MMCA:多模态动态权重更新,视觉定位新SOTA | ACM MM‘24 Oral
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Visual Grounding with Multi-modal Conditional Adaptation

- 论文地址:https://arxiv.org/abs/2409.04999
- 论文代码:https://github.com/Mr-Bigworth/MMCA
创新点
- 提出了多模态条件适应(
MMCA)方法,该方法从一种新颖的权重更新视角改善了视觉引导模型中视觉编码器的特征提取过程。 - 将提出的
MMCA应用于主流的视觉引导框架,并提出了灵活的多模态条件变换器和卷积模块,这些模块可以作为即插即用组件轻松应用于其他视觉引导模型。 - 进行广泛的实验以验证该方法的有效性,在四个具有代表性的数据集上的结果显示出显著的改善,且成本较小。
内容概述
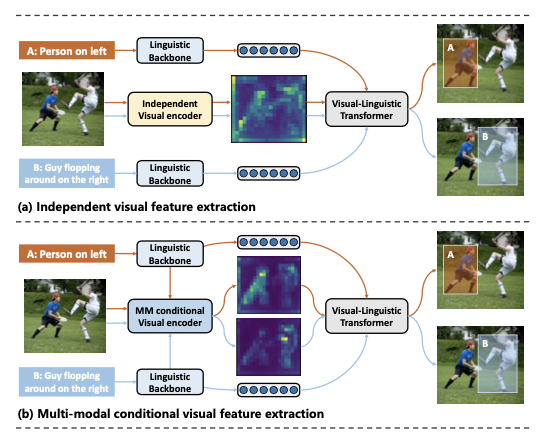
视觉定位旨在将传统的物体检测推广到定位与自由形式文本描述相对应的图像区域,已成为多模态推理中的核心问题。现有的方法通过扩展通用物体检测框架来应对这一任务,使用独立的视觉和文本编码器分别提取视觉和文本特征,然后在多模态解码器中融合这些特征以进行最终预测。
视觉定位通常涉及在同一图像中定位具有不同文本描述的物体,导致现有的方法在这一任务上表现不佳。因为独立的视觉编码器对于相同的图像生成相同的视觉特征,从而限制了检测性能。最近的方法提出了各种语言引导的视觉编码器来解决这个问题,但它们大多仅依赖文本信息,并且需要复杂的设计。
受LoRA在适应不同下游任务的高效性的启发,论文引入了多模态条件适配(MMCA),使视觉编码器能够自适应更新权重,专注于与文本相关的区域。具体而言,首先整合来自不同模态的信息以获得多模态嵌入,然后利用一组从多模态嵌入生成的权重系数,来重组权重更新矩阵并将其应用于视觉定位模型的视觉编码器。
MMCA
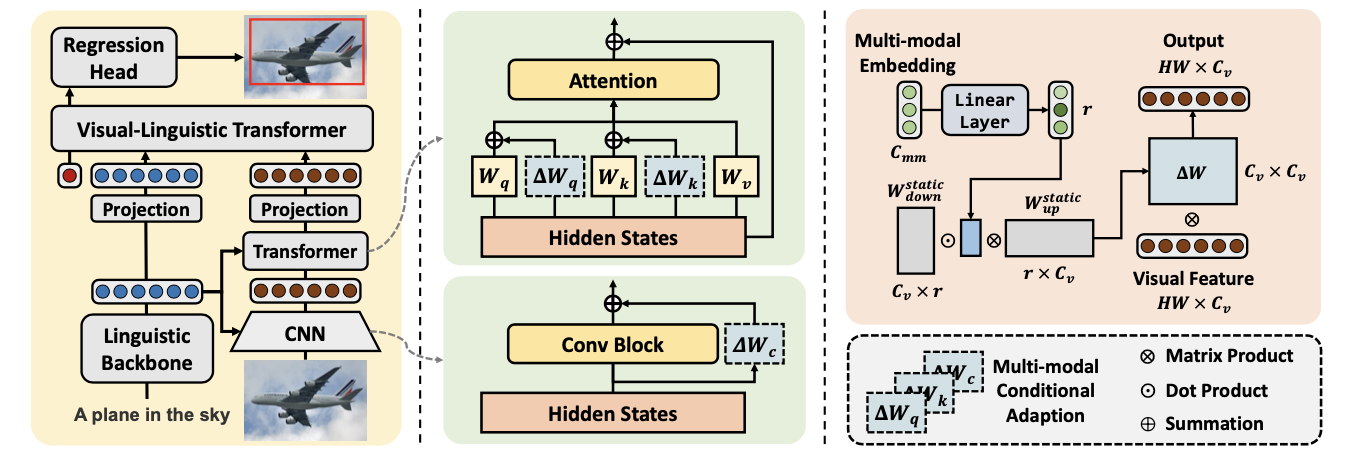
MMCA遵循典型的端到端编码器-解码器范式:
- 给定一幅图像和一个语言表达作为输入将其输入到编码器部分,以生成相应的特征嵌入。
- 在语言分支中,语言主干将经过分词的语言表达作为输入,并提取文本特征 f t ∈ R N t × C t f_t\in \mathbb{R}^{N_t\times C_t} ft∈RNt×Ct ,其中 N t N_t Nt 是语言标记的数量。
- 在视觉分支中,
CNN主干首先提取一个二维特征图,然后经过一系列变换器编码器层,生成一个展平的视觉特征序列 f v ∈ R N v × C v f_v\in \mathbb{R}^{N_v\times C_v} fv∈RNv×Cv 。 - 多模态条件适应(
MMCA)模块以层级方式应用于卷积层和变换器层的参数矩阵。该模块同时接受视觉和文本特征作为输入,并动态更新视觉编码器的权重,以实现基于语言的视觉特征提取。
- 将视觉和文本特征嵌入连接在一起,并在多模态解码器(视觉-语言变换器)的输入中添加一个可学习的标记 [
REG],该解码器将来自不同模态的输入标记嵌入对齐的语义空间,并通过自注意力层执行模态内和模态间的推理。 - 回归头使用 [
REG] 标记的输出状态来直接预测被指对象的四维坐标 b ^ = ( x ^ , y ^ , w ^ , h ^ ) \hat b = (\hat{x}, \hat{y}, \hat{w}, \hat{h}) b^=(x^,y^,w^,h^) 。与真实框 b = ( x , y , w , h ) b = (x, y, w, h) b=(x,y,w,h) 的训练损失可以表述为:
L = L s m o o t h − l 1 ( b ^ , b ) + L g i o u ( b ^ , b ) \begin{equation} \mathcal L=\mathcal L_{smooth-l1}(\hat b, b)+L_{giou}(\hat b, b) \end{equation} L=Lsmooth−l1(b^,b)+Lgiou(b^,b)
条件适应
对于视觉引导任务,论文希望不同的指代表达能够控制视觉编码器的一组权重更新,从而引导编码器的注意力集中在与文本相关的区域。然而,直接生成这样的矩阵带来了两个缺点:(1)这需要一个大型参数生成器。(2)没有约束的生成器可能在训练中对表达式过拟合,而在测试期间却难以理解表达式。
受LoRA的启发,让网络学习一组权重更新的基矩阵并使用多模态信息重新组织更新矩阵。这使得参数生成器变得轻量,并确保网络的权重在同一空间内更新。
具体而言,先对权重更新矩阵进行分解,并将其重新表述为外积的和,通过 B i , A i B_i, A_i Bi,Ai 并使用加权和来控制适应的子空间:
KaTeX parse error: Undefined control sequence: \label at position 76: …B_i\otimes A_i \̲l̲a̲b̲e̲l̲{eq3} \end{equa…
KaTeX parse error: Undefined control sequence: \label at position 87: …B_i\otimes A_i \̲l̲a̲b̲e̲l̲{eq4} \end{equa…
为了简化并且不引入其他归纳偏差,使用线性回归来生成这一组权重:
KaTeX parse error: Undefined control sequence: \label at position 77: …2, ..., b_r]^T \̲l̲a̲b̲e̲l̲{eq5} \end{equa…
其中 W g ∈ R r × d , [ b 1 , b 2 , . . . , b r ] T W_g\in \mathbb{R}^{r\times d}, [b_1, b_2, ..., b_r]^T Wg∈Rr×d,[b1,b2,...,br]T 是参数矩阵, E m m ∈ R d E_{mm}\in \mathbb{R}^{d} Emm∈Rd 是特定层的多模态嵌入,它是由文本特征和从前一层输出的视觉特征生成的。
与迁移学习任务不同,这里并不打算微调一小部分参数以适应特定的下游任务,而是希望视觉编码器能够适应各种表达。因此,所有参数矩阵 W 0 , B , A , W g , [ b 1 , b 2 , . . . , b r ] T W_0, B, A, W_g, [b_1, b_2, ..., b_r]^T W0,B,A,Wg,[b1,b2,...,br]T 在训练阶段都是可学习的。
多模态嵌入
仅依赖文本信息来引导视觉编码器可能会在某些应用中限制灵活性,并且性能可能会受到文本信息质量的影响。为了缓解这些问题,采用门控机制来调节文本信息的输入。
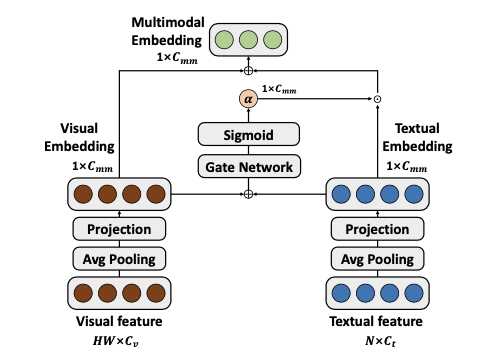
给定文本特征 F t ∈ R N t × C t F_t\in \mathbb{R}^{N_t\times C_t} Ft∈RNt×Ct 和展平的视觉特征 F v ∈ R H W × C v F_v\in \mathbb{R}^{HW\times C_v} Fv∈RHW×Cv ,使用简单门控机制来融合视觉和文本嵌入:
E t = W t F t , E v = W v F v \begin{equation} E_{t} = W_tF_t, E_{v}=W_vF_v \end{equation} Et=WtFt,Ev=WvFv
α = σ [ W g 1 δ ( W g 2 ( E t + E v ) ) ] \begin{equation} \alpha =\sigma[W^1_g\delta(W^2_g(E_{t}+E_{v}))] \end{equation} α=σ[Wg1δ(Wg2(Et+Ev))]
E m m = α E t + E v \begin{equation} E_{mm} = \alpha E_{t} + E_{v} \end{equation} Emm=αEt+Ev
最后,融合嵌入 E m m E_{mm} Emm 被用来生成系数,从而指导视觉编码器的权重更新。
适配视觉定位
基于视觉编码器(卷积层和Transformer层),进一步提出了多模态条件Transformer和多模态条件卷积,用于将MMCA应用于视觉定位中。
视觉主干中的Transformer编码器层主要由两种类型的子层组成,即MHSA和FFN。通过应用多模态条件适应,MHSA和FFN的计算变为:
KaTeX parse error: Undefined control sequence: \label at position 159: …k} \end{split} \̲l̲a̲b̲e̲l̲{eq8} \end{equa…
KaTeX parse error: Undefined control sequence: \label at position 60: …ta W_{m}h'+h') \̲l̲a̲b̲e̲l̲{eq9} \end{equa…
其中 Δ W q , Δ W k , Δ W m \Delta W_{q}, \Delta W_{k}, \Delta W_{m} ΔWq,ΔWk,ΔWm 是查询、关键和MLP块的线性投影的条件权重更新。
为了便于应用多模态条件适应,将卷积权重更新展开为一个2-D矩阵并用两个矩阵 B ∈ R c i n × r , A ∈ R r × c o u t k 2 B\in \mathbb{R}^{c_{in}\times r}, A\in \mathbb{R}^{r\times c_{out}k^2} B∈Rcin×r,A∈Rr×coutk2 进行近似,秩为 r r r 。于是,卷积块的多模态条件适应可以通过两个连续的卷积层 C o n v B Conv_B ConvB 和 C o n v A Conv_A ConvA 来近似:
KaTeX parse error: Undefined control sequence: \label at position 82: …dot Conv_B(X)) \̲l̲a̲b̲e̲l̲{eq10} \end{equ…
其中 X X X 和 W m m = [ w 1 , w 2 , . . . , w r ] T W_{mm}=[w_1, w_2, ..., w_r]^T Wmm=[w1,w2,...,wr]T 分别是来自前一卷积层的视觉特征和从多模态嵌入生成的权重系数。在通道维度上计算系数与 C o n v B Conv_B ConvB 输出的点积,并将输出输入到 C o n v A Conv_A ConvA ,这相当于重新组织权重更新。
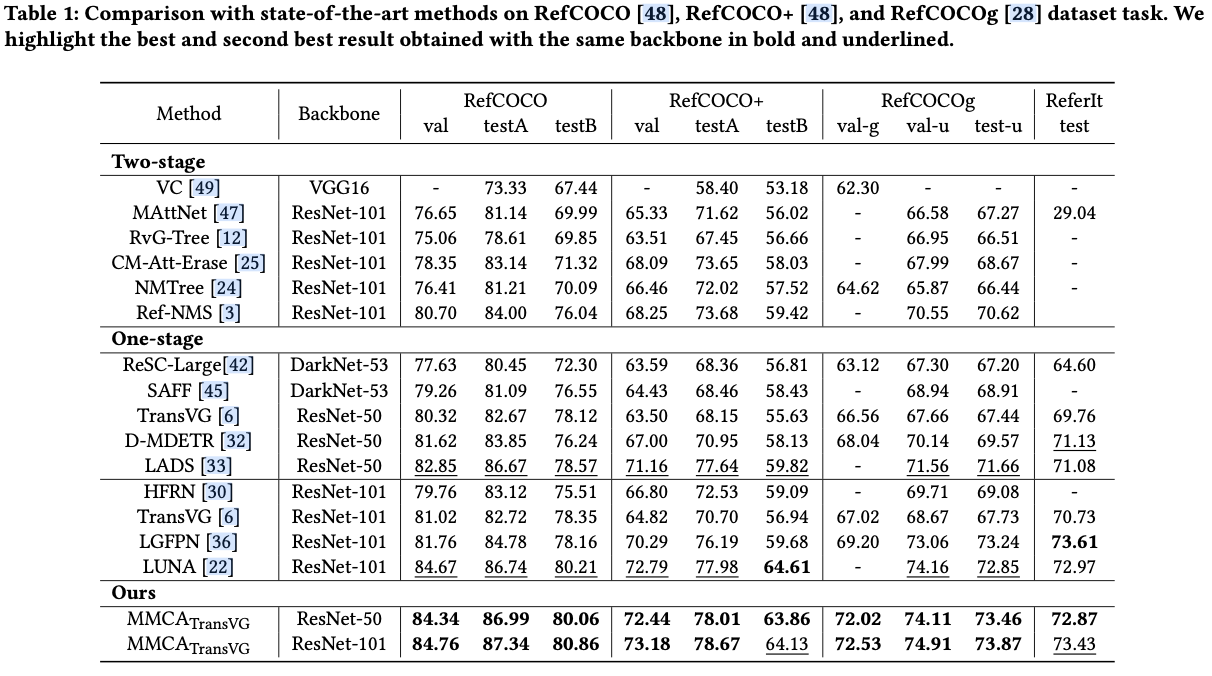
主要实验
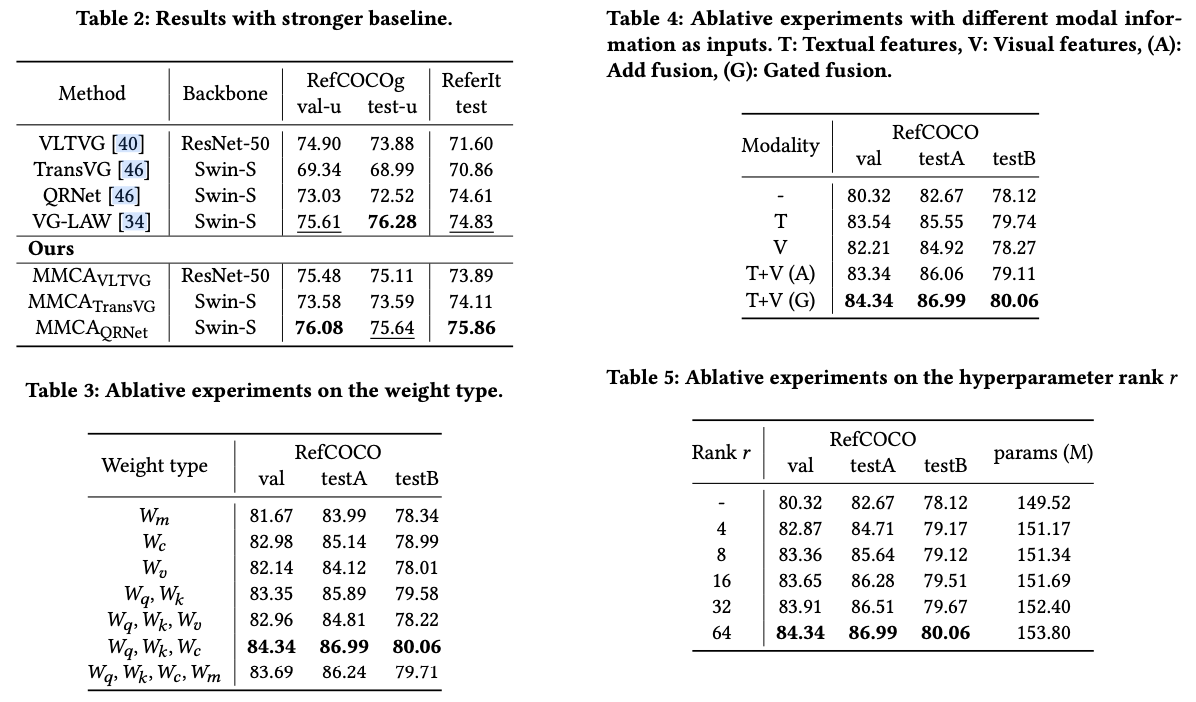
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

相关文章:
MMCA:多模态动态权重更新,视觉定位新SOTA | ACM MM‘24 Oral
来源:晓飞的算法工程笔记 公众号,转载请注明出处 论文: Visual Grounding with Multi-modal Conditional Adaptation 论文地址:https://arxiv.org/abs/2409.04999论文代码:https://github.com/Mr-Bigworth/MMCA 创新点 提出了多模…...
)
linux同步执行命令脚本 (xcall)
linux同步执行命令脚本 (xcall) 1、在/usr/local/bin目录下 创建xcall文件 vim /usr/local/bin/xcall2、输入内容 #!/bin/bash # 获取控制台指令 判断指令是否为空 pcount$# if((pcount0)); thenecho "command can not be null !"exit fifor host in bigdata01 …...

opencv - py_imgproc - py_grabcut GrabCut 算法提取前景
文章目录 使用 GrabCut 算法进行交互式前景提取目标理论演示 使用 GrabCut 算法进行交互式前景提取 目标 在本章中 我们将了解 GrabCut 算法如何提取图像中的前景我们将为此创建一个交互式应用程序。 理论 GrabCut 算法由英国剑桥微软研究院的 Carsten Rother、Vladimir K…...

ChatGPT多模态命名实体识别
ChatGPT多模态命名实体识别 ChatGPT辅助细化知识增强!一、研究背景二、模型结构和代码任务流程第一阶段:辅助精炼知识启发式生成第二阶段:基于…...
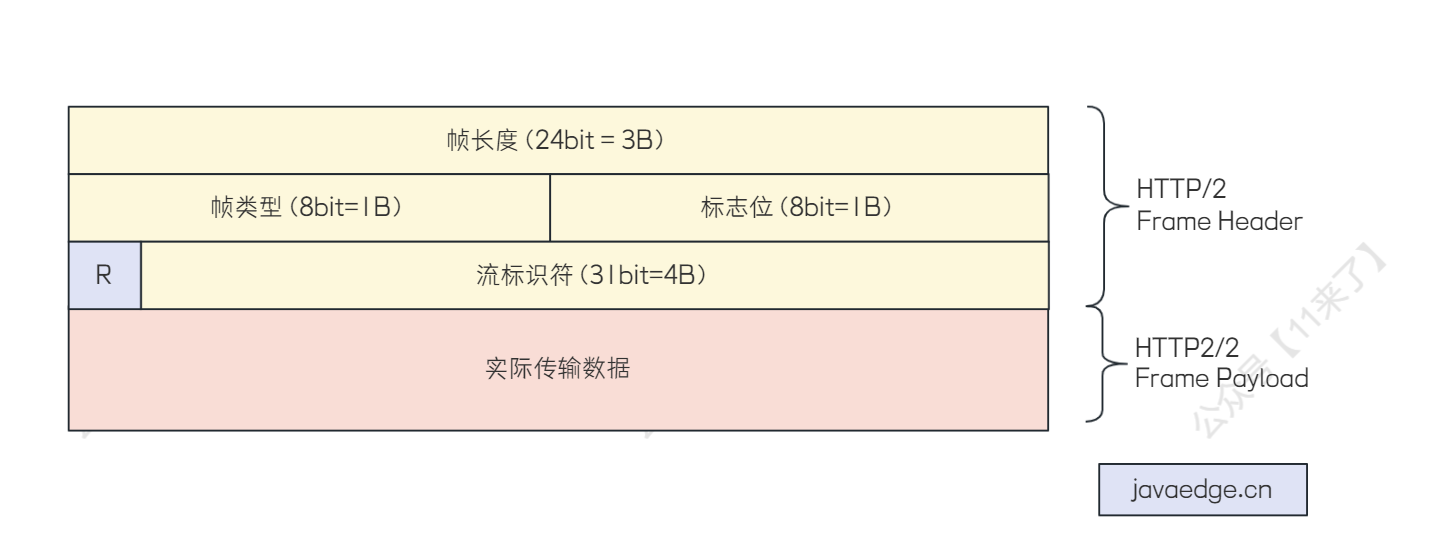
04-Dubbo的通信协议
04-Dubbo的通信协议 Dubbo 支持的通信协议 Dubbo 框架提供了自定义的高性能 RPC 通信协议: 基于 TCP 的 Dubbo2 协议 基于 HTTP/2 的 Triple 协议 Dubbo 框架是不和任何通信协议绑定的,对通信协议的支持非常灵活,支持任意的第三方协议&#x…...

开源数据库 - mysql - innodb源码阅读 - 线程启动
线程启动源码 /** Start up the InnoDB service threads which are independent of DDL recovery.*/void srv_start_threads() {if (!srv_read_only_mode) {/* Before 8.0, it was master thread that was doing periodicalcheckpoints (every 7s). Since 8.0, it is the log …...

在美团外卖上抢券 Python来实现
在美团外卖上抢券的 Python 实现 在如今的互联网时代,自动化脚本已经成为了许多用户生活中不可或缺的工具。尤其是在购物、抢券等场景中,自动化脚本能够帮助我们节省大量的时间和精力。今天,我们将一起探索如何使用 Python 编写一个简单的脚…...

【ONLYOFFICE 文档 8.2 版本深度测评】功能革新与用户体验的双重飞跃
引言 在数字化办公的浪潮中,ONLYOFFICE 文档以其强大的在线协作功能和全面的办公套件解决方案,赢得了全球用户的青睐。随着 8.2 版本的发布,ONLYOFFICE 再次证明了其在办公软件领域的创新能力和技术实力。 一.协作编辑 PDF:团队合…...

npm入门教程18:npm发布npm包
一、准备工作 注册npm账号: 前往npm官网注册一个账号。注册过程中需要填写个人信息,并完成邮箱验证。 安装Node.js和npm: 确保你的计算机上已安装Node.js和npm。Node.js的安装包中通常包含了npm。你可以通过运行node -v和npm -v命令来检查它…...

VueSSR详解 VueServerRenderer Nutx
SSR Vue中的SSR(Server-Side Rendering,服务器端渲染)是一种将页面的渲染工作从客户端转移到服务器端的技术。以下是对Vue中SSR的详细解释: 一、SSR的工作原理 在传统的客户端渲染(CSR)中,页面的…...

构建您自己的 RAG 应用程序:使用 Ollama、Python 和 ChromaDB 在本地设置 LLM 的分步指南
在数据隐私至关重要的时代,建立自己的本地语言模型 (LLM) 为公司和个人都提供了至关重要的解决方案。本教程旨在指导您完成使用 Ollama、Python 3 和 ChromaDB 创建自定义聊天机器人的过程,所有这些机器人都托管在您的系统本地。以…...

谷歌浏览器安装axure插件
1.在生成静态原型页面的路径下,找到resources\chrome\axure-chrome-extension.crx,这就是需要的插件了。 2.将axure-chrome-extension.crx重命名成axure-chrome-extension.zip然后解压到指定的文件夹(这个文件夹不能删除, 例如解压到了扩展程…...

Java唯一键实现方案
数据唯一性 1、生成UUID1.1 代码中实现1.2 数据库中实现优点缺点 2、数据库递增主键优点 3、数据库递增序列3.1 创建序列3.2 使用序列优点缺点 在Java项目开发中,对数据的唯一性要求,业务数据入库的时候保持单表只有一条记录,因此对记录中要求…...

opencv - py_imgproc - py_canny Canny边缘检测
文章目录 Canny 边缘检测目标理论OpenCV 中的 Canny 边缘检测其他资源 Canny 边缘检测 目标 在本章中,我们将学习 Canny 边缘检测的概念用于该目的的 OpenCV 函数:cv.Canny() 理论 Canny 边缘检测是一种流行的边缘检测算法。它由 John F. Canny 于1…...

Spring Boot 创建项目详细介绍
上篇文章简单介绍了 Spring Boot(Spring Boot 详细简介!),还没看到的读者,建议看看。 下面,介绍一下如何创建一个 Spring Boot 项目,以及自动生成的目录文件作用。 Maven 构建项目 访问 http…...

70B的模型需要多少张A10的卡可以部署成功,如果使用vLLM
部署一个 70B 的模型(如 defog/sqlcoder-70b-alpha)通常需要考虑多个因素,包括模型的内存需求和你的 GPU 配置。 1. 模型内存需求 大约计算,一个 70B 参数的模型在使用 FP16 精度时大约需要 280 GB 的 GPU 内存。对于 A10 GPU&a…...

clickhouse配置用户角色与权限
首先找到user.xml文件,默认在/etc/clickhouse-server路径下 一、配置角色 找到标签定义 <aaaa><readonly>1</readonly><allow_dll>0</allow_dll> </aaaa>其中aaaa为角色名称,readonly为只读权限(0–代表…...

面试题整理 4
总结整理了某公司面试中值得记录的笔试和问到的问题和答案。 目录 PHP传值和传引用区别?什么情况下用传值?什么情况下用传引用? 传值 传引用 区别 选择传值还是传引用时 简述PHP的垃圾回收机制 二维数组排序 什么是CSRF攻击ÿ…...

React基础大全
文章目录 一、React基本介绍1.虚拟DOM优化1.1 原生JS渲染页面1.2 React渲染页面 2.需要提前掌握的JS知识 二、入门1.React基本使用2.创建DOM的两种方式2.1 使用js创建(一般不用)2.2 使用jsx创建 3.React JSX3.1 JSX常见语法规则3.2 for循环渲染数据 4.模…...

51c大模型~合集10
我自己的原文哦~ https://blog.51cto.com/whaosoft/11547799 #Llama 3.1 美国太平洋时间 7 月 23 日,Meta 公司发布了其最新的 AI 模型 Llama 3.1,这是一个里程碑时刻。Llama 3.1 的发布让我们看到了开源 LLM 有与闭源 LLM 一较高下的能力。 Meta 表…...

本事同根生,相煎何太急
简 介: 【轮腿组比赛难度调整建议】针对智能车竞赛轮腿穿越组室外赛道的视觉识别难题,参赛选手提出以下建议:1.科目三元素应避开塑胶跑道线干扰区域;2.当前轮腿组任务量(机械、控制、导航、视觉等)已远超往…...

基于RAG技术构建AI知识库插件:从原理到实践
1. 项目概述与核心价值最近在折腾个人知识库和AI助手,发现一个挺有意思的插件项目:urantia-hub/urantia-papers-plugin。乍一看这个名字,可能很多人会有点懵,不知道这具体是干嘛的。简单来说,这是一个为AI助手…...

基于小安派-Eyes-DU的PWM呼吸灯实现:从环境搭建到代码烧录全解析
1. 项目概述上周,安信可开源硬件社区发布了一款名为“小安派-Eyes-DU”的新板子,我第一时间就入手了。作为一名嵌入式开发爱好者,拿到新板子后的第一件事,自然是想办法“点亮”它,看看它的能耐。官方资料里提到了一个亮…...

从零构建卡组构筑器:React+TS实战与复杂状态管理解析
1. 项目概述:从零构建一个卡组构筑器最近在GitHub上看到一个挺有意思的项目,叫guladam/deck_builder_tutorial。光看名字,很多朋友可能第一反应是“哦,一个教你怎么做卡组构筑器的教程”。但如果你真的点进去,或者像我…...

Minecraft服务器技能数据自动化管理:mcpskills-cli命令行工具实战指南
1. 项目概述与核心价值 最近在折腾一些Minecraft服务器的自动化管理,发现很多重复性的技能配置、权限同步工作特别耗时。手动去游戏里敲指令,或者对着配置文件一条条改,效率低还容易出错。就在这个当口,我发现了 alibiinformatio…...

智能体技能库构建指南:从基础工具到复杂工作流编排
1. 项目概述:智能体技能库的构建与价值最近在探索AI智能体(Agent)的开发与应用时,我一直在思考一个问题:一个真正“智能”的智能体,其核心能力究竟体现在哪里?是背后的大语言模型(LL…...

工业物联网数据上云省钱实战:边缘预处理与协议瘦身详解
背景与问题 工业物联网项目落地时,带宽费用往往是降本增效的第一道坎。几百台设备每秒上传数据,每月带宽费轻易上万,其中大量数据属于冗余“常态数据”。本文记录一套低成本方案:通过边缘计算网关做数据清洗与协议压缩,…...

免费电商平台批量下载图片方法,好用的让你不敢相信
pc+浏览器方法,批量快速下载淘宝、拼多多、抖音等常用电商均满足。 全程不花一分钱,所有资源都免费。 方法简单,操作方便。 只需在浏览其中增加 (downpictures) 当图扩展即可。 一、操作方法如下: 1、如使用edge浏览器,访问这个网址:当图 ,然后点击按钮“获取”,…...

AI Agent工作流引擎:从DAG编排到生产级应用实践
1. 项目概述:AI Agent工作流引擎的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“ai-agent-workflow”。光看名字,你可能觉得这又是一个关于AI智能体的框架,但仔细研究它的代码和设计理念,你会发现它瞄准的是一…...
)
文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板)
更多请点击: https://intelliparadigm.com 第一章:文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板) 核心痛点与监控目标 现代开发者文档(如 P…...