时间序列预测(十)——长短期记忆网络(LSTM)
目录
一、LSTM结构
二、LSTM 核心思想
三、LSTM分步演练
(一)初始化
1、权重和偏置初始化
2、初始细胞状态和隐藏状态初始化
(二)前向传播
1、遗忘门计算(决定从上一时刻隐状态中丢弃多少信息)
2、输入门及候选记忆元计算(决定存储多少选记忆元的新数据)
3、记忆元更新
4、输出门及隐状态更新
(三)反向传播
四、简单LSTM代码实现
修改要点:
输出结果;
五、LSTM变体
1、窥视孔连接(Peephole Connections)
2、耦合的遗忘和输入门(Coupled Forget and Input Gates)
3、门控循环单元(GRU)
4、深度门控RNN(Deep Gated RNN)
5、Clockwork RNN
6. Layer Normalization LSTM
7. Variational LSTM
8. Attention Mechanism
9. Multi-Scale LSTM
10. Attention-Based LSTM
11. Hierarchical LSTM
12. Context-Aware LSTM
13. Temporal Convolutional Networks (TCN)
14. S4 (State Space for Sequence Modeling)
15. Recurrent Neural Network with Sparse Connections
16. BERT-Style LSTM
17. Graph Neural Networks with LSTM
18. Attention-Based GRU
19. LSTM with External Memory
20. LSTM with Reinforcement Learning
往期文章:
时间序列预测(一)——线性回归(linear regression)-CSDN博客
时间序列预测(二)——前馈神经网络(Feedforward Neural Network, FNN)-CSDN博客
时间序列预测(六)——循环神经网络(RNN)_rnn序列预测-CSDN博客
长短期记忆网络(LSTM, Long Short-Term Memory)是一种专门设计用来解决时间序列数据的循环神经网络(RNN)。LSTM的主要优势是能够捕捉长时间依赖,适用于处理长期记忆(长期依赖)的问题,同时在训练过程中避免了传统RNN常见的梯度消失和爆炸问题。在时间序列预测中,LSTM网络非常适合处理具有长期相关性的输入数据,例如气温变化、股票价格、驾驶员行为数据等。LSTM可以通过记忆单元和门控机制来决定哪些信息需要“记住”,哪些需要“遗忘”。
一、LSTM结构
LSTM的结构和基础的RNN相比,并没有特别大的不同,都是一种重复神经网络模块的链式结构。在标准的RNN中,这个重复的模块只有一个非常简单的结构,如下图,只有一个激活函数tanh层。
LSTM的结构也是如此,只是重复模块的内容有所变化,没有单个神经网络层,而是有四个神经网络层,它们以非常特殊的方式交互。
其中不同符号表示不同的意思,
σ表示的Sigmoid 激活函数,有关激活函数的介绍可以看这篇文章:
时间序列预测(三)——激活函数(Activation Function)_预测任务用什么激活函数-CSDN博客
二、LSTM 核心思想
LSTM的关键就是记忆元(memory cell),与隐状态具有相同的形状,其设计目的是用于记录附加的信息。即贯穿图顶部的水平线。
LSTM的核心思想就是保护和控制记忆元。这里用到了三个门:输入门、遗忘门、输出门:
- 输入门决定新的输入信息是否需要记入记忆单元。
- 遗忘门决定当前的记忆单元是否需要遗忘部分过去的信息。
- 输出门决定记忆单元中的信息是否会影响当前输出

他们由 sigmoid 神经网络层和逐点乘法运算组成。选择性地让信息通过,选择性地让信息通过,sigmoid 层输出介于 0 和 1 之间的数字,值 0 表示“不让任何内容通过”,而值 1 表示“让所有内容通过!
三、LSTM分步演练
(一)初始化
1、权重和偏置初始化
LSTM有多个权重矩阵和偏置项需要初始化。对于一个具有输入维度xt(输入向量的维度)、隐藏层维度ht的LSTM单元,有以下主要的权重矩阵和偏置项:
- 遗忘门的权重矩阵Wf和偏置bf。
- 输入门的权重矩阵Wi和偏置bi。
- 输出门的权重矩阵Wo和偏置bo。
- 用于计算候选细胞状态的权重矩阵Wc和偏置bc。
这些权重矩阵和偏置项通常初始化为小的随机值,例如在[−0.1,0.1]区间内的随机数。
2、初始细胞状态和隐藏状态初始化
初始细胞状态C0和初始隐藏状态h0也需要初始化。一般来说,C0和h0可以初始化为全零向量。
(二)前向传播
1、遗忘门计算(决定从上一时刻隐状态中丢弃多少信息)
输入上一时刻的隐状态和当前时刻的特征
,通过sigmoid层输出一个介于0和1之间的数字ft,1表示 “完全保留此内容”,而0代表 “完全摆脱此内容”。

2、输入门及候选记忆元计算(决定存储多少选记忆元的新数据)
同样,输入和
,通过sigmoid层输出
![]() ,同时再通过tanh层输出候选记忆元(candidate memory cell)
,同时再通过tanh层输出候选记忆元(candidate memory cell)![]() ,
,

3、记忆元更新
将上一时刻的记忆元乘以ft,再添加候选记忆元乘以![]() ,最终计算出当前时刻的记忆元Ct
,最终计算出当前时刻的记忆元Ct

4、输出门及隐状态更新

同样,输入和
,通过sigmoid层输出
![]() ,再乘以
,再乘以![]() 通过tanh层的输出值,最终输出当前时刻的隐状态ht
通过tanh层的输出值,最终输出当前时刻的隐状态ht
(三)反向传播
反向传播的目标是通过链式法则(链式求导)计算损失函数相对于每个权重和偏置的梯度。LSTM 中的反向传播称为 通过时间的反向传播(Backpropagation Through Time,BPTT),因为 LSTM 具有时间依赖性。
-
计算损失函数的梯度:从最后的输出开始计算损失函数相对于 hT 和 cT 的梯度。
-
反向传播梯度:从时间步 T逐步往回传播梯度,依次计算遗忘门、输入门、输出门、记忆单元状态和隐藏状态的梯度。
-
计算权重和偏置的梯度:使用各门的梯度,结合前一时间步的隐藏状态和输入,计算权重 Wf,Wi,Wo,Wc以及偏置 bf,bi,bo,bc 的梯度。
-
更新参数:根据计算得到的梯度,通过优化算法(如梯度下降或Adam)更新权重和偏置,以最小化损失函数。
注意:LSTM反向传播的计算过程还是较为复杂的,但在Python等高层编程语言中,使用深度学习框架(如TensorFlow或PyTorch)可以简化实现。框架会自动处理反向传播的计算,你只需定义模型结构和损失函数,训练时框架会自动计算梯度和更新参数。
# 3. 设置损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 4. 训练模型
num_epochs = 1000
for epoch in range(num_epochs):model.train()# 前向传播outputs = model(x_train_tensor)loss = criterion(outputs, y_train_tensor)# 反向传播optimizer.zero_grad() # 清除之前的梯度loss.backward() # 计算梯度 optimizer.step() # 更新参数最后,再用当前时刻的隐状态ht和下一时刻的特征xt+1作为输入,重复上诉步骤,直到处理完整个序列。
注意:如果遗忘门始终为1且输入门始终为0,则过去的记忆元Ct−1 将随时间被保存并传递到当前时间步。这样可以缓解梯度消失问题,并更好地捕获序列中的长距离依赖关系。
四、简单LSTM代码实现
从RNN模型改成LSTM模型是比较简单的,因为两者的主要区别在于它们的结构和如何处理时间序列数据。LSTM比RNN更复杂,能够更好地处理长期依赖关系。接下来,我将逐步讲解如何将RNN模型替换为LSTM模型,并给出修改后的代码。
1、任务:
根据一个包含道路曲率(Curvature)、车速(Velocity)、侧向加速度(Ay)和方向盘转角(Steering_Angle)真实的数据集,去预测未来的方向盘转角。
2、做法:
提取前5个历史曲率、速度、方向盘转角作为输入特征,同时添加后5个未来曲率(由于车辆的预瞄距离)。目标输出为未来5个方向盘转角。采用LSTM网络训练。
3、修改要点:
- LSTM替换RNN:直接用
nn.LSTM替换原有的nn.RNN。 - LSTM层的隐藏状态:LSTM有两个隐藏状态,分别是
h0(隐藏状态)和c0(细胞状态)。 - 其余部分保持不变,包括数据预处理、训练过程等。
4、具体代码:
# LSTM 模型
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error as mae, r2_score
import matplotlib.pyplot as plt# 1. 数据预处理
# 读取数据
data = pd.read_excel('input_data_20241010160240.xlsx') # 替换为你的数据文件路径 # 提取特征和标签
curvature = data['Curvature'].values
velocity = data['Velocity'].values
steering = data['Steering_Angle'].values# 定义历史和未来的窗口大小
history_size = 5
future_size = 5features = []
labels = []
for i in range(history_size, len(data) - future_size):# 提取前5个历史的曲率、速度和方向盘转角history_curvature = curvature[i - history_size:i]history_velocity = velocity[i - history_size:i]history_steering = steering[i - history_size:i]# 提取后5个未来的曲率(用于预测)future_curvature = curvature[i:i + future_size]# 输入特征:历史 + 未来曲率feature = np.hstack((history_curvature, history_velocity, history_steering, future_curvature))features.append(feature)# 输出标签:未来5个方向盘转角label = steering[i:i + future_size]labels.append(label)# 转换为 NumPy 数组
features = np.array(features)
labels = np.array(labels)# 归一化
scaler_x = StandardScaler()
scaler_y = StandardScaler()features = scaler_x.fit_transform(features)
labels = scaler_y.fit_transform(labels)# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.05)# 将特征转换为三维张量,形状为 [样本数, 时间序列长度, 特征数]
input_feature_size = history_size * 3 + future_size # 历史曲率、速度、方向盘转角 + 未来曲率
x_train_tensor = torch.tensor(x_train, dtype=torch.float32).view(-1, 1, input_feature_size) # [batch_size, seq_len=1, input_size]
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, future_size) # 输出未来的5个方向盘转角
x_test_tensor = torch.tensor(x_test, dtype=torch.float32).view(-1, 1, input_feature_size)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, future_size)# 2. 创建LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(LSTMModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) # 使用LSTMself.fc = nn.Linear(hidden_size, output_size) # 输出层def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.lstm(x, (h0, c0)) # LSTM输出out = self.fc(out[:, -1, :]) # 只取最后一个时间步的输出return out# 实例化模型
input_size = input_feature_size # 输入特征数
hidden_size = 64 # 隐藏层大小
num_layers = 2 # LSTM层数
output_size = future_size # 输出5个未来方向盘转角
model = LSTMModel(input_size, hidden_size, num_layers, output_size)# 3. 设置损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 4. 训练模型
num_epochs = 1000
for epoch in range(num_epochs):model.train()# 前向传播outputs = model(x_train_tensor)loss = criterion(outputs, y_train_tensor)# 后向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 5. 预测
model.eval()
with torch.no_grad():y_pred_tensor = model(x_test_tensor)y_pred = scaler_y.inverse_transform(y_pred_tensor.numpy()) # 将预测值逆归一化
y_test = scaler_y.inverse_transform(y_test_tensor.numpy()) # 逆归一化真实值# 评估指标
r2 = r2_score(y_test, y_pred, multioutput='uniform_average') # 多维输出下的R^2
mae_score = mae(y_test, y_pred)
print(f"R^2 score: {r2:.4f}")
print(f"MAE: {mae_score:.4f}")# 支持中文
plt.rcParams['font.sans-serif'] = ['SimSun'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 绘制未来5个方向盘转角的预测和真实值对比
plt.figure(figsize=(10, 6))
for i in range(future_size):plt.plot(range(len(y_test)), y_test[:, i], label=f'真实值 {i+1} 步', color='blue')plt.plot(range(len(y_pred)), y_pred[:, i], label=f'预测值 {i+1} 步', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle')
plt.title('未来5个方向盘转角的实际值与预测值对比图')
plt.legend()
plt.grid(True)
plt.show()# 计算预测和真实方向盘转角的平均值
y_pred_mean = np.mean(y_pred, axis=1) # 每个样本的5个预测值取平均
y_test_mean = np.mean(y_test, axis=1) # 每个样本的5个真实值取平均# 绘制平均值的实际值与预测值对比图
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test_mean)), y_test_mean, label='真实值(平均)', color='blue')
plt.plot(range(len(y_pred_mean)), y_pred_mean, label='预测值(平均)', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle (平均)')
plt.title('未来5个方向盘转角的平均值对比图')
plt.legend()
plt.grid(True)
plt.show()# 绘制第1个时间步的实际值与预测值对比图
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test[:, 0], label='真实值 (第1步)', color='blue')
plt.plot(range(len(y_pred)), y_pred[:, 0], label='预测值 (第1步)', color='red')
plt.xlabel('样本索引')
plt.ylabel('Steering Angle')
plt.title('未来第1步方向盘转角的实际值与预测值对比图')
plt.legend()
plt.grid(True)
plt.show()# 计算每个时间步的平均绝对误差
time_steps = y_test.shape[1]
mae_per_step = [mae(y_test[:, i], y_pred[:, i]) for i in range(time_steps)]# 绘制每个时间步的平均绝对误差
plt.figure(figsize=(10, 6))
plt.bar(range(1, time_steps + 1), mae_per_step, color='orange')
plt.xlabel('时间步')
plt.ylabel('MAE')
plt.title('不同时间步的平均绝对误差')
plt.grid(True)
plt.show()
5、输出结果;





五、LSTM变体
1、窥视孔连接(Peephole Connections)
- 引入者:Gers和Schmidhuber(2000年)
- 特征:允许门控层直接访问细胞状态,增强了对长期依赖的学习能力。
- 应用:通过让门控直接查看单元状态,可以更好地控制信息流动。

2、耦合的遗忘和输入门(Coupled Forget and Input Gates)
使用耦合的 forget 和 input 门。我们不是单独决定要忘记什么以及应该添加新信息什么,而是一起做出这些决定
- 特征:将遗忘门和输入门合并,决定何时忘记和输入新信息的过程是耦合的。
- 优点:简化了模型,同时可能提高了信息更新的效率,因为它只在特定条件下输入新值。

3、门控循环单元(GRU)
- 引入者:Cho等人(2014年)
- 特征:将遗忘门和输入门合并为一个更新门,并将细胞状态和隐藏状态合并为一个状态。
- 优点:结构更简单,计算效率高,越来越受到欢迎,尤其在一些任务上表现良好。

具体请看这篇文章:
时间序列预测(九)—门控循环单元网络(GRU)-CSDN博客
4、深度门控RNN(Deep Gated RNN)
- 引入者:Yao等人(2015年)
- 特征:在多个层次上使用门控结构,提升模型的表达能力。
- 优点:适应性强,能够捕捉更复杂的特征,特别适合于长序列数据。
5、Clockwork RNN
- 引入者:Koutnik等人(2014年)
- 特征:通过使用不同的时间步长来处理不同的时间序列信息,解决长期依赖问题。
- 优点:能够在不同时间尺度上学习,适合处理多时间尺度的数据。
6. Layer Normalization LSTM
- 引入者:Ba 等人 (2016年)
- 特征:在每一层的输入进行层归一化,改善训练过程中的稳定性。
- 优点:减少了内部协变量偏移,加速收敛,并且在许多任务中提升了模型性能。
7. Variational LSTM
- 引入者:未特定提及,但结合了变分推理的思路。
- 特征:通过变分推理处理不确定性和缺失数据。
- 优点:增强了模型的鲁棒性,适合于需要建模不确定性的任务。
8. Attention Mechanism
- 引入者:Bahdanau 等人 (2014年)
- 特征:为模型引入注意力机制,使其动态关注序列中的重要信息。
- 优点:提升了长序列数据的处理能力,特别在自然语言处理和机器翻译等领域取得显著效果。
9. Multi-Scale LSTM
- 引入者:未特定提及,但在多尺度学习的研究中得到广泛应用。
- 特征:在不同时间尺度上并行运行多个LSTM。
- 优点:能够捕捉多层次的时间特征,提高对复杂序列的建模能力。
10. Attention-Based LSTM
- 引入者:结合了Bahdanau等人的工作(2014年)。
- 特征:在LSTM中引入注意力机制,动态选择重要的信息。
- 优点:提高了在长序列中的预测准确性和模型的可解释性。
11. Hierarchical LSTM
- 引入者:未特定提及,但适用于处理层次结构数据。
- 特征:在多层次上对数据进行建模,适合复杂结构的数据(如文本、视频)。
- 优点:能够更好地捕捉上下文信息,适用于处理具有层次特征的数据集。
12. Context-Aware LSTM
- 引入者:未特定提及,通常在任务特定模型中使用。
- 特征:结合上下文信息,通过额外输入增强模型的决策能力。
- 优点:提升了模型在特定场景或条件下的适应性和准确性。
13. Temporal Convolutional Networks (TCN)
- 引入者:Bai 等人 (2018年)
- 特征:使用卷积操作替代递归结构处理序列数据。
- 优点:能有效处理长序列数据,具有并行化的优势,并且在许多任务中表现良好。
14. S4 (State Space for Sequence Modeling)
- 引入者:Tay et al. (2021年)
- 特征:结合了状态空间模型和深度学习,通过状态空间方程处理长序列。
- 优点:在长序列建模方面表现出色,能够捕捉长期依赖关系,同时计算效率较高。
15. Recurrent Neural Network with Sparse Connections
- 引入者:未特定提及,近年来在RNN结构中逐渐受到关注。
- 特征:通过稀疏连接减少参数量,提高计算效率。
- 优点:保持性能的同时,显著降低计算成本,适用于资源有限的场景。
16. BERT-Style LSTM
- 引入者:结合了BERT的思想与LSTM。
- 特征:通过自注意力机制增强LSTM的上下文理解能力。
- 优点:在文本理解和生成任务中表现出更好的效果,提升了模型的表达能力。
17. Graph Neural Networks with LSTM
- 引入者:在图神经网络与RNN结合的研究中逐渐发展。
- 特征:结合图结构数据与LSTM,用于处理图形序列数据。
- 优点:能够在具有图结构的序列数据中捕捉复杂的关系,适合社交网络和推荐系统等领域。
18. Attention-Based GRU
- 引入者:结合GRU和注意力机制的研究。
- 特征:在GRU中引入注意力机制,使其能够动态关注输入序列中的重要部分。
- 优点:提高了在长序列预测中的准确性和可解释性。
19. LSTM with External Memory
- 引入者:结合神经图灵机(Neural Turing Machines)等思路。
- 特征:在LSTM结构中引入外部记忆,增强信息存储和检索能力。
- 优点:能够处理更复杂的任务,如序列生成和推理,适合于需要长期记忆的应用。
20. LSTM with Reinforcement Learning
- 引入者:在强化学习与RNN结合的研究中得到应用。
- 特征:在LSTM训练过程中引入强化学习策略,优化决策过程。
- 优点:在动态和不确定环境中表现出色,能够适应实时决策任务。
参考文献:
《动手学深度学习》 — 动手学深度学习 2.0.0 documentation (d2l.ai)
如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博客
了解 LSTM 网络 -- colah 的博客
别忘了给这篇文章点个赞哦,非常感谢。我也正处于学习的过程,如果有问题,欢迎在评论区留言讨论,一起学习!

相关文章:
时间序列预测(十)——长短期记忆网络(LSTM)
目录 一、LSTM结构 二、LSTM 核心思想 三、LSTM分步演练 (一)初始化 1、权重和偏置初始化 2、初始细胞状态和隐藏状态初始化 (二)前向传播 1、遗忘门计算(决定从上一时刻隐状态中丢弃多少信息) 2、…...
Flink CDC 同步 Mysql 数据
文章目录 一、Flink CDC、Flink、CDC各有啥关系1.1 概述1.2 和 jdbc Connectors 对比 二、使用2.1 Mysql 打开 bin-log 功能2.2 在 Mysql 中建库建表准备2.3 遇到的坑2.4 测试 三、番外 一、Flink CDC、Flink、CDC各有啥关系 Flink:流式计算框架,不包含 …...

【python实战】-- 根据文件名分类
系列文章目录 文章目录 系列文章目录前言一、根据文件名分类到不同文件夹总结 前言 一、根据文件名分类到不同文件夹 汇总指定目录下所有满足条件的文件到新文件夹 import os import shutil import globsource_dir rD:\Users\gxcaoty\Desktop\39642 # 源目录路径 destinatio…...

蓝桥双周赛 第21场 小白入门赛
1 动态密码 思路:可以直接填空也可以写程序 void solve() {int a 20241111;stack<int> stk;while(a){stk.push(a % 2);a / 2;}while(stk.size()){cout << stk.top();stk.pop();}} 2 购物车里的宝贝 思路:总体异或和为0即可说明可分成一样…...
Linux 进程间通信 共享内存_消息队列_信号量
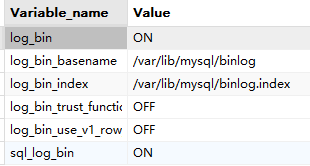
共享内存 共享内存是一种进程间通信(IPC)机制,它允许多个进程访问同一块内存区域。这种方法可以提高效率,因为数据不需要在进程之间复制,而是可以直接在共享的内存空间中读写。 使用共享内存的步骤通常包括:…...
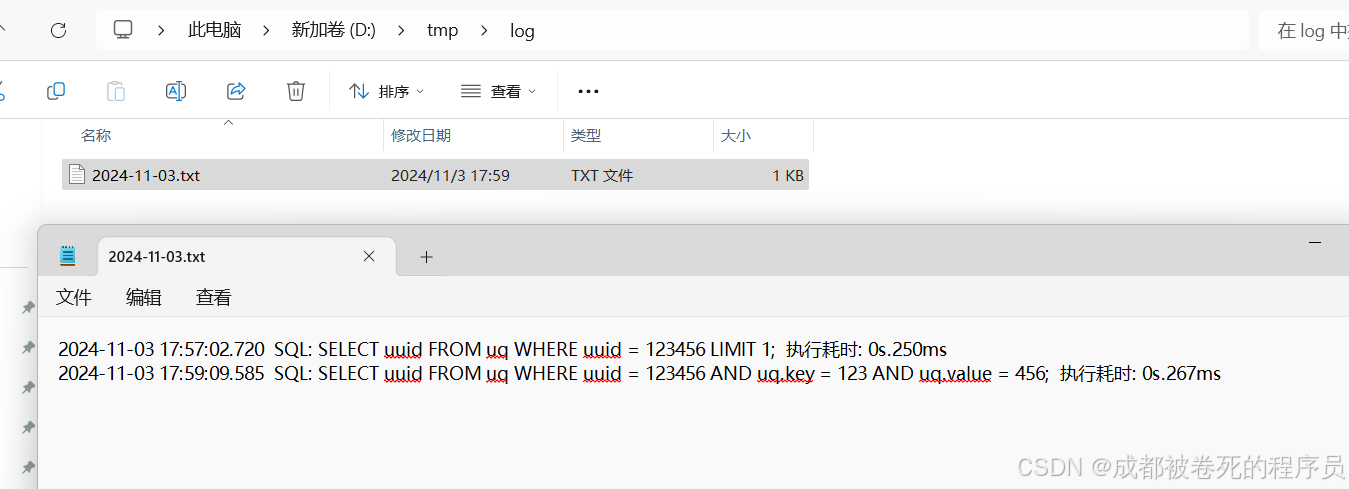
Mybatis自定义日志打印
一,目标 替换?为具体的参数值统计sql执行时间记录执行时间过长的sql,并输出信息到文档(以天为单位进行存储) 平常打印出来的sql都是sql一行,参数一行。如图: 二,理论 这里我们主要通过Mybatis…...

【在Linux世界中追寻伟大的One Piece】Socket编程TCP(续)
目录 1 -> V2 -Echo Server多进程版本 2 -> V3 -Echo Server多线程版本 3 -> V3-1 -多线程远程命令执行 4 -> V4 -Echo Server线程池版本 1 -> V2 -Echo Server多进程版本 通过每个请求,创建子进程的方式来支持多连接。 InetAddr.hpp #pragma…...

面试高频问题:C/C++编译时内存五个分区
在面试时,C/C++编译时内存五个分区是经常问到的问题,面试官通过这个问题来考察面试者对底层的理解。在平时开发时,懂编译时内存分区,也有助于自己更好管理内存。 目录 内存分区的定义 内存分区的重要性 代码区 数据区 BSS区 堆区 栈区 静态内存分配 动态内存分配…...
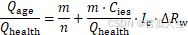
阅读博士论文《功率IGBT模块健康状态监测方法研究》
IGBT的失效可以分为芯片级失效和封装级失效。其中封装级失效是IGBT模块老化的主要原因,是多种因素共同作用的结果。在DBC的这种结构中,流过芯片的负载电流通过键合线传导到 DBC上层铜箔,再经过端子流出模块。DBC与芯片和提供机械支撑的基板之…...

Spring ApplicationContext接口
ApplicationContext接口是Spring框架中更高级的IoC容器接口,扩展了BeanFactory接口,提供了更多的企业级功能。ApplicationContext不仅具备BeanFactory的所有功能,还增加了事件发布、国际化、AOP、资源加载等功能。 ApplicationContext接口的…...
[perl] 数组与哈希
数组变量以 符号开始,元素放在括号内 简单举例如下 #!/usr/bin/perl names ("a1", "a2", "a3");print "\$names[0] $names[0]\n"; print "size: ",scalar names,"\n";$new_names shift(names); …...
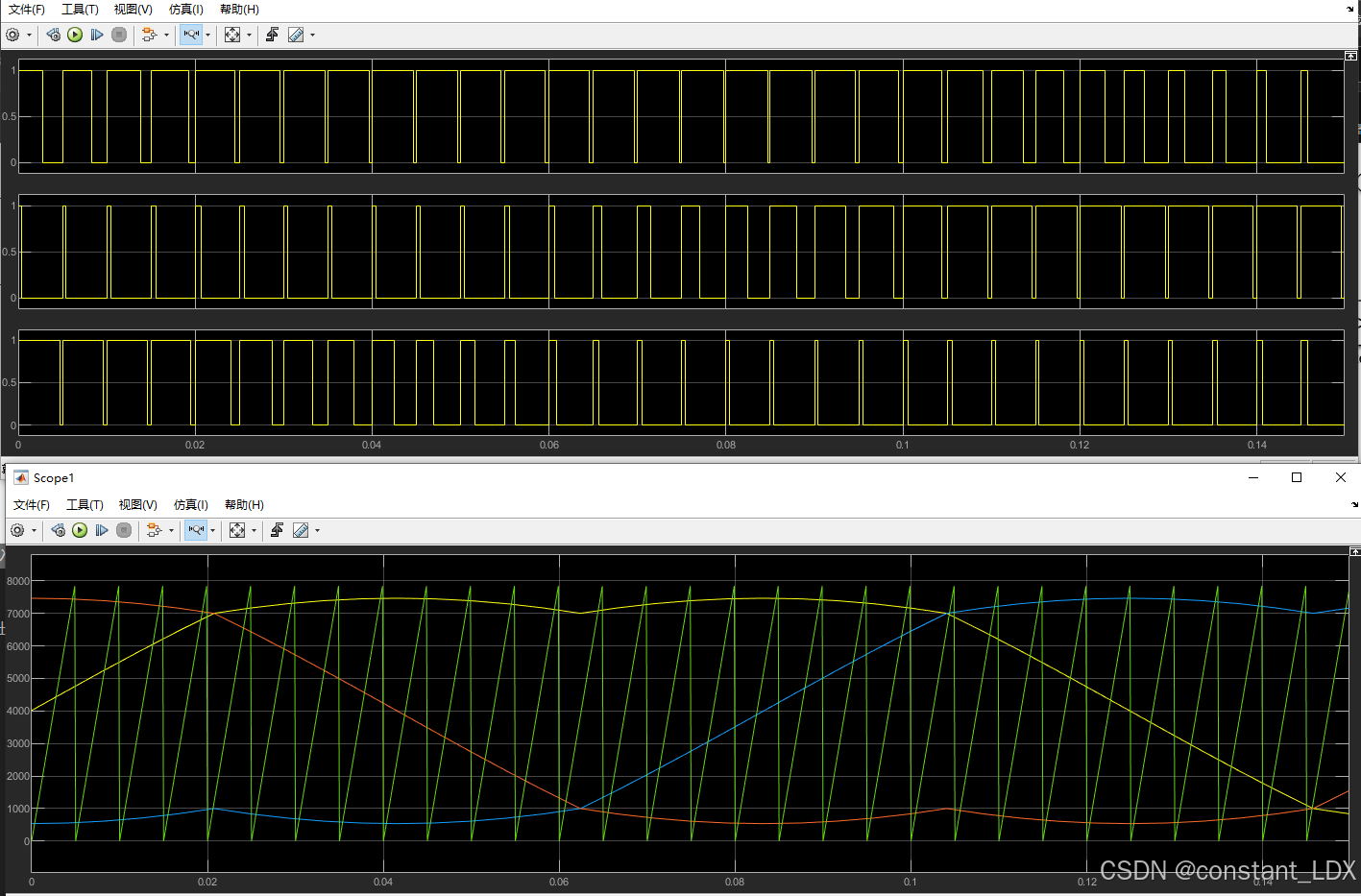
电机学习-SPWM原理及其MATLAB模型
SPWM原理及其MATLAB模型 一、SPWM原理二、基于零序分量注入的SPWM三、MATLAB模型 一、SPWM原理 SPWM其实是相电压的控制方式,定义三相正弦相电压的表达式: { V a m V m sin ω t V b m V m sin ( ω t − 2 3 π ) V c m V m sin ( ω t 2…...
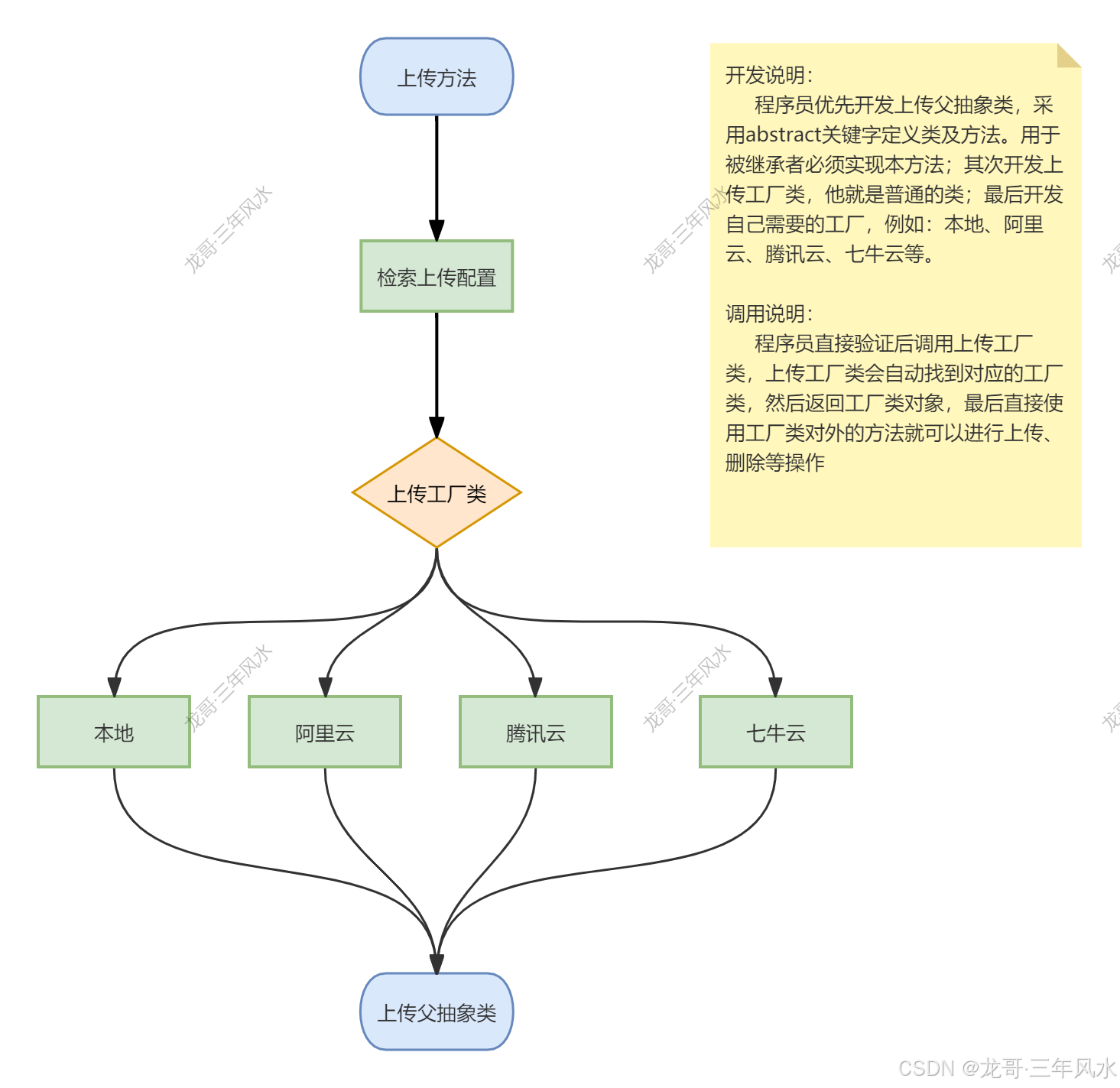
群控系统服务端开发模式-应用开发-腾讯云上传工厂及七牛云上传工厂开发
记住业务流程图,要不然不清楚自己封装的是什么东西。 一、腾讯云工厂开发 切记在根目录下要安装腾讯云OSS插件,具体代码如下: composer require qcloud/cos-sdk-v5 在根目录下extend文件夹下Upload文件夹下channel文件夹中,我们修…...

【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法
【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 文章目录 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和…...

《计算机原理与系统结构》学习系列——处理器(下)
系列文章目录 目录 流水线冒险数据冒险数据相关与数据冒险寄存器先读后写旁路取数使用型冒险阻塞 控制冒险分支引发的控制冒险假设分支不发生动态分支预测双预测位动态分支预测缩短分支延迟带冒险控制的单周期流水线图 异常MIPS中的异常MIPS中的异常处理另一种异常处理机制非精…...

JDK新特性(8-21)数据类型-直接内存
目录 Jdk 新特性 JDK 8 特性 默认方法实现作用:可以使接口更加灵活,不破坏现有实现的情况下添加新的方法。 函数式接口 StreamAPI JDK 9 特性 JDK 10 特性 JDK 11 特性 JDK 14 特性 JDK 17 特性 JDK 21 特性 数据类型 基本数据类型和引用数据类型的区别…...

003-Kotlin界面开发之声明式编程范式
概念本源 在界面程序开发中,有两个非常典型的编程范式:命令式编程和声明式编程。命令式编程是指通过编写一系列命令来描述程序的运行逻辑,而声明式编程则是通过编写一系列声明来描述程序的状态。在命令式编程中,程序员需要关心程…...

QT pro项目工程的条件编译
QT pro项目工程的条件编译 前言 项目场景:项目中用到同一型号两个相机,同时导入两个版本有冲突,编译不通过, 故从编译就区分相机导入调用,使用宏区分 一、定义宏 在pro文件中定义宏: DEFINES USE_Cam…...

深度学习之经典网络-AlexNet详解
AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,…...

部署Prometheus、Grafana、Zipkin、Kiali监控度量Istio
1. 模块简介 Prometheus 是一个开源的监控系统和时间序列数据库。Istio 使用 Prometheus 来记录指标,跟踪 Istio 和网格中的应用程序的健康状况。Grafana 是一个用于分析和监控的开放平台。Grafana 可以连接到各种数据源,并使用图形、表格、热图等将数据…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践
制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0的浪潮中,制造业企业面临着…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看
终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还…...
基于CircuitPython与NeoPixel打造可编程LED亚克力灯牌:从硬件选型到代码实现
1. 项目概述:打造你的专属可编程光之铭牌在创客和电子爱好者的世界里,总有一些项目能完美地融合软件编程的灵活性与硬件制作的实体成就感。今天要分享的,就是这样一个让我爱不释手的小玩意儿:一个基于CircuitPython和NeoPixel的可…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...

开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300%
开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300% 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款功能强大的开源PCB自动布线工具,它能帮…...