大模型重要技术系列三:高效推理
接上一篇高效训练,这一篇汇总下高效推理的方法。高效推理的两个主要优化目标是低延迟(快速得到推理结果)和高吞吐量(能同时处理很多请求),同时还要尽可能地少用资源(算力、存储、网络带宽)。
如果要说高效训练和高效推理哪个更重要,从产生的效益来说,应该说高效推理更重要,因为模型训练出来最终都是要用来推理使用的。整个生态产业中,训练基座大模型的就那么多家,训练出来更多时间也是对外提供推理服务;具体一个企业中,训练或者微调完模型后,多数时间也是在业务场景中使用推理。
高效推理如此重要,少不了学者们已经总结了综述文章,本文主要基于两篇综述文章,取其精华,从不同的分类角度全面概括高效推理的方法。目前Transformer结构基本一统大模型江山,多数高效推理方法均针对Transformer模型结构。
1
综述一
来自于2023年12月卡莱基梅隆大学的《Towards Efficient Generative Large Language Model Serving:A Survey from Algorithms to Systems》,是一个比较简洁版的综述,从机器学习系统研究的角度,分类如下:
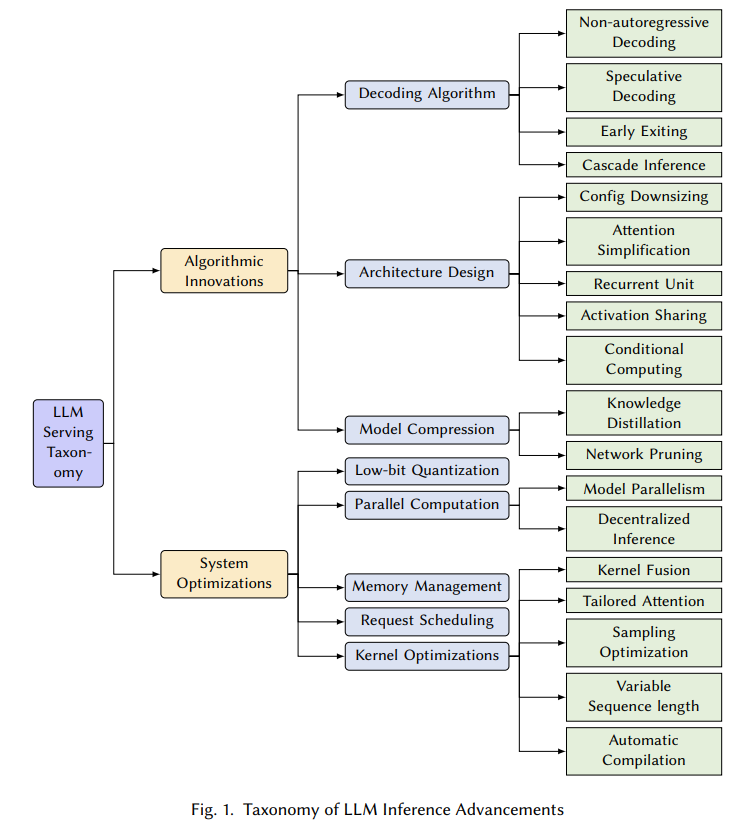
图1. LLM推理技术分类,来源[1]
总体分为模型算法、系统优化两个大类,由于第二篇综述在此基础上增加了数据维度,更全面,我们只从本综述挑选亮点分部分介绍。
1.1 Decoder算法优化
对Decoder算法优化的总结,如下图2。大模型中最常见的是只有解码器的Decoder-Only结构,解码器中最常见的是自回归模型,见图中(a),每一时刻由上一token预测下一token,每一次预测由于attention计算都要消耗大量的资源,优化Decoder就是要想办法减少资源消耗,提高计算效率,包括图中后面四种方法。
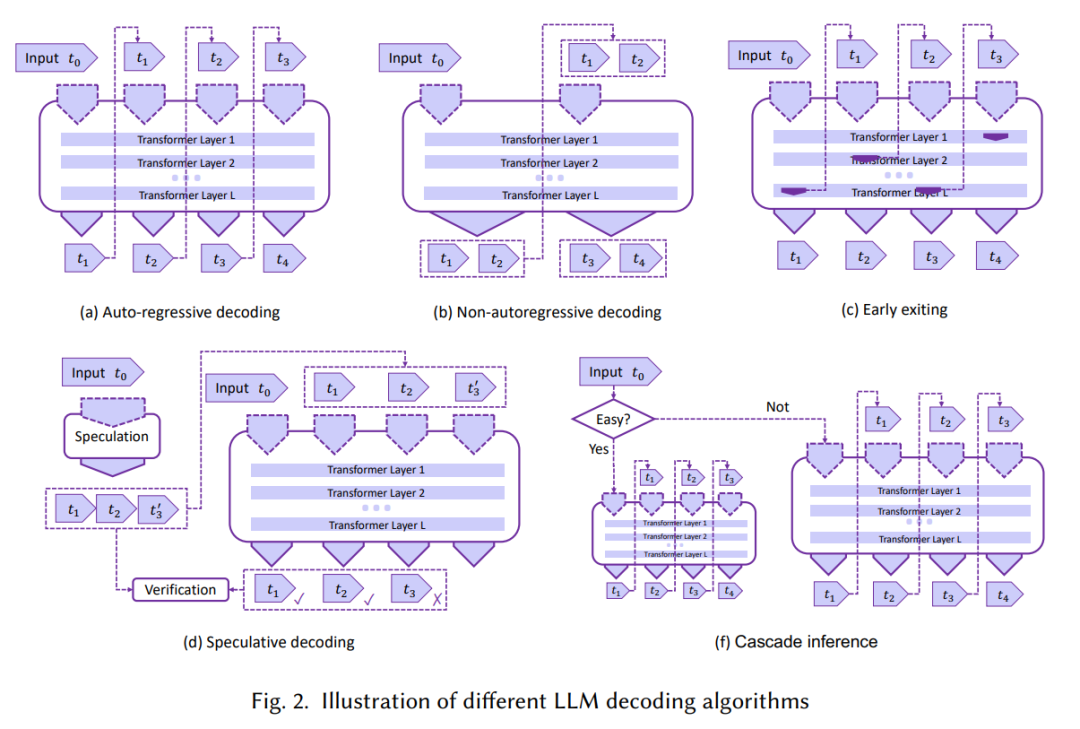
图2. 大模型Decoder算法分类,来源[1]
前排提示,文末有大模型AGI-CSDN独家资料包哦!
Non-autoregressive decoding
token不再是一个一个预测出来,一次预测多个或者并行预测多个tokens,该方法假设前后token之间有一定的条件独立性。当前该方法比自回归方法速度更快,但可靠性还是比自回归方法低。
Early exiting
每次预测下一个token不一定计算完整的Transformer层,根据不同的情况提前退出得到预测的token,以便减少计算量,但该方法可能导致预测准确率下降。
Speculative decoding
用一个小模型预测token(只是其中一种方式),这样出结果快,同时用原始大模型验证结果,不对就纠正,LLM计算量没有变,但验证的时候可以并行计算节约时间。
Cascade inference
将共享前缀的 KV Cache 存到共享内存中,读一次共享前缀的 KV Cache 即可,具有独特的后缀部分保持原来的计算逻辑,最终共享前缀和独特的后缀部分的各自的部分 attention 结果合并起来,得到最终的 attention 结果。
1.2 开源推理工具
市面上主要的开源推理工具,考察支持的指标包括:
**并行计算方式:**张量并行、流水线并行、计算资源是否offload到系统CPU或者内存上。
**Iteration Scheduling:**对要推理的数据如何有效的安排调度,从比较粗的Request粒度到更细的Iteration粒度,例如根据数据长度进行拼凑,先推理一批,剩下的再推理,尽量利用满GPU资源。
**Attention内核计算方式:**不同的计算方法,例如著名的Paged Attention。
**优先考虑的目标:**低延迟Low Latency还是高吞度High Throughput。
列表中目前最流行的应该是vLLM,不过大模型领域发展很快,各个工具支持的功能在迭代中会不断完善,这个统计很快会不准,而且新工具会不断出来。
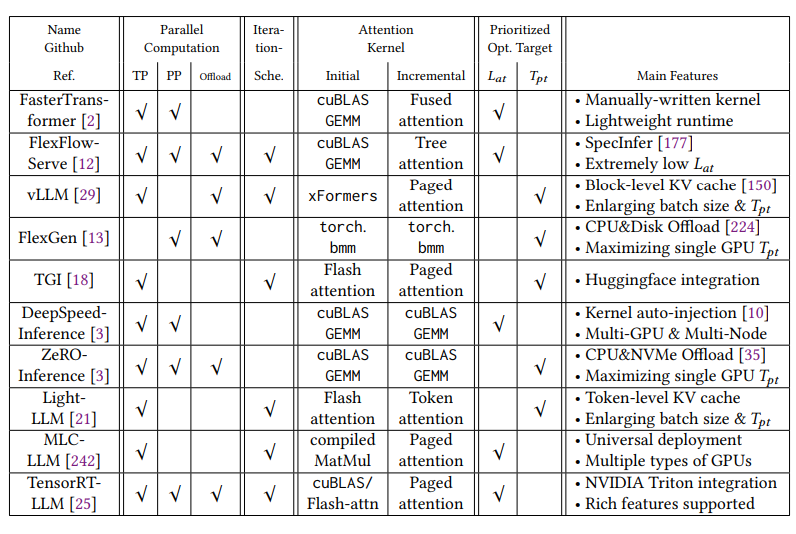
图3. 开源推理工具,来源[1]
2
综述二
接下来重点说综述二,时间上2024年7月也比综述一新,内容上更全面、更有时效性,来自清华大学等的《A Survey on Efficient Inference for Large Language Models》,本文仍然基于主流Transformer模型结构讨论。
2.1 方法分类
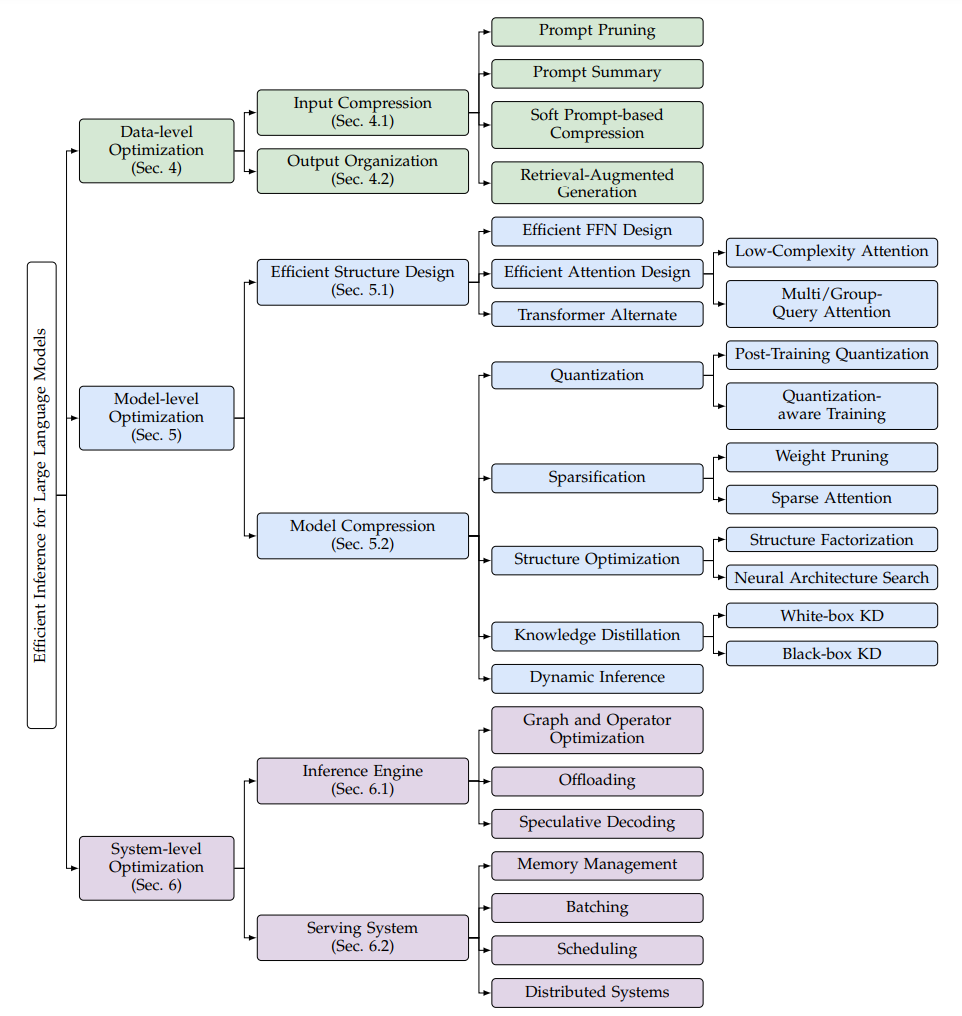
图4. LLM高效推理优化方法分类,来源[2]
这个分类方法很熟悉,和我们上一篇总结高效训练方法逻辑一样,或者说模型领域好多事情都是按照数据、模型、算力三个维度划分的,这里的Data-level包括输入数据的压缩和输出数据的优化组织,Model-level包括模型结构优化和模型压缩,System-level包括推理引擎和服务系统优化,和算力维度对应,如何有效利用算力。
2.2 整体视角
基于Transformer通过Decoder解码器一个一个token输出的方式,以及现在使用KV Cache的事实标准,推理可以分为两个阶段:
-
预填充阶段(Prefilling):使用初始token和KV Cache计算输出第一个token;
-
解码阶段(Decoding):不断更新KV Cache,由上一token预测下一token。
这样划分的原因是影响两个阶段效率的因素和效率表现不一样。按这个方式划分后,要提高推理效率,可以分解为如何提高获取第一个输出token效率、以及解码阶段的效率,评估指标也可以分解为如何降低第一个token输出的时间、后续token输出时间。
此外,整体上核心影响模型高效推理的三个因素是:
-
模型大小
-
Attention计算
-
Decoder解码方式
2.3 数据维度优化
2.3.1 输入压缩
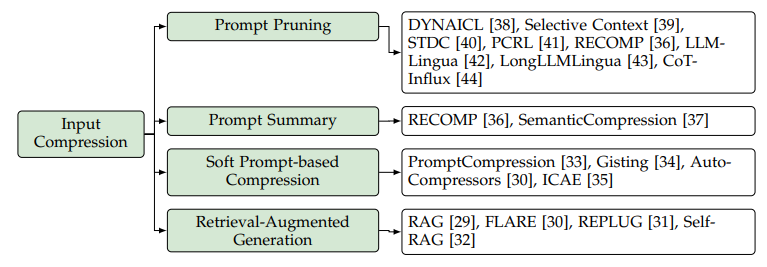
图5. 输入压缩,来源[2]
输入大模型进行推理的内容都叫Prompt提示词,输入数据压缩就是减少Prompt长度,从而降低模型的计算量。
-
**Prompt Pruning:**提示剪枝,剪掉无用或者重复的token、句子或者文档,例如使用小模型来计算内容的相似性、决定剪掉哪些内容。
-
**Prompt Summary:**提示摘要,对长的提示词内容提取核心的摘要,减少输入长度。
-
**Soft Prompt:**Soft Prompt指的是一个可学习的连续的token序列,通过不同的技术把原始的长的Fix Prompt变为短的Soft Prompt。
-
**RAG:**这个概念想必只要是关心大模型应用的同学都多少有了解,即把知识存入知识库,推理的时候从知识库检索相关的知识,再输入大模型推理使用,这样只输入需要的知识,也算是尽量减少无关输入。
2.3.2 输出结构优化
与其让大模型不加约束地输出,不如指定一些输出格式要求,更符合想要的内容,也能提高输出效率。
Skeleton-of-Thought (SoT)是最基础和重要的一个技术,分为两阶段,第一阶段让大模型输出问题的骨架,第二阶段让大模型扩展骨架中的每个点,然后把所有扩展后的内容组合起来得到最后的输出,这样输出的内容都是想要的,没有垃圾数据。
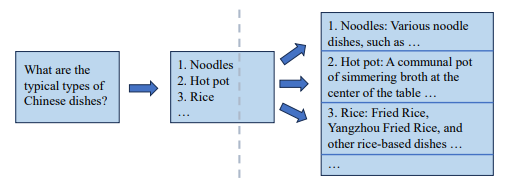
图6. SoT样例,来源[2]
SoT的一个例子如图6,问大模型典型的中国菜,第一步先列出名称,第二步再对第一步中每个名称进行扩展解释,这样输出结构化,清晰明了,没有无用的废话。
在SoT基础上还发展了其他技术SGD、APAR。目前一个很流行的推理框架SGLang,定义了领域相关的语言,可以分析不同生成内容之间的依赖,来控制最终的输出。SGLang的功能很多,不只是输出优化上,有兴趣的可以单独作为一个主题学习。
2.4 模型维度优化
2.4.1模型结构优化
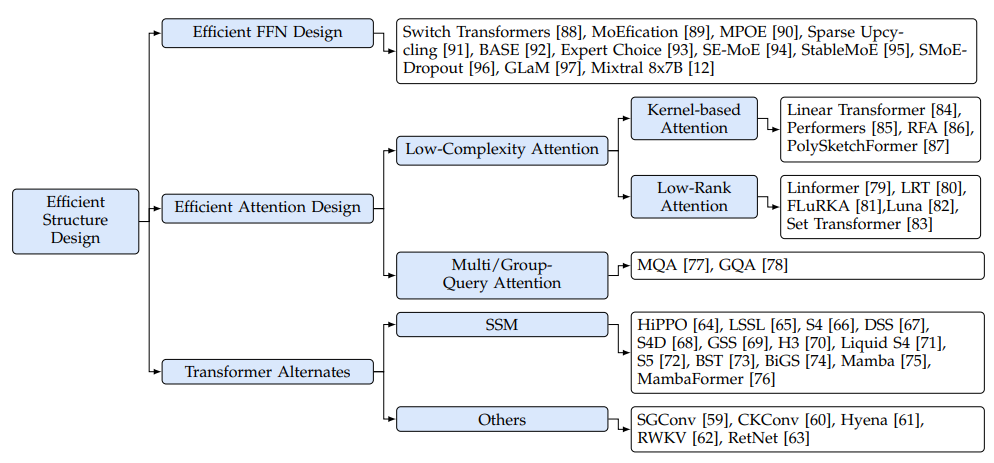
图7. 模型结构优化,来源[2]
大家一提到算法设计都会想到模型结构的设计,虽然大模型主体都使用Transformer,具体细节上还是有改进空间。Transformer内部主要包括Attention和FFN计算。
FFN优化主要使用Mixture-of-Experts (MoE) 方法,系统含多个专家模型,根据不同输入需求决定使用哪个专家模型。优化的领域包括如何构建专家模型、不同专家模型之间如何路由选择、如何训练MoE。
Attention优化有著名的Multi-Query Attention(MQA),然后发展到基于组的GQA,是工程中非常有效果的方法,后面我们会单独说一下。此外还有以降低Attention计算复杂度为目标的方法,包括基于核函数(把Q、K、V的计算映射到核函数)和低秩分解(K、V分解到更低的低秩空间)。
更换Transformer结构,按照历史发展规律来说,Transformer总有被替换的一天,所以探索新的网络结构也很有必要,当前主要有SSM和RWKV。
2.4.2 模型压缩

图8. 模型压缩,来源[2]
模型压缩在高效推理中有明显的效果,我们选量化和蒸馏重点说说,每一个都是大的知识点。
量化
把模型权重和激活从高精度比特位数转换到低精度,一般地,从训练后保存的FP16或者FP32精度量化为Int8、Int4或其他低精度,极大减少计算量和存储空间,关于不同精度可以参考我专门写的文章彻底理解系列之:FP32、FP16、TF32、BF16、混合精度
量化公式如下,其中S表示缩放因子,Z为量化后的零点,N为比特位数。
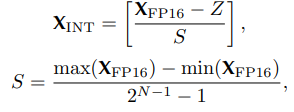
根据量化进行的时间,可分为模型训练后量化PTQ和训练中量化QAT,量化对象分为只量化模型权重、或者量化权重加激活。
蒸馏
把大的模型蒸馏为小模型,大模型当老师,小模型是学生,让小模型尽可能达到老师的水平,同时达到减少模型参数的目的,包括白盒知识蒸馏和黑盒知识蒸馏。
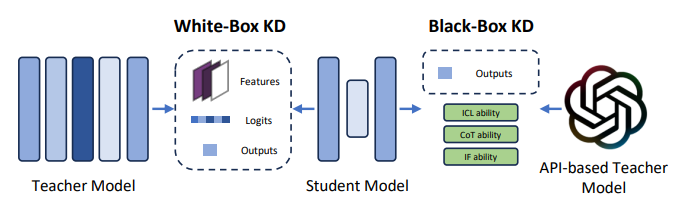
图9. 白盒和黑盒知识蒸馏,来源[2]
白盒蒸馏会进入老师模型结构和参数进行蒸馏,黑盒蒸馏不关心老师模型结构和参数,两种方法的学生模型都会通过训练学习老师模型的logits输出。以二分类问题为例简要说一下蒸馏原理,如果输入数据X,标签为0或者1,通过老师模型训练得到模型A,再次把输出X传入模型A,得到的其实是0到1之间的logits值,并不是0或者1,学生模型直接学习输入X和输出的logits,尽量去模仿老师模型。
**2.5 系统维度优化
**
2.5.1 推理引擎优化
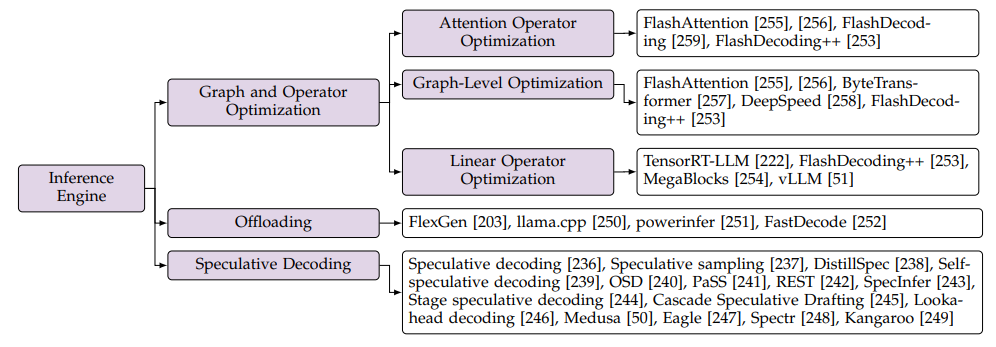
图10. 推理引擎优化,来源[2]
推理引擎优化是为了提高模型前向计算的速度,如图10,其包含了计算图和算子优化、Offloading和Speculative Decoding。综述一把Speculative Decoding放在了算法优化中,我觉得更合理,它主要体现了解码器算法的优化。Offloading比较好理解,是当GPU及其存储不够用时,部分任务转移使用系统的CPU和内存。我们重点看看图和算子优化。
图优化主要指算子融合,把多个算子融合为一个,优点:减少内存访问、减少算子加载时的开销、减少算子依赖从而提高计算并行度。例如FlashAttention把attention操作融合实现在一个单独内核中。
Attention算子优化,除了FlashAttention的算子融合,FlashDecoding致力于最大化Decoding计算的并行性。加之现在用上KV Cache技术后,加快了Attention计算,在Attention算子优化之外,线性算子运算花费的时间比Attention还多,所以优化线性算子很迫切。线性算子基本的实现方法是 General Matrix-Matrix Multiplication (GEMM),即矩阵相乘,其改进的一个方法是 General Matrix-Vector Multiplication (GEMV) ,矩阵和向量相乘,根据不同的形状具体优化,减少内存访问,提高数据复用率,让处理器尽可能满负荷地工作。
2.5.2 服务系统优化
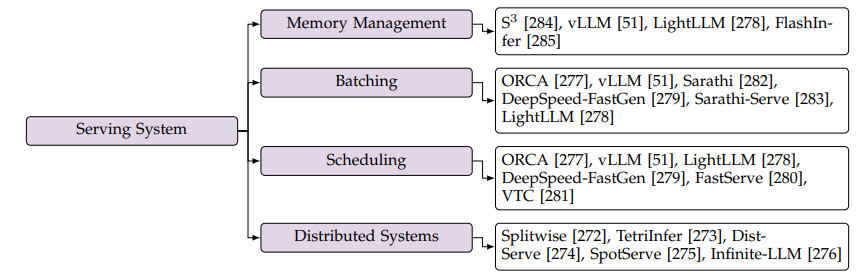
图11. 服务系统优化,来源[2]
服务系统优化的目标主要是提高异步处理的效率。
内存管理关键是对KV Cache的存储和使用优化,主要的方法是vLLM的PageAttention,借鉴分页管理内存的方法来管理KV Cache。
Continuous Batching是把多个请求根据其数据长短等特点组装到一个batch里,缩短计算时间。例如把长的Prefilling请求数据切分开,和多个短的Decoding请求数据放在一个batch里。
Scheduling指的是如何有效安排收到的推理请求,提高系统的吞吐量,比如最简单的先到先处理,或者文章中提到的DeepSpeed-FastGen优先处理Decoding请求等,以及其他各种方法。
分布式系统是传统IT比较成熟的思想和方案,大模型中主要特点在于如何对多GPU进行分布式计算,另外模型推理可分为Prefilling和Decoding阶段,二者可以解耦然后进行粒度更细的分布式计算,这个也是当前比较热门的课题。
除了以上所有优化方案之外,还有硬件加速方案,不是本文讨论重点。
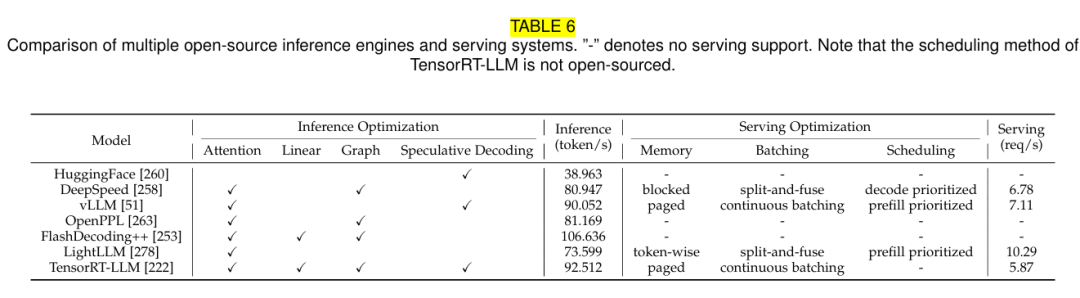
最后是常见推理工具优化功能的支持对比和性能对比。
3
一点体会
在高效训练一文中,我们解释了训练和推理阶段的不同,高效处理的方法也不一样,但训练的前向计算和推理绝大部分是相同的,所以二者都有可以共同使用的方法,比如:张量并行、Flash Attention、算子融合、低精度等。
综述一、二中有的方法偏理论,在工程中不一定好实践,比如基于核函数降低空间维度的attention。实际应用中还是有倾向性使用一些好实现并且效果明显的,或者推理工具已经现成支持的,本节对使用频率高的方法再抽出来说说。
KV Cache绝对是数一数二重要的方法,通过Cache存储KV值,大大减少重复计算量,节约计算时间。在讲多头注意力的文章彻底理解Transformer自注意力、多头注意力MHA、KV Cache、MQA、GQA时,有朋友建议增加解释为什么是KV Cache,不是Q Cache、QK Cache或者其他Cache,在此完善解释一下。t时刻计算attention时,公式如下:
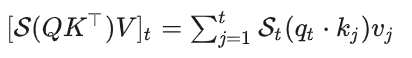
其中S是softmax,可看出只用到了t时刻的Q,但用到了t时刻以及之前的所有K和V,所以之前的K、V需要Cache,而Q每次使用当前时刻的,不需要Cache。
量化是比较独立且好实施的方法,各种精度的量化技术比较成熟,并且量化后使用的算力和存储减少都能看到立竿见影的效果。
其他方法,看各种工具的支持情况,选择适合自己场景的就是最好的。

相关文章:
大模型重要技术系列三:高效推理
接上一篇高效训练,这一篇汇总下高效推理的方法。高效推理的两个主要优化目标是低延迟(快速得到推理结果)和高吞吐量(能同时处理很多请求),同时还要尽可能地少用资源(算力、存储、网络带宽&#…...

Android 刘海屏适配指南
如果您不希望您的内容与刘海区域重叠, 以确保您的内容不会与状态栏及 导航栏。如果您要呈现在刘海区域中,请使用 WindowInsetsCompat.getDisplayCutout() 检索 DisplayCutout 对象 包含每个刘海屏的安全边衬区和边界框。借助这些 API 您需要检查视频内容…...

微信小程序服务通知
项目中用到了小程序的服务消息通知,通知订单状态信息,下边就是整理的一下代码,放到项目中,把项目的小程序appid和小程序的secret写进去,直接运行即可 提前申请好小程序服务信息通知短信模板,代码需要用到模…...

Ubuntu使用Qt虚拟键盘,支持中英文切换
前言 最近领导给了个需求,希望将web嵌入到客户端里面,做一个客户端外壳,可以控制程序的启动、停止、重启,并且可以调出键盘在触摸屏上使用(我们的程序虽然是BS架构,但程序还是运行在本地工控机上的),我…...

泰州农商行
该文章用于测试,暴露面检测服务 1595116111115951161112159511611131595116111415951161115159511611161595116111715951161118159511611191595116112015951161121159511611221595116112315951161124159511611251595116112615951161127159511611281595116112915951…...

扫雷(C语言)
目录 前言 一、前提知识 二、扫雷游戏编写 2.2 test文件基本逻辑 2.2.1菜单编写 2.2.2game函数的逻辑 2.2.2.1定义两个数组 2.2.2.2两个数组数组的初始化 2.2.2.3打印棋盘 2.2.2.4布置雷 2.2.2.5排查雷 2.2.2.6获取坐标附近雷的数量 2.2.2.7什么时候…...

【实践功能记录8】使用UseElementSize实现表格高度自适应
一、关于 UseElementSize UseElementSize 是一个 Vue 组合式 API 的实用工具,通常用于获取 DOM 元素的尺寸信息,例如宽度、高度等。它通常与 v-slot 一起使用,以便在模板中直接访问这些尺寸信息。 地址:https://vueuse.org/core/u…...

SMO算法 公式推导
min α 1 2 ∑ i 1 N ∑ j 1 N α i α j y i y j K ( x i ⋅ x j ) − ∑ i 1 N α i s.t. ∑ i 1 N α i y i 0 0 ≤ α i ≤ C , i 1 , 2 , ⋯ , N (9-69) \begin{aligned} & \min_{\alpha} \quad \frac{1}{2} \sum_{i1}^{N} \sum_{j1}^{N} \alpha_i \alpha_j…...

nodejs包管理器pnpm
简介 通常在nodejs项目中我们使用npm或者yarn做为默认的包管理器,但是pnpm的出现让我们的包管理器有了更多的选择,pnpm相比npm具有以下优势: 速度更快,pnpm在安装依赖时,会将依赖包缓存到全局目录,下次安…...
【postman】工具下载安装
postman作用 postman用于测试http协议接口,无论是开发, 还是测试人员, 都有必要学习使用postman来测试接口, 用起来非常方便。 环境安装 postman 可以直接在chrome 上安装插件,当然大部分的同学是没法连接到谷歌商店的,我们可以在电脑本地…...

Java_Springboot核心配置详解
Spring Boot以其简洁、高效和约定优于配置的理念,极大地简化了Java应用的开发流程。在Spring Boot中,核心配置是应用启动和运行的基础。本文将详细介绍Spring Boot中的两种配置文件格式、基础注解的配置方式、自定义配置以及多环境配置。 一、Spring Bo…...
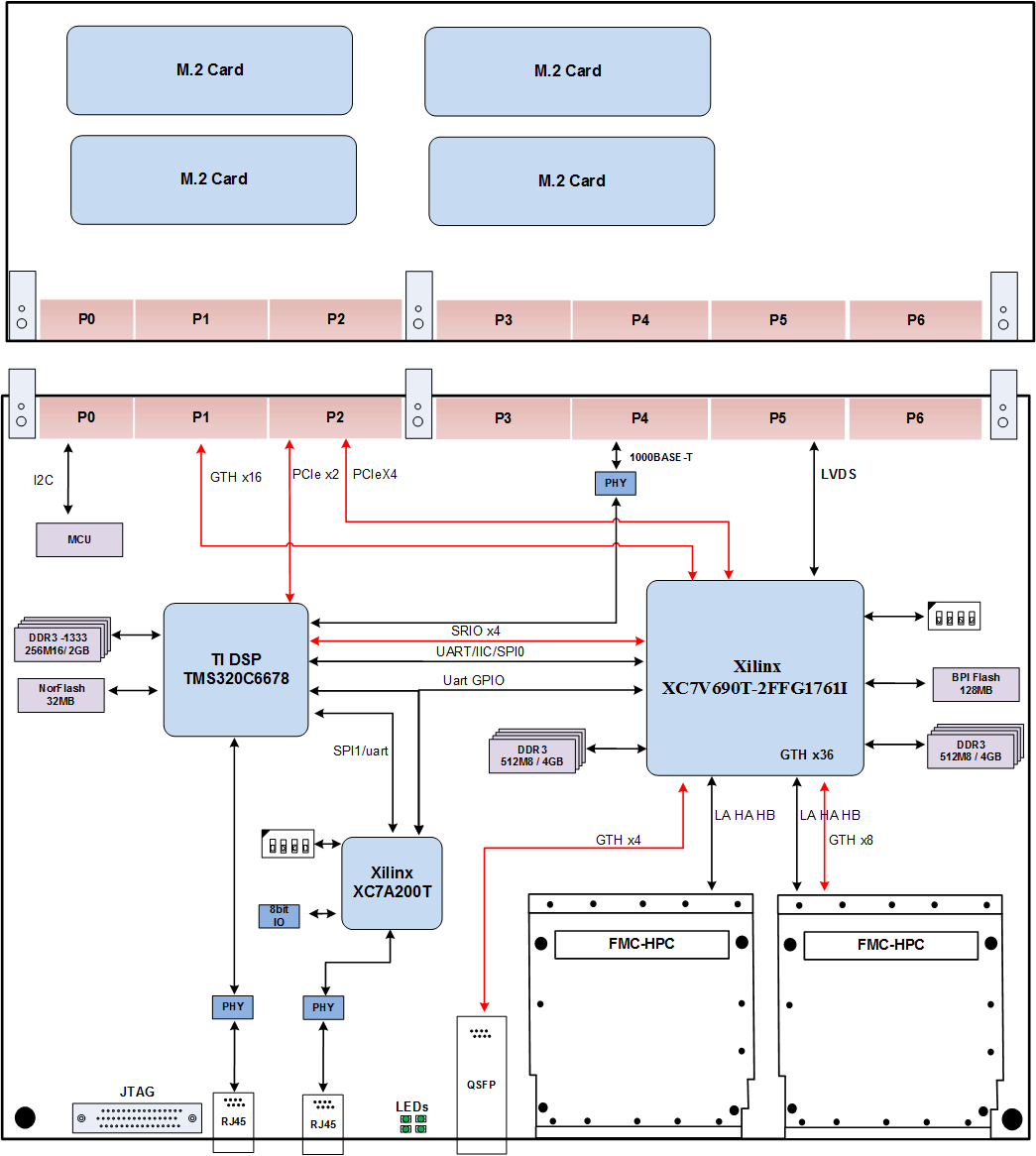
太速科技-9-基于DSP TMS320C6678+FPGA XC7V690T的6U VPX信号处理卡
基于DSP TMS320C6678FPGA XC7V690T的6U VPX信号处理卡 一、概述 本板卡基于标准6U VPX 架构,为通用高性能信号处理平台,系我公司自主研发。板卡采用一片TI DSP TMS320C6678和一片Xilinx公司Virtex 7系列的FPGA XC7V690T-2FFG1761I作为主处理器&#…...
在线UI设计工具:创意与效率的结合
随着UI设计领域的快速增长,设计师们纷纷投身于这一行业,选择一款合适的UI设计工具变得至关重要。除了经典的UI设计软件,在线UI设计工具因其灵活性和便捷性,越来越受到设计师们的喜爱。这种不受时间和地点限制,且不依赖…...
【MyBatis源码】SqlSessionFactoryBuilder源码分析
文章目录 概述类结构从 InputStream 创建 SqlSessionFactoryXMLConfigBuilder构建ConfigurationXMLConfigBuilder初始化方法parse()方法parseConfiguration属性(properties) 概述 SqlSessionFactory 是 MyBatis 的核心接口之一,提供创建 Sql…...

Percona XtraBackup数据备份方案
一、简介 官方文档:https://docs.percona.com/percona-xtrabackup/innovation-release/index.html Percona XtraBackup 是一款适用于基于 MySQL 的服务器的开源热备份实用程序,可让您的数据库在计划的维护时段内保持完全可用。无论是 24x7 高负载服务器还是低交易量服务器,…...

聚“芯”而行,华普微亮相第五届Silicon Labs Works With大会
2024年10月24日,由致力于以安全、智能无线连接技术建立更互联世界的全球领导厂商Silicon Labs主办的第五届Works With开发者大会在上海雅乐居万豪侯爵酒店成功举办。 作为全球性的物联网年度“盛宴”,本届大会群英荟萃,不仅有着来自生态大厂的…...

Java 用户随机选择导入ZIP文件,解压内部word模板并入库,Windows/可视化Linux系统某麒麟国防系统...均可适配
1.效果 压缩包内部文件 2.依赖 <!--支持Zip--><dependency><groupId>net.lingala.zip4j</groupId><artifactId>zip4j</artifactId><version>2.11.5</version></dependency>总之是要File类变MultipartFile类型的 好像是…...

【C++】C++17结构化绑定、std::optional、std::variant、std::any
二十二、C17中的结构化绑定、std::optional、std::variant、std::any 本部分是一个小系列,介绍C17中新引入的、用来解决各种不同返回情况的、标准库新组件。 1、C的结构化绑定 结构化绑定structured bindings是C17中引入的一项特性,它允许开发者方便地…...

C#的起源。J++语言的由来?J#和J++傻傻分不清?
C#的起源 C#读音是C Sharp, 它是微软为了对抗Java而生,最早是J,效率比Java还好,后来被Sun公司起诉J破坏了平台无关性,微软重新开发C#. C#和Java一样都定位为中间件语言,用虚拟机执行编译的字节码以达到跨平台目的。从语…...

Flutter 在 对接 google play 时,利用 android studio 可视化生成 已签名的aab包
android studio 可视化生成 aab包 第一 : 先说注意事项 在Flutter项目里面,直接打开当前项目是不行的,不显示相应操作,需要在Android 目录打开,直白点就是直接打开项目里面的Android 目录 不然会出现的一些问题 第一…...
方法顺序不确定性解析与解决方案)
Java反射getMethods()方法顺序不确定性解析与解决方案
1. 项目概述:一个看似简单却暗藏玄机的API行为如果你写过Java反射相关的代码,大概率用过Class.getMethods()这个方法。它的官方文档描述简洁明了:“返回一个包含 Method 对象的数组,这些对象反映了此 Class 对象表示的类或接口的所…...

RK3576开发板AP6275S无线模块调试:从驱动到应用实战
1. 项目概述:从零上手RK3576的无线模块调试最近在折腾一块基于瑞芯微RK3576的国产工业评估板——眺望电子的EVM-RK3576。这块板子接口资源相当丰富,双千兆网口、CAN、RS485、USB3.0等一应俱全,对于做工业网关、边缘计算盒子或者多媒体终端的开…...

蓝桥杯嵌入式LCD显示避坑指南:sprintf函数格式化变量显示的正确姿势
蓝桥杯嵌入式LCD显示避坑指南:sprintf函数格式化变量显示的正确姿势 在蓝桥杯嵌入式竞赛中,LCD显示是基础但至关重要的环节。许多参赛选手在实现变量动态显示时,常常因为对sprintf函数的使用不当而陷入各种"坑"中——数据显示不全、…...

从游戏动作到影视特效:Blender Python骨骼动画脚本的跨界实战指南
从游戏动作到影视特效:Blender Python骨骼动画脚本的跨界实战指南 在数字内容创作领域,骨骼动画是连接游戏开发与影视特效的核心技术纽带。无论是独立游戏开发者需要将角色动作导出到Unity引擎,还是影视动画师希望批量处理动作捕捉数据&#…...

老板出幻觉了!过度相信 AI,迟早要暴雷…
不怕 AI 出幻觉,就怕用户出幻觉~ 对打工牛马来说,更怕老板出幻觉。①最近,某位后端童鞋忍不了,发帖吐槽公司老板/高层过度迷信“AI 全自动写代码”。他表示这会留下维护隐患,难出好产品…… 迟早完蛋。PS:你…...
)
从靶场到实战:用Vulhub在Docker里一键复现Struts2全系列漏洞(S2-001到S2-053)
从靶场到实战:用Vulhub在Docker里一键复现Struts2全系列漏洞 在安全研究领域,能够快速搭建可复现的漏洞环境是每个从业者的基本功。传统方式需要手动配置Java环境、下载特定版本的Struts2框架、部署Web服务器,整个过程耗时费力且容易出错。而…...

Linux守护进程--进程、进程组、会话、终端
要弄明白守护进程,就必须先讲清楚进程、进程组、会话、终端一、进程当我们运行一个应用时,根据冯诺依曼体系结构,必须把这个应用的代码、数据以及PCB(进程控制块,process control block,也就是关于进程的描述结构体)加…...
)
超越官方TabBar:打造高交互小程序导航的3个高级技巧(附动态隐藏方案)
超越官方TabBar:打造高交互小程序导航的3个高级技巧(附动态隐藏方案) 在小程序生态中,导航栏作为用户交互的核心枢纽,其体验直接影响用户留存率。微信原生TabBar虽然开箱即用,但在动态效果、状态管理和场景…...

ARM与FPGA通信接口设计:从并行总线到AXI的软硬件协同实践
1. 项目概述:从一次调试“事故”说起去年,我在一个边缘计算网关的项目上,遇到了一个让人头大的问题。项目核心是一块定制板,处理器是四核的ARM Cortex-A53,旁边紧挨着一片中等规模的FPGA。我们的设计是让ARM负责复杂的…...

避开这些坑!新手用Python处理MODIS HDF数据时最常遇到的5个问题及解决方法
Python处理MODIS HDF数据的五大实战陷阱与解决方案 当你第一次用Python打开MODIS HDF文件时,那种期待感就像拆开一份科技礼物——直到GDAL抛出一连串晦涩的错误信息。作为遥感领域最常用的数据格式之一,MODIS HDF文件以其复杂的层级结构和特有的数据处理…...