Python数据分析NumPy和pandas(二十三、数据清洗与预处理之五:pandas的分类类型数据)
pandas的分类类型数据(Categorical Data)
这次学习使用Categorical Data,在某些 pandas 操作中使用分类类型能实现更好的性能和减少内存使用。另外还学习一些工具,这些工具有助于在统计和机器学习应用程序中使用分类数据。
一.背景
通常,表中的列会包含一组具有非重复值的同类型实例,之前学习的 unique 和 value_counts 函数,它们使我们能够从数组中提取不同的值并分别计算它们的频率。
import numpy as np
import pandas as pdnp.random.seed(12345)
# []*2 表示重复两次
values = pd.Series(['apple', 'orange', 'apple', 'apple'] * 2)
print(values)# 使用unique()对values去重,输出一个列表
print(pd.unique(values))# 使用value_counts()对values中出现的不同值计算出现的频次(计数),输出一个Series
print(values.value_counts())输出结果:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
dtype: object
['apple' 'orange']
apple 6
orange 2
Name: count, dtype: int64
许多数据系统(用于数据仓库、统计计算或其他用途)已经开发了专门的方法来表示具有重复值的数据,以实现更高效的存储和计算。在数据仓库中,最佳实践是使用包含不同值的所谓维度表,并将主要观测值存储为引用维度表的整数键:
import numpy as np
import pandas as pd# []*2 表示重复两次
values = pd.Series([0, 1, 0, 0] * 2)
dim = pd.Series(['apple', 'orange'])# 可以使用 take() 方法恢复原来的 Series 字符串。
# 原来的Series字符串:pd.Series(['apple', 'orange', 'apple', 'apple'] * 2)
val_str = dim.take(values)print(values)
print(dim)
print(val_str)输出结果:
0 0
1 1
2 0
3 0
4 0
5 1
6 0
7 0
dtype: int64
0 apple
1 orange
dtype: object
0 apple
1 orange
0 apple
0 apple
0 apple
1 orange
0 apple
0 apple
dtype: object
这种整数表示形式称为 categorical 或 dictionary-encoded 表示形式(例如:上面的apple用0表示,orange用1表示)。不同值的数组可以称为数据的类别、字典或级别。这里,我们将使用分类和类别(categorical 和 categories)这两个术语。引用类别的整数值称为类别代码或简称代码。
在执行分析时,分类表示可以显著提高性能(简单理解:就是用整数值代替原值分析,类似于上面的示例用0代表apple,1代表orange)。另外还可以对类别执行转换,同时保持代码不变。
可以以相对较低的成本进行的一些示例转换包括:重命名类别;添加新类别而不更改现有类别的顺序或位置。
二.pandas 中的分类扩展类型
pandas 具有特殊的 Categorical 扩展类型,用于保存使用基于整数的 categorical 表示或编码的数据。这是一种流行的数据压缩技术,适用于多次出现相似值的数据,并且可以以较低的内存使用量提供明显更快的性能,尤其是对于字符串数据。看下面的代码示例:
import numpy as np
import pandas as pd# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)df = pd.DataFrame({'fruit': fruits, 'basket_id': np.arange(N), 'count': rng.integers(3, 15, size=N), 'weight': rng.uniform(0, 4, size=N)}, columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)df输出:
| basket_id | fruit | count | weight | |
|---|---|---|---|---|
| 0 | 0 | apple | 11 | 1.564438 |
| 1 | 1 | orange | 5 | 1.331256 |
| 2 | 2 | apple | 12 | 2.393235 |
| 3 | 3 | apple | 6 | 0.746937 |
| 4 | 4 | apple | 5 | 2.691024 |
| 5 | 5 | orange | 12 | 3.767211 |
| 6 | 6 | apple | 10 | 0.992983 |
| 7 | 7 | apple | 11 | 3.795525 |
fruit_cat输出:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category Categories (2, object): ['apple', 'orange']
fruit_cat 的值现在是 pandas.Categorical 的实例,可以通过 .array 属性访问:
import numpy as np
import pandas as pd# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)df = pd.DataFrame({'fruit': fruits, 'basket_id': np.arange(N), 'count': rng.integers(3, 15, size=N), 'weight': rng.uniform(0, 4, size=N)}, columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)c = fruit_cat.array
print(type(c))
type(c)输出:
pandas.core.arrays.categorical.Categorical
Categorical 对象具有 categories 和 codes 属性:
import numpy as np
import pandas as pd# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)df = pd.DataFrame({'fruit': fruits, 'basket_id': np.arange(N), 'count': rng.integers(3, 15, size=N), 'weight': rng.uniform(0, 4, size=N)}, columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)c = fruit_cat.array
print(type(c))# Categorical 对象的 categories 和 codes 属性
print(c.categories)
print(c.codes)c.categories 输出:
Index(['apple', 'orange'], dtype='object')
c.codes 输出:
array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int8)
使用 categories 访问器会更方便,稍后在 “分类方法” 中学习使用。
在代码和类别之间进行映射的一个非常使用技巧是使用dict和enumerate,例如:
dict(enumerate(c.categories))
输出:{0: 'apple', 1: 'orange'}
可以将转换后的结果列赋值给DataFrame的相应列,使其转换为分类列;还可以用其他的Python序列类型直接创建 pandass.Categorical列。例如下面代码中的后5行:
import numpy as np
import pandas as pd# []*2 表示重复两次
fruits = ['apple', 'orange', 'apple', 'apple'] * 2
N = len(fruits)# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)df = pd.DataFrame({'fruit': fruits, 'basket_id': np.arange(N), 'count': rng.integers(3, 15, size=N), 'weight': rng.uniform(0, 4, size=N)}, columns=['basket_id', 'fruit', 'count', 'weight'])
print(df)# df['fruit'] 是一个 Python 字符串对象的数组。我们可以通过如下调用将其转换为 categorical:
fruit_cat = df['fruit'].astype('category')
print(fruit_cat)c = fruit_cat.array
print(type(c))# Categorical 对象的 categories 和 codes 属性
print(c.categories)
print(c.codes)dict(enumerate(c.categories))df['fruit'] = df['fruit'].astype('category')
print(df['fruit'])my_categories = pd.Categorical(['foo', 'bar', 'baz', 'foo', 'bar'])
print(my_categories)print(df['fruit']) 输出:
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): ['apple', 'orange']
print(my_categories) 输出:
['foo', 'bar', 'baz', 'foo', 'bar']
Categories (3, object): ['bar', 'baz', 'foo']
如果从其他来源获取了分类编码数据,则可以使用替代 from_codes 构造函数,例如:
import numpy as np
import pandas as pdcategories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
print(my_cats_2)输出:
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo', 'bar', 'baz']
除非明确指定,否则分类转换不假定类别的特定排序。因此,categories 数组的顺序可能会有所不同,具体取决于输入数据的顺序。但使用 from_codes 或任何其他构造函数时,可以指示类别有意义的排序:
import numpy as np
import pandas as pdcategories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
ordered_cat = pd.Categorical.from_codes(codes, categories, ordered=True)
print(ordered_cat)输出:
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo' < 'bar' < 'baz']
输出 [foo < bar < baz] 表示在排序中 'foo' 在 'bar' 之前,依此类推。另外,可以使用 as_ordered 对无序分类实例进行排序:
import numpy as np
import pandas as pdcategories = ['foo', 'bar', 'baz']
codes = [0, 1, 2, 0, 0, 1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
print(my_cats_2.as_ordered())用as_ordered() 输出:
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo' < 'bar' < 'baz']
最后要注意的是,分类数据不必是字符串,虽然上面我只学习展示了字符串示例。分类数组可以包含任何不可变的值类型。
三.使用 Categoricals 进行计算
与 unencoded 版本(如字符串数组)相比,在 pandas 中使用 Categorical 的行为方式通常相同。pandas 的某些功能(如 groupby 函数)在处理分类时性能更好,还有一些函数可以使用 ordered 标志。
下面学习一个示例,对一些随机数值数据使用 pandas.qcut 分箱函数,返回 pandas.Categorical:
import numpy as np
import pandas as pd# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)# 计算此数据draws的四分位数分箱并提取一些统计数据
bins = pd.qcut(draws, 4)
print(bins)print(bins)输出:
[(-3.121, -0.675], (0.687, 3.211], (-3.121, -0.675], (-0.675, 0.0134], (-0.675, 0.0134], ..., (0.0134, 0.687], (0.0134, 0.687], (-0.675, 0.0134], (0.0134, 0.687], (-0.675, 0.0134]]
Length: 1000
Categories (4, interval[float64, right]): [(-3.121, -0.675] < (-0.675, 0.0134] < (0.0134, 0.687] <
(0.687, 3.211]]
下面我们给四分位数用labels参数指定名称,可能在数据分析或生成报表时更有用:
import numpy as np
import pandas as pd# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)# 计算此数据draws的四分位数分箱并提取一些统计数据,用labels指定四分位数名称
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
print(bins)输出:
['Q1', 'Q4', 'Q1', 'Q2', 'Q2', ..., 'Q3', 'Q3', 'Q2', 'Q3', 'Q2']
Length: 1000
Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']
在用print(bins.codes[:10]) 输出看看:[0 3 0 1 1 0 0 2 2 0]
设置了labels的 bins 分类不包含边缘数据的信息,因此我们可以使用 groupby 来提取一些汇总统计信息:
import numpy as np
import pandas as pd# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
# 正态分布数据
draws = rng.standard_normal(1000)# 计算此数据draws的四分位数分箱并提取一些统计数据,用labels指定四分位数名称
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
bins = pd.Series(bins, name='quartile')
results = (pd.Series(draws).groupby(bins).agg(['count', 'min', 'max']).reset_index())
print(results)
print(results['quartile'])results输出:
quartile count min max
0 Q1 250 -3.119609 -0.678494
1 Q2 250 -0.673305 0.008009
2 Q3 250 0.018753 0.686183
3 Q4 250 0.688282 3.211418
results['quartile'] 输出:
0 Q1
1 Q2
2 Q3
3 Q4
Name: quartile, dtype: category
Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']
results中的 'quartile' 列保留 bin 中的原始分类信息,包括排序。
四.使用分类(categoricals)提高性能
在前面,我说过分类类型可以提高性能和内存使用,我们看一些例子,考虑一些具有 1000 万个元素和少量不同类别的 Series:
import numpy as np
import pandas as pd# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)
N = 10_000_000
labels = pd.Series(['foo', 'bar', 'baz', 'qux'] * (N // 4))# 将标签转换为分类标签:
categories = labels.astype('category')# 用以下代码来比较labels和categories的内存使用情况
lab_mem = labels.memory_usage(deep=True)
cat_men = categories.memory_usage(deep=True)
print(lab_mem, '\t', cat_men)内存对比输出:600000132 10000544 ,从输出可以看出categories对内存的使用明显要小。当然,转换为类别(categories)不是免费的,但是只需要一次性消耗。使用 categoricals 时,GroupBy 操作可以明显加快速度,因为基础算法使用基于整数的 codes 数组,而不是字符串数组。大家可以用labels.value_counts()和categories.value_counts()消耗的时间做个对比,会发现categories.value_counts()耗时比labels.value_counts()少指数级甚至少的更多。
五.分类的方法
包含分类数据的序列具有几个类似于 Series.str 专用字符串方法的特殊方法。特殊访问器属性 cat 提供对 categorical 方法的访问。
import numpy as np
import pandas as pd# 设置一个种子,为了每次运行获取相同的随机值
rng = np.random.default_rng(seed=12345)s = pd.Series(['a', 'b', 'c', 'd'] * 2)
cat_s = s.astype('category')
print(cat_s)
print(cat_s.cat.codes)
print(cat_s.cat.categories)# 假设我们知道此数据的实际类别集超出了数据中观察到的四个值,可以使用 set_categories 方法来更改它们
actual_categories = ['a', 'b', 'c', 'd', 'e']
cat_s2 = cat_s.cat.set_categories(actual_categories)
print(cat_s2)print(cat_s.value_counts())
print(cat_s2.value_counts())以上代码输出:
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (4, object): ['a', 'b', 'c', 'd']
0 0
1 1
2 2
3 3
4 0
5 1
6 2
7 3
dtype: int8
Index(['a', 'b', 'c', 'd'], dtype='object')
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (5, object): ['a', 'b', 'c', 'd', 'e']
a 2
b 2
c 2
d 2
Name: count, dtype: int64
a 2
b 2
c 2
d 2
e 0
Name: count, dtype: int64
在大型数据集中,分类通常用作节省内存和提高性能的便捷工具。筛选大型 DataFrame 或 Series 后,许多类别可能不会显示在数据中。为了帮助解决这个问题,我们可以使用 remove_unused_categories 方法来修剪未观察到的类别:
import numpy as np
import pandas as pds = pd.Series(['a', 'b', 'c', 'd'] * 2)
cat_s = s.astype('category')cat_s3 = cat_s[cat_s.isin(['a', 'b'])]
print(cat_s3)
print(cat_s3.cat.remove_unused_categories())cat_s3输出:
0 a
1 b
4 a
5 b
dtype: category
Categories (4, object): ['a', 'b', 'c', 'd']
cat_s3.cat.remove_unused_categories() 输出:
0 a
1 b
4 a
5 b
dtype: category
Categories (2, object): ['a', 'b']
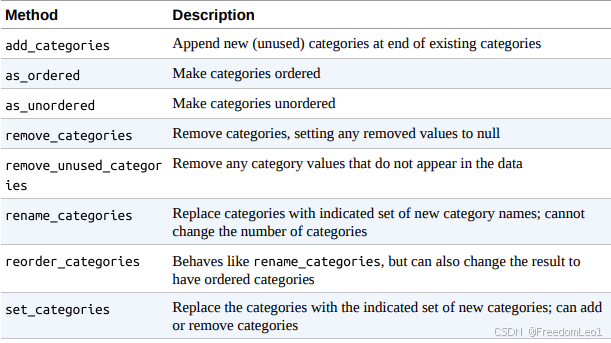
下图是可用分类方法的列表:
六.创建用于建模的虚拟变量
当您使用统计或机器学习工具时,通常会将分类数据转换为虚拟变量,也称为独热编码。这涉及创建一个 DataFrame,其中包含每个不同类别的列;这些列包含给定类别的出现次数,出现一次为 1,否则为 0。使用pandas.get_dummies 函数将此一维分类数据转换为包含虚拟变量的 DataFrame:
import numpy as np
import pandas as pdcat_s = pd.Series(['a', 'b', 'c', 'd'] * 2, dtype='category')
# 这里要指定dtype类型,否则会返回布尔型,这是因为新版pandas的原因
pd.get_dummies(cat_s, dtype=float)
print(a)输出结果:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 1.0 | 0.0 | 0.0 | 0.0 |
| 5 | 0.0 | 1.0 | 0.0 | 0.0 |
| 6 | 0.0 | 0.0 | 1.0 | 0.0 |
| 7 | 0.0 | 0.0 | 0.0 | 1.0 |
总结:有效的数据准备可以让我们花更多时间分析数据,减少准备分析的时间,从而显著提高工作效率。数据清洗与预处理的学习先到这,学的内容要不断的实操练习才会熟练。后面我将继续学习数据整理:连接、合并和重塑等。
相关文章:
Python数据分析NumPy和pandas(二十三、数据清洗与预处理之五:pandas的分类类型数据)
pandas的分类类型数据(Categorical Data) 这次学习使用Categorical Data,在某些 pandas 操作中使用分类类型能实现更好的性能和减少内存使用。另外还学习一些工具,这些工具有助于在统计和机器学习应用程序中使用分类数据。 一.背…...
--multi/exec/eval命令执行流程)
redis源码系列--(二)--multi/exec/eval命令执行流程
本文主要记录multi/exec、eval、redis执行lua脚本的源码流程 redis在exec之前,所有queued的命令是没有执行的,!!!在执行时会通过检测client是否被打上CLIENT_DIRTY_CAS标记来判断[watch后,exec时]时间段内是否有key被…...

【力扣打卡系列】移动零(双指针)
坚持按题型打卡&刷&梳理力扣算法题系列,语言为go,Day19 移动零(双指针) 题目描述 解题思路 p和q同时从起点移动,p每次都,q仅在交换时,p遇到非零数时与p值交换!!…...

无源元器件-电容选型参数总结
🏡《总目录》 目录 1,概述2,电容选型参数2.1,电容值(Capacitance)2.2,额定电压(Rated Voltage )2.3,外观(Appearance)2.4,尺寸(Dimension)2.5,耐压(Voltage Proof)2.6,绝缘电阻(Insulation Resistance)2.7,耗散因子或耗散系数(IQ or Dissipation Facto…...

Linux下的socket编程
概述 下面是一个通用的server端程序源码,用于实现两个client之间的通信。 功能 1、接收user的命令cmd消息,并将cmd消息发送到dev; 2、接收dev的应答ack消息,并将ack消息发送到user; 架构实现 通过6个线程实现。 …...

【算法】Floyd多源最短路径算法
目录 一、概念 二、思路 三、代码 一、概念 在前面的学习中,我们已经接触了Dijkstra、Bellman-Ford等单源最短路径算法。但首先我们要知道何为单源最短路径,何为多源最短路径 单源最短路径:从图中选取一点,求这个点到图中其他…...

iOS SmartCodable 替换 HandyJSON 适配记录
前言 HandyJSON群里说建议不要再使用HandyJSON,我最终选择了SmartCodable 来替换,原因如下: 首先按照 SmartCodable 官方教程替换 大概要替换的内容如图: 详细的替换教程请前往:使用SmartCodable 平替 HandyJSON …...
)
使用 axios 拦截器实现请求和响应的统一处理(附常见面试题)
在现代前端开发中,我们经常需要向服务器发送 HTTP 请求,并根据响应内容做不同的处理。axios 是一个流行的 HTTP 库,提供了 拦截器 功能,可以在请求和响应阶段插入自定义逻辑,这使得我们在处理认证、错误提示等场景时更…...
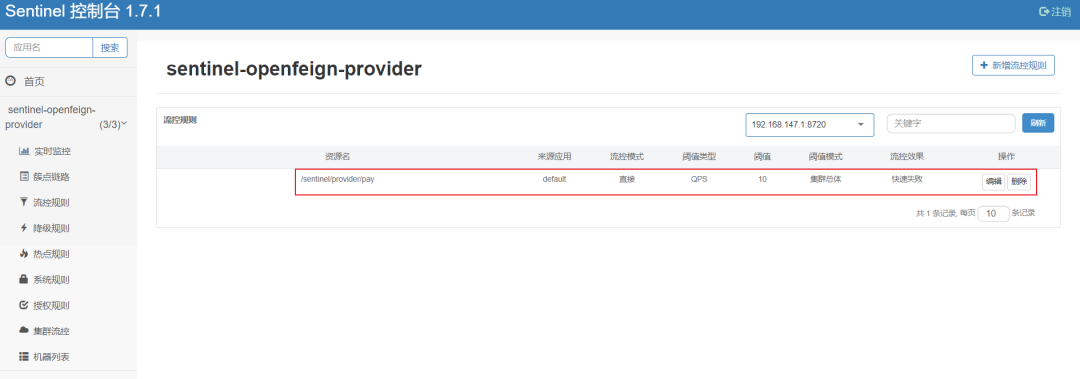
阿里 Sentinel
1、什么是sentinel? sentinel顾名思义:卫兵;在Redis中叫做哨兵,用于监控主从切换,但是在微服务中叫做流量防卫兵。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定…...

【点云网络】 pointnet 和 pointnet++
这两个网络都是斯坦福大学的一个团队提出的 我先先看一下pointnet的网络架构,这个网络比较经典,是2016年提出的: PointNet 是一个专门用于点云数据处理的神经网络。它的设计目的是直接操作不规则的点云数据,而无需将点云数据转换为规则网格或…...

.net core mvc 控制器中页面跳转
方式一: 在控制器的方法内部结尾使用 return View(); 来打开与方法同名的页面,如: public ActionResult Login() { return View(); } 该写法打开 Login 页面。 方式二: 可以添加参数来显式地指定要跳转的页面࿰…...

大学适合学C语言还是Python?
在大学学习编程时,选择C语言还是Python,这主要取决于你的学习目标、专业需求以及个人兴趣。以下是对两种语言的详细比较,帮助你做出更明智的选择: C语言 优点: 底层编程:C语言是一种底层编程语言&#x…...

跳表原理课堂笔记
课程地址 跳表是一种基于随机化的有序数据结构,它提出是为了赋予有序单链表以 O(logn) 的快速查找和插入的能力 创建 首先在头部创建一个 sentinel 节点,然后在 L1 层采用“抛硬币”的方式来决定 L0 层的指针是否增长到 L1 层 例如上图中,L…...

Windows系统使用OpenSSL生成自签名证书
Nginx服务器添加SSL证书。 要在Windows系统的Nginx Web服务器上使用OpenSSL生成证书,并确保该证书能在局域网内被计算机信任,你可以按照以下详细步骤进行操作: 一、生成证书 下载并安装OpenSSL: 从OpenSSL的官方网站下载适用于Wi…...

定位new的表达式
这里面会涉及内存池,所谓的内存池就是池化技术,让我们使用的更加方便,里面有1.线存池和连接池。 如果想要高频释放内存池,要针对系统有个堆,而堆事针对我们需要的生擒一个特例,和我们家庭里面妈妈给爸爸的…...

矩阵特殊打印方式
小伙伴们大家好,好几天没更新了,主要有个比赛。从今天起继续给大家更新,今天给大家带来一种新的题型:矩阵特殊打印方式。 螺旋打印矩阵 解题思路 首先给大家看一下什么是螺旋方式打印: 就像这样一直转圈圈。 我想大多…...

OCC 拟合的平面转换为有界平面
问题:针对导入的部分面无法获取大小,同时也无法判断点是否在面上。但是OBB可以获取大小 解决方法:通过面拟合转换gp_Pln,然后获取面的内外边,重新修剪生成新的TopoDS_Face 疑问:本人对OCC中各种面的特性不…...

Nginx性能优化的几个方法
文章目录 一 Nginx 配置优化二 缓存利用三 压缩策略四 安全性优化修改配置文件修改 Nginx 源码使用第三方模块 五 监控和日志优化六 系统层面优化七 故障转移优化 小伙伴们平时使用 Nginx 是否有进行过性能优化呢?还是软件装好了就直接使用呢? 今天松哥和…...

Unity性能优化5【物理篇】
1.刚体的碰撞检测属性首选离散型 离散碰撞的缺点是小物体快速移动时,有丢失碰撞的风险。此下拉菜单中,越下面的选项碰撞检测频率越高,性能消耗也显著增加。因此在选择碰撞检测类型时尽量选择离散型。 2.优化碰撞矩阵 合理标记碰撞矩阵可以减…...

我的工具列表
开发工具 名称备注Visual Studio微软开发工具集Visual Studio Code代码编辑器Qt CreatorQt IDEQt Design StudioQt 界面设计器linguistQt 国际化翻译PyCharmPython IDEVMware Workstation Pro虚拟机MATLAB数据计算和仿真Keil单片机 IDENavicat Premium数据库管理MobaXterm远程…...

别再死记硬背真值表了!用Logsim动态仿真,直观理解RS和D触发器的工作原理
动态仿真教学:用Logsim破解RS与D触发器的核心原理 当你第一次翻开数字电路教材,看到那些密密麻麻的真值表和抽象的逻辑符号时,是否感到一阵眩晕?传统教学往往要求学生死记硬背各种触发器的状态转换规则,却很少解释这些…...

taotoken的按token计费模式如何帮助个人开发者控制实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的按Token计费模式如何帮助个人开发者控制实验成本 对于个人开发者、学生或独立研究者而言,在探索AI应用或进行…...

HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南
HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 你是否厌倦了炉石传说中繁琐的动画等待?是否渴望更高效的游…...

基于DSP与SC1083 ADC的光纤远程数据采集系统设计实战
1. 项目概述:当DSP遇上高速光缆,如何构建一个“快、准、稳”的远程数据采集系统在工业自动化、电力监测、超声无损检测这些领域,我们经常需要面对一个头疼的问题:如何把现场传感器采集到的大量、高速、有时甚至是微弱的模拟信号&a…...

【Midjourney颗粒感控制白皮书】:基于1278组V6.1→V6.2渲染样本的统计建模,颗粒强度与--chaos关联性达r=0.93
更多请点击: https://intelliparadigm.com 第一章:Midjourney颗粒感控制白皮书导论 颗粒感(Grain)是Midjourney图像生成中影响画面质感、胶片氛围与艺术真实性的关键隐式参数。它并非独立命令,而是深度耦合于 --sty…...

如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南
如何在现代显示器上完美重温经典游戏?终极宽屏修复工具包指南 【免费下载链接】WidescreenFixesPack Plugins to make or improve widescreen resolutions support in games, add more features and fix bugs. 项目地址: https://gitcode.com/gh_mirrors/wi/Wides…...

大模型概念遗忘:SCUGP梯度投影实现精准神经外科手术
1. 项目概述:这不是“删除记忆”,而是给大模型做一次精准的神经外科手术“Who is Harry Potter?”——这个看似简单的问答,恰恰成了检验大模型“概念遗忘”能力的黄金测试题。微软研究院这篇论文标题里藏着一个反直觉的事实:他们…...

告别云服务器:利用家庭宽带公网IPv6,零成本搭建你的专属开发/测试环境
告别云服务器:利用家庭宽带公网IPv6,零成本搭建你的专属开发/测试环境 在云计算成本日益攀升的今天,个人开发者和初创团队常常面临一个两难选择:要么支付高昂的云服务费用,要么忍受本地开发环境的局限性。但很少有人意…...

如何为Public Money Public Code网站添加新的支持组织:完整操作指南
如何为Public Money Public Code网站添加新的支持组织:完整操作指南 【免费下载链接】publiccode.asia-legacy Website of https://publiccode.asia 项目地址: https://gitcode.com/gh_mirrors/pu/publiccode.asia-legacy 想要为publiccode.asia这个开源项目…...

基于Rust和Axum的高性能静态文件服务器架构设计与实现
基于Rust和Axum的高性能静态文件服务器架构设计与实现 【免费下载链接】simple-http-server Simple http server in Rust (Windows/Mac/Linux) 项目地址: https://gitcode.com/gh_mirrors/si/simple-http-server 在现代化开发工作流中,高效的文件共享与静态资…...