吞吐量最高飙升20倍!破解强化学习训练部署难题
**强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。近日,字节跳动豆包大模型团队与香港大学联合提出 HybridFlow(开源项目名:veRL),一个灵活且高效的 RL/RLHF 框架。该框架采用混合编程模型,融合单控制器(Single-Controller)的灵活性和多控制器(Multi-Controller)的高效性,可更好实现和执行多种 RL 算法,显著提升训练吞吐量,降低开发和维护复杂度。实验结果表明,HybridFlow 在运行各种 RL(HF) 算法时,吞吐量相较 SOTA 基线提升了 1.5-20 倍。
从 ChatGPT [1] 到 o1 等各种大语言模型,强化学习(RL)算法在提升模型性能和适应性方面起着至关重要的作用。在大模型后训练(Post-Training)阶段引入 RL 方法,已成为提升模型质量和对齐人类偏好 [2, 3] 的重要手段。
然而,随着模型规模的不断扩大,RL 算法在大模型训练中面临着灵活性和性能的双重挑战。
传统的 RL/RLHF 系统在灵活性和效率方面存在不足,难以适应不断涌现的新算法需求,无法充分发挥大模型潜力。
因此,开发一个高效且灵活的大模型 RL 训练框架显得尤为重要。这不仅需要高效地执行复杂的分布式计算流程,还要具备适应不同 RL 算法的灵活性,以满足不断发展的研究需求。
字节跳动豆包大模型团队与香港大学近期公开联合研究成果—— HybridFlow ,一个灵活且高效的大模型 RL 训练框架,兼容多种训练和推理框架,支持灵活的模型部署和多种 RL 算法实现。
HybridFlow 采用混合编程模型,将单控制器的灵活性与多控制器的高效性相结合,解耦了控制流和计算流。基于 Ray 的分布式编程,动态计算图,异构调度能力,通过封装单模型的分布式计算、统一模型间的数据切分,以及支持异步 RL 控制流,HybridFlow 能够高效地实现和执行各种 RL 算法,复用计算模块和支持不同的模型部署方式,大大提升了系统的灵活性和开发效率。
实验结果表明,HybridFlow 在各种模型规模和 RL 算法下,训练吞吐量相比其他框架提升了 1.5 倍至 20 倍。
目前,该论文已被 EuroSys 2025 接收,代码仓库也对外公开。

论文题目:HybridFlow: A Flexible and Efficient RLHF Framework
论文地址:https://team.doubao.com/zh/publication/hybridflow-a-flexible-and-efficient-rlhf-framework?view_from=research
代码链接:https://github.com/volcengine/veRL
RL(Post-Training)复杂计算流程给 LLM 训练带来全新的挑战
在深度学习中,数据流(DataFlow)是一种重要的计算模式抽象,用于表示数据经过一系列复杂计算后实现特定功能。神经网络的计算就是典型的 DataFlow ,可以用计算图(Computational Graph)来描述,其中节点代表计算操作,边表示数据依赖。
大模型 RL 的计算流程比传统神经网络更为复杂。在 RLHF 中,需要同时训练多个模型,如 Actor 、Critic 、参考策略(Reference Policy)和奖励模型(Reward Model),并在它们之间传递大量数据。这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。
传统的分布式 RL 通常假设模型可在单个 GPU 上训练,或使用数据并行方式 [4,5],将控制流和计算流合并在同一进程中。这在处理小规模模型时效果良好,但面对大模型,训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
HybridFlow 解耦控制流和计算流,兼顾灵活高效
大模型 RL 本质上是一个二维的 DataFlow 问题:high-level 的控制流(描述 RL 算法的流程)+ low-level 的计算流(描述分布式神经网络计算)。
近期开源的 RLHF 框架,如 DeepSpeed-Chat [6]、OpenRLHF [7] 和 NeMo-Aligner [8],采用了统一的多控制器(Multi-Controller)架构。各计算节点独立管理计算和通信,降低了控制调度的开销。然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。
与此前框架不同,HybridFlow 采用了混合编程模型,控制流由单控制器(Single-Controller)管理,具有全局视图,实现新的控制流简单快捷,计算流由多控制器(Multi-Controller)负责,保证了计算的高效执行,并且可以在不同的控制流中复用。
尽管相比纯粹的多控制器架构,这可能带来一定的控制调度开销,但 HybridFlow 通过优化数据传输,降低了控制流与计算流之间的传输量,兼顾了灵活性和高效性。
系统设计之一:Hybrid Programming Model(编程模型创新)
- 封装单模型分布式计算
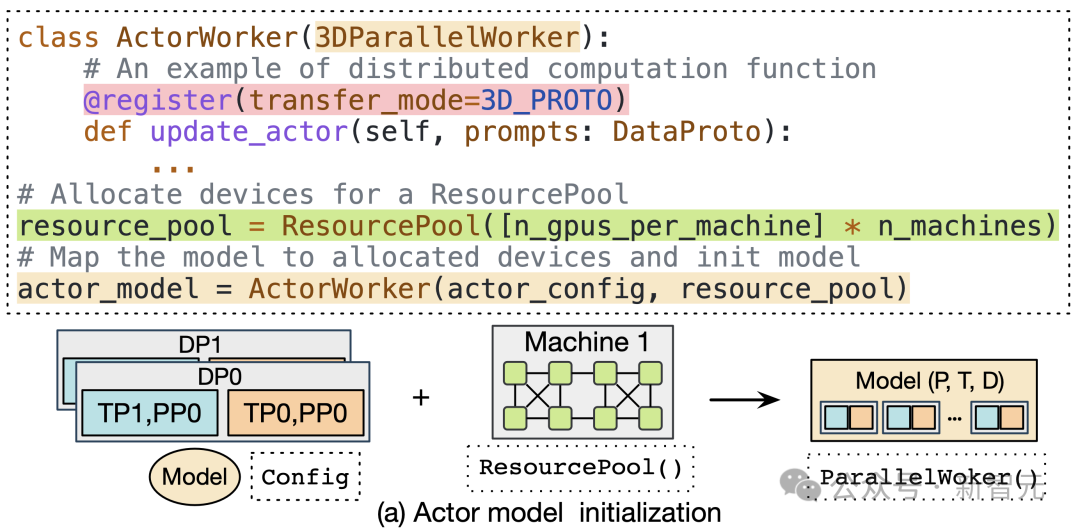
在 HybridFlow 中,每个模型(如 Actor、Critic、参考策略、奖励模型等)的分布式计算被封装为独立的模块,称为模型类。
这些模型类继承于基础的并行 Worker 类(如 3DParallelWorker 、FSDPWorker 等),通过抽象的 API 接口,封装了模型的前向、反向计算、优化器更新和自回归生成等操作。该封装方式提高了代码的复用性,便于模型的维护和扩展。
对于不同的 RL 控制流,用户可以直接复用封装好的模型类,同时自定义部分算法所需的数值计算,实现不同算法。当前 HybridFlow 可使用 Megatron-LM [13] 和 PyTorch FSDP [14] 作为训练后端,同时使用 vLLM [15] 作为自回归生成后端,支持用户使用其他框架的训练和推理脚本进行自定义扩展。
- 灵活的模型部署
HybridFlow 提供了资源池(ResourcePool)概念,可以将一组 GPU 资源虚拟化,并为每个模型分配计算资源。不同的资源池实例可以对应不同设备集合,支持不同模型在同一组或不同组 GPU 上部署。这种灵活的模型部署方式,满足了不同算法、模型和硬件环境下的资源和性能需求。
- 统一模型间的数据切分
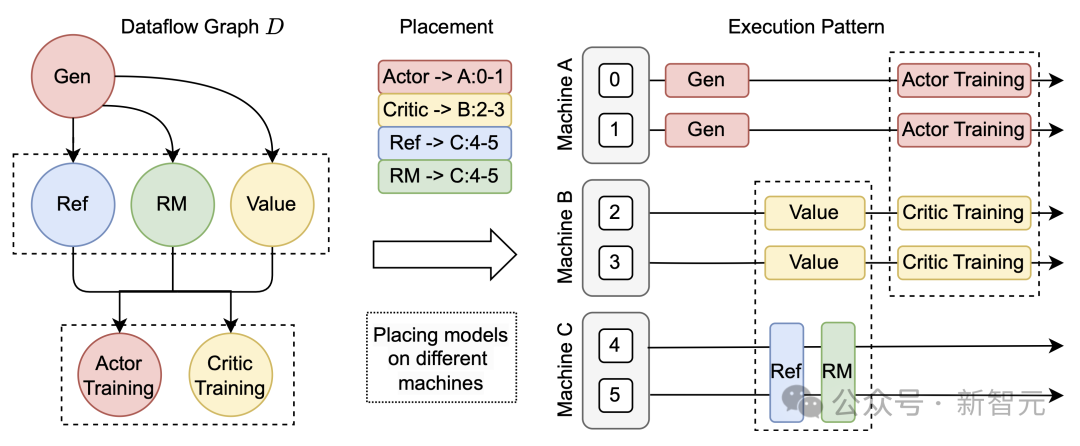
在大模型 RL 计算流程中,不同模型之间的数据传输涉及复杂的多对多广播和数据重分片。
为解决该问题,HybridFlow 设计了一套通用数据传输协议(Transfer Protocol),包括收集(collect)和分发(distribute)两个部分。
通过在模型类的操作上注册相应的传输协议,比如:@register(transfer_mode=3D_PROTO),HybridFlow 可以在控制器层(Single-Controller)统一管理数据的收集和分发,实现模型间数据的自动重分片,支持不同并行度下的模型通信。
HybridFlow 框架已经支持多种数据传输协议,涵盖大部分数据重切分场景。同时,用户可灵活地自定义收集(collect)和分发(distribute)函数,将其扩展到更复杂的数据传输场景。

- 支持异步 RL 控制流
在 HybridFlow 中,控制流部分采用单控制器架构,可灵活实现异步 RL 控制流。
当模型部署在不同设备集合上时,不同模型计算可并行执行,这提高了系统的并行度和效率。对于部署在同一组设备上的模型,HybridFlow 通过调度机制实现了顺序执行,避免资源争夺和冲突。
- 少量代码灵活实现各种 RL 控制流算法
得益于混合编程模型的设计,HybridFlow 可以方便地实现各种 RLHF 算法,如 PPO [9]、ReMax [10]、Safe-RLHF [11]、GRPO [12] 等。用户只需调用模型类的 API 接口,按算法逻辑编写控制流代码,无需关心底层的分布式计算和数据传输细节。
例如,实现 PPO 算法只需少量代码,通过调用 actor.generate_sequences 、critic.compute_values 等函数即可完成。同时,用户只需要修改少量代码即可迁移到 Safe-RLHF 、ReMax 以及 GRPO 算法。

系统设计之二:3D-HybridEngine(训练推理混合技术)降低通信内存开销
在 Online RL 算法中,Actor 模型需要在训练和生成(Rollout)阶段之间频繁切换,且两个阶段可能采用不同并行策略。
具体而言,训练阶段,需要存储梯度和优化器状态,模型并行度(Model Parallel Size, MP)可能相应增高,而生成阶段,模型无需存储梯度和优化器状态,MP 和数据并行度(Data Parallel Size, DP)可能较小。因此,在两个阶段之间,模型参数需要重新分片和分配,依赖传统通信组构建方法会带来额外通信和内存开销。
此外,为了在新的并行度配置下使用模型参数,通常需要在所有 GPU 之间进行全聚合(All-Gather)操作,带来了巨大的通信开销,增加了过渡时间。
为解决这个问题,HybridFlow 设计了 3D-HybridEngine ,提升了训练和生成过程效率。
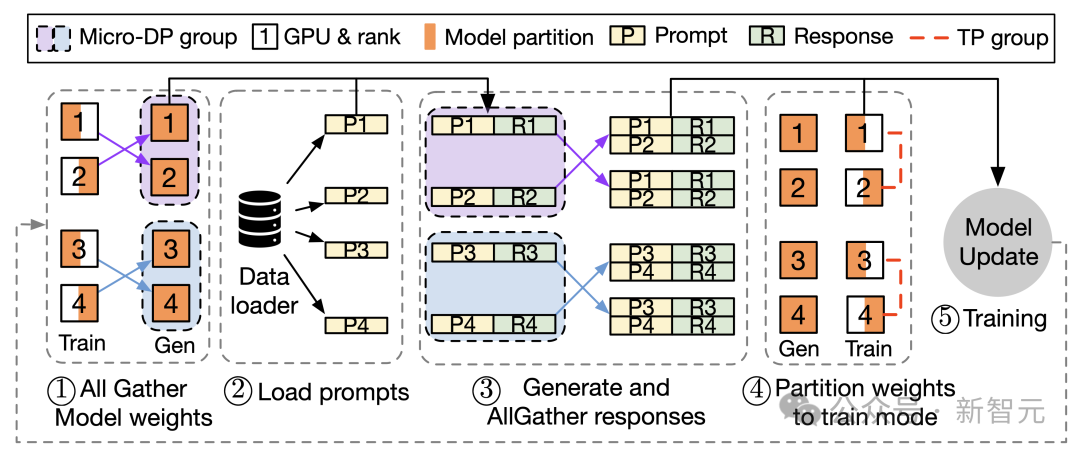
3D-HybridEngine 一次迭代的流程
3D-HybridEngine 通过优化并行分组方法,实现了零冗余的模型参数重组,具体包括以下步骤:
- 定义不同的并行组
在训练和生成阶段,3D-HybridEngine 使用不同的三维并行配置,包括:流水线并行(PP)、张量并行(TP)和数据并行(DP)的大小。训练阶段的并行配置为 𝑝-𝑡-𝑑 。在生成阶段,我们新增一个新的微数据并行组(Micro DP Group,𝑑𝑔),用于处理 Actor 模型参数和数据的重组。生成阶段的并行配置为 𝑝𝑔-𝑡𝑔-𝑑𝑔-𝑑 。
- 重组模型参数过程
通过巧妙地重新定义生成阶段的并行分组,可以使每个 GPU 在生成阶段复用训练阶段已有的模型参数分片,避免在 GPU 内存中保存额外的模型参数,消除内存冗余。
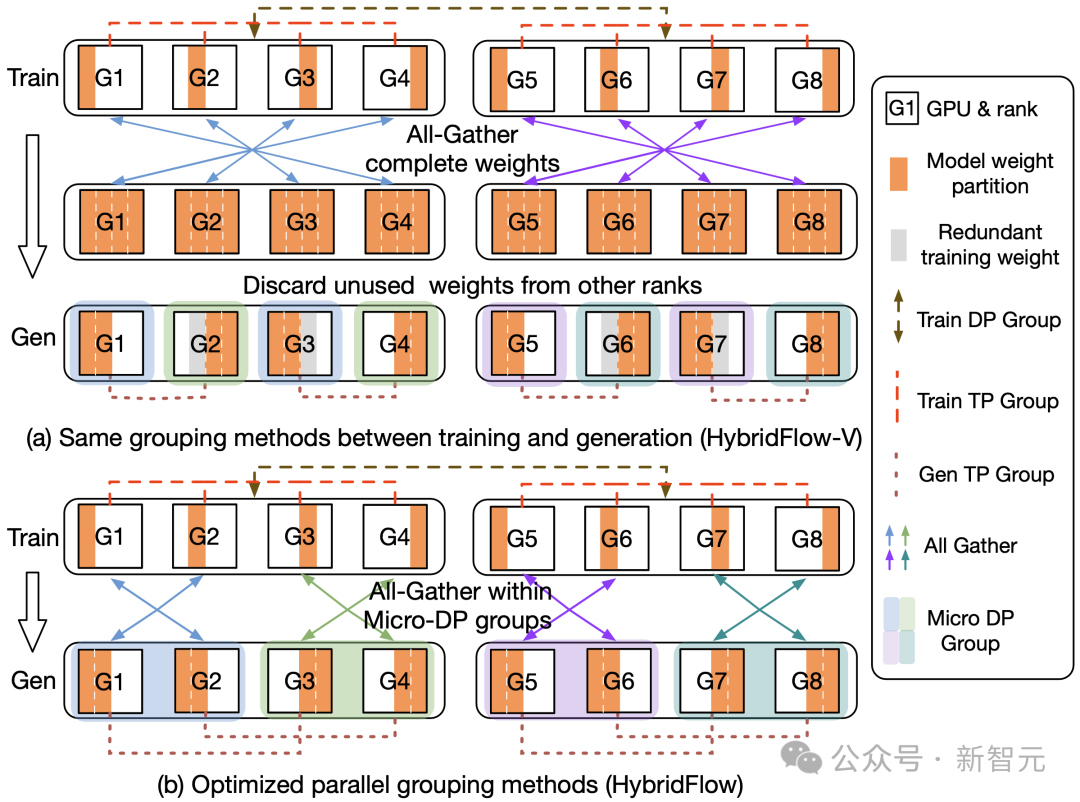
- 减少通信开销
参数重组过程中,3D-HybridEngine 仅在每个微数据并行组(Micro DP Group)内进行 All-Gather 操作,而非所有 GPU 之间进行。这大大减少了通信量,降低过渡时间,提高了整体的训练效率。
实验结果:HybridFlow 提供灵活性的同时,加速了训练
团队在 16 台 A100 GPU 集群上,对 HybridFlow 和主流 RLHF 框架(DeepSpeed-Chat [6] v0.14.0、OpenRLHF [7] v0.2.5 和 NeMo-Aligner [8] v0.2.0)进行对比实验。实验涵盖了不同模型规模(7B、13B、34B、70B)的 LLM ,以及不同 RLHF 算法(PPO [9]、ReMax [10]、Safe-RLHF [11])。
所有实验中,Actor、Critic、参考策略 Reference Policy 和奖励模型 Reward Model 均采用相同规模模型。更多实验配置和测试细节请移步完整论文。
- 更高的端到端训练吞吐量
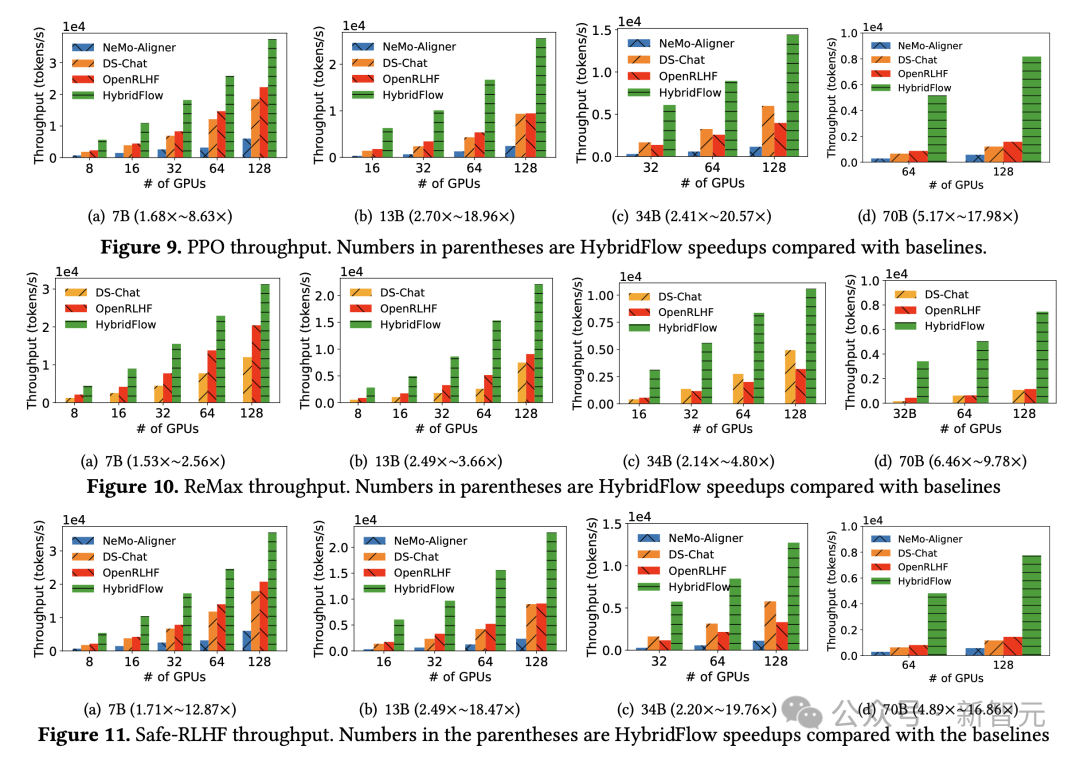
结果显示,HybridFlow 在各种模型规模和 RLHF 算法下,都显著优于其他框架,实现了更高训练吞吐量。
无论 PPO 、ReMax 还是 Safe-RLHF 算法,HybridFlow 在所有模型规模下平均训练吞吐量均大幅领先于其他框架,提升幅度在 1.5 倍至 20 倍之间。
随 GPU 集群规模扩大,HybridFlow 吞吐量也获得良好扩展。这得益于其灵活的模型部署,充分利用硬件资源,实现高效并行计算。同时,HybridFlow 能够支持多种分布式并行框架(Megatron-LM [13]、FSDP [14]、vLLM [15]),满足不同模型规模的计算需求。
- HybridEngine 有效减少开销
分析 Actor 模型在训练和生成阶段的过渡时间,团队发现,HybridFlow 的 3D-HybridEngine 的零冗余模型参数重组技术,有效减少了模型参数在两个阶段之间的重分片和通信开销。
相比其他框架,过渡时间减少了 55.2% ,在 70B 模型上过渡时间降低了 89.1% 。

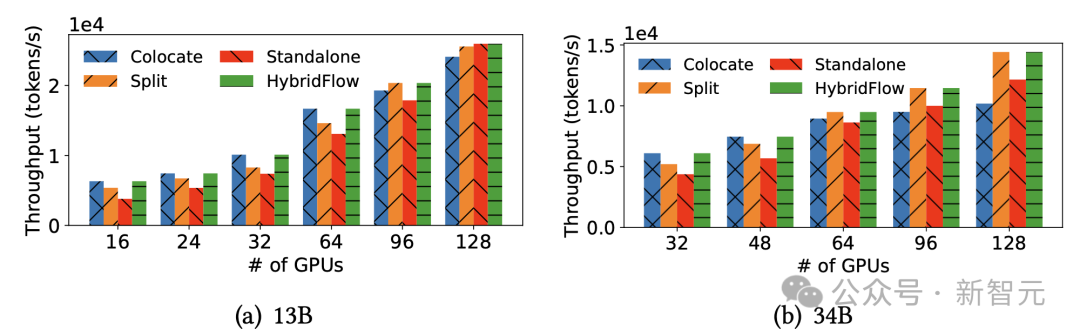
- 不同模型部署方式对比下的三个洞察
团队对比了不同的模型部署策略,总结了模型部署和 GPU 分配的三大关键洞察:
1. 为 Actor 模型分配更多的 GPU ,可以缩短 critical path ;
2. Colocate 模式在相对小规模集群中能够最大化 GPU 利用率;
3. 在大规模集群中将 Actor 和 Critic 模型部署在不同的设备能够提升扩展率。
值得一提的是,HybridFlow 同样适用于更广泛的 RL 训练场景,随着 o1 模型诞生,业内对 Reasoning 能力、RL 关注度也在提升,团队后续将围绕相关场景进行探索和实验。
写在最后
该成果来自豆包大模型 Foundation 团队,论文一作是团队的实习生明同学,目前就读于香港大学。
「刚加入公司没多久,就把这么重要的系统给我做,机会十分难得。」 他分享道。
明同学进一步补充:「团队里大牛很多,无论什么问题,肯定能找到人聊。这段经历不仅让我学习到非常多新技术,还完整经历一个工业级开源项目从立项到发布的全周期。大家都愿意提供帮助,每个人都是我的 Mentor 。」
目前,豆包大模型 Foundation 团队正持续吸引优秀人才加入,硬核、开放、充满创新精神是团队氛围的关键词。团队希望与具备创新精神、责任心的技术人才一起,推进大模型训练提效工作取得更多进展和成果。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
吞吐量最高飙升20倍!破解强化学习训练部署难题
**强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。近日,字节跳动豆包大模型团队与香港大学联合提出 HybridFlow(开源项…...

redis的数据过期策略
Redis对数据设置了数据的有效时间,数据过期之后,就需要将数据从内存中删除掉.可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略),而这种策略有两种:惰性删除和定期删除 惰性删除:设置key过期时间后,我们不去管它,当需要该key时,我们在检查其是否…...

三周精通FastAPI:27 使用使用SQLModel操作SQL (关系型) 数据库
官网文档:https://fastapi.tiangolo.com/zh/tutorial/sql-databases/ SQL (关系型) 数据库 FastAPI不需要你使用SQL(关系型)数据库。 但是您可以使用任何您想要的关系型数据库。 这里我们将看到一个使用SQLModel的示例。 SQLModel是在SQLAlchemy和Pydantic的基础…...
Kubernetes金丝雀发布
华子目录 Canary金丝雀发布什么是金丝雀发布Canary发布方式基于header(http包头)灰度发布基于权重的金丝雀发布 Canary金丝雀发布 什么是金丝雀发布 金丝雀发布也称为灰度发布,是一种软件发布策略主要目的是在将新版本的软件全面推广到生产环…...

树形DP讲解
文章目录 树形DP讲解一、引言二、树形DP基础1、树的定义2、树形DP的基本思想3、代码示例:子树大小 三、经典例题解析1、树的平衡点1.1、代码示例 2、没有上司的舞会(树的最大独立集)2.1、代码示例 四、总结 树形DP讲解 一、引言 树形动态规…...

容器:如何调试容器
调试容器,主要是指的调试Dockerfile,调试Dockerfile中的各个命令的执行,大小等 1、docker history查看构建过程和所有的中间层 2、docker run rm -it -u root XXX sh,通过临时容器的方式启动,可以调试中间层文件 3、do…...

用图说明 CPU、MCU、MPU、SoC 的区别
CPU CPU 负责执行构成计算机程序的指令,执行这些指令所指定的算术、逻辑、控制和输入/输出(I/O)操作。 MCU (microcontroller unit) 不同的 MCU 架构如下,注意这里的 MPU 表示 memory protection unit MPU (microprocessor un…...

牛客周赛 Round 65
文章目录 超市思路:Solved: 雨幕思路:Solved: 闺蜜思路:Solved: 医生思路:Solved: 降温(easy)思路:Solved: F-降温(hard&a…...

超级经典的79个软件测试面试题(内含答案)
1、软件的生命周期(prdctrm) 计划阶段(planning)-〉需求分析(requirement)-〉设计阶段(design)-〉编码(coding)->测试(testing)->运行与维护(running maintrnacne) 测试用例 用例编号 测试项目 测试标题 重要级别 预置条件 输入数据 执行步骤 预期结果 2、问…...

【Mac】安装 F5-TTS
1、下载项目 项目地址:【GitHub】 SWivid F5-TTS 2、创建并激活 Python 虚拟环境 # 创建 Python 虚拟环境 userMac F5-TTS-main % python3 -m venv f5-tts# 激活进入 Python 虚拟环境 userMac F5-TTS-main % source f5-tts/bin/activate (f5-tts) userrMac F5-TT…...

Leaflet查询矢量瓦片偏移的问题
1、问题现象 使用Leaflet绘制工具查询出来的结果有偏移 2、问题排查 1)Leaflet中latLngToContainerPoint和latLngToLayerPoint的区别 2)使用Leaflet查询需要使用像素坐标 3)经排查发现,container获取的坐标是地图容器坐标&…...

存储引擎技术进化
B-tree 目前支撑着数据库产业的半壁江山。 50 年来不变而且人们还没有改变它的意向 鉴定一个算法的优劣,有一个学派叫 IO复杂度分析 ,简单推演真假便知。 下面就用此法分析下 B-tree(traditional b-tree) 的 IO 复杂度,对读、写 IO 一目了…...

CentOS 9 Stream 上安装 Maven
CentOS 9 Stream 上安装 Maven 在 CentOS 9 Stream 上安装 Maven,可以按照以下步骤进行: 更新系统软件包: sudo dnf update安装 Maven: CentOS 9 Stream 默认的包管理器中已经包含 Maven,你可以直接安装: s…...

强势改进!TCN-Transformer时间序列预测
强势改进!TCN-Transformer时间序列预测 目录 强势改进!TCN-Transformer时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现TCN-Transformer时间序列预测; 2.运行环境为Matlab2023b; 3.单个变量时间序…...

MyBatis的不同参数传递封装
MyBatis参数传递 传参方式 1. 使用 #{} 占位符 这是 MyBatis 中最常用的参数传递方式。它将参数直接替换到 SQL 语句中的占位符位置。 单个参数: <select id"selectUserById" resultType"User">SELECT * FROM users WHERE id #{id}…...

kotlin 协程方法总结
Kotlin 协程是一套强大的异步编程工具,以下是对 Kotlin 协程常用方法的总结: 1. 协程构建器 launch: 启动一个新的协程,不阻塞当前线程,返回一个 Job 对象。 GlobalScope.launch {// 协程体}async: 启动一个新的协程并返回一个…...

脉冲当量计算方法
脉冲的概念: 脉冲当量是指控制器输出一个定位控制脉冲时,所产生的定位控制移动的位移。在直线运动中,它表示移动的距离;在圆周运动中,它表示转动的角度。简而言之,脉冲当量就是电机接收一个脉冲信号后能够移…...

TongWeb7.0.E.6_P11嵌入式版本使用指引(by lqw)
文章目录 声明相关概念手册的使用示范工程安装工程介质 安装前准备示范工程参考(spring-boot-helloWorld-2.x)示范参考 声明 1.本文参考001_TongWeb_V7.0嵌入式版_JavaEE标准容器用户指南_70E6_P11A01.pdf,实际以最新更新的手册为准。 2.本文…...

Node.js:Express 服务 路由
Node.js:Express 服务 & 路由 创建服务处理请求req对象 静态资源托管托管多个资源挂载路径前缀 路由模块化 Express是Node.js上的一个第三方框架,可以快速开发一个web框架。本质是一个包,可以通过npm直接下载。 创建服务 Express创建一…...

C++之多态(上)
C之多态 多态的概念 多态(polymorphism)的概念:通俗来说,就是多种形态。多态分为编译时多态(静态多态)和运⾏时多 态(动态多态),这⾥我们重点讲运⾏时多态,编译时多态(静态多态)和运⾏时多态(动态多态)。编译时 多态(静态多态)主…...
框架安全自查清单:开发者必知的5个高危漏洞与修复方案)
若依(RuoYi)框架安全自查清单:开发者必知的5个高危漏洞与修复方案
若依(RuoYi)框架安全自查清单:开发者必知的5个高危漏洞与修复方案 在当今快速迭代的软件开发环境中,安全防护已成为项目全生命周期中不可忽视的关键环节。作为国内广泛使用的快速开发框架,若依(RuoYi)凭借其模块化设计和丰富的功能集成&#…...

高效流感病毒A抗体:制备方法与免疫防御利器
流感病毒A(Influenza Virus A),简称FluA,作为常见的呼吸道病毒,每年都会在全球范围内引发季节性流感爆发。它具有高度的变异性,能够不断进化出新的亚型,使得人群对其普遍易感。流感不仅会导致发…...

OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南
OBS智能跟拍插件:3分钟实现直播自动追踪的终极指南 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 您是否在直播时经常为手动调整摄像头而烦恼?是否希望…...

OBS面部追踪插件终极指南:3分钟实现智能直播自动对焦
OBS面部追踪插件终极指南:3分钟实现智能直播自动对焦 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 在直播和视频录制中,你是否经常需要手动调整摄像头…...

app评论区升级成功
经过我10个小时的激情工作,评论区终于是可以运行起来了,而且我升级了系统,让代码更加直观和可维护。什么你说不好看,等会就好看了。...

某供应链企业200GB数据泄露复盘:如果开了透明加密,攻击者拿走的只有乱码
图:供应链企业数据泄露的3条典型路径(U盘导出/数据库导出/截图)与TDE透明加密的拦截机制事件还原:一次"完美"的内部数据窃取说明:以下事件基于多起真实安全事件综合脱敏处理,技术细节均为真实攻击…...

C++学习笔记17:析构函数
目录 一、什么是析构函数? 二、析构函数写法 三、析构函数的特点 四、析构函数什么时候调用? 五、析构函数不是销毁对象本身 六、为什么需要析构函数? 七、用析构函数释放动态内存 八、析构函数的调用顺序 九、析构函数和构造函数的…...

终极Visual C++运行库修复指南:如何一次性解决所有DLL缺失问题
终极Visual C运行库修复指南:如何一次性解决所有DLL缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾因"找不到MSVCP140.dll&qu…...

R3nzSkin国服特供版:免费体验英雄联盟全皮肤终极指南
R3nzSkin国服特供版:免费体验英雄联盟全皮肤终极指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟皮肤价格昂贵而烦恼吗&…...

从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证
从Verilog到GDS:用Calibre nmLVS-H模式搞定复杂芯片的层级化物理验证 在当今超大规模集成电路设计中,物理验证已成为确保芯片功能正确的最后一道防线。随着工艺节点不断微缩,设计复杂度呈指数级增长,传统的扁平化验证方法已难以应…...