Python中的SQL数据库管理:SQLAlchemy教程
Python中的SQL数据库管理:SQLAlchemy教程
在Python应用程序中,操作数据库是常见的需求之一。而 SQLAlchemy 是一个功能强大的数据库管理库,它提供了Pythonic的接口来管理和查询SQL数据库。SQLAlchemy 兼具 ORM(对象关系映射)和核心 SQL 表达式构建功能,让用户既能享受面向对象的操作,也能灵活地编写复杂的 SQL 查询。本文将带您一步步了解 SQLAlchemy 的使用方式和常用技巧,帮助您在Python中高效管理SQL数据库。
一、SQLAlchemy 简介
SQLAlchemy 可以分为两个主要部分:
- SQLAlchemy Core:一个轻量级的SQL表达式语言,支持基本的SQL查询构建。
- SQLAlchemy ORM:基于对象关系映射的ORM库,允许我们将数据库表与Python对象关联,通过操作对象来操作数据库表。
安装 SQLAlchemy
要使用 SQLAlchemy,首先确保安装最新版本:
pip install sqlalchemy
二、创建数据库引擎
SQLAlchemy 的数据库连接是通过 Engine 对象实现的。连接数据库时,只需提供数据库URL,SQLAlchemy 将会自动选择相应的数据库驱动。
from sqlalchemy import create_engine# SQLite 示例数据库
engine = create_engine('sqlite:///example.db')
常见的数据库URL格式
- SQLite:
sqlite:///example.db - PostgreSQL:
postgresql://username:password@localhost:5432/mydatabase - MySQL:
mysql+pymysql://username:password@localhost/mydatabase
三、定义表结构
1. 使用 SQLAlchemy Core 定义表
可以通过 Table 对象定义表结构,包含表名、字段类型和主键等信息:
from sqlalchemy import MetaData, Table, Column, Integer, Stringmetadata = MetaData()users = Table('users', metadata,Column('id', Integer, primary_key=True),Column('name', String, nullable=False),Column('age', Integer)
)
2. 使用 ORM 定义表和模型
SQLAlchemy ORM 允许我们用 Python 类表示数据库中的表,定义一个模型类并继承 Base,通过字段类型定义表的结构。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, StringBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String, nullable=False)age = Column(Integer)# 创建所有定义的表
Base.metadata.create_all(engine)
四、建立会话并操作数据库
要操作数据库,需要通过 Session 对象与数据库交互。Session 提供了事务管理的功能,是 ORM 的核心部分。
from sqlalchemy.orm import sessionmaker# 创建Session类
Session = sessionmaker(bind=engine)
session = Session()
1. 插入数据
通过 ORM 模型实例化对象后,可以使用 session.add() 或 session.add_all() 插入一条或多条数据。
# 创建一个新用户
new_user = User(name="Alice", age=25)
session.add(new_user)
session.commit() # 提交更改
2. 查询数据
SQLAlchemy 提供了多种查询方法,如 query()、filter() 等,让我们可以方便地进行各种复杂查询。
# 查询所有用户
users = session.query(User).all()
for user in users:print(user.name, user.age)# 查询单个用户
user = session.query(User).filter_by(name="Alice").first()
print(user.name, user.age)
3. 更新数据
通过查询获取对象后,直接修改对象的属性并提交即可完成更新。
user = session.query(User).filter_by(name="Alice").first()
user.age = 30
session.commit()
4. 删除数据
使用 session.delete() 删除数据,删除后需要提交更改。
user = session.query(User).filter_by(name="Alice").first()
session.delete(user)
session.commit()
五、高级查询技巧
SQLAlchemy 提供了丰富的查询 API,支持复杂查询操作,例如排序、分组、连接等。
1. 排序和限制
可以使用 order_by() 和 limit() 方法实现结果排序和限制结果数量。
# 按年龄降序排序,获取前 5 个用户
users = session.query(User).order_by(User.age.desc()).limit(5).all()
2. 分组查询
可以使用 group_by() 实现分组查询,并结合 func 模块进行聚合计算。
from sqlalchemy import func# 查询每个年龄段的用户数量
age_count = session.query(User.age, func.count(User.id)).group_by(User.age).all()
3. 多表连接查询
在多表关联查询中,可以使用 join() 函数连接表,例如通过用户 ID 在 orders 表中查找用户订单。
# 假设有一个 Orders 表,我们可以通过 User 表和 Orders 表的关系进行连接查询
orders = session.query(User, Order).join(Order, User.id == Order.user_id).all()
六、使用事务管理
在 SQLAlchemy 中,事务是通过 Session 管理的。操作数据时可以使用 commit() 提交事务,也可以使用 rollback() 回滚事务。在批量操作数据时,通常使用事务块来确保操作的原子性。
# 开启事务
try:user = User(name="Bob", age=22)session.add(user)session.commit()
except Exception as e:session.rollback() # 出错时回滚事务print(f"发生错误: {e}")
finally:session.close()
七、模型间关系管理
在 ORM 中,我们可以通过关系(relationship)来定义模型之间的关联,如一对多或多对多关系。SQLAlchemy 提供了 relationship() 方法进行关联映射。
1. 一对多关系
假设我们有一个 User 和 Post 表,每个用户可以有多个帖子,可以定义一对多的关系。
from sqlalchemy.orm import relationshipclass Post(Base):__tablename__ = 'posts'id = Column(Integer, primary_key=True)title = Column(String, nullable=False)user_id = Column(Integer, ForeignKey('users.id'))user = relationship("User", back_populates="posts")class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)name = Column(String, nullable=False)age = Column(Integer)posts = relationship("Post", back_populates="user")
2. 多对多关系
假设有一个 Student 和 Course 表,可以使用 association_table 创建中间表来定义多对多的关系。
association_table = Table('student_course', Base.metadata,Column('student_id', Integer, ForeignKey('students.id')),Column('course_id', Integer, ForeignKey('courses.id'))
)class Student(Base):__tablename__ = 'students'id = Column(Integer, primary_key=True)name = Column(String)courses = relationship("Course", secondary=association_table, back_populates="students")class Course(Base):__tablename__ = 'courses'id = Column(Integer, primary_key=True)title = Column(String)students = relationship("Student", secondary=association_table, back_populates="courses")
八、总结
SQLAlchemy 是一个功能强大的数据库管理库,为 Python 开发者提供了操作 SQL 数据库的高效方式。通过 SQLAlchemy,您可以轻松地进行表定义、数据插入、复杂查询、事务管理和关系管理等操作。本教程涵盖了 SQLAlchemy 的基础与进阶使用方法,希望对您在实际开发中的数据库管理有所帮助。
相关文章:

Python中的SQL数据库管理:SQLAlchemy教程
Python中的SQL数据库管理:SQLAlchemy教程 在Python应用程序中,操作数据库是常见的需求之一。而 SQLAlchemy 是一个功能强大的数据库管理库,它提供了Pythonic的接口来管理和查询SQL数据库。SQLAlchemy 兼具 ORM(对象关系映射&…...

LeetCode --- 421周赛
题目列表 3334. 数组的最大因子得分 3335. 字符串转换后的长度 I 3336. 最大公约数相等的子序列数量 3337. 字符串转换后的长度 II 一、数组的最大因子得分 数据范围足够小,可以用暴力枚举移除的数字,得到答案,时间复杂度为O(n^2)&#…...

简单了解前缀树/字典树(Trie树)C++代码
介绍Trie树 Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。 前缀树也有一些其它的名称:字典…...

ubuntu安装与配置Nginx(2)
1. 配置 Nginx Nginx 的配置文件通常位于 /etc/nginx/nginx.conf,而虚拟主机的配置文件通常在 /etc/nginx/sites-available/ 和 /etc/nginx/sites-enabled/ 目录中。 在/etc/nginx/conf.d目录下新建xx.conf文件,配置文件, nginx -t 检查语法…...
Linux环境下Mongodb部署
文章目录 一、系统环境二、MongoDb安装添加MongoDB官方库安装MongoDB配置MongoDB 三、MongoDB常见操作四、MongoDB用户管理创建用户修改密码删除用户 五、启用安全控制六、备份与还原1. 备份2. 恢复 七、外部工具连接MongoDB 一、系统环境 CentOS Stream 9 64bit 二、MongoD…...

(九)JavaWeb后端开发——Servlet
目录 1.Servlet由来 2.Servlet快速入门 3.Servlet执行原理 4.Servlet生命周期 1.Servlet由来 在JaveEE API文档中对Servlet的描述是:可以运行在服务器端的微小程序,但是实际上,Servlet就是一个接口,定义了Java类被浏览器访问…...

【零售和消费品&家居用品】家庭门窗开闭状态安全监控系统源码&数据集全套:改进yolo11-DCNV2
改进yolo11-GhostDynamicConv等200全套创新点大全:家庭门窗开闭状态安全监控系统源码&数据集全套 1.图片效果展示 项目来源 人工智能促进会 2024.11.01 注意:由于项目一直在更新迭代,上面“1.图片效果展示”和“2.视频效果展示”…...

【JavaScript】axios 二次封装拦截器(接口、实例、全局)
学习 coderwhy 老师结合 ts 二次封装 axios 目录结构 config config\index.ts // export const BASE_URL "http://codercba.com:9002"; export const TIME_OUT 10000;// 1. 根据环境变量区分接口地址 // let BASE_URL: string; // if (process.env.NODE_ENV &qu…...

Linux_02 Linux常用软件——vi、vim
vi编辑器有三种主要模式,每种模式的功能和用途不同: 一、命令模式 (Command Mode): - 启动 vi 时默认进入此模式。 - 你可以在此模式下移动光标,输入各种命令(如删除、复制、粘贴等)。 yy:…...

C++代码优化--要求或禁止在堆中产生对象
目录 1.引言 2.栈与堆区别 2.1. 栈(Stack) 2.2. 堆(Heap) 3.限制在堆上分配内存的好处 4.对象在栈上分配内存的方法 4.1. 使用RAII(资源获取即初始化) 4.2. 避免使用new和delete 4.3. 限制对象的生…...

MybatisPlus入门(六)MybatisPlus-空值处理
一、MybatisPlus-空值处理 1.1)问题引入: 在查询中遇到如下情况,有部分筛选条件没有值,如商品价格有最大值和最小值,商品价格部分时候没有值。 1.2)解决办法: 步骤一:新建查询实体…...

钉钉内集成第三方免密登录(Vue+.Net)
需要实现的效果就是在钉钉内点击应用能跳转到第三方网站并且免密登录 1.登录钉钉PC端管理后台 2.通过管理后台进去开发者后台 3.应用开发 创建H5微应用 4.应用创建成功后直接点权限管理全部授权 5.设置H5登录地址 6. 应用管理发布 至此需要配置的步骤全部已完成,…...

卷积神经网络实验三:模型优化(1)
作者有话说: 这篇文章写的还是比混乱的。因为本人也是第一次做这样的尝试,虽然接触深度学习有一年了,但是对于模型的优化仅仅是局限于理论上。通过这一次的实验,我对于模型的理解也更深了几分。我不期望这篇文章能帮你能解决多大问…...

STM32F103的CAN通讯接收测试
首先配置CUBEMX 1.打开CUBEMX 设置时钟,由于我没有外部时钟,所以我选择内部时钟,选择8倍频,1分频,APB1时钟频率为32MKHZ,也就是说每秒能够执行 3200 万个时钟周期,1M是每秒执行100万个时钟周期。 2.CAN收…...

【Rust中的智能指针】
Rust中的智能指针 什么是智能指针?什么是Rust中的智能指针?Rust中的智能指针BoxBox的使用场景 Rust中的智能指针Rc与Arcrust中的RefCellrefcell的缺点:rust中的weak先来看看C中的weak_ptr定义代码示例: Deref和Drop 总结 什么是智…...

基于深度学习的社交网络中的社区检测
在社交网络分析中,社区检测是一项核心任务,旨在将网络中的节点(用户)划分为具有高内部连接密度且相对独立的子群。基于深度学习的社区检测方法,通过捕获复杂的网络结构信息和节点特征,在传统方法基础上实现…...

【Python基础】
一、编程语言介绍 1、分类 机器语言 (直接用 0 1代码编写)汇编语言 (英文单词替代二进制指令)高级语言 2、总结 1、执行效率:机器语言>汇编语言>高级语言(编译型>解释型) 2、开发效率&…...
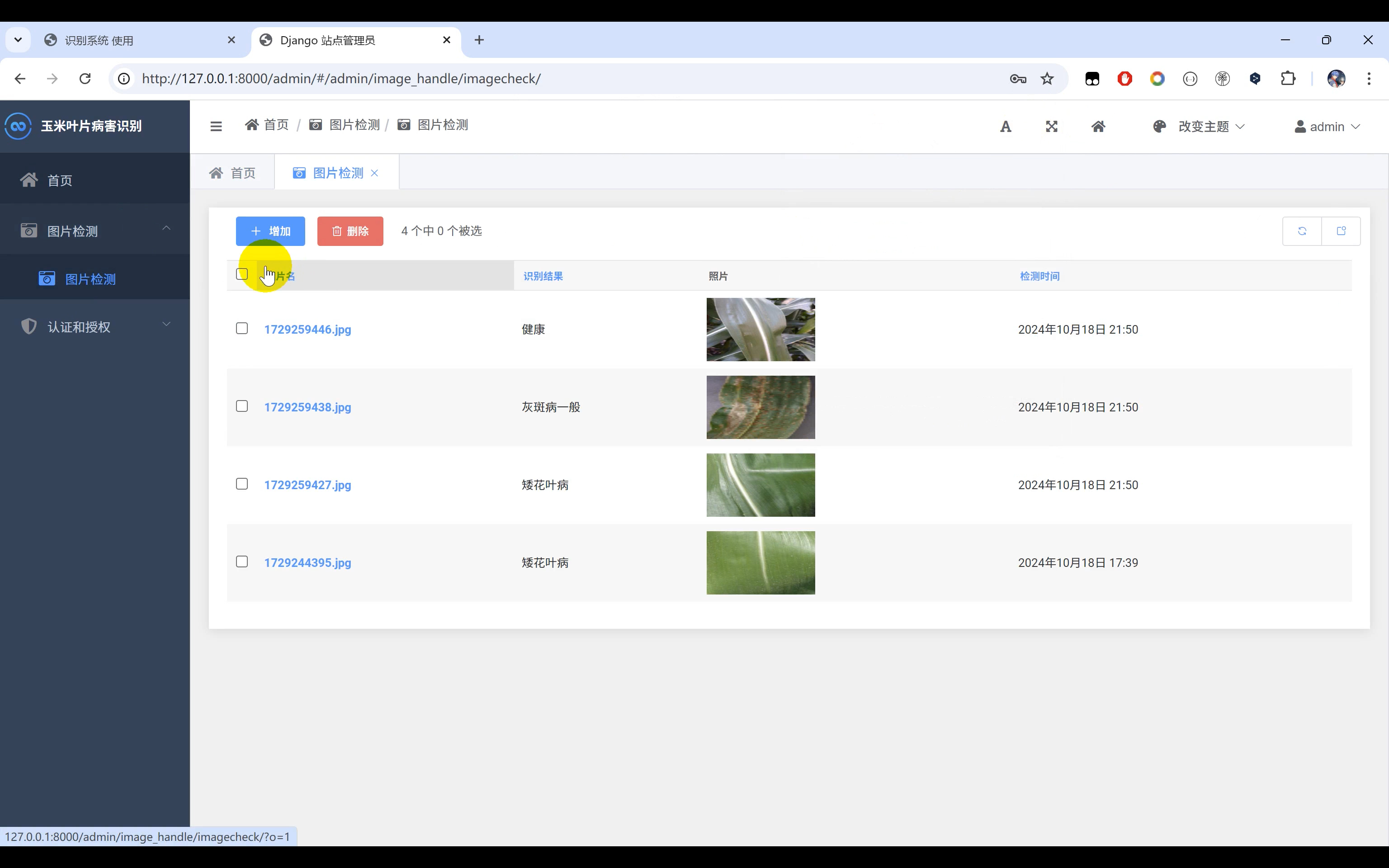
【玉米叶部病害识别】Python+深度学习+人工智能+图像识别+CNN卷积神经网络算法+TensorFlow
一、介绍 玉米病害识别系统,本系统使用Python作为主要开发语言,通过收集了8种常见的玉米叶部病害图片数据集(‘矮花叶病’, ‘健康’, ‘灰斑病一般’, ‘灰斑病严重’, ‘锈病一般’, ‘锈病严重’, ‘叶斑病一般’, ‘叶斑病严重’&#x…...

【设计模式】如何用C++实现依赖倒置
【设计模式】如何用C实现依赖倒置 一、什么是依赖倒置? 依赖倒置原则(Dependency Inversion Principle,DIP)是SOLID面向对象设计原则中的一项。它的核心思想是: 高层模块不应该依赖于低层模块,两者都应该…...

使用onnxruntime-web 运行yolov8-nano推理
ONNX(Open Neural Network Exchange)模型具有以下两个特点促成了我们可以使用onnxruntime-web 直接在web端上运行推理模型,为了让这个推理更直观,我选择了试验下yolov8 识别预览图片: 1. 跨平台兼容性 ONNX 是一种开…...

NIPAP:开源IP地址管理平台如何实现企业级网络规划效率提升300%
NIPAP:开源IP地址管理平台如何实现企业级网络规划效率提升300% 【免费下载链接】NIPAP Neat IP Address Planner - NIPAP is the best open source IPAM in the known universe, challenging classical IP address management (IPAM) systems in many areas. 项目…...
)
py每日spider案例之某guangdong省人mingzhengfu登录接口(难度高 )
加密入口: 逆向接口: sm2密钥接口: js逆向代码: const fs = require("fs"); const path = re...

R3nzSkin国服换肤终极教程:5分钟免费解锁英雄联盟全皮肤
R3nzSkin国服换肤终极教程:5分钟免费解锁英雄联盟全皮肤 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟国服的限定皮肤望而…...

WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题
WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经遇到过这样的场景:…...

【GitHub宝藏框架】跨平台桌面开发利器:PinnacleQt与PySide6/PyQt6实战解析
1. 为什么PinnacleQt是Python开发者的跨平台利器 第一次接触PinnacleQt是在去年开发一个医疗数据可视化工具时。当时需要在Windows和macOS上部署相同的界面,试过Electron、Flutter等方案后,最终被这个基于Qt的框架惊艳到了。它完美解决了我在Python生态中…...

在Node.js后端服务中集成Taotoken实现AI功能调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现AI功能调用 将大模型能力集成到后端服务是现代应用开发的常见需求。对于Node.js开发者而言&a…...

通过curl命令直接调用Taotoken大模型API的排错指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调用Taotoken大模型API的排错指南 对于需要在无SDK环境下进行快速测试、调试或集成的开发者而言,直接…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...