clickhouse运维篇(二):多机器手动部署ck集群
熟悉流程并且有真正部署需求可以看一下我的另一篇简化部署的文章,因为多节点配置还是比较麻烦的先要jdk、zookeeper,再ck,还有各种配置文件登录不同机器上手动改配置文件还挺容易出错的。
clickhouse运维篇(三):生产环境一键生成配置并快速部署ck集群
多机器手动部署ck集群
- 1、 安装jdk
- 2、 zookeeper集群搭建(选举机制,奇数节点部署)
- 3、 clickhouse集群规划
- 4、 clickhouse集群搭建
- 5、 配置nginx代理
- 6、 集群验证
- 7、 分布式,本地表测试
1、 安装jdk
上传jdk安装包到各节点
1、解压安装包 (这里举例解压到/opt/jdk8u333)
2、 执行 sh setup.sh install
3、 修改环境变量
vi /etc/profile
vi /etc/profile
在文件末尾加
#java
export JAVA_HOME=/opt/jdk8u333
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}
export PATH=$PATH:${JAVA_HOME}/bin
4、 执行指令生效
source /etc/profile
2、 zookeeper集群搭建(选举机制,奇数节点部署)
举例三个节点:
172.168.1.206
172.168.1.207
172.168.1.208
上传安装包到各节点
解压安装包(这里举例解压到/opt/app/zookeeper-3.7.2)
1、创建目录
mkdir /opt/app/zookeeper-3.7.2/zkData2、 复制zoo_sample.cfg文件命名为 zoo.cfg
cp zoo_sample.cfg zoo.cfg3、 在各个节点创建一个id(距离下边在206、207、208三个节点的zkData目录下分别创建)
echo 1 >/opt/app/zookeeper-3.7.2/zkData/myid
echo 2 >/opt/app/zookeeper-3.7.2/zkData/myid
echo 3 >/opt/app/zookeeper-3.7.2/zkData/myid4、修改zoo.cfg文件
vi zoo.cfgclientPort为16871
dataDir为上边创建的zkData
server.后边的1、2、3为机器节点id;
server.1=172.168.1.206:2888:3888
server.2=172.168.1.207:2888:3888
server.3=172.168.1.208:2888:3888
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/app/zookeeper-3.7.2/zkData
clientPort=16871
server.1=172.168.1.206:2888:3888
server.2=172.168.1.207:2888:3888
server.3=172.168.1.208:2888:38885、 在其余节点重复以上操作,在bin目录下执行启动脚本
sh zkServer.sh start6、 查看集群状态
./zkServer.sh status
说明集群搭建完成,172.168.1.208是主节点
3、 clickhouse集群规划

- 根据集群部署分配的服务器进行预先考虑
a. 需要多少个分片 【多少台机器多少个分片,最好一个机器不要多分片,会导致查询的负载不平衡,导致短筒效应 (保证分片数<=机器数最佳)】
b. 每个分片多少个副本 【默认同一个分片的副本不要在同一个机器上,不能起到容灾作用,一般情况一个分片内两个实例即可,一主一副】
-
同一个实例不能既是主分片又是副本分片,想要部署m分片每个分片内n个实例的集群就需要部署 m*n 个clickhouse实例。
-
例如,所以如果只有三台机器,想部署3分片每个分片2实例的集群就需要3*2=6个 实例【遵循上面1.a中 分片数<=机器数】。 如果机器1上有了shard1的分片,副本实例就最好启动在机器2或者机器3上【遵循上面1.b中 同一分片副本不在相同机器】

4、 clickhouse集群搭建
举例三个节点:
172.168.1.206
172.168.1.207
172.168.1.208
上传安装包到各节点
1、解压安装包 (这里举例解压到/opt/app/clickhouse-23.4.2.9)
2、 修改配置文件,打开config目录
cd config
vi config.xml3、 修改config.xml文件
设置clickhouse端口16860
打开所有地址监听
tcp端口默认9000(可以按需修改)
<http_port>16860</http_port>
<listen_host>::</listen_host>
<tcp_port>9000</tcp_port>
添加集群节点信息 【三机器两分片、每个分片两个实例的配置文件】
// clickhose xml需要修改的内容<remote_servers><!-- 可自定义clickhouse集群名 --><ck_cluster><!-- 数据分片1 --><shard><internal_replication>true</internal_replication><!-- 副本1 --><replica><host>172.168.1.206</host><port>9000</port><user>default</user><password>my_password</password></replica><!-- 副本2 --><replica><host>172.168.1.207</host><port>9000</port><user>default</user><password>my_password</password></replica></shard><!-- 数据分片2 --><shard><internal_replication>true</internal_replication><replica><host>172.168.1.207</host><port>9001</port><user>default</user><password>my_password</password></replica><replica><host>172.168.1.208</host><port>9000</port><user>default</user><password>my_password</password></replica></shard></ck_cluster></remote_servers><macros><shard>02</shard><replica>replica_208</replica></macros><zookeeper><!-- index内容为server.id --><node index="1"><host>172.168.1.206</host><port>16871</port></node><node index="2"><host>172.168.1.207</host><port>16871</port></node><node index="3"><host>172.168.1.208</host><port>16871</port></node></zookeeper><!-- 如果一个机器上部署多个实例这几个端口不要冲突 --><http_port>16860</http_port><tcp_port>9000</tcp_port><interserver_http_host>172.168.1.208</interserver_http_host><interserver_http_port>9009</interserver_http_port><http><max_connections>1024</max_connections><async_insert>1</async_insert> <!-- 启用异步插入 --></http><!-- vim下输入 /clickhouse-23.4 查找path相关tag是否配置正确 --> <path>/opt/app/my_app-2.4/clickhouse-23.4.2.9/data/</path><format_schema_path>/opt/app/my_app-2.4/clickhouse-23.4.2.9/data/format_schemas/</format_schema_path><log>/opt/app/my_app-2.4/clickhouse-23.4.2.9/log/clickhouse-server/clickhouse-server.log</log><errorlog>/opt/app/my_app-2.4/clickhouse-23.4.2.9/log/clickhouse-server/clickhouse-server.err.log</errorlog><tmp_path>/opt/app/my_app-2.4/clickhouse-23.4.2.9/tmp/</tmp_path><user_files_path>/opt/app/my_app-2.4/clickhouse-23.4.2.9/data/user_files/</user_files_path>4、修改users.xml文件
设置default账号的密码
<password>my_password</password>
5、其余节点重复以上步骤,然后启动服务(注意修改config.xml中的值)
/opt/app/my_app-2.4/clickhouse-23.4.2.9/bin/clickhouse server --config-file /opt/app/my_app-2.4/clickhouse-23.4.2.9/config/config.xml --pid-file /opt/app/my_app-2.4/clickhouse-23.4.2.9/clickhouse.pid --daemon
5、 配置nginx代理
编辑nginx配置文件底部加入clickhouse反向代理供web服务调用
$ vim /opt/app/my_app-2.4/nginx/conf/my_app.confupstream clickhouse_cluster {server 172.168.1.206:16860;server 172.168.1.207:16860;server 172.168.1.207:16861; server 172.168.1.208:16860;
}# 新增的 ClickHouse 反向代理并配置相应的黑白名单策略, 入的流量应该是访问ck集群的流量,
# 所以应该是访问源的网段也就是my_app对应的网段或者ip
server {listen 1442;allow localhost;allow 192.168.13.0/24;allow 10.1.5.0/16; deny all;location / {proxy_pass http://clickhouse_cluster;}
}
● nginx反向代理验证
[root@localhost ~]# curl localhost:1442
Ok.
6、 集群验证
这里使用dbever工具验证
1、执行sql,查看ck集群节点状态
SELECT * from system.clusters;
2、执行sql,查看zookeeper中/clickhouse的节点是否存在
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
如果截图如上则表示分布式集群部署成功
查看各个节点状态,关注最后一列可以看出各个节点的与集群的连接状况【比如第三行数字22就是实例与cluster连接有问题】
7、 分布式,本地表测试
- 语句加
on cluster ck_cluster就是在所有实例上执行
创建一个表
-- 删除本地表
DROP TABLE IF EXISTS test_table_local on cluster ck_cluster SYNC;-- 创建本地表
CREATE TABLE test_table_local ON CLUSTER ck_cluster
(`tenantId` UInt64 CODEC (Delta(8), ZSTD(1)),`alarmId` String,`grade` Int32,
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{uuid}/{shard}/audit_log_local', '{replica}');-- 删除分布式表
DROP TABLE IF EXISTS test_table_all on cluster ck_cluster SYNC;
-- 创建分布式表
CREATE TABLE test_table_all ON CLUSTER ck_cluster as test_table_local ENGINE = Distributed('ck_cluster', 'default', 'test_table_local', rand());
分布式表测试
SELECT count(*) FROM test_table_all;
本地表测试
INSERT INTO test_table_local (id, name, grade) VALUES (1,'jack',60);
相关文章:
clickhouse运维篇(二):多机器手动部署ck集群
熟悉流程并且有真正部署需求可以看一下我的另一篇简化部署的文章,因为多节点配置还是比较麻烦的先要jdk、zookeeper,再ck,还有各种配置文件登录不同机器上手动改配置文件还挺容易出错的。 clickhouse运维篇(三)&#x…...

OpenCV视觉分析之目标跟踪(7)目标跟踪器类TrackerVit的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 VIT 跟踪器由于特殊的模型结构而变得更快且极其轻量级,模型文件大约为 767KB。模型下载链接:https://github.com/opencv/…...

Java 实现 RESTful 风格的 Web 服务详解
前言 RESTful(Representational State Transfer)风格的 API 已经成为现代 Web 服务的标准。它通过简单的 HTTP 方法和资源定位来提供了一种高度可扩展和易于维护的服务接口。Java 作为一种功能强大且广泛使用的编程语言,提供了多种框架来实现…...

18.网工入门篇--------今天介绍下广域网技术
广域网(Wide Area Network,WAN)是一种能连接多个城市、国家甚至横跨几个洲,提供远距离通信的网络。以下是关于广域网技术的详细介绍: 广域网的组成: 结点交换机:这是广域网的核心设备࿰…...

鸿蒙原生应用开发及部署:首选华为云,开启HarmonyOS NEXT App新纪元
目录 前言 HarmonyOS NEXT:下一代操作系统的愿景 1、核心特性和优势 2、如何推动应用生态的发展 3、对开发者和用户的影响 华为云服务在鸿蒙原生应用开发中的作用 1、华为云ECS C系列实例 (1)全维度性能升级 (2ÿ…...

Spring JdbcTemplate详解
文章目录 Spring JdbcTemplate详解一、引言二、配置JdbcTemplate1、引入依赖2、配置数据库连接池3、配置JdbcTemplate 三、使用JdbcTemplate操作数据库1、添加数据2、查询数据查询某个值根据条件查询返回某个对象查询对象集合 四、总结 Spring JdbcTemplate详解 一、引言 在J…...

Docker篇(Docker安装)
目录 一、Centos7.x 1. yum 包更新到最新 2. 安装需要的软件包 3. 设置 yum 源为阿里云 4. 安装docker 5. 安装后查看docker版本 6. 设置ustc镜像源 二、CentOS安装Docker 前言 1. 卸载(可选) 2. 安装docker 3. 启动docker 4. 配置镜像加速 …...

Pytorch 实现图片分类
CNN 网络适用于图片识别,卷积神经网络主要用于图片的处理识别。卷积神经网络,包括一下几部分,输入层、卷积层、池化层、全链接层和输出层。 使用 CIFAR-10 进行训练, CIFAR-10 中图片尺寸为 32 * 32。卷积层通过卷积核移动进行计…...

得物App获评新奖项,正品保障夯实供应链创新水平
近日,得物App再度获评新奖项——“2024上海市供应链创新与应用优秀案例”。 本次奖项为上海市供应链领域最高奖项,旨在评选出在供应链创新成效上处于领先地位、拥有成功模式和经验的企业。今年以来,得物App已接连获得“上海市质量金奖”、“科…...

【数据结构-邻项消除】力扣735. 小行星碰撞
给定一个整数数组 asteroids,表示在同一行的小行星。 对于数组中的每一个元素,其绝对值表示小行星的大小,正负表示小行星的移动方向(正表示向右移动,负表示向左移动)。每一颗小行星以相同的速度移动。 找…...

002-Kotlin界面开发之Kotlin旋风之旅
Kotlin旋风之旅 Compose Desktop中哪些Kotlin知识是必须的? 在学习Compose Desktop中,以下Kotlin知识是必须的: 基础语法:包括变量声明、数据类型、条件语句、循环等。面向对象编程:类与对象、继承、接口、抽象类等。…...
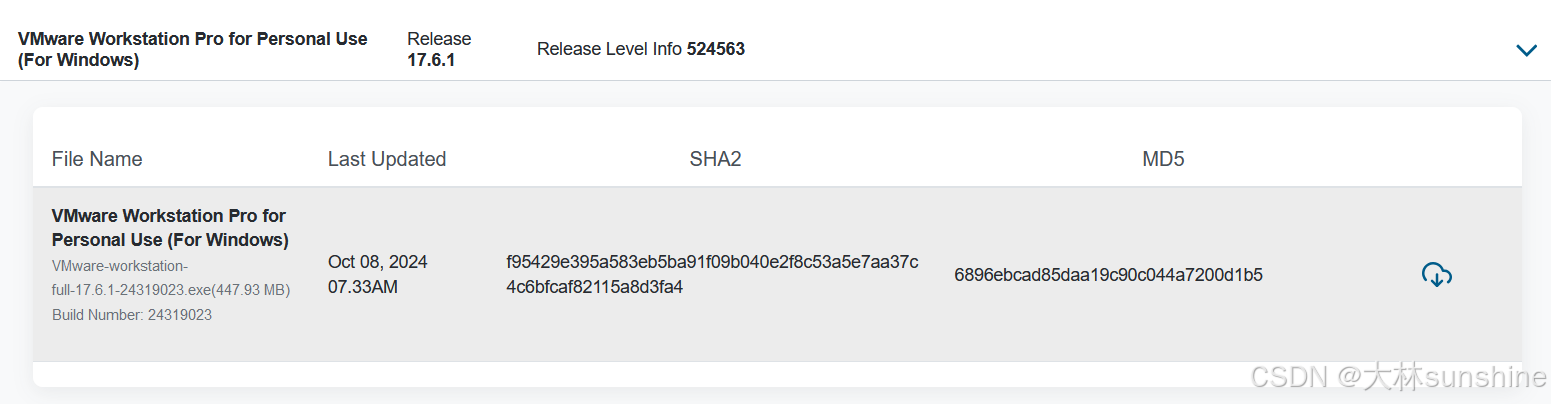
VMware Workstation Pro for Personal Use (For Windows)
这是从broadcom.com网下载的个人版本的Vmware 17.6.1,存分享不要分。 VMware-workstation-full-17.6.1-24319023.exe(447.93 MB) Build Number: 24319023 Oct 08, 2024 07.33AM SHA2: f95429e395a583eb5ba91f09b040e2f8c53a5e7aa37c4c6bfcaf82115a8…...

论文 | PROMPTAGATOR : FEW-SHOT DENSE RETRIEVAL FROM 8 EXAMPLES
1. 背景信息 在信息检索领域,传统的方法往往依赖于大量的标注数据来训练模型,以便在各种任务中表现良好。然而,许多实际应用中的监督数据是有限的,尤其是在不同的检索任务中。最近的研究开始关注如何从一个拥有丰富监督数据的任务…...
使用 Github 进行项目管理
GitHub 是一个广泛使用的代码托管和协作平台,它提供了强大的工具来支持项目管理和团队协作。在项目开发和工作中,避免不了 Github 的使用,然鹅我一直没有稍微系统地学习过 github 的整个工作流程,对这些操作都是一知半解的&#x…...

企业SRC挖掘选择与信息收集指南
内容预览 ≧∀≦ゞ 企业SRC挖掘选择与信息收集指南导语1. 企业SRC的选择2. 信息收集2.1 集团与子公司2.2 小程序与APP2.3 Web端信息收集 3. 信息收集常用模板总结 企业SRC挖掘选择与信息收集指南 导语 近年来,企业的安全响应中心(SRC)已逐渐…...

Golang | Leetcode Golang题解之第524题通过删除字母匹配到字典里最长单词
题目: 题解: func findLongestWord(s string, dictionary []string) (ans string) {m : len(s)f : make([][26]int, m1)for i : range f[m] {f[m][i] m}for i : m - 1; i > 0; i-- {f[i] f[i1]f[i][s[i]-a] i}outer:for _, t : range dictionary …...
【DBeaver】连接带kerberos的hive[Apache|HDP]
目录 一、安装配置Kerberos客户端环境 1.1 安装Kerberos客户端 1.2 环境配置 二、基于Cloudera驱动创建连接 三、基于Hive原生驱动创建连接 一、安装配置Kerberos客户端环境 1.1 安装Kerberos客户端 在Kerberos官网下载,地址如下:https://web.mit.edu/kerberos…...
Unity3D 开发教程:从入门到精通
Unity3D 开发教程:从入门到精通 Unity3D 是一款强大的跨平台游戏引擎,广泛应用于游戏开发、虚拟现实、增强现实等领域。本文将详细介绍 Unity3D 的基本概念、开发流程以及一些高级技巧,帮助你从零基础到掌握 Unity3D 开发。 目录 Unity3D…...
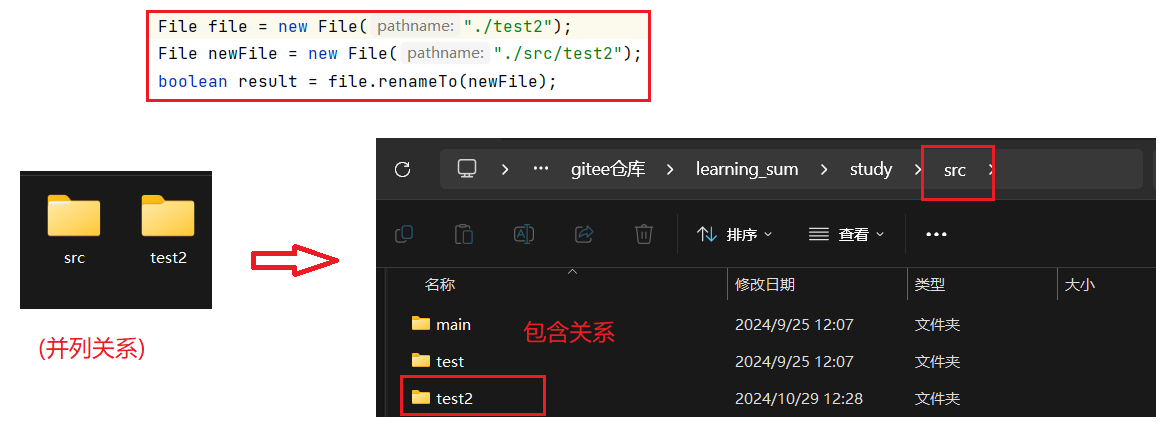
文件操作和 IO(一):文件基础知识 文件系统操作 => File类
目录 1. 什么是文件 1.1 概念 1.2 硬盘, 内存, 寄存器之间的区别 1.3 机械硬盘和固态硬盘 2. 文件路径 2.1 绝对路径 2.2 相对路径 3. 文件分类 4. File 类 4.1 属性 4.2 构造方法 4.3 方法 1. 什么是文件 1.1 概念 狭义上的文件: 保存在硬盘上的文件广义的上的文…...

用Pyhon写一款简单的益智类小游戏——2048
文字版——代码及讲解 代码—— import random# 初始化游戏棋盘 def init_board():return [[0] * 4 for _ in range(4)]# 在棋盘上随机生成一个2或4 def add_new_tile(board):empty_cells [(i, j) for i in range(4) for j in range(4) if board[i][j] 0]if empty_cells:i,…...

Prism Launcher:重新定义你的Minecraft启动体验
Prism Launcher:重新定义你的Minecraft启动体验 【免费下载链接】PrismLauncher A custom launcher for Minecraft that allows you to easily manage multiple installations of Minecraft at once (Fork of MultiMC) 项目地址: https://gitcode.com/gh_mirrors/…...

30天学会AI工程师|Day 14:自己实现一个小工具,你才会真正理解 Agent 是怎么“动起来”的
你先知道一件事 昨天你理解了 Tool Calling 的概念,今天最好亲手做一个最小工具。 为什么这一步重要 你完全可以从一个非常简单的例子开始。比如做一个计算器工具,输入两个数字和一个运算符,返回结果。或者做一个时间查询工具,返回…...

终极直播输入可视化指南:如何用开源工具展示键盘鼠标操作
终极直播输入可视化指南:如何用开源工具展示键盘鼠标操作 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 在游戏直播、教学演示或技术分享中,观众…...

终极免费InfluxDB图形化管理工具:告别命令行的高效解决方案
终极免费InfluxDB图形化管理工具:告别命令行的高效解决方案 【免费下载链接】InfluxDBStudio InfluxDB Studio is a UI management tool for the InfluxDB time series database. 项目地址: https://gitcode.com/gh_mirrors/in/InfluxDBStudio 你是否厌倦了在…...

3分钟上手Bifrost:跨平台三星固件下载与解密终极指南
3分钟上手Bifrost:跨平台三星固件下载与解密终极指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备刷机找不到官方固件而烦恼吗&…...
)
中药实验管理系统|基于springboot+vue的中药实验管理系统(源码+数据库+文档)
中药实验管理系统 目录 基于springbootvue的中药实验管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

9 款 AI 毕业论文工具硬核横评:okbiye 领衔,解锁高效合规写作新路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的本科论文写作,向来是耗时耗力的 “攻坚战”。选题迷茫、大纲混乱、格式反复出错、查重屡屡超标、AI 痕迹过重难通过检测…...

猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源
猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾…...

别再死记硬背了!COBOL中COMP、COMP-3、COMP-5数据类型的区别与实战赋值避坑指南
COBOL数值类型实战手册:COMP家族的内存布局与精准赋值策略 在金融核心系统维护中,我曾目睹过因COMP-3类型使用不当导致整月利息计算误差达六位数的生产事故。这种"古董级"数据类型的独特设计,至今仍在每秒处理数百万交易的银行系统…...

Hyperf 高并发的庖丁解牛
它的本质是:**Hyperf 的高并发并非来自 PHP 语言本身的计算速度,而是来自对 I/O 等待时间 (I/O Wait Time) 的极致利用。它通过 Swoole/Swow 扩展 将传统的 同步阻塞 (Sync-Blocking) 模式转变为 异步非阻塞 (Async-Non-blocking) 模式,并利用…...