【C++篇】数据之林:解读二叉搜索树的优雅结构与运算哲学
文章目录
- 二叉搜索树详解:基础与基本操作
- 前言
- 第一章:二叉搜索树的概念
- 1.1 二叉搜索树的定义
- 1.1.1 为什么使用二叉搜索树?
- 第二章:二叉搜索树的性能分析
- 2.1 最佳与最差情况
- 2.1.1 最佳情况
- 2.1.2 最差情况
- 2.2 平衡树的优势
- 第三章:二叉搜索树的基本操作实现
- 3.1 插入操作详解
- 3.1.1 详细示例
- 3.1.2 循环实现插入操作
- 3.1.2.1 逻辑解析:
- 3.2 查找操作详解
- 3.2.1 详细示例
- 3.2.2 循环实现查找操作
- 3.2.2.1 逻辑解析:
- 3.3 删除操作详解
- 3.3.1 详细示例
- 3.3.2 循环实现删除操作
- 3.3.2.1 逻辑解析:
- 3.4 遍历操作详解
- 3.4.1 中序遍历
- 3.4.1.1 示例代码
- 3.4.1.2 逻辑解析:
- 3.4.2 前序遍历
- 3.4.2.1 示例代码
- 3.4.2.2 逻辑解析:
- 3.4.3 后序遍历
- 3.4.3.1 示例代码
- 3.4.3.2 逻辑解析:
- 总结
二叉搜索树详解:基础与基本操作
💬 欢迎讨论:在学习过程中,如果有任何疑问或想法,欢迎在评论区留言一起讨论。
👍 点赞、收藏与分享:觉得这篇文章对你有帮助吗?记得点赞、收藏并分享给更多的朋友吧!你们的支持是我不断进步的动力!
🚀 分享给更多人:如果你觉得这篇文章对你有帮助,欢迎分享给更多对数据结构感兴趣的朋友,一起学习进步!
前言
二叉搜索树(Binary Search Tree, BST)是一种重要的数据结构,广泛应用于计算机科学中的数据管理和检索。它允许高效的查找、插入和删除操作,且在最佳情况下能够达到对数时间复杂度。
本文将深入探讨二叉搜索树的概念、性能分析及其基本操作,通过详细的示例和解释,帮助读者理解如何构建和操作这一数据结构。
第一章:二叉搜索树的概念
1.1 二叉搜索树的定义
二叉搜索树是一种特殊的二叉树,其具有以下特性:
- 节点的左子树:所有节点的值小于或等于该节点的值。
- 节点的右子树:所有节点的值大于该节点的值。
- 每个节点的左右子树也都是二叉搜索树。

这种结构确保了我们可以有效地进行查找、插入和删除操作。
1.1.1 为什么使用二叉搜索树?
- 快速查找:由于节点的结构特性,查找操作可以在平均
O(log N)时间内完成。 - 动态数据支持:允许动态插入和删除数据,能够应对频繁变化的数据集。
- 有序性:通过中序遍历,我们能够得到一个升序的序列,这对于某些算法(如排序)非常有用。
第二章:二叉搜索树的性能分析
2.1 最佳与最差情况
2.1.1 最佳情况
- 完全二叉树:
- 当树为完全平衡时,查找、插入和删除的时间复杂度均为
O(log N)。例如,若插入的顺序是随机的,树可能较为平衡,此时查找、插入和删除的时间复杂度均为O(log N)。
- 当树为完全平衡时,查找、插入和删除的时间复杂度均为

2.1.2 最差情况
- 退化成链表的情况:
- 如果数据以有序方式插入(例如:1, 2, 3, …),二叉搜索树将退化为链表,导致每次操作都需遍历整个链表,此时时间复杂度变为
O(N)。
- 如果数据以有序方式插入(例如:1, 2, 3, …),二叉搜索树将退化为链表,导致每次操作都需遍历整个链表,此时时间复杂度变为
2.2 平衡树的优势
为了避免最坏情况的发生,平衡二叉树(如AVL树和红黑树)引入了旋转操作,确保在插入和删除时树的高度保持平衡。这样,在任何情况下,操作的时间复杂度均保持在O(log N)。
- 自平衡机制:通过旋转和重组树的结构,动态维护树的高度,使其尽可能接近
O(log N)的状态。
第三章:二叉搜索树的基本操作实现
3.1 插入操作详解
插入操作是构建二叉搜索树的基本步骤之一。其主要流程如下:
-
判断树是否为空:
- 如果树为空,将新节点设为根节点。这是构建树的第一步。
-
比较并递归插入:
- 从根节点开始,根据节点值的大小决定向左子树还是右子树移动。
-
找到合适位置后插入:
- 当找到一个空位后,将新节点插入。


3.1.1 详细示例
让我们一步一步实现插入操作:
-
定义节点结构:
template<class K> class BSTNode { public:K _key; // 存储节点的值BSTNode<K>* _left; // 左子节点BSTNode<K>* _right; // 右子节点BSTNode(const K& key) : _key(key), _left(nullptr), _right(nullptr) {} };- 解释:每个节点包含一个值和两个指向左右子节点的指针。使用模板类使得节点能够存储不同类型的数据。
-
定义树结构:
template<class K> class BSTree { private:BSTNode<K>* _root; // 根节点public:BSTree() : _root(nullptr) {} // 初始化树为空bool Insert(const K& key) {if (_root == nullptr) { // 树为空_root = new BSTNode<K>(key); // 新建根节点return true;}return _InsertRec(_root, key); // 从根节点开始插入}private:bool _InsertRec(BSTNode<K>* node, const K& key) {if (key < node->_key) { // 插入值小于当前节点if (node->_left == nullptr) { // 左子节点为空node->_left = new BSTNode<K>(key); // 创建新节点return true;}return _InsertRec(node->_left, key); // 递归插入} else if (key > node->_key) { // 插入值大于当前节点if (node->_right == nullptr) { // 右子节点为空node->_right = new BSTNode<K>(key); // 创建新节点return true;}return _InsertRec(node->_right, key); // 递归插入}return false; // 处理相等值的逻辑} };- 插入逻辑解析:
- 首先检查树是否为空,若为空,则直接将新节点设为根节点。
- 如果不为空,通过比较当前节点的值与要插入值的大小,决定向左或向右移动。
- 当找到合适的空位时,插入新节点。
- 如果当前值与要插入值相等,可以选择不插入,或者进行其他处理。
- 插入逻辑解析:
3.1.2 循环实现插入操作
除了递归方式,插入操作也可以用循环实现。以下是使用循环方式的示例代码:
bool InsertIterative(const K& key) {if (_root == nullptr) { // 树为空_root = new BSTNode<K>(key); // 新建根节点return true;}BSTNode<K>* current = _root;BSTNode<K>* parent = nullptr;while (current != nullptr) {parent = current; // 记录父节点if (key < current->_key) {current = current->_left; // 移动到左子节点} else if (key > current->_key) {current = current->_right; // 移动到右子节点} else {return false; // 找到相等值,处理逻辑}}// 根据比较结果将新节点连接到父节点if (key < parent->_key) {parent->_left = new BSTNode<K>(key); // 插入左子节点} else {parent->_right = new BSTNode<K>(key); // 插入右子节点}return true;
}
3.1.2.1 逻辑解析:
- 循环控制:使用
while循环遍历树,直到找到合适的空位插入新节点。 - 记录父节点:通过记录当前节点的父节点,以便在找到合适位置后,将新节点正确连接。
3.2 查找操作详解
查找操作使我们能够确认一个值是否存在于树中。其步骤如下:
-
从根节点开始比较:
- 判断目标值与当前节点的值大小关系。
-
决定查找方向:
- 若目标值小于当前节点,则向左子树查找;若大于,则向右子树查找。
-
终止条件:
- 如果找到目标值,返回成功;若当前节点为空,则说明值不存在。
3.2.1 详细示例
bool Find(const K& key) {return _FindRec(_root, key); // 从根节点开始查找
}private:
bool _FindRec(BSTNode<K>* node, const K& key) {if (node == nullptr) return false; // 未找到if (key == node->_key) return true; // 找到if (key < node->_key) {return _FindRec(node->_left, key); // 向左子树查找} else {return _FindRec(node->_right, key); // 向右子树查找}
}
- 查找逻辑解析:
- 从根节点开始进行比较,根据大小关系决定查找方向。
- 采用递归方式,直到找到目标值或到达空节点。
3.2.2 循环实现查找操作
与插入一样,查找操作也可以用循环实现。以下是循环方式的示例代码:
bool FindIterative(const K& key) {BSTNode<K>* current = _root;while (current != nullptr) {if (key == current->_key) {return true; // 找到目标值} else if (key < current->_key) {current = current->_left; // 向左子树查找} else {current = current->_right; // 向右子树查找}}return false; // 未找到
}
3.2.2.1 逻辑解析:
- 循环控制:使用
while循环遍历树,直至找到目标值或到达空节点。 - 效率:循环方式避免了递归调用的开销,在处理深度较大的树时,能更有效地利用栈空间。
3.3 删除操作详解
删除操作需要考虑节点的子树情况,包括:
-
查找节点:首先需要找到要删除的节点。
-
判断情况:
- 没有子节点:直接删除。
- 只有一个子节点:将父节点指向子节点。
- 有两个子节点:选择用左子树的最大值或右子树的最小值替代删除的节点。



3.3.1 详细示例
bool Erase(const K& key) {return _EraseRec(_root, key); // 从根节点开始删除
}private:
bool _EraseRec(BSTNode<K>*& node, const K& key) {if (node == nullptr) return false; // 未找到if (key < node->_key) {return _EraseRec(node->_left, key); // 向左子树查找} else if (key > node->_key) {return _EraseRec(node->_right, key); // 向右子树查找} else {// 找到要删除的节点if (node->_left == nullptr) {BSTNode<K>* temp = node;node = node->_right; // 更新指向右子节点delete temp; // 删除旧节点} else if (node->_right == nullptr) {BSTNode<K>* temp = node;node = node->_left; // 更新指向左子节点delete temp; // 删除旧节点} else {// 找到替代节点BSTNode<K>* temp = _FindMax(node->_left); // 左子树的最大值node->_key = temp->_key; // 替代值_EraseRec(node->_left, temp->_key); // 删除替代节点}return true;}
}BSTNode<K>* _FindMax(BSTNode<K>* node) {while (node->_right != nullptr) {node = node->_right; // 寻找右子树的最大值}return node; // 返回最大节点
}
- 删除逻辑解析:
- 首先查找目标节点,确定其子树情况。
- 根据情况选择删除操作,并保持树的性质。
3.3.2 循环实现删除操作
虽然递归实现直观,但删除操作也可以用循环实现。以下是循环实现的示例代码:
bool EraseIterative(const K& key) {BSTNode<K>* current = _root;BSTNode<K>* parent = nullptr;// 找到要删除的节点和其父节点while (current != nullptr && current->_key != key) {parent = current;if (key < current->_key) {current = current->_left; // 向左子树查找} else {current = current->_right; // 向右子树查找}}// 如果未找到if (current == nullptr) return false;// 处理删除逻辑if (current->_left == nullptr) {if (current == _root) {_root = current->_right; // 更新根节点} else if (parent->_left == current) {parent->_left = current->_right; // 更新父节点的左指针} else {parent->_right = current->_right; // 更新父节点的右指针}} else if (current->_right == nullptr) {if (current == _root) {_root = current->_left; // 更新根节点} else if (parent->_left == current) {parent->_left = current->_left; // 更新父节点的左指针} else {parent->_right = current->_left; // 更新父节点的右指针}} else {// 找到替代节点BSTNode<K>* successor = _FindMin(current->_right); // 右子树的最小值K successorKey = successor->_key; // 备份替代值EraseIterative(successorKey); // 递归删除替代节点current->_key = successorKey; // 替代当前节点的值}delete current; // 删除当前节点return true;
}BSTNode<K>* _FindMin(BSTNode<K>* node) {while (node && node->_left != nullptr) {node = node->_left; // 寻找左子树的最小值}return node; // 返回最小节点
}
3.3.2.1 逻辑解析:
- 查找节点:通过循环查找要删除的节点及其父节点。
- 处理删除逻辑:根据节点的子树情况,选择合适的删除策略。
- 更新指针:确保在删除节点后,正确更新父节点的指向,保持树的完整性。
3.4 遍历操作详解
遍历操作是对二叉搜索树进行全面访问的方式,通常分为三种基本类型:前序遍历、中序遍历和后序遍历。每种遍历都有其特定的应用场景。
3.4.1 中序遍历
中序遍历(左-根-右)会按顺序输出树中的节点值,使得遍历结果是一个升序序列。
步骤:
- 先访问左子树。
- 然后访问根节点。
- 最后访问右子树。
3.4.1.1 示例代码
void InOrderTraversal(BSTNode<K>* node) {if (node == nullptr) return; // 如果节点为空,返回InOrderTraversal(node->_left); // 递归访问左子树cout << node->_key << " "; // 访问当前节点InOrderTraversal(node->_right); // 递归访问右子树
}
3.4.1.2 逻辑解析:
- 递归方式:此方法通过递归访问每个节点,确保按顺序访问。
- 输出顺序:中序遍历确保了节点值的升序排列,对于排序需求非常有用。
3.4.2 前序遍历
前序遍历(根-左-右)常用于复制树结构,因为它先访问根节点。
步骤:
- 先访问根节点。
- 然后访问左子树。
- 最后访问右子树。
3.4.2.1 示例代码
void PreOrderTraversal(BSTNode<K>* node) {if (node == nullptr) return; // 如果节点为空,返回cout << node->_key << " "; // 访问当前节点PreOrderTraversal(node->_left); // 递归访问左子树PreOrderTraversal(node->_right); // 递归访问右子树
}
3.4.2.2 逻辑解析:
- 根节点优先:此方法适合在需要先处理根节点的场景,例如在构建其他数据结构时。
- 结构复制:前序遍历有助于复制树结构,因为它提供了节点的先后顺序。
3.4.3 后序遍历
后序遍历(左-右-根)常用于删除树的节点,因为它先访问子节点。
步骤:
- 先访问左子树。
- 然后访问右子树。
- 最后访问根节点。
3.4.3.1 示例代码
void PostOrderTraversal(BSTNode<K>* node) {if (node == nullptr) return; // 如果节点为空,返回PostOrderTraversal(node->_left); // 递归访问左子树PostOrderTraversal(node->_right); // 递归访问右子树cout << node->_key << " "; // 访问当前节点
}
3.4.3.2 逻辑解析:
- 子节点优先:后序遍历确保在删除节点之前,先处理它的子节点。这种策略在清空树时非常重要。
- 删除操作:通常用在需要在树结构被修改前完成所有子树处理的场景。
总结
在这篇博客中,我们如同探险者,走进了二叉搜索树的奥秘世界,揭示了这一数据结构背后的智慧。二叉搜索树不仅是一种高效的数据存储与检索方式,更是算法与结构之美的结合。通过插入、查找和删除操作的细致分析,我们看到了效率与灵活性的完美平衡。
中序遍历所展现的有序之美、前序遍历的根节点优先以及后序遍历的从容处理,犹如乐章中的不同乐器,共同演绎出数据处理的交响曲。二叉搜索树不仅帮助我们优化程序性能,更启示我们在面对复杂问题时,保持思维的清晰与结构的严谨。
在这个快速发展的技术时代,掌握二叉搜索树的精髓,将使我们在数据的海洋中游刃有余。未来的学习旅程将更加丰富,二叉搜索树将继续为我们提供无尽的启示与灵感。
💬 讨论区:如果你有任何问题,欢迎在评论区留言讨论!
👍 支持一下:如果你觉得这篇文章对你有帮助,请点赞、收藏并分享给更多学习者!
以上就是关于【C++篇】数据之林:解读二叉搜索树的优雅结构与运算哲学的内容啦,各位大佬有什么问题欢迎在评论区指正,或者私信我也是可以的啦,您的支持是我创作的最大动力!❤️

相关文章:
【C++篇】数据之林:解读二叉搜索树的优雅结构与运算哲学
文章目录 二叉搜索树详解:基础与基本操作前言第一章:二叉搜索树的概念1.1 二叉搜索树的定义1.1.1 为什么使用二叉搜索树? 第二章:二叉搜索树的性能分析2.1 最佳与最差情况2.1.1 最佳情况2.1.2 最差情况 2.2 平衡树的优势 第三章&a…...

C#-类:声明类、声明类对象
一:类的声明 class 类名 {//特征——成员变量//行为——成员方法//保护特征——成员属性//构造函数和析构函数//索引器//运算符重载//静态成员 }类名:帕斯卡 同一个语句块中的不同类 不能重名 二:声明类对象 2.1 类的声明 ≠ 类对象的声…...

【AIGC】ChatGPT提示词Prompt高效编写技巧:逆向拆解OpenAI官方提示词
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯OpenAI官方提示词的介绍OpenAI官方提示词的结构与组成如何通过分析提示词找到其核心组件 💯OpenAI官方提示词分析案例一:制定教学计划案例二&…...

【linux】端口监听和终止进程
端口监听和终止进程 有时候,即使进程看起来已经关闭,它可能仍然占用着端口。你可以使用 netstat -tulpn | grep <端口号> 来查看哪个进程正在使用该端口,然后使用 kill -9 来强制关闭该进程。 [naienotebook-npu-b1bb152e-7655cb9d4…...

【网络安全】|kali中安装nessus
1、使用 df -h 命令查看磁盘使用情况,确保磁盘容量大于40G 简单粗暴办法:重装系统,装系统中注意磁盘空间相关的选项 //磁盘扩容:https://wiki.bafangwy.com/doc/670/ 2、安装 nessus 安装教程 https://blog.csdn.net/Cairo_A/a…...
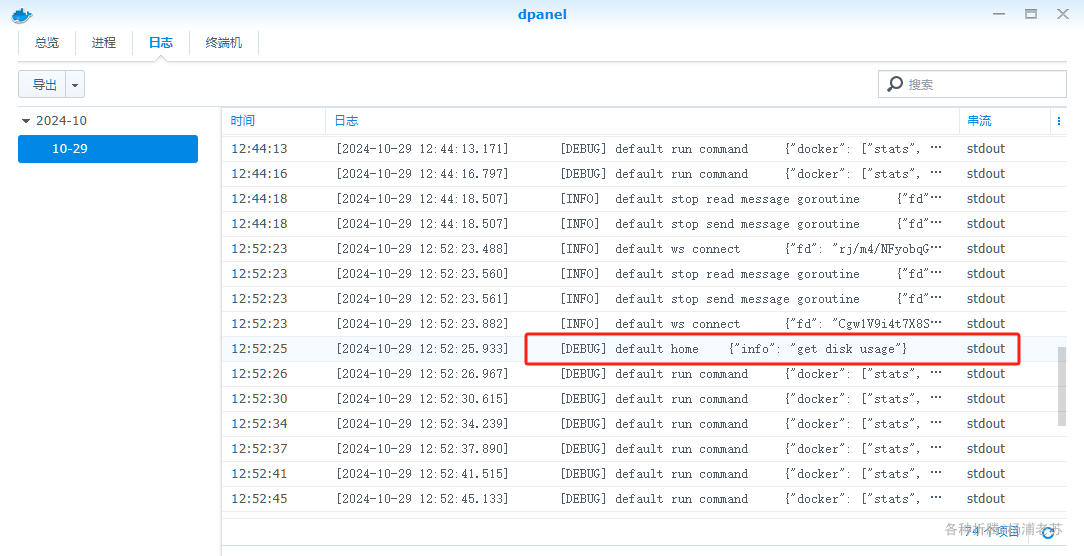
Docker可视化管理面板DPanel的安装
本文软件由网友 rui 推荐; 什么是 DPanel ? DPanel 是一款 Docker 可视化管理面板,旨在简化 Docker 容器、镜像和文件的管理。它提供了一系列功能,使用户能够更轻松地管理和部署 Docker 环境。 软件特点: 可视化管理&…...

【android12】【AHandler】【3.AHandler原理篇AHandler类方法全解】
AHandler系列 【android12】【AHandler】【1.AHandler异步无回复消息原理篇】-CSDN博客 【android12】【AHandler】【2.AHandler异步回复消息原理篇】-CSDN博客 其他系列 本人系列文章-CSDN博客 1.简介 前面两篇我们主要介绍了有回复和无回复的消息的使用方法和源码解析&a…...
使用Docker Compose构建多容器应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Docker Compose构建多容器应用 引言 Docker Compose 简介 安装 Docker Compose 创建基本配置 运行多容器应用 查看服务状态 …...

面试知识目录
面试知识目录 八股文 java基础 java反射java HashMap面向对象多线程虚拟机内存 SpringMybatisMySQLPostgresqlSQL优化Nosql...
Rust移动开发:Rust在Android端集成使用介绍
Andorid调用Rust 目前Rust在移动端上的应用,一般作为应用sdk的提供,供各端使用,目前飞书底层使用Rust编写通用组件。 该篇适合对Android、Rust了解,想看如何做整合,如果想要工程源码,可以评论或留言有解疑…...

vue3动态监听div高度案例
案例场景 场景描述:现在左边的线条长度需要根据右边盒子的高度进行动态变化 实践代码案例 HTML部分 <div v-for"(device, index) in devices" :key"index"><!-- 动态设置 .left-bar 的高度 --><div class"left-bar"…...

数据转换 | Matlab基于SP符号递归图(Symbolic recurrence plots)一维数据转二维图像方法
目录 基本介绍程序设计参考资料获取方式 基本介绍 Matlab基于SP符号递归图(Symbolic recurrence plots)一维数据转二维图像方法 符号递归图(Symbolic recurrence plots)是一种一维时间序列转图像的技术,可用于平稳和非平稳数据集;对噪声具有…...

分类算法——逻辑回归 详解
逻辑回归(Logistic Regression)是一种广泛使用的分类算法,特别适用于二分类问题。尽管名字中有“回归”二字,逻辑回归实际上是一种分类方法。下面将从底层原理、数学模型、优化方法以及源代码层面详细解析逻辑回归。 1. 基本原理 …...

只允许指定ip远程连接ssh
我们都会使用securtcrt或者xshell等软件进行远程登录,这样虽然会给我们带来很多便捷,但是同样会存在一定的风险。有很多人专门通过重复的扫描试图破解我们的linux服务器,从而获取免费的“肉鸡”。因此我们可以通过设置hosts.allow和hosts.den…...

Rust 力扣 - 2841. 几乎唯一子数组的最大和
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 我们遍历长度为k的窗口,用一个哈希表记录窗口内的所有元素(用来对窗口内元素去重),我们取哈希表中元素数量大于等于m的窗口总和的最大值 题解代码 use std::coll…...

TwinCL: A Twin Graph Contrastive Learning Model for Collaborative Filtering
TwinCL: A Twin Graph Contrastive Learning Model for Collaborative Filtering 摘要 在推荐和协同过滤领域,图对比学习(Graph Contrasive Learning,GCL)已经成为一种有影响的方法。然而,对比学习有效性的原因还没有…...
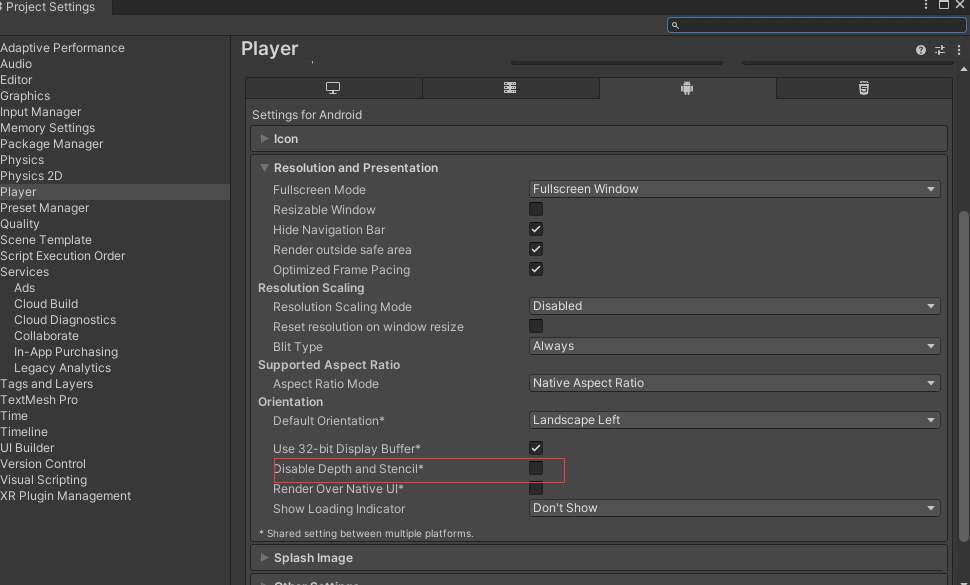
如何区分实例化网格中的每个实例
1)如何区分实例化网格中的每个实例 2)项目在模拟器上切换程序后有概率画面冻结 3)Unity工程导入团结引擎,GUID会变化,导致引用关系丢失 4)Mask在Android平台下渲染异常 这是第407篇UWA技术知识分享的推送&a…...

理解 WordPress | 第一篇:与内容管理系统的关系
初步了解 WordPress 在互联网世界里,WordPress 是一个家喻户晓的名字。它是一个开源的内容管理系统(Content Management System,简称 CMS),帮助用户轻松创建和管理网站。WordPress 诞生于 2003 年,最初是一…...

Python游戏脚本之实现飞机大战(附源码)
一.游戏设定 游戏界面如下图所示: 游戏的基本设定: 敌方共有大中小3款飞机,分为高中低三种速度; 子弹的射程并非全屏,而大概是屏幕长度的80%; 消灭小飞机需要1发子弹,中飞机需要8发,大飞机需要20发子弹; 每消灭一架小飞机得1000分,中飞机6000分,大飞…...

使用Spring Boot搭建简单的web服务
1 引言 1.1 Spring Boot简介 Spring Boot是由Pivotal团队提供的一套开源框架,旨在简化Spring应用的创建及部署。 一、核心设计思想 Spring Boot的核心设计思想是“约定优于配置”(Convention Over Configuration,简称COC)。这…...

【肾结石检测】基于matlab图像处理技术检测超声图像中的肾结石【含Matlab源码 15553期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

Grafana告警规则配置实战
Grafana告警规则配置实战 一、Grafana告警概述 Grafana提供强大的告警功能,可以基于Prometheus等数据源触发告警通知。 1.1 告警流程 ┌────────────────────────────────────────────────────────────…...

大模型对抗攻击与防御:保护 AI 系统安全
大模型对抗攻击与防御:保护 AI 系统安全 前言 随着大模型的广泛应用,对抗攻击成为一个重要的安全问题。攻击者可以通过精心设计的输入来欺骗模型,导致错误输出。 我在项目中研究过对抗攻击和防御方法,对这个领域有深入理解。今天分…...

3步突破格式限制:网易云音乐NCM文件转换终极指南
3步突破格式限制:网易云音乐NCM文件转换终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他设备播放而烦恼吗?ncmdump开源工具为你提供完美的NCM格式转换解…...

PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验
PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 观看外语影视时&…...

AI Security Agent:嵌入CI/CD的自动化安全协作者
1. 这不是又一个“AI安全”的概念炒作,而是DevSecOps流水线里正在静默替换人工的三个关键岗位你有没有在凌晨两点收到过这样的告警邮件:「CI/CD流水线第472次构建失败——SonarQube检测到Critical级SQL注入漏洞,阻断发布」?紧接着…...

应对野外挑战:鼎讯GO-50PRO在交通光缆施工中的核心优势
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯GO-50PRO光时域反射仪,作为一款集成了多种测试功能的专业设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无惧恶劣…...

【肾结石检测】图像处理技术检测超声图像中的肾结石【含Matlab源码 15553期】含报告
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

奇异线性系统与矩阵方程数值解法【附仿真】
✨ 长期致力于奇异线性方程组、鞍点问题、块二乘二线性方程组、矩阵方程、偏微分方程、最小范数最小二乘解、迭代方法、预处理、Schwarz-Christoffel映射、Sherman-Morrison-Woodbury公式研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕…...

英雄联盟智能助手:League Akari 的5大核心功能深度解析
英雄联盟智能助手:League Akari 的5大核心功能深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari 是一款基于英…...