线程相关题(线程池、线程使用、核心线程数的设置)
目录
线程安全的什么情况用?情况下用线程安全的类?
线程池线程方面的优化
线程池调优主要涉及以下几个关键参数。
线程不安全原因?
1. 共享资源访问冲突
2. 缺乏原子操作
3. 内存可见性问题
4. 重排序问题
如何解决线程不安全的问题?
1. 使用互斥锁(Mutex)
2. 使用信号量(Semaphore)
3. 使用读写锁(ReadWriteLock)
4. 采用线程安全的数据结构
5. 利用原子变量(Atomic Variables)
多用户同时修改同一条数据并发修改数据?
1. 数据库事务隔离级别
2. 乐观锁
3. 悲观锁
将任务并行执行完后,再串行执行。
核心线程数设置
判断一个任务是 CPU 密集型还是 I/O 密集型,可以从多个方面入手。
新建T1、T2、T3三个线程 ,怎么保持顺序执行
方法一:使用 join 方法
方法二:使用单线程执行器(ExecutorService)
使用 CountDownLatch
使用 CyclicBarrier
join方法的使用
线程核心参数:7个参数:核心线程数、最大线程数、
空闲线程存活时间、存活时间、
任务队列、线程工厂、拒绝策略
场景:核心线程数10、最大线程数20、有界队列20,
根据线程池运行原理什么时候创建最大线程数?
核心线程数10+有界队列20=30大于的话开始
拒绝策略什么开始?
最大线程数20+队列数20=40大于的话开始
拒绝策略有什么
4种:AbortPolicy(默认)AbortPolicy [ˈpɒləsi]
直接拒绝抛出异常,阻止系统继续接收该任务,这种需要注意处理。
新任务会被直接丢弃,并且不会有任何提示。
有调用者所在线程处理,
丢弃最早的任务。
线程安全的什么情况用?情况下用线程安全的类?
多线程共享资源场景
- 资源共享:当多个线程需要访问和修改同一个共享资源(如对象、数据结构)时,必须使用线程安全的类。例如,一个多线程的 Web 应用中,多个线程可能会同时访问和修改用户的会话信息(存储在一个共享的对象中),此时就需要使用线程安全的会话管理类,以确保会话数据的一致性。
- 数据竞争风险:如果不使用线程安全的类,在多线程环境下可能会出现数据竞争的情况。比如,两个线程同时对一个非线程安全的计数器进行自增操作,可能会导致计数结果不准确。线程安全的类通过内部的同步机制(如锁、原子操作)来避免这种情况的发生。
并发数据结构操作
- 集合类操作:在多线程环境下操作集合类(如 List、Set、Map)时,通常需要考虑线程安全。例如,在一个多线程的任务调度系统中,多个线程可能会同时向一个任务列表(ArrayList)中添加或移除任务,这时候使用线程安全的集合类(如 CopyOnWriteArrayList)可以避免数据不一致的问题。
- 缓存系统:对于多线程访问的缓存数据结构,线程安全尤为重要。比如,一个分布式缓存系统,多个线程可能会同时查询、更新缓存中的数据。使用线程安全的缓存类可以保证缓存数据的准确性和完整性。
避免复杂的同步操作
- 降低开发难度:如果手动实现同步机制来保证多线程环境下的资源安全,需要编写复杂的代码,包括正确地获取和释放锁、处理死锁等问题。而使用线程安全的类可以简化开发过程,让开发者更专注于业务逻辑。例如,在多线程的日志记录系统中,使用线程安全的日志记录器(如 Log4j 的线程安全版本),可以避免开发者自己去处理多个线程同时写入日志文件可能导致的混乱。
线程池线程方面的优化
在核心线程数的设置上,要根据任务类型和系统资源来确定。
对于计算密集型任务,核心线程数应设置为处理器核心数加 1 或减 1,以充分利用 CPU 资源且避免过多的上下文切换。
而对于 I/O 密集型任务,由于线程大部分时间在等待 I/O 操作完成,核心线程数可设置为处理器核心数的数倍,以提高利用率。
在队列选择方面,有多种队列可供选择。无界队列如 LinkedBlockingQueue,可容纳很多任务,但可能导致任务堆积,使内存溢出,适用于任务量小且任务处理速度快的场景。
有界队列如 ArrayBlockingQueue,能控制队列大小,防止内存无限膨胀,但队列满时会拒绝任务,需要合理处理拒绝策略。SynchronousQueue 是一种特殊的无存储功能的队列,适合任务处理速度快且要求即时响应的场景。
在拒绝策略上,
AbortPolicy 是默认策略,当任务被拒绝时直接抛出异常,适用于对任务丢失不敏感的场景。CallerRunsPolicy 会让调用者线程执行被拒绝的任务,有助于减轻线程池压力,但会降低调用者线程的执行效率。
DiscardPolicy 直接丢弃被拒绝的任务,
而 DiscardOldestPolicy 则丢弃队列中最老的任务,这两种策略可能会导致任务丢失,需谨慎使用。
线程池的动态调整也很重要。可以根据系统负载动态地调整线程池的大小,如在任务量突然增加时,增加线程池的线程数,以加快任务处理速度,任务量减少时,相应地减少线程数,节省资源。此外,还可以定期监控线程池的运行状况,包括线程的活跃度、队列的长度等,以便及时发现问题并优化。
线程池调优主要涉及以下几个关键参数。
一是核心线程数(corePoolSize)。这是线程池中始终保留的线程数量,它的优化需依据任务特性。对于 CPU 密集型任务,核心线程数应接近或等于 CPU 核心数,这样能最大程度减少线程上下文切换带来的开销,确保 CPU 资源高效利用。对于 I/O 密集型任务,由于线程常处于等待 I/O 完成的空闲状态,核心线程数通常设为 CPU 核心数的数倍,从而提高整体的任务处理效率。
二是最大线程数(maximumPoolSize)。它规定了线程池允许的最大线程数量。在任务队列满时,若有新任务到来,线程池会在核心线程数和最大线程数之间创建新线程来处理任务。合理设置此参数很重要,若设置过大,可能导致过多的线程竞争 CPU、内存等资源,引发性能下降和资源浪费;若设置过小,在任务高峰时无法及时处理任务,造成任务堆积。
三是线程存活时间(keepAliveTime)和存活时间单位(unit)。当线程池中的线程数大于核心线程数时,空闲时间超过存活时间的线程将被终止。存活时间的设置取决于任务的频率和持续时间。对于任务间隔时间长、持续时间短的情况,可适当缩短存活时间,以便更快地释放资源;反之,可适当延长。
四是任务队列(workQueue)。不同类型的任务队列对线程池性能有显著影响。有界队列(如 ArrayBlockingQueue)能限制队列长度,防止任务过多导致内存耗尽,但队列满时可能需要合理的拒绝策略来处理后续任务。无界队列(如 LinkedBlockingQueue)可容纳无限多的任务,但可能使任务无限堆积,造成内存问题或任务处理延迟。SynchronousQueue 没有存储功能,新任务必须在有空闲线程时才能被接收,常用于要求即时响应的场景。
五是拒绝策略(rejectedExecutionHandler)。当线程池和任务队列都无法容纳新任务时,就会触发拒绝策略。常见的拒绝策略包括 AbortPolicy(直接抛出异常)、CallerRunsPolicy(由调用线程处理任务)、DiscardPolicy(直接丢弃任务)和 DiscardOldestPolicy(丢弃队列中最老的任务)。选择合适的拒绝策略要根据任务的重要性和业务对任务丢失的容忍度来决定。
线程不安全原因?
1. 共享资源访问冲突
当多个线程同时访问和修改共享的数据或资源(如全局变量、共享文件、数据库连接等)时,如果没有适当的同步机制,就可能导致数据不一致。
例如,两个线程同时对一个计数器变量进行加 1 操作,可能会出现覆盖写入的情况,导致最终结果小于预期。
2. 缺乏原子操作
一些操作看起来是一个整体,但在机器指令层面可能被分解为多个步骤。
如果一个线程在执行这些步骤的过程中被中断,其他线程又开始执行相同的操作,就会出现问题。
比如,对一个变量的读取和写入操作,在多线程环境下可能不是原子的,导致数据不一致。
3. 内存可见性问题
在多线程环境中,每个线程可能有自己的缓存(如 CPU 缓存)。当一个线程修改了共享变量的值后,其他线程可能由于缓存的原因无法立即看到这个修改,从而导致线程之间数据不一致。例如,一个线程更新了一个共享的布尔变量的值,但另一个线程可能因为缓存还在使用旧的值。
4. 重排序问题
为了提高性能,编译器或处理器可能会对指令进行重新排序。在单线程环境下,这种重排序通常不会影响程序的正确性。但在多线程环境下,可能会导致线程安全问题。
例如,一个线程中两条语句的执行顺序被改变,可能会影响其他线程对共享变量的访问和操作。
如何解决线程不安全的问题?
1. 使用互斥锁(Mutex)
原理:互斥锁用于保护共享资源,同一时刻只有一个线程可以获取锁并访问被保护的资源。其他线程如果试图获取已被占用的锁,就会被阻塞,直到锁被释放。
示例:在 Java 中,可以使用synchronized关键字
或者java.util.concurrent.locks.Lock接口(如ReentrantLock)来实现互斥锁。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class Counter {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}}
2. 使用信号量(Semaphore)
原理:信号量维护了一个许可集,线程在访问共享资源前需要获取许可,
访问结束后释放许可。通过控制许可的数量,
可以限制同时访问共享资源的线程数量。
示例:在 Java 中,java.util.concurrent.Semaphore类可以实现信号量。
例如,限制同时访问某个资源的线程数量为 3:
import java.util.concurrent.Semaphore;
class ResourceAccess {
private Semaphore semaphore = new Semaphore(3);
public void accessResource() throws InterruptedException {
semaphore.acquire();
try {
// 访问共享资源的代码
} finally {
semaphore.release();
}
}
}
3. 使用读写锁(ReadWriteLock)
原理:读写锁区分对共享资源的读操作和写操作。
多个线程可以同时进行读操作,但写操作是互斥的,
且当有一个线程进行写操作时,其他线程(包括读线程)都不能访问。
示例:在 Java 中,java.util.concurrent.locks.ReadWriteLock接口
和ReentrantReadWriteLock类实现读写锁。
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
class DataHolder {
private int data;
private ReadWriteLock lock = new ReentrantReadWriteLock();
public int readData() {
lock.readLock().lock();
try {
return data;
} finally {
lock.readLock().unlock();
}
}
public void writeData(int newData) {
lock.writeLock().lock();
try {
data = newData;
} finally {
lock.writeLock().unlock();
}
}
}
4. 采用线程安全的数据结构
原理:许多编程语言都提供了线程安全的容器类。这些容器内部已经通过合适的同步机制(如锁)来保证在多线程环境下的安全访问。
示例:在 Java 中,java.util.concurrent包下的ConcurrentHashMap、
CopyOnWriteArrayList等容器是线程安全的。
例如,使用ConcurrentHashMap来实现线程安全的计数:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
class ThreadSafeCounter {
private ConcurrentHashMap<String, AtomicInteger> counterMap
= new ConcurrentHashMap<>();
public void increment(String key) {
AtomicInteger counter = counterMap.get(key);
if (counter == null) {
counter = new AtomicInteger(0);
AtomicInteger oldCounter = counterMap.putIfAbsent(key, counter);
if (oldCounter!= null) {
counter = oldCounter;
}
}
counter.incrementAndGet();
}}
5. 利用原子变量(Atomic Variables)
原理:原子变量提供了一些原子操作,如get、set、incrementAndGet等,
这些操作在硬件层面保证了操作的原子性,避免了多个线程同时操作一个变量时的不一致性。
示例:在 Java 中,java.util.concurrent.atomic包下有多种原子变量,如AtomicInteger、AtomicLong、AtomicBoolean等。
import java.util.concurrent.atomic.AtomicInteger;
class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}}
主要有三点:
- 原子性:一个或者多个操作在 CPU 执行的过程中被中断
- 可见性:一个线程对共享变量的修改,另外一个线程不能立刻看到
- 有序性:程序执行的顺序没有按照代码的先后顺序执行
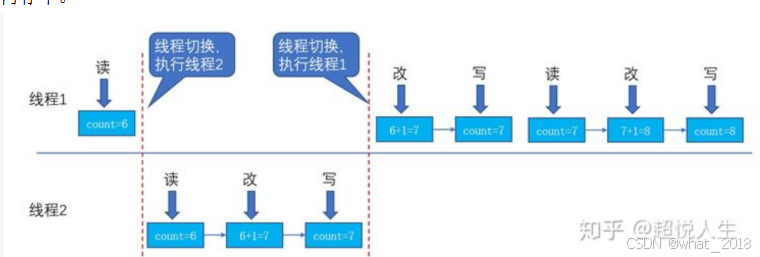
原子性 count++, i++
一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
Cpu切换时候会打断
读、改、写三步来进行;即先从内存中读出count的值,然后执行+1操作,再将结果写回内存中。
有序性:动态编译器为了程序的整体性能会进行指令重排序
https://blog.csdn.net/a13545564067/article/details/105453345
多用户同时修改同一条数据并发修改数据?
当多用户同时修改同一条数据时,可能会出现数据不一致的情况,
以下是一些处理这种并发修改的方法:
1. 数据库事务隔离级别
读未提交(Read Uncommitted):这是最低的隔离级别,一个事务可以读取另一个事务未提 交的数据。在这种情况下,
并发修改可能会导致脏读、不可重复读和幻读等问题,
一般不建议用于对数据一致性要求较高的场景。
读已提交(Read Committed):一个事务只能读取另一个事务已经提交的数据。
这种隔离级别可以避免脏读,但可能会出现不可重复读的情况,即同一事务中多次读取同一数据可能得到不同的值。
可重复读(Repeatable Read):保证在同一事务中多次读取同一数据的结果是相同的,
它可以解决不可重复读的问题,但可能会出现幻读
(在事务执行过程中,另一个事务插入了满足条件的数据)。
串行化(Serializable):这是最高的隔离级别,事务是串行执行的,
能完全避免脏读、不可重复读和幻读,但会严重影响系统的并发性能。
2. 乐观锁
版本号机制:在数据表中添加一个版本号(version)字段。
当用户读取数据时,同时获取版本号。
在提交修改时,检查版本号是否与读取时一致。
如果一致,说明数据没有被其他用户修改,更新数据并将版本号加 1;
如果不一致,说明数据已经被修改,需要根据业务情况决定是重试还是抛出异常。
时间戳机制:类似于版本号机制,不过是使用时间戳来记录数据的最后修改时间。
提交修改时,比较时间戳是否一致来判断数据是否被修改。
3. 悲观锁
数据库层面的锁:例如,在 SQL 语句中使用 FOR UPDATE(针对 MySQL 的 InnoDB 引擎) 来对查询的数据行进行加锁。当一个用户对数据行进行修改时,其他用户 如果也想修改同一行数据,就需要等待锁被释放。
这种方式可以有效防止数据被并发修改,但会降低系统的并发性能。
应用程序层面的锁:使用编程语言提供的锁机制,如 Java 中的 synchronized 关键字或 Lock 接口,对访问和修改数据的代码块进行加锁。
但这种锁是基于应用程序所在的服务器,
在分布式环境下可能不太适用,需要结合分布式锁来使用。
将任务并行执行完后,再串行执行。
一种常见的方法是结合线程池和CountDownLatch。
首先创建线程池来执行并行任务,对于每个并行任务,在线程池中提交执行。
同时,使用CountDownLatch来计数并行任务的数量。当每个并行任务完成时,在任务内部调用CountDownLatch的countDown()方法。
主线程通过CountDownLatch的await()方法阻塞,直到所有并行任务完成(即计数器为 0)。之后,主线程就可以执行后续的串行任务了。
另一种方式是使用CompletableFuture,在 Java 8 及以后版本中可以利用它的特性。
通过CompletableFuture的allOf()方法将多个并行的CompletableFuture任务组合在一起,
这个组合后的任务会在所有并行任务都完成后才结束。
然后可以通过thenRun()或thenAccept()等方法在这个组合任务完成后执行串行任务,实现先并行后串行的执行顺序。
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ParallelThenSerial {
public static void main(String[] args) throws InterruptedException {
// 创建一个包含5个线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 假设我们有10个并行任务,创建CountDownLatch并初始化为10
CountDownLatch countDownLatch = new CountDownLatch(10);
// 提交10个并行任务到线程池
for (int i = 0; i < 10; i++) {
final int taskNumber = i;
executorService.submit(() -> {
try {
System.out.println("执行并行任务: " + taskNumber);
// 模拟任务执行时间
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 每个任务完成后,计数减1
countDownLatch.countDown();
}
});
}
// 主线程等待所有并行任务完成
countDownLatch.await();
System.out.println("所有并行任务已完成,开始串行任务");
// 在这里执行串行任务,例如下面简单的打印
System.out.println("这是串行任务的一部分");
// 关闭线程池
executorService.close();
}}
以下是使用CompletableFuture实现相同功能的示例代码:
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService
;import java.util.concurrent.Executors;
public class ParallelThenSerialWithCompletableFuture {
public static void main(String[] args) {
// 创建一个包含5个线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 创建10个CompletableFuture代表并行任务
CompletableFuture<?>[] futures = new CompletableFuture[10];
for (int i = 0; i < 10; i++) {
final int taskNumber = i;
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("执行并行任务: " + taskNumber);
// 模拟任务执行时间
try {
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}, executorService);
futures[taskNumber] = future;
}
// 使用allOf等待所有并行任务完成,然后执行串行任务
CompletableFuture.allOf(futures).thenRun(() -> {
System.out.println("所有并行任务已完成,开始串行任务");
// 这里执行串行任务,例如简单的打印
System.out.println("这是串行任务的一部分");
});
// 关闭线程池(注意:这里关闭线程池的时机需要根据实际情况调整,
因为CompletableFuture可能仍在使用线程池)
executorService.shutdown();
}}
核心线程数设置
多线程核心线程数的设置没有固定标准,需综合多方面因素考虑。
从 CPU 核心数角度看,若任务是 CPU 密集型,核心线程数一般设置为与 CPU 核心数相等或接近。例如,一个四核 CPU,核心线程数设为 4 左右,这样能充分利用 CPU 资源,避免线程切换带来的额外开销,提高程序执行效率。
对于 I/O 密集型任务,情况则不同。由于线程在等待 I/O 操作时会处于阻塞状态,此时可设置较多的核心线程数。
还需考虑任务的性质和业务需求。如果任务执行时间较短且频繁提交,过多的核心线程数可能导致线程频繁创建和销毁,增加系统负担。此时可根据任务提交频率和处理速度,合理设置核心线程数,使线程资源得到充分利用。如果业务对响应时间要求极高,可能需要适当增加核心线程数,以确保任务能快速处理。
另外,系统资源的限制也很关键。如果内存资源有限,过多的线程会消耗大量内存,导致内存不足,进而影响系统性能。同时,过高的线程数可能超出操作系统对线程的管理能力,造成系统不稳定。所以,在设置核心线程数时,要兼顾系统的内存、CPU 使用率等资源状况。
如何判断当前任务是 CPU 密集型还是 I/O 密集型?
判断一个任务是 CPU 密集型还是 I/O 密集型,可以从多个方面入手。
首先,从任务性质来看,如果任务主要涉及大量的计算操作,比如复杂的数学运算、数据加密解密、图形渲染等,这些操作需要 CPU 进行持续的运算,很少有等待 I/O 的时间,那么该任务大概率是 CPU 密集型任务。相反,如果任务的执行过程中需要频繁地与外部设备(如磁盘、网络、数据库等)进行数据交换,像从数据库中频繁读取数据、网络文件传输等操作,大部分时间都在等待 I/O 操作完成,这类任务通常是 I/O 密集型任务。
其次,可以通过性能分析工具来判断。在 Java 环境中,有很多性能分析工具可供使用,比如 JProfiler、VisualVM 等。以 JProfiler 为例,它可以监测程序运行时的 CPU 使用率和 I/O 操作情况。如果在任务执行过程中,CPU 使用率一直保持在较高水平(接近或达到 100%),而 I/O 操作很少,那么很可能是 CPU 密集型任务;反之,如果 I/O 等待时间占总执行时间的比例较高,就可能是 I/O 密集型任务。
还可以通过简单的代码测试来判断。在代码中,可以分别记录任务执行过程中的 CPU 时间和 I/O 等待时间。例如,在 Java 中可以使用 System.currentTimeMillis () 方法在任务开始和结束时分别记录时间,同时使用操作系统提供的工具(如 Linux 下的 top 命令)查看 CPU 使用率。如果 CPU 时间占总时间的比重较大,那么任务倾向于 CPU 密集型;如果 I/O 等待时间占比较大,则倾向于 I/O 密集型。
最后,从业务逻辑角度分析,某些业务场景本身就暗示了任务类型。
比如,一个数据分析系统中的数据处理模块,如果是对大量数据进行统计分析运算,这就是 CPU 密集型业务;
而如果是将处理好的数据存储到远程数据库或从远程数据库中频繁获取数据来更新本地缓存,这就是 I/O 密集型业务。
IO密集: 文件读写、DB读写、网格请求等。一般设置 线程数= 2CPU核数+ 1
IO主要是网络传输、磁盘读取,不需要占用太多CPU
CPU密集:计算型代码、Bitmap转换、Gson装换等。一般设置 线程数=CPU核数+ 1
方法:
- 压测(jmeter)找平衡点,设置多了出现线程上下文切换。
- 采用理论然后压测
可以使用 Runtime.getRuntime().availableProcessor() 方法来获取 [ˈprəʊsesə(r)]
实际应用中 线程数 = ((线程CPU时间+线程等待时间)/ 线程CPU时间 ) * 核心数N
+1因为线程由于偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程也能确保 CPU 的时钟周期不会被浪费,从而保证 CPU 的利用率。
java中常见的六种线程池详解 - AnonyStar - 博客园
多线程面试题(2021最新版)-腾讯云开发者社区-腾讯云
https://zhuanlan.zhihu.com/p/458062389
①并发高、任务时间短->CPU+1,减少上线文切换
②并发不高、任务执行时间长
IO密集型的任务-> CPU核数*2+1
计算密集型的任务->CPU核数+1
③并发高、业务执行时间长,解决这种类型的任务关键不在于线程池,而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,第二步增加服务器,第三步......
新建T1、T2、T3三个线程 ,怎么保持顺序执行
现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完之后执行,T3在T2执行完后执行?
方法一:使用 join 方法
- 原理:join方法可以让一个线程等待另一个线程执行完毕后再执行。例如,让 T2 线程等待 T1 线程执行完,T3 线程等待 T2 线程执行完。
- 示例代码:class Main {
public static void main(String[] args) {
Thread T1 = new Thread(() -> {
System.out.println("T1线程开始执行");
// 模拟T1线程执行的任务
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1线程执行完毕");
});
Thread T2 = new Thread(() -> {
try {
T1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T2线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T2线程执行完毕");
});
Thread T3 = new Thread(() -> {
try {
T2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T3线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T3线程执行完毕");
});
T1.start();
T2.start();
T3.start();
}}
方法二:使用单线程执行器(ExecutorService)
原理:通过创建一个单线程的线程池,将任务按顺序提交到线程池中,
这样任务就会按提交的顺序依次执行。
示例代码:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> {
System.out.println("T1线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1线程执行完毕");
});
executor.submit(() -> {
System.out.println("T2线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T2线程执行完毕");
});
executor.submit(() -> {
System.out.println("T3线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T3线程执行完毕");
});
executor.shutdown();
}}
使用 CountDownLatch
- 原理:CountDownLatch是一个同步辅助类。它允许一个或多个线程等待其他线程完成操作。可以把CountDownLatch看作是一个计数器,当创建CountDownLatch时需要指定一个计数值,每个线程完成自己的任务后调用countDown方法来减少这个计数器的值。当计数器的值变为 0 时,等待这个CountDownLatch的线程就可以继续执行。
- 示例代码:
import java.util.concurrent.CountDownLatch;class Main {
public static void main(String[] args) {
final CountDownLatch latch1 = new CountDownLatch(1);
final CountDownLatch latch2 = new CountDownLatch(1);
Thread T1 = new Thread(() -> {
System.out.println("T1线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1线程执行完毕");
latch1.countDown();
});
Thread T2 = new Thread(() -> {
try {
latch1.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T2线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T2线程执行完毕");
latch2.countDown();
});
Thread T3 = new Thread(() -> {
try {
latch2.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T3线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T3线程执行完毕");
});
T1.start();
T2.start();
T3.start();
}}
使用 CyclicBarrier
- 原理:CyclicBarrier是一个可循环使用的屏障。它会让一组线程到达一个屏障点时被阻塞,直到最后一个线程到达屏障点,这些线程才会一起继续执行。可以通过设置屏障点的数量(参与的线程数量)来控制线程的同步。
- 示例代码:
import java.util.concurrent.CyclicBarrier;class Main {
public static void main(String[] args) {
CyclicBarrier barrier1 = new CyclicBarrier(2);
CyclicBarrier barrier2 = new CyclicBarrier(2);
Thread T1 = new Thread(() -> {
System.out.println("T1线程开始执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1线程执行完毕");
try {
barrier1.await();
} catch (Exception e) {
e.printStackTrace();
}
});
Thread T2 = new Thread(() -> {
System.out.println("T2线程开始执行");
try {
barrier1.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("T2线程执行完毕");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
barrier2.await();
} catch (Exception e) {
e.printStackTrace();
}
});
Thread T3 = new Thread(() -> {
System.out.println("T3线程开始执行");
try {
barrier2.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("T3线程执行完毕");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
T1.start();
T2.start();
T3.start();
}}
join方法的作用?
答: Thread类中的join方法的主要作用就是同步,它可以使得线程之间的并行执行变为串行执行。当我们调用某个线程的这个方法时,这个方法会挂起调用线程,直到被调用线程结束执行,调用线程才会继续执行。
Join方法传参和不传参的区别?
答:join方法中如果传入参数,则表示这样的意思:如果A线程中掉用B线程的join(10),则表示A线程会等待B线程执行10毫秒,10毫秒过后,A、B线程并行执行。需要注意的是,
jdk规定,join(0)的意思不是A线程等待B线程0秒,而是A线程等待B线程无限时间,直到B线程执行完毕,即join(0)等价于join()。
join方法将挂起调用线程的执行,直到被调用的对象完成它的执行。
join方法的使用
join在线程里面意味着“插队”,哪个线程调用join代表哪个线程插队先执行——但是插谁的队是有讲究了,不是说你可以插到队头去做第一个吃螃蟹的人,而是插到在当前运行线程的前面,比如系统目前运行线程A,在线程A里面调用了线程B.join方法,则接下来线程B会抢先在线程A面前执行,等到线程B全部执行完后才继续执行线程A。
join()方法的底层是利用wait()方法实现的
多线程中Thread的join方法_thread join-CSDN博客
相关文章:
线程相关题(线程池、线程使用、核心线程数的设置)
目录 线程安全的什么情况用?情况下用线程安全的类? 线程池线程方面的优化 线程池调优主要涉及以下几个关键参数。 线程不安全原因? 1. 共享资源访问冲突 2. 缺乏原子操作 3. 内存可见性问题 4. 重排序问题 如何解决线程不安全的问题࿱…...

2181、合并零之间的节点
2181、[中等] 合并零之间的节点 1、问题描述: 给你一个链表的头节点 head ,该链表包含由 0 分隔开的一连串整数。链表的 开端 和 末尾 的节点都满足 Node.val 0 。 对于每两个相邻的 0 ,请你将它们之间的所有节点合并成一个节点ÿ…...

powerlaw:用于分析幂律分布的Python库
引言 幂律分布在游戏行业中非常重要。在免费游戏模式下,玩家的付费行为往往遵循幂律分布。少数“鲸鱼玩家”贡献了大部分的收入,而大多数玩家可能只进行少量或不进行付费。通过理解和应用幂律分布,游戏开发者可以更好地分析和预测玩家行为&a…...

工作管理实战指南:利用Jira、Confluence等Atlassian工具打破信息孤岛,增强团队协作【含免费指南】
如果工作场所存在超级反派,其中之一可能会被命名为“信息孤岛”,因为它们能够对公司的生产力和协作造成严重破坏。当公司决定使用太多互不关联的工具来完成工作时,“信息孤岛”就会出现,导致团队需要耗费大量时间才能就某件事情达…...

JAVA语言多态和动态语言实现原理
JAVA语言多态和动态语言实现原理 前言invoke指令invokestaticinvokespecialinvokevirtualinvokeintefaceinvokedynamicLambda 总结 前言 我们编码java文件,javac编译class文件,java运行class,JVM执行main方法,加载链接初始化对应…...

阿里云-防火墙设置不当导致ssh无法连接
今天学网络编程的时候,看见有陌生ip连接,所以打开了防火墙禁止除本机之外的其他ip连接: 但是当我再次用ssh的时候,连不上了才发现大事不妙。 折腾了半天,发现阿里云上可以在线向服务器发送命令,所以赶紧把2…...

使用WebAssembly优化Web应用性能
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用WebAssembly优化Web应用性能 引言 WebAssembly 简介 安装工具 创建 WebAssembly 项目 编写 WebAssembly 代码 编译 WebAssem…...

软件测试模型
软件测试模型是在软件开发过程中,用于指导软件测试活动的一系列方法和框架。这些模型帮助测试团队确定何时进行测试、测试什么以及如何测试,从而确保软件的质量和稳定性。 一 V模型 V模型是一种经典的软件测试模型,它由瀑布研发模型演变而来的测试模型…...

动态规划——两个数组的dp问题
目录 一、最长公共子序列 二、不同的子序列 三、通配符匹配 四、正则表达式匹配 五、两个字符串的最小ASCII删除和 六、最长重复子数组 七、交错字符串 一、最长公共子序列 最长公共子序列 第一步:确定状态表示 dp[i][j]:表示字符串 s1 的 [0&am…...

视频QoE测量学习笔记(二)
目录 自适应比特率(ABH或ABS) HAS:HTTP adaptive streaming 自适应本质: HAS正在解决传统流协议中主要关注的几个方面: DASH标准化原因 HAS发展 编码: 影响HAS系统的四个主要问题: 一个健全的HAS方…...

RSA算法详解:原理与应用
RSA算法详解:原理与应用 RSA算法是现代密码学的基石之一,广泛应用于安全通信、数据加密和身份验证等领域。本文将详细介绍RSA算法的原理、实现步骤以及实际应用。 一、RSA算法概述 RSA(Rivest-Shamir-Adleman)算法由Ron Rivest…...

YOLOv6-4.0部分代码阅读笔记-effidehead_fuseab.py
effidehead_fuseab.py yolov6\models\heads\effidehead_fuseab.py 目录 effidehead_fuseab.py 1.所需的库和模块 2.class Detect(nn.Module): 3.def build_effidehead_layer(channels_list, num_anchors, num_classes, reg_max16, num_layers3): 1.所需的库和模块 impo…...
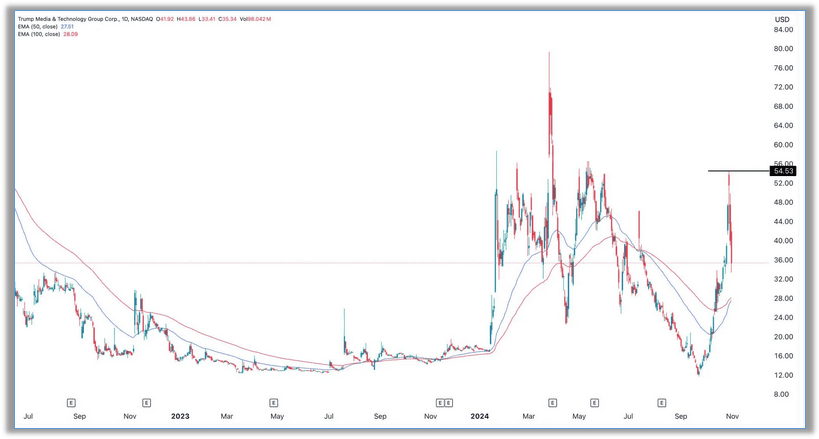
特朗普概念股DJT股票分析:为美国大选“黑天鹅事件”做好准备
猛兽财经核心观点: (1)特朗普媒体科技集团的股价近期已经从年初至今的高点下跌了35%以上。 (2)该公司将面临一个重大的黑天鹅事件。 (3)这一结果将对特朗普媒体科技集团产生重大影响。 随着投资…...

【MySQL】 运维篇—故障排除与性能调优:常见故障的排查与解决
数据库系统在运行过程中可能会遇到各种故障,如性能下降、连接失败、数据损坏等。及时有效地排查和解决这些故障,对于保证系统的稳定性和数据的完整性至关重要。 常见故障及排查方法 1. 数据库连接失败 故障描述:应用程序无法连接到数据库&…...

Android R S T U版本如何在下拉栏菜单增加基本截图功能
本文主要是MTK增加下拉栏开关菜单,功能实现为基本的截图功能,metrics_constants.proto修改 QuickSetting 新增快捷设置图标,以便对应getMetricsCategory获取;一个布局文件,一个配置加载合入实现,一个新增想要实现截图的类。 /frameworks/base/proto/src/metrics_constan…...
C#二叉树原理及二叉搜索树代码实现
一、概念 二叉树(Binary Tree)是一种树形数据结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树的每个节点包含三个部分:一个值、一个指向左子节点的引用和一个指向右子节点的引用。 二、二叉树…...

.eslintrc.js 的解释
如果您的项目中没有 .eslintrc.js 文件,您可以按以下步骤创建并配置 ESLint: 1. 创建 ESLint 配置文件 在您的项目根目录下创建一个新的文件,命名为 .eslintrc.js。 2. 配置 ESLint 规则 在 .eslintrc.js 文件中添加以下内容,…...

确保企业架构与业务的一致性与合规性:数字化转型中的关键要素与战略实施
在现代企业的数字化转型过程中,确保企业架构(Enterprise Architecture, EA)与企业业务的紧密一致性与合规性至关重要。无论是在战略层面还是运营层面,EA都为企业的未来发展提供了清晰的蓝图,确保企业在应对复杂的业务环…...

goframe开发一个企业网站 前端界面 拆分界面7
将页面拆出几个公用部分 在resource/template/front创建meta.html header.html footer.html meta.html <head><meta charset"utf-8"><meta content"widthdevice-width, initial-scale1.0" name"viewport"><title>{{.…...

Postman断言与依赖接口测试详解!
在接口测试中,断言是不可或缺的一环。它不仅能够自动判断业务逻辑的正确性,还能确保接口的实际功能实现符合预期。Postman作为一款强大的接口测试工具,不仅支持发送HTTP请求和接收响应,还提供了丰富的断言功能,帮助测试…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...

Go语言静态站点生成器Zeuxis:极简架构与高性能构建实践
1. 项目概述:一个轻量级、高性能的静态站点生成器最近在折腾个人博客和文档站点,发现市面上的静态站点生成器虽然多,但要么配置复杂、学习曲线陡峭,要么过于臃肿,启动和构建速度慢得让人抓狂。直到我遇到了bnomei/zeux…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...