stack和queue --->容器适配器
不支持迭代器,迭代器无法满足他们的性质
边出边判断
实现
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<stack>
#include<queue>
using namespace std;
int main()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);while (!st.empty()){cout << st.top() << " ";st.pop();}cout << endl;
}

//用适配器的方式实现栈
//Stack.h#pragma once
#include<vector>
#include<list>
//模板
//template<class T>
//class stack
//{
// T* _a;
// size_t _top;
// size_t _capacity;
//};//传什么就是什么
//stack<int,vector<int>> s1;
//stack<int,list<int>> s1;namespace DD
{
//加上模板的方式template<class T, class Container>class stack{public:void push(const T& x)//入栈{_con.push_back(x);}void pop()//出栈{_con.pop_back();}const T& top() const//取栈顶元素{return _con.back();}size_t size()const//size{return _con.size();}bool empty() const//判空{return _con.empty();}private:Container _con;};
}
//Test.cpp#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<stack>
#include<queue>
using namespace std;
#include"Stack.h"
int main()
{//显示传一个容器//DD::stack<int,vector<int>> st;//实现的数组栈DD::stack<int,list<int>> st;//实现链式栈st.push(1);st.push(2);st.push(3);st.push(4);while (!st.empty()){cout << st.top() << " ";st.pop();}cout << endl;return 0;
}
//4 3 2 1//也可以是缺省的
template<class T, class Container=vector<int>>//也可以是缺省的
DD::stack<int>st;//4 3 2 1//用适配器的方式实现队列
//Queue.h#pragma once
#include<vector>
#include<list>
#include<deque>namespace DD
{template<class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);//尾插}void pop(){_con.pop_front();//头出}const T& front() const{return _con.front();}const T& back() const{return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}//Test.cpp#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<stack>
#include<queue>
using namespace std;
#include"Queue.h"//.h是用来展开的
int main()
{//DD::queue<int>q; //1 2 3 4//DD::queue<int, list<int>>q; //1 2 3 4DD::queue<int, vector<int>>q;//不支持,会报错q.push(1);q.push(2);q.push(3);q.push(4);while (!q.empty())//队列不为空取队头数据{cout << q.front() << " ";q.pop();}cout << endl;return 0;
}
deque的介绍
deque(双端队列):是一种双开口的“连续”空间的数据结果,双开口的含义是:可以在头尾两端进行插入和删除操作,并且数据复杂度为O(1)
vector 插入数据需要扩容,与vector比较,头插效率高,不需要搬移元素
list不支持随机访问
与list相比其底层是连续空间,空间利用率比较高,不需要存储额外字段
deque并不是真正连续的空间,而是由一段连续的小空间拼接而成,实际deque类似于一个动态的二维数组

为什么选择deque(核心是迭代器支撑的)作为stack和queue的底层默认容器
stack是一种先进后出的特殊线性结构,因此只要具有push_back()和pop_back()操作的线性结构都可以作为stack的底层容器,vector和list都可以
queue是先进先出的特殊线性数据结构,只要具有push_back()和pop_front()操作的线性结构都可以作为queue的底层容器,比如list
STL中对stack和queue默认选择dequeu作为其底层容器主要是因为
1)stack和queue不需要遍历(没有迭代器),只需要在固定的一端或者两端进行操作
2)在stack中元素增长时,deque比vector的效率高,不需要挪动数据,;queue中的元素增长时,deque不仅效率高,而且内存使用率高
结合了deque的缺点,完美地避开了他的缺点
deque借助其迭代器维护其假想连续的结构的方式

头插和尾插

priority_queue的模拟实现
通过对priority_queue的底层结构是堆,依次此处秩序堆堆进行通用的封装即可
//PriorityQueue.h#pragma once
#include<vector>
namespace DD
{//默认用vector适配template<class T,class Container=vector<T>>class priority_queue{public:void AdjustUp(int child){int parent = (child - 1) / 2;while (child > 0){//小堆if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}}//优先级队列的插入void push(const T& x){//要向上调整_con.push_back(x);AdjustUp(_con.size() - 1);//size是最后一个数据的下一个位置}void AdjustDown(int parent){size_t child = parent * 2 + 1;while (child < _con.size()){// 假设法,选出左右孩子中小的那个孩子if (child + 1 <_con.size() && _con[child + 1] < _con[child]){++child;}if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}//优先级队列的删除void pop(){//直接交换堆顶的数据和最后一个数据swap(_con[0], _con[_con.size() - 1]);_con.pop_back();//从根位置向下调整AdjustDown(0);}//判空bool empty(){return _con.empty();}const T& top(){return _con[0];//返回堆顶位置的数据就是根位置的数据}size_t size(){return _con.size();}private:Container _con;};
}//Test.cpp#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<stack>
#include<queue>
using namespace std;
#include"Stack.h"
#include"Queue.h"//.h是用来展开的#include"PriorityQueue.h"
int main()
{//默认是大的优先级高DD::priority_queue<int>pq;//4 3 2 1//可以改成小的优先级高//priority_queue<int,vector<int>,greater<int>>pq;//1 2 3 4pq.push(4);pq.push(2);pq.push(1);pq.push(3);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;return 0;
}//我们是小堆 所以是 1 2 3 4优先级队列还支持迭代器区间构造
//PoriorityQueue.h#pragma once
#include<vector>
namespace DD
{//默认用vector适配template<class T,class Container=vector<T>>class priority_queue{public://我们不写编译器会自动生成,自动生成会调用Container _con的默认构造//强制生成默认构造priority_queue() = default;template <class InputIterator>priority_queue(InputIterator first, InputIterator last):_con(first, last){//建堆//从最后一个结点的叶子结点开始,叶子结点不需要我们建,所以建倒着走的第一个非叶子结点,他是最后一个结点的父亲for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--);//_con.size()-1是最后一个叶子结点的下标{AdjustDown(i);}}void AdjustUp(int child){int parent = (child - 1) / 2;while (child > 0){//小堆if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}}//优先级队列的插入void push(const T& x){//要向上调整_con.push_back(x);AdjustUp(_con.size() - 1);//size是最后一个数据的下一个位置}void AdjustDown(int parent){size_t child = parent * 2 + 1;while (child < _con.size()){// 假设法,选出左右孩子中小的那个孩子if (child + 1 <_con.size() && _con[child + 1] < _con[child]){++child;}if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}//优先级队列的删除void pop(){//直接交换堆顶的数据和最后一个数据swap(_con[0], _con[_con.size() - 1]);_con.pop_back();//从根位置向下调整AdjustDown(0);}//判空bool empty(){return _con.empty();}const T& top(){return _con[0];//返回堆顶位置的数据就是根位置的数据}size_t size(){return _con.size();}private:Container _con;};
}#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
#include"PriorityQueue.h"
int main()
{
//迭代器区间可以是我们容器的,也可以是指向数组的指针int a[] = { 1,4,2,5,6,3,2 };DD::priority_queue<int>pq1(a, a + sizeof(a) / sizeof(int));
仿函数
//仿函数
//仿函数是一个类
//这个类型的对象可以像函数一样使用,因为重载了operator()
template<class T>
struct Less
{//重载了opertor()bool operator()(const T& x, const T& y)const{return x < y;}
};
int main()
{//lessFunc是这个类型的对象Less<int>lessFunc;cout << lessFunc(1, 2) << endl;cout << lessFunc.operator()(1, 2) << endl;//本质是调用operator()}//1
//1外:
仿函数可以用来建堆,以及日期类的比较
传小于是大堆
多参数构造函数支持隐式类型转换
我们默认没传是大堆
sort(aq1.begin(),dq1.end(),less<int>()); //是函数对应的参数,要加()priority_queue<int,vector<int>,less<int>> pq; //是类对应的参数,不加()相关文章:
stack和queue --->容器适配器
不支持迭代器,迭代器无法满足他们的性质 边出边判断 实现 #define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> #include<stack> #include<queue> using namespace std; int main() {stack<int> st;st.push(1);st.push(2);st.push(3);…...

ffmpeg视频解码
一、视频解码流程 使用ffmpeg解码视频帧主要可分为两大步骤:初始化解码器和解码视频帧,以下代码以mjpeg为例 1. 初始化解码器 初始化解码器主要有以下步骤: (1)查找解码器 // 查找MJPEG解码器pCodec avcodec_fin…...

前端入门一之CSS知识详解
前言 CSS是前端三件套之一,在MarkDown中也完美兼容这些语法;这篇文章是本人大一学习前端的笔记;欢迎点赞 收藏 关注,本人将会持续更新。 文章目录 Emmet语法:CSS基本语法:css语法结构只有3种:…...
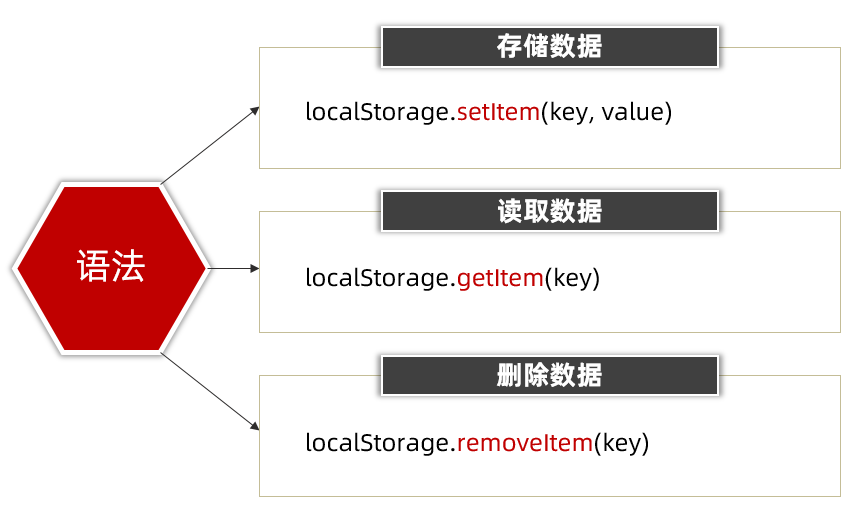
【JS学习】10. web API-BOM
文章目录 Web APIs - 第5天笔记js组成window对象定时器-延迟函数location对象navigator对象histroy对象本地存储(今日重点)localStorage(重点)sessionStorage(了解)localStorage 存储复杂数据类型 综合案例…...

C#实现递归获取所有父级的列表
条件: 父级的id是子级的父id形成递归条件 实现功能: 获取自己到最顶级父级的列表(假如最顶级父级的父ID0) 代码: 解释:CF_CODE是自己的ID,CF_PARENT_ID是父id /// <summary>/// 递归获…...

【深度学习】梯度累加和直接用大的batchsize有什么区别
梯度累加与使用较大的batchsize有类似的效果,但是也有区别 1.内存和计算资源要求 梯度累加: 通过在多个小的mini-batch上分别计算梯度并累积,梯度累积不需要一次加载所有数据,因此显著减少了内存需求。这对于显存有限的设别尤为重…...

【Linux】网络相关的命令
目录 ① ip addr show ② ip route show ③ iptables -nvL ④ ping -I enx00e04c6666c0 192.168.1.100 ⑤ ip route get 192.168.1.100 ⑥ sudo ip addr add dev enx00e04c6666c0 192.168.1.101/24 ⑦ ifconfig ⑧ netstat ⑨ traceroute ⑩ nslookup ① ip addr sho…...
-四数相加II)
leetcode哈希表(五)-四数相加II
题目 454.四数相加II 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0 示例 1: 输入&…...

Java学习路线:Maven(一)认识Maven
目录 认识Maven 新建Maven文件 导入依赖 认识Maven Maven是一个Java的项目管理工具,通过Maven,我们可以实现: 项目自动构建,包括代码的编译、测试、打包、安装等依赖管理,快速完成依赖的导入 在学习Maven之前&…...

【深度学习】— 多输入多输出通道、多通道输入的卷积、多输出通道、1×1 卷积层、汇聚层、多通道汇聚层
【深度学习】— 多输入多输出通道、多通道输入的卷积、多输出通道、11 卷积层、汇聚层、多通道汇聚层 多输入多输出通道多通道输入的卷积示例:多通道的二维互相关运算 多输出通道实现多通道输出的互相关运算 11 卷积层11 卷积的作用 使用全连接层实现 11 卷积小结 …...

java mapper 的 xml讲解
<?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace"com.bnc.s12.mapper.GoodaCateDT…...

全面解析:区块链技术及其应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 全面解析:区块链技术及其应用 文章目录 全面解析:区块链技术及其应用什么是区块链区块链的工作原理1. 分…...

python基础学习笔记
本文类比c语言讲解python 一.变量和类型 前缀小知识: 注意:1.python写每一行代码时,结尾不需要 ; 这点是和c语言有很大区别的 2.代码的缩进(就是每行代码前面的空格)是非常重要的后文会提到 1.定义变量 注意: 和C/C …...

【dvwa靶场:XSS系列】XSS (DOM) 低-中-高级别,通关啦
一、低级low 拼接的url样式: http://127.0.0.1/dvwa/vulnerabilities/xss_d/?default 拼接的新内容 <script>alert("假客套")</script> 二、中级middle 拼接的url样式: http://127.0.0.1/dvwa/vuln…...

ONLYOFFICE 8.2深度体验:高效协作与卓越性能的完美融合
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ONLYOFFICE 8.2 🔍引言📒1. ONLYOFFICE 产品简介📚2. 功能与特点🍁协作编辑 PDF🍂…...

Mac如何将多个pdf文件归并到一个
电脑:MacBook Pro M1 操作方式: very easy 选中想要归并的所有pdf文件,然后 右键 -> quick actions -> Create PDF 然后就可以看到将所选pdf文件归并为一个pdf的文件了...

LINUX下的Mysql:Mysql基础
目录 1.为什要有数据库 2.什么是数据库 3.LINUX下创建数据库的操作 4.LINUX创建表的操作 5.SQL语句的分类 6.Mysql的架构 1.为什要有数据库 直接用文件直接存储数据难道不行吗?非得搞个数据库呢? 首先用文件存储数据是没错,但是文件不方…...

自然语言处理方向学习建议
自然语言处理方向学习建议 自然语言处理(NLP)作为人工智能的一个重要分支,近年来在学术界和工业界都取得了显著的发展。作为即将或正在攻读博士学位的你,投身于NLP领域无疑是一个充满挑战与机遇的选择。以下是一些针对NLP方向学习…...

介绍一下如何生成随机数(c基础)
适合对象 c语言初学者 总结语言用色,个人强调用红色,注意为易错点,若有问题请告诉我谢谢。(建议通过目录观看)。一定要自己动手打代码。 rand函数 是生成随机数的函数,但实则是伪随机数。(即是同一个值) 格式 #include<st…...

24-11-1-读书笔记(三十一)-《契诃夫文集》(五)下([俄] 契诃夫 [译] 汝龙)生活乏味但不乏魅力。
文章目录 《契诃夫文集》(五)下([俄] 契诃夫 [译] 汝龙)生活乏味但不乏魅力。目录阅读笔记总结 《契诃夫文集》(五)下([俄] 契诃夫 [译] 汝龙)生活乏味但不乏魅力。 休息,…...
)
AI Agent社交交互延迟超800ms?——用eBPF+LLM Token流控双引擎压测实录(性能提升4.8倍原始基线)
更多请点击: https://intelliparadigm.com 第一章:AI Agent社交交互延迟超800ms?——用eBPFLLM Token流控双引擎压测实录(性能提升4.8倍原始基线) 当AI Agent在高并发社交场景中响应延迟突破800ms,用户会感…...

基于随机森林的加州房价二分类实验
一、加州房价数据集介绍 本实验使用模拟加州房价数据集完成随机森林二分类任务,通过构建房屋特征与房价等级的映射关系,实现房价高低二分类预测,掌握随机森林集成学习算法、模型评估、特征重要性分析与参数调优方法。 数据集简介 数据集名称&…...

大学生如何学习AI智能体?从零基础到OPC一人公司
掌握AI智能体能力,是大学生未来就业和创业的核心竞争力。 在AI智能体时代,普通人若能借助模型、智能体和自动化工具完成从任务交付到产品落地的闭环,将成为稀缺人才。智能体来了旗下的OPC中国,为大学生提供了完整的学习、实训和就…...

初创团队如何通过Taotoken模型广场选型并控制AI成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken模型广场选型并控制AI成本 对于资源有限的初创团队而言,将大模型能力集成到产品中是加速创新…...

深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化
深度解析抖音直播回放下载架构设计:从FLV流捕获到多线程存储优化 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

Triton模型服务实战:生产级部署、监控与故障排查
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界的空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在部署时被现实迎…...

从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册
从QPLL与CPLL选型到线速计算:一份给Xilinx GTY新手的时钟配置速查手册 第一次接触Xilinx UltraScale系列FPGA的GTY收发器时,最让人头疼的莫过于时钟配置。面对QPLL0、QPLL1和CPLL三种时钟源,以及N1、N2、M、D等分频参数,新手工程师…...

数字孪生赋能设备预测性维护:构建工业设备全生命周期智能运维新模式
在智能制造加速推进的今天,工业设备作为生产体系的核心资产,其稳定运行直接决定着企业的生产效率、产品质量与经济效益。但据行业统计,全球制造业每年因设备非计划停机造成的损失超过 5000 亿美元,单台关键设备每分钟停机损失可达…...

武林外传十年之约手游官网下载:武林外传十年之约最新官方下载渠道
《武林外传十年之约》又名《武林外传手游》《武林外传怀旧版》《武林外传正版复刻》,由安徽游昕联合忆往游戏运营的正版武侠 MMORPG 手游。1:1 复刻同福客栈、七侠镇、五霸岗、十八里铺等经典场景,完美还原枪豪、剑客、术士、医师四大职业体系࿰…...

第一性原理计算在半导体缺陷研究中的应用:以氢掺杂氧化镓为例
1. 项目概述:从“掺杂”与“缺陷”说起在半导体材料的研究与开发中,我们常常听到“掺杂”这个词。简单来说,就像在炒菜时撒入不同的调料来改变风味,掺杂就是在纯净的半导体材料(本征材料)中,有目…...