提升大数据量分页查询性能:深分页优化全解
前言
在处理数据量逐渐增大的数据库表时,优化查询性能是一个常见的挑战。朋友们可能会建议说,创建索引不就能解决问题了吗?然而,当数据量达到相当规模时,简单的索引可能不足以应对所有情况。这时,可能会有人提出分库分表的方案,但是,对于那种缓慢增长的数据集来说,这样的措施似乎有些过犹不及,显得过于复杂且成本高昂。
因此,今天我们要介绍的是一位解决深度分页查询问题的关键角色——高效的深分页解决方案。深分页是指在数据量非常大时,仍然能够快速、准确地返回分页查询结果的技术手段。
更多精选好文
一、深分页是什么
深分页问题是指在处理大量数据时,当用户请求访问非常靠后的页面(即“深”分页)时,数据库查询性能显著下降的情况。传统分页方法通常使用 LIMIT 和 OFFSET 关键字来实现,但在数据量庞大时,这种方式要求数据库从头开始扫描直到达到指定的偏移量,然后再返回限定数量的结果,这导致了效率低下和资源浪费。
来个示例演示一下:我们先来建立一张user表,并对其生成500万的数据,直接通过sql查询来感受一下数据量增大带来的查询负担。
直接通过limit查询:
SELECT * from `user` LIMIT 4999990, 10;
直接耗时3s多,这里还是本地环境下,排除了网络传输的IO情况。

接下来我们来讲讲解决方案吧。
二、MySQL中解决方案
针对MySQL单表中的解决方案,我们可以通过下面三种常用的来解决:
- 子查询优化
- 延迟关联
- 书签记录
2.1、子查询优化
2.1.1、介绍
当 user 表具有主键或索引字段时,我们可以借助主键进行子查询以确定偏移起点,这会极大减少扫描行数,从而显著提高查询性能。
# 子查询优化
SELECT *
FROM `user`
WHERE id > (SELECT idFROM `user`ORDER BY id DESCLIMIT 10, 1
)
LIMIT 10;
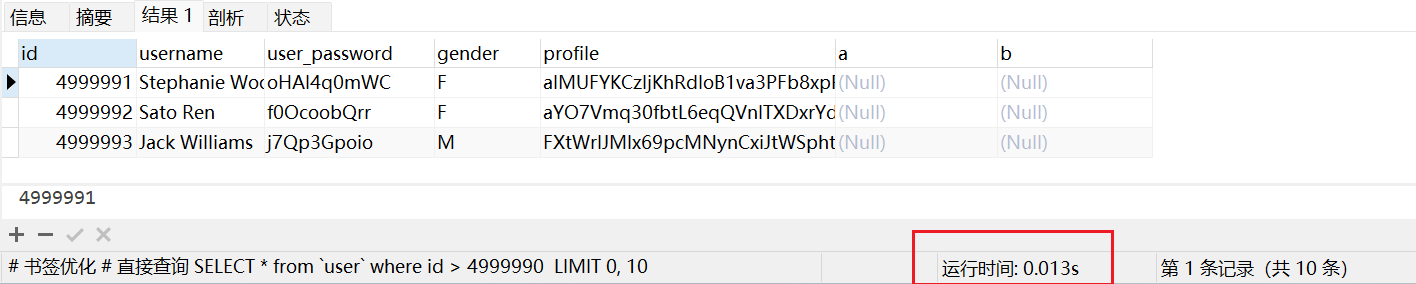
直接查询结果显示,查询时间仅为 0.013 秒,性能提升了 200 多倍!

2.1.2、优缺点分析
2.1.2.1、优点
- 性能提升:
- 通过子查询找到起始点,避免了
OFFSET导致的性能问题。传统的OFFSET方法在大数据集上需要扫描大量行,而子查询方法只需扫描必要的行,大大减少了扫描行数。 - 查询时间显著减少,从几秒甚至几十秒缩短到毫秒级别。
- 通过子查询找到起始点,避免了
- 一致性:
- 整个分页查询的逻辑更加一致,易于维护和扩展。无论是浅分页还是深分页,都可以使用相同的优化策略。
- 灵活性:
- 可以根据业务需求动态调整分页参数,提高系统的灵活性。
- 减少数据传输:
- 子查询中只需要
id列,减少了数据传输量,进一步提高了查询效率。
- 子查询中只需要
2.1.2.2、缺点
- 索引依赖:
- 这种方法依赖于表的主键或索引字段。如果表没有合适的索引,性能提升效果可能不明显,甚至可能导致性能下降。
- 子查询开销:
- 尽管子查询减少了整体的扫描行数,但子查询本身也有一定的开销。在某些极端情况下,如果子查询的结果集非常大,可能会引入额外的性能开销。
- 适用范围:
- 这种方法适用于按主键或索引字段排序的分页查询。如果排序字段不是主键或索引字段,可能需要其他优化策略。
2.2、延迟关联
这种方式,本质上来说还是通过 JOIN 关联的形式进行绑定。
# 内连接优化
SELECT t1.*
FROM `user` t1
INNER JOIN (SELECT idFROM `user`ORDER BY id DESCLIMIT 10, 10
) AS t2
ON t1.id = t2.id;这种方式实现,基本同上性能差不多,核心思想也是通过利用索引覆盖,来优化了Limit分页查询的效率。
2.3、书签优化(滚动查询)
2.3.1、介绍
书签优化,也称为滚动查询,是一种通过记录上一次查询的最大记录ID来优化深分页查询的方法。这种方法的核心思想是从第一页开始查询,然后获取本页最大的记录ID,再根据大于该记录ID的数据向后持续滚动。由于ID通常是递增的,因此可以直接根据ID进行查询。
# 书签优化
SELECT *
FROM `user`
WHERE id > 4999990
LIMIT 10;
2.3.2、优缺点分析
2.3.2.1、优点
- 性能提升:
- 通过记录上一次查询的最大记录ID,避免了
OFFSET导致的性能问题。传统的OFFSET方法在大数据集上需要扫描大量行,而书签优化方法只需扫描必要的行,大大减少了扫描行数。 - 查询时间显著减少,从几秒甚至几十秒缩短到毫秒级别。
- 通过记录上一次查询的最大记录ID,避免了
- 一致性:
- 整个分页查询的逻辑更加一致,易于维护和扩展。无论是浅分页还是深分页,都可以使用相同的优化策略。
- 灵活性:
- 可以根据业务需求动态调整分页参数,提高系统的灵活性。
- 减少数据传输:
- 只需记录上一次查询的最大记录ID,减少了数据传输量,进一步提高了查询效率。
2.3.2.2、缺点
-
致命问题:不支持跳页查询(使用场景有限)
- 这种方法只能支持固定增长的场景,如果涉及到比较灵活的分页查询,则不能满足业务的实现
-
并发问题:
- 在高并发场景下,如果多用户同时进行分页查询,可能会出现记录ID冲突或数据不一致的问题。需要额外的锁机制或事务管理来保证数据的一致性。
-
适用范围:
- 这种方法适用于按主键或递增字段排序的分页查询。如果排序字段不是主键或递增字段,可能需要其他优化策略。
2.3.3、结论
书签优化(滚动查询)是一种有效的深分页解决方案,尤其适用于大数据集的分页查询。通过记录上一次查询的最大记录ID,显著提高了查询性能。尽管这种方法依赖于递增ID,并且在某些场景下可能需要额外的处理,但其带来的性能提升使其在许多场景下仍然是值得推荐的优化策略。希望这个方案能帮助你更好地处理深分页问题。
三、分库分表中解决方案
对于大数据量场景,使用分库分表后,我们又该如何解决深分页问题呢?接下来我们将提出几种常见的方法来了解一下常见的解决方案。
3.1 Sharding-JDBC 的流式处理和归并排序优化
在数据量庞大的系统中,分库分表是一种常见的策略。Sharding-JDBC 提供了一种流式查询(Streaming Query)的方式,能够在不加载所有数据的情况下进行深度分页。流式处理将数据逐条读取,不会一次性加载至内存中,这有效避免了内存暴涨的问题;同时还会通过归并排序的方式筛选出所需的数据。不过,流式处理涉及一些特殊注意事项:
- 流式查询会锁定数据库连接:在执行流式查询时,需要确保数据读取完成后才关闭连接,避免因长时间占用数据库连接而导致的资源浪费。
- 磁盘 I/O 和缓存影响:流式查询在数据量较大时会增加磁盘 I/O 和缓存消耗。因此,数据库配置时可以考虑限制流式查询的行数和超时时间,以避免对系统资源的过度占用。
Sharding-JDBC 的流式处理适用于分页结果较多、每次查询结果集较大的场景,能够在深分页时显著降低系统的内存负担。
3.2 禁止跳页查询法
在深分页中,跳页查询会导致查询的偏移量(OFFSET)过大,影响查询效率。例如,查询 OFFSET 1000000 的数据时,数据库需要扫描并跳过前 1000000 条数据,操作复杂且耗时。针对这种情况,可以采用“禁止跳页查询法”,通过连续 ID(如订单号或主键)来实现分页:
- 初次查询时按顺序字段(如 ID 或创建时间)排序并记录最大值,例如
max_id或max_create_time。 - 查询下一页时,利用最大值实现分页,通过
WHERE id > last_max_id ORDER BY id LIMIT page_size的方式获得新的分页数据。
这种方式避免了大量数据的跳过操作,能有效提高分页查询效率,但需要数据具备连续且有序的字段,如 ID 或时间戳字段。
3.3 二次查询法
当分页查询需要跳转时,二次查询法可以通过分散偏移量来减轻数据库的查询压力,适用于分表场景。具体步骤如下:
- 初次查询时将偏移量分散至各个分表,例如偏移量
offset / 分表数。 - 执行子查询:针对每个分表按分散后的偏移量限制查询,例如
LIMIT。 - 二次查询和合并:将所有子查询的结果集中并在逻辑层进行排序和分页操作。
这种方法有效减少了数据库负载,但实现上较复杂,且适用于按特定字段排序的分页查询,能够在业务场景中提供较好的性能提升。
3.4 使用搜索引擎或缓存系统支持分页
在部分高性能需求场景中,可以将分页查询交给搜索引擎或缓存系统来完成:
- Redis:对于常用查询结果,可以将其缓存到 Redis 中并在缓存中进行分页。Redis 通过哈希、集合等数据结构可以高效地实现分页功能。
- Elasticsearch:将数据同步至 Elasticsearch,并利用其分布式搜索和强大的分页能力来代替数据库分页。Elasticsearch 支持倒排索引,特别适用于需要实时索引更新的场景。
在此方案中,Redis 和 Elasticsearch 提供的索引和缓存功能能够显著提升分页查询性能,但要注意数据同步的一致性和缓存失效的处理。
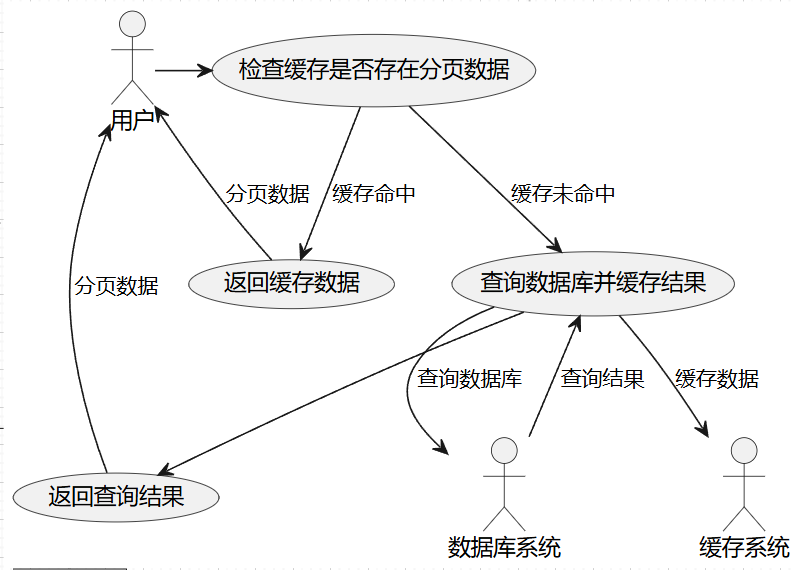
3.5 总结
在实际应用中,针对不同的业务需求可以灵活选择适合的分页优化策略。以下是对每种策略的优缺点分析:
1. Sharding-JDBC 流式处理
优点:
- 内存效率:流式处理将数据逐条读取,不会一次性加载至内存中,有效避免了内存暴涨的问题。
- 归并排序:通过归并排序的方式筛选出所需的数据,确保结果的准确性。
缺点:
- 锁定数据库连接:流式查询会锁定数据库连接,需要确保数据读取完成后才关闭连接,否则可能造成资源浪费。
- 磁盘 I/O 和缓存影响:流式查询在数据量较大时会增加磁盘 I/O 和缓存消耗,需要合理配置数据库以避免资源过度占用。
2. 禁止跳页查询法
优点:
- 性能提升:通过记录上一次查询的最大记录ID,避免了大量数据的跳过操作,显著提高了查询效率。
- 简单易懂:逻辑简单直观,容易理解和实现。
- 适用于连续ID:特别适合具有连续且有序字段(如 ID 或时间戳)的表。
缺点:
- 依赖连续ID:方法依赖于表的ID是递增的。如果ID不是连续递增的,或者有删除操作导致ID不连续,可能会影响查询的正确性。
- 初始查询限制:需要从第一页开始查询,并逐步获取每一页的最大记录ID。如果需要直接跳到某一页,必须先查询前面所有的页,这在某些场景下可能不太方便。
- 并发问题:在高并发场景下,多用户同时进行分页查询可能会出现记录ID冲突或数据不一致的问题,需要额外的锁机制或事务管理来保证数据的一致性。
3. 二次查询法
优点:
- 减少数据库负载:通过分散偏移量,有效减少了单个查询的负载,提高了查询效率。
- 适用于分表场景:特别适合分表和数据分散的场景,能够在业务场景中提供较好的性能提升。
- 灵活性:可以根据实际情况调整偏移量的分散策略,灵活性较高。
缺点:
- 误差:这种分散到各个表查询,查询到的只是一个平均的数据,可能会导致一定的误差。
- 适用范围:适用于按特定字段排序的分页查询,如果排序字段不适用,可能需要其他优化策略。
4. 使用 Redis 或 Elasticsearch
优点:
- 高性能:Redis 和 Elasticsearch 提供的索引和缓存功能能够显著提升分页查询性能,特别适合对性能和实时性要求较高的系统。
- 分布式处理:Elasticsearch 支持分布式搜索,能够处理大规模数据的实时索引和查询。
- 灵活性:支持多种数据结构和查询方式,可以根据业务需求灵活选择。
缺点:
- 数据同步:需要将数据同步至缓存系统或搜索引擎,增加了数据同步的复杂性和一致性问题。
- 资源消耗:缓存系统和搜索引擎本身也会消耗一定的系统资源,需要合理配置以避免资源过度占用。
- 学习曲线:使用 Redis 或 Elasticsearch 需要一定的学习和配置成本,特别是对于复杂的业务场景。
在实际应用中,可以根据具体的业务需求和系统特点选择合适的分页优化策略:
- Sharding-JDBC 适合流式处理大数据量的分页。
- 禁止跳页查询法 适用于偏移量较大时的数据查询。
- 二次查询法 适合分表和数据分散的场景。
- 使用 Redis 或 Elasticsearch 适合对性能和实时性要求更高的系统。
通过上述优化方式,能够在深分页时有效减少数据库的负载和系统的内存占用,提高整体查询效率。
四、案例分析:百度搜索引擎如何处理深分页问题
4.1、背景
当我们通过关键词进行搜索时,例如输入“你好”,并持续点击“下一页”直到最后一页,我们会发现搜索结果主要集中在最近一年内的数据。这引发了我们对百度搜索引擎如何处理大批量数据的思考。
4.2、技术手段
-
近期数据的快速检索
- Elasticsearch 存储:对于最近一年内的数据,百度可能使用 Elasticsearch 进行存储和检索。Elasticsearch 是一个高性能的分布式搜索和分析引擎,能够快速处理大量实时数据。通过其倒排索引机制,可以实现高效的全文搜索和快速的响应时间。
- 缓存机制:为了进一步提升性能,百度可能会使用缓存技术(如 Redis)来存储热门搜索结果,从而减少对后端数据库的访问频率,提高查询速度。
-
深分页查询优化
- 二次查询与归并排序:
- 当用户请求的分页较深时,系统不会一次性从所有分表中取出所有数据进行排序,而是采用二次查询的方法。首先,从每个分表中取出一定数量的数据(例如每页所需数量的几倍),然后在内存中进行归并排序,最后返回给用户指定页码的数据。
- 这种方法可以显著减少一次性从数据库中取出大量数据的压力,同时避免了深分页带来的性能问题。
- Sharding-JDBC 流式处理:
- 使用 Sharding-JDBC 等数据库中间件,可以在不修改应用程序代码的前提下,实现对分库分表数据的透明化查询。Sharding-JDBC 支持流式处理,即在处理查询结果时逐步加载数据,而不是一次性加载所有数据,这对于处理大数据量的分页查询特别有用。
- 结合归并排序等算法,可以有效地处理深分页查询,确保即使在查询大量数据时也能提供良好的用户体验。
- 二次查询与归并排序:
百度搜索引擎通过结合多种技术手段来应对不同的查询场景,具体如下:
- 浅分页查询:对于常见的浅分页查询(如一年内的数据),直接利用缓存和 Elasticsearch 快速返回结果。这确保了大多数用户的查询请求能够得到迅速响应。
- 深分页查询:对于深分页查询,采用二次查询、归并排序和 Sharding-JDBC 的流式处理等优化策略,确保即使在查询大量数据时也能保持良好的性能和用户体验。
4.3、结论
通过上述技术手段,百度搜索引擎能够高效地处理大批量数据查询,特别是在深分页场景下,确保了数据的快速检索和良好的用户体验。这些策略不仅提高了查询效率,还保证了数据的准确性和完整性。
五、总结
本文探讨了在处理大数据量时如何优化数据库的分页查询性能,特别是针对深分页问题。深分页问题是指当用户请求访问非常靠后的页面时,数据库查询性能显著下降的情况。传统的 LIMIT 和 OFFSET 方法在数据量庞大时效率低下,难以满足高性能需求。因此,本文针对单数据库表和分库分表场景,提出了多种解决方案,以有效应对深分页问题。
希望本文能帮助你更好地理解和解决深分页查询问题。如果你觉得有帮助,别忘了给我点赞哦!😊
相关文章:
提升大数据量分页查询性能:深分页优化全解
前言 在处理数据量逐渐增大的数据库表时,优化查询性能是一个常见的挑战。朋友们可能会建议说,创建索引不就能解决问题了吗?然而,当数据量达到相当规模时,简单的索引可能不足以应对所有情况。这时,可能会有…...

WPF 实现冒泡排序可视化
WPF 实现冒泡排序可视化 实现冒泡排序代码就不过多讲解,主要是实现动画效果思路,本demo使用MVVM模式编写,读者可自行参考部分核心代码,即可实现如视频所示效果。 对于新手了解算法相关知识应该有些许帮助,至于其它类型…...

Claude 3.5 新功能 支持对 100 页的PDF 图像、图表和图形进行可视化分析
Claude 3.5 Sonnet发布PDF图像预览新功能,允许用户分析长度不超过100页的PDF中的视觉内容。 此功能使用户能够轻松上传文档并提取信息,特别适用于包含图表、图形和其他视觉元素的研究论文和技术文档。 视觉PDF分析:用户现在可以从包含各种视觉…...

正式开源:从 Greenplum 到 Cloudberry 迁移工具 cbcopy 发布
Cloudberry Database 作为 Greenplum 衍生版本和首选开源替代,由 Greenplum 原始团队成员创建,与 Greenplum 保持原生兼容,并能实现无缝迁移,且具备更新的 PostgreSQL 内核和更丰富的功能。GitHub: https://github.com/cloudberry…...

Python如何读写文件?
1. 文件读取 (1)使用open()函数打开文件 基本语法是file_object open(file_name, mode),其中file_name是要打开的文件的名称(包括路径,如果文件不在当前目录下),mode是打开文件的模式。例如&a…...

100种算法【Python版】第38篇——Boyer-Moore算法
本文目录 1 算法说明2 算法示例3 python代码1 算法说明 Boyer-Moore算法由Robert S. Boyer和J. Strother Moore于1977年提出,旨在提高字符串匹配的效率。该算法在寻找固定模式的过程中,利用模式本身的信息,优化搜索过程,特别适合长文本中的模式查找。 算法原理 Boyer-Moo…...

贪心算法---java---黑马
贪心算法 1)Greedy algorithm 称之为贪心算法或者贪婪算法,核心思想是 将寻找最优解的问题分为若干个步骤每一步骤都采用贪心原则,选取当前最优解因为未考虑所有可能,局部最优的堆叠不一定得到最终解最优 贪心算法例子 Dijkstra while …...

程序员的减压秘籍:高效与健康的平衡艺术
引言 在当今竞争激烈的科技行业中,程序员常常面临着极高的精神集中要求和持续的创新压力。这种工作性质让许多程序员在追求高效和创新的过程中,感到精疲力竭,面临身心健康的挑战。因此,找到有效的方法来缓解工作压力,…...

2024 年 QEMU 峰会纪要
2024 年 QEMU 峰会已于 10 月 31 日在 KVM 论坛召开,这是一个仅对项目中最活跃的维护者和子维护者开放的邀请会议。 出席者: Dan Berrang Cdric Le Goater Kevin Wolf Michael S. Tsirkin Stefan Hajnoczi Philippe Mathieu-Daud Markus Armbruster Th…...

C++/list
目录 1.list的介绍 2.list的使用 2.1list的构造 2.2list iterator的使用 2.3list capacity 2.4list element access 2.5list modifers 2.6list的迭代器失效 3.list的模拟实现 4.list与vector的对比 欢迎 1.list的介绍 list的文档介绍 cplusplus.com/reference/list/li…...

刘艳兵-DBA015-对于属于默认undo撤销表空间的数据文件的丢失,哪条语句是正确的?
对于属于默认undo撤销表空间的数据文件的丢失,哪条语句是正确的? A 所有未提交的交易都将丢失。 B 数据库实例中止。 C 数据库处于MOUNT状态,需要恢复才能打开。 D 数据库保持打开状态以供查询,但除具有SYSDBA特权的用…...
树莓派基本设置--10.使用MIPI摄像头
树莓派5将以前的CSI和DSI接口合并成两个两用的CSI/DSI(MIPI)端口。 一、配置摄像头 使用树莓派摄像头或第三方相机可以按照下面表格修改相机配置: 摄像头模块文件位于:/boot/firmware/config.txtV1 相机 (OV5647&am…...

【ARCGIS实验】地形特征线的提取
目录 一、提取不同位置的地形剖面线 二、将DEM转化为TIN 三、进行可视分析 四、进行山脊、山谷等特征线的提取 1、正负地形提取(用于校正) 2、山脊线提取 3、山谷线的提取 4、河网的提取 5、流域的分割 五、鞍部点的提取 1、背景 2、目的 3…...

HTML 基础标签——表格标签<table>
文章目录 1. `<table>` 标签:定义表格2. `<tr>` 标签:定义表格行3. `<th>` 标签:定义表头单元格4. `<td>` 标签:定义表格单元格5. `<caption>` 标签:为表格添加标题6. `<thead>` 标签:定义表格头部7. `<tbody>` 标签:定义表格…...

线程函数和线程启动的几种不同形式
线程函数和线程启动的几种不同形式 在C中,线程函数和线程启动可以通过多种形式实现。以下是几种常见的形式,并附有相应的示例代码。 1. 使用函数指针启动线程 最基本的方式是使用函数指针来启动线程。 示例代码: #include <iostream&g…...

数组排序简介-基数排序(Radix Sort)
基本思想 将整数按位数切割成不同的数字,然后从低位开始,依次到高位,逐位进行排序,从而达到排序的目的。 算法步骤 基数排序算法可以采用「最低位优先法(Least Significant Digit First)」或者「最高位优先…...

进程间通信(命名管道 共享内存)
文章目录 命名管道原理命令创建命名管道函数创建命名管道 共享内存原理shmgetFIOK 代码应用:premsnattch 命名管道 用于两个毫无关系的进程间的通信。 原理 Linux文件的路径是多叉树,故文件的路径是唯一的。 让内核缓冲区不用刷新到磁盘中,…...

Python 网络爬虫教程:从入门到高级的全面指南
Python 网络爬虫教程:从入门到高级的全面指南 引言 在信息爆炸的时代,网络爬虫(Web Scraping)成为了获取数据的重要工具。Python 以其简单易用的特性,成为了网络爬虫开发的首选语言。本文将详细介绍如何使用 Python …...
详细解释)
深度学习:正则化(Regularization)详细解释
正则化(Regularization)详细解释 正则化(Regularization)是机器学习和统计建模领域中用以防止模型过拟合同时增强模型泛化能力的一种技术。通过引入额外的约束或惩罚项到模型的损失函数中,正则化能够有效地限制模型的…...

Freertos学习日志(1)-基础知识
目录 1.什么是Freertos? 2.为什么要学习RTOS? 3.Freertos多任务处理的原理 1.什么是Freertos? RTOS,即(Real Time Operating System 实时操作系统),是一种体积小巧、确定性强的计算机操作系统…...

降AI率软件越便宜越好吗?实测5个主流降AI工具,首选嘎嘎降!
一、前言:2026 年毕业必须通过 aigc 检测 2026 年各高校对学术论文的 AIGC 疑似度的审查全面变严, 均发布了具体 AIGC 检测报告和数值要求,211 和 985 高校规定本科论文 AI 率要低于 20%, 硕士要求 AI 率不高于 15%。普通高校一般要求 AI 率控制在 30% 以内。AIGC 检测率超标的…...

【Midjourney胶片摄影风格终极指南】:20年影像工程师亲授7种不可外传的参数组合与暗房逻辑复刻法
更多请点击: https://intelliparadigm.com 第一章:胶片摄影的数字复刻本质与Midjourney底层成像机制 胶片摄影的“颗粒感”“色偏”“晕影”并非缺陷,而是光化学反应在银盐乳剂中非线性响应的物理印记;Midjourney 并不模拟胶片&a…...

企业无线准入实战:AC联动RADIUS与内置Portal构建安全访客网络
1. 为什么企业需要安全访客网络? 想象一下这样的场景:你的公司经常有合作伙伴、客户来访,他们需要临时使用Wi-Fi。如果直接开放内部网络,就像把家门钥匙随便发给陌生人;如果用简单密码共享,又像在公共场合大…...

从真空袋到回流焊:一份给硬件创业团队的元器件储存与使用避坑指南
从真空袋到回流焊:硬件创业团队的元器件储存与使用避坑指南 当你拆开一包全新的芯片,是否曾想过这些看似坚固的小方块其实对环境湿度极其敏感?对于资源有限的硬件创业团队来说,正确处理MSL(湿度敏感等级)元…...

SyncedStore深度解析:揭秘CRDT技术如何实现无冲突数据同步
SyncedStore深度解析:揭秘CRDT技术如何实现无冲突数据同步 【免费下载链接】SyncedStore SyncedStore CRDT is an easy-to-use library for building live, collaborative applications that sync automatically. 项目地址: https://gitcode.com/gh_mirrors/sy/Sy…...

三步搞定Windows磁盘空间不足:WinDirStat终极清理方案
三步搞定Windows磁盘空间不足:WinDirStat终极清理方案 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 你是否经常遇到Windows…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...

本地RAG系统实战:基于开源模型构建私有知识库问答应用
1. 项目概述与核心价值最近在折腾本地大模型应用的时候,发现了一个挺有意思的项目,叫Awareness-Local。这名字听起来有点玄乎,但说白了,它就是一个帮你把本地文件(比如PDF、Word、TXT,甚至图片里的文字&…...

实验室里的“学霸”与街头上的“全才”:深度解析 PaLM 与 ChatGPT
在 AI 的史诗级进程中,2022 年是一个被历史铭记的分水岭。那一年,Google 推出了参数量惊人的 PaLM,展示了“暴力美学”的巅峰;而几个月后,OpenAI 的 ChatGPT 横空出世,彻底改变了人类与机器交互的方式。 很…...

MAX3421E USB主机控制器实战:为微控制器扩展USB外设连接能力
1. 项目概述:为你的微控制器打开USB主机世界的大门如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定对它们的USB设备功能不陌生——插上电脑就能被识别成一个串口、一个键盘或者一个U盘。但你想过反过来吗?让你的微控制器项目变成“…...