【MySQL】深层理解索引及特性(重点)--下(12)
索引(重点)
- 1. 索引的作用
- 2. 索引操作
- 2.1 主键索引
- 2.1.1 主键索引的特点
- 2.1.2 创建主键索引
- 2.2 唯一键索引
- 2.2.1 唯一键索引的特点
- 2.2.2 唯一索引的创建
- 2.3 普通索引
- 2.3.1 普通索引的特点
- 2.3.2 普通索引的创建
- 2.4 全文索引
- 2.4.1 全文索引的作用
- 2.4.2 全文索引的创建
- 3. 查询索引
- 4. 删除索引
- 5. 索引创建原则
1. 索引的作用
索引:提高数据库的性能,索引是物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行正确的create index,查询速度就可能提高成百上千倍。但是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些操作,增加了大量的IO。所以它的价值,在于提高一个海量数据的检索速度。
常见索引类型分为:
- 主键索引(Primary Key)
主键索引是一种特殊的唯一索引,不允许有重复值,并且每个表只能有一个主键。主键通常用于唯一标识表中的每一行数据。在创建表的时候,如果指定了某列为主键,那么该列会自动创建一个主键索引。 - 唯一索引(Unique)
唯一索引确保了索引列中的所有值都是唯一的,但与主键不同的是,一个表可以有多个唯一索引。唯一索引允许有一个或多个NULL值存在,这取决于数据库系统的设计。 - 普通索引(Index)
普通索引是最基本的索引类型,它没有任何限制,可以包含重复的值。通过在查询条件中频繁使用的列上创建普通索引,可以显著提高查询效率。 - 全文索引(Fulltext)
全文索引主要用于全文本搜索,它可以对文本内容进行复杂的搜索操作,比如查找包含特定单词或短语的记录。全文索引特别适合于处理大量的文本数据,如新闻文章、博客帖子等。值得注意的是,不同的数据库管理系统支持的全文索引功能可能有所不同,例如MySQL中的InnoDB和`MyISAM存储引擎都支持全文索引,但实现方式和性能特点可能有所区别。
示例:
当我们在数据量少的表中查询数据不会发现主键查询和普通查询之间的差异。
创建一个海量表:
--构建一个8000000条记录的数据--构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解-- 产生随机字符串
delimiter $$create function rand_string(n INT)returns varchar(255)begin
declare chars_str varchar(100) default'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));set i = i + 1;end while;return return_str;end $$delimiter ;--产生随机数字
delimiter $$create function rand_num()returns int(5)begin
declare i int default 0;set i = floor(10+rand()*500);return i;end $$delimiter ;--创建存储过程,向雇员表添加海量数据
delimiter $$create procedure insert_emp(in start int(10),in max_num int(10))begindeclare i int default 0;
set autocommit = 0;
repeatset i = i + 1;insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());until i = max_numend repeat;commit;end $$delimiter ;-- 执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
注:已经绑定资源,可以自行下载。
进入到一个数据库,用soure命令导入数据:
我的数据包index_data.sql在 /root/MySQL_data/some 目录下
命令:
//进入到test数据库
use test// 导入数据
source /root/MySQL_data/some/index-data.sql
这是一个有8000000条记录的数据,需要等一会儿,我花费了7分钟。

此时的表还没有创建索引,进行查询:
命令:select * from EMP where empno = 188888

查询花费了4.69秒,这是在本机一个人来操作,在实际项目中,如果放在公网,假如同时有
1000个人并发查询,那很可能就死机。
怎么让查询变得快呢?
答:创建索引。
创建索引:
命令:alter table EMP add index(empno);

创建索引花费了26.7秒。
再次查询:
命令:select * from EMP where empno = 188888;

当执行查询的时候会明显的变快。
2. 索引操作
2.1 主键索引
2.1.1 主键索引的特点
- 唯一性:主键索引确保了索引列中的每一个值都是唯一的,不允许出现重复值。这是主键索引的核心特性,确保了每一行数据在表中都有一个唯一的标识符。
- 非空性:主键索引的列不允许有NULL值。这意味着在插入或更新数据时,必须为该列提供一个有效的、非空的值。
- 自动创建:当您在创建表时指定某个列为PRIMARY KEY时,数据库会自动为该列创建一个主键索引。如果表中没有显式定义主键,某些数据库系统可能会自动创建一个隐式的主键(例如,SQL Server中的IDENTITY列)。
- 快速查找:主键索引通常是一个B+树索引,这种结构允许数据库高效地进行查找、插入和删除操作。因此,使用主键进行查询通常比使用其他索引或无索引的查询要快得多。
- 聚簇索引:在某些数据库系统中,主键索引默认是聚簇索引(Clustered Index)。聚簇索引决定了数据在物理存储上的顺序,这意味着按主键顺序访问数据时性能最佳。一个表只能有一个聚簇索引,因为数据只能有一种物理排序方式。
- 约束作用:主键不仅是一个索引,还是一种约束。它确保了表中数据的完整性和一致性,防止了重复记录的插入。
- 外键引用:主键通常被用作其他表的外键(Foreign Key),以建立表之间的关系。外键必须引用一个唯一的列,通常是另一个表的主键。
2.1.2 创建主键索引
-
创建表时在字段后面指定
命令:create table t1( id int primary key, name varchar(10), age tinyint ); -
创建表时,在最后面指定某列为索引
命令:create table t2( id int, name varchar(10), age tinyint, primary key(id) ); -
创建表结束后,用
alter命令
命令:create table t3( id int, name varchar(10), age tinyint );alter table t3 add primary key(id);
2.2 唯一键索引
2.2.1 唯一键索引的特点
- 唯一性:
唯一键索引确保索引列中的每一个值都是唯一的,不允许出现重复值。这是唯一键索引的核心特性,确保了数据的唯一性和完整性。 - 允许多个NULL值:
与主键索引不同,唯一键索引允许列中有多个NULL值。这是因为NULL在数据库中被视为未知值,而不是具体的重复值。 - 提高查询性能:
唯一键索引可以显著提高查询性能,特别是在需要确保某一列或组合列的值唯一的情况下。通过创建唯一键索引,数据库可以在查询时更快地找到特定的记录。 - 约束作用:
唯一键索引不仅是一个索引,还是一种约束。它确保了表中数据的完整性和一致性,防止了重复记录的插入。 - 可以应用于多个列:
唯一键索引可以应用于单个列,也可以应用于多个列的组合。当应用于多个列的组合时,确保整个组合的值是唯一的,而不是单个列的值。
2.2.2 唯一索引的创建
-
创建表时在字段后面指定
命令:create table t1( id int unique, name varchar(10), age tinyint ); -
创建表时,在最后面设置某列为索引
命令:create table t2( id int, name varchar(10), age tinyint, unique(id) ); -
创建表结束后,用
alter命令
命令:create table t3( id int, name varchar(10), age tinyint );alter table t3 add unique(id);
2.3 普通索引
2.3.1 普通索引的特点
- 允许重复值:
普通索引允许索引列中的值重复。这意味着同一个值可以在索引列中出现多次。 - 提高查询性能:
普通索引可以显著提高查询性能,特别是对于经常用于查询条件的列。通过创建索引,数据库可以更快地定位到所需的记录。 - 不强制非空:
普通索引不要求列中的值必须是非空的。列中的值可以是NULL,并且可以有多个NULL值。 - 可以应用于多个列:
普通索引可以应用于单个列,也可以应用于多个列的组合。当应用于多个列的组合时,索引会根据组合列的值进行排序和查找。 - 不影响数据插入和更新:
创建普通索引不会像唯一索引那样对数据插入和更新施加额外的约束。这意味着在插入或更新数据时,即使索引列中有重复值,也不会引发错误。
总的来说:普通索引的主要目的是提高查询性能,特别是在频繁用于查询条件的列上。
2.3.2 普通索引的创建
-
创建表时,在最后面设置某列为索引
命令:create table t1( id int, name varchar(10), age tinyint, index(id) ); -
创建表后,用
alter命令
命令:create table t2( id int, name varchar(10), age tinyint );alter table t2 add index(id); -
创建表后,创建一个索引名为 idx_name 的索引,
create index
命令:create table t3( id int, name varchar(10), age tinyint );create index ind_t3_id on t3(id);
2.4 全文索引
2.4.1 全文索引的作用
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
早期版本的MySQL(5.6及之前)中,全文索引仅支持MyISAM存储引擎。
从MySQL 5.7开始,InnoDB存储引擎也支持全文索引。
全文索引的主要作用:
- 提高搜索性能
- 快速查找:全文索引使用专门的算法(如倒排索引)来加速文本搜索。通过索引,数据库可以快速定位包含特定单词或短语的记录,而不需要扫描整个表。
- 减少I/O操作:全文索引减少了磁盘I/O操作,提高了查询效率,特别是在处理大量文本数据时。
- 支持复杂的搜索操作
- 模糊匹配:全文索引可以支持模糊匹配,如部分单词匹配、前缀匹配等。
- 短语搜索:可以搜索包含特定短语的记录。
- 近义词搜索:通过配置,可以支持近义词搜索,提高搜索的准确性和相关性。
- 布尔搜索:支持使用布尔运算符(如AND、OR、NOT)进行复杂查询。
- 自然语言搜索
- 自然语言处理:全文索引可以支持自然语言搜索,即用户可以用自然语言形式的查询语句进行搜索,系统会返回最相关的记录。
- 权重计算:全文索引可以根据关键词在文档中的出现频率和位置等因素计算权重,返回最相关的记录。
2.4.2 全文索引的创建
创建全文索引:
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body))engine=MyISAM;
插入数据:
INSERT INTO articles (title,body) VALUES('MySQL Tutorial','DBMS stands for DataBase ...'),('How To Use MySQL Well','After you went through a ...'),('Optimizing MySQL','In this tutorial we will show ...'),('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),('MySQL vs. YourSQL','In the following database comparison ...'),('MySQL Security','When configured properly, MySQL ...');
查询有没有database数据
命令:select * from articles where body like '%database%';

显然,可以查询出结果。
但是,有没有使用全文索引呢?
可以explain 工具查看一下。
命令:
explain select * from articles where body like '%database%';

下面是各项的解释:
-
id: 查询块的标识号。在这个例子中只有一个查询块,所以id为1。
-
select_type: 表明查询的类型。这里"SIMPLE"表示这个查询只涉及一张表。
-
table: 被访问的表名。这里是"articles"表。
-
partitions: 如果表被分区,则此列为分区名称。在这里,由于表未分区,因此为NULL。
-
type: 访问类型,表明MySQL如何读取数据。这里的"ALL"意味着全表扫描,即MySQL将遍历整张表的所有行。
-
possible_keys: 可能使用的索引列表。在这个例子中,没有列出任何可能的索引,说明查询没有使用索引。
-
key: 实际使用的索引。同样,这里也是NULL,确认了没有使用索引的事实。
-
key_len: 索引中使用的字节数。既然没有使用索引,这一项也为NULL。
-
ref: 显示了哪个列或常量被用来查找行。这里为NULL,再次确认没有使用索引来优化查询。
-
rows: MySQL估计的要检查的行数。这里估计为6行。
-
filtered: 过滤掉不符合WHERE子句的行后剩余的百分比。这里为16.67%,意味着大约只有16.67%的数据会被实际返回给查询。
-
Extra: 包含其他额外的信息。这里的"Using where"表示MySQL正在使用WHERE子句过滤行。
总的来说,这个EXPLAIN输出表明了一个全表扫描的操作,没有使用任何索引,可能会导致较慢的查询速度,尤其是在大表上的情况。如果可能的话,考虑添加适当的索引以改善查询性能。
已经创建全文索引了,什么没有使用呢?怎么才能使用呢?
命令:
select * from articles
where match(body) against ('database');

为什么会报错呢?
答:当你在一个全文索引中指定了多个列时,查询时必须使用相同的列集。
命令:
select * from articles
where match(title,body) against('database');

用explain工具查询:

key对应的是title,可以看出,使用的是title索引,所以,改查询使用索引了。
为什么key只是对应title而不是对应title 和body 呢?
答:创建全文索引的时候使用的是 fulltext(title,body),所以该全文索引是多列,并且该全文索引的名字是第一个列名–title 。这里的key对应的是索引的名字
3. 查询索引
-
方法一:
语法:show keys from table_name;
上述命令显示的内容看着不方便可以使用:
show keys from table_name\G示例:
命令:show keys from articles \G
-
方法2:
语法:show index from table_name;
或:show index from table_name\G示例:
命令:show index from t1\G

-
方法3(查询到的信息表简略):
语法:desc table_name;
4. 删除索引
-
删除主键索引
语法:alter table table_name drop primary key;一个表中只用一个主键索引,像这种范式的删除方法其实还是针对它一个索引。
示例:
命令:alter table t1 drop primary;

-
其他索引的删除
语法:alter table table_name drop index column_name;

-
使用
drop index
语法:drop index index_name on table_name;该语法不能删除主键,主键是表中重要的组成部分,只能用
alter table t1 drop primary进行删除。示例:
删除表
t1的唯一索引unique
命令:drop index unique on t1

为什么会报错呢?
答:unique是索引的类型,不是索引的名字。删除索引的时候要先查询索引的类型。查询一下索引的名字:
show index from t1\G

删除
number列的索引:drop index number on t1;

5. 索引创建原则
索引创建原则 :
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引
- 不会出现在where子句中的字段不该创建索引
相关文章:
【MySQL】深层理解索引及特性(重点)--下(12)
索引(重点) 1. 索引的作用2. 索引操作2.1 主键索引2.1.1 主键索引的特点2.1.2 创建主键索引 2.2 唯一键索引2.2.1 唯一键索引的特点2.2.2 唯一索引的创建 2.3 普通索引2.3.1 普通索引的特点2.3.2 普通索引的创建 2.4 全文索引2.4.1 全文索引的作用2.4.2 …...

无人机声学侦测算法详解!
一、算法原理 无人机在飞行过程中,其电机工作、旋翼震动以及气流扰动等都会产生一定程度的噪声。这些噪声具有独特的声学特征,如频率范围、时域和频域特性等,可以用于无人机的检测与识别。声学侦测算法利用这些特征,通过一系列步…...

git 提交仓库
创建 git 仓库: mkdir pySoundImage cd pySoundImage git init touch README.md git add README.md git commit -m “first commit” git remote add origin https://gitee.com/hunan-co-changsha-branch/pytest.git git push -u origin master 已有仓库ÿ…...
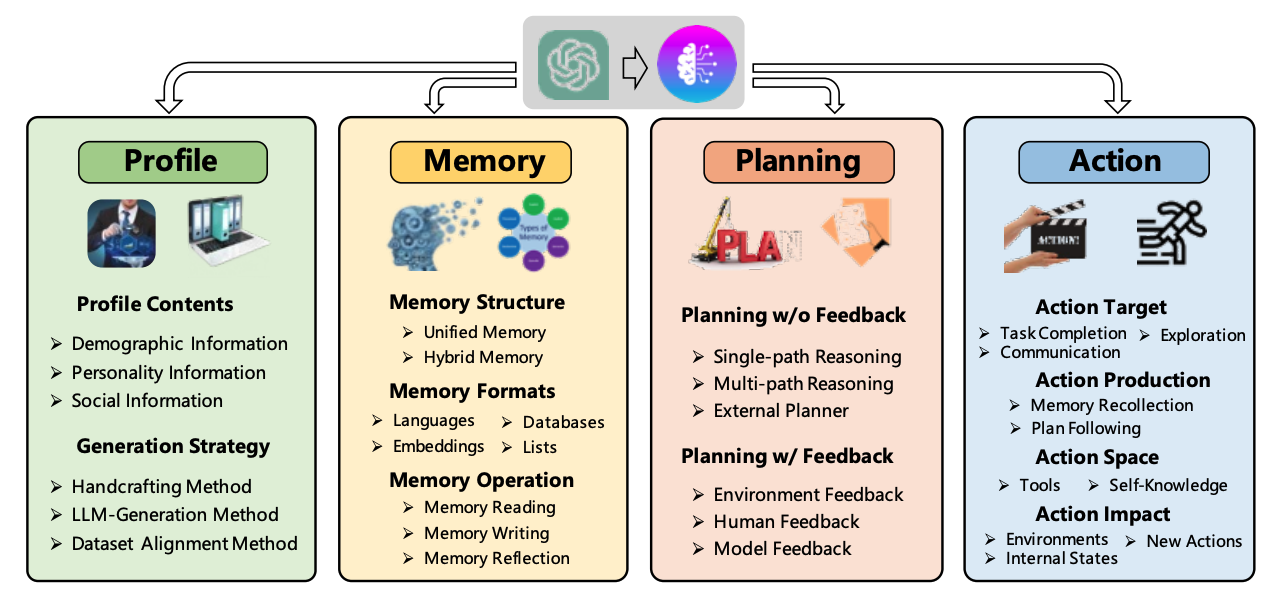
基于大语言模型(LLM)自主Agent 智能体综述
近年来,LLM(Large Language Model)取得了显著成功,并显示出了达到人类智能的巨大潜力。基于这种能力,使用LLM作为中央控制器来构建自助Agent,以获得类人决策能力。 Autonomous agents 又被称为智能体、Agent。指能够通过感知周围环境、进行规划以及执行动作来完成既定任务。…...

使用命令行管理 Windows 环境变量
1. 使用命令提示符 (CMD) 1.1. 设置环境变量 添加或修改临时环境变量(当前会话有效) set MY_VARvalue添加或修改用户环境变量 setx MY_VAR "value"添加或修改系统环境变量(需要管理员权限): setx /M MY…...
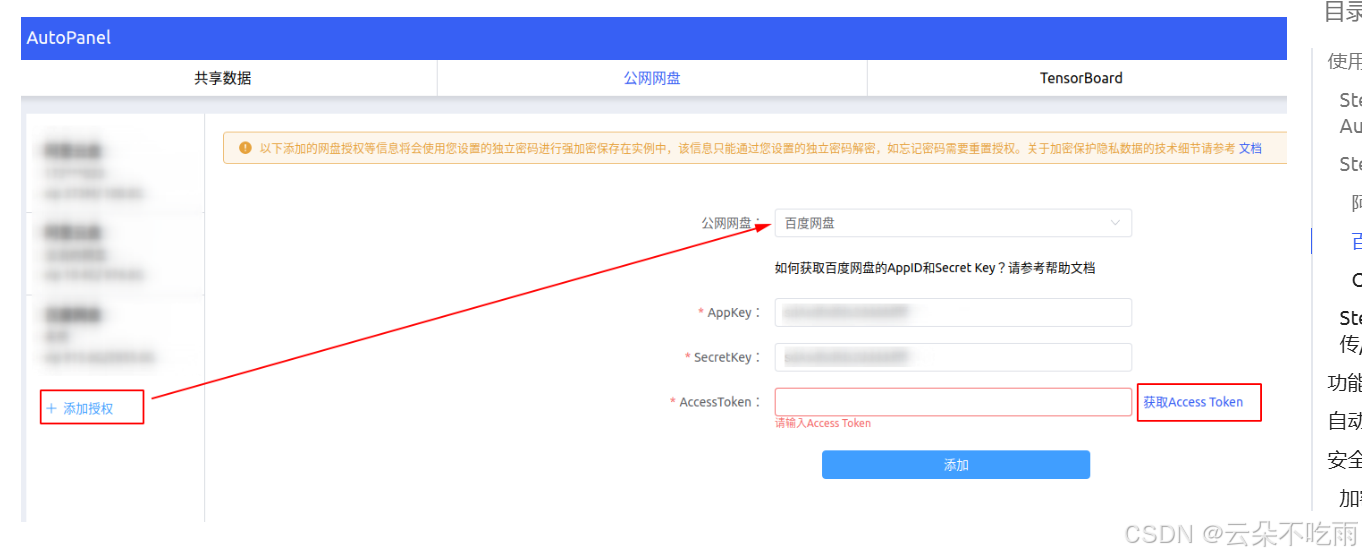
AUTODL配置百度网盘数据传输
AUTODL使用 1.配置百度网盘开放平台 2.接入并创建应用 3.创建应用 4.添加授权...
)
LeetCode46. 全排列(2024秋季每日一题 57)
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 示例 2: 输入:nums …...

SpringBoot新闻稿件管理系统:架构与实现
3系统分析 3.1可行性分析 通过对本新闻稿件管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本新闻稿件管理系统采用SSM框架,JAVA作为开发语…...

MinIO讲解和java应用案例示范
一、MinIO 基本概念 1.1 什么是 MinIO? MinIO 是一个高性能的对象存储服务器,专为云原生应用设计。它支持 Amazon S3 API,因此可以与现有的 S3 客户端和工具集成。MinIO 主要用于存储非结构化数据,如图片、视频、备份文件和日志…...

区块链技术与应用 【全国职业院校技能大赛国赛题目解析】第1套 区块链系统设计与运维部分
模块一:区块链产品方案设计及系统运维(35分) 选手完成本模块的任务后,将任务中设计结果、运行代码、运行结果等截图粘贴至客户端桌面【区块链技术应用赛\重命名为工位号\模块一提交结果.docx】中对应的任务序号下。 前述: 我们收到答案后,将针对比赛的答案和样题进行解…...

yaml文件编写
Kubernetes 支持YAML和JSON格式管理资源 JSON 格式:主要用于 api 接口之间消息的传递 YAML 格式;用于配置和管理,YAML是一种简洁的非标记性语言,内容格式人性化容易读懂 一,yaml语法格式 1.1 基本语法规则 使用空格进行缩进(不使用制表符࿰…...

TOEIC 词汇专题:娱乐休闲篇
TOEIC 词汇专题:娱乐休闲篇 在娱乐和休闲活动中,我们会接触到许多特定的词汇。这些词汇涉及到活动入场、观众互动、评论等各个方面,帮助你在相关场景中更加自如。 1. 入场和观众 一些常用词汇帮助你轻松应对观众与入场管理相关的场景&#…...
显示器)
驱动TFT-1.44寸屏(ST7735)显示器
目录 一、驱动芯片介绍 二、驱动方式 三、主函数main运行 四、完整代码下载 TFT1.44寸屏,搭配ST7735驱动芯片,是一种专为小型电子设备设计的彩色液晶显示解决方案。该屏幕采用薄膜晶体管(TFT)技术,能够实现高亮度、…...

鸿蒙HarmonyOS NEXT一多适配技术方案
鸿蒙一多是什么 HarmonyOS 系统面向多终端提供了“一次开发,多端部署”(后文中简称为“一多”)的能力,让开发者可以基于一种设计,高效构建多端可运行的应用。 一套代码工程,一次开发上架,多端按…...

golang 中map使用的一些坑
golang 中map使用的一些坑 1、使用map[string]interface{},类型断言[]int失败 接收下游的数据是用json转为map[string]any go a : "{\"a\":\"1\",\"b\":[123]}" var marshal map[string]any json.Unmarshal([]byte(a), &…...

cordova 离线打包Android -Linux
背景 已有 cordova 运行环境的docker镜像; 需要在离线环境下执行 cordova 从创建项目到构建安装包一系列命令,最终生成 apk 文件。 方案 先在有网环境(最好与离线环境的OS一致)走一遍 cordova 创建打包工程、添加插件、添加平…...

【python】OpenCV—findContours(4.3)
文章目录 1、功能描述2、代码实现3、完整代码4、结果展示5、涉及到的库函数5.1、cv2.Canny5.2 cv2.boxPoints 6、参考 1、功能描述 找出图片中的轮廓,拟合轮廓外接椭圆和外接矩阵 2、代码实现 导入必要的库,固定好随机种子 import cv2 as cv import …...

前端通过nginx部署一个本地服务的方法
前端通过nginx部署一个本地服务的方法: 1.下载ngnix nginx 下载完成后解压缩后运行nginx.exe文件 2.打包你的前端项目文件 yarn build 把生成的dist文件复制出来,替换到nginx的html文件下 3.配置conf目录的nginx.conf文件 主要配置server监听 ser…...

Linux:防火墙和selinux对服务的影响
1-1selinux 1-1 SELinux是对程序、文件等权限设置依据的一个内核模块。由于启动网络服务的也是程序,因此刚好也 是能够控制网络服务能否访问系统资源的一道关卡。 1-2 SELinux是通过MAC的方式来控制管理进程,它控制的主体是进程,而目标则是…...

从 vue 源码看问题 — vue 如何进行异步更新?
前言 在上一篇 如何理解 vue 响应式? 中,了解到响应式其实是通过 Observer 类中调用 defineReactive() 即 Object.defineProperty() 方法为每个目标对象的 key(key 对应的 value 为非数组的) 设置 getter 和 setter 实现拦截&…...

TestDisk与PhotoRec:数据恢复终极指南,三步找回丢失的重要文件
TestDisk与PhotoRec:数据恢复终极指南,三步找回丢失的重要文件 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 当硬盘分区神秘消失、重要文件被误删除、存储设备突然无法访问时&#…...

机器遗忘:从合规需求到技术实现,ROEL-TID框架如何平衡效率与精度
1. 项目概述:当机器学习模型需要“忘记”时在过去的十年里,我亲眼见证了机器学习如何从一个学术概念,演变为驱动商业决策、优化用户体验乃至重塑行业格局的核心引擎。从电商平台的“猜你喜欢”,到金融系统的欺诈交易拦截ÿ…...
)
保姆级教程:在Windows电脑上免梯子安装GPT4All最新版(附模型下载避坑指南)
Windows系统本地部署GPT4All全流程指南:从零基础到高效运行最近半年,开源大语言模型生态中最令人兴奋的变化之一,就是像GPT4All这样的工具让普通开发者也能在消费级硬件上运行强大的AI模型。作为一名长期关注AI本地化部署的技术顾问ÿ…...
)
【机密级】火山引擎内部培训材料流出:DeepSeek模型热更新+AB灰度发布架构图(含K8s Operator CRD定义与Prometheus告警阈值清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek火山引擎部署概览 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder)在火山引擎(VolcEngine)上的部署,依托其高性能GPU资源池、弹性伸缩能…...

拯救B站缓存视频:3分钟学会m4s转mp4的终极方案
拯救B站缓存视频:3分钟学会m4s转mp4的终极方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了珍贵的视频内容&a…...

终极指南:5分钟掌握Camera Shakify,为Blender相机添加真实抖动效果
终极指南:5分钟掌握Camera Shakify,为Blender相机添加真实抖动效果 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 在3D动画和视觉特效创作中,相机运动的真实性是区分业余作品与专业作…...
)
ChatGPT提示工程进阶实战(故事化表达失效的7大隐形陷阱)
更多请点击: https://kaifayun.com 第一章:故事化表达失效的底层认知重构 当工程师在技术文档中反复使用“用户点击按钮后,系统就像一位耐心的向导,带他走过三步旅程”这类修辞时,信息熵并未降低——反而因隐喻失准而…...
))
GESP6级C++考试语法知识(二十六、广度优先搜索(一、认识BFS))
第一课《消息传播城——认识广度优先搜索 BFS》🌟一、故事开始:国王的紧急消息1、很久很久以前,有一座叫:🏰「消息传播城」的大王国。2、有一天,怪兽突然来袭!国王必须立刻通知所有村庄…...

逃离塔科夫SPT-AKI存档编辑器:终极离线版角色管理解决方案
逃离塔科夫SPT-AKI存档编辑器:终极离线版角色管理解决方案 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirro…...

3分钟掌握QMC音频解密:qmc-decoder实战指南与算法深度解析
3分钟掌握QMC音频解密:qmc-decoder实战指南与算法深度解析 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 在数字音乐时代,你是否曾因QQ音乐加密格式…...