springcloud通过MDC实现分布式链路追踪
在DDD领域驱动设计中,我们使用SpringCloud来去实现,但排查错误的时候,通常会想到Skywalking,但是引入一个新的服务,增加了系统消耗和管理学习成本,对于大型项目比较适合,但是小的项目显得太过臃肿了,我们此时就可以使用TraceId,将其存放到MDC中,返回的时候参数带上它,访问的时候日志打印出来,每次访问生成的TraceId不同,这样可以实现分布式链路追踪的问题。
通用部分
封装TraceIdUtil工具类
import org.apache.commons.lang3.StringUtils;
import org.slf4j.MDC;
import cn.hutool.core.util.IdUtil;public class TraceIdUtil {public static final String TRACE_ID_KEY = "TraceId";/*** 生成TraceId* @return*/public static String generateTraceId(){String traceId = IdUtil.fastSimpleUUID().toUpperCase();MDC.put(TRACE_ID_KEY,traceId);return traceId;}/*** 生成TraceId* @return*/public static String generateTraceId(String traceId){if(StringUtils.isBlank(traceId)){return generateTraceId();}MDC.put(TRACE_ID_KEY,traceId);return traceId;}/*** 获取TraceId* @return*/public static String getTraceId(){return MDC.get(TRACE_ID_KEY);}/*** 移除TraceId* @return*/public static void removeTraceId(){MDC.remove(TRACE_ID_KEY);}
}
logback.xml日志文件的修改
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [TRACEID:%X{TraceId}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
需注意:

biff 模块
创建过滤器
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import org.apache.commons.lang3.StringUtils;
import com.karry.admin.bff.common.util.TraceIdUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;@Slf4j
@WebFilter
public class TraceFilter implements Filter {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {log.info("Init Trace filter init.......");System.out.println("Init Trace filter init.......");}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {try {HttpServletRequest servletRequest = (HttpServletRequest) request;String gateWayTraceId = ((HttpServletRequest) request).getHeader(TraceIdUtil.TRACE_ID_KEY);String traceId = TraceIdUtil.generateTraceId(StringUtils.isEmpty(gateWayTraceId)? IdUtil.fastSimpleUUID().toUpperCase(): gateWayTraceId);// 创建新的请求包装器log.info("TraceIdUtil.getTraceId():"+TraceIdUtil.getTraceId());//将请求和应答交给下一个处理器处理filterChain.doFilter(request,response);}catch (Exception e){e.printStackTrace();}finally {//最后移除,不然有可能造成内存泄漏TraceIdUtil.removeTraceId();}}@Overridepublic void destroy() {log.info("Init Trace filter destroy.......");}
}配置过滤器生效
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import com.karry.admin.bff.common.filter.TraceFilter;
import lombok.extern.slf4j.Slf4j;@Slf4j
@Configuration
public class WebConfiguration {@Bean@ConditionalOnMissingBean({TraceFilter.class})@Order(Ordered.HIGHEST_PRECEDENCE + 100)public FilterRegistrationBean<TraceFilter> traceFilterBean(){FilterRegistrationBean<TraceFilter> bean = new FilterRegistrationBean<>();bean.setFilter(new TraceFilter());bean.addUrlPatterns("/*");return bean;}
}
figen接口发送的head修改
此处修改了发送的请求的header,在其他模块就可以获取从biff层生成的traceId了。
import org.springframework.context.annotation.Configuration;
import com.karry.admin.bff.common.util.TraceIdUtil;
import feign.RequestInterceptor;
import feign.RequestTemplate;@Configuration
public class FeignRequestInterceptor implements RequestInterceptor {@Overridepublic void apply(RequestTemplate template){String traceId = TraceIdUtil.getTraceId();//当前线程调用中有traceId,则将该traceId进行透传if (traceId != null) {template.header(TraceIdUtil.TRACE_ID_KEY,TraceIdUtil.getTraceId());}}
}
统一返回处理
此种情况时针对BaseResult,,这种统一返回的对象无法直接修改的情况下使用的,如果可以直接修改:
/*** 链路追踪TraceId*/public String traceId = TraceIdUtil.getTraceId();
不可以直接修改就用响应拦截器进行处理:
import org.springframework.core.MethodParameter;
import org.springframework.http.MediaType;
import org.springframework.http.server.ServerHttpRequest;
import org.springframework.http.server.ServerHttpResponse;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice;
import com.karry.app.common.utils.TraceIdUtil;
import com.karry.order.sdk.utils.BeanCopyUtils;
import com.souche.platform.common.model.base.BaseResult;
import lombok.SneakyThrows;@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {/*** 开关,如果是true才会调用beforeBodyWrite*/@Overridepublic boolean supports(MethodParameter returnType, Class converterType) {return true;}@SneakyThrows//异常抛出,相当于方法上throw一个异常@Overridepublic Object beforeBodyWrite(Object object, MethodParameter methodParameter, MediaType mediaType, Class aClass,ServerHttpRequest serverHttpRequest, ServerHttpResponse serverHttpResponse) {BaseResult result = BeanCopyUtils.copy(object, BaseResult.class);result.setTraceId(TraceIdUtil.getTraceId());return result;}}非biff模块
创建过滤器
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import org.apache.commons.lang3.StringUtils;
import com.karry.app.common.utils.TraceIdUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;@Slf4j
@WebFilter
public class TraceFilter implements Filter {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {log.info("Init Trace filter init.......");}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {try {HttpServletRequest servletRequest = (HttpServletRequest) request;String gateWayTraceId = ((HttpServletRequest) request).getHeader(TraceIdUtil.TRACE_ID_KEY);String traceId = TraceIdUtil.generateTraceId(StringUtils.isEmpty(gateWayTraceId)? IdUtil.fastSimpleUUID().toUpperCase(): gateWayTraceId);//将请求和应答交给下一个处理器处理filterChain.doFilter(request,response);}catch (Exception e){e.printStackTrace();}finally {//最后移除,不然有可能造成内存泄漏TraceIdUtil.removeTraceId();}}@Overridepublic void destroy() {log.info("Init Trace filter destroy.......");}
}
配置过滤器生效
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import com.karry.admin.bff.common.filter.TraceFilter;
import lombok.extern.slf4j.Slf4j;@Slf4j
@Configuration
public class WebConfiguration {@Bean@ConditionalOnMissingBean({TraceFilter.class})@Order(Ordered.HIGHEST_PRECEDENCE + 100)public FilterRegistrationBean<TraceFilter> traceFilterBean(){FilterRegistrationBean<TraceFilter> bean = new FilterRegistrationBean<>();bean.setFilter(new TraceFilter());bean.addUrlPatterns("/*");return bean;}
}
线程池
上面对于单线程的情况可以进行解决,traceId和Threadlocal很像,是键值对模式,会有内存溢出问题,还是线程私有的。 所以在多线程的情况下就不能获取主线程的traceId了。我们就需要设置线程工厂包装 Runnable 来解决这个问题。
import org.slf4j.MDC;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Map;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;@Configuration
public class MyThreadPoolConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor() {// 自定义 ThreadFactoryThreadFactory threadFactory = new ThreadFactory() {private final ThreadFactory defaultFactory = Executors.defaultThreadFactory();private final String namePrefix = "Async---";@Overridepublic Thread newThread(Runnable r) {// 获取主线程的 MDC 上下文Map<String, String> contextMap = MDC.getCopyOfContextMap();// 包装 Runnable 以设置 MDC 上下文Runnable wrappedRunnable = () -> {try {// 设置 MDC 上下文MDC.setContextMap(contextMap);// 执行任务r.run();} finally {// 清除 MDC 上下文MDC.clear();}};Thread thread = defaultFactory.newThread(wrappedRunnable);thread.setName(namePrefix + thread.getName());return thread;}};ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,30L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(500),threadFactory,new ThreadPoolExecutor.CallerRunsPolicy());return executor;}
}
相关文章:
springcloud通过MDC实现分布式链路追踪
在DDD领域驱动设计中,我们使用SpringCloud来去实现,但排查错误的时候,通常会想到Skywalking,但是引入一个新的服务,增加了系统消耗和管理学习成本,对于大型项目比较适合,但是小的项目显得太过臃…...

logback日志级别动态切换四种方案
生产环境中经常有需要动态修改日志级别。 现在就介绍几种方案 方案一:开启logback的自动扫描更新 配置如下 <?xml version"1.0" encoding"UTF-8"?> <configuration scan"true" scanPeriod"60 seconds" debug…...

AI视频管理平台中使用目标检测模型中的NMS参数原理及设置原则
目标检测模型中的NMS参数原理及设置原则 在目标检测模型中,非极大值抑制(Non-Maximum Suppression,简称NMS)是一种常用的后处理技术,用于筛选和保留最佳的检测框。本文将详细介绍NMS的原理、参数设置原则以及实际应用…...

从零开始点亮一个LED灯 —— keil下载、新建工程、版本烧录、面包板使用、实例代码
一、keil下载 参考视频:Keil5安装教程视频 (全套资料51和32皆可用Keil5编译设置)_哔哩哔哩_bilibili 视频内容包括下载链接、安装教程、库导入,非常详细! 二、新建工程 2.1.使用stm32CubeMX新建工程 10. 使用STM32CubeMX新建工程 — [野…...

[pdf,epub]105页《分析模式》漫谈合集01
105页的《分析模式》漫谈合集第1集的pdf、epub文件,已上传到本账号的CSDN资源。 如果无法下载,也可以访问umlchina.com/url/ap.html 已排版成适合手机阅读,pdf的排版更好一些。 ★UMLChina为什么叒要翻译《分析模式》? ★[缝合故…...

计算机网络5层模型
应用层常见协议 DNS协议 作用:用于实现网络设备名字到IP地址映射的网络服务 特点:DNS是因特网使用的命名系统,它将人们易于记忆的主机名(如www.example.com)转换为机器可识别的IP地址。 FTP协议 作用:用于实现交互式文件传输功能。 特点:FTP支持Standard(主动…...

Python毕业设计选题:基于Python的无人超市管理系统-flask+vue
开发语言:Python框架:flaskPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 系统首页 超市商品详情 购物车 我的订单 管理员登录界面 管理员功能界面 用户界面 员…...

WindowsDocker安装到D盘,C盘太占用空间了。
Windows安装 Docker Desktop的时候,默认位置是安装在C盘,使用Docker下载的镜像文件也是保存在C盘,如果对Docker使用评率比较高的小伙伴,可能C盘空间,会被耗尽,有没有一种办法可以将Docker安装到其它磁盘,同时Docker的数据文件也保存在其他磁盘呢? 答案是有的,我们可以…...
Java面试经典 150 题.P80. 删除有序数组中的重复项 II(004)
本题来自:力扣-面试经典 150 题 面试经典 150 题 - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台https://leetcode.cn/studyplan/top-interview-150/ 题解: class Solution {public int removeDuplicates(int[] nums)…...

【Three.js】SpriteMaterial 加载图片泛白,和原图片不一致
解决方法 如上图所示,整体泛白了,解决方法如下,添加 material.map.colorSpace srgb const imgTexture new THREE.TextureLoader().load(imgSrc)const material new THREE.SpriteMaterial({ map: imgTexture, transparent: true, opacity:…...

了解神经网络中的激活函数
一、激活函数的特征 非线性,激活函数必须是非线性函数。可微性,训练网络模型时,基于梯度的模型最优化方法要求激活函数必须是可导的。单调性,单调递增或单调递减,单调函数保证模型的简单。隐藏层一般需要使用激活函数…...
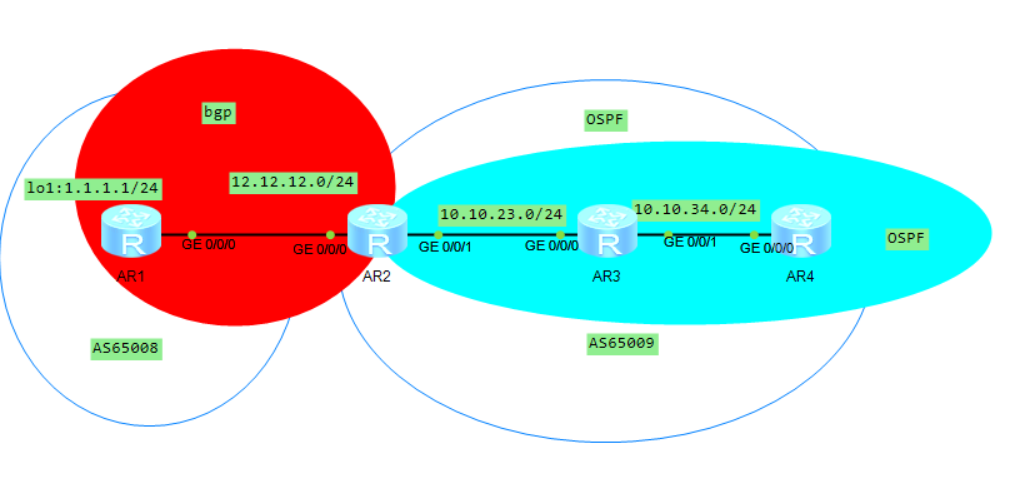
配置BGP与IGP交互和路由自动聚合示例
组网需求 如图所示,用户将网络划分为AS65008和AS65009,在AS65009内,使用IGP协议来计算路由(该例使用OSPF做为IGP协议)。要求实现两个AS之间的互相通信。 配置思路 采用如下的思路配置BGP与IGP交互: 在AR…...

代码随想录算法训练营第三十三天 | 62.不同路径 63.不同路径
LeetCode 62.不同路径: 文章链接 题目链接:62.不同路径 思路: 动态规划 使用二维数组保存递推结果 ① dp数组及下标含义 dp[i][j]:表明从(0, 0)到下标为(i, j)的点有多少条不同的路径 ② 递推式: 机器人只能向下或向…...

使用Flask构建RESTful API
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Flask构建RESTful API Flask简介 环境搭建 安装Flask 项目结构 创建应用 路由定义 请求处理 获取查询参数 获取请求体 响应…...

基于springboot的Java学习论坛平台
基于springboot的Java学习论坛平台 摘 要 在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括学习平台的网络应用,在外国学习平台已经是很普遍的方式,不过国内的管理平台可能还处于起步阶段。学习平台具…...

Python离线环境搭建
引言 在软件开发过程中,我们常常会遇到内网环境无法直接访问外网的情况,这就需要我们通过一些特殊手段来搭建Python开发环境。本文将详细介绍如何利用U盘在内网机与外网机之间迁移Python环境及其依赖包。 工具准备 1台内网机1台外网机1个U盘 操作步骤…...

windows下kafka使用出现的问题
kafka启动 启动kafka需要先启动zookeeper,在kafka根目录下先启动zookeeper .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties启动kafka 另开一个cmd命令行 .\bin\windows\kafka-server-start.bat .\config\server.propertieskafka与jdk版…...

ctfshow文件包含web78~81
目录 web78 方法一:filter伪协议 方法二:input协议 方法三:data协议 web79 方法一:input协议 方法二:data协议 web80 方法一:input协议 方法二:日志包含getshell web81 web78 if(isset($_GET[file]…...

鸿蒙生态认识
好的,让我们更深入地探讨鸿蒙生态的发展机遇、面临的挑战,以及未来的潜力。 对鸿蒙生态的认知与分析 鸿蒙系统作为一种新兴的操作系统,旨在打破设备之间的壁垒,打造一个更加连通的生态环境。以下是对其崛起的进一步分析…...

Hadoop-004-Big Data Tools插件的使用
一、Big Data Tools插件配置流程 1、安装Big Data Tools插件 以IntelliJ IDEA 2024.2.3为例打开setting, 搜索安装Big Data Tools插件后重启IDEA 2、Windows系统基础配置 Windows系统需要做一些基础设置,配合插件使用,将之前下载的hadoop-3.2.4.tar.gz 解压到D…...

CH582低功耗实战:从1.2mA到5uA,我是如何排查并优化BLE广播功耗的
CH582低功耗实战:从1.2mA到5uA的BLE广播功耗优化全记录 当你的蓝牙传感器在货架上静静等待唤醒时,每微安的电流都在偷走电池的生命。去年冬天,我们团队就遭遇了这样的噩梦——基于CH582开发的温湿度信标,标称续航6个月的产品在实际…...

2026年B站资源下载全攻略:3步学会用BiliTools高效保存视频
2026年B站资源下载全攻略:3步学会用BiliTools高效保存视频 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

别再死记硬背Prompt了!用LangChain的ChatPromptTemplate,5分钟搞定角色扮演对话机器人
用LangChain的ChatPromptTemplate快速构建角色扮演对话机器人 你是否曾经为了设计一个能记住对话历史的客服机器人,不得不手动拼接几十行提示词?或者为了让AI扮演特定角色,反复调整系统消息却始终达不到理想效果?LangChain的Chat…...
)
别再只跑测试了!用KAIR库从零训练你自己的SwinIR超分模型(附DIV2K/Flickr2K数据集处理避坑指南)
从测试到训练:SwinIR超分模型实战进阶指南 当你第一次用SwinIR的预训练模型将模糊照片变得清晰时,那种惊艳感可能让你跃跃欲试想训练自己的模型。但面对几十GB的数据集和复杂的训练配置,很多开发者停在了"只跑测试"的阶段。本文将带…...

不同版本Python安装常见问题与解决方案
1. 如何在特定的版本下安装package (1) 在命令提示符中,打开相应版本python的安装目录; (2) 执行语句python.exe -m pip install XX (3) 更新库 2. 如何在Spyder中设定特定的python解释器 Spyder—Tools—Python Interpreter...

海底管道电伴热机理及系统建模与控制策略【附程序】
✨ 长期致力于电伴热、集肤效应、Hammerstein模型、参数辨识、约束广义预测控制算法、功率调节、场路耦合法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&#…...

关键字[Static]
一、static 的三种用法 1. 静态局部变量 * 特性: * - 只初始化一次(程序启动时) * - 函数返回后值保留(不销毁) * - 下次调用时保持上次的值 * - 存储在静态区,不在栈上 2. 静态全局变量(文件作用域限制) 仅在 xx.c 内可见,其他文件无法访问 3. 静态函数(文件作用域限…...

从地图导航到推荐系统:欧式距离在真实业务场景中的Python应用避坑指南
从地图导航到推荐系统:欧式距离在真实业务场景中的Python应用避坑指南 当你在外卖App上查看"3公里内的餐厅",或在电商平台看到"相似用户还买了"的推荐时,背后可能都在使用同一个数学工具——欧式距离。这个看似简单的距离…...

避坑指南:STM32驱动LD3320语音模块,SPI通信和中断配置的那些‘坑’我都替你踩过了
STM32与LD3320语音模块深度避坑实战:从SPI配置到中断优化的完整指南 当第一次拿到LD3320语音识别模块时,大多数开发者都会为它的"即插即用"特性感到兴奋——理论上只需要简单的SPI连接和基础配置就能实现语音识别功能。然而在实际项目中&#…...

FPGA系统时钟革新:纯硅可编程振荡器提升可靠性与设计灵活性
1. 项目概述:为什么FPGA需要一个更“稳”的时钟?在FPGA(现场可编程门阵列)的设计与应用中,时钟信号就像是整个数字系统的“心跳”。无论是高速数据采集、复杂算法处理,还是多协议通信,一个稳定、…...