大数据导论及分布式存储HadoopHDFS入门
思维导图





数据导论
数据是什么?
进入21世纪,我们的生活就迈入了"数据时代" 作为21世纪的新青年,"数据"一词经常出现。
数据无时无刻的在影响着我们的现实生活
什么是数据? 数据又如何影响现实生活?
数据:一种可以被鉴别的对客观事件进行记录的符号。 简单来说就是:对人类的行为及产生的事件的一种记录.
我们无时无刻都在产生数据:

数据的价值


大数据时代
当下时代已经是数据的时代,数据非常重要并且蕴含巨大的价值。

1. 什么是数据?
人类的行为及产生的事件的一种记录称之为数据
2. 数据有什么价值?
对数据的内容进行深入分析,可以更好的帮助了解事和物在现实世界的运行规律
比如,购物的订单记录(数据)可以帮助平台更好的了解消费者,从而促进交易。
大数据诞生
大数据的诞生
大数据的诞生和信息化以及互联网的发展是密切相关的。

大数据的诞生和信息化以及互联网的发展是密切相关的。


上世纪70年代后,逐步出现了基于TCP/IP协议的小规模的计算机互联互通。 但多数是军事、科研等用途。

上世纪90年代左后,全球互联的互联网出现。
个人、企业均可参与其中,真正逐步的实现了全球互联。

在2000年后,互联网上的商业行为剧增
现在知名的互联网公司(谷歌、AWS、腾讯、阿里等)也是在这个年代开始起步。
在互联网参与者众多的前提下,商业公司、科研单位等,所能获得的数据量也是剧增。

剧增的数据量,和羸弱的单机性能,让许多科技公司开始尝试以数量来解决问题。

在这个过程中,分布式处理技术诞生了。



1. 大数据的诞生是跟随着互联网的发展的
当全球互联网逐步建成(2000年左右),各大企业或政府单位拥有了海量的数据亟待处理。
基于这个前提逐步诞生了以分布式的形式(即多台服务器集群)完成海量数据处理的处理方式,并逐步发展成现代大数据体系。
2. Apache Hadoop对大数据体系的意义
第一款获得业界普遍认可的开源分布式解决方案
让各类企业都有可用的企业级开源分布式解决方案
一定程度上催生出了众多的大数据体系技术栈
从Hadoop开始(2008年左右)大数据开始蓬勃发展
大数据概念
大数据是指无法用传统的数据处理工具和方法,在合理的时间内进行捕获、管理和处理的大规模、复杂和多样化的数据集合。随着互联网、物联网、社交媒体等技术的发展,数据量呈指数级增长,大数据的概念应运而生。
大数据的普通认知:bigdata,无法用常规软件处理的数据集合,需要一种新的模式(分布式)去处理
大数据的核心思想:分而治之(分布式)
大数据解决的问题:
海量数据的存储
海量数据的计算
海量数据的迁移
海量数据的查询
大数据的应用场景:为生活赋能/大数据人工智能时代/数字化时代,如智慧城市、智能制造、金融风控、健康医疗、互联网广告等。
狭义上:对海量数据进行处理的软件技术体系
广义上:数字化、信息化时代的基础支撑,以数据为生活赋能
大数据特点
大数据有5个主要特征,称之为:5V特性


大数据的核心工作
从海量的高增长、多类别、低信息密度的数据中挖掘出高质量的结果


后续将学习的技术也是围绕着这三点来进行的,即:
分布式存储相关技术栈
分布式计算相关技术栈
海量数据传输相关技术栈
1. 什么是大数据
狭义上:对海量数据进行处理的软件技术体系
广义上:数字化、信息化时代的基础支撑,以数据为生活赋能
2. 大数据的5个主要特征
-
大:(数据量大)大数据的一个核心特点就是数据量巨大,通常用TB(太字节)、PB(拍字节)甚至更大单位来衡量。
-
多:(数据种类和来源多),大数据不仅包括传统的结构化数据,还包括半结构化和非结构化数据。例如,文本、图片、视频、音频等。
-
值:(低价值密度)虽然数据量庞大,但有用信息的密度较低,需要高效的数据处理技术来提取价值。
-
快:(增长速度快,处理速度快,获取速度快)数据流动速度快,需要实时或近实时处理。
-
信:结果准确,可以依赖
3. 大数据的核心工作:
存储:妥善保存海量待处理数据
计算:完成海量数据的价值挖掘
传输:协助各个环节的数据传输
大数据处理步骤
明确分析的目的和思路:把分析的目的分解成若干个不同的分析要点
数据收集:一般数据来源为数据库、第三方数据统计工具、文件数据等
数据处理:(E抽取T转换L加载)主要包含数据清洗、数据转化、数据提取、数据计算等
数据分析:提取为数据有价值的信息的过程
数据可视化:一般能用图说明问题的不用表格,能用表格说明问题的就不要用文字
撰写报告:数据分析报告作为结论总结
大数据生态
存储: Apache Hadoop HDFS、Apache HBase等
计算: Apache Hadoop MapReduce、Apache Spark、Apache Flink
传输: Apache Sqoop、Apache Flume、Apache Kafka等
大数据主体上分成如下三大核心工作体系。

数据存储


数据计算


数据传输


大数据体系内的软件种类还是非常多的。在后续的学习中我们都能够逐步的接触到它们。

1. 大数据的核心工作:
存储:妥善保存海量待处理数据
计算:完成海量数据的价值挖掘
传输:协助各个环节的数据传输
2. 大数据软件生态
存储:Apache Hadoop HDFS、Apache HBase等
计算:Apache Hadoop MapReduce、Apache Spark、Apache Flink
传输:Apache Sqoop、Apache Flume、Apache Kafka等
hadoop发展历程
Hadoop创始人: Doug Cutting Hadoop起源于Apache Lucene子项目:Nutch Nutch的设计目标是构建一个大型的全网搜索引擎。 遇到瓶颈:如何解决数十亿网页的存储和索引问题 Google三篇论文: 三驾马车 《The Google file system》:谷歌分布式文件系统GFS 《MapReduce Simplified Data Processing on Large Clusters》:谷歌分布式计算框架MapReduce 《Bigtable A Distributed Storage System for Structured Data》:谷歌结构化数据存储系统 雅虎时代: 卡大爷带着hadoop去了雅虎.利用雅虎的资源发展技术. 开源社区版本: Apache软件基金会(Apache Software Foundation,简称ASF)是专门支持开源项目的一个非盈利性组织。 URL:http://hadoop.apache.org/ 商业发行版本: CDH(Cloudera's Distribution, including Apache Hadoop) Cloudera公司出品,目前使用最多的商业版 1.x版本系列: HDFS 和 MapReduce 2.x版本系列: HDFS 和 MapReduce 和 YARN 主要基于jdk7,但是jdk7在15年左右不更新,不得不切换更新版本 3.x版本系列: HDFS 和 MapReduce 和 YARN 依赖jdk8
什么是Hadoop?

Hadoop是Apache软件基金会下的顶级开源项目,用以提供:
分布式数据存储
分布式数据计算
分布式资源调度
为一体的整体解决方案。
Apache Hadoop是典型的分布式软件框架,可以部署在1台乃至成千上万台服务器节点上协同工作。 个人或企业可以借助Hadoop构建大规模服务器集群,完成海量数据的存储和计算。
Hadoop发展

Hadoop创始人:Doug Cutting
Hadoop起源于Apache Lucene子项目:Nutch
Nutch的设计目标是构建一个大型的全网搜索引擎。
遇到瓶颈:如何解决数十亿网页的存储和索引问题
Google三篇论文
《The Google file system》:谷歌分布式文件系统GFS
《MapReduce: Simplified Data Processing on Large Clusters》:谷歌分布式计算框架MapReduce
《Bigtable: A Distributed Storage System for Structured Data》:谷歌结构化数据存储系统

Hadoop发行版本

开源社区版本
Apache软件基金会(Apache Software Foundation,简称ASF)是专门支持开源项目的一个非盈利性组织。
URL:http://hadoop.apache.org/
商业发行版本
CDH(Cloudera's Distribution, including Apache Hadoop) Cloudera公司出品,目前使用最多的商业版
HDP(Hortonworks Data Platform),Hortonworks公司出品,目前被Cloudera收购
星环,国产商业版,星环公司出品,在国内政企使用较多
1. 什么是Hadoop
Hadoop是开源的技术框架,提供分布式存储、计算、资源调度的解决方案
2. Hadoop的发展
创始人Doug Cutting
基于Nutch搜索项目发展
发展受到Google三篇著名的论文影响
3. Hadoop的版本
Apache 开源社区版 (原生版本)
Cloudera等商业公司自行封装的商业版
分布式和集群
分布式: 分布式的主要工作是分解任务,将职能拆解给多个服务器,多个服务器在一起做不同的事,配合完成同一个任务 集群: 集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
分布式
概念
分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情
单机模式

该模式可以形象的比喻为:一个餐厅的厨房只有一个人,这个人既要买菜、又要切菜、还要炒菜,效率很低!
分布式模式

该模式可以形象的比喻为:一个餐厅的厨房有三个人,一个人买菜、一个人切菜、一个人炒菜,效率提高了!
集群
概念
所谓集群是指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。

分布式的基础架构
数量多,在现实生活中往往带来的不是提升,而是:混乱。
同学们思考一下, 众多的服务器一起工作,是如何高效、不出问题呢?
大数据体系中,分布式的调度主要有2类架构模式:
去中心化模式
中心化模式
去中心化模式

去中心化模式,没有明确的中心。
众多服务器之间基于特定规则进行同步协调。
中心化模式

主从模式
大数据框架,大多数的基础架构上,都是符合:中心化模式的。
即:有一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派,避免混乱。
这种模式,也被称之为:一主多从模式,简称主从模式(Master And Slaves)
我们学习的Hadoop框架,就是一个典型的主从模式(中心化模式)架构的技术框架。

分布式和集群区别?
分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
Hadoop是哪种分布式架构模式?
主从模式(中心化模式)的架构
Hadoop框架概论
Hadoop介绍

Hadoop是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
Hadoop是Apache Lucene创始人 Doug Cutting 创建的,最早起源一个Nutch项目。
2003年Google发表了一篇GFS论文,为大规模数据存储提供了可行的解决方案。
2004年 Google发表论文MapReduce系统,为大规模数据计算提供可行的解决方案。
Nutch的开发人员以谷歌的论文为基础,完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目Hadoop。
到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
如今,国内外的互联网巨头基本都在使用Hadoop框架作为大数据解决方案,越来越多的企业将Hadoop 技术作为进入大数据领域的必备技术。
Hadoop框架内容
狭义解释
Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
MAPREDUCE(分布式运算编程框架):解决海量数据计算
YARN(作业调度和集群资源管理的框架):解决资源任务调度
广义解释
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop国内外应用
国外应用
Yahoo

Yahoo的Hadoop机器总节点数目已经超过42000个,有超过10万的核心CPU在运行Hadoop,总的集群存储容量大于350PB,每月提交的作业数目超过1000万个。
Yahoo的Hadoop应用主要包括以下几个方面:
广告系统支持
用户行为分析
Web搜索支持
反垃圾邮件系统
个性化推荐
国内应用
阿里巴巴

阿里巴巴的Hadoop集群大约有3200台服务器,大约30000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150000个
Hadoop集群主要为电子商务网络平台提供底层的基础计算和存储服务,主要应用包括:
· 数据平台系统。
· 搜索支撑。
· 电子商务数据。
· 推荐引擎系统。
· 搜索排行榜。
Hadoop版本
发行版
Hadoop发行版本分为开源社区版和商业版。
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差。
商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH等。
三大版本
1.x版本系列:hadoop的第二代开源版本,该版本基本已被淘汰
2.x版本系列:架构产生重大变化,引入了Yarn平台等许多新特性,是现在使用的主流版本。 3.x版本系列: 该版本是最新版本。
Hadoop架构
HDFS(分布式存储文件系统): 解决了海量数据的存储
NameNode(主节点):管理从节点,分配存储数据的任务 存储元数据(描述数据的数据) SecondaryNameNode(辅助主节点): 帮助主节点合并管理元数据
DataNode(从节点):存储海量数据
YARN(资源调度的组件): 解决了多任务的资源调度
ResourceManager(主节点): 接收用户计算请求任务 根据任务进行资源分配 NodeManager(从节点): 执行主节点分配的任务
MapReduce(分布式计算组件): 解决了海量数据的计算
核心思想: 分而治之
map阶段: 先拆分成多个map任务
reduce阶段: 再执行reduce任务把各个map结果合并归纳
三大组件配合:
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop架构模块

Hadoop2.x架构内部模型-HDFS和Yarn

HDFS模块:
NameNode(主节点):集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode(辅助主节点):主要能用于hadoop当中元数据信息的辅助管理
DataNode(从节点):集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager(主节点):接收用户的计算请求任务,并负责集群的资源分配
NodeManager(从节点): 负责执行主节点分配的任务
Hadoop2.x架构模型-MapReduce

Hadoop模块之间的关系
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop集群搭建
集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群
NameNode、DataNode、SecondaryNameNode
YARN集群
ResourceManager、NodeManager
集群搭建方式
Standalone mode(单机模式)
单机模式, 1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,主要用于学习和调试。
Cluster mode(集群模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
大数据集群方案-单机模式

注意,在单机模式下,要求Windows系统运行内存至少也是8G!
大数据集群方案-集群模式
本套已经搭建好Hadoop所有的开发环境,集群模式方案如下:

注意,在集群模式下,要求Windows系统运行内存至少是16G!
Hadoop集群使用
集群介绍:
用户名: root
密码: 123456
初始使用: 把三台虚拟机快照恢复到7hive安装完成 注意: hive没有配置环境变量,可以自己配置
启动集群
启动hdfs和yarn命令: start-all.sh
停止hdfs和yarn命令: stop-all.sh
启动mr历史任务服务器: mapred --daemon start historyserver
jps: 查看java进程的一个小工具
本地配置域名映射
注意: 想要上传文件夹需要配置本地域名映射
hosts文件路径: C:\Windows\System32\drivers\etc
把以下内容复制到文件末尾,保存
192.168.88.161 node1.itcast.cn node1
192.168.88.162 node2.itcast.cn node2
192.168.88.163 node3.itcast.cn node3
配置完成后,可以直接通过node1访问
Hadoop启动和关闭-集群模式
1、启动三台虚拟机
在资料中已经提供好了三台虚拟机, 分别为node1(192.168.88.161)、node2(192.168.88.162)、node3(192.168.88.163)
2、使用CRT分别连接三台虚拟机
3、集群一键启动和关闭
一键启动大数据环境

一键关闭大数据环境

注意: 想要查看mr历史任务需要单独启动historyserver


Hadoop页面访问-集群模式
4.查看启动进程-jps java的进程



5、查看HDFS页面
启动NameNode.连接URL: http://192.168.88.161:9870

6、查看YARN页面
启动ResourceManager.连接URL:http://192.168.88.161:8088

7、查看已经finished的mapreduce运行日志
启动historyserver.连接URL:http://192.168.88.161:19888

web-ui页面查看
HDFS: http://node1:9870/
YARN: http://node1:8088/
MR: http://node1:19888
官方MapReduce示例
在Hadoop的安装包中,官方提供了MapReduce程序的示例examples,以便快速上手体验MapReduce。
该示例是使用java语言编写的,被打包成为了一个jar文件。
/export/server/hadoop-3.3.0/share/hadoop/mapreduce

评估圆周率π(PI)
MapReduce程序评估一下圆周率的值,执行中可以去YARN页面上观察程序的执行的情况。 hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi x y
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数x:用于指定map阶段运行的任务次数,并发度,举例:x=10
第三个参数y:用于指定每个map任务取样的个数,举例: x=50。


单词词频统计WordCount
WordCount算是大数据统计分析领域的经典需求了,相当于编程语言的HelloWorld。统计文本数据中, 相同单词出现的总次数。用SQL的角度来理解的话,相当于根据单词进行group by分组,相同的单词 分为一组,然后每个组内进行count聚合统计。
已知word.txt文件内容如下,计算每个单词出现的次数
zhangsan lisi wangwu zhangsan
zhaoliu lisi wangwu zhaoliu
xiaohong xiaoming hanmeimei lilei
zhaoliu lilei hanmeimei lilei


第一个参数:wordcount表示执行单词统计的MapReduce程序;
第二个参数:指定输入文件的路径;
第三个参数:指定输出结果的路径(注意:该路径不能已存在);

配置本地域名解析:

# HadoopCluster
192.168.88.161 node1.itcast.cn node1
192.168.88.162 node2.itcast.cn node2
192.168.88.163 node3.itcast.cn node3#添加后保存关闭
HDFS文件系统
HDFS的概述
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统 。
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。

HDFS的特点

HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。
HDFS的架构
HDFS采用Master/Slave架构
一个HDFS集群有两个重要的角色,分别是Namenode和Datanode。
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。

1、Client
就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode
就是 master,它是一个主管、管理者。
管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息….)。
配置副本策略。
处理客户端读写请求。
3、DataNode
就是Slave。
NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块。
执行数据块的读/写操作。
定时向namenode汇报block信息。
4、Secondary NameNode
并非 NameNode 的热备。
当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。 在紧急情况下,可辅助恢复 NameNode。
HDFS的副本机制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
hdfs配置文件:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。 hadoop 当中, 文件的 block 块大小默认是 128M(134217728字节)。
hadoop 当中, 文件的 block 块大小默认是 128M(134217728字节)默认是3个副本。
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
hdfs配置文件:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。

HDFS的Shell命令
HDFS的shell命令: 操作命令类似于Linux的shell对文件的操作,如ls、mkdir、rm等。
HDFS的shell命令格式:
格式1: hadoop fs <args> # 既可以操作HDFS,也可以操作本地系统
或者
格式2: hdfs dfs <args> # 只能操作HDFS系统可以使用hdfs dfs -h 查看所有命令
put: 上传 本地linux系统上传到HDFS文件系统上
get: 下载 从HDFS文件系统上下载到本地
Shell命令介绍
安装好hadoop环境之后,可以执行hdfs相关的shell命令对hdfs文件系统进行操作,比如文件的创建、删除、修改文件权限等。
对HDFS的操作命令类似于Linux的shell对文件的操作,如ls、mkdir、rm等。
Hadoop提供了文件系统的shell命令使用格式如下:





ls命令

mkdir命令

put命令

get命令
hadoop fs -get [-f] [-p] <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。

mv命令

rm命令

cp命令

cat命令

HDFS shell命令行常用操作
合并下载HDFS文件
hadoop fs -getmerge [-nl] [-skip-empty-file] <src> <localdst>
下载多个文件合并到本地文件系统的一个文件中。
-nl选项表示在每个文件末尾添加换行符

追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果<localSrc>为-,则输入为从标准输入中读取。

相关文章:
大数据导论及分布式存储HadoopHDFS入门
思维导图 数据导论 数据是什么? 进入21世纪,我们的生活就迈入了"数据时代" 作为21世纪的新青年,"数据"一词经常出现。 数据无时无刻的在影响着我们的现实生活 什么是数据? 数据又如何影响现实生活? 数据…...

语言模型的采样方法
语言模型的采样方法 语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。 在采用自回归范式的文本生成任务中,语言模型将依次生成一组向量并将其解码为文本。将这组向量解码为文本的过程被成为语言模型解码。 解码过程显著影响着生成文本…...

使用 Nginx 配置真实 IP 地址转发
使用 Nginx 配置真实 IP 地址转发 在许多 web 应用程序中,获取客户端的真实 IP 地址非常重要,尤其是在使用反向代理服务器(如 Nginx)时。本文将指导你如何在 Nginx 中配置 X-Real-IP 和 X-Forwarded-For 头部,以确保你…...

WPF+MVVM案例实战与特效(二十四)- 粒子字体效果实现
文章目录 1、案例效果2、案例实现1、文件创建2.代码实现3、界面与功能代码3、总结1、案例效果 提示:这里可以添加本文要记录的大概内容: 2、案例实现 1、文件创建 打开 Wpf_Examples 项目,在 Views 文件夹下创建窗体界面 ParticleWindow.xaml,在 Models 文件夹下创建粒子…...

Oracle视频基础1.4.3练习
15个视频 1.4.3 できない dbca删除数据库 id ls cd cd dbs ls ls -l dbca# delete a database 勾选 # chris 勾选手动删除数据库 ls ls -l ls -l cd /u01/oradata ls cd /u01/admin/ ls cd chris/ ls clear 初始化参数文件,admin,数据文件#新版本了…...

energy 发布 v2.4.5
更新内容 修复 energy cli install 命令安装开发环境 修复 动态库加载error未暴露 增加 JS ipc.on 监听模式,异步返回结果 修复 energy cli 不能强制退出问题 修复 MacOS 开发模式 debug 时不更新 helper 进程 优化 energy cli 在 MacOS 开发模式和安装包制作 link…...
一文详解工单管理系统,工单系统是什么意思
在现代企业管理中,工单管理系统已经成为提升效率和客户满意度的重要工具。随着企业规模的扩大和业务复杂性的增加,传统的手工工单处理方式已经无法满足企业的需求。本文将详细解析工单管理系统的定义、功能、优势,并推荐一款优秀的工单管理系…...

【无标题】基于SpringBoot的母婴商城的设计与实现
一、项目背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这样的大环境让那些止步不前,…...

你需要了解的Android主题相关知识
在 Android 开发中,主题(Theme)是用于定义应用的视觉风格的一组样式集合。主题决定了应用的配色、字体样式、控件外观等,是整个应用的一致性视觉体验的重要组成部分。以下是对 Android 主题的全面介绍,包括主题的基础概…...

基于Multisim数控直流稳压电源电路(含仿真和报告)
【全套资料.zip】数控直流稳压电源电路设计Multisim仿真设计数字电子技术 文章目录 功能一、Multisim仿真源文件二、原理文档报告资料下载【Multisim仿真报告讲解视频.zip】 功能 1.输出直流电压调节范围5-12V。 2.输出电流0-500mA。 3.输出直流电压能步进调节,步…...

精读预告Bigtable
文章目录 1. 引言:2. 背景 1. 引言: 在本期的精读会中,我们将深入解读另一篇具有里程碑意义的论文——《Bigtable: A Distributed Storage System for Structured Data》。这篇论文详细介绍了 Bigtable 作为谷歌用于管理结构化数据的分布式存…...
软件架构演变:从单体架构到LLM链式调用
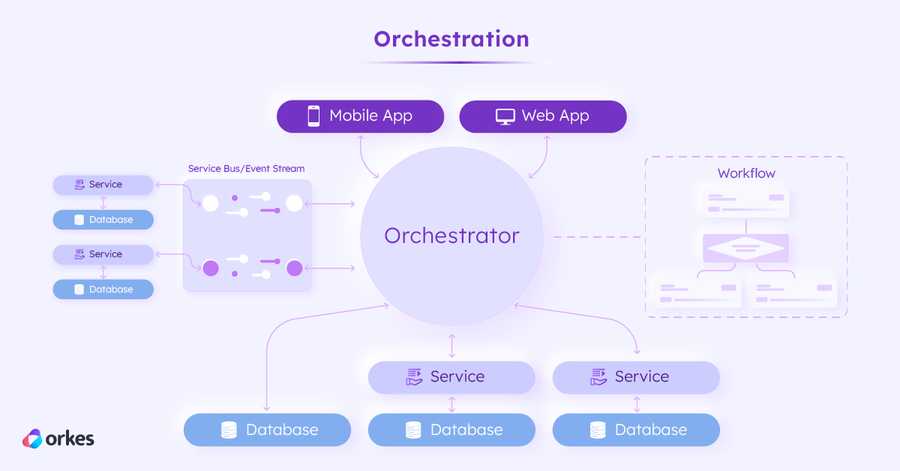
0 前言 软件架构——我们数字世界的蓝图——自20世纪中叶计算机时代诞生以来,已经发生了巨大演变。 20世纪60年代和70年代早期,以大型主机和单体软件为主导。而今天,数字领域已完全不同,运行在由云计算、API连接、AI算法、微服务…...

Redis-“自动分片、一定程度的高可用性”(sharding水平拆分、failover故障转移)特性(Sentinel、Cluster)
文章目录 零、写在前面一、水平拆分(sharding/分片)、故障转移(failover)机制介绍水平拆分(Sharding)故障转移机制 二、Redis的水平拆分的机制有关的配置1. 环境准备2. 配置文件配置3. 启动所有Redis实例4. 创建集群5. 测试集群读/写6. 集群管理 三、Red…...
 (并发-----原子性/互斥临界区/生产者消费者问题/临界区问题三条件/互斥性/进展性/公平性))
操作系统(9) (并发-----原子性/互斥临界区/生产者消费者问题/临界区问题三条件/互斥性/进展性/公平性)
目录 1. 并发(Concurrency)的定义 2. 原子性(Atomicity) 3. 互斥(Mutual Exclusion) 4. 生产者-消费者问题(Producer-Consumer Problem) 5. 临界区Critical Section 6. 临界区问题…...

Django响应
HTTPResponse: 是由Django创造的, 他的返回格式为 HTTPResponse(content响应体,content_type响应体数据类型,status状态码), 可以修改返回的数据类型,适用于返回图片,视频,音频等二进…...

算法:图的相关算法
图的相关算法 1. 图的遍历算法1.1 深度优先搜索1.2 广度优先搜索 2. 最小生成树求解算法普里姆(Prim)算法克鲁斯卡尔(Kruskal)算法 3. 拓扑排序4. 最短路径算法 1. 图的遍历算法 图的遍历是指从某个顶点出发,沿着某条搜索路径对图中的所有顶点进行访问且只访问次的…...

django的models使用介绍。
from django.db import modelsfrom utils.models import CommonModel# Create your models here. class User(CommonModel):#用户数据模型username models.CharField(用户名,max_length32, uniqueTrue)password models.CharField(密码,max_length256)nickname models.CharFi…...

【分布式技术】分布式事务深入理解
文章目录 概述产生原因关键点 分布式事务解决方案3PC3PC的三个阶段:3PC相比于2PC的改进:3PC的缺点: TCCTCC事务的三个阶段:TCC事务的设计原则:TCC事务的适用场景:TCC事务的优缺点:如何解决TCC模…...

力扣hot100-->hash表/map
hash表/map 1. 1. 两数之和 简单 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 …...

基于redis实现延迟队列
Redis实现延时队列 延时队列里装的主要是延时任务,用延时队列来维护延时任务的执行时间。 1、延时队列有哪些使用情景? 1、如果请求加锁没加成功 可以将这个请求扔到延时队列里,延后处理。 2、业务中有延时任务的需要 比如说࿰…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...