正式开源:从 Greenplum 到 Cloudberry 迁移工具 cbcopy 发布
Cloudberry Database 作为 Greenplum 衍生版本和首选开源替代,由 Greenplum 原始团队成员创建,与 Greenplum 保持原生兼容,并能实现无缝迁移,且具备更新的 PostgreSQL 内核和更丰富的功能。
GitHub: https://github.com/cloudberrydb/cloudberrydb
Hi 社区小伙伴们!酷克数据 HashData 正式宣布:大家期待已久的从 Greenplum 到 Cloudberry 数据迁移工具 cbcopy 正式开源啦!
- GitHub 仓库:https://github.com/hashDataInc/cbcopy/
从今日起,大家可以访问 GitHub 仓库,获取 cbcopy 源代码以及快速使用指南,期待大家积极反馈使用过程中遇到的问题、以及期待的新增功能与优化。
背景
随着 Greenplum 走向闭源,Cloudberry Database 成为 Greenplum 的开源替代首选,同时众多开源 Greenplum 数据库用户也面临着将数据迁移至 Cloudberry Database 的迫切需求。部分用户会通过相关数据备份和恢复工具将数据先导出、再导入的方式进行数据迁移。然而,这种曲线方式的局限性在迁移数据量巨大时变得尤为突出——当数据量攀升至几 TB 乃至更高,迁移效率便成为了一个不容小觑的难题,往往耗时极长,甚至可能长达数天,这无疑给企业的业务连续性和数据管理能力带来了前所未有的挑战。
为了破解这一迁移瓶颈、提升迁移效率,我们推出了全新的开源数据迁移工具——cbcopy。cbcopy 专为解决大规模数据迁移中的效率难题而生,凭借其技术设计与深度优化,实现了 Greenplum 与 Cloudberry 之间数据的高效、稳定迁移。本文将剖析 cbcopy 的特点、功能及其在实际迁移场景中的表现,为正在寻求从 Greenplum 到 Cloudberry 数据迁移解决方案的社区成员提供参考。
什么是 cbcopy
cbcopy 是一款功能强大的数据迁移工具,支持将 Greenplum 数据库集群(包括元数据和数据)迁移到 Cloudberry 数据库集群,并支持在不同 Cloudberry 数据库集群之间进行数据迁移,从而满足灾难恢复、数据迁移以及特定版本升级等多种需求。cbcopy 具备高度的可扩展性、灵活性和性能优化能力,通过简化迁移流程、缩短迁移时间,cbcopy 助力用户实现业务连续性的最大化,同时降低迁移过程中的风险和成本。
cbcopy 支持从 Greenplum 4.x、5.x、6.x 迁移到 Cloudberry,并支持 Cloudberry 1.x 系列版本升级。
主要优势
更加稳定、高效的性能:相较于传统迁移工具,cbcopy 在迁移大数据量时表现更为出色,显著缩短迁移时间,降低迁移过程中的风险和成本。
灵活的架构设计:cbcopy 的架构设计兼顾灵活性与高效性,能够适配多样的迁移场景。无论是等量节点迁移、大集群至小集群的精简,还是小集群向大集群的扩展,cbcopy 都能通过智能的数据重分布机制,确保数据在新环境中的最优布局。
压缩传输,成本优化:cbcopy 内置多种高效压缩算法(如 snappy、zlib、zstd 等),有效减少传输数据量,降低对网络带宽的依赖。即使在带宽有限的环境下,也能保证迁移的高效与稳定,为用户节省宝贵的资源和成本。
智能的迁移策略:cbcopy 根据源集群的统计信息,智能判断表的大小,并选择最优的迁移策略。对于大表,利用计算节点的并行处理能力和通信带宽进行迁移;对于小表,则直接在 coordinator 节点之间传输数据。
工作原理
元数据迁移
cbcopy 的元数据迁移功能建立在 gpbackup 和 gprestore 的基础之上,与 GPDB 内置的 pg_dump 工具相比,cbcopy 展现出了显著的性能优势。其核心竞争力在于采用批量检索元数据的方式,而非 pg_dump 所使用的一行一行获取元数据的方法。这种批量处理方式,在迁移大量元数据时,能大幅度提升迁移效率。
数据迁移
在数据迁移方面,GPDB 和 CBDB 均支持通过 SQL 命令来启动程序,cbcopy 正是利用这一功能来实现高效的数据迁移。具体迁移过程中,cbcopy 会在目标数据库上启动程序以接收和加载数据,同时在源数据库上启动程序以卸载数据并将其发送到目标数据库的程序。
架构设计
cbcopy 的架构设计如下图所示,特别适用于源集群(如 Greenplum Database 集群)与目标集群(Cloudberry Database 集群)计算节点数量相同的情况。
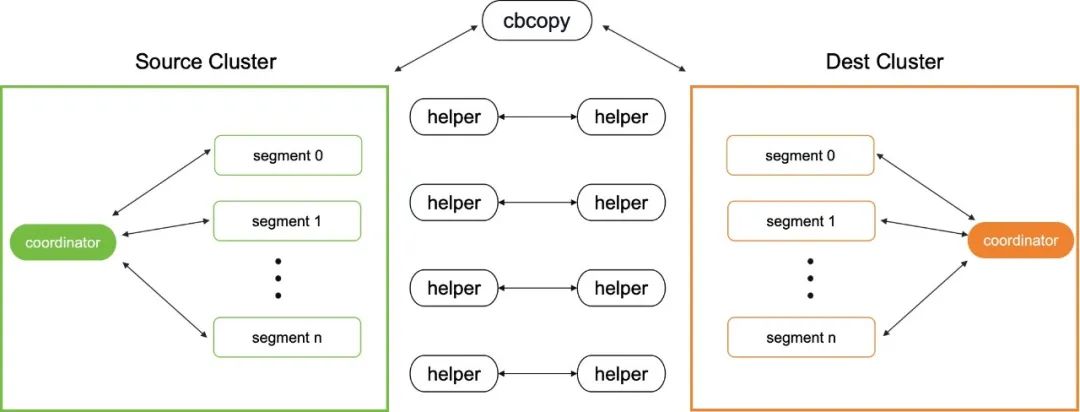 cbcopy 架构图
cbcopy 架构图
由上图可以看到,cbcopy 架构设计直观明了,在源集群与目标集群的计算节点之间建立一一对应关系,直接实现数据的高效迁移,充分发挥所有计算节点的并行处理能力和通信带宽的优势。
cbcopy 内部支持三种表复制策略:
Copy On Coordinator:当表的统计值 pg_class->reltuples 小于 --on-segment-threshold 时,cbcopy 将采用此策略。这表示数据迁移仅限于通过协调节点在源数据库和目标数据库之间进行。
Copy On Segment:若表的统计量 pg_class->reltuples 大于 --on-segment-threshold,且源数据库与目标数据库版本相同且节点数量一致,cbcopy 将启用此策略。这意味着数据迁移将在所有 segment 节点上并行执行,无需数据重分布。
Copy on External Table:对于不满足上述两种策略条件的表,cbcopy 将采用此外部表复制策略。此策略下,数据迁移将在所有 segment 节点上并行执行并进行重分布。
功能实践
cbcopy 主要支持四种级别的数据库对象迁移:整个集群,指定数据库,指定命名空间和指定表。迁移过程包含两部分,首先是迁移元数据,也就是数据库对象的定义;其次是用户表数据的迁移。
- 集群迁移
将一个集群完整迁移到另外一个集群,包括所有的元数据和数据。以下为示意例子:
cbcopy --source-host=127.0.0.1 --source-port=15432 --source-user=cdw --dest-host=127.0.0.1 --dest-port=25432 --dest-user=cdw1 –full
重要参数说明:
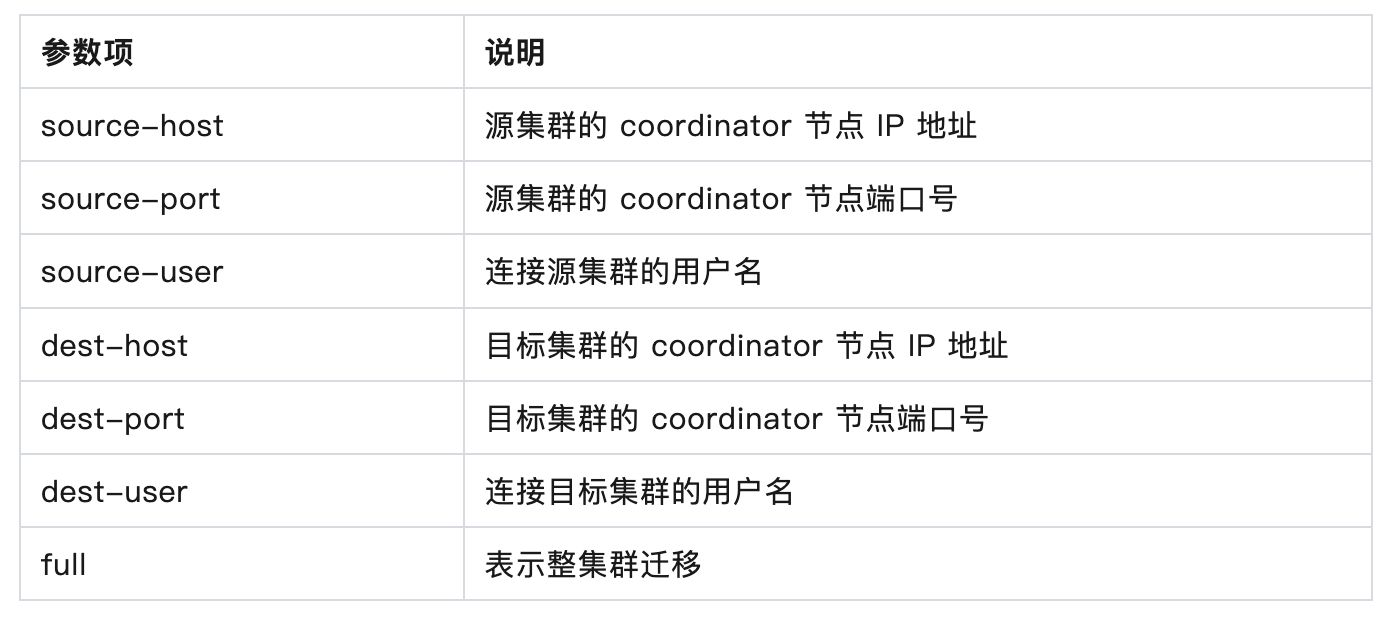
数据库迁移
将源集群的某个数据库完整迁移到另外一个集群,如果目标集群不存在同名数据库,则会创建一个新的数据库。以下为示意例子:
cbcopy --source-host=127.0.0.1 --source-port=15432 --source-user=cdw --dest-host=127.0.0.1 --dest-port=25432 --dest-user=cdw1 --dbname="gpadmin" --truncate
重要参数说明:

命名空间迁移
将源集群的某个数据库下的某个命名空间(schema)迁移到另外一个集群,如果目标集群不存在同名命名空间,则会创建一个新的命名空间。以下为示意例子:
cbcopy --source-host=127.0.0.1 --source-port=15432 --source-user=cdw --dest-host=127.0.0.1 --dest-port=25432 --dest-user=cdw1 --schema="gpadmin.schema1" --truncate
重要参数说明:

- 表迁移
将源集群的某些表迁移到另外一个集群,如果目标集群不存在同名表,则会创建新的表。以下为示意例子:
cbcopy --source-host=127.0.0.1 --source-port=15432 --source-user=cdw --dest-host=127.0.0.1 --dest-port=25432 --dest-user=cdw1 --include-table="gpadmin.public.aaa,gpadmin.public.bbb" --truncate
重要参数说明:

更多配置详情与使用方法,欢迎访问 GitHub README 文档查看了解,期待大家积极分享使用体验与意见建议!
推荐阅读
• 写在 Greenplum 归档之际:Cloudberry Database 接棒再出发
• Cloudberry Database 社区月报(202408):1.6.0 全新发布!
• Cloudberry Database 社区月报(202407):首次社区聚会成功举办!
• Cloudberry Database 社区月报(202406):更多工具开源
• Cloudberry Database 社区月报(202405):上榜 GitHub 热门项目
• Cloudberry Database 社区月报(202404):1.5.2 版本发布
• Cloudberry Database 社区月报(202403):1.5.1 版本发布
• Cloudberry Database 社区月报(202402):1.5.0 版本发布
• Cloudberry Database 社区月报(202401):Roadmap 2024 发布
引用链接
[1] Github地址: https://github.com/hashDataInc/cbcopy/
[2] 《贡献指南》: https://cloudberrydb.org/contribute
[3] 支持页面: https://cloudberrydb.org/support
相关文章:
正式开源:从 Greenplum 到 Cloudberry 迁移工具 cbcopy 发布
Cloudberry Database 作为 Greenplum 衍生版本和首选开源替代,由 Greenplum 原始团队成员创建,与 Greenplum 保持原生兼容,并能实现无缝迁移,且具备更新的 PostgreSQL 内核和更丰富的功能。GitHub: https://github.com/cloudberry…...

Python如何读写文件?
1. 文件读取 (1)使用open()函数打开文件 基本语法是file_object open(file_name, mode),其中file_name是要打开的文件的名称(包括路径,如果文件不在当前目录下),mode是打开文件的模式。例如&a…...

100种算法【Python版】第38篇——Boyer-Moore算法
本文目录 1 算法说明2 算法示例3 python代码1 算法说明 Boyer-Moore算法由Robert S. Boyer和J. Strother Moore于1977年提出,旨在提高字符串匹配的效率。该算法在寻找固定模式的过程中,利用模式本身的信息,优化搜索过程,特别适合长文本中的模式查找。 算法原理 Boyer-Moo…...

贪心算法---java---黑马
贪心算法 1)Greedy algorithm 称之为贪心算法或者贪婪算法,核心思想是 将寻找最优解的问题分为若干个步骤每一步骤都采用贪心原则,选取当前最优解因为未考虑所有可能,局部最优的堆叠不一定得到最终解最优 贪心算法例子 Dijkstra while …...

程序员的减压秘籍:高效与健康的平衡艺术
引言 在当今竞争激烈的科技行业中,程序员常常面临着极高的精神集中要求和持续的创新压力。这种工作性质让许多程序员在追求高效和创新的过程中,感到精疲力竭,面临身心健康的挑战。因此,找到有效的方法来缓解工作压力,…...

2024 年 QEMU 峰会纪要
2024 年 QEMU 峰会已于 10 月 31 日在 KVM 论坛召开,这是一个仅对项目中最活跃的维护者和子维护者开放的邀请会议。 出席者: Dan Berrang Cdric Le Goater Kevin Wolf Michael S. Tsirkin Stefan Hajnoczi Philippe Mathieu-Daud Markus Armbruster Th…...

C++/list
目录 1.list的介绍 2.list的使用 2.1list的构造 2.2list iterator的使用 2.3list capacity 2.4list element access 2.5list modifers 2.6list的迭代器失效 3.list的模拟实现 4.list与vector的对比 欢迎 1.list的介绍 list的文档介绍 cplusplus.com/reference/list/li…...

刘艳兵-DBA015-对于属于默认undo撤销表空间的数据文件的丢失,哪条语句是正确的?
对于属于默认undo撤销表空间的数据文件的丢失,哪条语句是正确的? A 所有未提交的交易都将丢失。 B 数据库实例中止。 C 数据库处于MOUNT状态,需要恢复才能打开。 D 数据库保持打开状态以供查询,但除具有SYSDBA特权的用…...
树莓派基本设置--10.使用MIPI摄像头
树莓派5将以前的CSI和DSI接口合并成两个两用的CSI/DSI(MIPI)端口。 一、配置摄像头 使用树莓派摄像头或第三方相机可以按照下面表格修改相机配置: 摄像头模块文件位于:/boot/firmware/config.txtV1 相机 (OV5647&am…...

【ARCGIS实验】地形特征线的提取
目录 一、提取不同位置的地形剖面线 二、将DEM转化为TIN 三、进行可视分析 四、进行山脊、山谷等特征线的提取 1、正负地形提取(用于校正) 2、山脊线提取 3、山谷线的提取 4、河网的提取 5、流域的分割 五、鞍部点的提取 1、背景 2、目的 3…...

HTML 基础标签——表格标签<table>
文章目录 1. `<table>` 标签:定义表格2. `<tr>` 标签:定义表格行3. `<th>` 标签:定义表头单元格4. `<td>` 标签:定义表格单元格5. `<caption>` 标签:为表格添加标题6. `<thead>` 标签:定义表格头部7. `<tbody>` 标签:定义表格…...

线程函数和线程启动的几种不同形式
线程函数和线程启动的几种不同形式 在C中,线程函数和线程启动可以通过多种形式实现。以下是几种常见的形式,并附有相应的示例代码。 1. 使用函数指针启动线程 最基本的方式是使用函数指针来启动线程。 示例代码: #include <iostream&g…...

数组排序简介-基数排序(Radix Sort)
基本思想 将整数按位数切割成不同的数字,然后从低位开始,依次到高位,逐位进行排序,从而达到排序的目的。 算法步骤 基数排序算法可以采用「最低位优先法(Least Significant Digit First)」或者「最高位优先…...

进程间通信(命名管道 共享内存)
文章目录 命名管道原理命令创建命名管道函数创建命名管道 共享内存原理shmgetFIOK 代码应用:premsnattch 命名管道 用于两个毫无关系的进程间的通信。 原理 Linux文件的路径是多叉树,故文件的路径是唯一的。 让内核缓冲区不用刷新到磁盘中,…...

Python 网络爬虫教程:从入门到高级的全面指南
Python 网络爬虫教程:从入门到高级的全面指南 引言 在信息爆炸的时代,网络爬虫(Web Scraping)成为了获取数据的重要工具。Python 以其简单易用的特性,成为了网络爬虫开发的首选语言。本文将详细介绍如何使用 Python …...
详细解释)
深度学习:正则化(Regularization)详细解释
正则化(Regularization)详细解释 正则化(Regularization)是机器学习和统计建模领域中用以防止模型过拟合同时增强模型泛化能力的一种技术。通过引入额外的约束或惩罚项到模型的损失函数中,正则化能够有效地限制模型的…...

Freertos学习日志(1)-基础知识
目录 1.什么是Freertos? 2.为什么要学习RTOS? 3.Freertos多任务处理的原理 1.什么是Freertos? RTOS,即(Real Time Operating System 实时操作系统),是一种体积小巧、确定性强的计算机操作系统…...

CentOS9 Stream 支持输入中文
CentOS9 Stream 支持输入中文 方法一:确保 gnome-control-center 和相关组件已更新方法二:手动添加输入法源配置方法三:配置 .xinputrc 文件方法四:检查语言包 进入centos9 stream后,点击右上角电源键,点击…...

基于向量检索的RAG大模型
一、什么是向量 向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (𝑥,𝑦) ,表示从原点 (0,0)到点 (𝑥,𝑦)的有向线段。 1.1、文本向量 1…...

【力扣 + 牛客 | SQL题 | 每日5题】牛客SQL热题216,217,223
也在牛客力扣写了一百来题了,个人感觉力扣的SQL题要比牛客的高三档的难度。(普遍来说) 1. 牛客SQL热题216:统计各个部门的工资记录数 1.1 题目: 描述 有一个部门表departments简况如下: dept_nodept_named001Marke…...

赛车电气系统设计的现代化转型与实践
1. 赛车电气系统设计的现状与挑战当人们谈论赛车技术时,脑海中浮现的往往是碳纤维车身、空气动力学套件或是大马力发动机。但在这光鲜亮丽的表象背后,电气系统才是现代赛车的"神经系统"。有趣的是,这个关键领域的设计方法却呈现出两…...

2025届毕业生推荐的AI学术平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作范畴之内,怎样迅速、精确地给论文确定一个既契合规范又能够切实有效吸…...
表面吸附模型的构建与可视化)
从DFT计算到论文插图:一条龙搞定Pt(111)表面吸附模型的构建与可视化
从DFT计算到论文插图:Pt(111)表面吸附模型的完整构建与可视化指南 在计算材料科学领域,构建精确的表面吸附模型是研究催化反应机理、表面化学过程的第一步。对于刚入门的研究者来说,如何快速构建一个符合物理实际的Pt(111)表面吸附模型&#…...

GO Feature Flag通知系统详解:Slack、Webhook实时告警
GO Feature Flag通知系统详解:Slack、Webhook实时告警 【免费下载链接】go-feature-flag GO Feature Flag is a simple, complete and lightweight self-hosted cloud native feature flag solution 100% Open Source. 🎛️ 项目地址: https://gitcode…...

3分钟解锁CAJ文件:如何将知网专属格式转换为可搜索PDF
3分钟解锁CAJ文件:如何将知网专属格式转换为可搜索PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/gh…...
告别‘鬼影重重’:ENVI Pixel Based Mosaicking工具处理无坐标影像的完整流程与色彩均衡技巧
告别‘鬼影重重’:ENVI Pixel Based Mosaicking工具处理无坐标影像的完整流程与色彩均衡技巧 在遥感影像处理领域,影像镶嵌是基础却至关重要的环节。当面对多源、无坐标的影像数据时,传统的地理参考镶嵌工具往往束手无策,而ENVI的…...
的开发详解五:SigmaStudio实战技巧与模块高效应用)
ADAU1701(含A2B)的开发详解五:SigmaStudio实战技巧与模块高效应用
1. SigmaStudio模块查找的终极技巧 第一次打开SigmaStudio时,面对左侧密密麻麻的模块列表,我完全懵了。就像走进一个巨大的图书馆却找不到分类标签,ADI把200多个算法模块分散在30多个分类里,光Volume Controls下面就有12种音量调节…...

29 - Go time 时间模块详解:时间处理、定时控制与底层设计
文章目录29 - Go time 时间模块详解:时间处理、定时控制与底层设计核心概念time 模块解决什么问题?Go 为什么不用字符串表示时间?time.Duration 是什么?小结基础使用示例获取当前时间时间格式化为什么是 2006-01-02?小…...

终极解决方案:让苹果触控板在Windows上获得原生级精准触控体验
终极解决方案:让苹果触控板在Windows上获得原生级精准触控体验 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-tou…...

基于ESP32与WLED打造智能可编程灯饰:从硬件连接到软件配置全攻略
1. 项目概述:打造你的专属智能光影秀又到年底了,看着满大街千篇一律的彩灯装饰,是不是觉得有点审美疲劳?想不想自己动手,做一套独一无二、能通过手机随心控制颜色和动画的智能灯饰?今天分享的这个项目&…...