HyperLogLog 的原理 详解
HyperLogLog(简称 HLL)是一种用于近似计数(特别是基数估计,Cardinality Estimation)的算法,它能够在大数据场景中高效地估计集合中不同元素的数量,尤其适用于数据流的情况。HyperLogLog 相较于传统的计数方法,具备非常低的空间复杂度,同时又能提供准确的估计结果。它是 LogLog 算法的改进版。
一、背景与需求
在很多数据处理场景中,我们需要估算数据流或大规模集合中不同元素的数量。例如:
- 网站访问者的去重统计。
- 网络中独立IP的计数。
- 社交网络中的独立用户数量。
对于这些问题,直接计算集合的基数(即集合中独立元素的数量)是非常消耗内存和计算资源的,尤其在数据量巨大的情况下。因此,我们需要一种空间复杂度低且计算高效的算法来近似这个基数。
二、基本概念
HyperLogLog 的设计目标是使用较小的内存空间(通常是常数空间)来对大数据集中的不同元素的基数进行估计。
- 估计的精度:HyperLogLog 的估计值是一个近似值,但通常精度非常高。
- 空间复杂度:HyperLogLog 使用 O(log(log(n))) 的空间来存储结果,其中 n 是数据集中的元素数量。这个空间复杂度比传统的哈希集合(需要 O(n) 空间)要小得多。
三、工作原理
HyperLogLog 基于以下几个关键的思想:
-
哈希函数:HyperLogLog 使用哈希函数将数据项映射到一个范围内。哈希函数的设计要求其具有均匀性,即对于不同的输入,它能生成均匀分布的输出。
-
桶(Buckets):HyperLogLog 使用多个桶来存储中间结果。每个桶保存一个整数值,表示该桶所记录的哈希值的前导零的数量。
-
最大前导零计数:对于每个元素,通过哈希函数计算其哈希值,然后记录该哈希值二进制表示中的前导零的数量。假设哈希值的长度为 L 位,那么每个桶存储的是哈希值中的前导零数。
-
桶的更新规则:每次插入一个新元素时,计算该元素的哈希值,并找到该哈希值二进制表示中的前导零的个数。然后更新对应桶的值,即该桶记录的值为该桶当前值和前导零数的最大值。
-
基数估计:最终的基数估计值是通过对所有桶中记录的前导零数的值进行合成计算得到的。
1.1 哈希映射与前导零
首先,假设我们对一个元素应用一个哈希函数 H,得到的哈希值是一个 m 位的二进制字符串。我们关心的是该哈希值中从左至右的前导零的数量。例如,如果哈希值为 0001011001,则前导零的数量为 3。
1.2 桶(Registers)
HyperLogLog 使用多个桶,每个桶记录一个整数值,表示该桶对应哈希值的最大前导零数。假设我们有 b 个桶,那么我们将输入的哈希值映射到其中的一个桶。
通过哈希函数,我们将输入数据映射到一个桶。然后,对于每个数据点,计算其哈希值中前导零的数量,并更新该桶的值。具体而言,如果哈希值的前导零数大于该桶当前记录的前导零数,则更新该桶的值。
1.3 基数估算
HyperLogLog 使用一种名为 Harmonic Mean 的方法来估算基数。为了避免估算偏差,最终的基数估算结果是通过所有桶的统计信息计算的。
- 计算所有桶中值的平均数。
- 使用此平均数来推算出总的基数。
具体计算公式如下:
其中:
- E 是基数估算值。
- m 是桶的数量(桶的数量等于 HyperLogLog 中注册器的数量)。
- Z 是桶中记录的前导零数的平均值。
是一个常数,具体值与桶的数量 m 有关。
四、空间复杂度与精度
HyperLogLog 的空间复杂度主要由桶的数量 m 决定。每个桶通常存储一个整数值,这个整数值代表前导零的最大值,因此每个桶所需的存储空间是常数级别的。通常,为了保持足够的精度,我们会选择 m 为 的形式,其中 n 为桶数的对数。
精度:HyperLogLog 的误差率(标准差)与桶的数量 m 相关。桶数越多,精度越高,但需要更多的内存空间。一般来说,HyperLogLog 的误差范围是 ±2%。
五、源代码实现(Python 示例)
下面是一个简化的 HyperLogLog 的 Python 实现:
import hashlib
import mathclass HyperLogLog:def __init__(self, b):self.b = b # number of registers (buckets)self.m = 1 << b # number of registers (m = 2^b)self.data = [0] * self.m # initialize registers to 0def _hash(self, value):# Use hashlib to compute a hash of the input valuereturn int(hashlib.md5(str(value).encode('utf8')).hexdigest(), 16)def _rho(self, x):# Count the number of leading zeros in the binary representation of xreturn (x ^ (1 << x.bit_length() - 1)).bit_length() + 1def add(self, value):# Hash the value and compute the register indexhash_value = self._hash(value)register_index = hash_value & (self.m - 1) # Use the lower b bits for the index# Update the corresponding register with the max rho valueself.data[register_index] = max(self.data[register_index], self._rho(hash_value))def estimate(self):# Use the registers to estimate the cardinalityZ = 1.0 / sum([2.0 ** -reg for reg in self.data])E = (self.m ** 2) * Z# Apply bias correction for small cardinalitiesif E <= 2.5 * self.m:V = self.data.count(0)if V > 0:E = self.m * math.log(self.m / V)# Large cardinalities correctionif E > (1 / 30.0) * (1 << 32):E = -(1 << 32) * math.log(1 - E / (1 << 32))return E# Example usage:
hll = HyperLogLog(15) # Initialize with 2^15 registers
for i in range(10000):hll.add(i)
print("Estimated cardinality:", hll.estimate())
代码解释:
- 初始化:HyperLogLog 类接受一个参数 b,指定桶的数量为
。每个桶存储一个整数值,表示前导零的数量。
- 哈希函数:_hash 方法使用 MD5 哈希来处理输入值,并返回一个整数。
- 更新桶:add 方法接受一个元素,计算其哈希值,并更新相应桶的值。
- 估算基数:estimate 方法使用所有桶的值来估算数据集的基数,并考虑了小基数和大基数的修正。
六、总结
HyperLogLog 是一个基于哈希的概率算法,具有非常高的内存效率,尤其适用于需要快速估算基数的大数据场景。它通过哈希映射和前导零统计来估计基数,在保证低空间复杂度的同时,仍然提供较为准确的结果。尽管它是一个近似算法,但在很多实际应用中,估算误差足够小,能够满足需求。
相关文章:
HyperLogLog 的原理 详解
HyperLogLog(简称 HLL)是一种用于近似计数(特别是基数估计,Cardinality Estimation)的算法,它能够在大数据场景中高效地估计集合中不同元素的数量,尤其适用于数据流的情况。HyperLogLog 相较于传…...
OCR、语音识别与信息抽取:免费开源的AI平台在医疗领域的创新应用
一、系统概述 在医疗行业中,大量数据来自手写病历、医学影像报告、患者对话记录等非结构化数据源。这些数据常常存在信息碎片化和管理困难的问题,给医务人员的工作带来了不便。思通数科AI多模态能力平台正是为了解决这一行业痛点而生,产品集…...

苍穹外卖Bug集合
初始化后端项目运行出现以下问题 以上报错是因为maven和jdk版本不符合,需要将jdk改成17,mavne改成3.9.9...

小菜家教平台(一):基于SpringBoot+Vue打造一站式学习管理系统
前言 现在已经学习了很多与Java相关的知识,但是迟迟没有进行一个完整的实践(之前这个项目开发到一半,很多东西没学搁置了,同时原先的项目中也有很多的问题),所以现在准备从零开始做一个基于SpringBootVue的…...

PyCharm中pylint安装与使用
目录 1. 安装插件2. pycharm中使用该功能3. 命令行使用 1. 安装插件 然后重启 2. pycharm中使用该功能 3. 命令行使用 前提是先 pip install pylint pylint demo01.py下面红框内容的意思是,得到10分/ 满分10分,上次运行获得8.33分,经调整…...

一篇文章了解TCP/IP模型
TCP/IP模型,即传输控制协议/互联网协议模型(Transmission Control Protocol/Internet Protocol Model),是互联网及许多其他网络上使用的分层通信模型。以下是对TCP/IP模型的详细介绍: 一、定义与组成TCP/IP模型是一个四…...

python文字识别---基于百度api
百度智能云账户注册:https://console.bce.baidu.com/ai/#/ai/ocr/app/list 获取appid、api_key、secret_key from aip import AipOcr import osconfig {appid: 116122887,api_key: DAQnt...,secret_key: 5S0Kpyh.... }# 初始化 AipOcr 客户端 client AipOcr(c…...

linux下linuxdeployqt打包过程
一 、linuxdeployqt下载安装 1.下载linuxdeployqt依赖拷贝工具 下载地址:https://github.com/probonopd/linuxdeployqt/releases 2.为了方便使用,将名字改短一点:mv linuxdeployqt-6-x86_64.AppImage linuxdeployqt3.修改下载的文件的可执行…...

【拥抱AI】AI大模型在软件开发中的应用如何保证数据安全?
随着AI大模型在软件开发中的广泛应用,数据安全问题变得尤为重要。确保数据的安全不仅关乎企业的声誉和合规性,还直接影响到用户对产品的信任。以下是几种常见的方法和最佳实践,以确保在使用AI大模型时的数据安全。 1. 数据加密 传输加密&a…...

python爬取旅游攻略(1)
参考网址: https://blog.csdn.net/m0_61981943/article/details/131262987 导入相关库,用get请求方式请求网页方式: import requests import parsel import csv import time import random url fhttps://travel.qunar.com/travelbook/list.…...
)
C++网络编程之IO多路复用(一)
概述 在C网络编程中,处理并发连接是一个非常关键的核心问题。为了有效管理来自多个客户端的请求,服务器需要能够同时监听多个套接字上的事件,这通常通过IO多路复用来实现。 IO多路复用是一种工作机制,它可以让程序监视多个文件描述…...
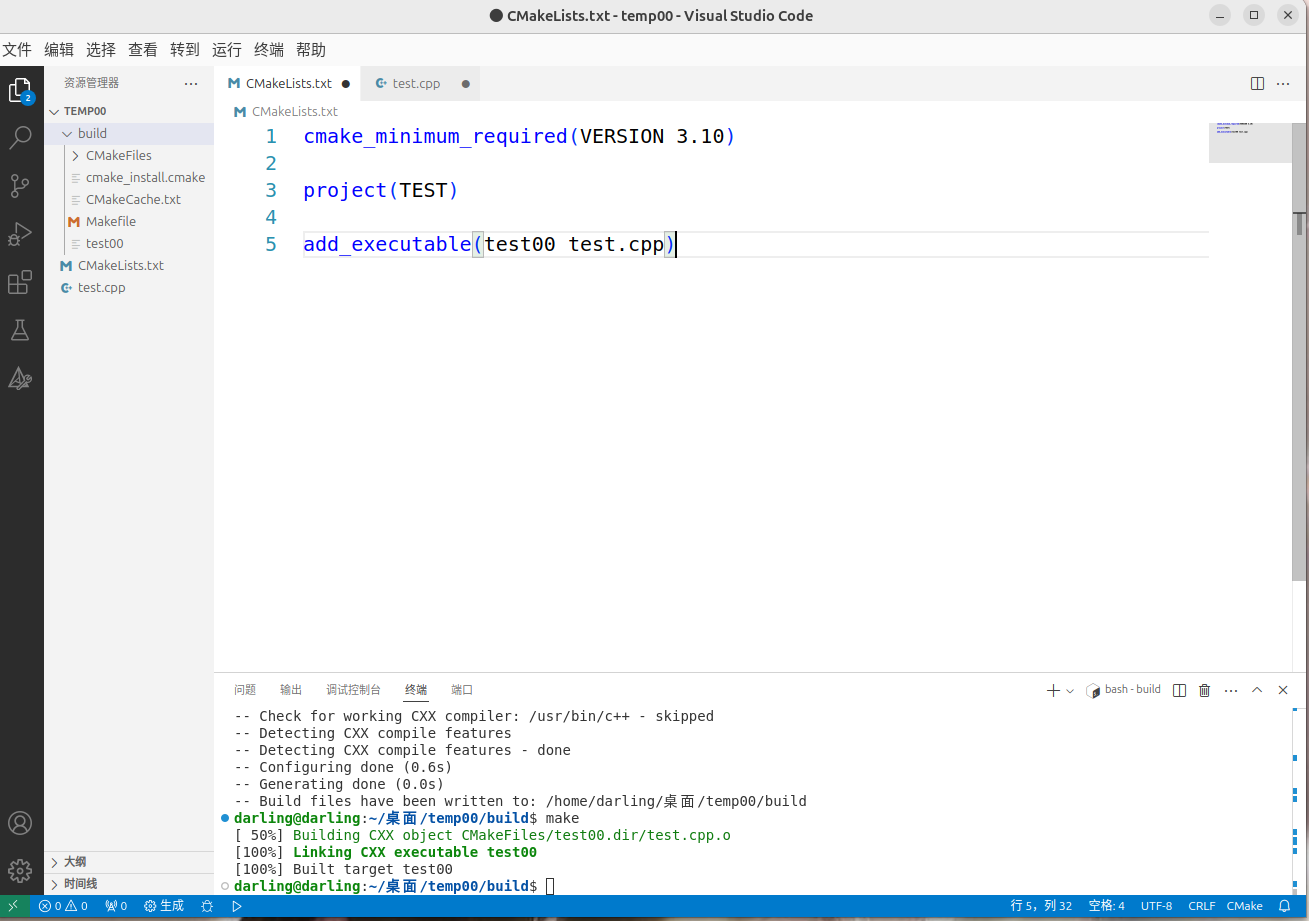
vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么区别
vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么区别 windows默认使用的是最新的visual studio,而linux默认就是cmake 文章目录 vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么…...

Antd Vue中使用table组件把相同名称的合并单元格---只需两步
当前效果: 想要的效果: 第一步:在获取table数据的地方处理数据 function getTableList () {getDataList().then(res > {if (res.code 200 && res.data) {const list res.datalet columnIndex 0 //第一条数据let rowSpan …...

cmake中execute_process详解
execute_process 是 CMake 中一个非常强大的命令,用于在构建过程中执行外部程序或脚本。它提供了丰富的选项来控制执行过程,并可以捕获输出、错误和返回码。以下是 execute_process 的详细解析: 基本语法 execute_process(COMMAND <comm…...

搜维尔科技:使用Sensglove Nova2触觉反馈手套遥操作机器人操作
使用Sensglove Nova2触觉反馈手套遥操作机器人操作 搜维尔科技:使用Sensglove Nova2触觉反馈手套遥操作机器人操作...

企业HR如何选对一款智能招聘软件?
随着招聘市场的竞争加剧和求职者期望的提升,传统的招聘方式已经难以满足企业的需求。智能招聘软件应运而生,成为企业HR提升招聘效率、优化招聘流程、增强雇主品牌吸引力的关键工具。然而,市场上的智能招聘软件琳琅满目,如何选择一…...

任务中心全新升级,新增分享接口文档功能,MeterSphere开源持续测试工具v3.4版本发布
2024年11月5日,MeterSphere开源持续测试工具正式发布v3.4版本。 在这一版本中,系统设置方面,任务中心支持实时查看系统即时任务与系统后台任务;接口测试方面,新增接口文档分享功能、接口场景导入导出功能,…...

书生大模型第三关Git 基础知识
关卡编号:L0G3000 任务一 破冰行动 fork仓库,注意这里不要勾选Copy branch Only!!!,因为后面课程中会使用到class分支: 克隆仓库: 移动分支: 创建自己的分支: 创建id.md文档,…...

WordPress 中最佳的维护服务:入门级用户指南
如果你是WordPress网站管理员,一定知道网站维护既耗时又复杂。然而,保持网站的正常运行和安全却至关重要。为了让你轻松应对这个挑战,我们总结了一些适合新手和小型网站的维护服务。本文将介绍两款适合初学者的维护服务:FixMySite…...

前端使用Luckysheet把返回的base64或二进制文件流格式,实现xlsx文件预览
xlsx文件预览 Luckysheet是什么?代码实现xlsx文件预览引入luckysheet的相关依赖安装luckyexcel指定一个表格容器实现逻辑 Luckysheet是什么? Luckysheet ,一款纯前端类似excel的在线表格,功能强大、配置简单、完全开源。 Luckys…...

【Linux驱动开发】第12天:Linux设备树核心:树形结构+节点+属性 完整全解
目录 设备树树形结构概述节点(Node)全解:命名规范标准节点常用设备节点属性(Property)全解:类型核心属性总线专用属性标签与节点引用:设备树复用的核心常见错误与注意事项总结:驱动…...

pycryptodome导入失败的四大底层原因与诊断方案
1. 这不是pycryptodome的问题,而是你没看清它真正依赖的底层逻辑“ImportError: No module named Crypto”、“AttributeError: module Crypto.Cipher has no attribute AES”、“ModuleNotFoundError: No module named Cryptography_cffi...”——这些报错我过去三…...

92、【Agent】【OpenCode】edit 工具提示词
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】grep 工…...
)
别再死记硬背了!用Python+MATLAB/Simulink,5步搞定自动控制原理的时域分析(附代码)
从理论到代码:用PythonMATLAB玩转自动控制时域分析 为什么我们需要用代码实现控制理论? 翻开任何一本自动控制原理教材,满眼都是微分方程、传递函数和响应曲线。传统学习方法强调手工计算和记忆公式,但现代工程师更需要的是将抽象…...

当Windows 11变得臃肿时:如何用开源工具Win11Debloat重获系统控制权
当Windows 11变得臃肿时:如何用开源工具Win11Debloat重获系统控制权 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to dec…...

RK3399嵌入式3D人脸识别系统:双目视觉与轻量化算法实战
1. 项目概述与核心价值最近在做一个挺有意思的项目,客户那边有个需求,要在他们现有的RK3399工控板上,集成一套完整的3D人脸识别系统。这活儿听起来挺酷,但真干起来,里头门道不少。RK3399这块板子大家应该不陌生&#x…...

龙芯3A5000工业主板实战:从硬件部署到软件生态的国产化替代指南
1. 项目概述:一颗“中国芯”的工业级落地 最近,圈子里关于国产自主平台的消息又热闹了起来。这次的主角,是集特智能新推出的一款工业主板,核心搭载了龙芯3A5000处理器和7A2000桥片。对于长期深耕工业控制、边缘计算、网络安全这些…...

汽车12V电源保护:TVS二极管选型、应用与EMC测试实战
1. 项目概述:为什么汽车12V电源线需要“特种保镖”?在汽车电子系统里,那根看似普通的12V DC电源线,其实是个“压力山大”的角色。它不仅要给车机、仪表、传感器、ECU(电子控制单元)这些“大脑”和“神经”稳…...

文档即代码?Claude API文档自动化生成全链路拆解,5步接入CI/CD流水线
更多请点击: https://codechina.net 第一章:文档即代码:Claude API文档自动化生成的核心范式 将API文档视为可版本化、可测试、可部署的一等公民,是现代AI服务工程化的关键跃迁。Claude API的文档不再由人工撰写后静态发布&#…...

西门子S7-1200 PLC编程避坑指南:从振荡电路到浮点数计算,新手最易犯的5个错误
西门子S7-1200 PLC编程实战避坑手册:从逻辑陷阱到数据精度的深度解析 在工业自动化领域,PLC编程就像是在钢丝上跳舞——一步错可能导致整个产线瘫痪。作为西门子S7-1200的资深用户,我见过太多初学者在相同的地方跌倒。这篇文章不会给你教科书…...