python爬取旅游攻略(1)
参考网址:
https://blog.csdn.net/m0_61981943/article/details/131262987
- 导入相关库,用
get请求方式请求网页方式:
import requests
import parsel
import csv
import time
import random
url = f'https://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat'
response = requests.get(url)

返回的 HTML 内容
html_data = response.text
print(html_data)

Selector类允许你创建一个对象,该对象可以用来从给定的 HTML 或 XML 文本中选择特定的元素。
selector = parsel.Selector(html_data)
print(selector)

selector.css(‘.li h2 a::attr(href)’):
- selector是前面创建的parsel.Selector对象,它代表网页的 HTML 内容。
- .css()是parsel.Selector对象的一个方法,用于使用 CSS 选择器语法来选择网页中的元素。
- '.li h2 a’是 CSS 选择器表达式,它的含义是选择所有具有类名li的元素下的< h2 >标签内的< a >标签。这个选择器的目的是找到网页中特定位置的链接元素。
- '::attr(href)'是一个 CSS 伪元素选择器,用于选择< a >标签的href属性。它的作用是提取这些链接元素的href属性值,也就是链接地址。
- .getall():
这是对前面选择结果的一个操作,用于获取所有满足选择条件的元素的href属性值,并以列表的形式返回。
所以,整行代码的作用是从网页的 HTML 内容中选择具有特定结构的链接元素,并提取它们的链接地址,存储在一个列表url_list中.
url_list = selector.css('.b_strategy_list li h2 a::attr(href)').getall()

保存到.csv文件里面
csv_qne = open('旅游攻略.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.writer(csv_qne)
csv_writer.writerow(['地点', '标题', '出发时间', '天数', '人均消费', '人物', '玩法', '浏览量','点赞量' ,'作者'])
detail_id = detail_url.replace('/youji/', '')#字符串中移除/youji/部分
url_1 = 'https://travel.qunar.com/travelbook/note/' + detail_id#构建一个完整的 URL,并将其赋值给url_1。这个完整的 URL 很可能是指向旅游攻略详情页面的地址。
for detail_url in url_list:# 字符串的 替换方法detail_id = detail_url.replace('/youji/', '')#字符串中移除/youji/部分url_1 = 'https://travel.qunar.com/travelbook/note/' + detail_id#构建一个完整的 URL,并将其赋值给url_1。这个完整的 URL 很可能是指向旅游攻略详情页面的地址。print(url_1)response_1 = requests.get(url_1).textselector_1 = parsel.Selector(response_1)title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get().replace('旅游攻略', '')comment = selector_1.css('.title.white::text').get()date = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()days = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()money = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howmuch > p > span.data::text').get()character = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()play_list = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.how > p > span.data span::text').getall()play = ' '.join(play_list)count = selector_1.css('.view_count::text').get()print(title, comment, date, days, money, character, play, count)
查找方法:
右键检查,查看css字段

title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get().replace('旅游攻略', '')


右键复制js路径
同理爬取其他数据
一个简单的例子
import requests
import parsel
import csv
import time
import randomurl = f'https://travel.qunar.com/travelbook/list.htm?page=1&order=hot_heat'
response = requests.get(url)
#print(response)
html_data = response.text
#print(html_data)
selector = parsel.Selector(html_data)
#print(selector)
url_list = selector.css('.b_strategy_list li h2 a::attr(href)').getall()
#csv_writer.writerow(['地点', '作者','地点', '短评', '出发时间', '天数', '人均消费', '人物', '玩法', '浏览量', '点赞'])
#print(url_list)
for detail_url in url_list:detail_id = detail_url.replace('/youji/', '')#字符串中移除/youji/部分url_1 = 'https://travel.qunar.com/travelbook/note/' + detail_id#构建一个完整的 URL,并将其赋值给url_1。这个完整的 URL 很可能是指向旅游攻略详情页面的地址。print(url_1)response_1 = requests.get(url_1).textselector_1 = parsel.Selector(response_1)comment = selector_1.css('.title.white::text').get()# title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get().replace('旅游攻略', '')date= selector_1.css("#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text").get()days=selector_1.css("#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text").get()author = selector_1.css("body > div.qn_mainbox > div > div.left_bar > ul > li:nth-child(1) > p.user_info > span.intro > span.user_name > a::text").get()dianzan = selector_1.css("body > div.qn_mainbox > div > div.left_bar > ul > li:nth-child(1) > p.user_info > span.nums > span.icon_love > span::text").get()print( comment, date, days, author, dianzan)
如果数据不够:
import requests
import parsel
import csv
import time
import random# 基础URL
base_url = 'https://travel.qunar.com'
page_number = 1
data_count = 0# 打开CSV文件,准备写入数据
with open('去哪儿.csv', mode='a', encoding='utf-8', newline='') as csv_qne:csv_writer = csv.writer(csv_qne)csv_writer.writerow(['地点', '短评', '出发时间', '天数', '人均消费', '人物', '玩法', '浏览量'])while data_count < 100:url = f'https://travel.qunar.com/travelbook/list.htm?page={page_number}&order=hot_heat'# 发送请求获取页面内容response = requests.get(url)html_data = response.textselector = parsel.Selector(html_data)# 获取详情页URL列表url_list = selector.css('.b_strategy_list li h2 a::attr(href)').getall()for detail_url in url_list:# 获取详情页IDdetail_id = detail_url.replace('/youji/', '')url_1 = base_url + '/travelbook/note/' + detail_idprint(url_1)# 获取详情页内容response_1 = requests.get(url_1).textselector_1 = parsel.Selector(response_1)# 获取标题,添加错误处理title_element = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get()if title_element:title = title_element.replace('旅游攻略', '')else:title = None# 获取短评,添加错误处理comment = selector_1.css('.title.white::text').get()# 获取出发时间,添加错误处理date = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()# 获取天数,添加错误处理days = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()# 获取人均消费,添加错误处理money = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howmuch > p > span.data::text').get()# 获取人物,添加错误处理character = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()# 获取玩法,添加错误处理play_list = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.how > p > span.data span::text').getall()play = ' '.join(play_list) if play_list else None# 获取浏览量,添加错误处理count = selector_1.css('.view_count::text').get()print(title, comment, date, days, money, character, play, count)# 写入数据,如果有值为None则写入空字符串if data_count == 0:row_data = [title or 'Sample Location', comment or '', date or '', days or '', money or '', character or '', play or '', count or '']else:row_data = [title or '', comment or '', date or '', days or '', money or '', character or '', play or '', count or '']csv_writer.writerow(row_data)data_count += 1if data_count >= 100:break# 获取下一页页码信息page_links = selector.css("body > div.qn_mainbox > div > div.left_bar > div.b_paging a::attr(href)").getall()page_link_numbers = [page_link.split('=')[-1] for page_link in page_links]page_numbers = [int(number) for number in page_link_numbers if number.isdigit()]if page_numbers:max_page = max(page_numbers)if page_number < max_page:page_number += 1else:# 如果当前页是最后一页,重新从第一页开始继续获取数据,直到达到100条page_number = 1else:print("未找到页码信息,可能出现问题,继续尝试下一页")page_number += 1time.sleep(random.randint(1, 3))相关文章:

python爬取旅游攻略(1)
参考网址: https://blog.csdn.net/m0_61981943/article/details/131262987 导入相关库,用get请求方式请求网页方式: import requests import parsel import csv import time import random url fhttps://travel.qunar.com/travelbook/list.…...
)
C++网络编程之IO多路复用(一)
概述 在C网络编程中,处理并发连接是一个非常关键的核心问题。为了有效管理来自多个客户端的请求,服务器需要能够同时监听多个套接字上的事件,这通常通过IO多路复用来实现。 IO多路复用是一种工作机制,它可以让程序监视多个文件描述…...
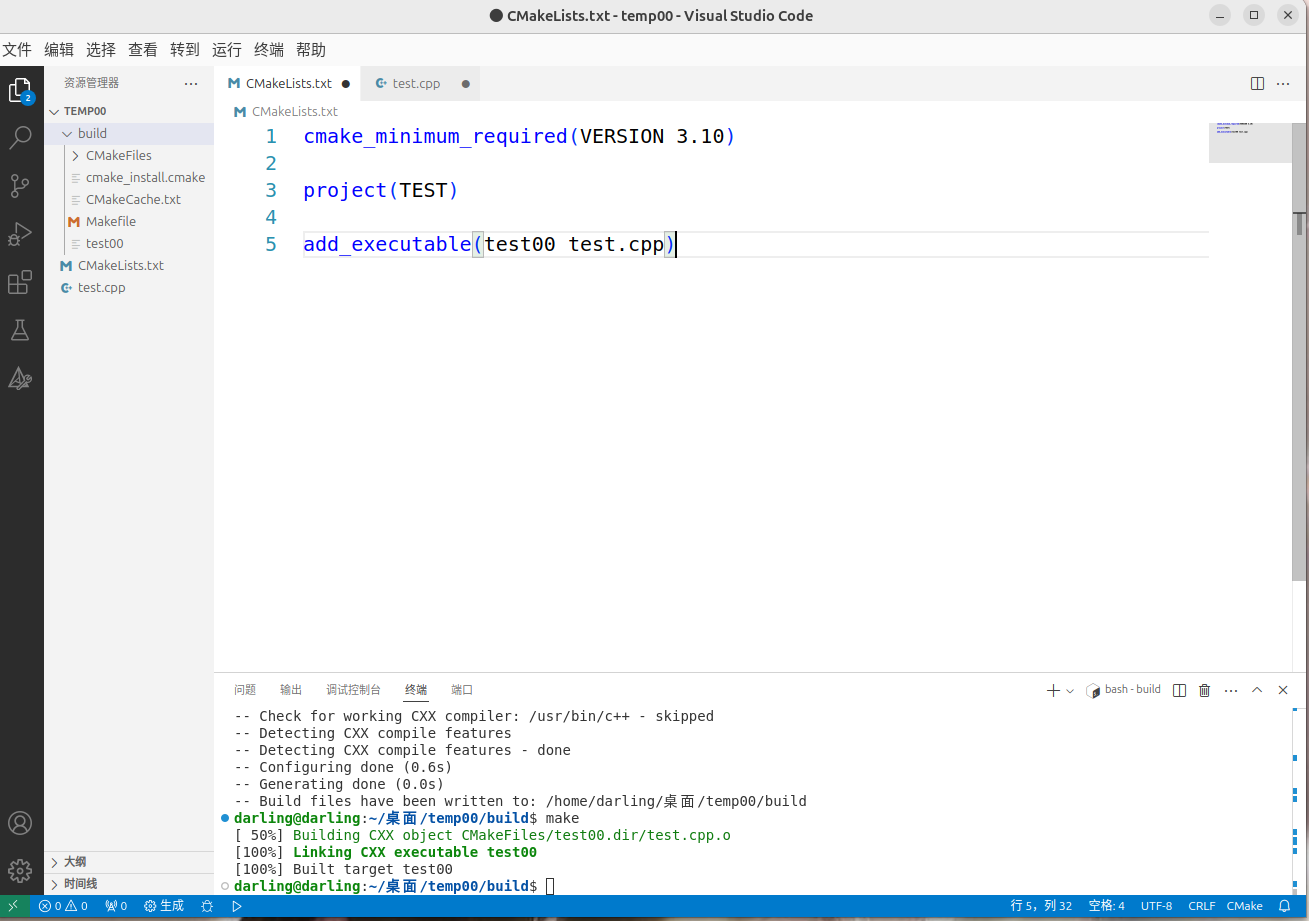
vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么区别
vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么区别 windows默认使用的是最新的visual studio,而linux默认就是cmake 文章目录 vscode在windows和linux如何使用cmake构建项目并make生成可执行文件,两者有什么…...

Antd Vue中使用table组件把相同名称的合并单元格---只需两步
当前效果: 想要的效果: 第一步:在获取table数据的地方处理数据 function getTableList () {getDataList().then(res > {if (res.code 200 && res.data) {const list res.datalet columnIndex 0 //第一条数据let rowSpan …...

cmake中execute_process详解
execute_process 是 CMake 中一个非常强大的命令,用于在构建过程中执行外部程序或脚本。它提供了丰富的选项来控制执行过程,并可以捕获输出、错误和返回码。以下是 execute_process 的详细解析: 基本语法 execute_process(COMMAND <comm…...

搜维尔科技:使用Sensglove Nova2触觉反馈手套遥操作机器人操作
使用Sensglove Nova2触觉反馈手套遥操作机器人操作 搜维尔科技:使用Sensglove Nova2触觉反馈手套遥操作机器人操作...

企业HR如何选对一款智能招聘软件?
随着招聘市场的竞争加剧和求职者期望的提升,传统的招聘方式已经难以满足企业的需求。智能招聘软件应运而生,成为企业HR提升招聘效率、优化招聘流程、增强雇主品牌吸引力的关键工具。然而,市场上的智能招聘软件琳琅满目,如何选择一…...

任务中心全新升级,新增分享接口文档功能,MeterSphere开源持续测试工具v3.4版本发布
2024年11月5日,MeterSphere开源持续测试工具正式发布v3.4版本。 在这一版本中,系统设置方面,任务中心支持实时查看系统即时任务与系统后台任务;接口测试方面,新增接口文档分享功能、接口场景导入导出功能,…...

书生大模型第三关Git 基础知识
关卡编号:L0G3000 任务一 破冰行动 fork仓库,注意这里不要勾选Copy branch Only!!!,因为后面课程中会使用到class分支: 克隆仓库: 移动分支: 创建自己的分支: 创建id.md文档,…...

WordPress 中最佳的维护服务:入门级用户指南
如果你是WordPress网站管理员,一定知道网站维护既耗时又复杂。然而,保持网站的正常运行和安全却至关重要。为了让你轻松应对这个挑战,我们总结了一些适合新手和小型网站的维护服务。本文将介绍两款适合初学者的维护服务:FixMySite…...

前端使用Luckysheet把返回的base64或二进制文件流格式,实现xlsx文件预览
xlsx文件预览 Luckysheet是什么?代码实现xlsx文件预览引入luckysheet的相关依赖安装luckyexcel指定一个表格容器实现逻辑 Luckysheet是什么? Luckysheet ,一款纯前端类似excel的在线表格,功能强大、配置简单、完全开源。 Luckys…...

腾讯混元宣布大语言模型和3D模型正式开源
腾讯混元大模型正在加快开源步伐。 11月5日,腾讯混元宣布最新的MoE模型“混元Large“以及混元3D生成大模型“ Hunyuan3D-1.0”正式开源,支持企业及开发者精调、部署等不同场景的使用需求,可在HuggingFace、Github等技术社区直接下载ÿ…...

提示工程指南 笔记
诸神缄默不语-个人CSDN博文目录 课程网站:提示工程指南 | Prompt Engineering Guide 原版是英文:https://www.promptingguide.ai/ 特别基础的内容我就不写了,只写一些值得记录的内容。 文章目录 1. 常用术语(LLM特供版ÿ…...

WordPress站点网站名称、logo设置
WordPress网站名称设置 后台打开查看站点自定义设置 点击网站名称修改 上传logo和站点图标...

本地缓存与 Redis:为什么我们仍然需要本地缓存?
文章目录 本地缓存与 Redis:为何仍需本地缓存?为什么需要本地缓存?多级缓存架构多级缓存的实现 本地缓存的实现方式使用 cachetools 实现 LRUCache使用 diskcache 实现持久化缓存 缓存装饰器实现进一步优化:缓存失效与更新 小结 好…...

要在微信小程序中让一个 `view` 元素内部的文字水平垂直居中,可以使用 Flexbox 布局
文章目录 主要特点:基本用法:常用属性: 要在微信小程序中让一个 view 元素内部的文字水平垂直居中,可以使用 Flexbox 布局。以下是如何设置样式的示例: .scan-button {display: flex; /* 启用 Flexbox 布局 */justify…...

图像超分辨率、DPSRGAN
图像超分辨率(Image Super-Resolution, ISR)是一种通过增加图像的分辨率来提高其细节和清晰度的技术。这项技术在多个领域都有广泛的应用,比如视频监控、医学诊断、遥感应用等。根据搜索结果,图像超分辨率算法主要可以分为以下几类…...

124.WEB渗透测试-信息收集-ARL(15)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:123.WEB渗透测试-信息收集-ARL(14) 点击fofa任务下发(…...

@Async注解提升Spring Boot项目中API接口并发能力
文章目录 同步调用异步调用1: 启用异步支持2: 修改 Task 类异步回调基本概念使用 Future<String>使用 CompletableFuture<String>Future<String> 和 CompletableFuture<String>区别1. 基本概念2. 主要区别同步调用 同步调用是最直接的调用方式,调用方…...

SpringBoot集成Flink-CDC
Flink CDC CDC相关介绍 CDC是什么? CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到MQ以…...

2024三星固件下载完整指南:Bifrost跨平台工具终极解决方案
2024三星固件下载完整指南:Bifrost跨平台工具终极解决方案 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备固件下载而烦恼吗ÿ…...

DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开
更多请点击: https://kaifayun.com 第一章:DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开 在DeepSeek内部技术文档搜索系统升级中,我们对原有RAG Pipeline进行了深度重构,核心…...

AI能力认知地图:从工具体验到工程落地的系统化拆解
1. 项目概述:这不是一份“AI工具清单”,而是一份可复用的AI能力认知地图你点开这篇文章,大概率不是为了收藏十个网站链接——而是想搞清楚:当AI能力已经像水电一样开始渗入日常工具链时,一个真实从业者该如何判断哪些能…...
(程序+数据库+报告+部署教程+答辩指导))
java+vue+SpringBootjava+vue+SpringBoot中小型制造企业质量管理系统(程序+数据库+报告+部署教程+答辩指导)(程序+数据库+报告+部署教程+答辩指导)
源代码数据库LW文档(1万字以上)开题报告答辩稿ppt部署教程代码讲解代码时间修改工具 技术实现 开发语言:后端:Java 前端:vue框架:springboot数据库:mysql 开发工具 JDK版本:JDK1.8 数…...

Python之streamjam包语法、参数和实际应用案例
Python StreamJam 包完整使用指南 一、StreamJam 包核心概述 StreamJam 是 Python 中一款轻量级、高性能的流式数据处理工具包,专为实时数据流、增量数据处理、管道式数据转换、异步/同步流处理设计,核心定位是替代复杂的大数据框架(如Spark、…...
)
AI大神吴恩达力荐,轻松入门大语言模型实战(附中文PDF+代码)
这本书由AI科普大神Jay Alammar与BERTopic算法作者Maarten Grootendorst联合撰写,是O’Reilly出版的LLM入门标杆指南,获吴恩达推荐。全书以图解方式讲解LLM原理、提示工程、文本分类生成、多模态应用及优化技术,分为理解原理、应用及优化三部…...

Blender 3MF插件:开源3D打印数据交换的终极解决方案
Blender 3MF插件:开源3D打印数据交换的终极解决方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 在3D打印行业快速发展的今天,数据交换的完整性…...

3步终极解决方案:如何专业卸载Windows 10/11的Microsoft Edge浏览器
3步终极解决方案:如何专业卸载Windows 10/11的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemo…...

长期使用TaotokenTokenPlan套餐的成本控制实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken TokenPlan套餐的成本控制实际感受 1. 从按次计费到预付费套餐的转变 在项目开发中引入大模型API调用后…...

7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘
7个实用技巧让你快速掌握Sabaki围棋软件:从零基础到高手复盘 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器ÿ…...