机器学习之fetch_olivetti_faces人脸识别--基于Python实现
fetch_olivetti_faces
数据集下载
fetch_olivetti_faces![]() https://github.com/jikechao/olivettifaces
https://github.com/jikechao/olivettifaces
sklearn.datasets.fetch_olivetti_faces(*, data_home=None, shuffle=False, random_state=0, download_if_missing=True, return_X_y=False, n_retries=3, delay=1.0)[source]
Load the Olivetti faces data-set from AT&T (classification).
Download it if necessary.
| Classes | 40 |
| Samples total | 400 |
| Dimensionality | 4096 |
| Features | real, between 0 and 1 |
Read more in the User Guide.
Parameters:
data_homestr or path-like, default=None
Specify another download and cache folder for the datasets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
shufflebool, default=False
If True the order of the dataset is shuffled to avoid having images of the same person grouped.
random_stateint, RandomState instance or None, default=0
Determines random number generation for dataset shuffling. Pass an int for reproducible output across multiple function calls. See Glossary.
download_if_missingbool, default=True
If False, raise an OSError if the data is not locally available instead of trying to download the data from the source site.
return_X_ybool, default=False
If True, returns instead of a object. See below for more information about the and object.(data, target)Bunchdatatarget
Added in version 0.22.
n_retriesint, default=3
Number of retries when HTTP errors are encountered.
Added in version 1.5.
delayfloat, default=1.0
Number of seconds between retries.
Added in version 1.5.
Returns:
dataBunch
Dictionary-like object, with the following attributes.
data: ndarray, shape (400, 4096)
Each row corresponds to a ravelled face image of original size 64 x 64 pixels.
imagesndarray, shape (400, 64, 64)
Each row is a face image corresponding to one of the 40 subjects of the dataset.
targetndarray, shape (400,)
Labels associated to each face image. Those labels are ranging from 0-39 and correspond to the Subject IDs.
DESCRstr
Description of the modified Olivetti Faces Dataset.
(data, target)tuple if
return_X_y=True
Tuple with the and objects described above.datatarget
Added in version 0.22.
Olivetti Faces人脸数据集合处理
简介
本资源文件提供了Olivetti Faces人脸数据集的处理方法和相关代码。Olivetti Faces是一个经典的人脸识别数据集,包含了40个不同个体的400张灰度图像。每个个体有10张图像,这些图像在不同的光照和表情条件下拍摄。
数据集特点
- 图像数量:400张
- 个体数量:40个
- 每张图像大小:47x47像素
- 图像格式:灰度图像
数据集下载
数据集可以从以下地址下载:
- 官方地址:http://cs.nyu.edu/~roweis/data/olivettifaces.gif
- 备用地址:百度网盘 请输入提取码 提取码:9m3c
数据处理
由于数据集是一张大图,每个人脸需要进行切割处理。可以使用Python脚本进行图像切割,具体代码如下:
# 导入所需的库 import cv2 import numpy as np# 读取大图 image = cv2.imread('olivettifaces.gif', cv2.IMREAD_GRAYSCALE)# 获取图像的尺寸 height, width = image.shape# 每个人脸的大小 face_height = height // 20 face_width = width // 20# 切割并保存每个人脸 faces = [] for i in range(20):for j in range(20):face = image[i*face_height:(i+1)*face_height, j*face_width:(j+1)*face_width]faces.append(face)cv2.imwrite(f'face_{i*20 + j}.png', face)print("图像切割完成,共保存了400张人脸图像。")使用方法
- 下载数据集并保存为
olivettifaces.gif。- 运行上述Python脚本进行图像切割。
- 切割后的人脸图像将保存在当前目录下,文件名为
face_0.png到face_399.png。参考资料
- 本资源文件的详细处理方法和代码参考自CSDN博客文章。
注意事项
- 请确保Python环境已安装OpenCV库。
- 如果遇到下载问题,可以使用备用地址进行下载。
贡献
欢迎对本资源文件进行改进和优化,提交Pull Request或Issue。
Examples
>>> from sklearn.datasets import fetch_olivetti_faces >>> olivetti_faces = fetch_olivetti_faces() >>> olivetti_faces.data.shape (400, 4096) >>> olivetti_faces.target.shape (400,) >>> olivetti_faces.images.shape (400, 64, 64)
读入人脸数据
import matplotlib.pyplot as plt
fig,ax=plt.subplots(8,8,figsize=(8,8))
fig.subplots_adjust(hspace=0,wspace=0)
from sklearn.datasets import fetch_olivetti_faces
faces=fetch_olivetti_faces().images
for i in range(8):for j in range(8):ax[i,j].xaxis.set_major_locator(plt.NullLocator())ax[i,j].yaxis.set_major_locator(plt.NullLocator())ax[i,j].imshow(faces[i*10+j],cmap='bone') 
import warnings
warnings.filterwarnings('ignore')#fetch_olivetti_faces图像分割
import numpy as np
from sklearn.datasets import fetch_olivetti_faces
faces=fetch_olivetti_faces().images
X=faces.reshape(-1,64*64)
y=np.arange(40).repeat(10)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=42)
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
param_grid={'C':[0.1,1,10,100,1000],'gamma':[0.0001,0.001,0.01,0.1]}
grid=GridSearchCV(SVC(),param_grid,cv=5)
grid.fit(X_train,y_train)
print(grid.best_params_)
print(grid.score(X_test,y_test)){'C': 100, 'gamma': 0.001}
0.97
人脸图像切分:
#读取olivettifaces.gif文件
import matplotlib.pyplot as plt
from PIL import Image
import cv2
im=Image.open('olivettifaces.gif')plt.imshow(im,cmap='gray')
plt.show()
#分割图片
im_array=np.array(im)
im_array.shape# 获取图像的尺寸
height, width = im_array.shape# 每个人脸的大小
face_height = height // 20
face_width = width // 20# 切割并保存每个人脸
faces = []
for i in range(20):for j in range(20):face = im_array[i*face_height:(i+1)*face_height, j*face_width:(j+1)*face_width]faces.append(face)# 保存人脸face = Image.fromarray(face)face.save(f'./人脸识别/picture/face_{i*20+j}.png')
print('人脸切割完成') 

人脸识别
# 读取人脸图片
import os
import numpy as np
from PIL import Image
import cv2
faces = []
for i in range(400):face = Image.open(f'./人脸识别/picture/face_{i}.png')face = np.array(face)faces.append(face)
faces = np.array(faces)
faces.shape 
import warnings
warnings.filterwarnings('ignore')
# 人脸识别
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X = faces.reshape(400, -1)
y = np.arange(40).repeat(10)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
param_grid = {'C': [0.1, 1, 10, 100, 1000], 'gamma': [0.0001, 0.001, 0.01, 0.1]}
grid = GridSearchCV(SVC(), param_grid, cv=5)
grid.fit(X_train, y_train)
print(grid.best_params_) 
相关文章:
机器学习之fetch_olivetti_faces人脸识别--基于Python实现
fetch_olivetti_faces 数据集下载 fetch_olivetti_faceshttps://github.com/jikechao/olivettifaces sklearn.datasets.fetch_olivetti_faces(*, data_homeNone, shuffleFalse, random_state0, download_if_missingTrue, return_X_yFalse, n_retries3, delay1.0)[source] L…...

【系统设计】深入理解HTTP缓存机制:从Read-Through缓存到HTTP缓存的交互流程
在现代Web开发中,缓存机制扮演着至关重要的角色。它不仅提升了用户体验,还极大地优化了资源的使用效率。在这篇博文中,我们将从“Read-Through”缓存的概念出发,深入探讨HTTP缓存的工作原理和交互流程,并详细描述max-a…...

FLINK单机版安装部署入门-1
文章目录 FLINK单机版安装部署高于1.9.3需要修改配置文件flink-conf.yaml(低于1.9.3可以跳过)linux启动集群windows下启动Flink实例运行(单机)还有一种方式是上传任务包运行examples\streamingjava: Compilation failed: internal java compiler error高版本启动脚本 FLINK单机…...

深度学习-学习率调整策略
在深度学习中,学习率调整策略(Learning Rate Scheduling)用于在训练过程中动态调整学习率,以实现更快的收敛和更好的模型性能。选择合适的学习率策略可以避免模型陷入局部最优、震荡不稳定等问题。下面介绍一些常见的学习率调整策…...

【学员提问bug】小程序在onUnload里面调接口,用来记录退出的时间, 但是接口调用还没成功, 页面就关闭了。如何让接口在onUnload关闭前调用成功?
这种问题比较通用,并不涉及到具体方法执行障碍,所以,解决起来也不麻烦。但是新手往往不知道如何做。 在小程序中,如果在 onUnload 中调用 API 记录页面退出时间,但因为页面关闭速度较快导致请求未完成,可以…...

【刷题13】链表专题
目录 一、两数相加二、两两交换链表的节点三、重排链表四、合并k个升序链表五、k个一组翻转链表 一、两数相加 题目: 思路: 注意整数是逆序存储的,结果要按照题目的要求用链表连接起来遍历l1的cur1,遍历l2的cur2,和…...

Python Turtle模块详解与使用教程
Python Turtle模块详解与使用教程 引言 Python是一种广泛使用的编程语言,其简洁易读的语法使得它成为初学者学习编程的理想选择。而Turtle模块则是Python标准库中一个非常有趣且实用的图形绘制工具,特别适合用于教育和学习编程的基础知识。通过Turtle模…...

【PTA】4-2 树的同构【数据结构】
给定两棵树 T1 和 T2。如果 T1 可以通过若干次左右孩子互换就变成 T2,则我们称两棵树是“同构”的。例如图1给出的两棵树就是同构的,因为我们把其中一棵树的结点A、B、G的左右孩子互换后,就得到另外一棵树。而图2就不是同构的。 图一…...

Node.js——fs模块-同步与异步
本文的分享到此结束,欢迎大家评论区一同讨论学习,下一篇继续分享Node.js的fs模块文件追加写入的学习。...
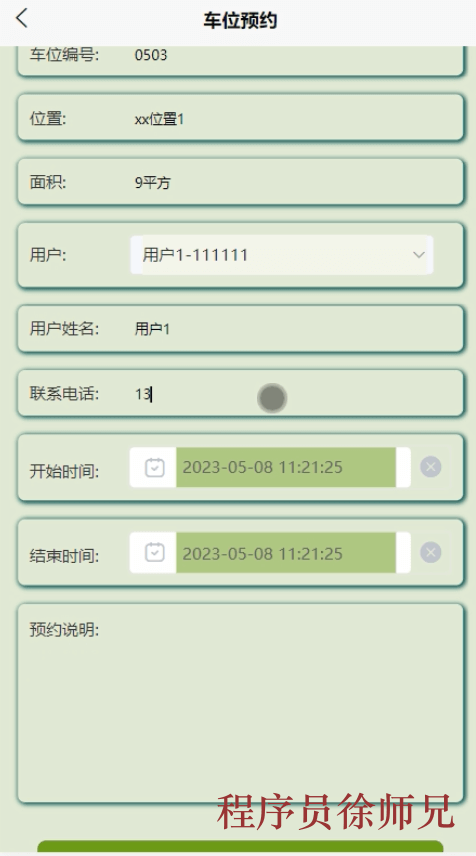
Java基于微信小程序的私家车位共享系统(附源码,文档)
博主介绍:✌stormjun、8年大厂程序员经历。全网粉丝15w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...
vscode 创建 vue 项目时,配置文件为什么收缩到一起展示了?
一、前言 今天用 vue 官方脚手架创建工程,然后通过 vscode 打开项目发现,配置文件都被收缩在一起了。就像下面这样 这有点反直觉,他们应该是在同一层级下的,怎么会这样,有点好奇,但是打开资源管理查看&…...

PySpark任务提交
一般情况下,spark任务是用scala开发的,但是对于一些偏业务人员,或者是基于上手的来说python的API确实降低了开发前置条件的难度,首当其冲的就是能跳过Java和Scala需要的知识储备,但是在提交任务到集群的时候就很麻烦了…...
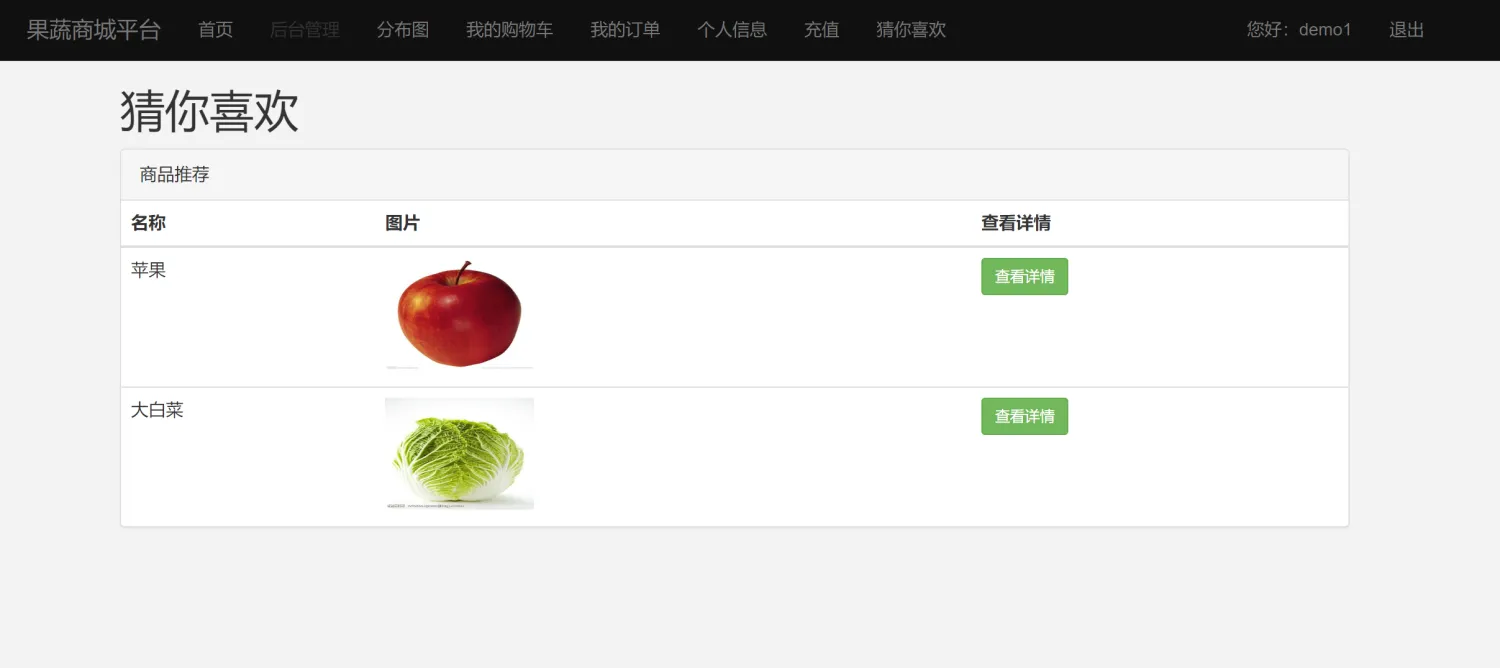
【果蔬购物商城管理与推荐系统】Python+Django网页界面+协同过滤推荐算法+管理系统网站
一、介绍 果蔬购物管理与推荐系统。本系统以Python作为主要开发语言,前端通过HTML、CSS、BootStrap等框架搭建界面,后端使用Django框架作为逻辑处理,通过Ajax实现前后端的数据通信。并基于用户对商品的评分信息,采用协同过滤推荐…...

【大模型】海外生成式AI赛道的关键玩家:OpenAI、Anthropic之外还有谁?
引言 在生成式AI快速发展的今天,不同公司在各自领域发挥着独特作用。本文将从基础模型研发、开发工具框架、垂直领域应用三个维度,为读者梳理当前生成式AI技术领域的主要参与者,帮助开发者更好地把握技术发展方向。 一、基础模型研发公司 O…...

kubevirt cloud-init配置
https://cloudinit.readthedocs.io/en/latest/reference/examples.html (示例) https://cloudinit.readthedocs.io/en/latest/reference/faq.html (常见问题) https://cloudinit.readthedocs.io/en/latest/howto/debug_user_data.html (检查user_data) https://clo…...

Oracle 大表添加索引的最佳方式
背景: 业务系统中现在经常存在上亿数据的大表,在这样的大表上新建索引,是一个较为耗时的操作,特别是在生产环境的系统中,添加不当,有可能造成业务表锁表,业务表长时间的停服势必会影响正常业务…...

速度了解云原生后端!!!
云原生后端是指基于云计算技术和理念构建的后端系统架构,旨在充分利用云计算的优势,实现快速部署、弹性扩展、高可用性和高效运维。以下是云原生后端的一些关键特点和技术: 容器化 容器化是云原生架构的核心之一,它使用容器技术&…...

云计算Openstack 虚拟机调度策略
OpenStack的虚拟机调度策略是一个复杂而灵活的系统,它主要由两种调度器实现:FilterScheduler(过滤调度器)和ChanceScheduler(随机调度器)。以下是对这两种调度器及其调度策略的详细解释: 一、F…...

在 macOS 上添加 hosts 文件解析的步骤
步骤 1: 打开 hosts 文件 打开终端: 你可以通过 Spotlight 搜索(按 Cmd Space 并输入 Terminal)来打开终端。 使用文本编辑器打开 hosts 文件: 在终端中输入以下命令,使用 nano 文本编辑器打开 hosts 文件:…...

RHCE【防火墙】
目录 一、防火墙简介 二、iptables 实验一:搭建web服务,设置任何人能够通过80端口访问。 实验二:禁止所有人ssh远程登录该服务器 实验三:禁止某个主机地址ssh远程登录该服务器,允许该主机访问服务器的web服务。服…...

深入解析mootdx:Python通达信数据接口的架构设计与性能优化
深入解析mootdx:Python通达信数据接口的架构设计与性能优化 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在量化交易和金融数据分析领域,高效稳定的数据获取是成功的关键…...
)
NotebookLM文化遗产研究不可逆断层预警:当AI开始“发明”不存在的碑刻铭文(含3类幻觉检测SOP)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文化遗产研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的私有文档进行深度语义理解与上下文关联推理。在文化遗产研究领域,该…...

【HarmonyOS6.1全场景实战】基线版本:我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App
我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App 摘要:从开篇词到第15篇,《灵犀厨房》的第一个里程碑版本 v2.0 正式发布。它不再是一个前端Demo,而是一个拥有用户认证系统、Python Flask后台、MySQL数据库、AI智能…...

Python网络爬虫框架xcapy实战:任务驱动与反爬对抗
1. 项目概述:一个为现代应用量身定制的网络抓取框架最近在做一个需要大规模、高频率抓取网页数据的项目,传统的爬虫框架用起来总觉得有点“水土不服”。要么是异步处理不够优雅,遇到复杂的反爬策略就手忙脚乱;要么是配置过于繁琐&…...

为什么你的NotebookLM总“读不懂”Nature论文?生信老炮拆解7类专业语义断层及5种Prompt工程修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM生物技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作流设计。在生物技术领域,它可高效整合海量文献、实验报告与基因组数据库摘要&#x…...

FakeLocation终极指南:三分钟掌握Android应用级虚拟定位黑科技
FakeLocation终极指南:三分钟掌握Android应用级虚拟定位黑科技 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否曾想过在手机上"瞬间移动"到世界任何角…...

基于RAG的LLM知识库构建:从智能分块到检索增强生成实战
1. 项目概述:一个为大型语言模型量身定制的知识库构建工具如果你和我一样,经常和大型语言模型打交道,无论是用它们来辅助编程、分析文档,还是构建问答系统,那你一定遇到过这个核心痛点:如何让模型精准地理解…...

回溯算法:暴力枚举最优解
一、上期回顾 吃透二分查找三大模板:基础查找、左边界、右边界,掌握二分答案解题思维,有序数组最优解法全部拿下。今天正式攻克回溯算法,暴力枚举最优写法,解决排列、组合、子集、棋盘类所有搜索题。二、递归与回溯核心…...

APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案
APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓…...

AzurLaneAutoScript:碧蓝航线玩家的终极自动刷图解决方案
AzurLaneAutoScript:碧蓝航线玩家的终极自动刷图解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为…...