【力扣 + 牛客 | SQL题 | 每日6题】牛客SQL热题 + 力扣hard
1. 牛客SQL热题206:获取每个部门中当前员工薪水最高的相关信息
1.1 题目:
描述
有一个员工表dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 |
| 10003 | d002 | 1996-08-03 | 9999-01-01 |
有一个薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10003 | 92527 | 2001-08-02 | 9999-01-01 |
获取每个部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号dept_no升序排列,以上例子输出如下:
| dept_no | emp_no | maxSalary |
| d001 | 10001 | 88958 |
| d002 | 10003 | 92527 |
示例1
输入:drop table if exists `dept_emp` ;
drop table if exists `salaries` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d002','1996-08-03','9999-01-01');INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,92527,'2001-08-02','9999-01-01');
复制输出:d001|10001|88958
d002|10003|925271.2 思路:
一个相关子查询即可搞定。
1.3 题解:
with tep1 as (-- 两表连接select t1.emp_no, dept_no, salaryfrom dept_emp t1join salaries t2on t1.emp_no = t2.emp_no
)select dept_no, emp_no, salary maxSalary
from tep1 t1
where salary = (-- 相关子查询,查找外部记录所在部门的最高薪水select max(salary)from tep1 t2where t1.dept_no = t2.dept_no
)
order by dept_no2. 牛客SQL热题205:获取所有员工当前的manager
2.1 题目:
描述
有一个员工表dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 |
| 10003 | d002 | 1995-12-03 | 9999-01-01 |
第一行表示为员工编号为10001的部门是d001部门。
有一个部门经理表dept_manager简况如下:
| dept_no | emp_no | from_date | to_date |
| d001 | 10002 | 1996-08-03 | 9999-01-01 |
| d002 | 10003 | 1990-08-05 | 9999-01-01 |
第一行表示为d001部门的经理是编号为10002的员工。
获取所有的员工和员工对应的经理,如果员工本身是经理的话则不显示,以上例子如下:
| emp_no | manager |
| 10001 | 10002 |
示例1
输入:drop table if exists `dept_emp` ;
drop table if exists `dept_manager` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d002','1995-12-03','9999-01-01');
INSERT INTO dept_manager VALUES('d001',10002,'1996-08-03','9999-01-01');
INSERT INTO dept_manager VALUES('d002',10003,'1990-08-05','9999-01-01');
复制输出:10001|100022.2 思路:
秒。
2.3 题解:
select t1.emp_no emp_no, t2.emp_no manager
from dept_emp t1
join dept_manager t2
on t1.dept_no = t2.dept_no
and t1.emp_no <> t2.emp_no3. 牛客SQL热题199:查找所有员工的last_name和first_name以及对应部门编号的dept_no
3.1 题目:
描述
有一个员工表,employees简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Christian | Koblick | M | 1986-12-01 |
有一个部门表,dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d002 | 1989-08-03 | 9999-01-01 |
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,也包括暂时没有分配具体部门的员工,以上例子如下:
| last_name | first_name | dept_no |
| Facello | Georgi | d001 |
| Simmel | Bezalel | d002 |
| Bamford | Parto | NULL |
| Koblick | Chirstian | NULL |
示例1
输入:drop table if exists `dept_emp` ;
drop table if exists `employees` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d002','1996-08-03','9999-01-01');
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
复制输出:Facello|Georgi|d001
Simmel|Bezalel|d002
Bamford|Parto|None
Koblick|Chirstian|None3.2 思路:
秒。
3.3 题解:
select last_name , first_name , dept_no
from employees t1
left join dept_emp t2
on t1.emp_no = t2.emp_no 4. 牛客SQL热题198:查找所有已经分配部门的员工的last_name和first_name以及dept_no
4.1 题目:
描述
有一个员工表,employees简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Christian | Koblick | M | 1986-12-01 |
有一个部门表,dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d002 | 1989-08-03 | 9999-01-01 |
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示,以上例子如下:
| last_name | first_name | dept_no |
| Facello | Georgi | d001 |
| Simmel | Bezalel | d002 |
示例1
输入:drop table if exists `dept_emp` ;
drop table if exists `employees` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d002','1996-08-03','9999-01-01');
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
复制输出:Facello|Georgi|d001
Simmel|Bezalel|d0024.2 思路:
秒。
4.3 题解:
select last_name , first_name , dept_no
from employees t1
join dept_emp t2
on t1.emp_no = t2.emp_no 5. 牛客SQL热题197:查找当前薪水详情以及部门编号dept_no
5.1 题目:
描述
有一个全部员工的薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 |
有一个各个部门的领导表dept_manager简况如下:
| dept_no | emp_no | to_date |
| d001 | 10001 | 9999-01-01 |
| d002 | 10003 | 9999-01-01 |
请你查找各个部门当前领导的薪水详情以及其对应部门编号dept_no,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列,以上例子输出如下:
| emp_no | salary | from_date | to_date | dept_no |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 | d001 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 | d002 |
示例1
输入:drop table if exists `salaries` ;
drop table if exists `dept_manager` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
INSERT INTO dept_manager VALUES('d001',10002,'9999-01-01');
INSERT INTO dept_manager VALUES('d002',10006,'9999-01-01');
INSERT INTO dept_manager VALUES('d003',10005,'9999-01-01');
INSERT INTO dept_manager VALUES('d004',10004,'9999-01-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
INSERT INTO salaries VALUES(10005,94692,'2001-09-09','9999-01-01');
INSERT INTO salaries VALUES(10006,43311,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10007,88070,'2002-02-07','9999-01-01');
复制输出:10002|72527|2001-08-02|9999-01-01|d001
10004|74057|2001-11-27|9999-01-01|d004
10005|94692|2001-09-09|9999-01-01|d003
10006|43311|2001-08-02|9999-01-01|d0025.2 思路:
秒。
5.3 题解:
select t1.emp_no, salary, from_date, t1.to_date, dept_no
from salaries t1
join dept_manager t2
on t1.emp_no = t2.emp_no
order by t1.emp_no6. 力扣hard题615:平均薪资:部门与公司比较
6.1 题目:
表:Salary
+-------------+------+ | 列名 | 类型 | +-------------+------+ | id | int | | employee_id | int | | amount | int | | pay_date | date | +-------------+------+ 在 SQL 中,id 是该表的主键列。 该表的每一行表示一个员工一个月的薪资。 employee_id 是来自 Employee 表的外键(reference 列)。
表: Employee
+---------------+------+ | 列名 | 类型 | +---------------+------+ | employee_id | int | | department_id | int | +---------------+------+ 在 SQL 中,employee_id 是该表的主键列。 该表的每一行表示一个员工所属的部门。
找出各个部门员工的平均薪资与公司平均薪资之间的比较结果(更高 / 更低 / 相同)。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Salary 表: +----+-------------+--------+------------+ | id | employee_id | amount | pay_date | +----+-------------+--------+------------+ | 1 | 1 | 9000 | 2017/03/31 | | 2 | 2 | 6000 | 2017/03/31 | | 3 | 3 | 10000 | 2017/03/31 | | 4 | 1 | 7000 | 2017/02/28 | | 5 | 2 | 6000 | 2017/02/28 | | 6 | 3 | 8000 | 2017/02/28 | +----+-------------+--------+------------+ Employee 表: +-------------+---------------+ | employee_id | department_id | +-------------+---------------+ | 1 | 1 | | 2 | 2 | | 3 | 2 | +-------------+---------------+ 输出: +-----------+---------------+------------+ | pay_month | department_id | comparison | +-----------+---------------+------------+ | 2017-02 | 1 | same | | 2017-03 | 1 | higher | | 2017-02 | 2 | same | | 2017-03 | 2 | lower | +-----------+---------------+------------+ 解释: 在三月,公司的平均工资是 (9000+6000+10000)/3 = 8333.33... 部门 '1' 的平均薪资是 9000,因为该部门只有一个员工,其员工号为 '1'。因为 9000 > 8333.33,所以比较结果为 'higher' 部门 '2' 的平均薪资是(6000 + 10000)/ 2 = 8000,该平均薪资是员工号 '2' 和 '3' 的薪资的平均值。因为 8000 < 8333.33,比较结果为 'lower'。根据同样的公式,对于二月份的平均薪资比较,结果为 'same',因为部门 '1' 和 '2' 都与公司的平均薪资相同,即为 7000。
6.2 思路:
两步走:
-- 先求出每个月公司的平均薪资
-- 然后以部门和月份分组,比较分组内的平均薪资与该月份公司的平均薪资的大小
6.3 题解:
-- 先求出每个月公司的平均薪资
with tep1 as (select substring(pay_date, 1, 7) pay_month , round(avg(amount), 4) avgsfrom Salarygroup by substring(pay_date, 1, 7)
), tep2 as (-- 多表连接select t2.employee_id , department_id, amount , substring(pay_date, 1, 7) pay_month from Salary t1 join Employee t2 on t1.employee_id = t2.employee_id
)-- 然后以部门和月份分组,比较分组内的平均薪资与该月份公司的平均薪资的大小
-- 我没有用round过不了最后一个案例,但使用round函数就可以过了。
-- 我也不知道为什么。
select pay_month, department_id,
case when round(avg(amount), 4) > (select avgs from tep1 t2 where t1.pay_month = t2.pay_month)
then 'higher'
when round(avg(amount), 4) < (select avgs from tep1 t2 where t1.pay_month = t2.pay_month)
then 'lower'
else 'same'
end comparison
from tep2 t1
group by pay_month, department_id相关文章:

【力扣 + 牛客 | SQL题 | 每日6题】牛客SQL热题 + 力扣hard
1. 牛客SQL热题206:获取每个部门中当前员工薪水最高的相关信息 1.1 题目: 描述 有一个员工表dept_emp简况如下: emp_nodept_nofrom_dateto_date10001d0011986-06-269999-01-0110002d0011996-08-039999-01-0110003d0021996-08-039999-01-01 有一个薪水…...

前端常见错误
搭建vueelement-ui脚手架错误 基于vue官方文档和element官方文档搭建手册报错 安装element Unchecked runtime.lastError: Could not establish connection. Receiving end does not exist. types.js?8ad0:39 Uncaught TypeError: Cannot read property prototype of undefi…...

Edge 浏览器插件开发:图片切割插件
Edge 浏览器插件开发:图片切割插件 在图片处理领域,按比例切割图片是一个常见需求。本文将带你开发一个 Edge 浏览器插件,用于将用户上传的图片分割成 4 个部分并自动下载到本地。同时,本文介绍如何使用 cursor 辅助工具来更高效…...
银河麒麟v10 xrdp安装
为了解决科技被卡脖子的问题,国家正在大力推进软硬件系统的信创替代,对于一些平时对Linux操作系统不太熟练的用户来讲提出了更高的挑战和要求。本文以银河麒麟v10 24.03为例带领大家配置kylin v10的远程桌面。 最近公司为了配置信创开发新购了几台银河麒…...

Leetcode 删除有序数组中的重复项 Ⅱ
使用双指针来解决此问题,关键词“有序”数组,一个 index 指针用于构建新数组,一个 i 指针用于遍历整个数组 以下是代码的中文解释以及算法思想: 算法思想 这道题要求对一个有序数组进行去重,使得每个元素最多出现两…...

大模型学习笔记------什么是大模型
大模型学习笔记------什么是大模型 1、大模型定义2、大模型发展历程3、大模型的核心特点4、大模型的应用领域5、大模型面临的挑战6、结束语 近两年大模型超级火,并且相关产品迎来爆发式增长。在工作中,也常常接触到大模型,并且已经开始进行相…...

【unique_str 源码学习】
文章目录 1.删除器定义2. operator->() 运算符重载3. add_lvalue_reference<element_type>::type 使用 基本原理这篇博主写的很详细 https://yngzmiao.blog.csdn.net/article/details/105725663 1.删除器定义 deleter_…...

flask第一个应用
文章目录 安装一、编程第一步二、引入配置三、代码解析 安装 python环境安装的过程就不重复赘述了,flask安装使用命令pip install Flask即可,使用命令pip show Flask查看flask版本信息 提示:以下是本篇文章正文内容,下面案例可供…...

华为OD机试真题(Python/JS/C/C++)- 考点 - 细节
华为OD机试 2024E卷题库疯狂收录中,刷题 点这里。 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。...

【C++刷题】力扣-#628-三个数的最大乘积
题目描述 给你一个整型数组 nums ,在数组中找出由三个数组成的最大乘积,并输出这个乘积。 示例 示例 1 输入:nums [1,2,3] 输出:6示例 2 输入:nums [1,2,3,4] 输出:24示例 3 输入:nums […...

Java项目实战II基于Java+Spring Boot+MySQL的工程教育认证的计算机课程管理平台(源码+数据库+文档)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着工程教…...

基于微信小程序实现信阳毛尖茶叶商城系统设计与实现
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,…...
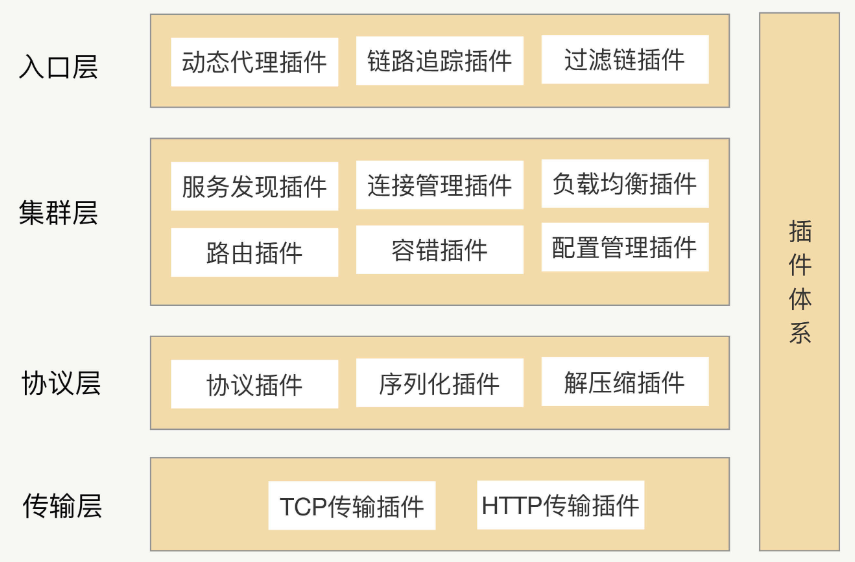
设计一个灵活的RPC架构
RPC架构 RPC本质上就是一个远程调用,需要通过网络来传输数据。传输协议可以有多种选择,但考虑到可靠性,一般默认采用TCP协议。为了屏蔽网络传输的复杂性,需要封装一个单独的数据传输模块用来收发二进制数据,这个单独模…...

大数据计算里的Broadcast Hash Join/Shuffle Hash Join/Sort Merge Join
文章目录 Broadcast Hash Join场景 Shuffle Hash Join场景 Sort Merge Join场景 Broadcast Hash Join 场景 大表和小小表,直接把B表加载到内存,然后读块1内容和内存中数据匹配 Shuffle Hash Join 场景 大表和小表JOIN ,小表分块后能加载…...

Java - 手写识别; 如何用spring ai和大模型做手写识别教程
识别后的文字 利用大模型提升Java手写识别:更简单、更高效 在Java场景中,我们经常需要处理手写识别的问题。过去,这类需求主要依赖于OCR技术,但其效果并不总是稳定。随着大模型的发展,使用大模型进行java手写识别成为…...

【Linux】用户权限管理:创建受限用户并配置特定目录访问权限
本文详细介绍了如何在 Linux 系统中创建一个名为 agent 的新用户,并限制其在特定目录下的权限。通过使用 useradd 命令创建用户,并使用 usermod 命令将新用户添加到现有用户组中,确保其具有适当的权限。接着,通过 chown 和 chmod …...

pgsql表分区和表分片设计
在设计 PostgreSQL 表分区和表分片时,主要目标是提高查询性能、可扩展性和数据管理的效率。以下是一些关键的设计步骤和策略: 1. 分区策略 水平分片:选择按日期进行水平分片,每天一个分片。这种策略适用于具有时间序列数据的场景…...

灵动AI ——视频创作新引擎 开启视觉奇幻之旅
灵动AI视频官网地址:https://aigc.genceai.com/ 灵动AI 科技与艺术的完美融合之作。它代表着当下最前沿的影像技术,为我们带来前所未有的视觉盛宴。...

AI设计、作图、画画工具哪个好用?看完这篇你就知道怎么选了
Stable Diffusion Stable Diffusion 是由 Stability AI 推出的开源 AI 文本到图像生成模型,以其开放性和灵活性在 AI 视觉工具领域广受欢迎。与 DALL-E 或 Midjourney 等只能依赖云计算的工具不同,Stable Diffusion 支持本地运行,也广泛兼容多…...

【python ASR】win11-从0到1使用funasr实现本地离线音频转文本
文章目录 前言一、前提条件安装环境Python 安装安装依赖,使用工业预训练模型最后安装 - torch1. 安装前查看显卡支持的最高CUDA的版本,以便下载torch 对应的版本的安装包。torch 中的CUDA版本要低于显卡最高的CUDA版本。2. 前往网站下载[Pytorch](https://pytorch.o…...

办公效率翻倍!OpenClaw AI 数字员工实操教程
适配系统:Windows 10 64位(新手专享版) 产品亮点: 零门槛安装:无需命令行操作,免去复杂环境配置即开即用:解压即安装,内置完整运行环境可视化操作:全程图形界面&#x…...

图片转Word怎么转?2026年图片转文档完整方法与工具对比
日常工作中,我们经常需要将拍摄的照片、截图或扫描的纸质文件转换成可编辑的Word文档。无论是转录会议笔记、整理手写资料,还是数字化办公文件,高效的转换工具能显著提升工作效率。本文将详细介绍多种图片转word文档的方法,帮你找…...

环保设备系统控制柜制造:从工艺联动到稳定达标的完整解析
一、什么是环保设备系统控制柜制造?环保设备系统控制柜制造,是指根据废气治理、污水处理、粉尘治理、喷淋塔、活性炭吸附、催化燃烧、RTO/RCO、除尘器、风机水泵、加药系统、污泥处理、在线监测和环保设备联动控制等实际需求,对PLC、变频器、…...

英雄联盟Akari助手:免费开源的游戏效率工具完整指南
英雄联盟Akari助手:免费开源的游戏效率工具完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐的操作和…...
)
中药实验管理系统|基于springboot+vue的中药实验管理系统(源码+数据库+文档)
中药实验管理系统 目录 基于springbootvue的中药实验管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生
终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Win…...

C++详解实现Stack方法
栈简介栈本着先进后出的原则,来存取数据。作为数据结构中的一种,这里不多介绍相关栈。仅以此文记录C中栈的实现,可帮助提升编程能力与对栈的理解。stack模拟stack是一种容器适配器,专门在具有后进先出的上下文环境中,其…...

思源宋体TTF:7种字重打造专业中文排版的全新体验
思源宋体TTF:7种字重打造专业中文排版的全新体验 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文设计项目的字体选择头疼吗?今天我要分享一个让我工作…...

ShizuTools LookBack功能剖析:无需卸载即可降级应用的原理与实现
ShizuTools LookBack功能剖析:无需卸载即可降级应用的原理与实现 【免费下载链接】ShizuTools Contains many tools to control android system via shizuku. 项目地址: https://gitcode.com/gh_mirrors/sh/ShizuTools ShizuTools LookBack功能是一款创新的A…...

如何用AntiMicroX解决PC游戏手柄兼容问题:5分钟快速上手终极手柄映射工具
如何用AntiMicroX解决PC游戏手柄兼容问题:5分钟快速上手终极手柄映射工具 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https:/…...