【论文笔记】Attention Prompting on Image for Large Vision-Language Models

🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: Attention Prompting on Image for Large Vision-Language Models
作者: Runpeng Yu, Weihao Yu, Xinchao Wang
发表: ECCV 2024
arXiv: https://arxiv.org/abs/2409.17143

摘要
与大型语言模型(LLMs)相比,大型视觉语言模型(LVLMs)也能接受图像作为输入,从而展现出更多有趣的涌现能力,并在各种视觉语言任务上表现出令人印象深刻的表现。
受LLMs中的文本提示启发,视觉提示已被探索以增强LVLM感知视觉信息的能力。
然而,之前的视觉提示技术仅处理视觉输入,不考虑文本查询,限制了模型遵循文本指令完成任务的能力。
为了填补这一空白,在这项工作中,我们提出了一种名为Attention Prompting on Image(API)的新提示技术,它简单地在原始输入图像上叠加一个由文本查询引导的注意力热图,从而有效地增强了LVLM在各种任务上的表现。
具体来说,我们使用类似于CLIP的辅助模型根据文本查询生成输入图像的注意力热图。
然后,热图简单地乘以原始图像的像素值,以获得LVLM的实际输入图像。
在各个视觉语言基准上的大量实验验证了我们的技术的有效性。
例如,API在MM-Vet和LLaVA-Wild基准上分别将LLaVA-1.5提高了3.8%和2.9%。
主要贡献
- 我们发现,当前的视觉提示技术严重修改输入图像,而没有考虑文本查询,限制了模型准确遵循指令的能力。
- 为了填补这一空白,我们提出了API方法,探讨如何从各种类型的VLM模型中提取有价值的归因图,并将它们作为视觉提示来提供视觉感知的线索,从而提高性能。
- 我们的实验证明了该方法在各种数据集上对广泛VLM模型的有效性。此外,我们的方法在解决幻觉问题上也已被证明是有效的。
方法

使用一个辅助的大型视觉语言模型结合输入图像和文本提示,生成一个由文本查询引导的注意力热图,再将注意力热图叠加在原始图像上。
Obtaining Attribution Map from CLIP
CLIP模型 g clip g_{\text{clip}} gclip 由一个视觉编码器和一个文本编码器组成,在隐空间中计算输入图像和文本之间的相似度 s i m ( I ^ , T ^ ) sim(\hat{I}, \hat{T}) sim(I^,T^),其中 I ^ = g clip img ( I ) \hat{I} = g_{\text{clip}}^{\text{img}}(I) I^=gclipimg(I), T ^ = g clip text ( T ) \hat{T} = g_{\text{clip}}^{\text{text}}(T) T^=gcliptext(T)。该相似度用于度量整张图像和文本之间的相关性。为了获得文本查询到每个图像patch的相关度图,我们需要对图像级别的相似度特征 I ^ \hat{I} I^ 进行分解,以此得到每个图像patch特征与文本特征 T ^ \hat{T} T^ 的相似度。
由于存在残差连接,视觉编码器的最终输出 I ^ \hat{I} I^ 实际上包括了每一层的影响。因此, I ^ \hat{I} I^ 可以表示为每一层类别标记位置值的线性组合:
I ^ = L ( [ Z cls 0 ] ) + ∑ l = 1 L L ( [ MSA l ( Z l − 1 ) ] cls ) + ∑ l = 1 L L ( [ MLP l ( Z ^ l ) ] cls ) \hat{I} = \mathcal{L}\left(\left[Z_{\text{cls}}^{0}\right]\right) + \sum_{l=1}^{L}\mathcal{L}\left(\left[\operatorname{MSA}^{l}\left(Z^{l-1}\right)\right]_{\text{cls}}\right) + \sum_{l=1}^{L}\mathcal{L}\left(\left[\operatorname{MLP}^{l}\left(\hat{Z}^{l}\right)\right]_{\text{cls}}\right) I^=L([Zcls0])+l=1∑LL([MSAl(Zl−1)]cls)+l=1∑LL([MLPl(Z^l)]cls)
L L L 表示视觉编码器中Transformer层的数量,其中 MSA \operatorname{MSA} MSA 和 MLP \operatorname{MLP} MLP 分别代表Transformer中的多头自注意力结构和多层感知器结构; L \mathcal{L} L 代表包括全连接层和Transformer结构之后计算相似度得分之前执行的归一化操作的线性变换; Z l Z^l Zl 表示第 l l l 个Transformer层的输入token序列; [ Z ] cls [Z]_\text{cls} [Z]cls 表示token序列 Z Z Z 中cls token的值。这些输出的cls token通过残差连接聚合,形成视觉编码器的输出。
在这些求和项中,MSA最后几层的输出起着决定性作用,而来自浅层MSA层输出、MLP输出以及与输入图像无关的 Z cls 0 Z^0_\text{cls} Zcls0 项的贡献可以视为对最终相似度测量的忽略不计。因此,相似度 s i m ( I ^ , T ^ ) sim(\hat{I}, \hat{T}) sim(I^,T^) 可以通过计算 T ^ \hat{T} T^ 与深层MSA的聚合输出的相似度来近似:
sim ( I ^ , T ^ ) ≈ sim ( ∑ l = L ′ L L ( [ MSA l ( Z l − 1 ) ] cls ) , T ^ ) \operatorname{sim}(\hat{I}, \hat{T}) \approx \operatorname{sim}\left(\sum_{l=L^{\prime}}^{L}\mathcal{L}\left(\left[\operatorname{MSA}^{l}\left(Z^{l-1}\right)\right]_{\text{cls}}\right), \hat{T}\right) sim(I^,T^)≈sim(l=L′∑LL([MSAl(Zl−1)]cls),T^)
其中 L ′ L^{\prime} L′ 代表预定义的起始层索引。为进一步计算文本查询对每个patch的归因,我们展开多头自注意力机制的操作:
[ MSA l ( Z l − 1 ) ] c l s = ∑ h H [ A ( l , h ) V ( l , h ) W ( l , h ) ] c l s + B l = ∑ t = 1 T [ ∑ h H A c l s , t ( l , h ) V t , : ( l , h ) W ( l , h ) + 1 H T B l ] ⏟ The MSA output corresponding to the t -th patch(token) ≜ ∑ t = 1 T η t l \begin{align*} {\left[\operatorname{MSA}^{l}\left(Z^{l-1}\right)\right]_{cls}} &= \sum_{h}^{H}\left[A^{(l, h)} V^{(l, h)} W^{(l, h)}\right]_{cls} + B^{l} \\ &= \sum_{t=1}^{T} \underbrace{\left[\sum_{h}^{H} A_{cls, t}^{(l, h)} V_{t,:}^{(l, h)} W^{(l, h)} + \frac{1}{H T} B^{l}\right]}_{\text{The MSA output corresponding to the }t\text{-th patch(token)}} \triangleq \sum_{t=1}^{T} \eta_{t}^{l} \end{align*} [MSAl(Zl−1)]cls=h∑H[A(l,h)V(l,h)W(l,h)]cls+Bl=t=1∑TThe MSA output corresponding to the t-th patch(token) [h∑HAcls,t(l,h)Vt,:(l,h)W(l,h)+HT1Bl]≜t=1∑Tηtl
在第 l l l 层中, A ( l , h ) A(l,h) A(l,h) 和 V ( l , h ) V(l,h) V(l,h) 分别是对应于第 h h h 个注意力头的注意力图和Value矩阵; W ( l , h ) W(l,h) W(l,h) 是第 l l l 层中用于合并多个注意力头的权重矩阵,对应于第 h h h 个头; B ( l ) B(l) B(l) 是第 l l l 层中用于合并多个注意力头的偏置矩阵; A c l s , t ( l , h ) A_{cls, t}^{(l, h)} Acls,t(l,h) 表示cls token对第 t t t 个token的注意力值; V t , : ( l , h ) V_{t,:}^{(l,h)} Vt,:(l,h) 表示 V ( l , h ) V(l,h) V(l,h) 的第 t t t 行; H H H 和 T T T 分别是注意力头的数量和token的数量;而值 T T T 等于patch数 P × P + 1 P \times P + 1 P×P+1。
因此,第 t t t 个patch的特征可以表示为 ψ t ≜ ∑ l = L ′ L L ( η t l ) \psi_{t}\triangleq\sum_{l=L^{\prime}}^{L}\mathcal{L}\left(\eta_{t}^{l}\right) ψt≜∑l=L′LL(ηtl),我们可以计算文本查询与第 t t t 个图像patch之间的相似性。相应地,归因图 Ψ c l s ∈ R P × P \Psi^{cls} \in \mathbb{R}^{P \times P} Ψcls∈RP×P 被定义为:
Ψ i , j c l s ≜ s i m ( ψ t , T ^ ) , where t = 1 + j + P ∗ ( i − 1 ) . \Psi^{cls}_{i,j} \triangleq sim(\psi_{t}, \hat{T}), \quad\text{where}\ t = 1 + j + P * (i - 1). Ψi,jcls≜sim(ψt,T^),where t=1+j+P∗(i−1).
通过对 cls token进行分解,我们可以识别哪些patch与查询更为相关。当查询包含特定实体时,这种方法特别有效,允许进行精确的定位。然而,在复杂的视觉问答(VQA)任务中,查询中往往没有明确提及实体,或者回答问题所涉及的逻辑和分析过程可能依赖于查询中没有明确提及的实体。为了解决这个问题,我们还定义了另一个互补归因图 Ψ c o m p \Psi^{comp} Ψcomp。该图旨在捕捉与查询具有潜在或隐含相关性的区域。
我们实验观察到,在CLIP的视觉Transformer中,查询特征 T ^ \hat{T} T^ 与最终层中除cls token外的token的相似度得分可以(反向)选择重要区域。对应图像背景或大块单色区域的patch与 T ^ \hat{T} T^ 的相似度得分显著高于代表特定实体(这些实体可能不一定出现在查询中)的token。一个可能的解释是,这些“空白”token本身缺乏有价值的信息,被Transformer视为寄存器。Transformer最初利用它们存储来自其他token的信息,随后通过注意力机制过滤和汇总这些存储的信息到cls token,以形成最终的预测。因此,与 T ^ \hat{T} T^ 具有高相似度得分的除cls token外的token,代表信息含量低的patch,可以不予考虑。我们定义互补归因图如下:
Ψ i , j c o m p ≜ 1 − s i m ( L ( Z t L ) , T ^ ) , where t = 1 + j + P ∗ ( i − 1 ) . \Psi^{comp}_{i,j} \triangleq 1 - sim(\mathcal{L}(Z^L_t), \hat{T}), \quad\text{where}\ t = 1 + j + P * (i - 1). Ψi,jcomp≜1−sim(L(ZtL),T^),where t=1+j+P∗(i−1).
Z t L Z^L_t ZtL 表示最后一个Transformer层的第 t t t 个输出token。互补归因图与相似度成反比,表明缺乏信息的patch被忽略,仅保留具有潜在相关性的patch。
因此,我们获得了两张相互补充的归因图: Ψ c l s \Psi^{cls} Ψcls 明确识别与查询实体直接相关的区域,但可能遗漏一些可能相关的区域。 Ψ c o m p \Psi^{comp} Ψcomp 同样识别所有可能相关的区域,但缺乏特异性,无法突出显示与查询实体直接相关的区域。
通过以下操作整合两个归因图,我们得到CLIP的最终归因图:
Ψ i , j ≜ Ψ i , j c l s + Ψ i , j c o m p − Ψ i , j c l s ∗ Ψ i , j c o m p \Psi_{i,j} \triangleq \Psi^{cls}_{i,j} + \Psi^{comp}_{i,j} - \Psi^{cls}_{i,j} * \Psi^{comp}_{i,j} Ψi,j≜Ψi,jcls+Ψi,jcomp−Ψi,jcls∗Ψi,jcomp
这种整合可以被视为一种soft OR操作。
Obtaining Attribution Map from LLaVA
LLaVA模型是一种MLLM,它利用多头自注意力机制从文本查询和图像patch中提取信息,预测后续的token。给定长度为 N N N 的文本token序列 Z text = { Z t text } t = 1 N Z^\text{text} = {\{Z^\text{text}_t \}}_{t=1}^{N} Ztext={Zttext}t=1N,以及长度为 P × P P \times P P×P 的图像token序列 Z img = { Z t img } t = 1 P × P Z^\text{img} = {\{Z^\text{img}_t \}}_{t=1}^{P \times P} Zimg={Ztimg}t=1P×P,LLaVA生成一个长度为 M M M 的新token序列 Z out = { Z t out } t = 1 M Z^\text{out} = {\{Z^\text{out}_t \}}_{t=1}^{M} Zout={Ztout}t=1M。我们直接使用token Z t out Z^\text{out}_t Ztout 与每个图像token之间的注意力权重作为 Z t out Z^\text{out}_t Ztout 对该图像patch的归因。类似于CLIP模型的策略,我们选择深层的注意力图来提取注意力权重。最终的归因图在整个生成的token序列和所有注意力头之间平均。形式上,归因图 Ψ \Psi Ψ 定义为:
Ψ i , j ≜ 1 M H ∑ m = 1 M ∑ h = 1 H A m , t ( L ˉ , h ) , where t = j + P ∗ ( i − 1 ) . \Psi_{i, j} \triangleq \frac{1}{M H} \sum_{m=1}^{M} \sum_{h=1}^{H} A_{m, t}^{(\bar{L}, h)}, \quad\text{where}\ t = j + P * (i - 1). Ψi,j≜MH1m=1∑Mh=1∑HAm,t(Lˉ,h),where t=j+P∗(i−1).
在定义中, A ( L ˉ , h ) A^{(\bar{L}, h)} A(Lˉ,h) 是第 L ˉ \bar{L} Lˉ 层的第 h h h 个头对应的注意力图,其中 L ˉ \bar{L} Lˉ 是一个超参数集合;为了符号的简洁性,此处 A ( L ˉ , h ) A^{(\bar{L}, h)} A(Lˉ,h) 是整个注意力图的一个子矩阵,仅包括 Z out Z^\text{out} Zout 和 Z img Z^\text{img} Zimg 之间的交叉注意力; A m , t ( L ˉ , h ) A_{m, t}^{(\bar{L}, h)} Am,t(Lˉ,h) 仍然表示从第 m m m 个token到第 t t t 个token的注意力值。
From Token Space to Pixel Space
Ψ ∈ R P × P \Psi \in \mathbb{R}^{P \times P} Ψ∈RP×P 的归因图在token空间中生成。我们首先将其调整回像素空间以获得原始热图 Φ ^ ≜ Resize ( Ψ ) \hat{\Phi} \triangleq \operatorname{Resize}(\Psi) Φ^≜Resize(Ψ)。由于patch的方形形状, Φ ^ \hat{\Phi} Φ^ 中的掩码模式也呈矩形。为了减轻矩形掩码模式与物体不规则形状不匹配的问题,我们应用均值滤波器以获得最终热图 Φ ≜ M e a n k ( Φ ^ ) \Phi \triangleq \operatorname{Mean_k}(\hat{\Phi}) Φ≜Meank(Φ^),其中 k k k 是滤波器的核大小。然后,将最终热图 Φ \Phi Φ 通过将其用作 alpha 通道叠加到原始图像上,得到标注后的最终图像 I a I^a Ia。
实验
主实验

与先前针对各种LVLMs的文本和视觉提示方法的比较。
消融实验

关于辅助VLM Scale的消融实验。

关于均值滤波器核大小的消融实验。

关于用于归因图提取的Transformer层的消融实验

本文方法与文本self-reflection方法的比较及结合。

本文方法在幻觉数据集上的表现。
总结
在这项工作中,我们介绍了一种名为Attention Prompting on Image(API)的新型视觉提示技术,该技术结合了一个辅助的LVLM,根据文本查询在图像上生成注意力热图。
我们广泛的实验证明了我们的提示方法在不同基准上对不同LVLM的优势。
此外,我们的方法为使用视觉信号进行LVLM集成和LVLM自我反思提供了新的见解。
相关文章:
【论文笔记】Attention Prompting on Image for Large Vision-Language Models
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: Attention Prompting on I…...

VScode设置系统界面字体
现象: 系统界面字体太大,导致菜单栏字体显示不全,每次使用都要先点然后才能打开终端和帮助 缩小字体应该就可以实现全部都看到的效果 步骤 Window: Zoom Level 调整所有窗口的默认缩放级别。大于“0”的每个增量(例如“1”&…...

Java中常见的异常类型
1、Exception和Error有什么区别? 首先Exception和Error都是继承于Throwable类,在Java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。 Except…...
)
Java学习Day58:相声二人组!(项目统计数据Excel图表导出)
<!DOCTYPE html> <html xmlns"http://www.w3.org/1999/html"><head><!-- 页面meta --><meta charset"utf-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><title>瑞通健康</tit…...

springboot 自动装配和bean注入原理及实现
装配:创建bean,并加入IOC容器。 注入:创建bean之间的依赖关系。 1、类自动装配 SpringBoot 自动装配使得开发人员可以轻松地搭建、配置和运行应用程序,而无需手动管理大部分的 bean 和配置。 Spring Boot 的自动装配机制与模块…...
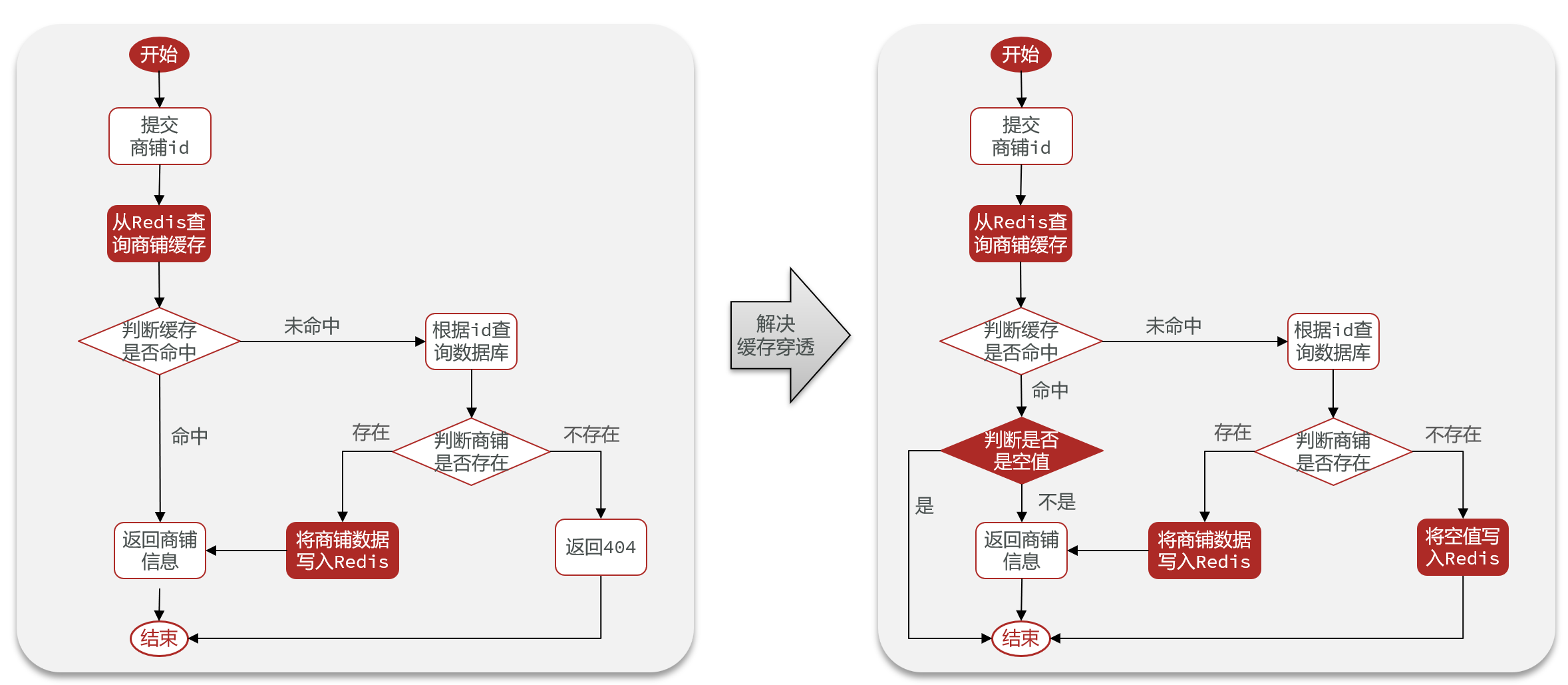
解决Redis缓存穿透(缓存空对象、布隆过滤器)
文章目录 背景代码实现前置实体类常量类工具类结果返回类控制层 缓存空对象布隆过滤器结合两种方法 背景 缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库 常见的解决方案有两种,分别…...
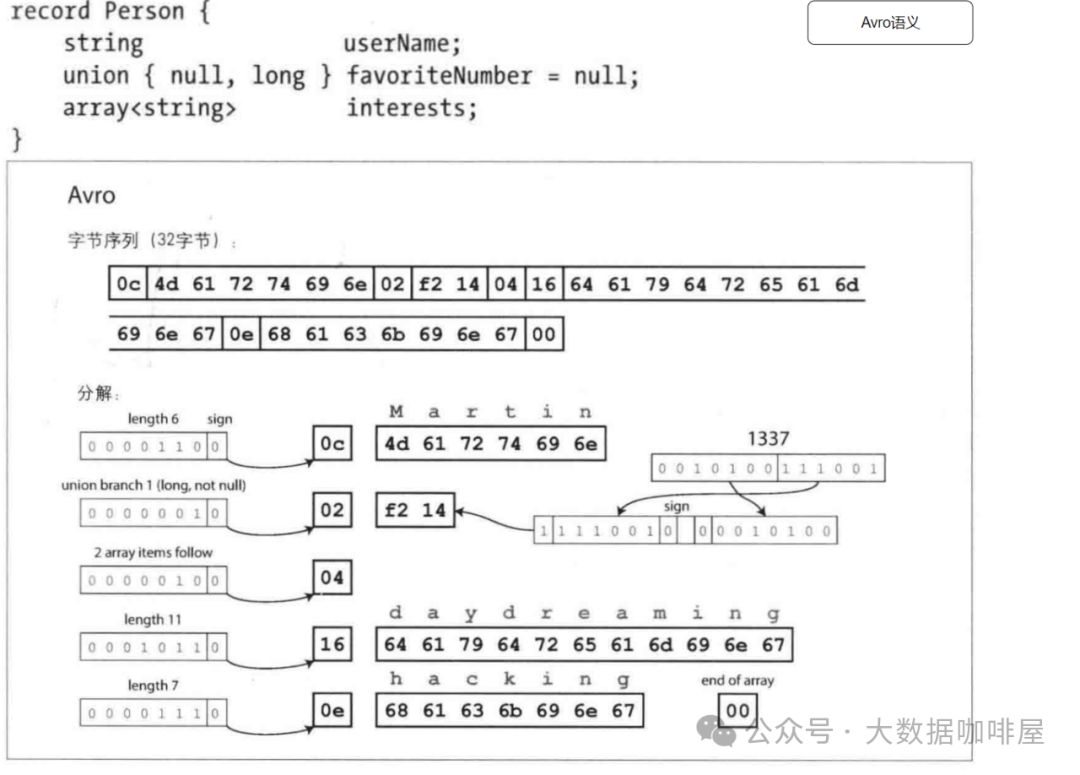
初探Flink的序列化
Flink中的序列化应用场景 程序通常使用(至少)两种不同的数据表示形式[2]: 1. 在内存中,数据保存在对象、结构体、列表、数组、哈希表和树等结构中。 2. 将数据写入文件或通过网络发送时,必须将其序列化为字节序列。 从内存中的表示到字节序列…...

QT 机器视觉 (3. 虚拟相机SDK、测试工具)
本专栏从实际需求场景出发详细还原、分别介绍大型工业化场景、专业实验室场景、自动化生产线场景、各种视觉检测物体场景介绍本专栏应用场景 更适合涉及到视觉相关工作者、包括但不限于一线操作人员、现场实施人员、项目相关维护人员,希望了解2D、3D相机视觉相关操作…...
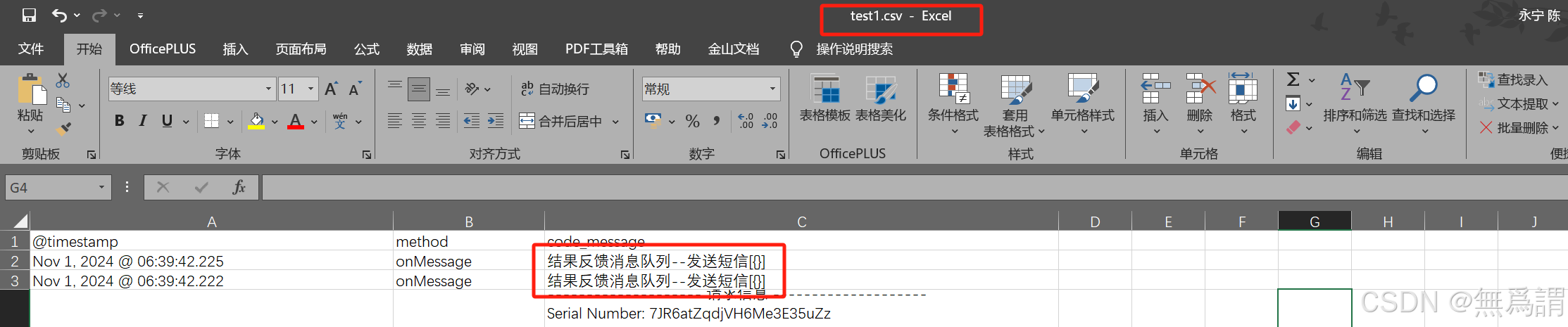
1分钟解决Excel打开CSV文件出现乱码问题
一、编码问题 1、不同编码格式 CSV 文件有多种编码格式,如 UTF - 8、UTF - 16、ANSI 等。如果 CSV 文件是 UTF - 8 编码,而 Excel 默认使用的是 ANSI 编码打开,就可能出现乱码。例如,许多从网络应用程序或非 Windows 系统生成的 …...

基于SpringBoot+Vue的仓库管理系统【前后端分离】
基于SpringBootVue的仓库管理系统设计与实现 摘要 仓库管理系统在现代企业物流中具有重要作用,能够有效提高库存管理效率,优化资源配置。本系统采用Spring Boot作为后端框架,Vue作为前端框架,通过前后端分离的开发模式构建一个现代…...

vue和django接口联调
vue访问服务端接口 配置跨域 前端跨域 打开vite.config.js,在和resolve同级的地方添加配置。 proxy代表代理的意思 "/api"是以/api开头的路径走这个配置 target代表目标 changeOrigin: true,是开启跨域请求 rewrite是编辑路径。 (path) > pa…...

2-141 怎么实现ROI-CS压缩感知核磁成像
怎么实现ROI-CS压缩感知核磁成像,这个案例告诉你。基于matlab的ROI-CS压缩感知核磁成像。ROI指在图像中预先定义的特定区域或区域集合,选择感兴趣的区域,通过减少信号重建所需的数据来缩短信号采样时间,减少计算量,并在…...

开源库 FloatingActionButton
开源库FloatingActionButton Github:https://github.com/Clans/FloatingActionButton 这个库是在前面这个库android-floating-action-button的基础上修改的,增加了一些更强大和实用的特性。 特性: Android 5.0 以上点击会有水波纹效果 可以选择自定义…...

技术选型不当对项目的影响与补救措施
在项目管理中,初期技术选型与项目需求不匹配的情况并不罕见,这可能导致项目延误、成本增加和最终成果的不理想。补救的关键措施包括:重新评估技术选型、加强团队沟通、实施有效的需求管理以及建立持续的反馈机制。其中,重新评估技…...

Spring的核心类: BeanFactory, ApplicationContext 笔记241103
Spring的核心类: BeanFactory, ApplicationContext, ConfigurableApplicationContext, WebApplicationContext, WebServerApplicationContext, ClassPathXmlApplicationContext, FileSystemXmlApplicationContext, XmlWebApplicationContext, AnnotationConfigServletWebServer…...

UE5移动端主要对象生命周期及监听
1、GameInstance 1、首先加载GameInstance,全局唯一,切换Map也是唯一的,用于做一些全局操作,比如监听Map加载,监听App进入前台、退出后台 // Fill out your copyright notice in the Description page of Project Settings.#include "Core/Base/MyGameInstance.h&q…...

LLM | 论文精读 | CVPR | SelTDA:将大型视觉语言模型应用于数据匮乏的视觉问答任务
论文标题:How to Specialize Large Vision-Language Models to Data-Scarce VQA Tasks? Self-Train on Unlabeled Images! 作者:Zaid Khan, Vijay Kumar BG, Samuel Schulter, Xiang Yu, Yun Fu, Manmohan Chandraker 期刊:CVPR 2023 DOI…...

kafka里的consumer 是推还是拉?
大家好,我是锋哥。今天分享关于【kafka里的consumer 是推还是拉?】面试题?希望对大家有帮助; kafka里的consumer 是推还是拉? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在Kafka中,消费者&…...

针对物联网边缘设备基于EIT的手部手势识别的1D CNN效率增强的组合模型压缩方法
论文标题:Combinative Model Compression Approach for Enhancing 1D CNN Efficiency for EIT-based Hand Gesture Recognition on IoT Edge Devices 中文标题:针对物联网边缘设备基于EIT的手部手势识别的1D CNN效率增强的组合模型压缩方法 作者信息&a…...

商品满减、限时活动、折扣活动的计算最划算 golang
可以对商品的不同活动(如满减、限时价和折扣)进行分组,并在购物车中显示各个活动标签下的最优价格组合。以下代码将商品按活动类别进行分组计算,并输出在购物车中的显示信息。 package mainimport ("fmt""math&qu…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

构建个人代码仓库:提升开发效率的实践指南
1. 项目概述:一个面向21世纪开发者的代码仓库最近在GitHub上看到一个挺有意思的项目,叫“21st-dev/1code”。光看这个名字,你可能觉得有点抽象,但点进去之后,我发现它其实是一个挺有想法的代码仓库。这个项目没有复杂的…...

数据分析师能力展示:从项目构建到报告呈现的完整指南
1. 项目概述:一个数据分析师的能力展示平台最近在GitHub上看到一个挺有意思的项目,叫“dataanalyst-showcase”。光看名字,你可能会觉得这又是一个数据科学项目合集,但点进去仔细研究后,我发现它的定位非常精准——它不…...

Linux内核C11升级:从C89到现代C语言的演进与挑战
1. 项目概述:一次内核语言的“心脏移植”手术最近Linux内核社区放出了一个重磅消息,未来计划将内核的C语言标准从使用了二十多年的C89/C90,升级到C11。这个消息一出,在开发者圈子里激起的讨论,不亚于当年从Python 2迁移…...
:为什么它突然支持Nastaliq音素映射?)
ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射?
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射? ElevenLabs于2024年Q2悄然上线乌尔都语&#…...

提示工程实战:从核心模式到高级技巧的AI交互优化指南
1. 项目概述:从代码仓库到提示工程实战指南最近在GitHub上看到一个名为“SKY-lv/prompt-engineer”的仓库,点进去一看,发现这不仅仅是一个简单的代码集合,更像是一位资深从业者(SKY-lv)精心整理的提示工程实…...

基于CircuitPython的Fruit Jam OS:在RP2350上构建复古微型计算机系统
1. 项目概述:当复古计算精神遇见现代微控制器如果你和我一样,对早期个人计算机那种开机即用、一切尽在掌控的纯粹体验抱有怀念,同时又痴迷于现代开源硬件带来的无限可能,那么Fruit Jam OS绝对是一个会让你眼前一亮的项目。它不是一…...

嵌入式开发内存优化实战:裁剪IRLib2红外库,释放微控制器Flash空间
1. 项目概述:当红外遥控遇上内存焦虑红外遥控,这个听起来有点“复古”的技术,至今仍是智能家居、玩具和各类嵌入式设备里最经济可靠的无线通信方案之一。它的原理不复杂:用一个特定频率(通常是38kHz)的载波…...