来自边缘分布乘积 M \mathbb{M} M)尽可能区分开。
直观地说,判别器T学习分配高分给正样本、低分给负样本,从而估计互信息。当T的表达能力足够强时,(2)中的下界会无限逼近真实的互信息。
Jensen-Shannon估计器
除了DV估计器,DIM还探索了其他的互信息估计方式。一种选择是基于Jensen-Shannon散度(JSD)的估计器:
I ^ ω , ψ ( J S D ) ( X ; E ψ ( X ) ) : = E P [ − s p ( − T ψ , ω ( x , E ψ ( x ) ) ) ] − E P × P ~ [ s p ( T ψ , ω ( x ′ , E ψ ( x ) ) ) ] ( 4 ) \widehat{\mathcal{I}}_{\omega,\psi}^{(\mathrm{JSD})}(X;E_\psi(X)):=\mathbb{E}_\mathbb{P}[-\mathrm{sp}(-T_{\psi,\omega}(x,E_\psi(x)))]-\mathbb{E}_{\mathbb{P}\times\tilde{\mathbb{P}}}[\mathrm{sp}(T_{\psi,\omega}(x^{\prime},E_\psi(x)))] \quad (4) I ω,ψ(JSD)(X;Eψ(X)):=EP[−sp(−Tψ,ω(x,Eψ(x)))]−EP×P~[sp(Tψ,ω(x′,Eψ(x)))](4)
其中, x x x是来自数据分布 P \mathbb{P} P的样本, x ′ x^\prime x′是另一个独立的样本, s p ( z ) = log ( 1 + e z ) \mathrm{sp}(z)=\log(1+e^z) sp(z)=log(1+ez)是softplus函数。
这个估计器本质上是最小化正样本和负样本在判别器T上softplus值之差的期望。它与二元交叉熵损失密切相关,在神经网络优化方面有着成熟的理论基础,实践中往往比DV估计器更稳定。
InfoNCE估计器
DIM还可以使用基于Noise-Contrastive Estimation(NCE)的infoNCE估计器:
T ^ ω , ψ (infoNCE) ( X ; E ψ ( X ) ) : = E P [ T ψ , ω ( x , E ψ ( x ) ) − E P ~ [ log ∑ x ′ e T ψ , ω ( x ′ , E ψ ( x ) ) ] ] . (5) \widehat{\mathcal{T}}_{\omega,\psi}^{\text{(infoNCE)}}(X;E_\psi(X)):=\mathbb{E}_{\mathbb{P}}\left[T_{\psi,\omega}(x,E_\psi(x))-\mathbb{E}_{\tilde{\mathbb{P}}}\left[\log\sum_{x^{\prime}}e^{T_{\psi,\omega}(x^{\prime},E_\psi(x))}\right]\right].\text{ (5)} T ω,ψ(infoNCE)(X;Eψ(X)):=EP[Tψ,ω(x,Eψ(x))−EP~[logx′∑eTψ,ω(x′,Eψ(x))]]. (5)
与JSD估计器类似,infoNCE也使用独立样本 x ′ x^\prime x′构造负样本。不同之处在于,infoNCE使用softmax而非softplus,并在求和号内加入了对数函数。
InfoNCE源自语言模型领域,与二元交叉熵在噪声对比学习中有着紧密联系。实验表明,infoNCE在下游任务上的表现常优于JSD,但在更具挑战的数据上优势减弱。
互信息最大化
有了互信息的估计,DIM的目标就是找到一个最优的编码器 E ψ E_\psi Eψ,使其提取的特征表示 E ψ ( X ) E_\psi(X) Eψ(X) 与输入 X X X 的互信息最大化:
( ω ^ , ψ ^ ) G = arg max ω , ψ I ^ ω ( X ; E ψ ( X ) ) ( 3 ) (\hat{\omega},\hat{\psi})_G=\arg\max_{\omega,\psi}\widehat{\mathcal{I}}_\omega(X;E_\psi(X)) \quad (3) (ω^,ψ^)G=argω,ψmaxI ω(X;Eψ(X))(3)
其中, I ^ ω \widehat{\mathcal{I}}_\omega I ω 可以是上述任意一种互信息估计器。 ψ \psi ψ 和 ω \omega ω 分别表示编码器和判别器的参数,下标 G G G 表示全局互信息。
与MINE相比,DIM在优化过程中引入了两点创新:
-
编码器 E ψ E_\psi Eψ 和判别器 T ω T_{\omega} Tω 共享低层的特征提取网络 C ψ C_\psi Cψ,即 E ψ = f ψ ∘ C ψ E_\psi=f_\psi\circ C_\psi Eψ=fψ∘Cψ, T ψ , ω = D ω ∘ g ∘ ( C ψ , E ψ ) T_{\psi,\omega}=D_\omega\circ g\circ(C_\psi,E_\psi) Tψ,ω=Dω∘g∘(Cψ,Eψ)。这种参数共享可以提高训练效率,减少过拟合风险。
-
互信息最大化可以针对输入数据的全局特征(即公式(3)),也可以针对局部特征(如图像块)进行。DIM同时考虑了全局和局部的互信息,实现了多尺度的特征学习。
负样本生成
互信息估计器的优劣很大程度上取决于负样本的质量和数量。以一个大小为 B B B 的小批次数据为例,DIM通过以下方式生成负样本:
-
将每个样本的全局特征 E ψ ( x ) E_\psi(x) Eψ(x) 与该批次中所有样本在所有位置的局部特征图组合,构成 O ( B × M 2 ) O(B\times M^2) O(B×M2) 个"全局-局部"负样本对;
-
类似地,将每个样本的局部特征与该批次中所有样本的全局特征组合,构成 O ( B × M 2 ) O(B\times M^2) O(B×M2) 个"局部-全局"负样本对。
这里 M × M M\times M M×M 为局部特征图的空间大小。可见,负样本的数量与批次大小和特征图大小呈平方关系,这对计算资源提出了挑战。
实验发现,infoNCE和DV估计器需要大量负样本才能达到较好的性能,而基于JSD的DIM对负样本数量不敏感,在负样本减少时反而表现更优。这可能是因为JSD天然具有对称性,能够自适应地调节正负样本的重要性,并且实际上随着负样本的数量变小,其性能优于 infoNCE。
小结
DIM通过互信息最大化的原则,结合判别器估计和负样本生成技术,为无监督表示学习开辟了一条新路。其创新点包括:
- 综合考虑了多种互信息估计方式,如DV、JSD和infoNCE,并在实践中进行了细致的比较;
- 将全局互信息和局部互信息结合,实现了多尺度特征的学习;
- 巧妙利用批次数据生成大量负样本,提高了互信息估计的效果;
- 针对不同的数据和任务,优化互信息估计和负样本生成策略,展现出了极大的灵活性。
DIM为深度神经网络的无监督学习提供了新的思路和范式,有望进一步提升模型的特征表达和泛化能力,应对更加复杂和多样化的现实任务。
3.2 LOCAL MUTUAL INFORMATION MAXIMIZATION
尽管公式(3)可以用于最大化输入和输出之间的互信息,但这可能并不总是最优的选择,具体取决于任务的性质。例如,对于图像分类任务,像素级的噪声往往是无用的,因此将这些信息编码到特征表示中可能无益于模型性能(如在零样本学习、迁移学习等场景下)。为了获得更适合分类任务的特征表示,我们可以转而最大化高层特征与图像局部块之间的平均互信息。通过鼓励同一特征表示与所有局部块有较高的互信息,这种方法有利于编码数据中跨块共享的信息。
假设特征向量的容量(即单元数和取值范围)有限,且编码器不支持无限的输出配置。在最大化整个输入与特征表示的互信息时,编码器可以自主选择从输入中传递何种信息,如局部块或像素的特定噪声。然而,如果编码器只传递某些部分输入的特定信息,这并不会提高其与其他不包含该噪声的块之间的互信息。这鼓励编码器倾向于提取输入中共享的信息,我们在实验中也验证了这一假设。

图3展示了我们的局部DIM(Deep InfoMax)框架。首先,我们将输入编码为一个特征图 C ψ ( x ) : = { C ψ ( i ) } i = 1 M × M C_{\psi}(x):=\{C_{\psi}^{(i)}\}_{i=1}^{M\times M} Cψ(x):={Cψ(i)}i=1M×M,该特征图反映了数据中的有用结构(如空间局部性),这里用 i i i 进行索引。然后,我们将这个局部特征图汇总为一个全局特征, E ψ ( x ) = f ψ ∘ C ψ ( x ) E_\psi(x)=f_\psi\circ C_\psi(x) Eψ(x)=fψ∘Cψ(x)。接着,我们在全局-局部特征对上定义互信息估计器,最大化平均估计互信息:
( ω ^ , ψ ^ ) L = arg max ω , ψ 1 M 2 ∑ i = 1 M 2 I ^ ω , ψ ( C ψ ( i ) ( X ) ; E ψ ( X ) ) ( 6 ) (\hat{\omega},\hat{\psi})_{L}=\arg\max_{\omega,\psi}\frac{1}{M^{2}}\sum_{i=1}^{M^{2}}\widehat{\mathcal{I}}_{\omega,\psi}(C_{\psi}^{(i)}(X);E_{\psi}(X)) \quad (6) (ω^,ψ^)L=argω,ψmaxM21i=1∑M2I ω,ψ(Cψ(i)(X);Eψ(X))(6)
我们发现,通过多种易于实现的架构,可以成功地优化这种"局部"目标,更多实现细节在附录 ( A . 2 ) ({A}.2) (A.2) 中提供。
以下是对局部互信息最大化的一些关键点:
-
动机:最大化全局互信息可能并不总是最优的,因为某些任务无关的信息(如图像中的噪声)可能被编码,而这对模型性能无益。
-
局部互信息:通过最大化高层特征与局部块之间的平均互信息,鼓励编码器提取数据中跨块共享的信息,这通常更有利于分类任务。
-
容量约束:在特征向量容量有限的情况下,最大化局部互信息将促使编码器选择性地传递共享信息,而非局部特定噪声。
-
实现框架:局部DIM首先将输入编码为反映数据结构的局部特征图,然后汇总为全局特征。互信息估计器在全局-局部特征对上定义,目标是最大化平均估计互信息。
-
优化方法:局部DIM目标可以通过多种易于实现的神经网络架构进行优化,展现出良好的灵活性。
总的来说,局部互信息最大化为无监督特征学习提供了一种新的视角,通过关注数据中共享的信息而非特定噪声,有望学到更鲁棒、更适合下游任务的表示。这一思想与数据增强、域适应等领域也有着内在的联系,值得进一步探索。
3.3 MATCHING REPRESENTATIONS TO A PRIOR DISTRIBUTION
除了信息量的绝对大小,一个好的表示还应具备其他优良特性,如紧致性(Gretton et al., 2012)、独立性(Hyvärinen & Oja, 2000; Hinton, 2002; Dinh et al., 2014; Brakel & Bengio, 2017)、解耦性(Schmidhuber, 1992; Rifai et al., 2012; Bengio et al., 2013; Chen et al., 2018; Gonzalez-Garcia et al., 2018)或独立可控性(Thomas et al., 2017)。DIM通过隐式地训练编码器,使其推前分布 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 与先验分布 V \mathbb{V} V 匹配,从而在学习到的表示上施加统计约束。
具体而言,如图7(见附录A.2)所示,DIM训练一个判别器 D ϕ : Y → R D_\phi:\mathcal{Y}\to\mathbb{R} Dϕ:Y→R 来估计 V \mathbb{V} V 和 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 之间的散度 D ^ ϕ ( V ∣ ∣ U ψ , P ) \widehat{\mathcal{D}}_\phi(\mathbb{V}||\mathbb{U}_{\psi,\mathbb{P}}) D ϕ(V∣∣Uψ,P),然后训练编码器最小化这个估计值:
( ω ^ , ψ ^ ) P = arg min ψ arg max ϕ D ^ ϕ ( V ∣ ∣ U ψ , P ) = E V [ log D ϕ ( y ) ] + E P [ log ( 1 − D ϕ ( E ψ ( x ) ) ) ] ( 7 ) (\hat{\omega},\hat{\psi})_P=\arg\min_\psi\arg\max_\phi\widehat{\mathcal{D}}_\phi(\mathbb{V}||\mathbb{U}_{\psi,\mathbb{P}})=\mathbb{E}_V[\log D_\phi(y)]+\mathbb{E}_\mathbb{P}[\log(1-D_\phi(E_\psi(x)))] \quad (7) (ω^,ψ^)P=argψminargϕmaxD ϕ(V∣∣Uψ,P)=EV[logDϕ(y)]+EP[log(1−Dϕ(Eψ(x)))](7)
这种方法类似于对抗自编码器(AAE, Makhzani et al., 2015),但没有使用生成器。它也类似于将噪声作为目标(Bojanowski & Joulin, 2017),但不是将先验噪声样本直接用作目标,而是训练编码器隐式地匹配噪声分布。
DIM的完整目标结合了全局互信息最大化、局部互信息最大化和先验匹配这三个子目标:
arg max ω 1 , ω 2 , ψ ( α I ^ ω 1 , ψ ( X ; E ψ ( X ) ) + β M 2 ∑ i = 1 M 2 I ^ ω 2 , ψ ( X ( i ) ; E ψ ( X ) ) ) + arg min ψ arg max ϕ γ D ^ ϕ ( V ∣ ∣ U ψ , P ) ( 8 ) \arg\max_{\omega_{1},\omega_{2},\psi}\left(\alpha\widehat{\mathcal{I}}_{\omega_{1},\psi}(X;E_{\psi}(X))+\frac{\beta}{M^{2}}\sum_{i=1}^{M^{2}}\widehat{\mathcal{I}}_{\omega_{2},\psi}(X^{(i)};E_{\psi}(X))\right)+\arg\min_{\psi}\arg\max_{\phi}\gamma\widehat{\mathcal{D}}_{\phi}(\mathbb{V}||\mathbb{U}_{\psi,\mathbb{P}}) \quad (8) argω1,ω2,ψmax αI ω1,ψ(X;Eψ(X))+M2βi=1∑M2I ω2,ψ(X(i);Eψ(X)) +argψminargϕmaxγD ϕ(V∣∣Uψ,P)(8)
其中, ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 分别是全局目标和局部目标的判别器参数, α \alpha α、 β \beta β 和 γ \gamma γ 是超参数。我们将在下面展示,这些超参数的选择会以有意义的方式影响学习到的表示。另外,我们在附录(A.8)中还展示,单独使用先验匹配就可以训练一个图像数据生成器。
关于将表示匹配到先验分布,这里总结几个关键点:
-
动机:除了信息量,表示的其他性质如紧致性、独立性、解耦性等也很重要,这取决于具体应用。
-
方法:DIM通过训练判别器估计编码器推前分布与先验分布的散度,然后训练编码器最小化该估计,从而隐式地将学习到的表示匹配到先验。
-
与相关工作的比较:这种方法类似于对抗自编码器(但没有生成器)和将噪声作为目标(但隐式地匹配噪声分布)。
-
完整目标:DIM的完整目标结合了全局互信息最大化、局部互信息最大化和先验匹配三个子目标,通过超参数 α \alpha α、 β \beta β、 γ \gamma γ 平衡它们的相对重要性。
-
超参数的影响:不同的超参数选择会以有意义的方式影响学习到的表示,体现出DIM的灵活性。
-
扩展应用:单独使用先验匹配就可以训练一个图像数据生成器,展现出这一思想的普适性。
从数学原理上看,公式(7)中判别器 D ϕ D_\phi Dϕ 的训练目标是最大化先验分布 V \mathbb{V} V 的对数概率和编码器推前分布 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 的负对数概率之和,这等价于最小化这两个分布的JS散度。而编码器 E ψ E_\psi Eψ 的训练目标恰好相反,是最小化判别器的散度估计,从而使 U ψ , P \mathbb{U}_{\psi,\mathbb{P}} Uψ,P 尽可能接近 V \mathbb{V} V。这种对抗训练的过程使编码器逐步将输入数据映射到期望的先验分布,从而在学习到的表示上施加了有效的统计约束。
总的来说,将表示匹配到先验分布是DIM的一个重要创新点,它为无监督学习引入了额外的归纳偏置,有助于获得具备特定性质的表示。这一思想与领域知识的引入、表示的可解释性等研究方向紧密相关,有望进一步提升深度学习的可用性和可靠性。
4. EXPERIMENTS
为了评估DIM(Deep InfoMax)学习到的表示的性质,我们在四个图像数据集上进行了测试:
数据集
-
CIFAR10和CIFAR100(Krizhevsky & Hinton, 2009):两个小规模带标签的数据集,分别包含10类和100类32×32的图像。
-
Tiny ImageNet:ImageNet(Krizhevsky & Hinton, 2009)的缩减版,图像大小为64×64,共200类。
-
STL-10(Coates et al., 2011):一个源自ImageNet的数据集,包含96×96的图像,其中100000个无标签训练样本和每类500个带标签样本。在无监督学习期间,我们对该数据集进行数据增强,随机裁剪为64×64并水平翻转。
-
CelebA(Yang et al., 2015,仅在附录A.5中使用):一个由带有40个二值属性标签的人脸图像组成的数据集。该数据集用于评估DIM捕获比类别标签更细粒度、比单个像素更粗粒度的信息的能力。
比较方法
在实验中,我们将DIM与多种无监督方法进行了比较:
- 变分自编码器(VAE, Kingma & Welling, 2013)
- β-VAE(Higgins et al., 2016; Alemi et al., 2016)
- 对抗自编码器(AAE, Makhzani et al., 2015)
- BiGAN(也称为具有确定性编码器的对抗学习推断:Donahue et al., 2016; Dumoulin et al., 2016)
- 将噪声作为目标(NAT, Bojanowski & Joulin, 2017)
- 对比预测编码(CPC, Oord et al., 2018)
需要注意的是,我们将CPC理解为使用摘要特征进行有序自回归,以预测"未来"的局部特征,与用于评估预测的对比损失(JSD、infoNCE或DV)无关。
有关实验中使用的神经网络架构的详细信息,请参见附录(A.2)。
实验意义
这些实验旨在全面评估DIM在不同类型和规模的图像数据集上学习到的表示的质量。通过与多种现有无监督学习方法的比较,我们可以了解DIM在特征提取、信息保留、泛化能力等方面的优势和局限性。
具体而言,CIFAR10、CIFAR100和Tiny ImageNet这些带标签的数据集可以用于评估DIM学习到的表示在下游分类任务上的性能,体现其特征的判别性和语义性。STL-10数据集包含大量无标签样本,可以考察DIM在半监督学习设置下的表现,即利用少量标签和大量无标签数据进行学习。CelebA数据集则侧重于评估DIM捕获图像中细粒度属性信息的能力,这对于人脸识别、属性编辑等任务至关重要。
总的来说,这些实验设置全面考虑了数据规模、标签可用性、任务类型等因素,有助于深入理解DIM的特点和适用范围。通过与其他无监督方法的系统比较,我们可以客观地评估DIM在表示学习领域的贡献和潜力。这不仅有助于推动DIM本身的改进和应用,也为无监督学习研究提供了重要的实证基础和比较基准。
我来帮您总结这段关于如何评估表征(representation)质量的内容。
4.1 HOW DO WE EVALUATE THE QUALITY OF A REPRESENTATION?
主要评估指标
-
线性分类评估
- 使用支持向量机(SVM)
- 可以衡量表征的线性可分性
- 同时也是表征与标签之间互信息的代理指标
-
非线性分类评估
- 使用单隐层神经网络(200个单元)和dropout
- 独立于线性可分性来评估表征与标签之间的互信息
-
半监督学习评估
- 在最后一个卷积层上添加小型神经网络
- 通过微调整个编码器来评估
-
MS-SSIM评估
- 使用基于L2重建损失训练的解码器
- 评估输入和表征之间的总体互信息
- 可以反映编码的像素级信息量
-
互信息神经估计(MINE)
- 评估输入X与输出表征之间的互信息
- 通过训练判别器来最大化KL散度
-
神经依赖度量(NDM)
- 使用判别器测量原始表征和打乱后的表征之间的KL散度
- 散度越高,因子之间的依赖性越强
注意事项
- 在评估过程中,编码器的权重保持固定
- 对于分类任务的评估,除了CelebA之外的所有数据集都进行了实验
- 其他度量指标主要在CIFAR10上进行测试
- 分类器的模型选择是通过对最后100轮优化结果取平均得到
- 统一设置了dropout率和学习率衰减计划,以减少所有模型在测试集上的过拟合
这些评估方法各有侧重,共同构成了一个全面的表征质量评估体系。通过这些指标的组合使用,可以更好地理解和改进表征学习模型。
4.2 REPRESENTATION LEARNING COMPARISON ACROSS MODELS
实验总结
-
DIM(G):指DIM的全局目标,仅设置为 ( α = 1 , β = 0 , γ = 1 ) (\alpha=1,\beta=0,\gamma=1) (α=1,β=0,γ=1)。
-
DIM(L):指DIM的局部目标,仅设置为 ( α = 0 , β = 1 , γ = 0.1 ) (\alpha=0,\beta=1,\gamma=0.1) (α=0,β=1,γ=0.1)。该设置是根据附录(A.5)中的消融研究结果选择的。
-
先验分布:我们选择了 [ 0 , 1 ] 64 [0,1]^{64} [0,1]64上的紧致均匀分布作为先验,这在实践中效果优于其他先验分布,例如高斯分布、单位球体或单位球面。
Classification comparisons


我们的分类结果见于表1、表2和表3。总体来说,使用局部目标的DIM(DIM(L))在所有数据集上均显著超越了其他模型,唯一例外是CPC。具体设置(架构、除了STL-10外未使用数据增强)下,DIM(L)的表现与完全监督的分类器相当,甚至更好,这表明在这种设置下,模型提取的特征几乎与原始像素一样好。需要注意的是,完全监督的分类器在这些基准测试中表现通常更好,尤其是在使用专门架构和精心选择的数据增强时。我们在CIFAR10数据集上也获得了有竞争力的结果(尽管是在不同的设置下),但我们在STL-10的数据表现是无监督学习的最新成果。这些结果支持了我们的局部DIM目标适合提取类别信息的假设。
我们的结果显示,infoNCE通常表现最好,但在数据集较大时,infoNCE与JSD之间的差异减小。DV在小数据集上可以与JSD竞争,但在大数据集上表现则较差。
关于CPC,我们仅能在上述设置下略微优于BiGAN。然而,当我们采用Oord等人(2018年)提出的带有步幅裁剪的架构时,CPC和DIM的表现都有显著提升。我们选择了图像宽度和高度的25%作为裁剪大小,步幅为图像大小的12.5%(例如,CIFAR10使用8×8的裁剪,步幅为4×4;STL-10使用16×16的裁剪,步幅为8×8),总共得到了7×7的局部特征。对于DIM(L)和CPC,我们都使用infoNCE以及相同的“编码与点积”架构(类似于深双线性模型),而不是Oord等人使用的浅双线性模型。CPC使用了三个这样的网络,每个网络负责下一行中局部特征图的不同预测任务。为了简化,我们省略了DIM中的先验项β。在没有数据增强的情况下,使用ResNet-50架构的CPC表现不如DIM(L)。在STL-10上进行数据增强实验时(使用与表2相同的编码架构),CPC和DIM的表现相当,CPC稍好一些。
CPC根据多个摘要特征进行预测,每个特征包含关于完整输入的不同信息量。我们可以通过计算随机采样的局部特征( 3 × 3 3\times3 3×3块)来向DIM添加类似的行为,然后最大化这些局部特征和完整局部特征集之间的互信息。当使用这种版本的DIM时,我们在所有可能的 3 × 3 3\times3 3×3局部特征块上共享一个互信息估计器。这是一种特定的遮挡技术实例,旨在提升DIM在STL-10上的表现。令人惊讶的是,这种架构在CIFAR10上表现不如完全全局表示。总体而言,在该设置下,DIM的表现仅略优于CPC,这表明CPC的严格自回归可能在某些任务中并非必要。
Extended comparisons

表4展示了CIFAR10数据集在线性可分性、重构(MS-SSIM)、互信息和依赖性(NDM)方面的结果。由于架构的差异,我们未与CPC进行比较。在线性分类器结果(SVC)方面,我们为每个模型训练了五个支持向量机,并平均了测试准确率。对于MINE,我们使用了衰减学习率调度,以减少估计的方差并加快收敛。
MS-SSIM与MINE提供的互信息估计高度相关,表明这些模型有效编码了逐像素信息。总体而言,所有模型的依赖性均显著低于BiGAN,这表明编码器输出的边际与生成器的球形高斯输入先验不匹配,尽管DIM的混合局部/全局版本接近。互信息方面,基于重构的模型如VAE和AAE得分较高,我们发现结合局部和全局DIM目标(如DIM(L+G),其中 α = 0.5 , β = 0.1 \alpha=0.5,\beta=0.1 α=0.5,β=0.1)得分非常高。有关更深入的分析,请参见附录中的消融研究和最近邻分析(A.4和A.5)。
4.3 ADDING COORDINATE INFORMATION AND OCCLUSIONS
最大化全局和局部特征之间的互信息并不是利用图像结构的唯一方法。我们考虑通过在计算全局特征时添加输入遮挡和增加辅助任务来增强DIM,这些任务旨在最大化局部特征与给定全局特征的绝对或相对空间坐标之间的互信息。这些改进提升了分类结果(见表5)。

对于遮挡,我们在计算全局特征时随机遮挡输入的一部分,同时使用完整输入计算局部特征。最大化遮挡的全局特征与未遮挡的局部特征之间的互信息,可以有效鼓励全局特征编码整张图像共享的信息。对于坐标预测,我们最大化模型预测局部特征 c ( i , j ) = C ψ ( i , j ) ( x ) c_{(i,j)}=C_\psi^{(i,j)}(x) c(i,j)=Cψ(i,j)(x)的坐标 ( i , j ) (i,j) (i,j)的能力,在计算全局特征 y = E ψ ( x ) y=E_\psi(x) y=Eψ(x)后,目标为最大化 E [ log p θ ( ( i , j ) ∣ y , c ( i , j ) ) ] \mathbb{E}[\log p_\theta((i,j)|y,c_{(i,j)})] E[logpθ((i,j)∣y,c(i,j))](即最小化交叉熵)。该任务还可以扩展为在给定全局特征 y y y的情况下,最大化局部特征对 ( c ( i , j ) , c ( i ′ , j ′ ) ) (c_{(i,j)},c_{(i^{\prime},j^{\prime})}) (c(i,j),c(i′,j′))及其相对坐标 ( i − i ′ , j − j ′ ) (i-i^{\prime},j-j^{\prime}) (i−i′,j−j′)之间的条件互信息。这个目标可以表示为 E [ log p θ ( ( i − i ′ , j − j ′ ) ∣ y , c ( i , j ) , c ( i ′ , j ′ ) ) ] \mathbb{E}[\log p_{\theta}((i-i^{\prime},j-j^{\prime})|y,c_{(i,j)},c_{(i^{\prime},j^{\prime})})] E[logpθ((i−i′,j−j′)∣y,c(i,j),c(i′,j′))]。我们的结果中使用了这两个目标。
附录(A.7)中包含了额外的实现细节。简单来说,我们的输入遮挡和坐标预测任务可以被视为对自监督特征学习中提出的修复(inpainting,Pathak等,2016)和上下文预测(context prediction,Doersch等,2015)任务的推广。通过这些任务增强DIM,有助于推动我们的方法进一步向学习表示转变,不仅仅是压缩低级(如像素)内容,还包括从低级内容中提取的高层特征之间的关系分布。
5. CONCLUSION
本研究介绍了深度信息最大化(Deep InfoMax, DIM),一种通过最大化互信息学习无监督表示的新方法。DIM能够捕捉在结构“位置”(例如图像中的块)之间具有局部一致性的信息。这为学习在多种任务中表现良好的表示提供了一种简单且灵活的方法。我们认为,这一方向对学习更高级别的表示具有重要意义。
6. 参考文献
1.LEARNING DEEP REPRESENTATIONS BY MUTUAL IN-
FORMATION ESTIMATION AND MAXIMIZATION
相关文章:
Deep InfoMax(DIM)(2019-02-ICLR)
论文:LEARNING DEEP REPRESENTATIONS BY MUTUAL INFORMATION ESTIMATION AND MAXIMIZATION ABSTRACT 研究目标 研究通过最大化输入和深度神经网络编码器输出之间的互信息来进行无监督表示学习目的是学习到对下游任务有用的特征表示 核心发现:结构很重…...

2024年10月中国数据库排行榜:TiDB续探花,GaussDB升四强
10月中国数据库流行度排行榜如期发布,再次印证了市场分层的加速形成。国家数据库测评结果已然揭晓,本批次通过的产品数量有限,凸显了行业标准的严格与技术门槛的提升。再看排行榜,得分差距明显增大,第三名与后续竞争者…...

css边框修饰
一、设置线条样式 通过 border-style 属性设置,可选择的一些属性如下: dotted:点线 dashed:虚线 solid:实线 double:双实线 效果如下: 二、设置边框线宽度 ① 通过 border-width 整体设置…...

利用Python进行数据可视化:实用指南与推荐库
利用Python进行数据可视化:实用指南与推荐库 数据可视化是将数据转化为图形和图表的过程,它能够帮助我们更直观地理解数据的趋势、模式和关系。在Python中,有许多强大的库可用于数据可视化,从简单的折线图到复杂的交互式图表,应有尽有。本文将详细介绍Python数据可视化的…...

MobileNetv2网络详解
背景: MobileNet v1中DW卷积在训练完之后部分卷积核会废掉,大部分参数为“0” MobileNet v2网络是由Google团队在2018年提出的,相比于MobileNet v1网络,准确率更高,模型更小 网络亮点: Inverted Residu…...

惊了!大模型连这样的验证码都能读懂_java_识别验证码
最近在看视觉大模型的能力,然后用了某网站的一个验证码试了试,竟然连这样的验证码都能认识,这个有点夸张,尤其是这个9和6颠倒的都能理解,现在的能力已经这么牛了么 具体就是用了通义最新的qwen vl模型spring ai alibab…...
【小白学机器学习26】 极大似然估计,K2检验,logit逻辑回归(对数回归)(未完成----)
目录 1 先从一个例题出来,预期值和现实值的差异怎么评价? 1.1 这样一个问题 1.2 我们的一般分析 1.3 用到的关键点1 1.4 但是差距多远,算是远呢? 2 极大似然估计 2.1 极大似然估计的目的 2.1.1 极大似然估计要解决什么问题…...

【日常记录-Java】SLF4J扫描实现框架的过程
1. 简介 SLF4J(Simple Logging Facade for Java)作为一种简单的门面或抽象,服务于其他各种日志框架,例如JUL、log4j、logback等,核心作用有两项: 提供日志接口;提供获取具体日志对象的方法; 2. 扫描过程 …...

uni-app 获取 android 手机 IMEI码
1、需求来源 最近项目上需要获取手机的IMEI码,并且在更换手机号登录后,需要提示重新更新IMEI码。 2、需求拆分 2.1 获取 IMEI 码 查阅 uni-app 官网发现在android 10 已经无法获取imei码,所以对于这个需求拆分成两种情况。 第一种情况&am…...
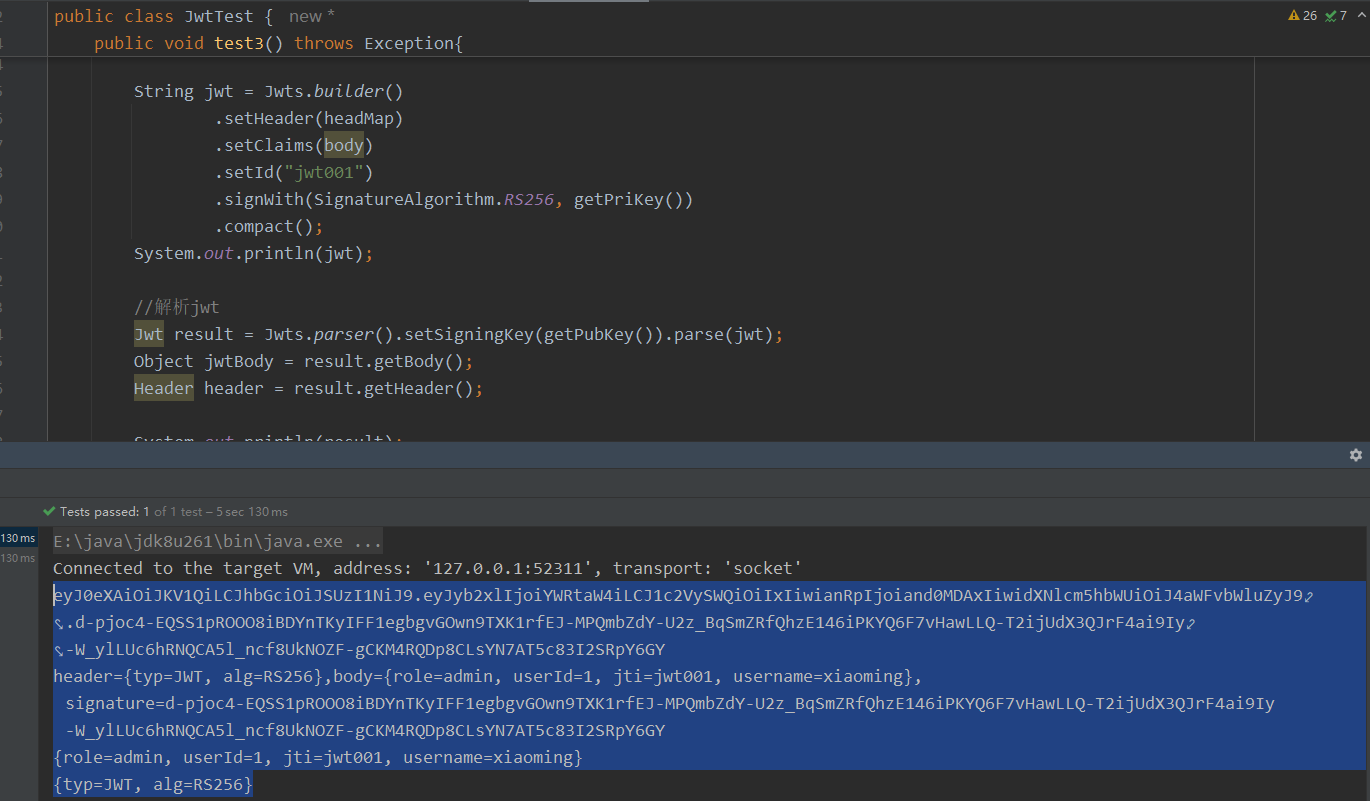
后台管理系统的通用权限解决方案(八)认证机制介绍、JWT介绍与jjwt框架的使用
文章目录 1 认证机制介绍1.1 HTTP Basic Auth1.2 Cookie-Session Auth1.3 OAuth1.4 Token Auth 2 JWT2.1 JWT介绍2.2 JWT的数据结构2.2.1 JWT头2.2.2 JWT有效载荷2.2.3 JWT签名 3 jjwt3.1 jjwt介绍3.2 jjwt案例 1 认证机制介绍 1.1 HTTP Basic Auth HTTP Basic Auth 是一种简…...

接口测试 —— Postman 变量了解一下!
Postman变量是在Postman工具中使用的一种特殊功能,用于存储和管理动态数据。它们可以用于在请求的不同部分、环境或集合之间共享和重复使用值。 Postman变量有以下几种类型: 1、环境变量(Environment Variables): 环境变量是在…...

鸿蒙系统:核心特性、发展历程与面临的机遇与挑战
好动与不满足是进步的第一必需品 文章目录 前言重要特点和组成部分核心特性主要组件发展历程 机遇挑战总结 前言 鸿蒙系统(HarmonyOS)是由华为技术有限公司开发的一款面向全场景的分布式操作系统。它旨在为用户提供更加流畅、安全且高效的数字生活体验&…...
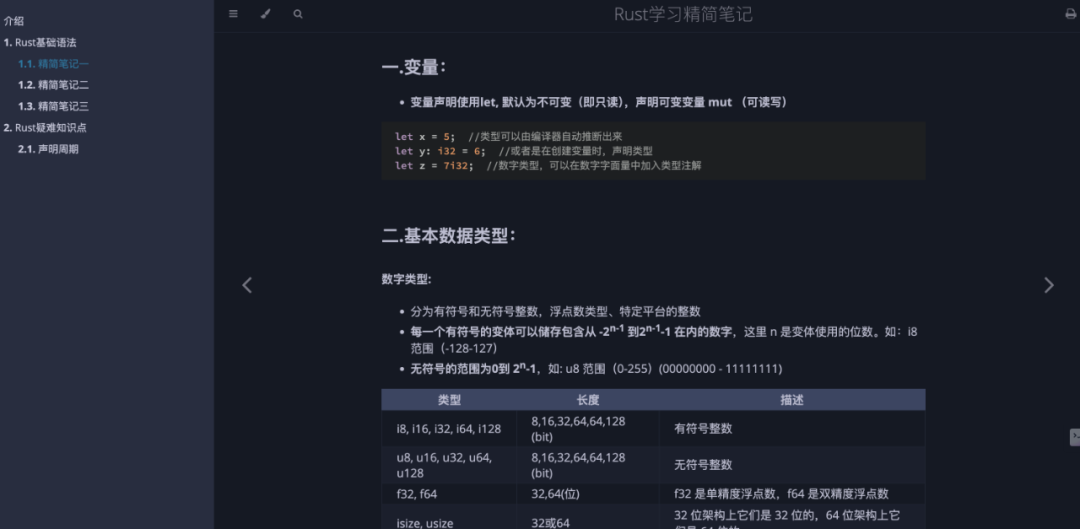
从0到1,用Rust轻松制作电子书
我之前简单提到过用 Rust 做电子书,今天分享下如何用Rust做电子书。制作电子书其实用途广泛,不仅可以用于技术文档(对技术人来说非常方便),也可以制作用户手册、笔记、教程等,还可以应用于文学创作。 如果…...

半天入门!锂电池剩余寿命预测(Python)
往期精彩内容: 时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 全是干货 | 数据集、学习资料、建模资源分享! EMD变体分解效果最好算法——CEEMDAN(五)-CSDN博客 拒绝信息泄露!VMD滚动分…...

学生党头戴式耳机哪款音质更胜一筹?TOP4好音质头戴式耳机推荐
在挑选头戴式耳机时,市场上琳琅满目的品牌和型号常常让人目不暇接。究竟哪个学生党头戴式耳机哪款音质更胜一筹?这已成为许多人面临的难题。由于每个人对耳机的偏好各有侧重——一些人追求音质的纯净,一些人重视佩戴的舒适性,而另…...

数据结构 ——— 二叉树的概念及结构
目录 二叉树的概念 特殊的二叉树 一、满二叉树 二、完全二叉树 二叉树的概念 二叉树树示意图: 从以上二叉树示意图可以看出: 二叉树每个节点的度不大于 2 ,那么整个二叉树的度也不大于 2 ,但是也不是每个节点都必须有 2 个…...

【React】React 的核心设计思想
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React 的核心设计思想引言声明式编程声明式 vs 命令式示例 组件化组件的优势组件…...

C++ 二叉树进阶:相关习题解析
目录 1. 二叉树创建字符串。 2. 二叉树的分层遍历1 3. 二叉树的分层遍历2 4. 二叉树的最近公共祖先 5. 将二叉搜索树转换为排序的双向链表 6. 从前序与中序遍历序列构造二叉树 7. 从中序与后序遍历序列构造二叉树 8. 二叉树的前序遍历,非递归迭代实现 9.…...

Matlab实现蚁群算法求解旅行商优化问题(TSP)(理论+例子+程序)
一、蚁群算法 蚁群算法由意大利学者Dorigo M等根据自然界蚂蚁觅食行为提岀。蚂蚁觅食行为表示大量蚂蚁组成的群体构成一个信息正反馈机制,在同一时间内路径越短蚂蚁分泌的信息就越多,蚂蚁选择该路径的概率就更大。 蚁群算法的思想来源于自然界蚂蚁觅食&a…...

2024年10月HarmonyOS应用开发者基础认证全新题库
注意事项:切记在考试之外的设备上打开题库进行搜索,防止切屏三次考试自动结束,题目是乱序,每次考试,选项的顺序都不同 这是基础认证题库,不是高级认证题库注意看清楚标题 高级认证题库地址:20…...
HCCS:整数优化的Transformer注意力Softmax替代方案
1. 整数优化的HCCS软最大替代方案概述在Transformer架构的多头注意力机制中,Softmax函数长期以来都是计算效率的瓶颈环节。传统Softmax需要进行指数运算和归一化操作,这在低精度整数推理场景下尤为昂贵。我们提出的HCCS(Head-Calibrated Clip…...

Windows平台Android开发环境自动化部署:ADB与Fastboot驱动智能安装工具技术解析
Windows平台Android开发环境自动化部署:ADB与Fastboot驱动智能安装工具技术解析 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitc…...

《Python脚本到OpenClaw技能:解锁Agent原生能力的转换指南》
将零散的Python脚本封装为OpenClaw技能,本质上是在为孤立的计算逻辑注入智能体的感知与决策能力。这不是简单的代码迁移,而是一场从"命令式执行"到"意图式响应"的范式转变。那些曾经只能在终端手动触发的脚本,一旦被赋予了技能的形态,就能被智能体在恰…...

CODESYS与C#共享内存通讯踩坑实录:从“找不到路径”到稳定运行的调试指南
CODESYS与C#共享内存通讯实战:从命名空间陷阱到工业级稳定方案 在工业自动化项目中,CODESYS与上位机程序的实时数据交换堪称"生命线"。共享内存作为性能最高的IPC方式,理论上能达到微秒级响应——直到你在部署现场遇到那个经典的&q…...

安全扫描自动化:构建持续安全检测体系
安全扫描自动化:构建持续安全检测体系 一、安全扫描自动化概述 1.1 安全扫描自动化的定义 安全扫描自动化是指通过工具和脚本自动执行安全检测任务,包括漏洞扫描、代码安全检测、配置安全检查等。它是DevSecOps实践的重要组成部分。 1.2 安全扫描自动化的…...

S32K144 Lin组件实战:告别官方LinStack,手把手教你用底层驱动搞定超声波雷达
S32K144 Lin组件实战:从高级封装到底层驱动的技术跃迁 在嵌入式开发领域,协议栈选择往往决定了项目的灵活性与开发效率。当我们使用NXP S32K144微控制器进行LIN总线通信时,官方提供的LinStack组件确实能快速搭建基础通信框架。但真正投入工业…...

在Node.js服务中集成Taotoken实现稳定的大模型调用方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型调用方案 应用场景类,针对需要构建AI功能的后端开发者,阐述如…...

告别限速!百度网盘解析工具终极使用指南
告别限速!百度网盘解析工具终极使用指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而烦恼吗?今天我要为你介绍一个…...

AI原生安全CLI Zypheron:重构渗透测试工作流,智能引导实战攻防
1. 项目概述:一个为实战而生的AI原生安全CLI如果你和我一样,常年泡在终端里,跟各种扫描器、爆破工具、信息收集脚本打交道,那你肯定也烦透了那种“脚本动物园”的工作模式。左手一个nmap输出要存成XML,右手一个subfind…...

别再让LLM“编造”非功能需求!SITS 2026强制要求的NFR提取三原则,90%团队至今未通过合规审计
更多请点击: https://intelliparadigm.com 第一章:AI原生需求分析:SITS 2026自然语言转需求实践 在 SITS(Software Intelligence Transformation Standard)2026 框架下,AI 原生需求分析不再依赖人工撰写 P…...