数据挖掘(六)
数据挖掘(六)
文章目录
- 数据挖掘(六)
- 消除歧义
- 从Twitter下载数据
- 加载数据集并分类
- 文本转换器
- 词袋
- N元语法
- 其他特征
- 朴素贝叶斯
- 贝叶斯定理
- 朴素贝叶斯算法
- 算法应用实例
- 应用
- 抽取特征
- 将字典转换为矩阵
- 训练朴素贝叶斯分类器
- 组装所有的部件
- 完整代码
本文使用朴素贝叶斯进行社会媒体挖掘,消除社交媒体用语的其一。朴素贝叶斯算法在计算用于分类的概率时,为了简化计算假设各个特征之间是相互独立的,稍微扩展就能用于对其他类型数据集进行分类,且不依赖于数值特征。
消除歧义
文本称为无结构格式,虽然包含很多信息,但是却没有标题、特定格式,语法松散以及其他问题,导致难以从中提取有用信息。数据间联系紧密,行文中经常相互提及,交叉引用现象也很常见,因此从这种格式中提取信息难度很大。文本挖掘的一个难点在于歧义。
从Twitter下载数据
- 以区分Twitter消息中Python的意思为例,一条消息称为tweet,最多不能超过140个字符。“#”号经常用来表示消息的主题。实验的目的是根据消息的内容判断消息中的Python是不是编程语言。
- 从Twitter网站中下载语料,剔除垃圾信息后用于分类任务。由于访问外网的限制,数据是通过网络途径获取。
加载数据集并分类
- 消息存储格式近似于JSON,JSON格式不会对数据强加过多用于表示结构的信息,可以直接用JavaScript语言读取。JSON定义了如数字、字符串、数组、字典等基本对象,适合存储包含非数值类型的数据。如果数据集全都是数值类型,为了节省空间和事件,最好使用类似于numpy矩阵这样的格式来存储。我们的数据集和JSON对象的区别在于,每两条消息之间有一行空行,目的是防止新追加的消息和前面的消息混在一起。我们使用json库解析数据集,需要先根据空行把度进行的文件拆分成一个列表得到真正的消息对象。
import os
import jsoninput_filename = os.path.join(os.getcwd(), 'data_mining', 'twitter', 'python_tweets.json')
classes_filename = os.path.join(os.getcwd(), 'data_mining', 'twitter', 'python_classes.json')
replicable_dataset = os.path.join(os.getcwd(), 'data_mining', 'twitter', 'replicable_dataset.json')
# tweets列表存储从文件中读进来的每条消息
tweets =[]
with open(input_filename) as inf:for line in inf:if len(line.strip()) == 0:continuetweets.append(json.loads(line)['text'])
print('加载了%d条tweets'%len(tweets))
加载了95条tweets
- 对于像Twitter这样禁止直接分享数据集的情况,我们可以只分享消息编号,把消息编号及其类别保存下来。保存所有消息的类别很容易,遍历数据集抽取编号,然而我们无法确定以后能再次获得所有消息,因此类别和消息可能就无法对应,我们只输出实际能用到的类别。首先创建列表存储我们能再次获取到的消息的类别,然后创建字典为消息的编号和类别建立起映射关系。
tweets =[]
labels = []
with open(input_filename) as inf:for line in inf:if len(line.strip()) == 0:continuetweets.append(json.loads(line))
with open(classes_filename) as inf:labels = json.load(inf)
dataset = [(tweet['id'], label) for tweet, label in zip(tweets, labels)]
# 把结果保存到replicable_dataset.json
with open(replicable_dataset, 'w') as outf:json.dump(dataset, outf)
文本转换器
词袋
- 文本数据集包括图书、文章、网站、手稿、代码以及其他形式的文本,有多种测量方法可以吧文本转换成算法可以处理的形式。比如平均词长和平均句长可以用来预测文本的可读性,还有单词是否出现等。
- 一种最简单高效的模型是只统计数据集中每个单词的出现次数,我们创建一个矩阵,每行表示数据集中的一篇文档,每列代表一个词。矩阵中的每项为某个词在文档中的出现次数。
from collections import Counter
# 统计单词时通常把所有字母转换为小写
s = """She is such a charming woman, it's hard to forget""".lower()
words = s.split()
# Counter方法统计列表汇总各字符串出现次数
c = Counter(words)
# 输出出现次数最多的前5个单词
c.most_common(5)
- 词袋模型主要分为三种:第一种是使用词语实际出现次数作为词频,缺点是当文档长度差异明显时,词频差距会非常大。第二种是使用归一化后的词频,每篇文档中所有词语的词频之和为1,规避了文档长度对词频的影响。第三种是使用二值特征来表示,单词在文档中出现值为1,不出现值为0。更通用的规范化方法叫做词频逆文档频率法(tf-idf),该加权方法用词频来代替词的出现次数,然后再用词频除以包含该词的文档的数量。Python有很多用于处理文本的库,比如NLTK自然语言处理工具集库,在分词方面提供了更多选择。
N元语法
- 比起用单个词作特征,使用N元语法能更好地描述文档,N元语法指由几个连续的词组成的子序列,可以理解为每条消息里一组连续的词。N元语法的计算方法和计算单个词语方法相同,我们把构成N元语法的几个词看成是词袋中的一个词。N元语法作为特征的数据集中每一项就变成了N元语法在给定文档中的词频。
- N元语法中的参数n,对于英语而言,一开始取2到5个值就可以,有些应用可能要使用更高的值。比如说当n取3时,我们从*Always look on the bright side of life.*中抽取前几个N元语法。第一个三元语法是Always look on,第二个是look on the,第三个是on the bright。几个N元语法有重合,其中三个词有不同程度的重复。
- N元语法比起单个词的优点是不用通过大量的计算,就提供了有助于理解词语用法的上下文信息,缺点是特征矩阵变得更为稀疏。对于社交媒体所产生的的内容以及其他短文档,N元语法不可能出现在多篇不同的文档中,除非是转发。然而在长文档中,N元语法就很有效。文档的另一种N元语法关注的不是一组词而是一组字符,字符N元语法有助于发现拼写错误。
其他特征
- 除了N元语法外,还可以抽取句法特征比如特定词语在句子中的用法。对于需要理解文本含义的数据挖掘应用,往往会用到词性。
朴素贝叶斯
贝叶斯定理
- 朴素贝叶斯概率模型是对贝叶斯统计方法的朴素解释为基础的,特征类型和形式多样的数据集可以用它进行分类。从频率轮者角度出发看问题的思想,假定数据遵从某种分布,我们的目标是确定该种分布的几个参数,我们假定参数是固定的,然后用自己的模型来套用数据,甚至通过测试来证明数据与我们的模型相吻合。相反,贝叶斯统计实际上是根据普通人实际的推理方式来建模。我们用拿到的数据来更新模型对某事件即将发生的可能性的预测结果。
- 在贝叶斯统计学中,我们使用数据来描述模型,而不是使用模型来描述数据。贝叶斯定理只在计算在已知B发生的情况下,A发生的概率是多少,即P(A|B)的值。大多数情况下B是被观察事件,A是预测结果。对于数据挖掘来说,B通常是观察样本个体,A是被预测个体所属类别。
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)
相关文章:
)
数据挖掘(六)
数据挖掘(六) 文章目录 数据挖掘(六)消除歧义从Twitter下载数据加载数据集并分类文本转换器词袋N元语法其他特征朴素贝叶斯贝叶斯定理朴素贝叶斯算法算法应用实例应用抽取特征将字典转换为矩阵训练朴素贝叶斯分类器组装所有的部件完整代码本文使用朴素贝叶斯进行社会媒体挖…...

Netty 组件介绍 - Channel
主要作用 close()可以用来关闭 channelcloseFuture()用来处理 channel 的关闭sync方法作用是同步等待 channel 关闭而 addListener 方法是异步等待 channel 关闭pipeline()方法添加处理器write()方法将数据写入writeAndFlush()方法将数据写入并刷出...

时间序列预测(十)——长短期记忆网络(LSTM)
目录 一、LSTM结构 二、LSTM 核心思想 三、LSTM分步演练 (一)初始化 1、权重和偏置初始化 2、初始细胞状态和隐藏状态初始化 (二)前向传播 1、遗忘门计算(决定从上一时刻隐状态中丢弃多少信息) 2、…...
Flink CDC 同步 Mysql 数据
文章目录 一、Flink CDC、Flink、CDC各有啥关系1.1 概述1.2 和 jdbc Connectors 对比 二、使用2.1 Mysql 打开 bin-log 功能2.2 在 Mysql 中建库建表准备2.3 遇到的坑2.4 测试 三、番外 一、Flink CDC、Flink、CDC各有啥关系 Flink:流式计算框架,不包含 …...

【python实战】-- 根据文件名分类
系列文章目录 文章目录 系列文章目录前言一、根据文件名分类到不同文件夹总结 前言 一、根据文件名分类到不同文件夹 汇总指定目录下所有满足条件的文件到新文件夹 import os import shutil import globsource_dir rD:\Users\gxcaoty\Desktop\39642 # 源目录路径 destinatio…...

蓝桥双周赛 第21场 小白入门赛
1 动态密码 思路:可以直接填空也可以写程序 void solve() {int a 20241111;stack<int> stk;while(a){stk.push(a % 2);a / 2;}while(stk.size()){cout << stk.top();stk.pop();}} 2 购物车里的宝贝 思路:总体异或和为0即可说明可分成一样…...
Linux 进程间通信 共享内存_消息队列_信号量
共享内存 共享内存是一种进程间通信(IPC)机制,它允许多个进程访问同一块内存区域。这种方法可以提高效率,因为数据不需要在进程之间复制,而是可以直接在共享的内存空间中读写。 使用共享内存的步骤通常包括:…...
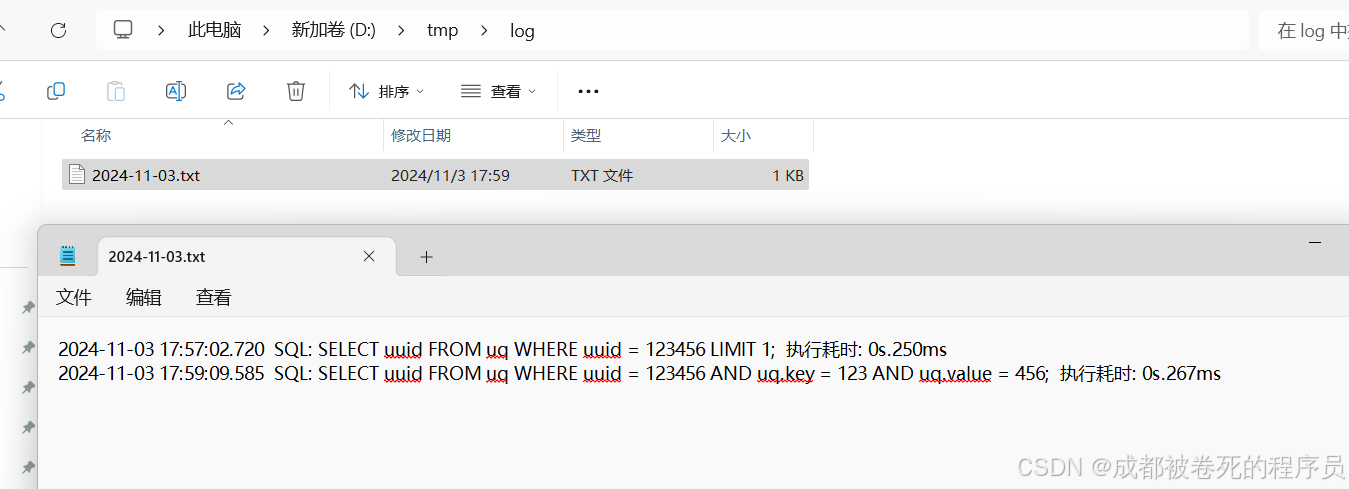
Mybatis自定义日志打印
一,目标 替换?为具体的参数值统计sql执行时间记录执行时间过长的sql,并输出信息到文档(以天为单位进行存储) 平常打印出来的sql都是sql一行,参数一行。如图: 二,理论 这里我们主要通过Mybatis…...

【在Linux世界中追寻伟大的One Piece】Socket编程TCP(续)
目录 1 -> V2 -Echo Server多进程版本 2 -> V3 -Echo Server多线程版本 3 -> V3-1 -多线程远程命令执行 4 -> V4 -Echo Server线程池版本 1 -> V2 -Echo Server多进程版本 通过每个请求,创建子进程的方式来支持多连接。 InetAddr.hpp #pragma…...

面试高频问题:C/C++编译时内存五个分区
在面试时,C/C++编译时内存五个分区是经常问到的问题,面试官通过这个问题来考察面试者对底层的理解。在平时开发时,懂编译时内存分区,也有助于自己更好管理内存。 目录 内存分区的定义 内存分区的重要性 代码区 数据区 BSS区 堆区 栈区 静态内存分配 动态内存分配…...
阅读博士论文《功率IGBT模块健康状态监测方法研究》
IGBT的失效可以分为芯片级失效和封装级失效。其中封装级失效是IGBT模块老化的主要原因,是多种因素共同作用的结果。在DBC的这种结构中,流过芯片的负载电流通过键合线传导到 DBC上层铜箔,再经过端子流出模块。DBC与芯片和提供机械支撑的基板之…...

Spring ApplicationContext接口
ApplicationContext接口是Spring框架中更高级的IoC容器接口,扩展了BeanFactory接口,提供了更多的企业级功能。ApplicationContext不仅具备BeanFactory的所有功能,还增加了事件发布、国际化、AOP、资源加载等功能。 ApplicationContext接口的…...
[perl] 数组与哈希
数组变量以 符号开始,元素放在括号内 简单举例如下 #!/usr/bin/perl names ("a1", "a2", "a3");print "\$names[0] $names[0]\n"; print "size: ",scalar names,"\n";$new_names shift(names); …...
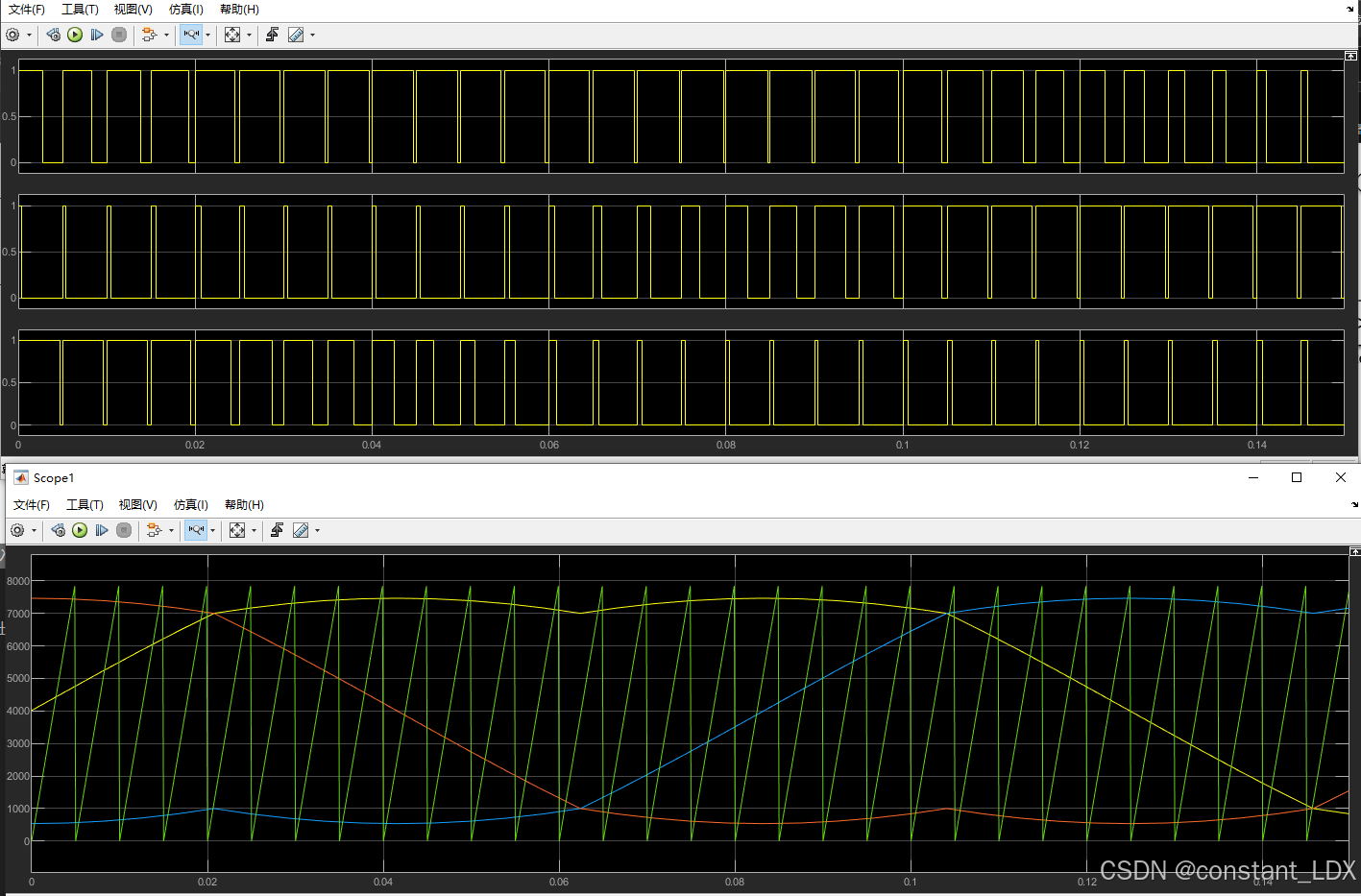
电机学习-SPWM原理及其MATLAB模型
SPWM原理及其MATLAB模型 一、SPWM原理二、基于零序分量注入的SPWM三、MATLAB模型 一、SPWM原理 SPWM其实是相电压的控制方式,定义三相正弦相电压的表达式: { V a m V m sin ω t V b m V m sin ( ω t − 2 3 π ) V c m V m sin ( ω t 2…...
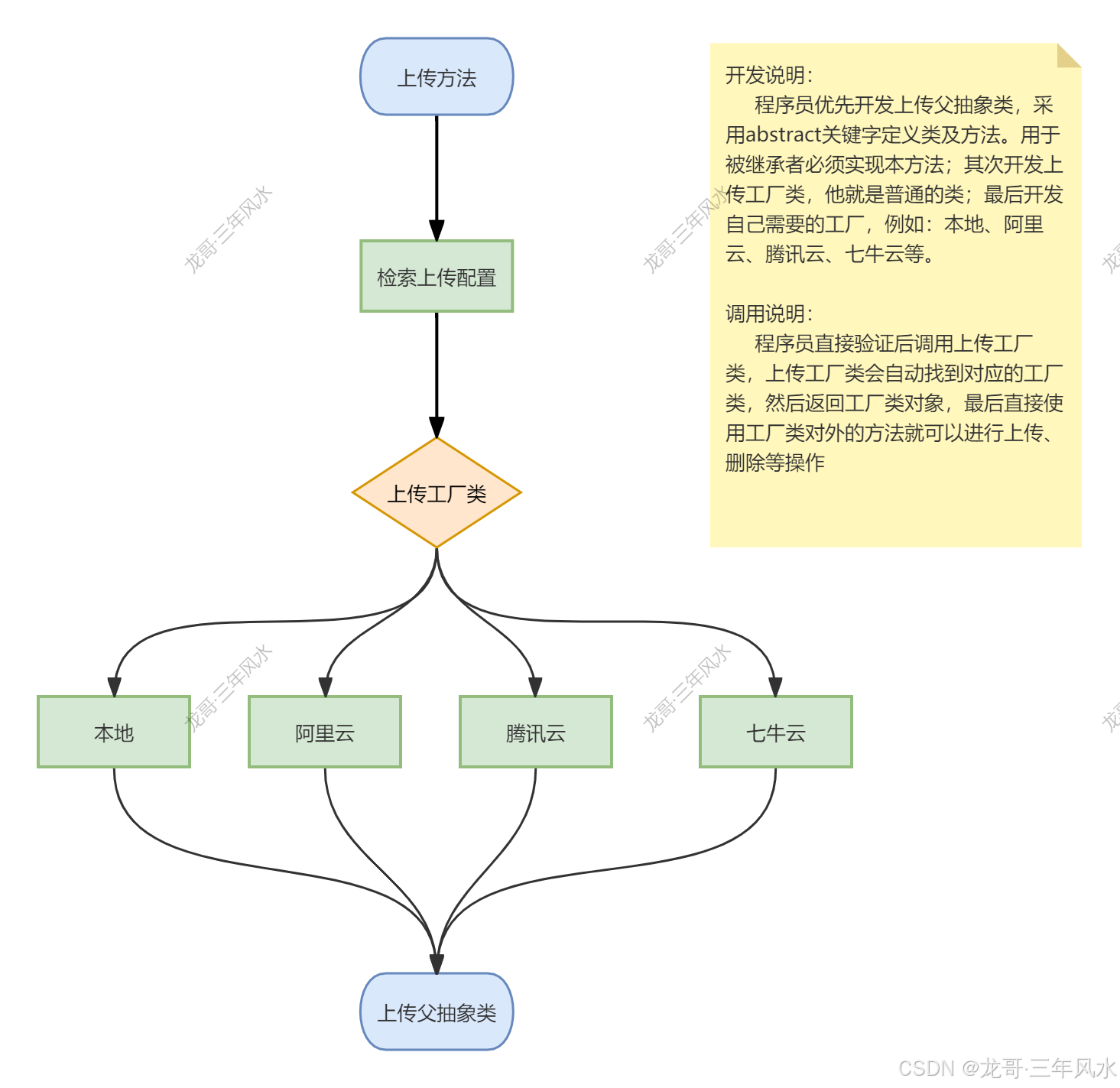
群控系统服务端开发模式-应用开发-腾讯云上传工厂及七牛云上传工厂开发
记住业务流程图,要不然不清楚自己封装的是什么东西。 一、腾讯云工厂开发 切记在根目录下要安装腾讯云OSS插件,具体代码如下: composer require qcloud/cos-sdk-v5 在根目录下extend文件夹下Upload文件夹下channel文件夹中,我们修…...

【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法
【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 文章目录 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和…...

《计算机原理与系统结构》学习系列——处理器(下)
系列文章目录 目录 流水线冒险数据冒险数据相关与数据冒险寄存器先读后写旁路取数使用型冒险阻塞 控制冒险分支引发的控制冒险假设分支不发生动态分支预测双预测位动态分支预测缩短分支延迟带冒险控制的单周期流水线图 异常MIPS中的异常MIPS中的异常处理另一种异常处理机制非精…...

JDK新特性(8-21)数据类型-直接内存
目录 Jdk 新特性 JDK 8 特性 默认方法实现作用:可以使接口更加灵活,不破坏现有实现的情况下添加新的方法。 函数式接口 StreamAPI JDK 9 特性 JDK 10 特性 JDK 11 特性 JDK 14 特性 JDK 17 特性 JDK 21 特性 数据类型 基本数据类型和引用数据类型的区别…...

003-Kotlin界面开发之声明式编程范式
概念本源 在界面程序开发中,有两个非常典型的编程范式:命令式编程和声明式编程。命令式编程是指通过编写一系列命令来描述程序的运行逻辑,而声明式编程则是通过编写一系列声明来描述程序的状态。在命令式编程中,程序员需要关心程…...

QT pro项目工程的条件编译
QT pro项目工程的条件编译 前言 项目场景:项目中用到同一型号两个相机,同时导入两个版本有冲突,编译不通过, 故从编译就区分相机导入调用,使用宏区分 一、定义宏 在pro文件中定义宏: DEFINES USE_Cam…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

Applite:告别命令行!macOS软件管理的图形化终极解决方案
Applite:告别命令行!macOS软件管理的图形化终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Homebrew复杂的命令行操作而头疼吗&…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...
搞定Linux视频编解码缓冲区)
别再为嵌入式设备大内存发愁了!手把手教你用CMA(连续内存分配器)搞定Linux视频编解码缓冲区
嵌入式多媒体开发中的连续内存优化实战:CMA技术深度解析 在嵌入式多媒体开发领域,视频编解码、图像处理等任务对内存管理提出了严苛要求。当你在树莓派上部署视频监控系统,或在工业摄像头中实现实时H.264编码时,是否经常遇到这样的…...

【仅限前200名】Midjourney铂金印相专属Prompt库泄露:含17组经暗房验证的--v 6.2参数矩阵与胶片光谱校准模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney铂金印相的光学本质与历史语境 铂金印相(Platinum Print)并非数字时代的产物,而是一种诞生于1873年的古典摄影工艺——其影像由铂族金属(主要是…...

如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解
如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

LC正弦波振荡器原理、设计与调试:从巴克豪森判据到电路实战
1. 从直流到交流:正弦波振荡器的核心价值与分类在电子电路的世界里,我们常常需要将稳定的直流电源,转换成特定频率和幅度的交流信号。这个看似“无中生有”的过程,正是正弦波振荡器的核心使命。无论是你手机里的无线通信模块、收音…...

云原生安全工具:保护云原生环境
云原生安全工具:保护云原生环境 一、云原生安全工具概述 1.1 云原生安全工具的定义 云原生安全工具是指专为云原生环境设计的安全工具和解决方案。它们用于保护容器、Kubernetes集群、微服务和Serverless应用的安全。 1.2 云原生安全工具的价值 安全防护:…...