YOLOv6-4.0部分代码阅读笔记-effidehead_fuseab.py
effidehead_fuseab.py
yolov6\models\heads\effidehead_fuseab.py
目录
effidehead_fuseab.py
1.所需的库和模块
2.class Detect(nn.Module):
3.def build_effidehead_layer(channels_list, num_anchors, num_classes, reg_max=16, num_layers=3):
1.所需的库和模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from yolov6.layers.common import *
from yolov6.assigners.anchor_generator import generate_anchors
from yolov6.utils.general import dist2bbox
2.class Detect(nn.Module):
class Detect(nn.Module):# 高效的分离头,用于融合锚框分支。'''Efficient Decoupled Head for fusing anchor-base branches.'''# 1.num_classes=80 :目标检测任务中的类别数,默认为80。# 2.anchors=None :锚点的配置,用于目标检测中的边界框定位。# 3.num_layers=3 :检测头中包含的层数,默认为3。# 4.inplace=True :是否使用 inplace 操作以减少内存使用。# 5.head_layers=None :检测头的层结构,这是一个包含多个模块的列表。# 6.use_dfl=True :是否使用分布式焦点损失(Distributed Focal Loss)。# 7.reg_max=16 :回归的最大值,用于目标检测中的回归任务。def __init__(self, num_classes=80, anchors=None, num_layers=3, inplace=True, head_layers=None, use_dfl=True, reg_max=16): # detection layer 检测层super().__init__()# 确保 head_layers 参数不为空,因为检测头需要这些层来构建网络。assert head_layers is not Noneself.nc = num_classes # number of classes 类别数量self.no = num_classes + 5 # number of outputs per anchor 每个锚点的输出数量self.nl = num_layers # number of detection layers 检测层数# 检查 anchors 是否为列表或元组。if isinstance(anchors, (list, tuple)):# 如果 anchors 是列表或元组,计算每个特征图上的锚点数量。这里假设每个特征图上的锚点是成对出现的,所以除以2。self.na = len(anchors[0]) // 2else:# 如果 anchors 不是列表或元组,直接将 anchors 赋值给 self.na 。self.na = anchors# 创建一个包含 num_layers 个元素的列表,每个元素都是一个形状为 (1,) 的零张量。这个网格用于在特征图上定义锚点的位置。self.grid = [torch.zeros(1)] * num_layers# 设置锚点的先验概率,通常用于目标检测中的类别预测。self.prior_prob = 1e-2# 根据传入的参数 inplace 设置是否使用 inplace 操作。self.inplace = inplace# 根据检测层的数量设置步长列表。步长决定了特征图上每个单元格对应原始图像的大小。stride = [8, 16, 32] if num_layers == 3 else [8, 16, 32, 64] # strides computed during build 构建期间计算的步长# 将步长列表转换为 PyTorch 张量,并存储在 self.stride 中。self.stride = torch.tensor(stride)# 根据传入的参数 use_dfl 设置是否使用 DFL。self.use_dfl = use_dfl# 设置回归任务中的最大值。self.reg_max = reg_max# 创建一个卷积层,用于将 self.reg_max + 1 个通道的输入映射到单个通道的输出,没有偏置项。self.proj_conv = nn.Conv2d(self.reg_max + 1, 1, 1, bias=False)# 设置网格单元的偏移量。self.grid_cell_offset = 0.5# 设置网格单元的大小。self.grid_cell_size = 5.0# 将传入的锚点 anchors 转换为张量,并除以步长张量 self.stride 来调整锚点的大小。# 然后,将结果重塑为 (self.nl, self.na, 2) 的形状,其中 self.nl 是检测层的数量, self.na 是每个特征图上的锚点数量,2 表示每个锚点的宽度和高度。self.anchors_init= ((torch.tensor(anchors) / self.stride[:,None])).reshape(self.nl, self.na, 2)# Init decouple head 初始化解耦头self.stems = nn.ModuleList()self.cls_convs = nn.ModuleList()self.reg_convs = nn.ModuleList()self.cls_preds = nn.ModuleList()self.reg_preds = nn.ModuleList()# 这个列表用于存储融合锚框分支的类别预测层,特别是在使用锚框融合技术时。self.cls_preds_ab = nn.ModuleList()# 这个列表用于存储融合锚框分支的边界框回归预测层,同样用于处理锚框融合。self.reg_preds_ab = nn.ModuleList()# Efficient decoupled head layers 高效解耦的头部层for i in range(num_layers):idx = i*7self.stems.append(head_layers[idx])self.cls_convs.append(head_layers[idx+1])self.reg_convs.append(head_layers[idx+2])self.cls_preds.append(head_layers[idx+3])self.reg_preds.append(head_layers[idx+4])self.cls_preds_ab.append(head_layers[idx+5])self.reg_preds_ab.append(head_layers[idx+6])def initialize_biases(self):for conv in self.cls_preds:b = conv.bias.view(-1, )b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob))conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)w = conv.weightw.data.fill_(0.)conv.weight = torch.nn.Parameter(w, requires_grad=True)for conv in self.cls_preds_ab:b = conv.bias.view(-1, )b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob))conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)w = conv.weightw.data.fill_(0.)conv.weight = torch.nn.Parameter(w, requires_grad=True)for conv in self.reg_preds:b = conv.bias.view(-1, )b.data.fill_(1.0)conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)w = conv.weightw.data.fill_(0.)conv.weight = torch.nn.Parameter(w, requires_grad=True)for conv in self.reg_preds_ab:b = conv.bias.view(-1, )b.data.fill_(1.0)conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)w = conv.weightw.data.fill_(0.)conv.weight = torch.nn.Parameter(w, requires_grad=True)# 初始化 self.proj 参数# torch.linspace(0, self.reg_max, self.reg_max + 1) :这个函数生成一个一维张量,包含从0到 self.reg_max (包括 self.reg_max )的等间隔值,总共有 self.reg_max + 1 个值。# nn.Parameter :将这个张量转换为一个参数,这样它就可以被包含在模型的参数列表中,但在优化过程中不会被更新,因为 requires_grad=False 。# self.proj :这个参数可能用于在回归任务中定义一个投影或者映射,例如,它可以用于将预测的边界框坐标映射到一个特定的范围内。self.proj = nn.Parameter(torch.linspace(0, self.reg_max, self.reg_max + 1), requires_grad=False)# 初始化 self.proj_conv.weight 权重# self.proj.view([1, self.reg_max + 1, 1, 1]) :将 self.proj 参数重塑为一个四维张量,形状为 [1, self.reg_max + 1, 1, 1] ,这通常是为了匹配卷积层权重的形状。# .clone() :创建 self.proj 的一个副本,以避免直接修改原始参数。# .detach() :从计算图中分离出这个张量,这样它就不会在梯度计算中被考虑。# nn.Parameter :将这个张量转换为一个参数,这样它就可以被包含在模型的参数列表中,但在优化过程中不会被更新,因为 requires_grad=False 。# self.proj_conv.weight :这个权重被设置为上述张量,用于 self.proj_conv 卷积层。由于 requires_grad=False ,这个权重在训练过程中不会被更新。self.proj_conv.weight = nn.Parameter(self.proj.view([1, self.reg_max + 1, 1, 1]).clone().detach(),requires_grad=False)# 这个方法同时处理了基于锚点(anchor-based)和无锚点(anchor-free)的分支,生成类别预测和边界框回归的输出。def forward(self, x):# 它处理模型在训练模式下的行为。if self.training:# 获取输入数据 x 的设备信息(CPU或GPU)。device = x[0].device# 分别存储无锚点分支的类别预测分数和边界框回归结果。cls_score_list_af = []reg_dist_list_af = []# 分别存储基于锚点分支的类别预测分数和边界框回归结果。cls_score_list_ab = []reg_dist_list_ab = []# 循环遍历每个检测层, self.nl 是检测层的数量。for i in range(self.nl):# 获取当前特征图的批次大小、通道数、高度和宽度。b, _, h, w = x[i].shape# 计算当前特征图的总单元格数。l = h * w# 将输入 x 通过第 i 个茎(stem)模块进行处理。x[i] = self.stems[i](x[i])# 分别存储类别预测和边界框回归的特征图。cls_x = x[i]reg_x = x[i]# 通过类别预测卷积层进一步处理特征图。cls_feat = self.cls_convs[i](cls_x)# 通过边界框回归卷积层进一步处理特征图。reg_feat = self.reg_convs[i](reg_x)#anchor_base 锚框# 这段代码处理了基于锚点(anchor-based)分支的类别预测和边界框回归输出。# 通过第 i 个检测层的类别预测层 self.cls_preds_ab[i] 对类别特征 cls_feat 进行处理,得到类别预测的中间结果 cls_output_ab 。这个结果通常是一个未经激活函数处理的原始分数,表示每个锚点属于各个类别的可能性。cls_output_ab = self.cls_preds_ab[i](cls_feat)# 通过第 i 个检测层的边界框回归层 self.reg_preds_ab[i] 对边界框特征 reg_feat 进行处理,得到边界框回归的中间结果 reg_output_ab 。这个结果通常包含边界框的位置和尺寸信息,通常是相对于锚点的偏移量。reg_output_ab = self.reg_preds_ab[i](reg_feat)# 对类别预测结果应用 Sigmoid 激活函数,将输出转换为概率值。cls_output_ab = torch.sigmoid(cls_output_ab)# 将类别预测结果重塑为形状为 [b, self.na, -1, h, w] 的张量,其中 b 是批次大小, self.na 是每个特征图上的锚点数量, -1 表示自动计算的维度, h 和 w 分别是特征图的高度和宽度。# cls_output_ab.permute(0,1,3,4,2) :置换张量维度,将类别预测结果的维度顺序调整为 [b, self.na, h, w, -1] 。cls_output_ab = cls_output_ab.reshape(b, self.na, -1, h, w).permute(0,1,3,4,2)# 将置换后的张量在第二和第三维度上展平,并添加到 cls_score_list_ab 列表中。cls_score_list_ab.append(cls_output_ab.flatten(1,3))# 将边界框回归结果重塑为形状为 [b, self.na, -1, h, w] 的张量。# reg_output_ab.permute(0,1,3,4,2) :置换张量维度,将边界框回归结果的维度顺序调整为 [b, self.na, h, w, -1] 。reg_output_ab = reg_output_ab.reshape(b, self.na, -1, h, w).permute(0,1,3,4,2)# 对边界框回归结果的宽度和高度进行调整。# reg_output_ab[..., 2:4].sigmoid() :对宽度和高度的预测值应用 Sigmoid 激活函数。# * 2 :将激活后的值乘以 2。# ** 2 :将乘以 2 后的值进行平方。# self.anchors_init[i].reshape(1, self.na, 1, 1, 2).to(device) :将第 i 个检测层的锚点初始化值重塑并移动到相应的设备上。# 最后,将调整后的宽度和高度值乘以对应的锚点值。reg_output_ab[..., 2:4] = ((reg_output_ab[..., 2:4].sigmoid() * 2) ** 2 ) * (self.anchors_init[i].reshape(1, self.na, 1, 1, 2).to(device))# 将置换后的边界框回归结果在第二和第三维度上展平,并添加到 reg_dist_list_ab 列表中。reg_dist_list_ab.append(reg_output_ab.flatten(1,3))#anchor_free 无锚框# 这段代码处理了无锚点(anchor-free)分支的类别预测和边界框回归输出。# 这一行通过第 i 个检测层的类别预测层 self.cls_preds[i] 对类别特征 cls_feat 进行处理,得到类别预测的中间结果 cls_output_af 。这个结果通常是一个未经激活函数处理的原始分数,表示每个位置属于各个类别的可能性。cls_output_af = self.cls_preds[i](cls_feat)# 这一行通过第 i 个检测层的边界框回归层 self.reg_preds[i] 对边界框特征 reg_feat 进行处理,得到边界框回归的中间结果 reg_output_af 。这个结果通常包含边界框的位置和尺寸信息。reg_output_af = self.reg_preds[i](reg_feat)# 对类别预测结果应用 Sigmoid 激活函数,将输出转换为概率值,范围在0到1之间。cls_output_af = torch.sigmoid(cls_output_af)# cls_output_af.flatten(2) :将类别预测结果在第二维度(类别维度)上展平,使得每个位置的类别预测分数连续排列。# permute((0, 2, 1)) :置换张量维度,将批次维度(0)、类别维度(2)和空间维度(1)的顺序进行调整,以符合后续处理的需要。# append :将整理后的类别预测结果添加到 cls_score_list_af 列表中。cls_score_list_af.append(cls_output_af.flatten(2).permute((0, 2, 1)))# reg_output_af.flatten(2) :将边界框回归结果在第二维度(边界框参数维度)上展平,使得每个位置的边界框回归参数连续排列。# permute((0, 2, 1)) :置换张量维度,将批次维度(0)、边界框参数维度(2)和空间维度(1)的顺序进行调整。# append :将整理后的边界框回归结果添加到 reg_dist_list_af 列表中。reg_dist_list_af.append(reg_output_af.flatten(2).permute((0, 2, 1)))# 沿着第二维度拼接基于锚点的类别预测结果。cls_score_list_ab = torch.cat(cls_score_list_ab, axis=1)# 沿着第二维度拼接基于锚点的边界框回归结果。reg_dist_list_ab = torch.cat(reg_dist_list_ab, axis=1)# 沿着第二维度拼接无锚点的类别预测结果。cls_score_list_af = torch.cat(cls_score_list_af, axis=1)# 沿着第二维度拼接无锚点的边界框回归结果。reg_dist_list_af = torch.cat(reg_dist_list_af, axis=1)# 在 YOLO 模型中, cls , reg , obj 代表的是三个不同的预测组成部分,对应的损失函数如下:# cls :这代表类别预测(classification)。对应的损失是类别预测损失( loss_cls )。这个损失计算的是模型预测的类别与真实类别之间的差异。它使用的是二元交叉熵损失( BCE Loss )。# reg :这代表边界框回归(bounding box regression)。对应的损失是IoU损失(loss_iou)。这个损失计算的是模型预测的边界框与真实边界框之间的交并比(IoU)差异。这里的交并比是通过IoU损失函数计算得出的。# obj :这代表目标存在概率(objectness)。对应的损失是对象存在概率损失(loss_obj)。这个损失计算的是模型预测的目标存在概率与真实存在概率之间的差异。这也是用二元交叉熵损失(BCE Loss)计算的。# 1. x : 这是经过每个检测层处理后的特征图列表。这些特征图可能用于后续的层或者用于其他目的,比如特征融合。# 2. cls_score_list_ab : 这是基于锚点分支的类别预测分数列表。它包含了每个检测层的类别预测结果,这些结果已经经过激活函数处理并整理成特定的形状。# 3. reg_dist_list_ab : 这是基于锚点分支的边界框回归结果列表。它包含了每个检测层的边界框回归结果,这些结果已经根据锚点信息调整过。# 4. cls_score_list_af : 这是无锚点分支的类别预测分数列表。它包含了每个检测层的类别预测结果,这些结果已经经过激活函数处理并整理成特定的形状。# 5. reg_dist_list_af : 这是无锚点分支的边界框回归结果列表。它包含了每个检测层的边界框回归结果。return x, cls_score_list_ab, reg_dist_list_ab, cls_score_list_af, reg_dist_list_af# 这段代码是 Detect 类的 forward 方法中处理推理(evaluation)模式的部分。在推理模式下,模型使用前向传播得到的预测结果来生成目标的类别分数和边界框。else:device = x[0].device# 这两个列表用于存储无锚点(anchor-free)分支的 类别预测分数 和 边界框回归结果 。cls_score_list_af = []reg_dist_list_af = []# 循环遍历每个检测层, self.nl 是检测层的数量。for i in range(self.nl):# 获取当前特征图的批次大小 b 、通道数、高度 h 和宽度 w 。b, _, h, w = x[i].shape# 计算当前特征图的总单元格数 l 。l = h * w# 将输入 x 的第 i 个元素通过第 i 个茎(stem)模块进行处理,以提取特征。x[i] = self.stems[i](x[i])# 分别存储类别预测和边界框回归的特征图。cls_x = x[i]reg_x = x[i]# 通过类别预测卷积层 self.cls_convs[i] 进一步处理类别预测特征图 cls_x ,得到类别特征 cls_feat 。cls_feat = self.cls_convs[i](cls_x)# 通过边界框回归卷积层 self.reg_convs[i] 进一步处理边界框回归特征图 reg_x ,得到边界框特征 reg_feat 。reg_feat = self.reg_convs[i](reg_x)#anchor_free 无锚框# 通过第 i 个检测层的类别预测层 self.cls_preds[i] 对类别特征 cls_feat 进行处理,得到类别预测的中间结果 cls_output_af 。cls_output_af = self.cls_preds[i](cls_feat)# 通过第 i 个检测层的边界框回归层 self.reg_preds[i] 对边界框特征 reg_feat 进行处理,得到边界框回归的中间结果 reg_output_af 。reg_output_af = self.reg_preds[i](reg_feat)# 检查是否使用分布式焦点损失。if self.use_dfl:# 将边界框回归结果重塑并置换维度,以适应 DFL 的计算。reg_output_af = reg_output_af.reshape([-1, 4, self.reg_max + 1, l]).permute(0, 2, 1, 3)# F.softmax(x,dim)# x :指的是输入矩阵。# dim :指的是归一化的方式,如果为0是对列做归一化,1是对行做归一化。# 对边界框回归结果应用 Softmax 函数,然后通过投影卷积层 self.proj_conv 进行处理。reg_output_af = self.proj_conv(F.softmax(reg_output_af, dim=1))# 对类别预测结果应用 Sigmoid 激活函数,将输出转换为概率值。cls_output_af = torch.sigmoid(cls_output_af)# 将类别预测结果重塑为形状为 [b, self.nc, l] 的张量,并添加到 cls_score_list_af 列表中。cls_score_list_af.append(cls_output_af.reshape([b, self.nc, l]))# 将边界框回归结果重塑为形状为 [b, 4, l] 的张量,并添加到 reg_dist_list_af 列表中。reg_dist_list_af.append(reg_output_af.reshape([b, 4, l]))# 将所有检测层的类别预测分数沿着最后一个维度拼接起来,并置换维度,以便得到形状为 [b, self.nc, num_anchors] 的张量。cls_score_list_af = torch.cat(cls_score_list_af, axis=-1).permute(0, 2, 1)# 将所有检测层的边界框回归结果沿着最后一个维度拼接起来,并置换维度,以便得到形状为 [b, 4, num_anchors] 的张量。reg_dist_list_af = torch.cat(reg_dist_list_af, axis=-1).permute(0, 2, 1)#anchor_free 无锚框# def generate_anchors(feats, fpn_strides, grid_cell_size=5.0, grid_cell_offset=0.5, device='cpu', is_eval=False, mode='af'):# -> 根据特征生成锚点。 -> return anchor_points, stride_tensor / return anchors, anchor_points, num_anchors_list, stride_tensor# 调用 generate_anchors 函数根据特征图 x 、步长 self.stride 、网格单元大小 self.grid_cell_size 、网格单元偏移量 self.grid_cell_offset 和设备信息生成锚点 anchor_points_af 和步长张量 stride_tensor_af 。anchor_points_af, stride_tensor_af = generate_anchors(x, self.stride, self.grid_cell_size, self.grid_cell_offset, device=x[0].device, is_eval=True, mode='af')# def dist2bbox(distance, anchor_points, box_format='xyxy'): -> 将距离(ltrb)转换为盒子(xywh或xyxy)。 -> return bbox# 调用 dist2bbox 函数将边界框回归结果 reg_dist_list_af 和锚点 anchor_points_af 转换为边界框坐标 pred_bboxes_af ,格式为 xywh (中心点坐标加上宽度和高度)。pred_bboxes_af = dist2bbox(reg_dist_list_af, anchor_points_af, box_format='xywh')# 将边界框坐标乘以步长张量 stride_tensor_af ,将它们从特征图空间转换到原始图像空间。pred_bboxes_af *= stride_tensor_af# 将无锚点分支的预测边界框设置为最终的预测结果。pred_bboxes = pred_bboxes_af# 将无锚点分支的类别预测分数设置为最终的类别预测分数。cls_score_list = cls_score_list_af# 返回最终的检测结果。# torch.cat([...], axis=-1) :将预测的边界框 pred_bboxes 、一个全为1的张量(表示置信度)、类别预测分数 cls_score_list 沿着最后一个维度拼接起来。# 返回的张量形状为 [b, num_anchors, 5] ,其中最后一个维度包含了边界框坐标 (x, y, w, h) 、置信度和类别分数。return torch.cat([pred_bboxes,torch.ones((b, pred_bboxes.shape[1], 1), device=pred_bboxes.device, dtype=pred_bboxes.dtype),cls_score_list],axis=-1)3.def build_effidehead_layer(channels_list, num_anchors, num_classes, reg_max=16, num_layers=3):
def build_effidehead_layer(channels_list, num_anchors, num_classes, reg_max=16, num_layers=3):chx = [6, 8, 10] if num_layers == 3 else [8, 9, 10, 11]head_layers = nn.Sequential(# stem0ConvBNSiLU(in_channels=channels_list[chx[0]],out_channels=channels_list[chx[0]],kernel_size=1,stride=1),# cls_conv0ConvBNSiLU(in_channels=channels_list[chx[0]],out_channels=channels_list[chx[0]],kernel_size=3,stride=1),# reg_conv0ConvBNSiLU(in_channels=channels_list[chx[0]],out_channels=channels_list[chx[0]],kernel_size=3,stride=1),# cls_pred0_afnn.Conv2d(in_channels=channels_list[chx[0]],out_channels=num_classes,kernel_size=1),# reg_pred0_afnn.Conv2d(in_channels=channels_list[chx[0]],out_channels=4 * (reg_max + 1),kernel_size=1),# cls_pred0_3abnn.Conv2d(in_channels=channels_list[chx[0]],out_channels=num_classes * num_anchors,kernel_size=1),# reg_pred0_3abnn.Conv2d(in_channels=channels_list[chx[0]],out_channels=4 * num_anchors,kernel_size=1),# stem1ConvBNSiLU(in_channels=channels_list[chx[1]],out_channels=channels_list[chx[1]],kernel_size=1,stride=1),# cls_conv1ConvBNSiLU(in_channels=channels_list[chx[1]],out_channels=channels_list[chx[1]],kernel_size=3,stride=1),# reg_conv1ConvBNSiLU(in_channels=channels_list[chx[1]],out_channels=channels_list[chx[1]],kernel_size=3,stride=1),# cls_pred1_afnn.Conv2d(in_channels=channels_list[chx[1]],out_channels=num_classes,kernel_size=1),# reg_pred1_afnn.Conv2d(in_channels=channels_list[chx[1]],out_channels=4 * (reg_max + 1),kernel_size=1),# cls_pred1_3abnn.Conv2d(in_channels=channels_list[chx[1]],out_channels=num_classes * num_anchors,kernel_size=1),# reg_pred1_3abnn.Conv2d(in_channels=channels_list[chx[1]],out_channels=4 * num_anchors,kernel_size=1),# stem2ConvBNSiLU(in_channels=channels_list[chx[2]],out_channels=channels_list[chx[2]],kernel_size=1,stride=1),# cls_conv2ConvBNSiLU(in_channels=channels_list[chx[2]],out_channels=channels_list[chx[2]],kernel_size=3,stride=1),# reg_conv2ConvBNSiLU(in_channels=channels_list[chx[2]],out_channels=channels_list[chx[2]],kernel_size=3,stride=1),# cls_pred2_afnn.Conv2d(in_channels=channels_list[chx[2]],out_channels=num_classes,kernel_size=1),# reg_pred2_afnn.Conv2d(in_channels=channels_list[chx[2]],out_channels=4 * (reg_max + 1),kernel_size=1),# cls_pred2_3abnn.Conv2d(in_channels=channels_list[chx[2]],out_channels=num_classes * num_anchors,kernel_size=1),# reg_pred2_3abnn.Conv2d(in_channels=channels_list[chx[2]],out_channels=4 * num_anchors,kernel_size=1),)return head_layers相关文章:

YOLOv6-4.0部分代码阅读笔记-effidehead_fuseab.py
effidehead_fuseab.py yolov6\models\heads\effidehead_fuseab.py 目录 effidehead_fuseab.py 1.所需的库和模块 2.class Detect(nn.Module): 3.def build_effidehead_layer(channels_list, num_anchors, num_classes, reg_max16, num_layers3): 1.所需的库和模块 impo…...
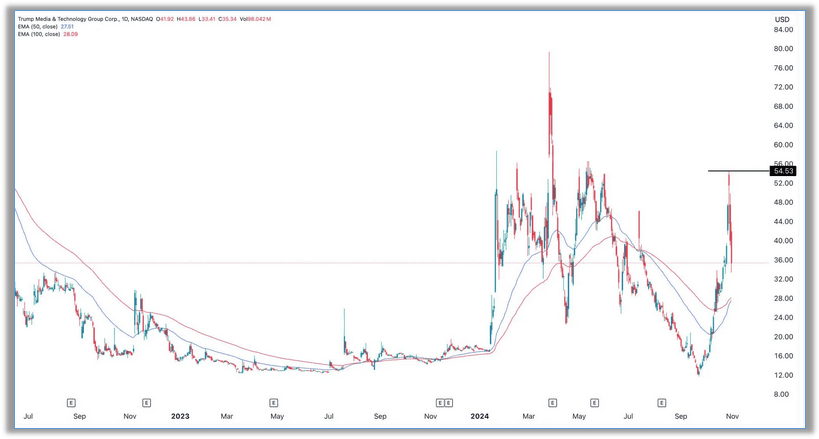
特朗普概念股DJT股票分析:为美国大选“黑天鹅事件”做好准备
猛兽财经核心观点: (1)特朗普媒体科技集团的股价近期已经从年初至今的高点下跌了35%以上。 (2)该公司将面临一个重大的黑天鹅事件。 (3)这一结果将对特朗普媒体科技集团产生重大影响。 随着投资…...

【MySQL】 运维篇—故障排除与性能调优:常见故障的排查与解决
数据库系统在运行过程中可能会遇到各种故障,如性能下降、连接失败、数据损坏等。及时有效地排查和解决这些故障,对于保证系统的稳定性和数据的完整性至关重要。 常见故障及排查方法 1. 数据库连接失败 故障描述:应用程序无法连接到数据库&…...

Android R S T U版本如何在下拉栏菜单增加基本截图功能
本文主要是MTK增加下拉栏开关菜单,功能实现为基本的截图功能,metrics_constants.proto修改 QuickSetting 新增快捷设置图标,以便对应getMetricsCategory获取;一个布局文件,一个配置加载合入实现,一个新增想要实现截图的类。 /frameworks/base/proto/src/metrics_constan…...
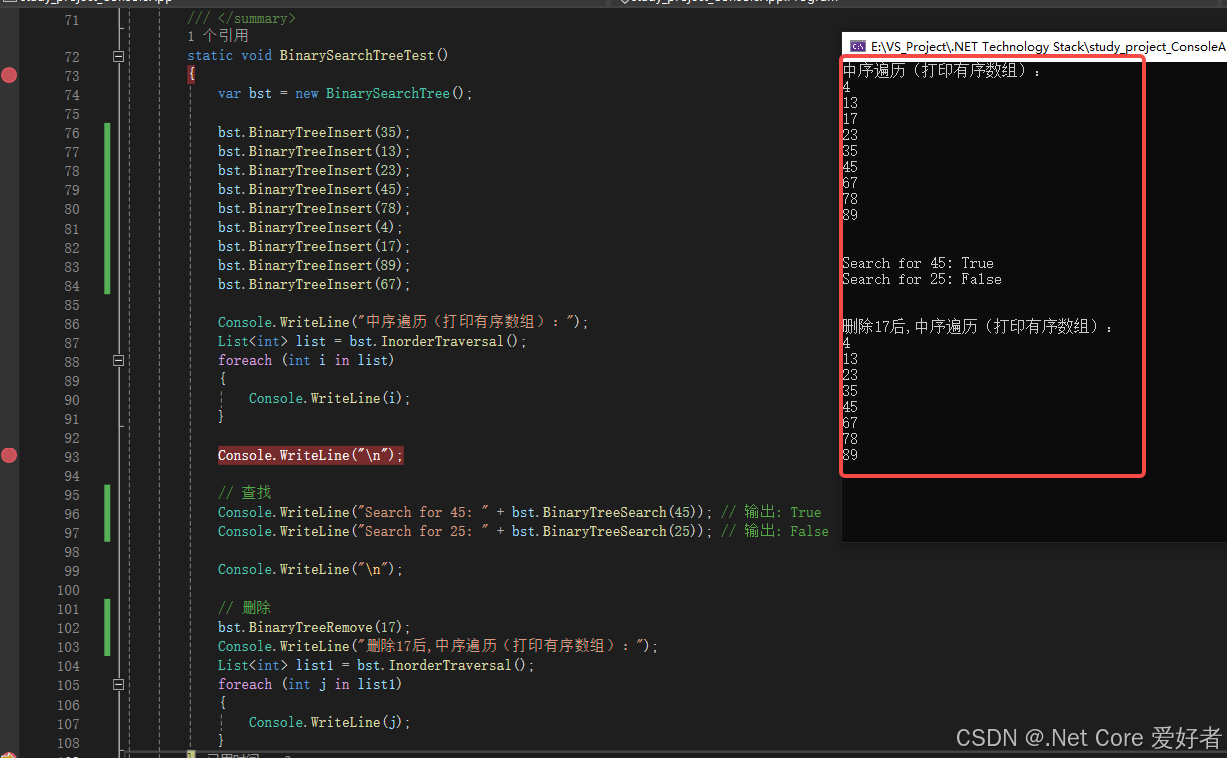
C#二叉树原理及二叉搜索树代码实现
一、概念 二叉树(Binary Tree)是一种树形数据结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树的每个节点包含三个部分:一个值、一个指向左子节点的引用和一个指向右子节点的引用。 二、二叉树…...

.eslintrc.js 的解释
如果您的项目中没有 .eslintrc.js 文件,您可以按以下步骤创建并配置 ESLint: 1. 创建 ESLint 配置文件 在您的项目根目录下创建一个新的文件,命名为 .eslintrc.js。 2. 配置 ESLint 规则 在 .eslintrc.js 文件中添加以下内容,…...

确保企业架构与业务的一致性与合规性:数字化转型中的关键要素与战略实施
在现代企业的数字化转型过程中,确保企业架构(Enterprise Architecture, EA)与企业业务的紧密一致性与合规性至关重要。无论是在战略层面还是运营层面,EA都为企业的未来发展提供了清晰的蓝图,确保企业在应对复杂的业务环…...

goframe开发一个企业网站 前端界面 拆分界面7
将页面拆出几个公用部分 在resource/template/front创建meta.html header.html footer.html meta.html <head><meta charset"utf-8"><meta content"widthdevice-width, initial-scale1.0" name"viewport"><title>{{.…...

Postman断言与依赖接口测试详解!
在接口测试中,断言是不可或缺的一环。它不仅能够自动判断业务逻辑的正确性,还能确保接口的实际功能实现符合预期。Postman作为一款强大的接口测试工具,不仅支持发送HTTP请求和接收响应,还提供了丰富的断言功能,帮助测试…...

github打不开网络问题
当打开github出现超时或者网络不能访问的情况时,我们进行如下方法解决: 1,ping gitbub.com查看域名分析的DNS IP C:\Users\86156>ping github.com 正在 Ping github.com [20.205.243.166] 具有 32 字节的数据: 来自 20.205.243.166 的回复…...

智能教育工具:基于SpringBoot的在线试题库
1 绪论 1.1 研究背景 现在大家正处于互联网加的时代,这个时代它就是一个信息内容无比丰富,信息处理与管理变得越加高效的网络化的时代,这个时代让大家的生活不仅变得更加地便利化,也让时间变得更加地宝贵化,因为每天的…...

typescript 如何跳过ts类型检查?
文章目录 前言any类型条件判断进行使用断言加注释跳过ts检查 前言 typescript 的使用,虽然让代码更加规范,利于维护,但也给开发带来很多麻烦。为了跳过很多ts的类型检查,大家也是费尽心思,下面就介绍一些常用的方式&a…...

详解ReentrantLock--三种加锁方式
目录 介绍AQS: 直观方式解释加锁的流程: Node是什么:它里面有什么属性呢 图解队列的排队过程: 源码分析三种加锁流程: 我们先讲解一下非公平锁的加锁流程: Lock()方式加锁: 在源码里对于Lock()的解…...

SQL 基础语法(一)
文章目录 1. SQL 分类2. 数据库操作3. 数据表操作4. 增删改操作5. 查询操作6. 用户管理7. 权限控制 1. SQL 分类 2. 数据库操作 #创建数据库 create database if not exists test;#查询所有数据库 show databases;#查询当前数据库 select database();#删除数据库 drop databas…...

Python酷库之旅-第三方库Pandas(190)
目录 一、用法精讲 881、pandas.Index.is_方法 881-1、语法 881-2、参数 881-3、功能 881-4、返回值 881-5、说明 881-6、用法 881-6-1、数据准备 881-6-2、代码示例 881-6-3、结果输出 882、pandas.Index.min方法 882-1、语法 882-2、参数 882-3、功能 882-4、…...

Spring学习笔记_19——@PostConstruct @PreDestroy
PostConstruct && PreDestroy 1. 介绍 PostConstruct注解与PreDestroy注解都是JSR250规范中提供的注解。 PostConstruct注解标注的方法可以在创建Bean后在为属性赋值后,初始化Bean之前执行。 PreDestroy注解标注的方法可以在Bean销毁之前执行。 2. 依赖…...

《云计算网络技术与应用》实训8-1:OpenvSwitch简单配置练习
1.按《云计算网络技术与应用》实训5-1进行环境配置,安装好OVS 2.开启OVS虚拟交换机 3.创建一个网桥br0 4.查看网桥列表 5.把ens34网卡连接到网桥br0上 6. 查看网桥br0所有端口 7.列出网卡ens34连接的所有网桥列表 8.查看OVS网络状态 9.将网桥br0上连接的网卡ens34删…...

【架构艺术】服务架构稳定性的基础保障
一个产品随着不断研发,其服务架构的复杂度会越来越高。随着产品的用户体量变大,为了保证产品能够长线运营,就需要保证整个服务架构的稳定性。因此,今天这篇文章,就从实操的角度,粗浅讨论一下,服…...

Python中使用pip换源的详细指南
在Python开发过程中,我们经常需要安装各种第三方库。pip是Python的包管理工具,用于安装和管理Python库。然而,由于网络原因,有时访问默认的Python包索引(PyPI)可能会比较慢。这时,我们可以通过更…...
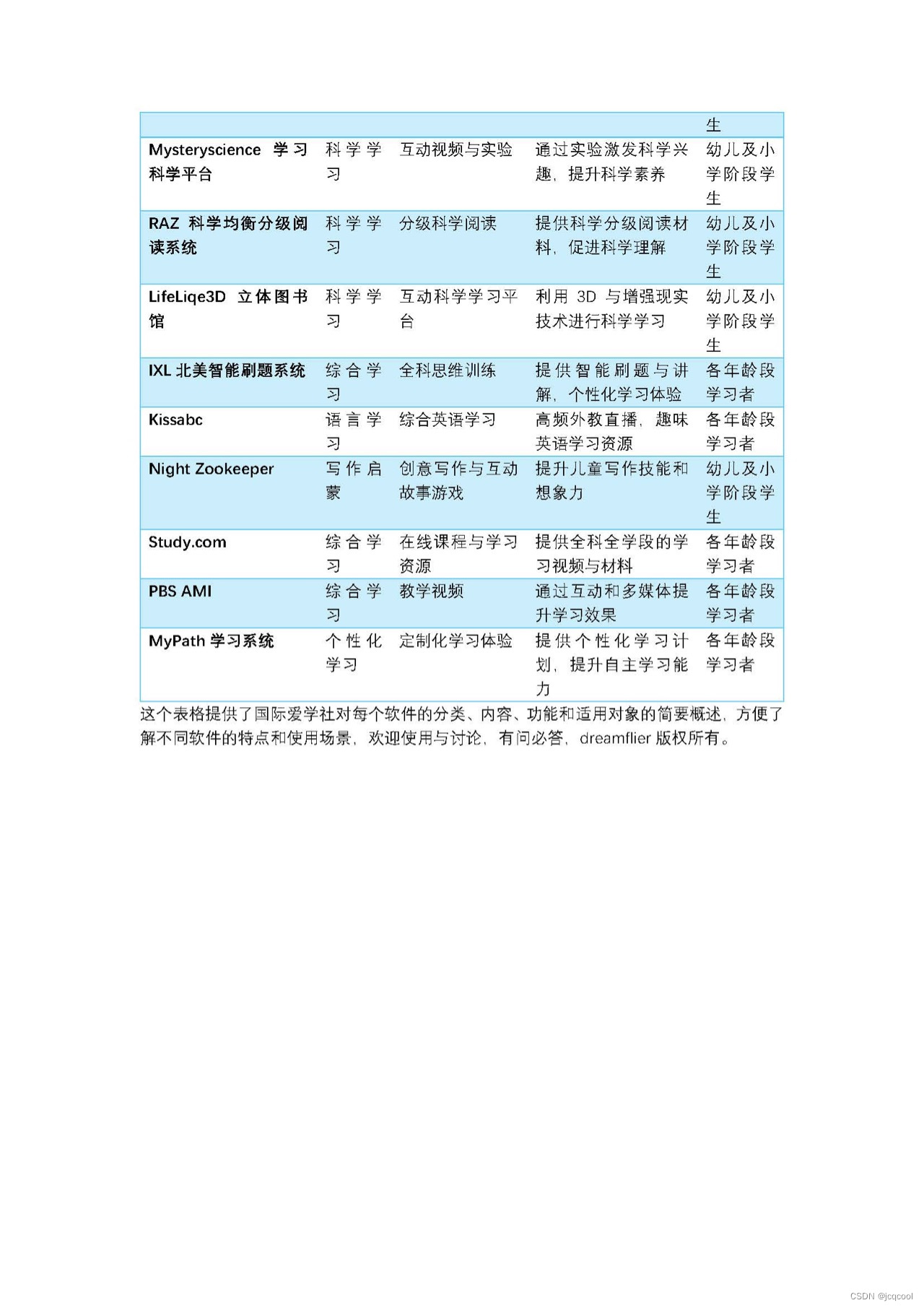
一站打包国际智慧教育自主学练软件资源
👑🌟一站打包国际智慧教育自主学练软件与资源平台,欧美学校正在使用,不出国就可以学👒🎈 💛 多元学练:我们正在使用的自主学练软件是美国学校一线教师使用的,涵盖了英语…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...
)
【限时公开】后印象派专属--ar 16:9 --style raw --stylize 800参数组合包(含塞尚构图/修拉点彩/劳特累克动态线共12套已验证prompt模板)
更多请点击: https://intelliparadigm.com 第一章:后印象派艺术精神与Midjourney风格迁移的本质逻辑 后印象派并非对印象派的简单延续,而是对主观表达、结构重构与象征张力的自觉回归——梵高旋转的星云、塞尚凝练的几何体、高更原始的色域&…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...
)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景) 当你第一次接触Git时,可能觉得它就是个"保存按钮"——每次改完代码就commit一下。但随着项目规模扩大,特别是多人协作时,…...
:构建智能体与工具交互的通用语言)
AI控制协议标准(ACPS):构建智能体与工具交互的通用语言
1. 项目概述与核心价值最近在开源社区里,一个名为“AI-Control-Protocol-Standard”的项目引起了我的注意。这个由DaibinThink发起的项目,名字听起来就很有分量——“AI控制协议标准”。乍一看,你可能觉得这又是一个关于AI模型如何被调用的技…...

DIY热熔螺母压入装置:从原理到实践,解决3D打印螺纹连接痛点
1. 项目概述:为什么我们需要一台热熔螺母压入装置?如果你和我一样,是个热衷于用3D打印制作原型、工具甚至小批量功能件的爱好者,那你一定遇到过这个痛点:如何在塑料件上实现一个坚固、耐用且能反复拆装的螺纹连接&…...